

水下生物在自然界中扮演着非常重要的角色,是人类宝贵的资源之一. 通过计算机视觉技术实现水下生物检测,不仅有利于水下生物资源的开发和利用,还对学术研究和经济价值都有重要的意义.
Yang等[1]采用YOLOv3 (you only look once v3)实现了对海参、海胆和扇贝的准确识别,但其未考虑水下图像失真对检测结果的影响. 徐凤强等[2]基于DSOD (deeply supervised object detector)模型提出一种智能检测和自主抓取系统,该系统能够协助机器人解决水下目标的智能检测问题并引导其自主抓取海产品,但其捕捞效率较低. Xu等[3]在ResNet-50(residual network-50)的基础上提出一种用于海洋目标检测的尺度感知特征金字塔网络,该网络实现了较好的泛化能力,但在混浊和拥挤环境下的检测性能有待提升. Wang等[4]提出一种结合空间金字塔池化(spatial pyramid pooling, SPP)和密集连接网络 (dense convolutional network, DenseNet)的方法用于淡水鱼物种识别,该方法能够有效对淡水鱼物种分类,但难以在微小型水下设备中应用. Zhao等[5]提出一种复合鱼类检测框架,通过增强路径聚合网络提高特征信息利用率,从而提高在复杂水下环境下对鱼类的识别和定位的精度,但该方法提出的模型过于复杂,不适用于微小型水下设备. Salman等[6]采用一种涉及高斯混合模型(Gaussian mixture model, GMM)和光流输出的混合方法,在R-CNN (regions with convolutional neural network features)上实现对鱼类的高精度检测,但该方法需要较大的计算资源并且实时性较差.
以上水下生物检测研究多是在经典的深度学习模型的基础上进行改进,模型具有层数深、体积大和参数量多的特点,这限制了其在移动设备中的应用,特别是在微小型水下设备中,过大的模型和冗余的参数不仅造成了存储资源的浪费,还对运行速度、续航时间产生负面影响. 目前,轻量化的模型已经被提出,如Tiny-YOLO、YOLO Nano[7]、GhostNet[8]等,但它们多用于智慧农业[9-11]、智慧城市[12-14]领域,在水下生物检测中的应用较少. Cai等[15]提出一种将YOLOv3与MobileNetv1相结合,用于实际养殖场鱼类检测的新方法,该方法实现了高精度的鱼类检测和计数,但在在线实时应用方面具有一定挑战. Qiu等[16]提出一种剪枝SSD (single shot multibox detector)的海参检测方法,该方法实现了对海参较高精度的检测,但剪枝后的模型体积依然较大. 强伟等[17]通过采用ResNet代替SSD的VGG (visual geometry group)卷积神经网络(convolutional neural networks, CNN)提升了对水下生物的检测精度,并用深度可分离卷积替代常规卷积减小了模型参数量,提升了检测速度,但改进后的模型参数量依然高达107.2 MB,影响其在水下应用的性能.
综上所述,本研究提出一种改进Mobilenet-YOLOv3的轻量化网络算法CPM-YOLOv3,并将其用于对石斑鱼的检测. 首先通过规整通道剪枝算法对Mobilenet-YOLOv3进行剪枝,去除对石斑鱼检测不重要的通道,完成对网络结构的初步压缩. 然后将特征提取网络中的SE (squeeze-and-excitation)模块全部替换成CBAM (convolutional block attention module),实现对网络结构的进一步压缩. 接着将CBAM引入检测层,在几乎不增加模型大小的前提下,提高压缩模型的检测精度. 将CPM-YOLOv3在石斑鱼数据集上训练并对模型的大小、参数量进行评估,最后验证其是否满足水下生物检测的精度和实时性要求.
1. 网络模型
1.1. Mobilenet-YOLOv3
YOLO (you only look once)是由Redmon等[18-20]提出的端到端的目标检测系列模型,包括YOLOv1、YOLOv2和YOLOv3等,其中YOLOv3能够较好地满足实时检测任务的精度和速度要求. 虽然YOLOv3在目标检测领域表现出良好的性能,但由于其模型体积大和参数量多,不适用于微小型水下设备. 本研究采用的Mobilenet-YOLOv3是通过将YOLOv3的主干网络Darknet53替换成Mobilenetv3得到的一种轻量级网络结构,其具有YOLOv3的优点,同时在一定程度上压缩了YOLOv3模型的大小. Mobilenetv3使用深度可分离卷积来构建模型,深度可分离卷积通过将标准卷积分解成逐通道卷积和逐点卷积减少计算量和参数量,进而减小网络模型,如图1所示. 同时,Mobilenetv3采用了SE[21]注意力机制,SE模块通过挤压和激励来获取每个特征通道的重要程度,使用通道重要程度去给每一个特征通道赋予权值,进而让网络模型更关注和识别目标相关的特征通道,从而提升网络模型的特征表达能力.
图 1
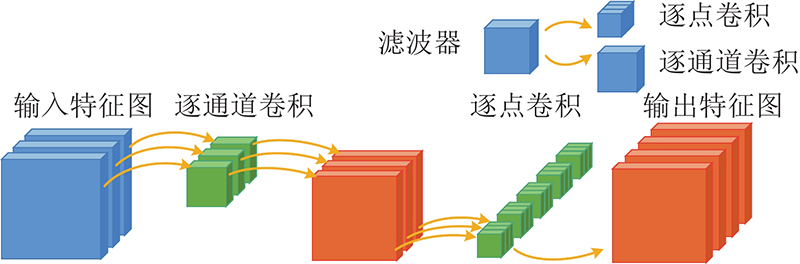
Mobilenet-YOLOv3在YOLOv3的基础上降低了计算量和参数量,在一定程度上减小了模型大小,能够应用在一般的嵌入式设备中. 但在微小型水下设备中,较大的模型和冗余的参数量不仅影响运行速度,还会降低续航时间和作业效率,设计出更小的模型不仅能节约存储空间,还能减少功耗,对水下生物检测具有很高的应用价值,因此本研究在Mobilenet-YOLOv3的基础上进一步改进,压缩模型的大小.
1.2. 规整通道剪枝策略
规整通道剪枝策略[22]本质是通过识别网络模型的通道来消除不重要的通道及相关的输入和输出关系. 在CNN中,批归一化 (batch normalization, BN)层用来对输入数据进行批归一化处理,批量标准化公式如下:
式中:
规整通道剪枝策略使用BN层中的缩放因子来评估通道的重要程度,在训练过程中通过对缩放因子施加L1正则约束,使得网络模型朝着结构性稀疏的方向调整参数,在训练结束后根据缩放因子对通道进行裁剪,通道剪枝原理如图2所示.
图 2
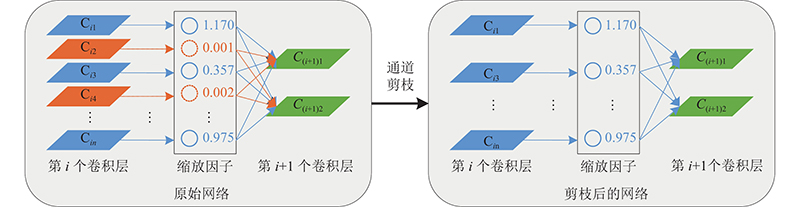
规整通道剪枝主要包括以下几个步骤:1)稀疏训练. 在训练过程中通过对缩放因子施加L1正则约束,使得网络模型朝着结构性稀疏的方向调整参数;2)通道裁剪. 在稀疏训练完成后,根据缩放因子数值以一定的裁剪比率对通道进行裁剪,以生成稀疏的网络结构;3)微调模型. 对稀疏的网络结构重新训练.
1.3. CBAM注意力机制
图 3

1.4. CPM-YOLOv3
本研究提出的CPM-YOLOv3是以Mobilenet-YOLOv3网络结构为基础,采用了多尺度特征融合的特征金字塔结构,通过提取不同感受野下的特征信息提升对不同大小目标的检测能力. CPM-YOLOv3使用了规整通道剪枝策略对网络结构进行稀疏化,并将特征提取层Mobilenetv3中的SE模块替换为CBAM,降低了模型参数量,压缩了网络模型大小,实现了对网络结构轻量化. 同时,通过在多尺度检测层中加入CBAM,在几乎不增加模型大小情况下提升了模型对目标特征的表达能力,提高了模型的检测性能. 整体的网络结构如图4所示.
图 4
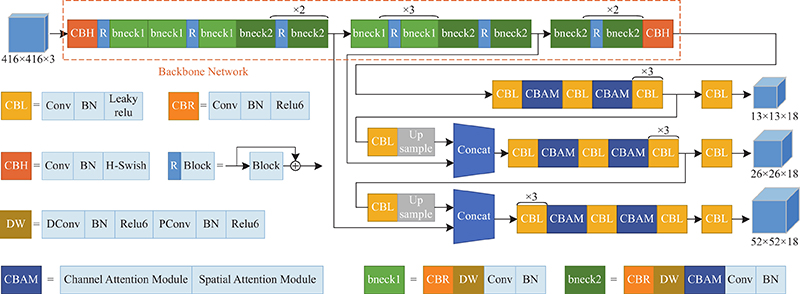
在特征提取层,CPM-YOLOv3主要采用Mobilenet-YOLOv3中的倒置残差模块. 倒置残差模块先将输入特征通过1×1卷积拓展到更高的维度,接着进行3×3或者5×5深度可分离卷积,最后使用1×1卷积进行降维,当且仅当输入和输出具有相同数量的通道时,倒置残差模块才会采用跳跃连接. 倒置残差模块在保持输入和输出的紧凑表示的同时,内部扩展到高维空间,以提高非线性全通道变换的表达能力.
Mobilenet-YOLOv3中的部分倒置残差模块在深度可分离卷积后添加SE注意力机制,激励对识别任务有用的特征通道,抑制对识别任务无用的特征通道. 在CPM-YOLOv3中将SE注意力模块替换成CBAM,和SE相比,CBAM不仅关注通道中的目标特征信息,还关注空间中目标特征信息,能够提高目标特征信息权重,同时采用CBAM替换SE模块可以有效降低参数量,减小模型大小. CPM-YOLOv3的特征提取网络结构如表1所示.
表 1 CPM-YOLOv3特征提取网络结构
Tab.1
| 输入 | 模块 | 卷积核数 | 输出 | CBAM | 激活函数 | 步幅 |
| 4162×3 | conv2d,3×3 | − | 16 | − | HS | 2 |
| 2082×16 | bneck,3×3 | 16 | 16 | − | RE | 1 |
| 2082×16 | bneck,3×3 | 64 | 24 | − | RE | 2 |
| 1042×24 | bneck,3×3 | 72 | 24 | − | RE | 1 |
| 1042×24 | bneck,5×5 | 72 | 40 | √ | RE | 2 |
| 522×40 | bneck,5×5 | 120 | 40 | √ | RE | 1 |
| 522×40 | bneck,5×5 | 120 | 40 | √ | RE | 1 |
| 522×40 | bneck,3×3 | 240 | 73 | − | HS | 2 |
| 262×73 | bneck,3×3 | 200 | 73 | − | HS | 1 |
| 262×73 | bneck,3×3 | 184 | 73 | − | HS | 1 |
| 262×73 | bneck,3×3 | 184 | 73 | − | HS | 1 |
| 262×73 | bneck,3×3 | 480 | 89 | √ | HS | 1 |
| 262×89 | bneck,3×3 | 672 | 89 | √ | HS | 1 |
| 262×89 | bneck,5×5 | 672 | 43 | √ | HS | 2 |
| 132×43 | bneck,5×5 | 960 | 43 | √ | HS | 1 |
| 132×43 | bneck,5×5 | 960 | 43 | √ | HS | 1 |
| 132×43 | conv2d,1×1 | − | 14 | − | HS | 1 |
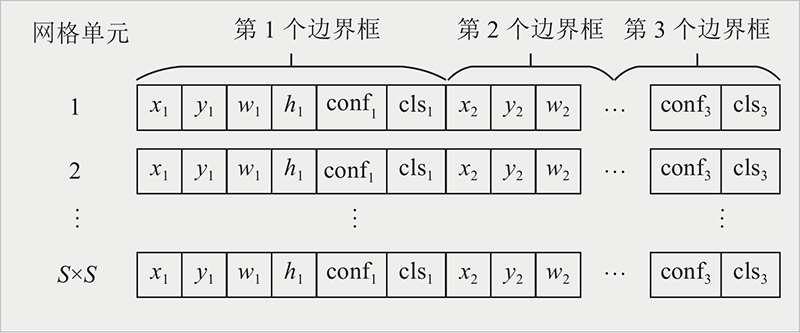
在检测层中CPM-YOLOv3采用了多尺度预测方法,在将图片输入网络模型后,经过下采样生成小尺寸特征图用于小目标检测,将小尺寸特征图进行上采样并与第25层输出的特征图融合生成中尺寸特征图,用于中等尺寸目标检测,将中等尺寸特征图进行上采样并与第49层输出的特征图进行融合,生成大尺寸特征图,用于大尺寸目标检测. 同时,本研究在每个检测层中分别加入2个CBAM,用于提高检测层关注目标特征信息的能力. 每个CBAM位置分别在第65、66、77、78、91、92卷积层后,如图4所示. 预测层的输出特征维度如图5所示,图中,S为特征图每一行或每一列的网格单元数目,xi、yi、wi、hi 为第i个边界框(bounding box, bbox)的中心点横坐标、中心点纵坐标、高度、宽度,confi为第i个bbox的置信度,clsi为第i个bbox的类别. 每个预测层的输出维度为S×S×18,S×S表示输出特征图的网格单元数,18表示每个网格单元的向量维度,包括3个6维的边界框,每个bbox包括4维的位置信息、1维的置信度和1维的类别信息.
图 5
CPM-YOLOv3在多尺度预测方法中使用了Anchor box机制[14],每种尺度预设3个Anchor box,共使用9个Anchor box. 通过使用K-means算法对预置框大小进行聚类, K-means算法采用的距离公式如下:
式中:
聚类后的预置框大小分别为(16.42,11.86)、(18.24,32.18)、(33.34,21.76) 、(35.65,66.21) 、(60.83,39.41) 、(102.51,74.16) 、(135.57,146.25) 、(244.30,192.56) 、(374.49,355.18).
CPM-YOLOv3的损失函数包含3部分:目标定位损失
式中:
式中:
2. 数据准备
图 6

表 2 石斑鱼数据集的数量信息
Tab.2
| 图像处理 | N | ||
| 非自然环境 | 自然环境下无遮挡 | 自然环境下有遮挡 | |
| 原始图像 | 100 | 415 | 150 |
| 旋转180° | 100 | 415 | 150 |
| 水平翻转 | 100 | 415 | 150 |
| 垂直翻转 | 100 | 415 | 150 |
| 添加随机噪声 | 100 | 415 | 150 |
| 提升亮度 | 100 | 415 | 150 |
| 总计 | 600 | 2490 | 900 |
3. 实验设置
3.1. 实验平台
实验硬件配置为Intel(R) Core(TM) i7-7800X CPU@3.50 GHz,模型在2个具有11 GB显存的GeForce GTX 1080 Ti上进行训练. 实验采用的操作系统为Ubuntu 18.04LTS,框架为Pytorch,使用CUDA 10.1版本并行计算框架配合cudnn 7.1版本的深度神经网络加速库.
3.2. 网络训练
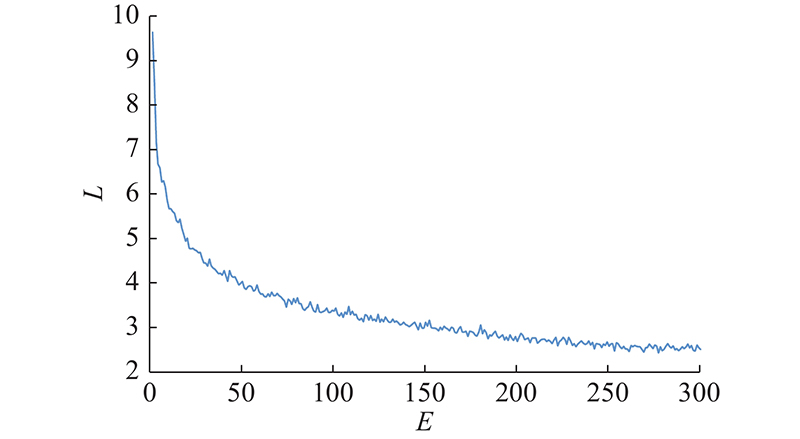
模型在训练过程中采用多尺寸图像训练,输入图像最小尺寸为320×320像素,最大尺寸为640×640像素,测试图像尺寸为512×512像素. 在训练过程中,当Anchor box与真实框的IoU>0.2时为正样本,否则为负样本. 在训练过程中采用Mosaic数据增强方法以丰富样本背景,提升网络模型的鲁棒性. 训练时的初始学习率为0.001,动量为0.9,权重衰减为0.0005,批处理大小为8. 模型总共训练了300个epoch,并分别在210个epoch和270个epoch时学习率降为原来的10%. CPM-YOLOv3在训练时的损失曲线如图7所示. 图中,L表示损失值,E表示迭代次数. 可以看出,训练损失在前50个epoch快速下降,随着迭代次数增加,损失曲线逐渐收敛.
图 7
3.3. 评价指标
本研究采用模型大小、参数量和检测时间评估模型性能,采用平均精度 (average precision, AP)和召回率(recall, R)来评价模型对石斑鱼的检测效果,以IoU为0.60时的AP和R作为检测效果的主要评价指标,以IoU为0.50、0.75时的AP50、AP75作为补充指标以验证模型的检测精度性能. AP和R的表达式如下:
式中:
4. 实验结果分析
4.1. 通道剪枝效果验证
本研究采用了规整通道剪枝策略对Mobilenet-YOLOv3进行剪枝,首先通过对BN层中的缩放因子进行稀疏训练得到不同通道的权重,接着设置不同的剪枝率对网络结构进行裁剪,得到不同大小的模型,最后将剪枝后的模型在石斑鱼数据集上进行重新训练和测试. 实验中的剪枝率分别设置为60%、70%、80%、90%、95%,不同比率剪枝后的模型的性能如表3所示. 表中,Prune60%表示剪枝率为60%的模型,其他类似;Para为参数量;M为模型大小.
表 3 不同剪枝比率下的模型
Tab.3
| 网络模型 | Para/MB | M/MB |
| Mobilenet-YOLOv3 | 22.68 | 91.08 |
| Prune60% | 4.84 | 19.66 |
| Prune70% | 3.62 | 14.78 |
| Prune80% | 2.90 | 11.88 |
| Prune90% | 2.22 | 9.08 |
| Prune95% | 1.69 | 7.02 |
如图8所示为不同比率剪枝模型在数据集上的测试结果. 可以看出,随着剪枝比率提高,剪枝后模型的平均检测精度和召回率呈下降趋势. 当剪枝比率为90%时,模型的AP、AP50、AP75分别损失了4.0%、4.2%、4.1%,R损失了2.5%. 当剪枝比率提高到95%时,模型平均检测精度和召回率大幅下降. 如表3所示,当模型剪枝为90%时,模型大小为9.08 MB,和原模型相比,模型大小降低了90.03%,参数量降低了90.21%. 平衡模型大小和检测精度,本研究选取90%的剪枝比率,并进行后续实验. 模型剪枝前、后的通道数量Nt变化如图9所示. 可以看出,不同层中被裁减掉的通道数量是不同的,这间接体现了在提取目标特征过程中,模型中的通道发挥的重要程度不一致,对重要程度小的通道进行裁剪是必要的.
图 8
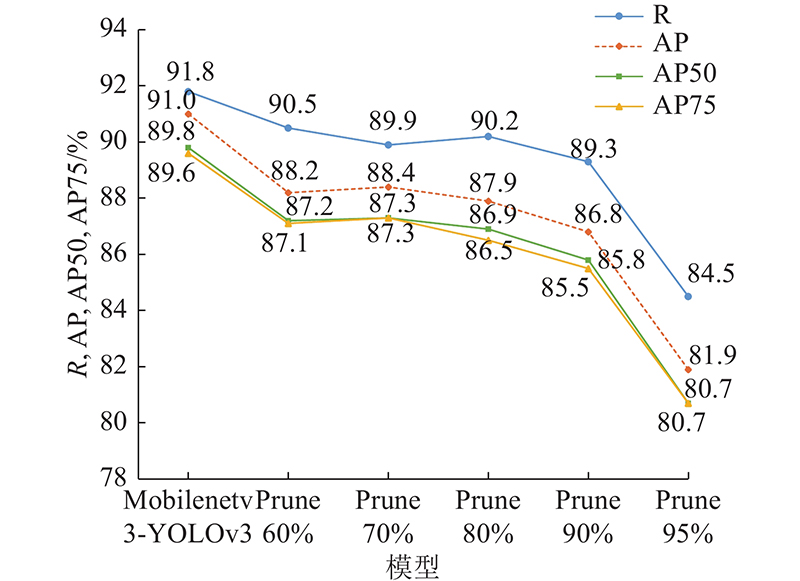
图 9
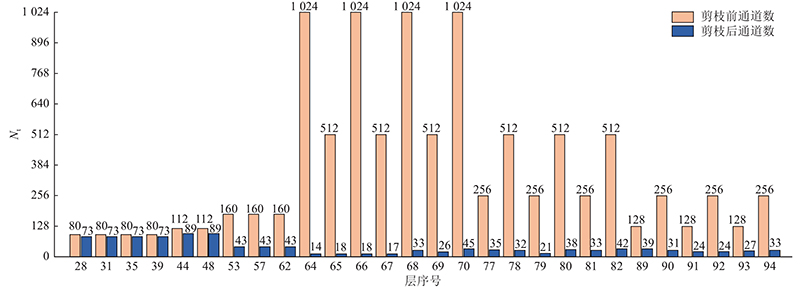
图 9 剪枝前、后通道数量对比图
Fig.9 Comparison of number of channels before and after pruning
4.2. CBAM有效性验证
如表4所示为CBAM对模型大小及检测精度的影响. 表中,T为检测时间. 可以看到,当用CBAM替换主干网络中的SE模块后,模型的参数量减少了1.08 MB,模型大小降低了46.70%,这是由于和SE机制相比,本研究CBAM中的通道注意力对通道的降维比率更大,降维后的通道数量更少,进而导致参数量和模型变小. 同时,由于CBAM采用了2种池化策略和注意力机制,对目标特征信息提取更准确,因此改进后模型的精度会有所提升. 如表4所示,当CBAM替换SE后,AP、AP50、AP75分别提升了0.2%、0.3%、0.4%,R提高了0.3%. 当在模型预测层加入CBAM后,模型AP提升了1.0%,AP50和AP75分别提升了0.9%、1.1%. 总体上,改进后的模型在检测时间上增加了0.6 ms,但参数量减小了1.08 MB,模型大小减小了4.22 MB,达到4.86 MB,AP提升了1.2%,R提升了0.4%,体现了CBAM在压缩模型大小和提升精度方面的有效性.
表 4 CBAM对模型大小及检测精度的影响
Tab.4
| 网络模型 | Para/MB | M/MB | R/% | AP/% | AP50/% | AP75/% | T/ms |
| Mobilenet-YOLOv3 Prune90% | 2.22 | 9.08 | 89.3 | 85.8 | 86.8 | 85.5 | 4.5 |
| + CBAM替换SE | 1.14 | 4.84 | 89.6 | 86.0 | 87.1 | 85.9 | 4.9 |
| + 在预测层加入CBAM | 1.14 | 4.86 | 89.7 | 87.0 | 88.0 | 87.0 | 5.1 |
| Mobilenet-YOLOv3 Prune90% (调整降维比例) | 0.80 | 3.46 | 88.2 | 85.2 | 85.2 | 84.3 | 4.3 |
为了进一步验证SE模块与CBAM中的通道注意力在相同降维比例时本研究改进模型的优越性,将剪枝90% Mobilenet-YOLOv3中SE模块全连接层的降维比例设置为与CBAM中通道注意力模块全连接层的降维比例一致并进行实验.
如表4所示,调整降维比例后的Mobilenet-YOLOv3 Prune90%在模型大小和参数量上低于其他模型,这是由于SE模块只包含通道注意力,而CBAM既包含通道注意力又包括空间注意力,当SE模块与CBAM保持相同降维比率时,模型大小能够下降并且低于CBAM,但随着模型大小减小,SE模块的检测效果也降低,而CBAM不仅能够减小模型大小,检测性能也有所提升. 如表4所示,与调整降维比例后的Mobilenet-YOLOv3 Prune90%模型相比,采用CBAM替换SE模块后,模型AP、AP50、AP75分别提高了0.8%、1.9%、1.6%,在预测层加入CBAM后,模型AP、AP50、AP75分别提高了1.8%、2.8%、2.7%. 总体上,改进后的模型在有效减小了模型大小的情况下提升了检测精度,同时表现出良好的实时性,体现了CBAM的作用.
图 10
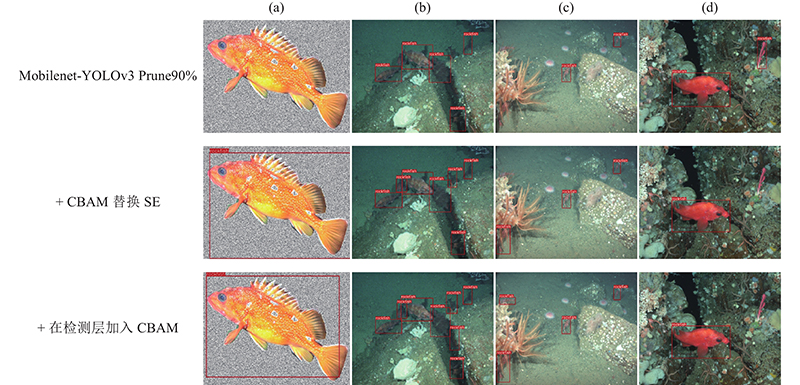
图 10 采用CBAM改进前、后检测效果对比图
Fig.10 Comparison of detection results before and after CBAM improvement
4.3. 不同算法检测效果对比
为了验证CPM-YOLOv3的模型性能和检测效果,选用原始模型及其他7种模型进行对比. 如表5所示,本研究所提出的CPM-YOLOv3模型大小仅有4.86 MB,和原始模型Mobilenet-YOLOv3相比,降低了94.66%,和YOLOv3、SSD相比,分别降低了97.93%、94.64%. 在参数量方面,和Tiny YOLOv3、Tiny YOLOv4、YOLO Nano相比,分别降低了86.85%、79.64%、60.00%. 和其他模型相比,CPM-YOLOv3 体积小、参数量少,更适合在微小型水下嵌入式设备中应用,同时CPM-YOLOv3检测速度为5.1 ms/帧,满足水下实时性检测要求.
表 5 不同算法检测结果对比
Tab.5
| 网络模型 | Para/MB | M/MB | T/ms |
| EfficientDet-D1 | 6.60 | 25.64 | 22.6 |
| SSD | 23.75 | 90.61 | 31.0 |
| YOLOv3 | 61.52 | 235.10 | 9.9 |
| Mobilenet-YOLOv3 | 22.68 | 91.08 | 5.9 |
| Tiny YOLOv3 | 8.67 | 33.17 | 2.6 |
| Tiny YOLOv4 | 5.60 | 22.50 | 4.8 |
| YOLO Nano | 2.85 | 11.22 | 53.5 |
| CPM-YOLOv3 | 1.14 | 4.86 | 5.1 |
为了详细验证CPM-YOLOv3对石斑鱼的检测情况,将模型在正常石斑鱼测试集和只含遮挡情况石斑鱼测试集上进行检测. 如图11所示,在正常测试集下,CPM-YOLOv3的平均检测精度比SSD高出7.9%,比YOLO Nano高出17.4%. 和原始模型Mobilenet-YOLOv3及EfficientDet-D1[25]、YOLOv3相比,CPM-YOLOv3在平均精度和召回率上均有降低,但依然能达到87%,能够较好地实现对石斑鱼的检测. 和轻量级模型Tiny YOLOv3相比,CPM-YOLOv3的平均精度和召回率与Tiny YOLOv3相差不大,但CPM-YOLOv3的模型更小. 和Tiny-YOLOv4相比,CPM-YOLOv3在平均精度上降低了0.6%,但召回率提高了0.5%. 在只含遮挡情况的测试集上,CPM-YOLOv3表现为84.9%的平均检测精度和87.2%的召回率,和SSD、YOLO Nano相比,平均检测精度分别提高了9.2%和37.6%,召回率分别提高了9.8%和14.5%,体现了CPM-YOLOv3在对遮挡石斑鱼的检测中也能表现较好的效果.
图 11
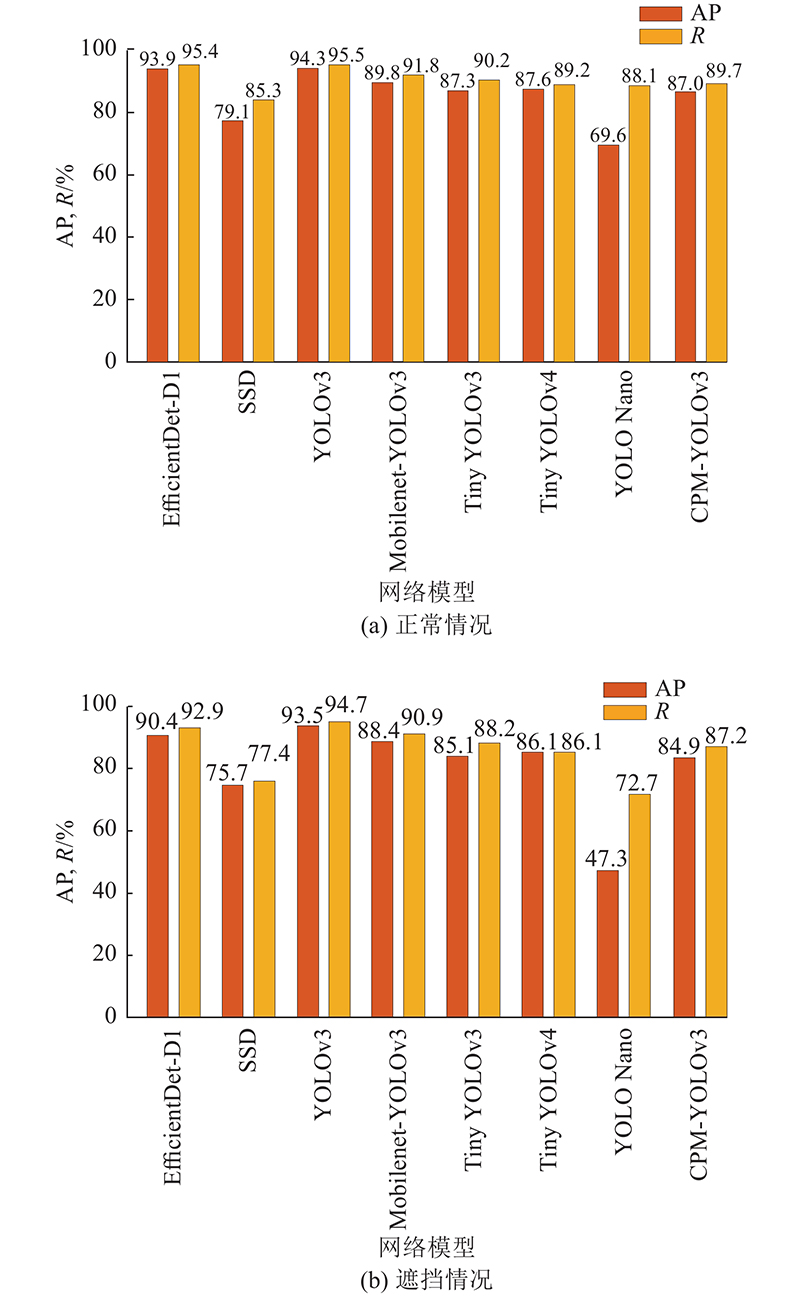
图 11 正常、遮挡测试集下的石斑鱼检测结果
Fig.11 Rockfish test results under normal and occluded test sets
如图12所示为不同模型在石斑鱼数据集上的检测效果图,在非自然数据集上,和轻量化模型Tiny YOLOv3、Tiny YOLOv4、YOLO Nano相比,CPM-YOLOv3对石斑鱼的位置信息预测更加准确,这是由于CPM-YOLOv3引入了注意力机制,模型更关注目标在特征图中的位置信息,进而导致预测位置信息更加准确. 如图12(b)所示,SSD和 YOLO Nano都存在漏检情况,而CPM-YOLOv3能够检测到所有石斑鱼. 在对只含遮挡石斑鱼图像的检测中,CPM-YOLOv3能够检测出互相遮挡的石斑鱼,实现与Mobilenet-YOLOv3、EfficientDet-D1和YOLOv3较为相同的检测效果,而SSD对遮挡石斑鱼检测效果较差,存在明显的漏检情况. YOLO Nano检测位置不准确,出现一鱼多检、检测框重复的问题,表现出较差的检测性能.
图 12

综上所述,实验结果表明,无论是正常情况还是遮挡情况,本研究提出的CPM-YOLOv3均能表现出良好的检测效果,同时,与其他模型相比,CPM-YOLOv3在模型大小和参数量方面也具优势,能够较好地平衡模型大小和检测精度、实时性,更适合在微小型水下设备中应用.
5. 结 语
针对在使用微小型设备进行水下生物检测中,由于模型较大体积和冗余的参数带来的存储资源浪费、运行及续航时间较差等问题,提出一种改进Mobilenet-YOLOv3的轻量化网络方法CPM-YOLOv3,通过规整通道剪枝算法对Mobilenet-YOLOv3进行剪枝,并将特征提取网络中的SE模块全部替换成CBAM,完成对网络结构的压缩,最终将模型大小降低了94.7%,参数量降低了95.0%. 通过在不同尺寸检测层中加入CBAM,提高了压缩后模型的检测精度. 实验结果显示CPM-YOLOv3的模型大小达到4.86 MB,平均检测精度为87.0%,速度为5.1 ms/帧,不仅有效压缩了模型大小,消除了冗余参数,还较好地实现了对水下生物的检测,在微小型水下设备中具有一定的实用性和经济价值.
本研究通过平衡模型大小、检测精度和速度提出了轻量化模型CPM-YOLOv3,实现了对石斑鱼的有效检测,但在研究过程中未考虑数据集图像质量对模型精度影响. 由于光的散射和水下悬浮粒子的影响,水下图像往往呈现对比度低、色偏严重的情况,对检测水下生物造成不利影响. 在未来研究中将采用图像增强算法提高水下数据集图像质量,进一步提升模型检测精度.
参考文献
Research on underwater object recognition based on YOLOv3
[J].DOI:10.1007/s00542-019-04694-8 [本文引用: 1]
基于水下机器人的海产品智能检测与自主抓取系统
[J].DOI:10.13700/j.bh.1001-5965.2019.0377 [本文引用: 1]
Intelligent detection and autonomous capture system of seafood based on underwater robot
[J].DOI:10.13700/j.bh.1001-5965.2019.0377 [本文引用: 1]
Scale-aware feature pyramid architecture for marine object detection
[J].DOI:10.1007/s00521-020-05217-7 [本文引用: 1]
Composited fishnet: fish detection and species recognition from low-quality underwater videos
[J].DOI:10.1109/TIP.2021.3074738 [本文引用: 1]
Automatic fish detection in underwater videos by a deep neural network-based hybrid motion learning system
[J].DOI:10.1093/icesjms/fsz025 [本文引用: 1]
基于深度学习的轻量化田间昆虫识别及分类模型
[J].
Automatic recognition and classification of field insects based on lightweight deep learning model
[J].
基于轻量卷积结合特征信息融合的玉米幼苗与杂草识别
[J].DOI:10.6041/j.issn.1000-1298.2020.12.026
Recognition of maize seedling and weed based on light weight convolution and feature fusion
[J].DOI:10.6041/j.issn.1000-1298.2020.12.026
Automatic recognition of dairy cow mastitis from thermal images by a deep learning detector
[J].DOI:10.1016/j.compag.2020.105754 [本文引用: 1]
M-YOLO: a nighttime vehicle detection method combining Mobilenet v2 and YOLO v3
[J].DOI:10.1088/1742-6596/1883/1/012094 [本文引用: 1]
Research on lightweight convolutional neural network in garbage classification
[J].DOI:10.1088/1755-1315/781/3/032011
A modified YOLOv3 model for fish detection based on MobileNet v1 as backbone
[J].DOI:10.1016/j.aquaeng.2020.102117 [本文引用: 1]
基于改进SSD 的水下目标检测算法研究
[J].DOI:10.3969/j.issn.1000-2758.2020.04.008 [本文引用: 1]
Research on underwater target detection algorithm based on improved SSD
[J].DOI:10.3969/j.issn.1000-2758.2020.04.008 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}