

随着信息技术的快速发展,数据量以爆炸性的速度持续增长,传统的数据库系统软件难以在交互式响应时间内回答用户的聚集查询. 而在具体的决策分析任务中,用户通常只须从数据中获取大致的趋势,不要求精确的结果. 并且,在实际情况中,数据分布并不均匀,存在严重的偏斜问题. 因此,如何在海量的偏斜数据中以更快的响应速度获取精度较高的查询结果具有重要的研究意义.
近似查询处理(approximate query processing, AQP)算法[1]以牺牲一定的精度为代价来换取更快的查询响应速度,保证用户的交互性需求,成为近年来数据库查询领域的一大研究热点. 目前,近似查询处理方法大致可以分为3类. 第1类是基于抽样的近似查询处理(sampling-based approximate query processing, SAQP)[2],它以抽样的方法创建一个随机的数据样本,并将该样本作为原始数据的摘要,估计查询结果. SAQP方法原理简单,适用于大多数通用查询,但该方法生成的样本往往不能代表总体数据集,影响估计结果的准确性[3]. 基于分层抽样的SAQP算法可以克服数据偏斜问题,但分层抽样依赖于对数据分布的先验知识,只适用于特定数据的查询,不具有一般性[4]. 第2类是聚集预计算(aggregate precomputation, AggPre)[5],该方法预先计算一些聚集查询的结果,之后使用该结果快速地回答用户查询. 但AggPre方法的查询效率取决于预聚集值的计算,有限数量的预聚集值很难提供足够准确的查询结果,而预先计算较多的聚集值又将花费大量的存储空间. 第3类是采用机器学习中的方法来实现近似查询处理,诸如变分自编码器(variational auto-encoder, VAE)、生成对抗网络(generative adversarial network, GAN). 此类算法可以学习到原始数据的分布特征,从而达到生成高质量样本的效果,提高查询准确率[6]. 其中,VAE是一种常见的生成模型[7],通过学习原始数据的低维潜在特征,对各种复杂的数据分布进行建模并生成具有较高辨别性和鲁棒性的关键分布特征. 但VAE误差衡量不够精确,难以使生成的数据符合期望分布,影响查询准确率. GAN是另一种有效的生成模型[8],通过使内部的生成网络与鉴别网络相互对抗,从而降低模型误差,生成符合原始数据分布的样本. 但是,GAN在训练过程中很难保证内部网络均衡,容易出现模型坍塌.
针对以上问题,本研究设计了新型的生成模型,该模型将条件变分自编码器的编码网络融入到条件生成对抗网络中,可以高效地近似原始数据的分布,克服数据偏斜;使用Wasserstein距离衡量模型误差,防止模型坍塌. 基于该模型实现近似查询处理,可以根据用户需求生成高质量的样本,而无须访问底层数据,避免磁盘交互. 将该算法与聚集预计算相融合构成交互式分析查询的通用框架,并通过设计的表决算法最小化查询误差,从而更好地处理交互式查询.
1. 相关工作
基于抽样的近似查询处理是目前应用最为广泛的近似查询算法之一. Cormode等[9]提出使用均匀随机抽样方法构建数据摘要,近似地回答用户查询. 该方法思路简单,响应时间短,但不能解决数据偏斜问题. Chaudhuri等[10]提出使用优化的分层抽样方法实现近似查询,可以保证较高的查询准确率,但该方法依赖于数据分布的先验知识,不具有查询一般性. Nguyen等[11]设计了新的分层抽样算法CVOPT,它根据变异系数为每个分组分配样本量,实现查询精度与样本大小的均衡. Ding等[12]提出新型度量方法“Sample+Seek”来衡量样本的准确性,并基于此实现了一种基于度量的抽样方法,提高了近似查询的准确率.
近年来,采用机器学习方法实现近似查询已经成为数据库领域的一大研究热点. Ma等[15]设计了一种基于机器学习的近似查询方法,它根据数据样本建立概率密度模型和回归模型,并使用该模型直接回答用户查询,避免磁盘交互,缩短查询响应时间. Thirumuruganathan等[16]提出使用变分自编码器模型对原始数据分布进行建模,生成高效、交互式的总体估计,克服数据偏斜. Zhang等[17]提出使用基于Wasserstein的条件生成对抗网络(conditional wasserstein generative adversarial network, CWGAN)来解决原始数据的偏斜问题,并与抽样方法相结合,高效地回答分组近似查询.
2. 基于Wasserstein的条件变分生成对抗网络
2.1. 模型简介
经典的深度生成模型主要包括条件变分自编码器(conditional variational auto-encoder, CVAE)与条件生成对抗网络(conditional generative adversarial network, CGAN). 其中,CVAE模型训练稳定,能学习到真实数据的关键特征,但误差较大. CGAN在训练时,容易产生极大的梯度波动,从而造成模型训练不稳定. 此外,CGAN往往生成与真实数据相差过大的样本,且生成的数据容易缺乏多样性,出现模型坍塌.
针对上述问题,本研究设计了新型的条件生成模型,基于Wasserstein的条件变分生成对抗网络(conditional variational Wasserstein generative adversarial network,CVWGAN). 该模型将经典的CVAE与CGAN相融合,能够更加精确地学习原始数据的分布,保证模型训练的稳定性,同时,使用Wasserstein距离衡量模型误差,从而避免模型坍塌.
2.2. 模型构建
2.2.1. 模型总体结构
本模型以CWGAN的网络结构为基础,融入CVAE中的编码网络,保证总体模型的稳定. 具体模型结构如图1所示.本模型由编码网络(encoder, E)、生成网络(generator, G)以及鉴别网络(discriminator, D)组成. 模型的具体信息如表1所示. 其中,编码网络将真实数据的未知分布映射为潜层空间(latent space, LS)中的常见分布,共有3层,以真实数据X以及对应的条件特征Y作为输入,映射得到各类数据在LS中分布的情况. 之后,模型根据该分布信息构建LS,并从中随机抽取大小为
图 1
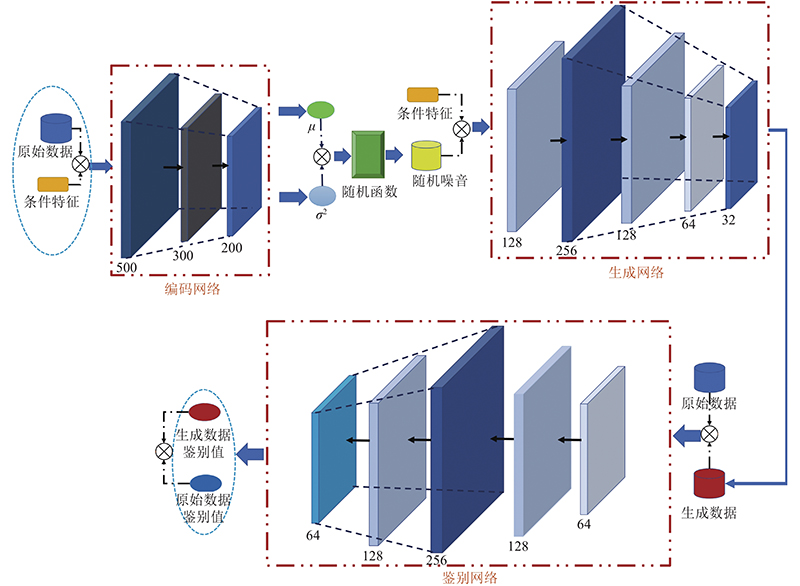
图 1 基于Wasserstein的条件变分生成对抗网络模型结构图
Fig.1 Structure diagram of conditional variational Wasserstein generative adversarial network model
表 1 基于Wasserstein的条件变分生成对抗网络模型信息表
Tab.1
| 网络模块 | 层数 | 输入 | 输出 | 神经元个数 | keep_prob | 激活函数 |
| E | 3 | X, Y | μ, δ2 | 500 | 0.9 | Relu |
| 300 | 0.8 | Relu | ||||
| 200 | 0.9 | Tanh | ||||
| G | 5 | Z, Y | XF | 128 | 0.9 | Relu |
| 256 | 0.8 | Relu | ||||
| 128 | 0.9 | Relu | ||||
| 64 | 0.9 | Relu | ||||
| 32 | 1.0 | Sigmoid | ||||
| D | 5 | X, XF | D(X), D(XF) | 64 | 1.0 | Relu |
| 128 | 0.9 | Relu | ||||
| 256 | 0.8 | Relu | ||||
| 128 | 0.9 | Relu | ||||
| 64 | 1.0 | Relu |
2.2.2. 模型重要参数设置
1)batch_size. 由实验测试可知,当batch_size=640时,收敛步数最少,收敛速度最快. 因此,本研究将模型的batch_size参数设置为640.
2)损失函数. 本模型的误差分为4部分:KL散度误差
本模型的潜层空间中数据的期望分布为高斯分布,因此,将编码网络生成的均值
式中:k为潜层空间中条件类别的总个数.
式中:P(X)、P(XF)分别为真实数据、生成的虚假数据的分布。
本模型将网络G、D相结合,使用Wasserstein距离作为两者的损失函数. Wasserstein距离(又称Earth-Mover距离)是衡量数据分布之间相似程度的有效方法[19],具体定义如下:
式中:
式中:
本研究以D网络拟合
3)优化器. 相较于其他优化算法,RMSPropOptimizer能够更好地保证鉴别网络在训练过程中误差梯度的稳定,且能够修改传统的梯度积累为指数加权的移动平均,从而能自适应地调节学习率的变化. 因此,本研究使用RMSPropOptimizer作为模型优化器,同时,综合考虑模型的收敛情况以及训练过程中误差大小的因素,将模型的学习率设置为0.001.
2.2.3. 模型训练算法
本研究所设计的条件生成模型的训练过程分为2个阶段:数据预处理与迭代训练. 具体流程如算法1所示.
算法 1 训练算法
Input: Original Data OD, Learning Rate
Output: Model after Training TModel
1. X, Y←MiniType(k, OD)
2. Initialize the Model{E, G, D}
3. While True do
4.
5. Z←Random(
6. XF←G(Z, Y)
7. dFake, dX←D(XF, X)
8. klloss←LKL(
9. reloss←LRE(XF, X)
10. gloss←LG(dFake)
11. dloss←LD(dFake, dX)
12. If klloss, reloss, gloss, dloss <
13. Break
14. End If
15. E←RMSPropOptimizer(E, klloss, reloss,
16. G←RMSPropOptimizer(G, reloss, gloss,
17. D←RMSPropOptimizer(D, dloss,
18. End While
19. TModel←{E, G, D}
20. Return TModel
本研究在数据预处理阶段对原始数据按照取值范围进行聚类,可以降低类内数据的偏斜程度,提升模型的学习效率. 本模型处理的原始数据具有规模庞大、分布偏斜的特点,因此,使用设计的MiniType算法,对原始数据进行聚类预处理,获得聚类后的真实数据X以及各类的条件特征Y.
在迭代训练阶段,将真实数据与对应的条件特征信息相融合作为模型的输入,使用编码网络得到潜层空间中数据分布的均值
在算法1的执行阶段,每次使用原始数据对模型进行训练都可能会涉及以下操作:1)使用MiniType算法对原始数据聚类处理;2)各网络模型生成样本数据;3)使用RMSPropOptimizer方法优化各网络模型的参数.
根据上述流程,可以得到,在训练算法执行阶段,操作1)需要
式中:H为各网络所具有的网络层数,即网络深度;
各网络模型的空间复杂度主要包括2部分:总参数量与各层输出特征图. 本算法所处理的训练数据为一维数据,且各层网络的尺寸结构均修改为适用于一维信号的形式,因此各网络模型的空间复杂度近似为
式中:
3. 基于条件生成模型的近似查询处理算法
3.1. 近似查询处理
1) 形式化定义. 给定一个具有
2) 近似查询准确度的衡量标准. 对于任意一个聚集查询
对于任意的一组查询
式中:m为查询总个数,
3.2. 表决算法
本研究设计的表决算法包含样本过滤器(sample filter, SF)与数据过滤器(data filter, DF),每种过滤器均采用集成学习的思想,且综合考虑近似查询算法的准确性与实用性,各过滤器均选用3种分类算法,更全面地对模型生成的数据进行过滤.
SF选用支持向量机、人工神经网络以及决策树等精度较高的分类算法构成分类器,以CVWGAN模型在训练过程中所产生的大量标注样本为训练数据,对模型生成的单一样本分类预测,具体流程如算法2所示.
算法 2 样本过滤算法
Input: Sample Filter Model SFModel, Threshold T, Sample S
Output: Quality of Samples Flag
1. predict←SFModel(S)
2. num
3. If num ≥T Then
4. Flag=True
5. Else
6. Flag=False
7. End If
8. Return Flag
在执行查询时,SF使用训练完成的分类算法对模型生成的数据样本分类预测并得到相应的结果. 若预测为真的算法个数不小于接受阈值T,则接受该样本,并使用DF对样本内部数据进行过滤,否则拒绝当前样本.
分析算法2可知,该算法的执行成本主要取决于样本过滤模型SFModel对样本的分类预测,且该模型包含支持向量机、人工神经网络以及决策树等算法,执行二分类操作. 针对支持向量机,该算法在预测阶段的时间成本为
DF与SF不同,其选用朴素贝叶斯、决策树以及逻辑回归等算法,以预处理后的真实数据以及对应的条件特征为训练集,对SF过滤后的样本的内部数据进行预测. 若预测结果中存在取值为异常点的情况,则删除该数据. 之后,DF获取预测结果中取值相同的结果个数Ns,并根据接受阈值T进行判断,若Ns小于T,则将该数据删除,执行阈值过滤. 当DF删除的数据过多时,算法对阈值过滤阶段所删除的数据重新预测并计算Ns,选择取值较高的数据加入原样本. 具体算法流程如算法3所示.
算法 3 数据过滤算法
Input. Sample
Output. Filtered Sample FS
1. length←|S|
2. Initialize the DT to be empty sets
3. For i
4. predict
5. No
6. If No > 0 Then
7. Remove(S, si)
8. continue
9. End If
10. Ns
11. If Ns < T Then
12. DT.Add(si)
13. Remove(S, si)
14. End If
15. End For
16. If |S|/ length< 0.95and | DT | >0 Then
17. T = T−1
18. For j
19. predict
20. Na
21. If Na
22. S.Add(dtj)
23. Remove(DT, dtj)
24. End If
25. End For
26. End If
27. FS
28. Return FS
综合分析算法3可知,该算法所执行的数据过滤操作主要包含数值过滤与二次过滤2个阶段,且算法内部的数值过滤模型DFModel的时间与空间复杂度均为
3.3. CVWGAQP++算法框架
将基于CVWGAN模型实现的近似查询处理算法与聚集预计算相融合,形成交互式查询的通用框架CVWGAQP++. 与基于模型的近似查询算法不同,CVWGAQP++使用生成的样本估计用户查询与聚集预计算之间的差异. 使用模型训练过程中预处理阶段所划分的各个类别作为预聚集值的计算范围,具体思想如算法4所示.
算法 4 CVWGAQP++
Input. Sample Filter SF,User Query Q, Aggregate Precomputation AP, Generation Model Model, Data Filter DF
Output. Final Result Result
1. Qn, Vt
2. While True do
3. originalS
4. If SF(originalS) = False Then
5. continue
6. End If
7. finalS
8. Break
9. End While
10. Ve
11. Result
12. Return Result
本算法使用
在上述算法的执行过程中,查询处理阶段的时间和空间复杂度分别为
4. 实验与分析
4.1. 实验设置
4.1.1. 实验环境设置
实验硬件环境为NVIDIA Tesla K80 GPU;8 GB内存;500 GB硬盘;操作系统为Windows 10. 采用Pycharm 2020.2编程环境与Python编程语言开发模拟测试程序,使用TensorFlow及Python学习框架构建本研究的生成模型.
4.1.2. 实验数据集
选用2个数据集进行实验,分别为真实数据集TLCTrip与合成数据集.
TLCTrip数据集:TLCTrip 为纽约市出租车和豪华轿车委员会(NYC Taxi and Limousine Commission)的真实数据集. 使用2010年—2020年黄车数据表中的”trip_distance”属性数据,截取其中的部分元组1500万个.
合成数据集:使用TPC-DS基准生成合成数据集. 固定生成数据的规模,将偏斜因子从0变化到2.0,每次增加0.5,获得5个含有100万行元组,偏斜程度不同的数据集.
4.1.3. 实验工作负载与评估指标
对实验数据集执行求平均的聚集查询,对每个查询重复执行1000次并对结果求平均. 平均查询响应时间表达式为
式中:Ne为所执行查询的次数,
为了评估本研究算法的效率,实验使用式(11)中所述的平均相对误差以及式(12)所述的平均查询响应时间作为评估指标.
4.2. 对比算法
为了更好地体现本研究提出的CVWGAQP++算法的准确性与高效性,选择以下对比算法.
1) 基于随机抽样的SAQP算法、AggPre算法以及基于随机抽样的SAQP++算法. 基于随机抽样的SAQP与AggPre是近似查询领域中应用十分广泛的近似算法,具有原理简单、通用性强的优势;基于随机抽样的SAQP++算法将基于随机抽样的SAQP与AggPre相结合,具有比SAQP以及AggPre更高的性能. 因此,本研究选用SAQP、AggPre以及SAQP++算法作为实验的对比算法,并均参照文献[20],在本实验平台进行实现.
2) 基于VAE的近似查询处理算法. VAE是基于模型的近似查询处理方向中较经典的生成模型算法,且该算法的模型结构与本研究算法相似,因此,选用VAE模型所实现的近似查询处理算法作为对比算法,并参照文献[16]中提出的基于多VAE模型的近似查询算法,在本实验平台进行实现.
3) 消融算法. 以CWGAN的网络结构为基础,融入CVAE中的编码网络,并先后与本研究设计的表决算法以及经典的AggPre相结合,进而形成本研究所提出的CVWGAQP++算法框架. 因此,为了更好地验证CVWGAQP++算法的高效性,针对该算法先后进行关于AggPre、表决算法以及CVAE模型算法的消融处理,并依次获得融合AggPre算法与CVAE且不含表决算法的CVWGAQP++(N)、融合CVAE且含有表决算法的CVWGAN(Y)、融合CVAE且不含表决算法的CVWGAN(N)以及CWGAN算法,并将上述算法作为对比算法,在本实验平台进行实现.
4.3. 结果分析
4.3.1. 克服数据偏斜的效果分析
为了测试本研究算法CVWGAQP++在偏斜数据中的查询效果,在偏斜因子(skew)不同的合成数据集中进行实验,并与其他对比算法进行对比,具体结果如图2所示. 图中,s为偏斜因子.
图 2
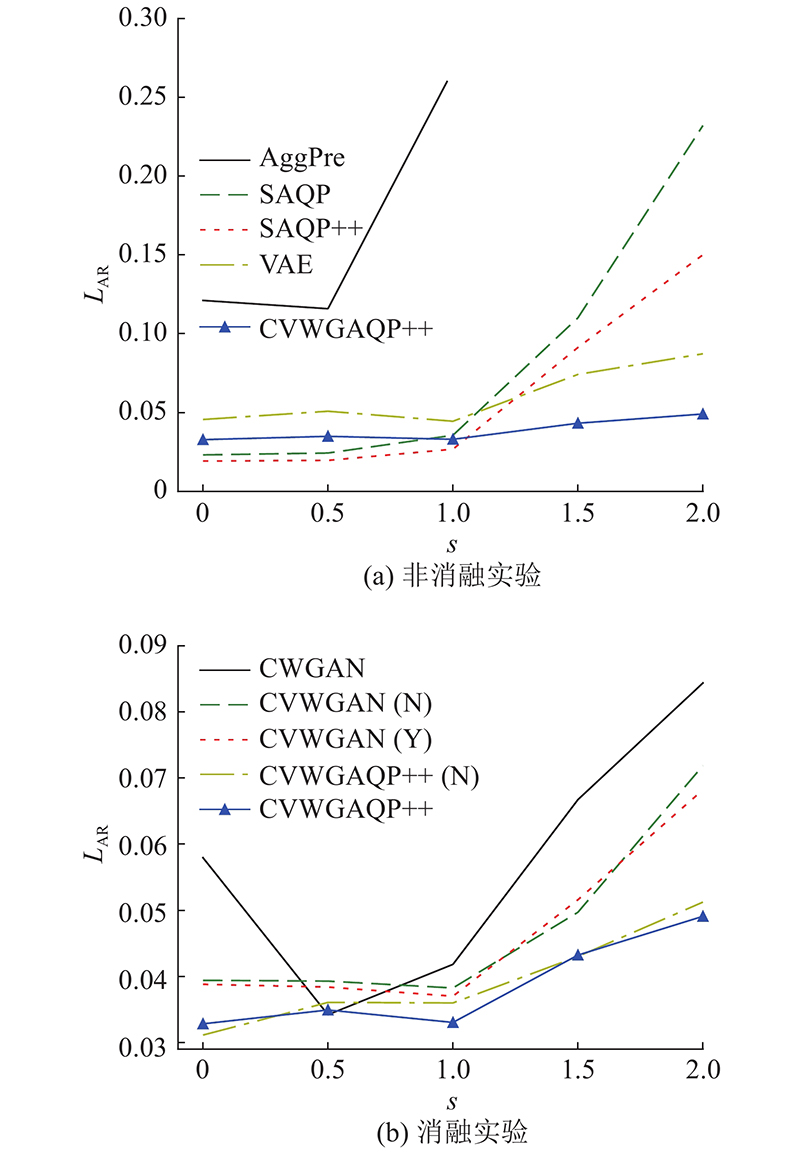
由图2(a)可以看出,当偏斜因子为0,数据均匀分布时,CVWGAQP++与各对比算法都有着较高的准确率,
4.3.2. 查询选择度变化的查询效果分析
在含有100万个元组的真实数据集下,通过变化查询选择度(selectivity),将CVWGAQP++与本实验中的其他对比算法进行对比测试,实验结果如图3所示. 图中,se为选择度. 可以看出,随着查询选择度的变化,本研究所提出的CVWGAQP++的平均相对误差增长缓慢,且远低于其他对比算法,因此,该算法能够更加准确地回答用户查询. 随着查询选择度的增加,CVWGAQP++与CVWGAQP++(N)算法的执行效果明显优于CVWGAN(Y)、CVWGAN(N)及CWGAN算法,且CVWGAN(Y)的平均相对误差也整体低于CVWGAN(N)的. 因此,CVWGAQP++算法所融合的CVAE、AggPre以及表决算法对提高算法的准确性具有重要的意义.
图 3
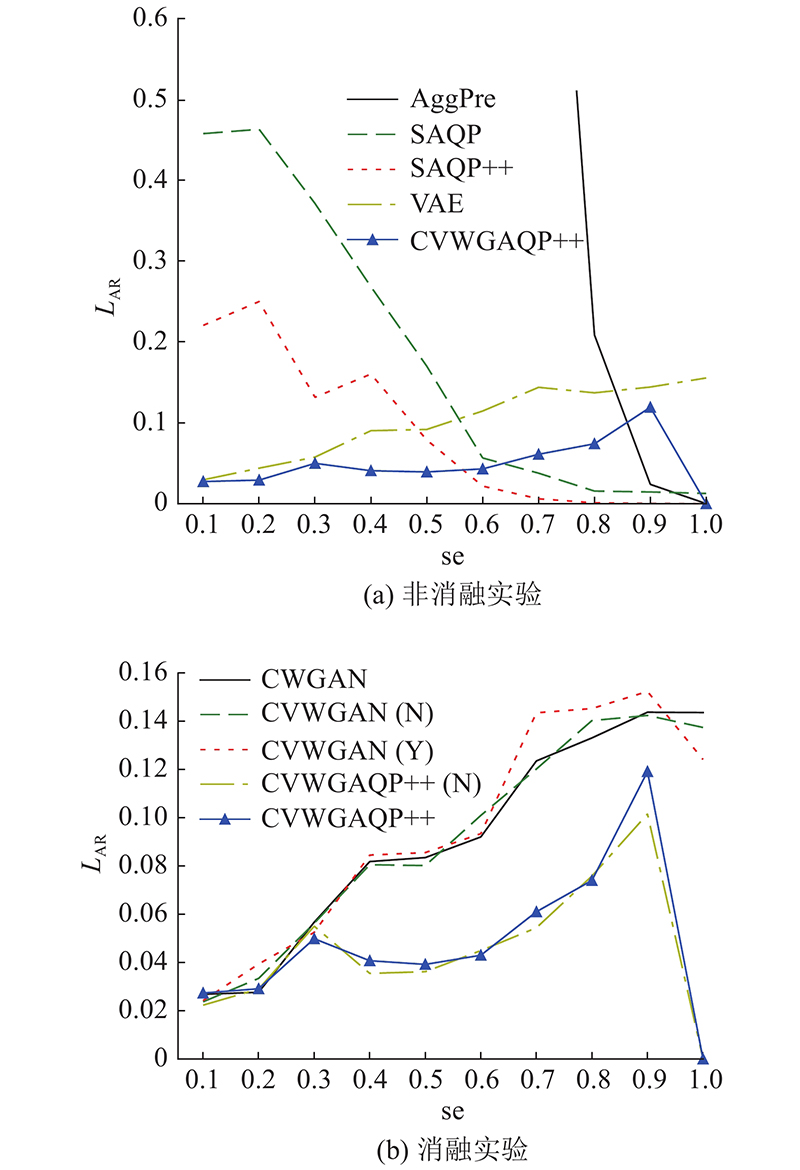
图 3 不同查询选择度下平均相对误差对比图
Fig.3 Comparison of average relative error under different selectivities
4.3.3. 原始数据规模变化的查询效果分析
在不同规模的真实数据集下,将CVWGAQP++与本实验中的其他对比算法进行对比测试,实验结果如图4所示. 可以看出,当原始数据规模大于500万时,生成模型算法的查询精度明显优于经典的近似算法SAQP以及AggPre,且随着原始数据规模的增加,两类算法之间的差异也在逐步地增大. 由图4(b)可以看出,与其他参与对比的消融算法相比,CVWGAQP++由于融合了CVAE模型的编码网络、表决算法以及AggPre等算法,查询准确率显著提高,平均相对误差整体上远低于其他各消融算法. 而且,分析图中的实验结果可知,随着原始数据规模的变化,CVWGAQP++(N)与CVWGAN(Y)的查询精度明显高于CVWGAN(N)和CWGAN算法. 综上,随着原始数据规模的变化,CVWGAQP++算法能够更加准确地回答用户查询.
图 4
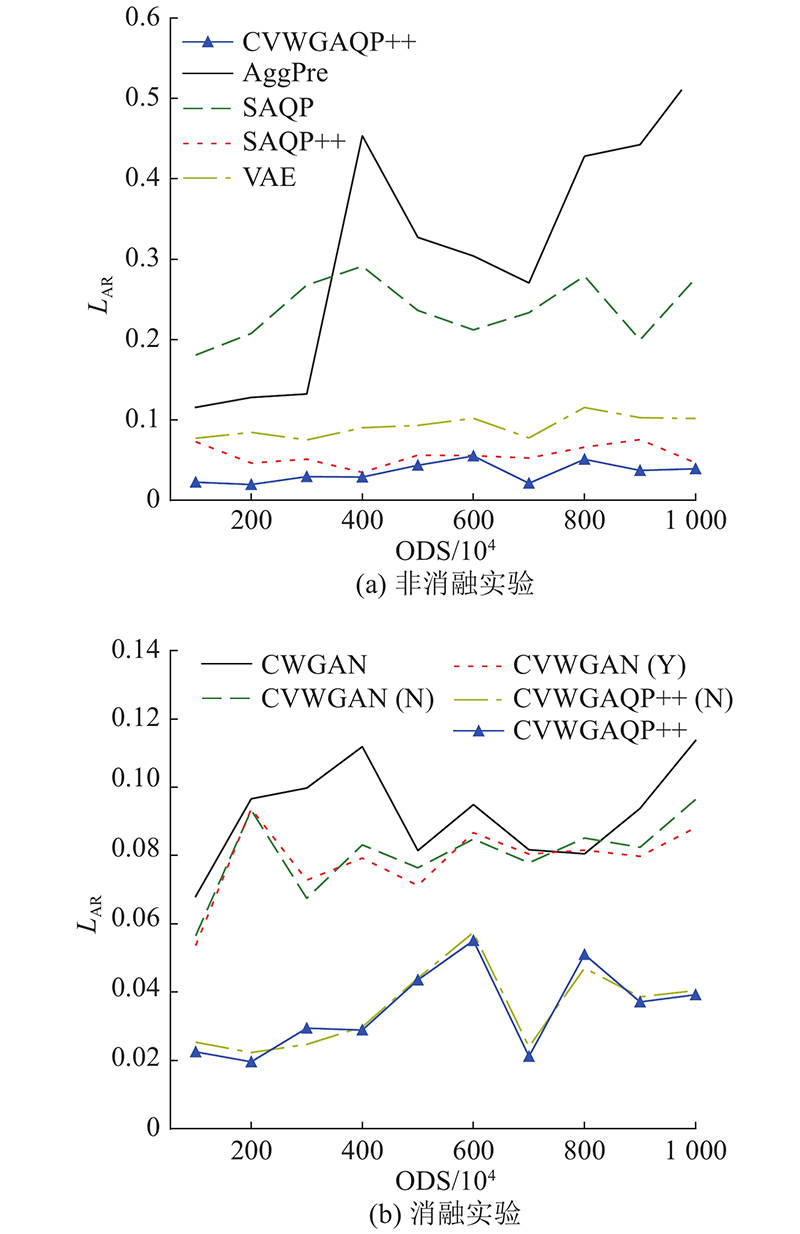
图 4 不同原始数据规模下平均相对误差对比图
Fig.4 Comparison of average relative error under different original data scales
4.3.4. 查询响应时间分析
在真实数据集下,设置查询选择度为0.8,通过变化原始数据的规模,测试CVWGAQP++与其他对比算法对用户查询的平均响应时间tave,实验结果如图5所示.
图 5
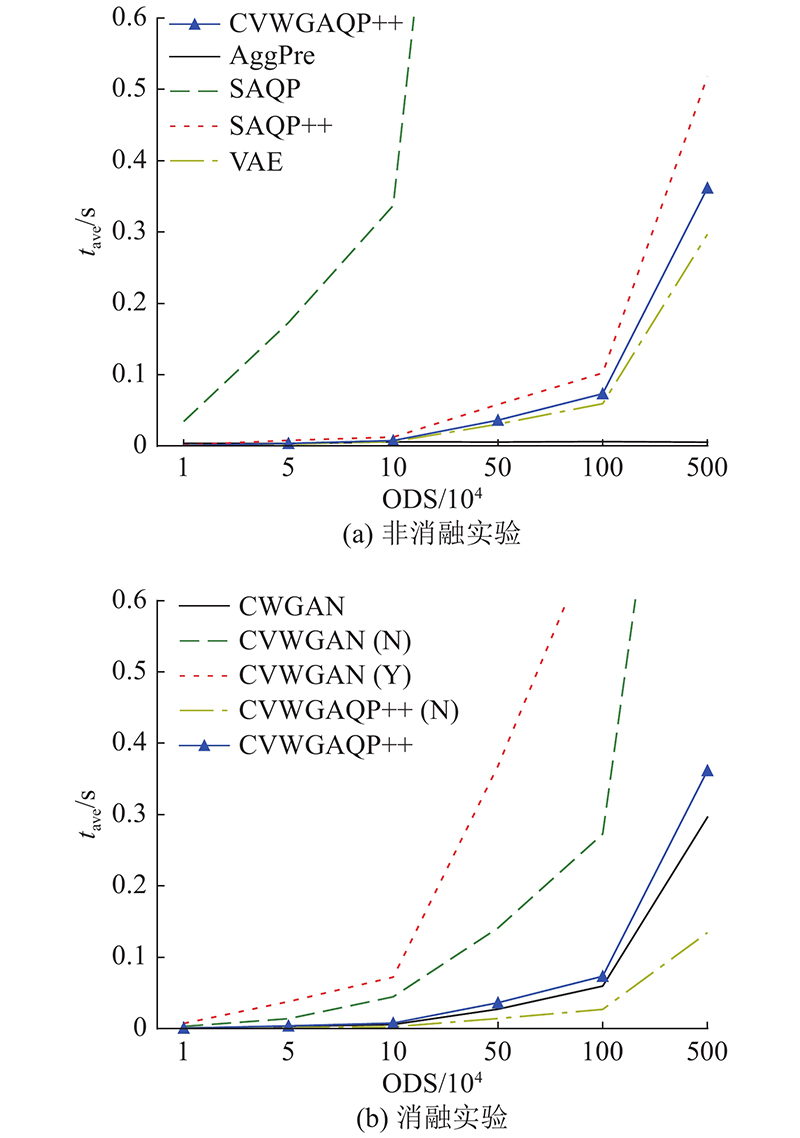
图 5 不同原始数据规模下平均查询响应时间对比图
Fig.5 Comparison of average query response time under different original data scales
由图5(a)可以看出,在预先加载好生成模型的情况下,随着原始数据规模的增加,生成模型算法CVWGAQP++的平均响应时间远小于SAQP++以及SAQP算法,原因在于CVWGAQP++算法在回答用户查询时,只须利用预先加载的生成模型,根据查询需要生成数据样本,而无须访问底层数据,从而能够避免磁盘交互,减少查询时间. CVWGAQP++算法为了保证查询精度引入了表决算法以及CVAE模型中的编码网络,因此,分析图5(b)中的实验数据可以得出,CVWGAQP++、CVWGAN(Y)及CVWGAN(N)算法的查询时间分别高于CVWGAQP++(N)、CVWGAN(N)及CWGAN算法,但总体来看,相互之间的差距并不大. 因此,本研究所提出的CVWGAQP++算法可以很好地满足用户查询的交互性.
5. 结 语
研究基于条件生成模型的近似查询处理算法. 本研究定义了一种高效的深度生成模型,该模型融合经典的模型算法CVAE与CGAN,并引入Wasserstein距离作为误差衡量,消除模型坍塌;将该模型应用于近似查询,并与聚集预计算相结合,提出CVWGAQP++算法框架;设计了高效的表决算法,降低近似查询误差. 实验结果表明,本研究所提出的算法相较于对比算法在性能上有显著的提高.
本研究所提算法在面临高度偏斜数据时,生成的样本质量仍存在一定的不足。在未来研究中将尝试对数据预处理阶段的类别划分策略进行优化,进一步降低类内数据的偏斜程度,提高算法的学习效率。
参考文献
Approximate query processing: what is new and where to go?
[J].DOI:10.1007/s41019-018-0074-4 [本文引用: 1]
Random sampling from databases: a survey
[J].DOI:10.1007/BF00140664 [本文引用: 1]
Stratified and ranked composite sampling
[J].DOI:10.1080/03610918.2018.1487067 [本文引用: 1]
Adding value to linked open data using a multidimensional model approach based on the RDF data cube vocabulary
[J].
Deepdb: learn from data, not from queries!
[J].DOI:10.14778/3384345.3384349 [本文引用: 1]
Deep learning
[J].DOI:10.1038/nature14539 [本文引用: 1]
Generative adversarial networks: an overview
[J].DOI:10.1109/MSP.2017.2765202 [本文引用: 1]
Synopses for massive data: samples, histograms, wavelets, sketches
[J].
Optimized stratified sampling for approximate query processing
[J].
Approximate computation of multidimensional aggregates of sparse data using wavelets
[J].DOI:10.1145/304181.304199 [本文引用: 1]
Pairwise context similarity for image retrieval system using variational auto-encoder
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}