

基于遥感图像的自动场景分类有重要的应用价值[1-4]. 遥感图像的场景分类通常基于机器学习的监督学习方法,如支持向量机、马尔可夫随机场、随机森林等[5-7]. 这些方法常忽略图像中隐藏的稀疏信息和空间信息,因此分类结果往往不令人满意[8]. 遥感图像还有类内差异大的特点. 在不同的图像采集条件下,由于植被组成、土壤湿度和地形等不同,同类别的遥感图像差异可能很大;由于季节性、照明条件和太阳角度的变化,同一片土地覆盖类型的遥感图像也会呈现明显的差异. 随着深度学习的深入研究,基于深度模型的遥感图像场景分类研究日益兴起. Yu等[9]提出双线性卷积神经网络模型,使用轻量级卷积神经网络来提取深度和抽象的图像特征. Yang等[10]提出基于深度学习的分类框架,该框架采用深度学习分类器为图像创建场景类别的初始判断,根据从图像中检测到的特定于类别的特征对象确定场景类别. 王协等[11] 提出基于多尺度学习与深度卷积神经网络,基于残差网络构建100层编码网络,并利用膨胀卷积实现特征图像的多尺度学习.
深度学习在遥感图像分类中虽应用潜力巨大,但也面临新的挑战:1)遥感图像包含大量信息,会消耗深度学习模型中数百个频带的神经元;2)训练动态学习模型常需要大量标注样本,在新场景中,这样的操作不仅困难而且耗时. 字典学习成为解决这类问题的有效方法[12-13]. Xu等[14] 使用字典学习去除遥感图像中的云区,能够恢复被薄云、厚云或云影污染的图像. Fwrraris等[15]提出基于耦合字典学习的多模态遥感图像间无监督变化检测方法. Wang等[16]提出改进的基于粒子群优化的在线词典学习方法,该方法在噪声抑制方面有较好的效果. Wang等[17]提出基于多维协同相关的稀疏重建模型和协同稀疏模型,用于遥感图像的稀疏重建. 这些方法在样本的原始空间进行字典学习,实际的应用场景均有局限,原因如下. 1)遥感图像的高维特性使得算法复杂性随着维数的增加而增加[18];2)遥感图像的高维特征存在冗余特征信息,常规的降维方法和字典学习作为独立阶段执行,无法保留数据的最佳分类信息[19-20].
本研究提出层次型非线性子空间字典学习(hierarchical nonlinear subspace dictionary learning, HNSDL)方法. 受多层字典学习的启发,HNSDL使用层次型非线性方法将数据样本投影到子空间,实现数据降维. 为了提高模型的辨识能力,在学习过程中引入稀疏编码的局部结构约束项. 在多个真实遥感图像数据集上进行实验设计和测试.
1. 相关知识
给定数据集
式(1)的求解涉及NP-hard问题,很难获得稀疏编码a对应的解,为此引入一阶范数,将式(1)替换为
Liu等[21]证明,在解足够稀疏的情况下,式(2)的解等同于式(1)的解. 使用最小化经验损失函数,字典学习和稀疏表示进一步表示为
式中:
式中:
2. 层次型非线性子空间字典学习方法
2.1. 重构误差项
传统的单层字典学习方法求解获得的字典和稀疏表示是浅层的,对于数据维度过高或样本数量过多的情况,这样的稀疏表示不利于识别和分类任务. 本研究结合分层字典学习[22]和非线性投影技术提出的HNSDL方法,考虑M层字典学习,将每层视为单层的字典学习模型. 原始样本X输入模型第1层,使用非线性函数
式中:
在第1层模型上,求解字典矩阵
2.2. 局部信息保持项
式中:函数
第m层字典学习的稀疏编码的局部信息保持项表示为
式中:
类内紧致性也是分类问题中须考虑的重要因素,来自同一类别的同类样本的投影编码应该具有相似的结构. 本研究构造类内紧致图V作为投影编码的约束,以帮助投影空间提高其类内相似性. 类内紧致图V的元素
式中:
第m层字典学习的投影编码的局部信息保持项表示为
式中:
2.3. HNSDL目标式和求解
根据以上分析,基于分层字典模型,将重构误差项、稀疏编码的局部信息保持项和投影编码的局部信息保持项结合在目标式中,得到HNSDL模型的第m层上的目标函数:
式中:
HNSDL目标式联合子空间学习和字典学习功能. 稀疏编码、投影编码的局部信息保持项不仅继承了样本的结构信息,还强调了模型的鲁棒性. 为了求解HNSDL目标式的参数
图 1
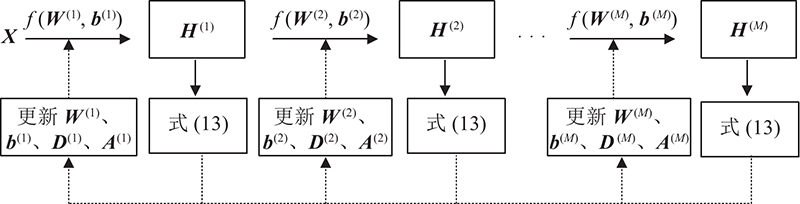
固定
对
式中:
固定
式(18)按列向量求解,得到
式中:
式中:
固定
式(23)采用二次规划方法求解:
式中:
2.4. 测试
对于给定的测试样本
式中:
令稀疏编码向量
算法:HNSDL算法 输入:带类别标签的图像集X; 输出:字典矩阵 //训练阶段 1. 使用KSVD[25]算法初始化 开始循环 for m = 1 to M do 2. 分别使用式(7)、(10)构建最近邻图 3. 固定 4. 固定 5. 固定 6. 固定 循环结束直到目标式(13)收敛或者达到最大迭代次数; 7. 返回 //测试阶段 for m = 1 to M do 8. 使用式(26)计算测试样本的稀疏编码向量 9. 使用KNN分类器对
3. 实 验
3.1. 数据集和实验设置
实验在3个公开的真实遥感图像数据集上进行验证. 1)Ucmerced[26]数据集由21个类的航空场景图像组成,每个类包含100幅RGB颜色的图像,每个图像的大小是256×256像素. 2)Google[27]数据集是空中场景数据集,包含12个航空场景类:农业、商业、港口、闲置土地、工业、草地、天桥、公园、池塘、住宅、河流和水,每类都包含200幅200×200像素的图像. 3)WHU-RS[28]数据集包含19类场景图像,每类包含50幅600×600像素的场景图像. 3个数据集的示例图像如图2所示. 实验使用CaffeNet[29]获得高维的遥感图像特征. CaffeNet使用5个卷积层提取场景的局部特征,3个完全连接的层作为网络的末层提取全局特征,得到2048维的图像特征.
图 2

实验对比算法包括2类. 1)传统的机器学习方法:NPE[30]、K-SVD[25]、DTT-HD[31]算法;2)深度学习方法:AlexNet[32]、TSDFF[33]、UDFF[34]和VGG-VD-16[35]. 为了体现分层非线性投影对遥感场景图像分类的影响,实验将HNSDL中的层次设为1,并使用PCA算法将图像的维数降至300,命名这种方法为单层HNSDL(HNSDL-1L). 各算法的参数设置遵循相应文献的设置. K-SVD算法使用KNN分类器,字典的大小与训练集图像的数量相同. DTT-HD算法使用离散Tchebichef变换和离散Ridgelet变换训练得到混合字典,分类器使用线性支持向量机,字典矩阵中每个字典子类的大小为10. AlexNet网络由5个卷积层和3个完全连接层组成. TSDFF算法使用多种方法提取并融合特征,分类器使用极限学习机. UDFE算法使用贪婪的分层无监督预训练结合高效的稀疏特征无监督学习算法,分类器使用线性支持向量机,惩罚因子的搜索范围为
3.2. 性能比较
比较HNSDL方法与对比算法在3个数据集上的场景分类,平均分类准确率Acc如表1所示,粗体表示分类效果最佳. 可以看出,1)深度模型的准确率高于传统的机器学习算法. 这说明深层结构的模型能够更多地挖掘数据样本的内在结构信息,也说明深度模型较传统的机器学习算法更适用于遥感图像场景分类问题. 2)HNSDL方法的准确率优于其他遥感场景分类方法,与次佳模型相比,3个数据集上的平均准确率分别提高1.65%、1.33%和0.23%. 与HNSDL-1L相比,HNSDL方法在3个数据集上的准确率都有明显提高,总体准确率分别提高5.92%、4.47%和3.80%. HNSDL方法的良好性能主要得益于分层模型和字典学习的融合,非线性投影将高维原始数据降到合适的分类维度,HNSDL方法能很好地获取遥感图像的可辨别结构信息. 使用带标签信息的局部结构约束项也可以有效提高模型的分类能力. 投影空间和字典学习的迭代更新机制保证了模型的所有参数同时达到最优. 3)HNSDL方法使用的遥感图像特征通过CaffeNet模型获取,对比拥有16层结构的VGG-Net-16算法,只有8层的CaffeNet模型结构更简单. 由此可以得出:深度模型的网络层次虽然有助于提升模型性能,但不是层次越多越好,遥感图像使用8层的网络模型就可以取得较好的分类效果.
表 1 3个数据集上平均分类准确率比较
Tab.1
| 数据集 | Acc | ||||||||
| NPE | K-SVD | DTT-HD | HNSDL-1L | AlexNet | UDFF | TSDFF | VGG-VD-16 | HNSDL | |
| Ucmerced | 87.83 | 89.02 | 90.55 | 90.04 | 92.38 | 91.93 | 93.00 | 94.31 | 95.96 |
| 86.30 | 87.46 | 88.04 | 87.87 | 89.53 | 89.12 | 90.73 | 91.01 | 92.34 | |
| WHU-RS | 88.71 | 90.03 | 92.22 | 92.43 | 94.40 | 93.87 | 95.02 | 96.00 | 96.23 |
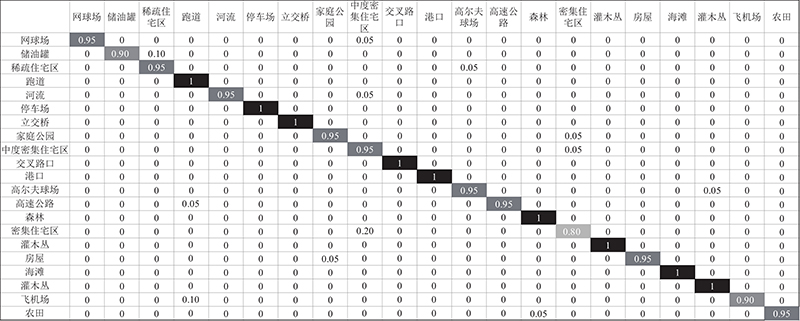
3个公开数据集上的遥感场景分类的混淆矩阵如图3~5所示. 图中,数值表示分类结果中子类的图像数量在训练集上的百分比. 可以看出,1)HNSDL方法在3个数据集的部分子类的分类准确率达到100%. HNSDL方法不但能够充分利用分层模型和非线性投影函数的优点,而且能够在低维空间内充分利用样本的结构化信息,说明HNSDL方法适用于遥感图像场景分类. 2)HNSDL方法在相似场景分类上的应用效果较好. 如Ucmerced数据集的住宅类和商业类、工业类和住宅类等;Google数据集的天桥类和闲置土地类、池塘类和河流类、农业类和牧场类等;WHU-RS数据集的密集住宅区类和中等密集住宅区类、稀疏住宅区类和储油罐类等. 结果表明,HNSDL方法使用的稀疏编码和投影编码的局部信息保持项来提高分类性能.
图 3

图 3 HNSDL方法在Ucmerced数据集上的混淆矩阵
Fig.3 Confusion matrix of HNSDL on Ucmerced dataset
图 4

图 5
3.3. 参数分析
HNSDL方法涉及的主要参数有模型层数M,投影空间维数d,子类字典的原子数Kc,正则化参数
表 2 不同正则化参数在Ucmerced数据集上的准确率
Tab.2
| 取值范围 | Acc1 | Acc2 | Acc3 |
| % | |||
| 10−4 | 92.32 | 93.22 | 94.72 |
| 10−3 | 94.96 | 93.66 | 95.06 |
| 10−2 | 95.63 | 95.06 | 95.96 |
| 10−1 | 95.96 | 95.80 | 95.56 |
| 1 | 95.85 | 95.96 | 95.26 |
图 6
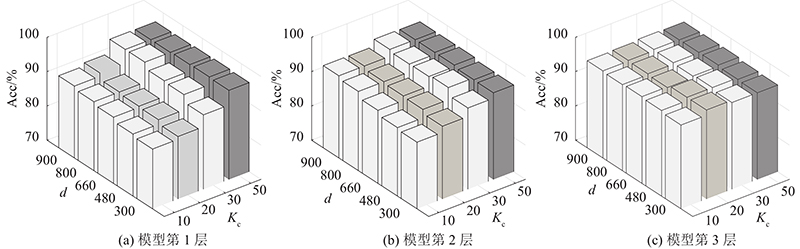
图 6 不同投影空间维数和子类字典原子数在Ucmerced数据集上的准确率
Fig.6 Accuracy performance of projection space dimension and sub-dictionary atoms on Ucmerced dataset
4. 结 语
本研究在字典学习的理论框架下,根据遥感场景图像的稀疏特性,提出用于遥感图像场景分类的分层非线性迁移子空间字典学习方法. 该方法通过学习非线性函数,将样本的结构信息和识别信息映射到投影空间,充分利用稀疏、投影编码的局部信息保持,获得类内紧致的遥感图像场景稀疏表示,得到更具分辨能力的字典模型. 通过在Ucmerced、Google和WHU-RS数据集上的实验,探讨在网络层数、投影空间、字典规模等参数设置下该方法的性能. 得到在较小网络规模和较少训练字典原子数时,所提方法能够取得分辨力强的分类器的结论. 所提方法适用于清晰无遮挡的遥感图像场景分类. 如何利用字典学习的噪声不敏感性处理带噪声环境下的遥感图像场景分类,设计更加健壮的分类器是下一步的工作计划. 此外,如何将所提方法与卷积神经网络相结合,设计集特征提取和分类识别于一体的字典学习模型将是下一阶段的研究方向.
参考文献
Remote sensing image scene classification meets deep learning: challenges, methods, benchmarks, and opportunities
[J].DOI:10.1109/JSTARS.2020.3005403 [本文引用: 1]
Two-stream feature aggregation deep neural network for scene classification of remote sensing images
[J].
Remote sensing image scene classification using CNN-MLP with data augmentation
[J].DOI:10.1016/j.ijleo.2020.165356
基于图像混合特征的城市绿地遥感图像配准
[J].
Urban green space remote sensing image registration using image mixed features
[J].
基于深度学习的遥感影像变化检测方法
[J].
Remote sensing image change detection method based on deep neural networks
[J].
Improved support vector machine enabled radial basis function and linear variants for remote sensing image classification
[J].
Multisensor and multiresolution remote sensing image classification through a causal hierarchical Markov framework and decision tree ensembles
[J].DOI:10.3390/rs13050849 [本文引用: 1]
A tidal flat wetlands delineation and classification method for high-resolution imagery
[J].DOI:10.3390/ijgi10070451 [本文引用: 1]
An efficient and lightweight convolutional neural network for remote sensing image scene classification
[J].DOI:10.3390/s20071999 [本文引用: 1]
Object-guided remote sensing image scene classification based on joint use of deep-learning classifier and detector
[J].DOI:10.1109/JSTARS.2020.2996760 [本文引用: 1]
基于多尺度学习与深度卷积神经网络的遥感图像土地利用分类
[J].
Land use classification of remote sensing images based on multi-scale learning and deep convolution neural network
[J].
Auto-encoder-based shared mid-level visual dictionary learning for scene classification using very high resolution remote sensing images
[J].DOI:10.1049/iet-cvi.2014.0270 [本文引用: 1]
Contrast-weighted dictionary learning based saliency detection for remote sensing images
[J].DOI:10.1016/j.patcog.2020.107757 [本文引用: 1]
Cloud removal based on sparse representation via multitemporal dictionary learning
[J].DOI:10.1109/TGRS.2015.2509860 [本文引用: 1]
Coupled dictionary learning for unsupervised change detection between multimodal remote sensing images
[J].DOI:10.1016/j.cviu.2019.102817 [本文引用: 1]
Particle swarm optimization based dictionary learning for remote sensing big data
[J].DOI:10.1016/j.knosys.2014.10.004 [本文引用: 1]
Hyperspectral image sparse reconstruction model based on collaborative multidimensional correlation
[J].DOI:10.1016/j.asoc.2021.107250 [本文引用: 1]
Finding GEMS: multi-scale dictionaries for high-dimensional graph signals
[J].DOI:10.1109/TSP.2019.2899822 [本文引用: 1]
Unsupervised joint feature learning and encoding for RGB-D scene labeling
[J].DOI:10.1109/TIP.2015.2465133 [本文引用: 1]
Atom-substituted tensor dictionary learning enhanced convolutional neural network for hyperspectral image classification
[J].DOI:10.1016/j.neucom.2021.05.051 [本文引用: 1]
Uncertainty principles and ideal atomic decomposition
[J].DOI:10.1109/18.959265 [本文引用: 1]
Discriminative robust deep dictionary learning for hyperspectral image classification
[J].DOI:10.1109/TGRS.2017.2704590 [本文引用: 1]
A locality-constrained and label embedding dictionary learning algorithm for image classification
[J].DOI:10.1109/TNNLS.2015.2508025 [本文引用: 1]
Joint local constraint and fisher discrimination based dictionary learning for image classification
[J].DOI:10.1016/j.neucom.2019.05.103 [本文引用: 1]
K-SVD: an algorithm for designing overcomplete dictionaries for sparse representation
[J].DOI:10.1109/TSP.2006.881199 [本文引用: 2]
Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery
[J].DOI:10.1109/LGRS.2015.2513443 [本文引用: 1]
A two-stream deep fusion framework for high-resolution aerial scene classification
[J].
Unsupervised deep feature extraction for remote sensing image classification
[J].DOI:10.1109/TGRS.2015.2478379 [本文引用: 1]
Remote sensing image scene classification: benchmark and state of the art
[J].DOI:10.1109/JPROC.2017.2675998 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}