[1]
沈宗礼, 余建波 基于迁移学习与深度森林的晶圆图缺陷识别
[J]. 浙江大学学报: 工学版 , 2020 , 54 (6 ): 1228 - 1239
[本文引用: 1]
SHEN Zong-li, YU Jian-bo Wafer map defect recognition based on transfer learning and deep forest
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (6 ): 1228 - 1239
[本文引用: 1]
[2]
LONG M, CAO Y, WANG J, et al. Learning transferable features with deep adaptation networks [C]// International Conference on Machine Learning . Lille: [s. n.], 2015: 97-105.
[本文引用: 7]
[3]
TZENG E, HOFFMAN J, SAENKO K, et al. Adversarial discriminative domain adaptation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 7167–7176.
[本文引用: 2]
[4]
GANIN Y, LEMPITSKY V. Unsupervised domain adaptation by backpropagation [C]// International Conference on Machine Learning . Lille: PMLR, 2015: 1180–1189.
[本文引用: 3]
[5]
LONG M, ZHU H, WANG J, et al. Deep transfer learning with joint adaptation networks[C]// International Conference on Machine Learning . Sydney: PMLR, 2017: 2208–2217.
[本文引用: 2]
[6]
SAITO K, WATANABE K, USHIKU Y, et al. Maximum classifier discrepancy for unsupervi-sed domain adaptation [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 3723–3732.
[本文引用: 3]
[7]
XU R, CHEN Z, ZUO W, et al. Deep cockt-ail network: multi-source unsupervised domain adaptation with category shift [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 3964–3973.
[本文引用: 6]
[8]
ZHAO H, ZHANG S, WU G. Adversarial multiple source domain adaptation [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems . Montreal: MIT Press, 2018: 8568–8579.
[本文引用: 2]
[9]
李威, 王蒙. 基于渐进多源域迁移的无监督跨域目标检测[EB/OL]. (2020-03-20). http://kns.cnki.net/kcms/detail/11.2109.TP.20200320.1044.003.html.
[本文引用: 1]
LI Wei, WANG Meng. Unsupervised cross-domain object detection based on progressive multi-source transfer [EB/OL]. (2020-03-20). http://kns.cnki.net/kcms/detail/11.2109.TP.20200320.1044.003.html.
[本文引用: 1]
[10]
PENG X, BAI Q, XIA X, et al. Moment matching for multi-source domain adaptation [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 1406–1415.
[本文引用: 9]
[11]
ZHAO S, WANG G, ZHANG S, et al. Multi-source distilling domain adaptation [C]// Proceedings of the AAAI Conference on Artificial Intelligence . New York: AAAI, 2020: 1297–1298.
[本文引用: 2]
[12]
ZHU Y, ZHUANG F, WANG D. Aligning domain specific distribution and classifier for cross-domain classification from multiple sources [C]// Proceedings of the AAAI Conference on Artificial Intelligence . Hawaii: AAAI, 2019: 5989–5996.
[本文引用: 1]
[13]
PENG X, HUANG Z, ZHU Y, et al. Federatedadversarial domain adaptation [C]// International Conference on Learning Representations . Addis Ababa: [s. n.], 2020.
[本文引用: 3]
[14]
ZHANG R, ISOLA P, ALEXEI A. Colorful image colorization [C]// European Conference on Computer Vision . Cham: Springer, 2016: 649–666.
[本文引用: 1]
[15]
GUSTAV L A, MICHAEL M, GREG O, et al. Learning representations for automatic colorization [C]// European Conference on Computer Vision . Amsterdam: [s. n.], 2016: 577–593.
[16]
CARL V, ABHINAV S, ALIREZA F, et al. Tracking emerges by colorizing videos [C]// Proceedings of the European Conference on Computer Vision . Munich: [s. n.], 2018: 391–408.
[本文引用: 1]
[17]
NOROOZI M, FAVARO P. Unsupervised learning of visual representations by solving jigsaw puzzles [C]// European Conference on Computer Vision . Amsterdam: [s. n.], 2016: 69–84.
[本文引用: 1]
[18]
CARL D, ABHINAV G, ALEXEI A. Unsupervised visual representation learning by conte-xt prediction [C]// Proceedings of the IEEE International Conference on Computer Vision . [S. l.]: IEEE, 2015: 1422–1430.
[本文引用: 1]
[19]
IMON J, PAOLO F. Self-supervised feature learning by learning to spot artifacts [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 2733–2742.
[本文引用: 1]
[20]
SPYROS G, PRAVEER S, NIKOS K. Unsupervised representation learning by predicting image rotations [EB/OL].(2018-03-21). https://doi.org/10.48550/arXiv.1803.07728.
[本文引用: 1]
[21]
DEEPAK P, PHILIPP K, JEFF D, et al. Context encoders: feature learning by inpainting [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas: IEEE, 2016: 2536–2544.
[本文引用: 1]
[22]
MISRA I, MAATEN L. Self-supervised learning of pretext-invariant representations [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 6707–6717.
[本文引用: 1]
基于迁移学习与深度森林的晶圆图缺陷识别
1
2020
... 迁移学习可以用来改善机器学习领域中跨域任务上的模型性能[1 ] ,当目标域标签样本较少且质量不高时,可以使用包含大量标签数据的源域作为辅助信息去训练泛化能力较强的分类器. 迁移学习存在一大障碍——域间差异,域适应可以有效地缓解这一障碍. 域适应即缩小域间数据的分布差异,将源域分类器更好地推广到目标域,它可以应用在一维文本、二维图像、三维视频等方面. 大多数研究集中在二维图像领域(图像分类、目标检测、语义分割),因此本文所提出的方法重点围绕二维图像分类展开. 将域适应运用到图像分类时,按照源域个数,可以将域适应分为单源域适应和多源域适应. ...
基于迁移学习与深度森林的晶圆图缺陷识别
1
2020
... 迁移学习可以用来改善机器学习领域中跨域任务上的模型性能[1 ] ,当目标域标签样本较少且质量不高时,可以使用包含大量标签数据的源域作为辅助信息去训练泛化能力较强的分类器. 迁移学习存在一大障碍——域间差异,域适应可以有效地缓解这一障碍. 域适应即缩小域间数据的分布差异,将源域分类器更好地推广到目标域,它可以应用在一维文本、二维图像、三维视频等方面. 大多数研究集中在二维图像领域(图像分类、目标检测、语义分割),因此本文所提出的方法重点围绕二维图像分类展开. 将域适应运用到图像分类时,按照源域个数,可以将域适应分为单源域适应和多源域适应. ...
7
... 在单源无监督域适应中,通过学习源和目标的域不变特征,将含有标签信息的单个源域分类器推广到无标签信息的目标域. 在单源的图像分类中,现有的域适应方法[2 -6 ] 大多获得了不错的分类精度. 在现实场景下的图像分类中,找到唯一适合的源域进行迁移是困难的,通常需要访问多个源域. ...
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... [2 ]、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-31 data set
Tab.1 标准 方法 A /% AW-D AD-W DW-A 平均值 单源迁移 DAN[2 ] 99.0 96.0 54.0 83.0 单源迁移 ADDA[3 ] 99.4 95.3 54.6 83.1 单源迁移 RevGrad[4 ] 99.2 96.4 53.4 83.0 源域组合 DAN[2 ] 98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4
在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
... [
2 ]
98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4 在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
... Comparison and analysis of accuracy on Office-Caltech10 data set
Tab.2 标准 方法 A /% ADC-W ACW-D AWD-C DWC-A 平均值 源域组合 Source only 99.0 98.3 87.8 86.1 92.8 源域组合 DAN[2 ] 99.3 98.2 89.7 94.8 95.5 多源迁移 Source only 99.1 98.2 85.4 88.7 92.9 多源迁移 FADA[13 ] 88.1 87.1 88.7 84.2 87.1 多源迁移 DAN[2 ] 99.5 99.1 89.2 91.6 94.9 多源迁移 DCTN[7 ] 99.4 99.0 90.2 92.7 95.3 多源迁移 M3 SDA[10 ] 99.4 99.2 91.5 94.1 96.1 多源迁移 本文方法 99.5 99.2 90.2 93.3 95.5
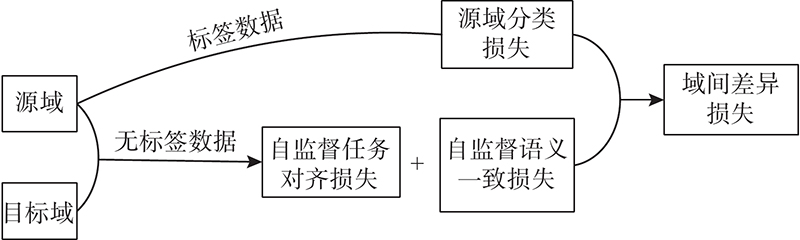
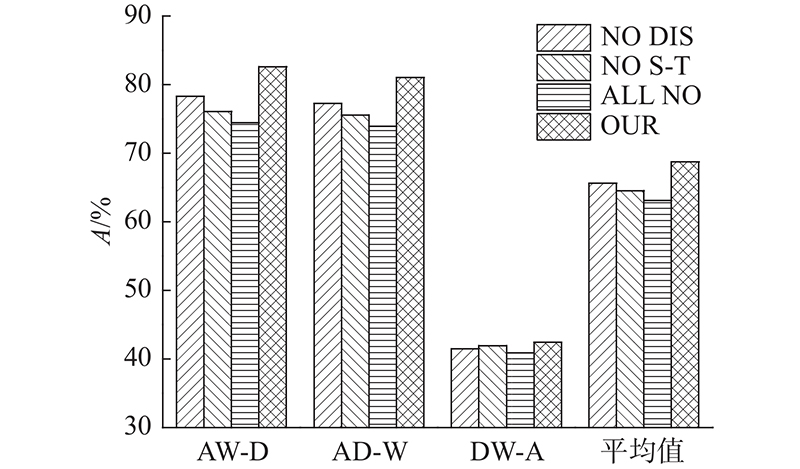
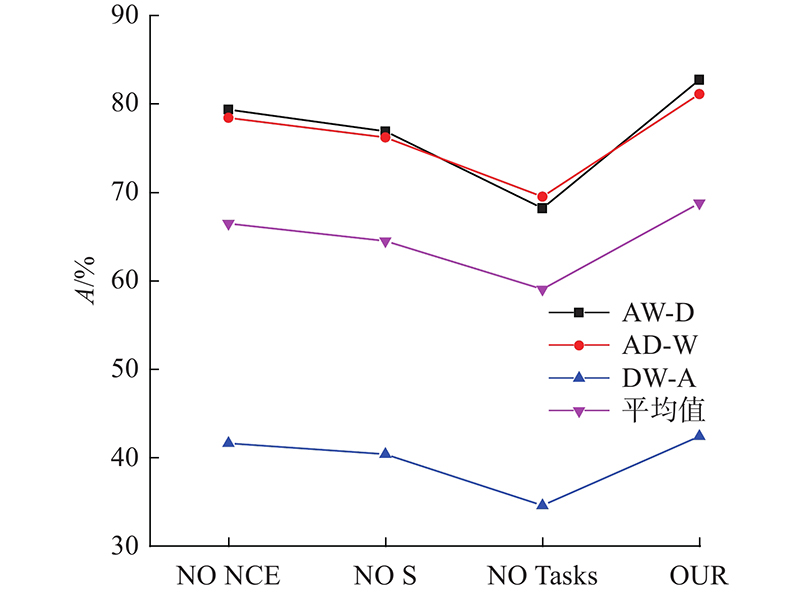
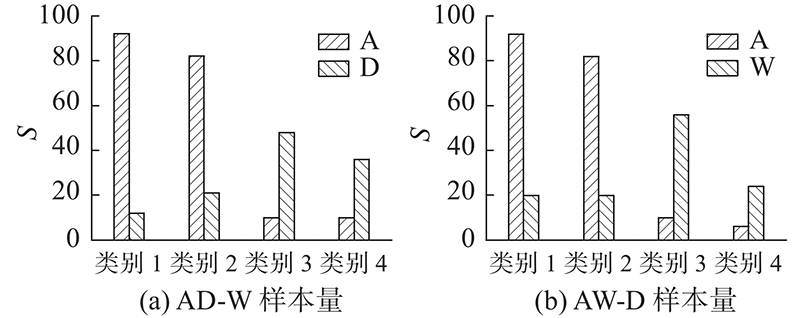
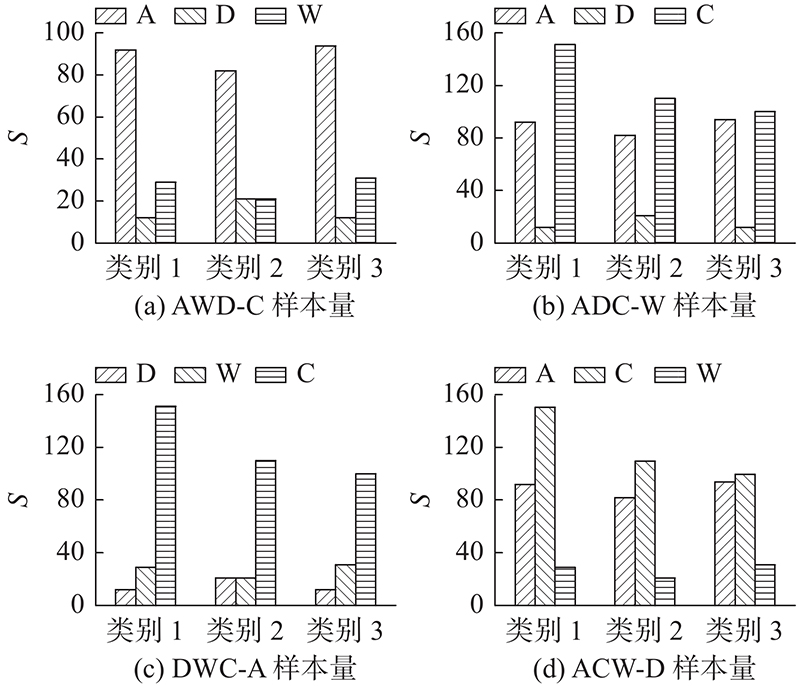
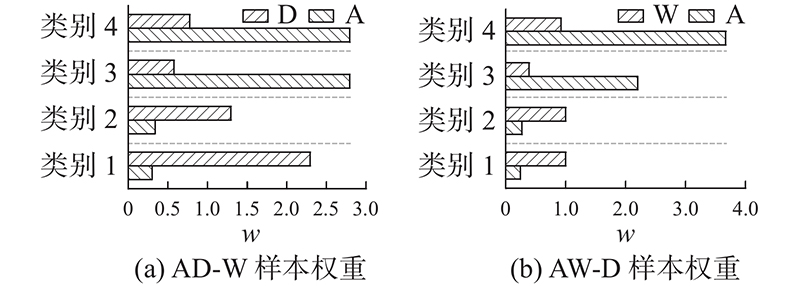
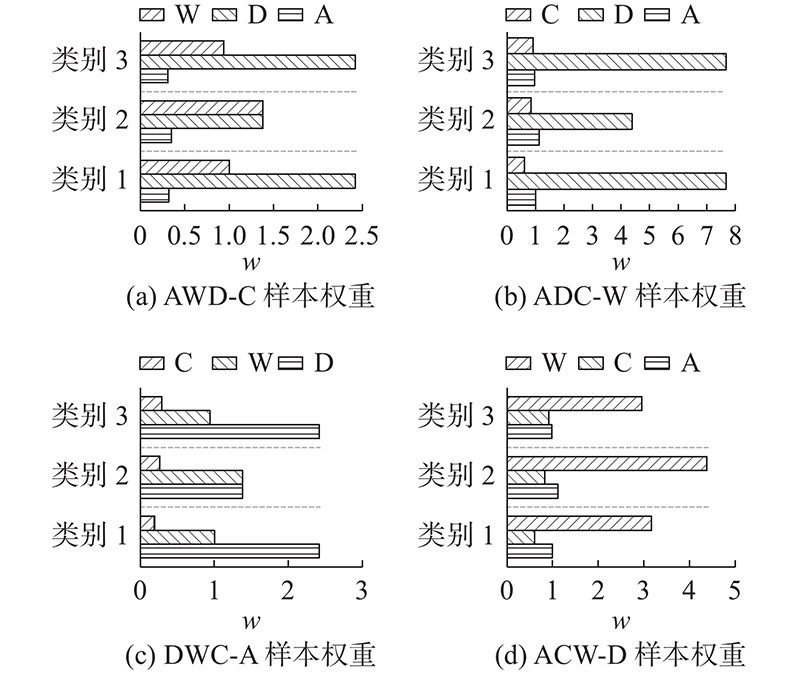
3.2.2. 各部分损失函数对分类性能影响分析 在Office-31和Office-Caltech10 2种数据集中,通过组合算法中不同部分的损失函数对模型进行优化,对比所得的分类精度,分析各部分损失函数对模型性能的影响,实验结果如图7 、8 所示. 图中,NO DIS表示模型中含有源域分类损失和自监督任务损失,NO S-T表示模型中含有源域分类损失和域间差异损失,ALL NO表示模型中仅含有源域分类损失,OUR表示模型中包含所有的损失函数. 从图7 、8 可以看出,当自监督任务损失与域间差异损失均不存在时,模型的迁移性能最差. 例如在AW-D这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了4.4%,比无自监督任务对齐损失时高6.6%,比两者损失均无时高8.2%. 在DWC-A这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了5.4%,比无自监督任务对齐损失时高6.4%,比两者损失均无时高7.5%. 自监督任务损失包含自监督任务对齐损失和自监督任务语义一致损失,无标签信息的源域和目标域样本通过自监督任务对齐损失对源域和目标域的对齐进行优化,自监督语义一致损失是对自监督任务本身进行优化,保证样本前、后语义的一致性. 域间差异损失优化了源域间公共类别的分类差异,提高了分类精度. 当缺少自监督任务损失和域间差异损失时,模型直接将源域分类器推广到目标域,没有对域间的对齐及分类器间的对齐进行优化,导致分类精度过低. 缺少自监督任务损失时的迁移性能相对低于缺少域间差异损失时的性能,表明自监督任务损失有效优化了域间特征的对齐效果,特征分布的差异减小. 图7 、8 中本文算法的精度最高,表明各部分损失函数的有效性,自监督任务损失和域间差异损失对模型具有良好的优化效果,不仅缩减了域间数据分布的差异,而且减少了源域决策边界的分类差异,提高了模型的迁移性能. ...
... [
2 ]
99.5 99.1 89.2 91.6 94.9 多源迁移 DCTN[7 ] 99.4 99.0 90.2 92.7 95.3 多源迁移 M3 SDA[10 ] 99.4 99.2 91.5 94.1 96.1 多源迁移 本文方法 99.5 99.2 90.2 93.3 95.5 3.2.2. 各部分损失函数对分类性能影响分析 在Office-31和Office-Caltech10 2种数据集中,通过组合算法中不同部分的损失函数对模型进行优化,对比所得的分类精度,分析各部分损失函数对模型性能的影响,实验结果如图7 、8 所示. 图中,NO DIS表示模型中含有源域分类损失和自监督任务损失,NO S-T表示模型中含有源域分类损失和域间差异损失,ALL NO表示模型中仅含有源域分类损失,OUR表示模型中包含所有的损失函数. 从图7 、8 可以看出,当自监督任务损失与域间差异损失均不存在时,模型的迁移性能最差. 例如在AW-D这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了4.4%,比无自监督任务对齐损失时高6.6%,比两者损失均无时高8.2%. 在DWC-A这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了5.4%,比无自监督任务对齐损失时高6.4%,比两者损失均无时高7.5%. 自监督任务损失包含自监督任务对齐损失和自监督任务语义一致损失,无标签信息的源域和目标域样本通过自监督任务对齐损失对源域和目标域的对齐进行优化,自监督语义一致损失是对自监督任务本身进行优化,保证样本前、后语义的一致性. 域间差异损失优化了源域间公共类别的分类差异,提高了分类精度. 当缺少自监督任务损失和域间差异损失时,模型直接将源域分类器推广到目标域,没有对域间的对齐及分类器间的对齐进行优化,导致分类精度过低. 缺少自监督任务损失时的迁移性能相对低于缺少域间差异损失时的性能,表明自监督任务损失有效优化了域间特征的对齐效果,特征分布的差异减小. 图7 、8 中本文算法的精度最高,表明各部分损失函数的有效性,自监督任务损失和域间差异损失对模型具有良好的优化效果,不仅缩减了域间数据分布的差异,而且减少了源域决策边界的分类差异,提高了模型的迁移性能. ...
2
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-31 data set
Tab.1 标准 方法 A /% AW-D AD-W DW-A 平均值 单源迁移 DAN[2 ] 99.0 96.0 54.0 83.0 单源迁移 ADDA[3 ] 99.4 95.3 54.6 83.1 单源迁移 RevGrad[4 ] 99.2 96.4 53.4 83.0 源域组合 DAN[2 ] 98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4
在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
3
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-31 data set
Tab.1 标准 方法 A /% AW-D AD-W DW-A 平均值 单源迁移 DAN[2 ] 99.0 96.0 54.0 83.0 单源迁移 ADDA[3 ] 99.4 95.3 54.6 83.1 单源迁移 RevGrad[4 ] 99.2 96.4 53.4 83.0 源域组合 DAN[2 ] 98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4
在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
... [
4 ]
98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4 在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
2
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-31 data set
Tab.1 标准 方法 A /% AW-D AD-W DW-A 平均值 单源迁移 DAN[2 ] 99.0 96.0 54.0 83.0 单源迁移 ADDA[3 ] 99.4 95.3 54.6 83.1 单源迁移 RevGrad[4 ] 99.2 96.4 53.4 83.0 源域组合 DAN[2 ] 98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4
在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
3
... 在单源无监督域适应中,通过学习源和目标的域不变特征,将含有标签信息的单个源域分类器推广到无标签信息的目标域. 在单源的图像分类中,现有的域适应方法[2 -6 ] 大多获得了不错的分类精度. 在现实场景下的图像分类中,找到唯一适合的源域进行迁移是困难的,通常需要访问多个源域. ...
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-31 data set
Tab.1 标准 方法 A /% AW-D AD-W DW-A 平均值 单源迁移 DAN[2 ] 99.0 96.0 54.0 83.0 单源迁移 ADDA[3 ] 99.4 95.3 54.6 83.1 单源迁移 RevGrad[4 ] 99.2 96.4 53.4 83.0 源域组合 DAN[2 ] 98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4
在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
6
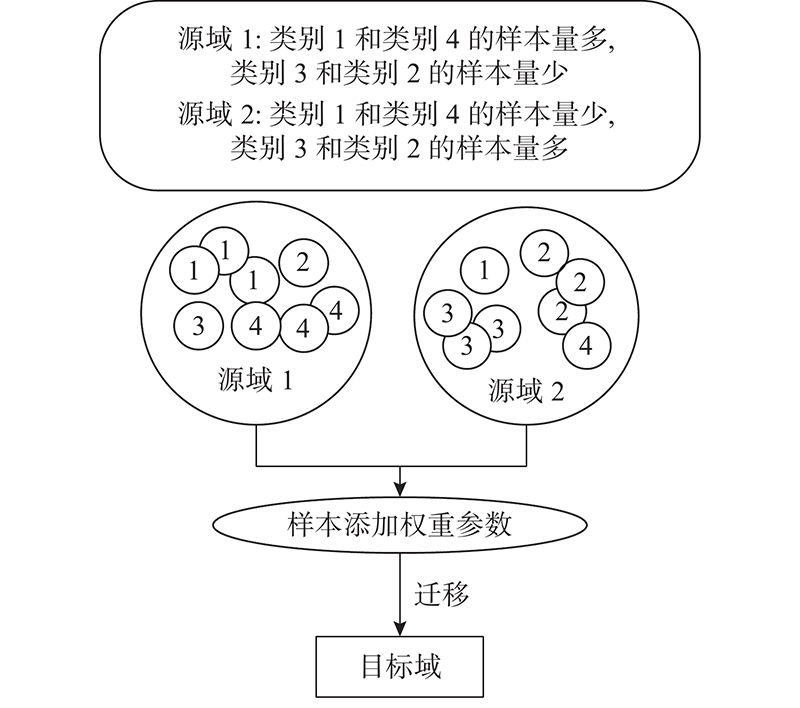
... 多源无监督域适应指通过学习多个源域的标签知识,得到关于目标域的标签信息. 目前,多数方法是将对抗思想引入多源图像分类中[7 -9 ] ,有效地减少域间差异,提高分类精度. Xu等[7 ] 提出深度网络,对抗多个源域之间的领域和类别迁移. Peng等[10 ] 通过对齐每对源域和目标域,实现目标域中图像的分类[10 -12 ] . Peng等[10 ] 旨在通过动态调整特征分布矩,将从多个源域学习到的图像特征的标签迁移到未标记目标域. 最新的思想是结合联邦学习与域自适应,解决图像处理问题. Peng等[13 ] 提出联邦域自适应方法,它旨在将不同源节点学习到的特征表示与目标节点的特征表示对齐. 尽管上述方法都在多源图像分类场景下取得了不菲的成果, 但是他们忽略了对无标签样本进行有效的学习,这可能会错过有关图像分类特征的重要信息. 此外, 他们没有对多源下类别不均衡的情况进行有效的分析. ...
... [7 ]提出深度网络,对抗多个源域之间的领域和类别迁移. Peng等[10 ] 通过对齐每对源域和目标域,实现目标域中图像的分类[10 -12 ] . Peng等[10 ] 旨在通过动态调整特征分布矩,将从多个源域学习到的图像特征的标签迁移到未标记目标域. 最新的思想是结合联邦学习与域自适应,解决图像处理问题. Peng等[13 ] 提出联邦域自适应方法,它旨在将不同源节点学习到的特征表示与目标节点的特征表示对齐. 尽管上述方法都在多源图像分类场景下取得了不菲的成果, 但是他们忽略了对无标签样本进行有效的学习,这可能会错过有关图像分类特征的重要信息. 此外, 他们没有对多源下类别不均衡的情况进行有效的分析. ...
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... [7 ]、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-31 data set
Tab.1 标准 方法 A /% AW-D AD-W DW-A 平均值 单源迁移 DAN[2 ] 99.0 96.0 54.0 83.0 单源迁移 ADDA[3 ] 99.4 95.3 54.6 83.1 单源迁移 RevGrad[4 ] 99.2 96.4 53.4 83.0 源域组合 DAN[2 ] 98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4
在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
... Comparison and analysis of accuracy on Office-Caltech10 data set
Tab.2 标准 方法 A /% ADC-W ACW-D AWD-C DWC-A 平均值 源域组合 Source only 99.0 98.3 87.8 86.1 92.8 源域组合 DAN[2 ] 99.3 98.2 89.7 94.8 95.5 多源迁移 Source only 99.1 98.2 85.4 88.7 92.9 多源迁移 FADA[13 ] 88.1 87.1 88.7 84.2 87.1 多源迁移 DAN[2 ] 99.5 99.1 89.2 91.6 94.9 多源迁移 DCTN[7 ] 99.4 99.0 90.2 92.7 95.3 多源迁移 M3 SDA[10 ] 99.4 99.2 91.5 94.1 96.1 多源迁移 本文方法 99.5 99.2 90.2 93.3 95.5
3.2.2. 各部分损失函数对分类性能影响分析 在Office-31和Office-Caltech10 2种数据集中,通过组合算法中不同部分的损失函数对模型进行优化,对比所得的分类精度,分析各部分损失函数对模型性能的影响,实验结果如图7 、8 所示. 图中,NO DIS表示模型中含有源域分类损失和自监督任务损失,NO S-T表示模型中含有源域分类损失和域间差异损失,ALL NO表示模型中仅含有源域分类损失,OUR表示模型中包含所有的损失函数. 从图7 、8 可以看出,当自监督任务损失与域间差异损失均不存在时,模型的迁移性能最差. 例如在AW-D这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了4.4%,比无自监督任务对齐损失时高6.6%,比两者损失均无时高8.2%. 在DWC-A这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了5.4%,比无自监督任务对齐损失时高6.4%,比两者损失均无时高7.5%. 自监督任务损失包含自监督任务对齐损失和自监督任务语义一致损失,无标签信息的源域和目标域样本通过自监督任务对齐损失对源域和目标域的对齐进行优化,自监督语义一致损失是对自监督任务本身进行优化,保证样本前、后语义的一致性. 域间差异损失优化了源域间公共类别的分类差异,提高了分类精度. 当缺少自监督任务损失和域间差异损失时,模型直接将源域分类器推广到目标域,没有对域间的对齐及分类器间的对齐进行优化,导致分类精度过低. 缺少自监督任务损失时的迁移性能相对低于缺少域间差异损失时的性能,表明自监督任务损失有效优化了域间特征的对齐效果,特征分布的差异减小. 图7 、8 中本文算法的精度最高,表明各部分损失函数的有效性,自监督任务损失和域间差异损失对模型具有良好的优化效果,不仅缩减了域间数据分布的差异,而且减少了源域决策边界的分类差异,提高了模型的迁移性能. ...
2
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-31 data set
Tab.1 标准 方法 A /% AW-D AD-W DW-A 平均值 单源迁移 DAN[2 ] 99.0 96.0 54.0 83.0 单源迁移 ADDA[3 ] 99.4 95.3 54.6 83.1 单源迁移 RevGrad[4 ] 99.2 96.4 53.4 83.0 源域组合 DAN[2 ] 98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4
在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
1
... 多源无监督域适应指通过学习多个源域的标签知识,得到关于目标域的标签信息. 目前,多数方法是将对抗思想引入多源图像分类中[7 -9 ] ,有效地减少域间差异,提高分类精度. Xu等[7 ] 提出深度网络,对抗多个源域之间的领域和类别迁移. Peng等[10 ] 通过对齐每对源域和目标域,实现目标域中图像的分类[10 -12 ] . Peng等[10 ] 旨在通过动态调整特征分布矩,将从多个源域学习到的图像特征的标签迁移到未标记目标域. 最新的思想是结合联邦学习与域自适应,解决图像处理问题. Peng等[13 ] 提出联邦域自适应方法,它旨在将不同源节点学习到的特征表示与目标节点的特征表示对齐. 尽管上述方法都在多源图像分类场景下取得了不菲的成果, 但是他们忽略了对无标签样本进行有效的学习,这可能会错过有关图像分类特征的重要信息. 此外, 他们没有对多源下类别不均衡的情况进行有效的分析. ...
1
... 多源无监督域适应指通过学习多个源域的标签知识,得到关于目标域的标签信息. 目前,多数方法是将对抗思想引入多源图像分类中[7 -9 ] ,有效地减少域间差异,提高分类精度. Xu等[7 ] 提出深度网络,对抗多个源域之间的领域和类别迁移. Peng等[10 ] 通过对齐每对源域和目标域,实现目标域中图像的分类[10 -12 ] . Peng等[10 ] 旨在通过动态调整特征分布矩,将从多个源域学习到的图像特征的标签迁移到未标记目标域. 最新的思想是结合联邦学习与域自适应,解决图像处理问题. Peng等[13 ] 提出联邦域自适应方法,它旨在将不同源节点学习到的特征表示与目标节点的特征表示对齐. 尽管上述方法都在多源图像分类场景下取得了不菲的成果, 但是他们忽略了对无标签样本进行有效的学习,这可能会错过有关图像分类特征的重要信息. 此外, 他们没有对多源下类别不均衡的情况进行有效的分析. ...
9
... 多源无监督域适应指通过学习多个源域的标签知识,得到关于目标域的标签信息. 目前,多数方法是将对抗思想引入多源图像分类中[7 -9 ] ,有效地减少域间差异,提高分类精度. Xu等[7 ] 提出深度网络,对抗多个源域之间的领域和类别迁移. Peng等[10 ] 通过对齐每对源域和目标域,实现目标域中图像的分类[10 -12 ] . Peng等[10 ] 旨在通过动态调整特征分布矩,将从多个源域学习到的图像特征的标签迁移到未标记目标域. 最新的思想是结合联邦学习与域自适应,解决图像处理问题. Peng等[13 ] 提出联邦域自适应方法,它旨在将不同源节点学习到的特征表示与目标节点的特征表示对齐. 尽管上述方法都在多源图像分类场景下取得了不菲的成果, 但是他们忽略了对无标签样本进行有效的学习,这可能会错过有关图像分类特征的重要信息. 此外, 他们没有对多源下类别不均衡的情况进行有效的分析. ...
... [10 -12 ]. Peng等[10 ] 旨在通过动态调整特征分布矩,将从多个源域学习到的图像特征的标签迁移到未标记目标域. 最新的思想是结合联邦学习与域自适应,解决图像处理问题. Peng等[13 ] 提出联邦域自适应方法,它旨在将不同源节点学习到的特征表示与目标节点的特征表示对齐. 尽管上述方法都在多源图像分类场景下取得了不菲的成果, 但是他们忽略了对无标签样本进行有效的学习,这可能会错过有关图像分类特征的重要信息. 此外, 他们没有对多源下类别不均衡的情况进行有效的分析. ...
... [10 ]旨在通过动态调整特征分布矩,将从多个源域学习到的图像特征的标签迁移到未标记目标域. 最新的思想是结合联邦学习与域自适应,解决图像处理问题. Peng等[13 ] 提出联邦域自适应方法,它旨在将不同源节点学习到的特征表示与目标节点的特征表示对齐. 尽管上述方法都在多源图像分类场景下取得了不菲的成果, 但是他们忽略了对无标签样本进行有效的学习,这可能会错过有关图像分类特征的重要信息. 此外, 他们没有对多源下类别不均衡的情况进行有效的分析. ...
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... [10 ]等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-31 data set
Tab.1 标准 方法 A /% AW-D AD-W DW-A 平均值 单源迁移 DAN[2 ] 99.0 96.0 54.0 83.0 单源迁移 ADDA[3 ] 99.4 95.3 54.6 83.1 单源迁移 RevGrad[4 ] 99.2 96.4 53.4 83.0 源域组合 DAN[2 ] 98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4
在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
... 在Office-Caltech10数据集中,W域、D域的样本量较少,A域、C域的样本量较多,样本量较多的域向样本量较少的域迁移时的准确率相对较高,故各个域向A域、C域迁移时的精度较低. 后2组任务中本文的分类精度相对低于M3 SDA[10 ] ,2种算法均是基于ResNet实现,但M3 SDA[10 ] 使用的是ImageNet 预训练开发后的模型,即自然场景中的对象识别,优势在于拥有大量的预训练数据,故准确率相对较高. 在相同样本量的情况下,本文方法的分类精度比所有的主流方法高,表明本文的模型不仅能够提取到更高级的语义知识,促进域间对齐,而且利用域间差异损失减少了各源域间决策边界的分类差异,提高了分类器的泛化能力,取得了较好的分类结果. ...
... [10 ]使用的是ImageNet 预训练开发后的模型,即自然场景中的对象识别,优势在于拥有大量的预训练数据,故准确率相对较高. 在相同样本量的情况下,本文方法的分类精度比所有的主流方法高,表明本文的模型不仅能够提取到更高级的语义知识,促进域间对齐,而且利用域间差异损失减少了各源域间决策边界的分类差异,提高了分类器的泛化能力,取得了较好的分类结果. ...
... Comparison and analysis of accuracy on Office-Caltech10 data set
Tab.2 标准 方法 A /% ADC-W ACW-D AWD-C DWC-A 平均值 源域组合 Source only 99.0 98.3 87.8 86.1 92.8 源域组合 DAN[2 ] 99.3 98.2 89.7 94.8 95.5 多源迁移 Source only 99.1 98.2 85.4 88.7 92.9 多源迁移 FADA[13 ] 88.1 87.1 88.7 84.2 87.1 多源迁移 DAN[2 ] 99.5 99.1 89.2 91.6 94.9 多源迁移 DCTN[7 ] 99.4 99.0 90.2 92.7 95.3 多源迁移 M3 SDA[10 ] 99.4 99.2 91.5 94.1 96.1 多源迁移 本文方法 99.5 99.2 90.2 93.3 95.5
3.2.2. 各部分损失函数对分类性能影响分析 在Office-31和Office-Caltech10 2种数据集中,通过组合算法中不同部分的损失函数对模型进行优化,对比所得的分类精度,分析各部分损失函数对模型性能的影响,实验结果如图7 、8 所示. 图中,NO DIS表示模型中含有源域分类损失和自监督任务损失,NO S-T表示模型中含有源域分类损失和域间差异损失,ALL NO表示模型中仅含有源域分类损失,OUR表示模型中包含所有的损失函数. 从图7 、8 可以看出,当自监督任务损失与域间差异损失均不存在时,模型的迁移性能最差. 例如在AW-D这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了4.4%,比无自监督任务对齐损失时高6.6%,比两者损失均无时高8.2%. 在DWC-A这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了5.4%,比无自监督任务对齐损失时高6.4%,比两者损失均无时高7.5%. 自监督任务损失包含自监督任务对齐损失和自监督任务语义一致损失,无标签信息的源域和目标域样本通过自监督任务对齐损失对源域和目标域的对齐进行优化,自监督语义一致损失是对自监督任务本身进行优化,保证样本前、后语义的一致性. 域间差异损失优化了源域间公共类别的分类差异,提高了分类精度. 当缺少自监督任务损失和域间差异损失时,模型直接将源域分类器推广到目标域,没有对域间的对齐及分类器间的对齐进行优化,导致分类精度过低. 缺少自监督任务损失时的迁移性能相对低于缺少域间差异损失时的性能,表明自监督任务损失有效优化了域间特征的对齐效果,特征分布的差异减小. 图7 、8 中本文算法的精度最高,表明各部分损失函数的有效性,自监督任务损失和域间差异损失对模型具有良好的优化效果,不仅缩减了域间数据分布的差异,而且减少了源域决策边界的分类差异,提高了模型的迁移性能. ...
2
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-31 data set
Tab.1 标准 方法 A /% AW-D AD-W DW-A 平均值 单源迁移 DAN[2 ] 99.0 96.0 54.0 83.0 单源迁移 ADDA[3 ] 99.4 95.3 54.6 83.1 单源迁移 RevGrad[4 ] 99.2 96.4 53.4 83.0 源域组合 DAN[2 ] 98.8 96.2 54.9 83.3 源域组合 JAN[5 ] 99.4 95.9 54.6 83.3 源域组合 MCD[6 ] 99.5 96.2 54.4 83.4 源域组合 RevGrad[4 ] 98.8 96.2 54.6 83.2 多源迁移 DCTN[7 ] 99.6 96.9 54.9 83.8 多源迁移 M3 SDA[10 ] 99.4 96.2 55.4 83.7 多源迁移 MDAN[8 ] 99.2 95.4 55.2 83.3 多源迁移 MDDA[11 ] 99.2 97.1 56.2 84.2 多源迁移 本文方法 99.6 97.2 56.4 84.4
在Office-31数据集中,W域与D域有较大的相似性,但它们与A域的差异性较大,因此前2组任务精度较高,第3组任务的分类性能较差. 本文方法在3组任务中精度有所提高,表明在自监督任务训练中,模型所获得的特征具有更高级的语义信息,为下一步域间对齐提供了有效的辅助信息. ...
1
... 多源无监督域适应指通过学习多个源域的标签知识,得到关于目标域的标签信息. 目前,多数方法是将对抗思想引入多源图像分类中[7 -9 ] ,有效地减少域间差异,提高分类精度. Xu等[7 ] 提出深度网络,对抗多个源域之间的领域和类别迁移. Peng等[10 ] 通过对齐每对源域和目标域,实现目标域中图像的分类[10 -12 ] . Peng等[10 ] 旨在通过动态调整特征分布矩,将从多个源域学习到的图像特征的标签迁移到未标记目标域. 最新的思想是结合联邦学习与域自适应,解决图像处理问题. Peng等[13 ] 提出联邦域自适应方法,它旨在将不同源节点学习到的特征表示与目标节点的特征表示对齐. 尽管上述方法都在多源图像分类场景下取得了不菲的成果, 但是他们忽略了对无标签样本进行有效的学习,这可能会错过有关图像分类特征的重要信息. 此外, 他们没有对多源下类别不均衡的情况进行有效的分析. ...
3
... 多源无监督域适应指通过学习多个源域的标签知识,得到关于目标域的标签信息. 目前,多数方法是将对抗思想引入多源图像分类中[7 -9 ] ,有效地减少域间差异,提高分类精度. Xu等[7 ] 提出深度网络,对抗多个源域之间的领域和类别迁移. Peng等[10 ] 通过对齐每对源域和目标域,实现目标域中图像的分类[10 -12 ] . Peng等[10 ] 旨在通过动态调整特征分布矩,将从多个源域学习到的图像特征的标签迁移到未标记目标域. 最新的思想是结合联邦学习与域自适应,解决图像处理问题. Peng等[13 ] 提出联邦域自适应方法,它旨在将不同源节点学习到的特征表示与目标节点的特征表示对齐. 尽管上述方法都在多源图像分类场景下取得了不菲的成果, 但是他们忽略了对无标签样本进行有效的学习,这可能会错过有关图像分类特征的重要信息. 此外, 他们没有对多源下类别不均衡的情况进行有效的分析. ...
... 从3个部分对模型性能进行分析. 1)与现有的主流方法进行分类精度对比分析. 在Office-31数据集中,从单源迁移、多源组合和多源迁移3个标准下与DAN[2 ] 、ADDA[3 ] 、RevGard[4 ] 、JAN[5 ] 、MCD[6 ] 、DCTN[7 ] 、MDAN[8 ] 、MDDA[11 ] 和M3 SDA[10 ] 等方法进行比较. 在Office-Caltech10数据集中,从多源组合和多源迁移2个标准下与DAN[2 ] 、DCTN[7 ] 、FADA[13 ] 和M3 SDA[10 ] 等方法进行比较. 2)分析各部分损失函数对模型性能的影响. 为了对比差异更清晰,Office-31数据集取4个类别中的样本,Office-Caltech10数据集取3个类别中的样本,分别对域间差异损失、自监督任务训练、自监督任务损失及自监督任务语义一致损失重点分析. 3)在类别不均衡的条件下,保持2)中的样本类别个数,对每个类别中的样本量进行删改,对设置动态权重参数前、后的分类精度进行对比分析. ...
... Comparison and analysis of accuracy on Office-Caltech10 data set
Tab.2 标准 方法 A /% ADC-W ACW-D AWD-C DWC-A 平均值 源域组合 Source only 99.0 98.3 87.8 86.1 92.8 源域组合 DAN[2 ] 99.3 98.2 89.7 94.8 95.5 多源迁移 Source only 99.1 98.2 85.4 88.7 92.9 多源迁移 FADA[13 ] 88.1 87.1 88.7 84.2 87.1 多源迁移 DAN[2 ] 99.5 99.1 89.2 91.6 94.9 多源迁移 DCTN[7 ] 99.4 99.0 90.2 92.7 95.3 多源迁移 M3 SDA[10 ] 99.4 99.2 91.5 94.1 96.1 多源迁移 本文方法 99.5 99.2 90.2 93.3 95.5
3.2.2. 各部分损失函数对分类性能影响分析 在Office-31和Office-Caltech10 2种数据集中,通过组合算法中不同部分的损失函数对模型进行优化,对比所得的分类精度,分析各部分损失函数对模型性能的影响,实验结果如图7 、8 所示. 图中,NO DIS表示模型中含有源域分类损失和自监督任务损失,NO S-T表示模型中含有源域分类损失和域间差异损失,ALL NO表示模型中仅含有源域分类损失,OUR表示模型中包含所有的损失函数. 从图7 、8 可以看出,当自监督任务损失与域间差异损失均不存在时,模型的迁移性能最差. 例如在AW-D这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了4.4%,比无自监督任务对齐损失时高6.6%,比两者损失均无时高8.2%. 在DWC-A这一组任务中,当与无域间差异损失比较时,本文算法的精度提高了5.4%,比无自监督任务对齐损失时高6.4%,比两者损失均无时高7.5%. 自监督任务损失包含自监督任务对齐损失和自监督任务语义一致损失,无标签信息的源域和目标域样本通过自监督任务对齐损失对源域和目标域的对齐进行优化,自监督语义一致损失是对自监督任务本身进行优化,保证样本前、后语义的一致性. 域间差异损失优化了源域间公共类别的分类差异,提高了分类精度. 当缺少自监督任务损失和域间差异损失时,模型直接将源域分类器推广到目标域,没有对域间的对齐及分类器间的对齐进行优化,导致分类精度过低. 缺少自监督任务损失时的迁移性能相对低于缺少域间差异损失时的性能,表明自监督任务损失有效优化了域间特征的对齐效果,特征分布的差异减小. 图7 、8 中本文算法的精度最高,表明各部分损失函数的有效性,自监督任务损失和域间差异损失对模型具有良好的优化效果,不仅缩减了域间数据分布的差异,而且减少了源域决策边界的分类差异,提高了模型的迁移性能. ...
1
... 自监督学习主要是利用辅助任务从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,可以学习到更多的语义特征. 给灰度图像上色[14 -16 ] , 将图像分块并根据中心一块去预测位置[17 -18 ] ,提出对破坏的图像进行分类[19 ] 、图像旋转[20 ] 、图像修复[21 ] 等大量的辅助任务,不断应用于二维图像处理. 在现实场景中,大多数方法没有利用自监督任务去解决多源无监督的问题. 为了解决域间数据分布差异造成迁移性能较差的问题, 在无标签数据上同时进行多个自监督辅助任务. 为了保持模型的高效性和分类的准确率,选择较易实现和高性能的3个自监督任务. ...
1
... 自监督学习主要是利用辅助任务从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,可以学习到更多的语义特征. 给灰度图像上色[14 -16 ] , 将图像分块并根据中心一块去预测位置[17 -18 ] ,提出对破坏的图像进行分类[19 ] 、图像旋转[20 ] 、图像修复[21 ] 等大量的辅助任务,不断应用于二维图像处理. 在现实场景中,大多数方法没有利用自监督任务去解决多源无监督的问题. 为了解决域间数据分布差异造成迁移性能较差的问题, 在无标签数据上同时进行多个自监督辅助任务. 为了保持模型的高效性和分类的准确率,选择较易实现和高性能的3个自监督任务. ...
1
... 自监督学习主要是利用辅助任务从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,可以学习到更多的语义特征. 给灰度图像上色[14 -16 ] , 将图像分块并根据中心一块去预测位置[17 -18 ] ,提出对破坏的图像进行分类[19 ] 、图像旋转[20 ] 、图像修复[21 ] 等大量的辅助任务,不断应用于二维图像处理. 在现实场景中,大多数方法没有利用自监督任务去解决多源无监督的问题. 为了解决域间数据分布差异造成迁移性能较差的问题, 在无标签数据上同时进行多个自监督辅助任务. 为了保持模型的高效性和分类的准确率,选择较易实现和高性能的3个自监督任务. ...
1
... 自监督学习主要是利用辅助任务从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,可以学习到更多的语义特征. 给灰度图像上色[14 -16 ] , 将图像分块并根据中心一块去预测位置[17 -18 ] ,提出对破坏的图像进行分类[19 ] 、图像旋转[20 ] 、图像修复[21 ] 等大量的辅助任务,不断应用于二维图像处理. 在现实场景中,大多数方法没有利用自监督任务去解决多源无监督的问题. 为了解决域间数据分布差异造成迁移性能较差的问题, 在无标签数据上同时进行多个自监督辅助任务. 为了保持模型的高效性和分类的准确率,选择较易实现和高性能的3个自监督任务. ...
1
... 自监督学习主要是利用辅助任务从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,可以学习到更多的语义特征. 给灰度图像上色[14 -16 ] , 将图像分块并根据中心一块去预测位置[17 -18 ] ,提出对破坏的图像进行分类[19 ] 、图像旋转[20 ] 、图像修复[21 ] 等大量的辅助任务,不断应用于二维图像处理. 在现实场景中,大多数方法没有利用自监督任务去解决多源无监督的问题. 为了解决域间数据分布差异造成迁移性能较差的问题, 在无标签数据上同时进行多个自监督辅助任务. 为了保持模型的高效性和分类的准确率,选择较易实现和高性能的3个自监督任务. ...
1
... 自监督学习主要是利用辅助任务从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,可以学习到更多的语义特征. 给灰度图像上色[14 -16 ] , 将图像分块并根据中心一块去预测位置[17 -18 ] ,提出对破坏的图像进行分类[19 ] 、图像旋转[20 ] 、图像修复[21 ] 等大量的辅助任务,不断应用于二维图像处理. 在现实场景中,大多数方法没有利用自监督任务去解决多源无监督的问题. 为了解决域间数据分布差异造成迁移性能较差的问题, 在无标签数据上同时进行多个自监督辅助任务. 为了保持模型的高效性和分类的准确率,选择较易实现和高性能的3个自监督任务. ...
1
... 自监督学习主要是利用辅助任务从大规模的无监督数据中挖掘自身的监督信息,通过这种构造的监督信息对网络进行训练,可以学习到更多的语义特征. 给灰度图像上色[14 -16 ] , 将图像分块并根据中心一块去预测位置[17 -18 ] ,提出对破坏的图像进行分类[19 ] 、图像旋转[20 ] 、图像修复[21 ] 等大量的辅助任务,不断应用于二维图像处理. 在现实场景中,大多数方法没有利用自监督任务去解决多源无监督的问题. 为了解决域间数据分布差异造成迁移性能较差的问题, 在无标签数据上同时进行多个自监督辅助任务. 为了保持模型的高效性和分类的准确率,选择较易实现和高性能的3个自监督任务. ...
1
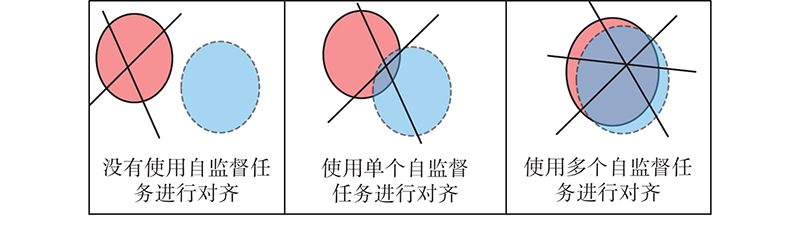
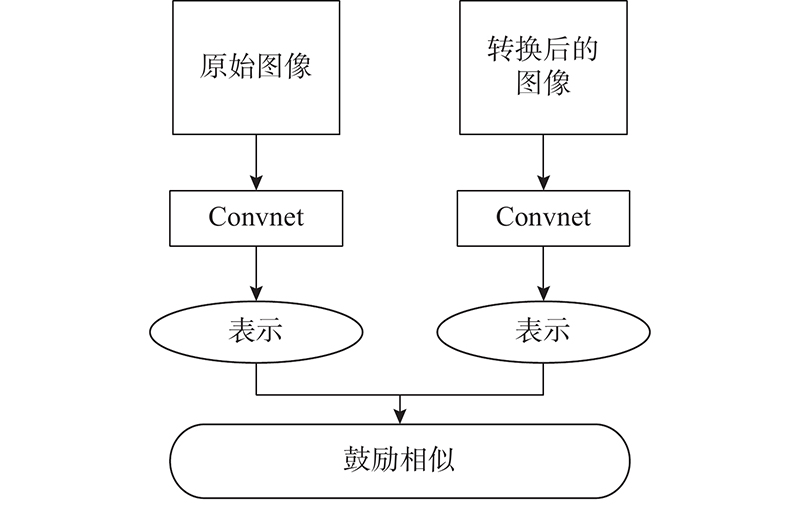
... 样本进行自监督任务训练的目的是无标签数据通过辅助任务学习有意义的图像语义信息. 这种信息应该是一致的, 但是许多辅助任务会导致原信息与转换后的信息不同. 为了鼓励转换前、后语义信息的一致性,保护相应的语义信息,受Misra等[22 ] 的启发,采用噪声对比估计作为语义一致损失,对自监督任务进行优化. 自监督任务语义一致原理如图3 所示. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}