

现代经济的发展与人们生活品质的不断提高,车辆的使用逐年增多. 一个城市的交通在很大程度上代表这个城市的发展,由于车辆的不断增加给城市交通管理带来了一定的困难. 为了适应车辆的逐年增多,建立能够高效、便捷管理交通的智能交通系统[1]是城市发展的重要前提,车流量分析、全自动收费系统的精准性在很大程度上反映系统的性能,因此需要依靠车型的识别与分类来提高智能交通系统的精准性.
车型分类主要是根据车型、车身的主要标志等外观特征对车辆进行分类,传统的车型分类算法[2]包括特征提取与分类器设计2个部分. 近年来机器学习和计算机视觉在图像处理方向的飞速发展,使得更多的研究者将目光转移到使用机器学习的方法来进行车型的分类. AlexNet[3]在ILSVRC图像识别竞赛中的良好表现,加速了卷积神经网络在图像分类中的应用. Dong等[4]利用半监督卷积神经网络对车型进行识别,但是在相似车型识别上的识别精度不高. 袁公萍等[5]对Faster R-CNN进行改进,通过引入中心损失函数与softmax损失函数实现联合监控,减少全连接层数,实现识别精度的提升,但这种方法中的联合损失权重需要进行多组实验确定,较为复杂. 近年来,深度神经网络(DCNN)[6]在图像分类中取得了良好的成绩. 杨州等[7]提出将多尺度特征融合与DCNN相结合的算法,在图像场景分类中取得较好的成果. 李大湘等[8]提出在DCNN的基础上,结合拉格朗日支持向量机(Lagrangian support vector machine,LSVM)与Adaboost方法,利用PCA降维的DCNN -ALSVM车型分类方法,但是识别精度上仍有提升的空间. 以上算法虽然在识别精度上有一定的提升,但在一定程度上增加了网络的复杂性.
本文采用高效率网络(EfficientNet ,high efficiency network)[9]作为基础特征提取网络,通过复合缩放的方式,使网络中的深度、宽度、分辨率达到平衡,将深度可分离卷积集成到基础特征提取模块中,大大减少了模型参数量,保证了模型的分类准确率和泛化能力. 本文的机器模型构建以EfficientNet-B0为基础,在具体的设计中进行如下改进:在网络进行特征提取时,增加含有残差结构的双通道注意力机制来提取图像的关键信息,增加softmax分类器与最后的全连接层连接;使用标签平滑正则化的方式处理损失函数,通过实验发现,改进后的模型提高了车型分类的准确率.
1. EfficientNet模型构建
1.1. EfficientNet概述
EfficientNet的主要思想是通过复合缩放(compound scaling)的方法提出固定的比例,平衡网络的深度d、宽度w、分辨率r,实现3个维度之间的平衡,解决了通过增加单个维度而使准确率达到饱和的问题. 复合缩放公式如下:
表 1 EfficientNet缩放参数
Tab.1
| EfficientNet | w | d | r | dr |
| B0 | 1.0 | 1.0 | 224 | 0.2 |
| B1 | 1.0 | 1.1 | 240 | 0.2 |
| B2 | 1.1 | 1.2 | 260 | 0.3 |
| B3 | 1.2 | 1.4 | 300 | 0.3 |
| B4 | 1.4 | 1.8 | 380 | 0.4 |
| B5 | 1.6 | 2.2 | 456 | 0.4 |
| B6 | 1.8 | 2.6 | 528 | 0.5 |
| B7 | 2.0 | 3.1 | 600 | 0.5 |
实验表明,当数据集分辨率与模型分辨率一致时,模型的分类准确率最高,因此选择与数据集分辨率224×224最匹配的EfficientNet-B0作为基础模型.
1.2. EfficientNet模型结构与改进
1.2.1. 深度可分离卷积
在轻量级网络中通常采用深度可分离卷积[13]代替普通卷积,在同等参数量的情况下,深度可分离卷积比普通卷积取得更深层的网络.
进行普通卷积之后输出图像特征图,高为
式中:p为填充数,
参数量P的计算过程如下:
计算量(FLOPs)的计算过程如下:
式中:
从式(6)、(7)可以看出,运用深度可分离卷积极大地降低了模型的参数量和计算量,实现了卷积通道和区域的分离,保证了网络的精度,提高了网络的检测速度.
1.2.2. MBConv卷积块
图 1
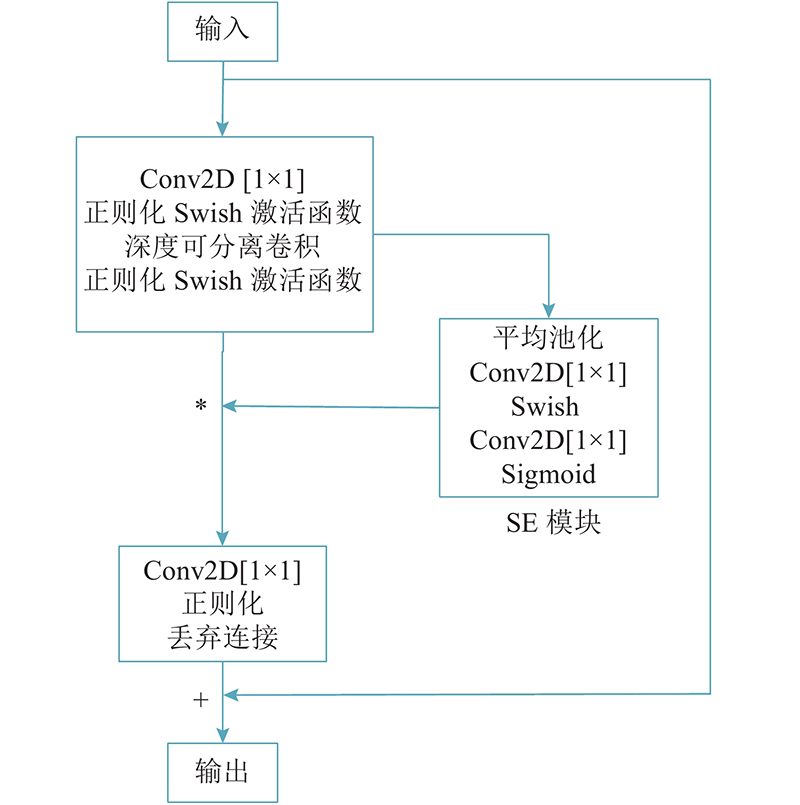
EfficientNet-B0 改进后的网络参数结构如表2所示. 一共有16 层 MBConv卷积层,最后一层为一个卷积层经过平均池化后输出给全连接层,增加一个softmax分类器与全连接层连接. 将输出结果映射到(0,1),输出结果为该输入图像识别为不同车型的分类概率,概率总和为1,预测概率最大的车型为预测车型,得到更好的图像分类效果.
表 2 EfficientNet-B0网络参数结构
Tab.2
| 阶段 | 参数 | 通道数 | 分辨率 |
| 1 | Conv3×3 | 32×1 | 224×224 |
| 2 | MBConv1, 3×3 | 16×1 | 112×112 |
| 3 | MBConv6, 3×3 | 24×2 | 112×112 |
| 4 | MBConv6, 5×5 | 40×2 | 56×56 |
| 5 | MBConv6, 3×3 | 80×3 | 28×28 |
| 6 | MBConv6, 5×5 | 112×3 | 14×14 |
| 7 | MBConv6, 5×5 | 192×4 | 14×14 |
| 8 | MBConv6, 3×3 | 320×1 | 7×7 |
| 9 | Conv1×1×1, Pooling | 1280×1 | 7×7 |
| 10 | FC, softmax | 1280×1 | 7×7 |
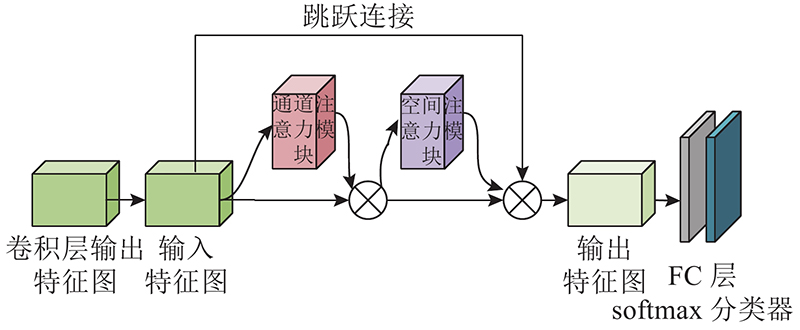
1.2.3. 双通道残差注意力机制
注意力机制[18](attention mechanism)是通过在全局信息中寻找具有关键作用的局部信息来对数据进行处理,能够更有针对性地关注有用特征,排除无用信息.
图 2
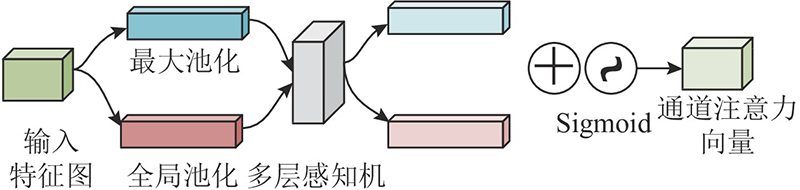
图 3
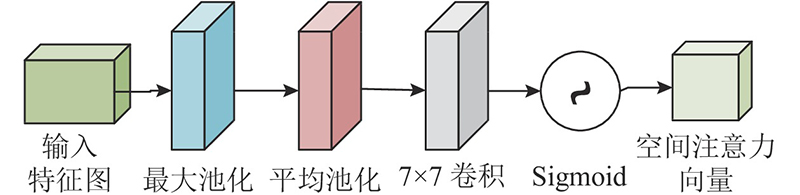
图 4
2. 损失函数的选择
2.1. 交叉熵损失函数
交叉熵损失函数[21]通常与softmax函数一起出现在神经网络分类问题中,计算公式为
式中:
交叉熵损失函数的定义为
式中:m为样本总数,
式中: y为预测标签. 交叉熵损失函数更注重于标签预测的准确率,忽略了其他非正确标签的差异性,容易造成过拟合(over-fitting)问题.
2.2. 标签平滑正则化损失函数
标签平滑正则化(label smoothing regularization, LSR)[23]是通过引入噪声,改变经过传统独热编码化后的标签值,从而改变预测概率和损失函数的值,使得网络具有更好的包容性.
LSR处理后输出的独热编码标签值为
式中:ε为较小的超参数,K为类别总数.
LSR处理后的损失函数Li为
LSR损失函数通过设置ε为超参数,相当于在预测真实标签时加入了噪声,计算非正确标签的差异,因此LSR处理过的网络具有一定的容错性.
改用LSR损失函数,代替原始模型中的交叉熵损失函数,解决了交叉熵损失函数对标签预测结果盲目自信的问题,改善了模型的过拟合问题.
3. 实验结果分析
3.1. 实验数据介绍
实验操作系统为Ubuntu14.04,使用GPU加速训练,安装CUDA10.0和cudnn7.4.2以支持GPU的使用. 算法仿真软件为Python 3.6.2,pytorch1.0.1.
采用北京理工大学制作的BIT-Vehicles数据集. 该数据集中的所有图像来自真实交通中的监控视频截图,其中包括6类车型,总共9 850张图像,数据集分布及标签设置如表3所示.
表 3 BIT-Vehicles数据集分布
Tab.3
| 类别 | 数量 | y |
| 公共汽车(Bus) | 558 | 0 |
| 微型客车(Microbus) | 883 | 1 |
| 小货车(Minivan) | 475 | 2 |
| 小轿车(Sedan) | 5921 | 3 |
| 越野车(SUV) | 1392 | 4 |
| 卡车(Truck) | 822 | 5 |
根据数据集中提供的车辆位置信息,将车辆从图中截取. 由于不同车型之间的图像数据量相差过大,通过调节图像亮度、图像翻转,对样本量较小的Bus、Microbus、Minivan、Truck类别数据进行数据扩充,对样本量较大的Sedan、SUV类别进行随机抽取,将图像分辨率归一化为224×224像素. 为了防止因数据集分布不均而造成的误差,针对6种车型分别选取1 000幅图像作为总训练集,共选取600幅图像作为测试集. 如图5所示为6类车型的图像示例.
图 5

3.2. 模型评价指标
机器学习中,常通过混淆矩阵分析模型对预测结果的具体情况,是模型评估常用的指标,主要通过将真实结果与预测结果放在同一矩阵下,直观地看到真实结果与预测结果的具体分布情况. 如表4所示为二分类问题的混淆矩阵.
表4中,TP(true positive)为真阳性,FP(false positive)为假阳性,TN(true negative)为真阴性,FN(false negative)为假阴性.
准确率Acc(accuracy)是判别模型总体能力的指标,通过预测正确的样本占总样本的比例来表示,计算公式为
召回率R(recall)是指预测为正样本的图像占实际为正样本的概率,计算公式为
漏警率Mi(miss rate)是指预测为负样本的图像占实际为正样本的概率,计算公式为
3.3. 实验结果对比及分析
3.3.1. 实验结果
数据集分辨率为224×224像素,将数据集输入到EfficientNet-B0~B7中,在不同模型下的分类准确率及保存的模型参数量P如表5所示.
表 5 EfficientNet-B0~B7的训练结果
Tab.5
| EfficientNet | Acc /% | P/106 |
| B0 | 93.17 | 15.59 |
| B1 | 91.17 | 25.26 |
| B2 | 92.83 | 29.81 |
| B3 | 90.17 | 41.33 |
| B4 | 93.00 | 67.65 |
| B5 | 92.50 | 109.05 |
| B6 | 91.00 | 156.56 |
| B7 | 93.00 | 224.88 |
从表5可知,当输入图像分辨率为224×224像素时,EfficientNet-B0对图像的分类准确率最高,保存的模型参数量最小,因此选择EfficientNet-B0作为基准模型. 训练时,批尺寸为32,随机梯度动量为0.9,学习率为0.1,当训练准确率超过99.9%时结束训练.
通过五折交叉验证实验,开展实验验证. 使用EfficientNet-B0作为原始模型,EfficientNet-B0单独与LSR处理和单独与softmax分类器及残差CBAM相结合作为对比模型,将实验结果与本文方法进行对比分析,不同模型下的车型分类准确率如表6所示.
表 6 不同模型下的车型分类准确率
Tab.6
| 类别 | Acc /% | ||||
| Efficient Net-B0 | B0+LSR | B0+softmax | B0+残差 CBAM | 本文方法 | |
| Bus | 99.90 | 99.90 | 99.90 | 99.99 | 99.99 |
| Microbus | 95.60 | 96.20 | 97.00 | 96.60 | 98.20 |
| Minivan | 99.80 | 99.80 | 99.80 | 99.99 | 99.99 |
| Sedan | 98.60 | 98.60 | 98.00 | 97.80 | 98.40 |
| SUV | 84.80 | 82.80 | 84.60 | 85.60 | 86.60 |
| Truck | 95.40 | 97.00 | 96.00 | 96.00 | 97.80 |
从表6可以看出,单独处理的模型分类准确率有一定的提升,本文的改进模型较原始模型有明显的提升. 其中Microbus提升了2.6%,SUV提升了1.8%,Truck提升了2.4%,平均准确率较改进前的模型提高了1.11%.
如图6所示为原始模型与本文改进后的模型在测试集上的损失收敛过程. 图中,Ne为迭代次数. 原始模型在损失逐渐稳定后有小幅上升的趋势,改进后的模型损失收敛更加稳定,减少了过拟合.
图 6
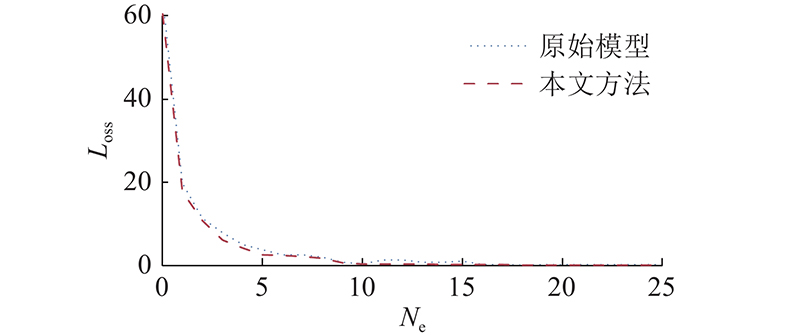
图 6 改进前、后的模型损失收敛曲线
Fig.6 Loss convergence curve of model before and after improvement
不同模型下单张图片的识别时间T如表7所示. 原始EfficientNet-B0的识别时间最短,速度最快,改进后的模型单张图片识别时间增加了3 ms左右,在实际应用中不影响网络的识别速度.
表 7 单张图片的识别时间
Tab.7
| 模型 | T/ms |
| EfficientNet-B0 | 8.9825 |
| B0+LSR | 10.9409 |
| B0+softmax | 12.3933 |
| B0+残差CBAM | 12.1856 |
| 本文方法 | 11.9415 |
表 8 EfficientNet-B0的混淆矩阵
Tab.8
| 真实标签 | 预测值 | |||||
| y = 0 | y = 1 | y = 2 | y = 3 | y = 4 | y = 5 | |
| 0 | 100 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 96 | 0 | 2 | 2 | 0 |
| 2 | 0 | 0 | 100 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 98 | 2 | 0 |
| 4 | 0 | 6 | 0 | 9 | 85 | 0 |
| 5 | 0 | 0 | 5 | 0 | 0 | 95 |
表 9 改进后模型的混淆矩阵
Tab.9
| 真实标签 | 预测值 | |||||
| y = 0 | y = 1 | y = 2 | y = 3 | y = 4 | y = 5 | |
| 0 | 100 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 98 | 0 | 1 | 1 | 0 |
| 2 | 0 | 0 | 100 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 98 | 2 | 0 |
| 4 | 0 | 4 | 0 | 9 | 87 | 0 |
| 5 | 0 | 0 | 2 | 0 | 0 | 98 |
从混淆矩阵可以看出,原始模型中越野车的召回率最小,主要识别为小轿车和微型客车,漏警率分别为9%和6%,其次卡车识别为小货车的漏警率为5%. 利用改进后的模型提高了越野车和卡车的召回率,降低了各自错分车型的漏警率.
3.3.2. 不同方法对比分析
图 7
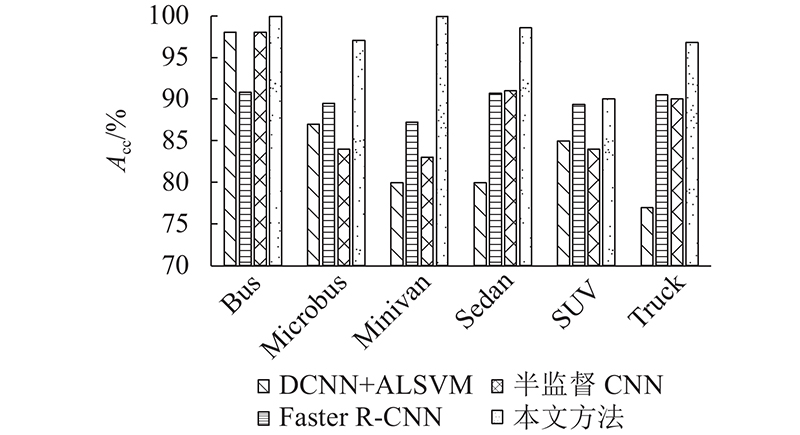
图 8
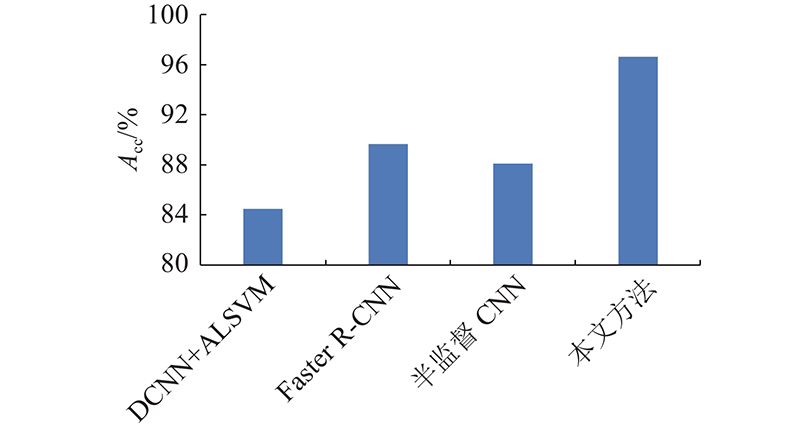
4. 结 语
本文使用EfficientNet对车型进行特征提取,在网络特征提取后增加带有残差结构的双通道注意力机制,关注了图像的通道特征和空间特征,保证模型不易产生梯度消失. 提出在网络最后的全连接层处增加softmax分类器,使用标签平滑正则化的方式处理损失函数,提高网络的容错性,减少模型的过拟合. 实验表明,本文方法较原始EfficientNet在车型分类准确率上有明显的提升,其中Microbus提升2.6%,SUV提升1.8%,Truck提升2.4%,且优于现有的DCNN、Faster-CNN的改进算法,表明本文方法具有一定的实用价值.
参考文献
基于卷积神经网络的交通场景语义分割方法研究
[J].DOI:10.11959/j.issn.1000-436x.2018053 [本文引用: 1]
Research on semantic segmentation method of traffic scene based on convolutional neural network
[J].DOI:10.11959/j.issn.1000-436x.2018053 [本文引用: 1]
ImageNet classification with deep convolutional neural networks
[J].
Vehicle type classification using a semisupervised convolutional neural network
[J].DOI:10.1109/TITS.2015.2402438 [本文引用: 1]
基于深度卷积神经网络的车型识别方法
[J].
Vehicle recognition method based on deep convolution neural network
[J].
基于深度卷积神经网络的目标检测研究综述
[J].
A review of target detection based on deep convolution neural network
[J].
基于多尺度特征融合的遥感图像场景分类
[J].DOI:10.3788/OPE.20182612.3099 [本文引用: 1]
Remote sensing image scene classification based on multi-scale feature fusion
[J].DOI:10.3788/OPE.20182612.3099 [本文引用: 1]
基于DCNN特征与集成学习的车型分类算法
[J].
Vehicle classification algorithm based on DCNN feature and ensemble learning
[J].
EfficientNet: rethinking model scaling for convolutional neural networks
[J].
EfficientNet在阴虚证眼象识别中的应用研究
[J].
Application of EfficientNet in eye image recognition of yin deficiency syndrome
[J].
基于轻量级网络的实时人脸识别算法研究
[J].DOI:10.3778/j.issn.1673-9418.1907037 [本文引用: 1]
Research on real-time face recognition algorithm based on lightweight network
[J].DOI:10.3778/j.issn.1673-9418.1907037 [本文引用: 1]
Neural architecture search with reinforcement learning
[J].
基于Swish激活函数的双通道CNN结构
[J].DOI:10.3969/j.issn.1672-9722.2020.06.028 [本文引用: 1]
Dual channel CNN architecture based on Swish activation function
[J].DOI:10.3969/j.issn.1672-9722.2020.06.028 [本文引用: 1]
数据智能: 趋势与挑战
[J].DOI:10.12011/1000-6788-2020-0027-34 [本文引用: 1]
Data intelligence: trends and challenges
[J].DOI:10.12011/1000-6788-2020-0027-34 [本文引用: 1]
图像分类卷积神经网络的反馈损失计算方法改进
[J].DOI:10.3969/j.issn.1000-1220.2019.07.032 [本文引用: 1]
Improvement of feedback loss calculation method of image classification convolution neural network
[J].DOI:10.3969/j.issn.1000-1220.2019.07.032 [本文引用: 1]
基于独热编码和卷积神经网络的异常检测
[J].
Anomaly detection based on independent heat coding and convolutional neural network
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}