[1]
高文, 汤洋, 朱明 复杂背景下目标检测的级联分类器算法研究
[J]. 物理学报 , 2014 , 63 (9 ): 156 - 164
[本文引用: 1]
GAO Wen, TANG Yang, ZHU Ming Study on the cascade classifier in target detection under complex background
[J]. Acta Physica Sinica , 2014 , 63 (9 ): 156 - 164
[本文引用: 1]
[2]
王浩, 单文静, 方宝富 基于多层上下文卷积神经网络的目标检测算法
[J]. 模式识别与人工智能 , 2020 , 33 (2 ): 113 - 120
[本文引用: 1]
WANG Hao, SHAN Wen-jing, FANG Bao-fu Multi-layers context convolutional neural network for object detection
[J]. Pattern Recognition and Artificial Intelligence , 2020 , 33 (2 ): 113 - 120
[本文引用: 1]
[3]
REN S Q, HE K M, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2015 , 39 (6 ): 1137 - 1149
[本文引用: 3]
[4]
尉婉青, 禹晶, 柏鳗晏, 等 SSD与时空特征融合的视频目标检测
[J]. 中国图象图形学报 , 2021 , 26 (3 ): 542 - 555
DOI:10.11834/jig.200020
[本文引用: 1]
WEI Wan-qing, YU Jing, BAI Man-yan, et al Video object detection using fusion of SSD and spatiotemporal features
[J]. Journal of Image and Graphics , 2021 , 26 (3 ): 542 - 555
DOI:10.11834/jig.200020
[本文引用: 1]
[5]
徐利锋, 黄海帆, 丁维龙, 等 基于改进DenseNet的水果小目标检测
[J]. 浙江大学学报: 工学版 , 2021 , 55 (2 ): 377 - 385
[本文引用: 1]
XU Li-feng, HUANG Hai-fan, DING Wei-long, et al Detection of small fruit target based on improved DenseNet
[J]. Journal of Zhejiang University: Engineering Science , 2021 , 55 (2 ): 377 - 385
[本文引用: 1]
[6]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C] // IEEE Conference on Computer Vision and Pattern Recognition . Washington: IEEE, 2016: 779–788.
[本文引用: 2]
[7]
REDMON J, FARHADI A. YOLO9000: better, faster, stronger [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 6517-6525.
[8]
REDMON J, FARHADI A. YOLOv3: an incremental improvement [EB/OL]. (2018-08-08). https://arxiv.org/pdf/1804.02767.pdf.
[本文引用: 1]
[9]
SHELHAMER E, LONG J, DARRELL T Fully convolutional networks for semantic segmentation
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (4 ): 640 - 651
DOI:10.1109/TPAMI.2016.2572683
[本文引用: 1]
[10]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2999-3007.
[本文引用: 2]
[11]
ZHANG S F, CHI C, YAO Y Q, el al. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 9756-9765.
[本文引用: 2]
[12]
LIN T Y, DOLLAR P, GIRSGICK, et al. Feature pyramid networks for object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 936-944.
[本文引用: 1]
[13]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// European Conference on Computer Vision . Amsterdam: Springer, 2016: 21–37.
[本文引用: 2]
[14]
郑浦, 白宏阳, 李伟, 等 复杂背景下的小目标检测算法
[J]. 浙江大学学报: 工学版 , 2020 , 54 (9 ): 1777 - 1784
[本文引用: 1]
ZHENG Pu, BAI Hong-yang, LI Wei, et al Small target detection algorithm in complex background
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (9 ): 1777 - 1784
[本文引用: 1]
[15]
FU C Y, LIU W, RANGA A, et al. DSSD: deconvolutional single shot detector [EB/OL]. (2017-01-23). https://arxiv.org/pdf/1701.06659.pdf.
[本文引用: 2]
[16]
LI Z X, ZHOU F Q. FSSD: feature fusion single shot multibox detector [EB/OL]. (2017-12-04). https://arxiv.org/pdf/1712.00960.pdf.
[本文引用: 2]
[17]
SHEN Z Q, LIU Z, LI J G, et al. DSOD: learning deeply supervised object detectors from Scratch [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 1937-1945.
[本文引用: 1]
[18]
ZHANG S F, WEN L Y, BIAN X, et al. Single-shot refinement neural network for object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4203-4212.
[本文引用: 2]
[19]
HE Y X, ZHU C C, WANG J R, et al. Bounding box regression with uncertainty for accurate object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 2883-2892.
[本文引用: 1]
[20]
BODLA N, SINGH B, CHELLAPPA R, et al. Soft-NMS: improving object detection with one line of code [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 5562-5570.
[本文引用: 1]
[21]
LIU S T, HUANG D, WANG Y H. Adaptive NMS: refining pedestrian detection in a crowd [C]// IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 6452-6461.
[本文引用: 1]
[22]
LUO Y H, CAO X, ZHANG J T, et al. CE-FPN: enhancing channel information for object detection [EB/OL]. (2021-03-09). https://arxiv.org/pdf/2103.10643.pdf.
[本文引用: 1]
[23]
PANG J M, CHEN K, SHI J P, et al. Libra R-CNN: towards balanced learning for object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 821-830.
[本文引用: 1]
[24]
GUO C X, FAN B, ZHANG Q, et al. AugFPN: improving multi-scale feature learning for object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 12592-12601.
[本文引用: 1]
[25]
WANG K X, LIEW J H, ZHOU D Q, et al. PANet: few-shot image semantic segmentation with prototype alignment [C]// IEEE International Conference on Computer Vision . Seoul: IEEE, 2019: 9196-9205.
[本文引用: 1]
[26]
TAN X M, PANG R M, LE Q V. EfficientDet: scalable and efficient object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 10778-10787.
[本文引用: 1]
[27]
CHOLLET F. Xception: deep learning with depthwise separable convolutions [C]// IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 1800-1807.
[本文引用: 1]
[28]
HE J, SHEN L, ALBANIE S, et al Squeeze-and-excitation networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 42 (8 ): 2011 - 2023
DOI:10.1109/TPAMI.2019.2913372
[本文引用: 1]
[29]
HOU Q B, ZHOU D Q, FENG J S, et al. Coordinate attention for efficient mobile network design [C]//IEEE International Conference on Computer Vision . [S. l.]: IEEE, 2021: 13708-13717.
[本文引用: 1]
[30]
HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3 [C]// IEEE International Conference on Computer Vision . Seoul: IEEE, 2019: 1314-1324.
[本文引用: 1]
[31]
JIANG B R, LUO R X, MAO J Y, et al. Acquisition of localization confidence for accurate object detection [C]// European Conference on Computer Vision . Munich: Springer, 2018: 816-832.
[本文引用: 2]
[32]
TIAN Z, SHEN C H, CHEN H, et al. FCOS: fully convolutional one-stage object detection [C]// IEEE International Conference on Computer Vision . Seoul: IEEE, 2019: 9626-9635.
[本文引用: 2]
[33]
LI X, WANG W H, WU L J, et al Generalized focal loss: learning qualified and distributed bounding boxes for dense object detection
[J]. Advances in Neural Information Processing Systems , 2020 , 33 : 21002 - 21012
[本文引用: 1]
[34]
WU S K, LI X P, WANG X G IoU-aware single-stage object detector for accurate localization
[J]. Image and Vision Computing , 2020 , 97 : 103911
[本文引用: 2]
[35]
ZHENG Z, WANG P, LIU W, et al. Distance-IoU Loss: faster and better learning for bounding box regression[C]// AAAI Conference on Artificial Intelligence. New York: AAAI, 2020: 12993-13000.
[本文引用: 1]
[36]
HE K M, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN [C]// IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2980-2988.
[本文引用: 2]
[37]
CAI Z W, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection [C]// IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6154-6162.
[本文引用: 2]
[38]
YI J R, WU P X, METAXAS D N ASSD: attentive single shot multibox detector
[J]. Computer Vision and Image Understanding , 2019 , 189 : 102827
[本文引用: 2]
复杂背景下目标检测的级联分类器算法研究
1
2014
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
复杂背景下目标检测的级联分类器算法研究
1
2014
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
基于多层上下文卷积神经网络的目标检测算法
1
2020
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
基于多层上下文卷积神经网络的目标检测算法
1
2020
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
Faster R-CNN: towards real-time object detection with region proposal networks
3
2015
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
... [
3 ]
ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0 图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
SSD与时空特征融合的视频目标检测
1
2021
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
SSD与时空特征融合的视频目标检测
1
2021
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
基于改进DenseNet的水果小目标检测
1
2021
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
基于改进DenseNet的水果小目标检测
1
2021
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
2
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
1
... 目标检测是图像处理和计算机视觉领域的重要研究方向之一,对安防监控、工业检测、医学图像分析等方面有着重要的研究价值[1 ] . 近年来,随着深度学习在各个领域的广泛引用,越来越多的目标检测算法被提出[2 ] . 如今主流的目标检测算法主要分为以下2类. 1)基于候选框生成的双阶段(two stage)方法,例如Ren等[3 ] 提出Faster R-CNN网络,通过利用候选区域生成网络(region proposal network, RPN)提取少量且准确的候选区域,实现模型的端到端训练[4 ] . 2)基于单阶段回归的单阶段(one-stage)算法,通过在定位、尺度和横纵比上按照一定规则密集采样来检测目标[5 ] ,例如Redmon等[6 -8 ] 提出的YOLO系列网络,直接通过回归的方式实现目标检测任务. ...
Fully convolutional networks for semantic segmentation
1
2017
... 单阶段检测器仅依赖于单个完全卷积网络(fully convolutional networks, FCN)进行分类与定位[9 ] ,只包含一次目标检测过程,所以检测精度较差且定位可能出现较大的偏差. 目前,学术界对单阶段检测方法的改进主要集中在以下2个方面. 1)改变正负样本的选择策略,解决正负样本不均衡问题,例如Lin等[10 ] 提出的RetinaNet使用Focal Loss,给所有负样本赋予权重参加训练,Zhang等[11 ] 提出ATSS来自适应选择正负样本. 2)加入多尺度特征融合,如Lin等[12 ] 提出加入特征金字塔(feature pyramid network,FPN)将不同尺度的特征层进行融合. ...
2
... 单阶段检测器仅依赖于单个完全卷积网络(fully convolutional networks, FCN)进行分类与定位[9 ] ,只包含一次目标检测过程,所以检测精度较差且定位可能出现较大的偏差. 目前,学术界对单阶段检测方法的改进主要集中在以下2个方面. 1)改变正负样本的选择策略,解决正负样本不均衡问题,例如Lin等[10 ] 提出的RetinaNet使用Focal Loss,给所有负样本赋予权重参加训练,Zhang等[11 ] 提出ATSS来自适应选择正负样本. 2)加入多尺度特征融合,如Lin等[12 ] 提出加入特征金字塔(feature pyramid network,FPN)将不同尺度的特征层进行融合. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
2
... 单阶段检测器仅依赖于单个完全卷积网络(fully convolutional networks, FCN)进行分类与定位[9 ] ,只包含一次目标检测过程,所以检测精度较差且定位可能出现较大的偏差. 目前,学术界对单阶段检测方法的改进主要集中在以下2个方面. 1)改变正负样本的选择策略,解决正负样本不均衡问题,例如Lin等[10 ] 提出的RetinaNet使用Focal Loss,给所有负样本赋予权重参加训练,Zhang等[11 ] 提出ATSS来自适应选择正负样本. 2)加入多尺度特征融合,如Lin等[12 ] 提出加入特征金字塔(feature pyramid network,FPN)将不同尺度的特征层进行融合. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
1
... 单阶段检测器仅依赖于单个完全卷积网络(fully convolutional networks, FCN)进行分类与定位[9 ] ,只包含一次目标检测过程,所以检测精度较差且定位可能出现较大的偏差. 目前,学术界对单阶段检测方法的改进主要集中在以下2个方面. 1)改变正负样本的选择策略,解决正负样本不均衡问题,例如Lin等[10 ] 提出的RetinaNet使用Focal Loss,给所有负样本赋予权重参加训练,Zhang等[11 ] 提出ATSS来自适应选择正负样本. 2)加入多尺度特征融合,如Lin等[12 ] 提出加入特征金字塔(feature pyramid network,FPN)将不同尺度的特征层进行融合. ...
2
... 单阶段多边框检测器(single shot multi-box detector,SSD)是高效的单阶段目标检测器[13 ] . 原始SSD方法将轻量级的VGG网络作为主干网络,截断了基础VGG网络结构中的全连接层,在网络末端添加一系列逐渐减小的卷积特征层,实现了在多尺度映射中检测不同尺度的对象,使用NMS对最终的检测结果进行后处理[14 ] . SSD直接从平面卷积神经网络特征图检测对象,所以它可以实现对对象实时检测,处理速度比大部分主流对象检测器快. 虽然SSD是从不同尺度的特征层进行预测,但由于卷积神经网络提取的特征随着层数的增加,语义信息越来越强,SSD将不同层级的特征当作相同的级别进行预测,忽视了浅层的细节特征和高层语义特征之间的联系,因此SSD存在巨大的改进空间. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
复杂背景下的小目标检测算法
1
2020
... 单阶段多边框检测器(single shot multi-box detector,SSD)是高效的单阶段目标检测器[13 ] . 原始SSD方法将轻量级的VGG网络作为主干网络,截断了基础VGG网络结构中的全连接层,在网络末端添加一系列逐渐减小的卷积特征层,实现了在多尺度映射中检测不同尺度的对象,使用NMS对最终的检测结果进行后处理[14 ] . SSD直接从平面卷积神经网络特征图检测对象,所以它可以实现对对象实时检测,处理速度比大部分主流对象检测器快. 虽然SSD是从不同尺度的特征层进行预测,但由于卷积神经网络提取的特征随着层数的增加,语义信息越来越强,SSD将不同层级的特征当作相同的级别进行预测,忽视了浅层的细节特征和高层语义特征之间的联系,因此SSD存在巨大的改进空间. ...
复杂背景下的小目标检测算法
1
2020
... 单阶段多边框检测器(single shot multi-box detector,SSD)是高效的单阶段目标检测器[13 ] . 原始SSD方法将轻量级的VGG网络作为主干网络,截断了基础VGG网络结构中的全连接层,在网络末端添加一系列逐渐减小的卷积特征层,实现了在多尺度映射中检测不同尺度的对象,使用NMS对最终的检测结果进行后处理[14 ] . SSD直接从平面卷积神经网络特征图检测对象,所以它可以实现对对象实时检测,处理速度比大部分主流对象检测器快. 虽然SSD是从不同尺度的特征层进行预测,但由于卷积神经网络提取的特征随着层数的增加,语义信息越来越强,SSD将不同层级的特征当作相同的级别进行预测,忽视了浅层的细节特征和高层语义特征之间的联系,因此SSD存在巨大的改进空间. ...
2
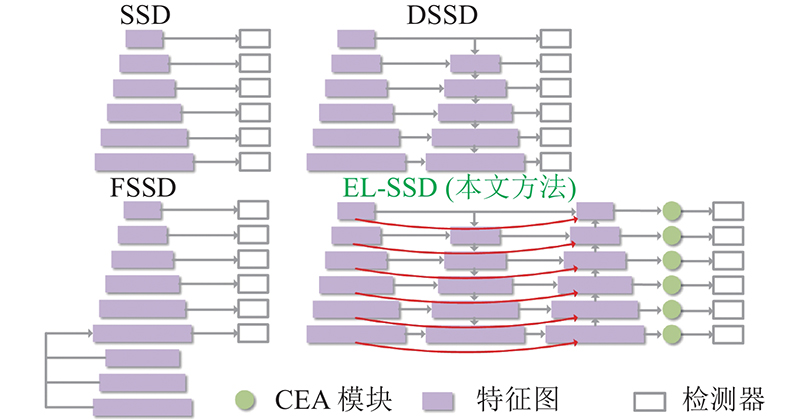
... 选择SSD作为改进的单阶段检测器,因为SSD提供了简单、速度和精度之间的最佳权衡. 目前,针对SSD的主流改进是通过增加特征融合模块,以增强网络的特征提取能力. 如图1 所示,DSSD提出用ResNet-101替换VGG16作为主干网络,在SSD末尾增加反卷积层,引入额外的上下文信息[15 ] . FSSD增加了额外的多尺度融合特征模块,将不同尺度特征图连接在一起,通过下采样生成新的特征金字塔层[16 ] . DSOD研究如何从零开始训练对象检测器,设计密集网络结构,以提升参数效率[17 ] . RefineDet在SSD网络的基础上,采用启发式的两步级联回归,优化了正负样本筛选[18 ] . 与现有的基于SSD的检测器相比,EL-SSD具有更高的平均检测精度和较快的检测速度,检测效率有了明显的提升. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
2
... 选择SSD作为改进的单阶段检测器,因为SSD提供了简单、速度和精度之间的最佳权衡. 目前,针对SSD的主流改进是通过增加特征融合模块,以增强网络的特征提取能力. 如图1 所示,DSSD提出用ResNet-101替换VGG16作为主干网络,在SSD末尾增加反卷积层,引入额外的上下文信息[15 ] . FSSD增加了额外的多尺度融合特征模块,将不同尺度特征图连接在一起,通过下采样生成新的特征金字塔层[16 ] . DSOD研究如何从零开始训练对象检测器,设计密集网络结构,以提升参数效率[17 ] . RefineDet在SSD网络的基础上,采用启发式的两步级联回归,优化了正负样本筛选[18 ] . 与现有的基于SSD的检测器相比,EL-SSD具有更高的平均检测精度和较快的检测速度,检测效率有了明显的提升. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
1
... 选择SSD作为改进的单阶段检测器,因为SSD提供了简单、速度和精度之间的最佳权衡. 目前,针对SSD的主流改进是通过增加特征融合模块,以增强网络的特征提取能力. 如图1 所示,DSSD提出用ResNet-101替换VGG16作为主干网络,在SSD末尾增加反卷积层,引入额外的上下文信息[15 ] . FSSD增加了额外的多尺度融合特征模块,将不同尺度特征图连接在一起,通过下采样生成新的特征金字塔层[16 ] . DSOD研究如何从零开始训练对象检测器,设计密集网络结构,以提升参数效率[17 ] . RefineDet在SSD网络的基础上,采用启发式的两步级联回归,优化了正负样本筛选[18 ] . 与现有的基于SSD的检测器相比,EL-SSD具有更高的平均检测精度和较快的检测速度,检测效率有了明显的提升. ...
2
... 选择SSD作为改进的单阶段检测器,因为SSD提供了简单、速度和精度之间的最佳权衡. 目前,针对SSD的主流改进是通过增加特征融合模块,以增强网络的特征提取能力. 如图1 所示,DSSD提出用ResNet-101替换VGG16作为主干网络,在SSD末尾增加反卷积层,引入额外的上下文信息[15 ] . FSSD增加了额外的多尺度融合特征模块,将不同尺度特征图连接在一起,通过下采样生成新的特征金字塔层[16 ] . DSOD研究如何从零开始训练对象检测器,设计密集网络结构,以提升参数效率[17 ] . RefineDet在SSD网络的基础上,采用启发式的两步级联回归,优化了正负样本筛选[18 ] . 与现有的基于SSD的检测器相比,EL-SSD具有更高的平均检测精度和较快的检测速度,检测效率有了明显的提升. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
1
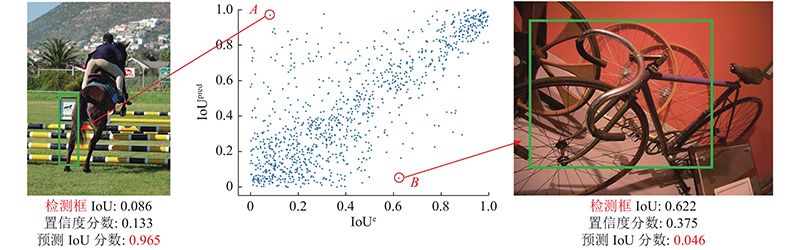
... NMS是计算机视觉中的重要组成部分,当采用平均精度(mean average precision,mAP)作为目标检测的评价指标时,利用贪婪NMS算法能够获得较优的性能,因此在主流的检测器中被广泛使用. 在目标检测中,NMS高效地检测聚类,通过不断检索分类置信度最高的检测框,使用交集-重叠来表示2个边界框之间的内在关联,将大于人工给定IoU阈值的边界框视作冗余检测框删去[19 ] ,即贪婪地选取得分最高的结果并删除那些超过阈值的相邻结果. 近年来,对NMS的改进是目标检测的重点之一. Soft-NMS提出连续函数衰减高分边界框的相邻框的置信分数,代替原本贪婪NMS中的直接消除所有较低分数的相邻边界框,有效提高了重叠物体的检测效果[20 ] . Adaptive-NMS设计动态抑制策略,使阈值随着实例的聚集和遮挡而上升,当实例单独出现时会衰减[21 ] . 上述对NMS算法的改进忽视了高分置信度边界框定位误差引起的检测效果损失,如图2 所示,检测框A分类置信度较高,但由于与真实框的IoU低于检测框B,经过传统NMS筛选后,保留存在定位偏差的检测框A,导致实际网络检测结果目标的位置较真实目标位置偏移较大,影响模型的检测性能. 提出的OPS-NMS通过构建分类置信度及定位置信度级联聚类,择优选取预测框,可以有效地解决上述问题. ...
1
... NMS是计算机视觉中的重要组成部分,当采用平均精度(mean average precision,mAP)作为目标检测的评价指标时,利用贪婪NMS算法能够获得较优的性能,因此在主流的检测器中被广泛使用. 在目标检测中,NMS高效地检测聚类,通过不断检索分类置信度最高的检测框,使用交集-重叠来表示2个边界框之间的内在关联,将大于人工给定IoU阈值的边界框视作冗余检测框删去[19 ] ,即贪婪地选取得分最高的结果并删除那些超过阈值的相邻结果. 近年来,对NMS的改进是目标检测的重点之一. Soft-NMS提出连续函数衰减高分边界框的相邻框的置信分数,代替原本贪婪NMS中的直接消除所有较低分数的相邻边界框,有效提高了重叠物体的检测效果[20 ] . Adaptive-NMS设计动态抑制策略,使阈值随着实例的聚集和遮挡而上升,当实例单独出现时会衰减[21 ] . 上述对NMS算法的改进忽视了高分置信度边界框定位误差引起的检测效果损失,如图2 所示,检测框A分类置信度较高,但由于与真实框的IoU低于检测框B,经过传统NMS筛选后,保留存在定位偏差的检测框A,导致实际网络检测结果目标的位置较真实目标位置偏移较大,影响模型的检测性能. 提出的OPS-NMS通过构建分类置信度及定位置信度级联聚类,择优选取预测框,可以有效地解决上述问题. ...
1
... NMS是计算机视觉中的重要组成部分,当采用平均精度(mean average precision,mAP)作为目标检测的评价指标时,利用贪婪NMS算法能够获得较优的性能,因此在主流的检测器中被广泛使用. 在目标检测中,NMS高效地检测聚类,通过不断检索分类置信度最高的检测框,使用交集-重叠来表示2个边界框之间的内在关联,将大于人工给定IoU阈值的边界框视作冗余检测框删去[19 ] ,即贪婪地选取得分最高的结果并删除那些超过阈值的相邻结果. 近年来,对NMS的改进是目标检测的重点之一. Soft-NMS提出连续函数衰减高分边界框的相邻框的置信分数,代替原本贪婪NMS中的直接消除所有较低分数的相邻边界框,有效提高了重叠物体的检测效果[20 ] . Adaptive-NMS设计动态抑制策略,使阈值随着实例的聚集和遮挡而上升,当实例单独出现时会衰减[21 ] . 上述对NMS算法的改进忽视了高分置信度边界框定位误差引起的检测效果损失,如图2 所示,检测框A分类置信度较高,但由于与真实框的IoU低于检测框B,经过传统NMS筛选后,保留存在定位偏差的检测框A,导致实际网络检测结果目标的位置较真实目标位置偏移较大,影响模型的检测性能. 提出的OPS-NMS通过构建分类置信度及定位置信度级联聚类,择优选取预测框,可以有效地解决上述问题. ...
1
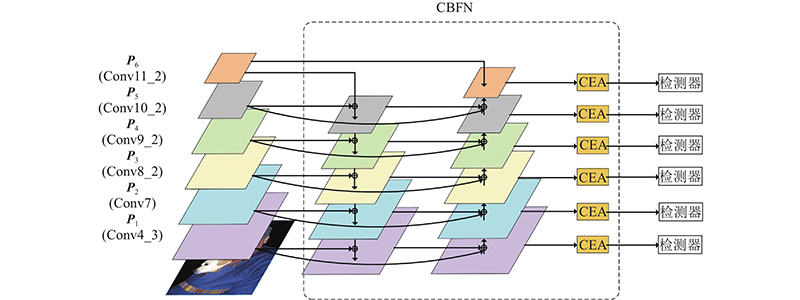
... 特征金字塔是用来解决特征图上下文语义缺失的常用办法,主流的基于特征金字塔(FPN-based)的改进算法通常直接将跨尺度融合特征的输出结果作为边框回归和分类预测的特征图[22 ] . 在通过特征金字塔的过程中,往往采用1×1的卷积层作为降低主干输出特征图P i [23 ] . 例如从高级特征图中通常能提取1 024个信息通道甚至更多,但是通常在特征金字塔的融合过程中被压缩到相比小得多的信息通道数,如256个. 除此以外,特征金字塔网络自上而下的特征融合过程中语义信息会被稀释[24 ] ,本文提出的CBFN模块将特征金字塔作为强化原有特征图的语义信息的工具,将通过改进特征金字塔的输出特征图与原来的6个特征图进行concat连接. ...
1
... 特征金字塔是用来解决特征图上下文语义缺失的常用办法,主流的基于特征金字塔(FPN-based)的改进算法通常直接将跨尺度融合特征的输出结果作为边框回归和分类预测的特征图[22 ] . 在通过特征金字塔的过程中,往往采用1×1的卷积层作为降低主干输出特征图P i [23 ] . 例如从高级特征图中通常能提取1 024个信息通道甚至更多,但是通常在特征金字塔的融合过程中被压缩到相比小得多的信息通道数,如256个. 除此以外,特征金字塔网络自上而下的特征融合过程中语义信息会被稀释[24 ] ,本文提出的CBFN模块将特征金字塔作为强化原有特征图的语义信息的工具,将通过改进特征金字塔的输出特征图与原来的6个特征图进行concat连接. ...
1
... 特征金字塔是用来解决特征图上下文语义缺失的常用办法,主流的基于特征金字塔(FPN-based)的改进算法通常直接将跨尺度融合特征的输出结果作为边框回归和分类预测的特征图[22 ] . 在通过特征金字塔的过程中,往往采用1×1的卷积层作为降低主干输出特征图P i [23 ] . 例如从高级特征图中通常能提取1 024个信息通道甚至更多,但是通常在特征金字塔的融合过程中被压缩到相比小得多的信息通道数,如256个. 除此以外,特征金字塔网络自上而下的特征融合过程中语义信息会被稀释[24 ] ,本文提出的CBFN模块将特征金字塔作为强化原有特征图的语义信息的工具,将通过改进特征金字塔的输出特征图与原来的6个特征图进行concat连接. ...
1
... 与PANet[25 ] 和EfficientDet[26 ] 将特征金字塔作为可堆叠重复模块(repeated blocks)不同,本文将有效的双向跨尺度和加权特征融合特征金字塔作为融合原待检测特征图的工具. 由于加入了额外的卷积层操作和权重计算,影响网络计算效率,选择用深度可分离卷积[27 ] 代替特征金字塔中的传统卷积操作,大大减少了参数运算量,在每次卷积后添加批归一化(batch normalization)和激活函数来加快训练速度. 如图4 所示,选择Conv4-3、Conv7、Conv8-2、Conv9-2、Conv10-2和Conv11-2作为特征金字塔的输入特征层(P 1 ~P 6 ),在原有的自上而下网络路径后,添加自下而上的路径融合网络,减少由于单一自上而下路径上采样高分辨率的特征带来的特征信息稀释. 对于原有输入的特征层P i P i P i in ,保证后续的特征融合过程中特征图通道数相等. 在自上而下的路径中,特征层P i +1td 进行上采样操作,将特征层P i+ 1td 与输入特征层P i in 相加后,得到特征层P i td . 在自下而上的路径中,为了避免将特征图输入特征金字塔后通道数减少引起的信息损失,将特征层P i -1dt 进行下采样操作,并与特征层P i td 及特征层P i in 相加,得到特征层P i dt . 由于将多个特征图跨尺度直接相加融合可能会导致混叠效应(aliasing effects),对特征层进行相加融合操作时,为每一个特征层添加权重ω
1
... 与PANet[25 ] 和EfficientDet[26 ] 将特征金字塔作为可堆叠重复模块(repeated blocks)不同,本文将有效的双向跨尺度和加权特征融合特征金字塔作为融合原待检测特征图的工具. 由于加入了额外的卷积层操作和权重计算,影响网络计算效率,选择用深度可分离卷积[27 ] 代替特征金字塔中的传统卷积操作,大大减少了参数运算量,在每次卷积后添加批归一化(batch normalization)和激活函数来加快训练速度. 如图4 所示,选择Conv4-3、Conv7、Conv8-2、Conv9-2、Conv10-2和Conv11-2作为特征金字塔的输入特征层(P 1 ~P 6 ),在原有的自上而下网络路径后,添加自下而上的路径融合网络,减少由于单一自上而下路径上采样高分辨率的特征带来的特征信息稀释. 对于原有输入的特征层P i P i P i in ,保证后续的特征融合过程中特征图通道数相等. 在自上而下的路径中,特征层P i +1td 进行上采样操作,将特征层P i+ 1td 与输入特征层P i in 相加后,得到特征层P i td . 在自下而上的路径中,为了避免将特征图输入特征金字塔后通道数减少引起的信息损失,将特征层P i -1dt 进行下采样操作,并与特征层P i td 及特征层P i in 相加,得到特征层P i dt . 由于将多个特征图跨尺度直接相加融合可能会导致混叠效应(aliasing effects),对特征层进行相加融合操作时,为每一个特征层添加权重ω
1
... 与PANet[25 ] 和EfficientDet[26 ] 将特征金字塔作为可堆叠重复模块(repeated blocks)不同,本文将有效的双向跨尺度和加权特征融合特征金字塔作为融合原待检测特征图的工具. 由于加入了额外的卷积层操作和权重计算,影响网络计算效率,选择用深度可分离卷积[27 ] 代替特征金字塔中的传统卷积操作,大大减少了参数运算量,在每次卷积后添加批归一化(batch normalization)和激活函数来加快训练速度. 如图4 所示,选择Conv4-3、Conv7、Conv8-2、Conv9-2、Conv10-2和Conv11-2作为特征金字塔的输入特征层(P 1 ~P 6 ),在原有的自上而下网络路径后,添加自下而上的路径融合网络,减少由于单一自上而下路径上采样高分辨率的特征带来的特征信息稀释. 对于原有输入的特征层P i P i P i in ,保证后续的特征融合过程中特征图通道数相等. 在自上而下的路径中,特征层P i +1td 进行上采样操作,将特征层P i+ 1td 与输入特征层P i in 相加后,得到特征层P i td . 在自下而上的路径中,为了避免将特征图输入特征金字塔后通道数减少引起的信息损失,将特征层P i -1dt 进行下采样操作,并与特征层P i td 及特征层P i in 相加,得到特征层P i dt . 由于将多个特征图跨尺度直接相加融合可能会导致混叠效应(aliasing effects),对特征层进行相加融合操作时,为每一个特征层添加权重ω
Squeeze-and-excitation networks
1
2020
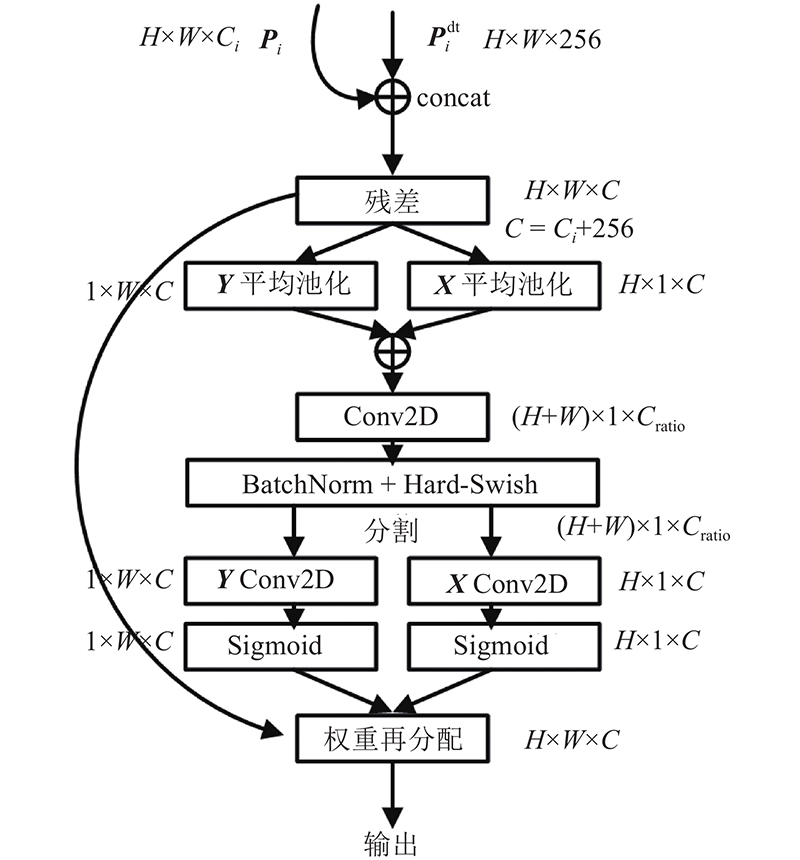
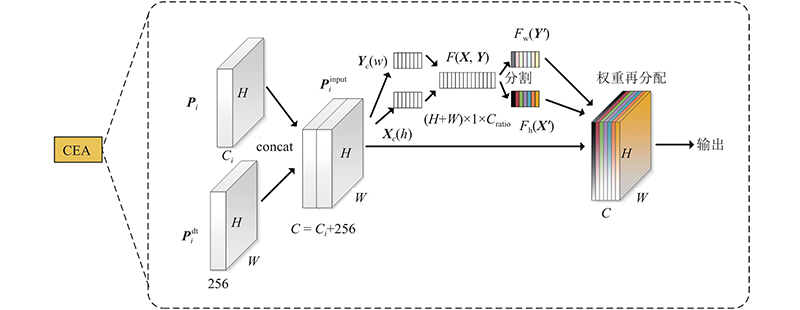
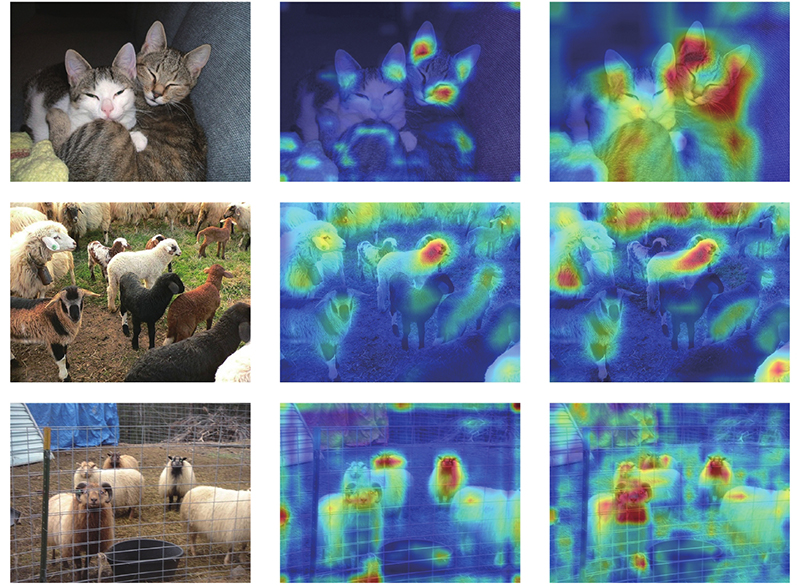
... CEA模块的结构如图5 所示. 该模块将接收到的P i dt 分别与相同分辨率的P i [28 ] . EL-SSD主要解决单阶段检测器检测定位效果不佳的问题,选择加入轻量级的协调注意力[29 ] (coordinate attention),在获取通道信息的基础上捕获特征位置信息和通道关系,以增强网络结构的特征表示,具体过程如图6 所示. ...
1
... CEA模块的结构如图5 所示. 该模块将接收到的P i dt 分别与相同分辨率的P i [28 ] . EL-SSD主要解决单阶段检测器检测定位效果不佳的问题,选择加入轻量级的协调注意力[29 ] (coordinate attention),在获取通道信息的基础上捕获特征位置信息和通道关系,以增强网络结构的特征表示,具体过程如图6 所示. ...
1
... 式中:Y P 为对Y f cat 为concat连接操作;f ratio 为根据缩放参数R 使用1×1的卷积减低通道数,以减少计算量;f BN 为使用批归一化(batch normalization);δ 为hard-swish[30 ] 激活函数. 在完成缩放归一化操作后,将Z X′ Y′
2
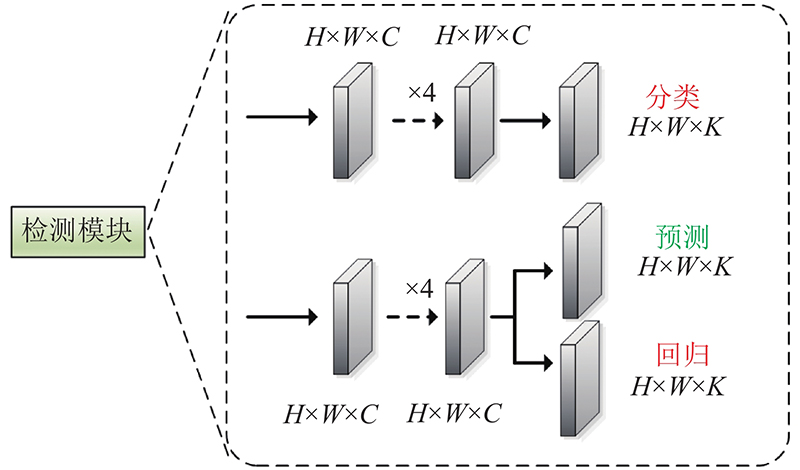
... 基于卷积神经网络的目标检测都依赖于边框回归和非极大值抑制来定位对象. 虽然对预测过程中的类标签概率可以反映分类置信度,但是缺少定位置信度来表示回归得出的边框的定位质量,因此在SSD的检测模块中,额外添加了定位质量预测分支,学习预测候选框和真实框的内在联系. 对于定位质量,IoU-Net提出使用IoU作为预测定位质量的标准[31 ] .FCOS提出中心度(centerness)预测来抑制低位置质量的预测框[32 ] .Generalized Focal Loss的实验[33 ] 提出,针对定位质量的预测IoU的效果优于centerness. 本文选择预测IoU作为定位质量的标准. 受到RetinaNet的启发,将分类和回归分别放在2个并行的小型FCN[34 ] 网络中进行预测,在回归网络上添加了额外的IoU预测分支,如图8 所示. ...
... 基于得到的IoU预测分数,提出定位质量分数和分类分数共同引导的OPS-NMS方法,解决了分类置信度和定位精度之间的不对准问题. NMS将分类置信度阈值作为筛选检测框标准,IoU-guided NMS[31 ] 直接使用IoU置信度替换分类置信度作为选取标准,但单一选择分类置信度或者IoU置信度都无法有效地同时表示待检测目标的分类质量和定位质量. IoU-aware RetinaNet[34 ] 提出将IoU分数与分类分数相乘得到质量分数,但定位质量估计和分类分数预测都是独立训练,定位质量估计都是由正样本分配监督,可能会导致负样本产生无法控制的高质量预测图. 图9 中,IoUe 为IoU的评估值,IoUpred 为IoU预测分数.如图9 所示,将不可靠的定位质量和预测分数联合,可能会导致高分类分数的检测框被抑制. ...
2
... 基于卷积神经网络的目标检测都依赖于边框回归和非极大值抑制来定位对象. 虽然对预测过程中的类标签概率可以反映分类置信度,但是缺少定位置信度来表示回归得出的边框的定位质量,因此在SSD的检测模块中,额外添加了定位质量预测分支,学习预测候选框和真实框的内在联系. 对于定位质量,IoU-Net提出使用IoU作为预测定位质量的标准[31 ] .FCOS提出中心度(centerness)预测来抑制低位置质量的预测框[32 ] .Generalized Focal Loss的实验[33 ] 提出,针对定位质量的预测IoU的效果优于centerness. 本文选择预测IoU作为定位质量的标准. 受到RetinaNet的启发,将分类和回归分别放在2个并行的小型FCN[34 ] 网络中进行预测,在回归网络上添加了额外的IoU预测分支,如图8 所示. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
Generalized focal loss: learning qualified and distributed bounding boxes for dense object detection
1
2020
... 基于卷积神经网络的目标检测都依赖于边框回归和非极大值抑制来定位对象. 虽然对预测过程中的类标签概率可以反映分类置信度,但是缺少定位置信度来表示回归得出的边框的定位质量,因此在SSD的检测模块中,额外添加了定位质量预测分支,学习预测候选框和真实框的内在联系. 对于定位质量,IoU-Net提出使用IoU作为预测定位质量的标准[31 ] .FCOS提出中心度(centerness)预测来抑制低位置质量的预测框[32 ] .Generalized Focal Loss的实验[33 ] 提出,针对定位质量的预测IoU的效果优于centerness. 本文选择预测IoU作为定位质量的标准. 受到RetinaNet的启发,将分类和回归分别放在2个并行的小型FCN[34 ] 网络中进行预测,在回归网络上添加了额外的IoU预测分支,如图8 所示. ...
IoU-aware single-stage object detector for accurate localization
2
2020
... 基于卷积神经网络的目标检测都依赖于边框回归和非极大值抑制来定位对象. 虽然对预测过程中的类标签概率可以反映分类置信度,但是缺少定位置信度来表示回归得出的边框的定位质量,因此在SSD的检测模块中,额外添加了定位质量预测分支,学习预测候选框和真实框的内在联系. 对于定位质量,IoU-Net提出使用IoU作为预测定位质量的标准[31 ] .FCOS提出中心度(centerness)预测来抑制低位置质量的预测框[32 ] .Generalized Focal Loss的实验[33 ] 提出,针对定位质量的预测IoU的效果优于centerness. 本文选择预测IoU作为定位质量的标准. 受到RetinaNet的启发,将分类和回归分别放在2个并行的小型FCN[34 ] 网络中进行预测,在回归网络上添加了额外的IoU预测分支,如图8 所示. ...
... 基于得到的IoU预测分数,提出定位质量分数和分类分数共同引导的OPS-NMS方法,解决了分类置信度和定位精度之间的不对准问题. NMS将分类置信度阈值作为筛选检测框标准,IoU-guided NMS[31 ] 直接使用IoU置信度替换分类置信度作为选取标准,但单一选择分类置信度或者IoU置信度都无法有效地同时表示待检测目标的分类质量和定位质量. IoU-aware RetinaNet[34 ] 提出将IoU分数与分类分数相乘得到质量分数,但定位质量估计和分类分数预测都是独立训练,定位质量估计都是由正样本分配监督,可能会导致负样本产生无法控制的高质量预测图. 图9 中,IoUe 为IoU的评估值,IoUpred 为IoU预测分数.如图9 所示,将不可靠的定位质量和预测分数联合,可能会导致高分类分数的检测框被抑制. ...
1
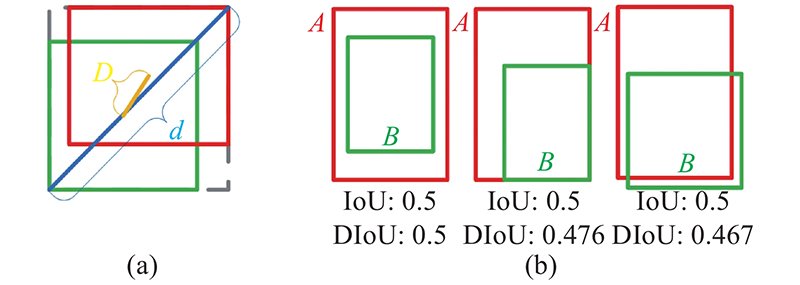
... 式中:N Pos 为正样本个数,x ij p i 个默认框与第p 类的第j 个真实框匹配指标,c i p i 个默认框预测为第p 类的置信度,c i 0 为第i 个默认框预测为背景的置信度. 传统的SSD使用Smooth L1函数作为定位损失函数,将位置信息作为4个相互独立的变量进行训练回归,然而将位置信息作为一个整体进行训练回归,可以有效地加速函数收敛,提高训练的精度和鲁棒性. 选择CIoU Loss函数[35 ] 训练定位回归,如下所示: ...
2
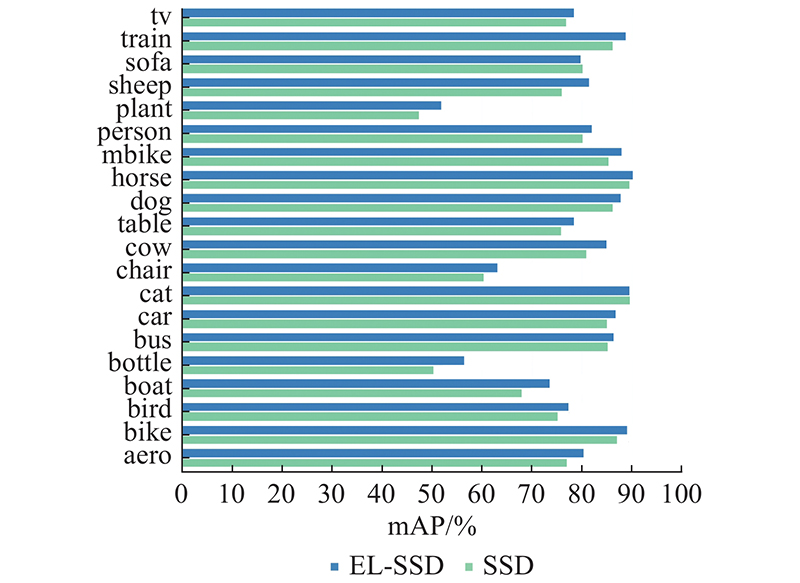
... 将提出的EL-SSD的实验结果与表1 的经典目标检测算法及SSD的各种改进算法的基础网络结构进行比较,各个网络均未采用多尺度训练和额外的数据增强. EL-SSD将输入图片的分辨率调整至300×300像素后输入特征提取网络,平均精度达到79.8%,较初始SSD算法提高了2.6%,比骨干网络为VGGNet的双阶段网络Faster R-CNN提高了6.6%,比Mask R-CNN[36 ] 和Cascade R-CNN[37 ] 分别提高了2.4%和0.2%. EL-SSD的平均精度较另一单阶段目标检测算法YOLOV2提高了6.1%,较单阶段无锚框的检测算法FCOS及改进算法ATSS分别提高了6.3%和4.6%. 除此以外,在输入相同(相近)分辨率的图片情况下,El-SSD的检测精度优于DSSD、FSSD、ASSD[38 ] 及RetinaNet等基于SSD的后续改进算法,提高了0.4%~1.2%,比RefineDet低了0.2%. EL-SSD检测一张图片需要37 ms,检测速度略低于初始SSD及FSSD,优于DSSD、RetinaNet及RefineDet,达到了检测精度和检测速度的均衡. 如图11 所示为EL-SSD和SSD在VOC数据集上20类物体的检测精度对比. 可以发现,EL-SSD在大部分类别中检测效果都有明显的提升. 在目标检测任务中,一般将尺寸小于32×32像素的目标定义为小目标. 针对SSD检测效果较差的小目标物体类别Plant和Bottle,EL-SSD的检测精度分别提高了4.5%和6.6%,本文通过实验分析得出EL-SSD通过CBFN模块和OPS-NMS,有效缓解了由定位不准问题和语义信息的缺失问题引起的小目标检测效果不佳问题. 如表2 所示,EL-SSD小目标类别在预测框与真实框的IoU阈值IoUt 为0.75和0.95的情况下精度都明显高于SSD,在目标定位效果上有明显的提升. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
2
... 将提出的EL-SSD的实验结果与表1 的经典目标检测算法及SSD的各种改进算法的基础网络结构进行比较,各个网络均未采用多尺度训练和额外的数据增强. EL-SSD将输入图片的分辨率调整至300×300像素后输入特征提取网络,平均精度达到79.8%,较初始SSD算法提高了2.6%,比骨干网络为VGGNet的双阶段网络Faster R-CNN提高了6.6%,比Mask R-CNN[36 ] 和Cascade R-CNN[37 ] 分别提高了2.4%和0.2%. EL-SSD的平均精度较另一单阶段目标检测算法YOLOV2提高了6.1%,较单阶段无锚框的检测算法FCOS及改进算法ATSS分别提高了6.3%和4.6%. 除此以外,在输入相同(相近)分辨率的图片情况下,El-SSD的检测精度优于DSSD、FSSD、ASSD[38 ] 及RetinaNet等基于SSD的后续改进算法,提高了0.4%~1.2%,比RefineDet低了0.2%. EL-SSD检测一张图片需要37 ms,检测速度略低于初始SSD及FSSD,优于DSSD、RetinaNet及RefineDet,达到了检测精度和检测速度的均衡. 如图11 所示为EL-SSD和SSD在VOC数据集上20类物体的检测精度对比. 可以发现,EL-SSD在大部分类别中检测效果都有明显的提升. 在目标检测任务中,一般将尺寸小于32×32像素的目标定义为小目标. 针对SSD检测效果较差的小目标物体类别Plant和Bottle,EL-SSD的检测精度分别提高了4.5%和6.6%,本文通过实验分析得出EL-SSD通过CBFN模块和OPS-NMS,有效缓解了由定位不准问题和语义信息的缺失问题引起的小目标检测效果不佳问题. 如表2 所示,EL-SSD小目标类别在预测框与真实框的IoU阈值IoUt 为0.75和0.95的情况下精度都明显高于SSD,在目标定位效果上有明显的提升. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...
ASSD: attentive single shot multibox detector
2
2019
... 将提出的EL-SSD的实验结果与表1 的经典目标检测算法及SSD的各种改进算法的基础网络结构进行比较,各个网络均未采用多尺度训练和额外的数据增强. EL-SSD将输入图片的分辨率调整至300×300像素后输入特征提取网络,平均精度达到79.8%,较初始SSD算法提高了2.6%,比骨干网络为VGGNet的双阶段网络Faster R-CNN提高了6.6%,比Mask R-CNN[36 ] 和Cascade R-CNN[37 ] 分别提高了2.4%和0.2%. EL-SSD的平均精度较另一单阶段目标检测算法YOLOV2提高了6.1%,较单阶段无锚框的检测算法FCOS及改进算法ATSS分别提高了6.3%和4.6%. 除此以外,在输入相同(相近)分辨率的图片情况下,El-SSD的检测精度优于DSSD、FSSD、ASSD[38 ] 及RetinaNet等基于SSD的后续改进算法,提高了0.4%~1.2%,比RefineDet低了0.2%. EL-SSD检测一张图片需要37 ms,检测速度略低于初始SSD及FSSD,优于DSSD、RetinaNet及RefineDet,达到了检测精度和检测速度的均衡. 如图11 所示为EL-SSD和SSD在VOC数据集上20类物体的检测精度对比. 可以发现,EL-SSD在大部分类别中检测效果都有明显的提升. 在目标检测任务中,一般将尺寸小于32×32像素的目标定义为小目标. 针对SSD检测效果较差的小目标物体类别Plant和Bottle,EL-SSD的检测精度分别提高了4.5%和6.6%,本文通过实验分析得出EL-SSD通过CBFN模块和OPS-NMS,有效缓解了由定位不准问题和语义信息的缺失问题引起的小目标检测效果不佳问题. 如表2 所示,EL-SSD小目标类别在预测框与真实框的IoU阈值IoUt 为0.75和0.95的情况下精度都明显高于SSD,在目标定位效果上有明显的提升. ...
... Comparison of mean average precision on VOC2007 test dataset
Tab.1 方法 骨干网络 输入尺寸 GPU mAP/% v /(帧·s−1 ) Faster R-CNN[3 ] VGGNet 1000×600 Titan X 73.2 7.0 Faster R-CNN[3 ] ResNet-101 1000×600 1080Ti 78.8 2.3 Mask R-CNN[36 ] ResNet-50 1000×600 1080Ti 77.4 4.2 Cascade R-CNN[37 ] VGGNet 1000×600 1080Ti 79.6 5.3 YOLOV2[6 ] Darknet-19 352×352 Titan X 73.7 81.0 RefineDet320[18 ] VGGNet 320×320 1080Ti 80.0 22.1 FCOS[32 ] ResNet-50 1333×800 1080Ti 73.5 17.6 ATSS[11 ] ResNet-50 1333×800 1080Ti 75.2 14.9 RetinaNet400[10 ] ResNet-101 ~640x400 1080Ti 79.4 12.4 FSSD300[16 ] VGGNet 300×300 1080Ti 78.8 65.0 SSD300[13 ] VGGNet 300×300 1080Ti 77.2 42.1 ASSD321[38 ] ResNet-101 321×321 K40 79.5 11.4 DSSD321[15 ] ResNet-101 321×321 Titan X 78.6 9.5 EL-SSD300 VGGNet 300×300 1080Ti 79.8 27.0
图 11 VOC2007测试集20类目标检测精度结果的柱状图 ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}