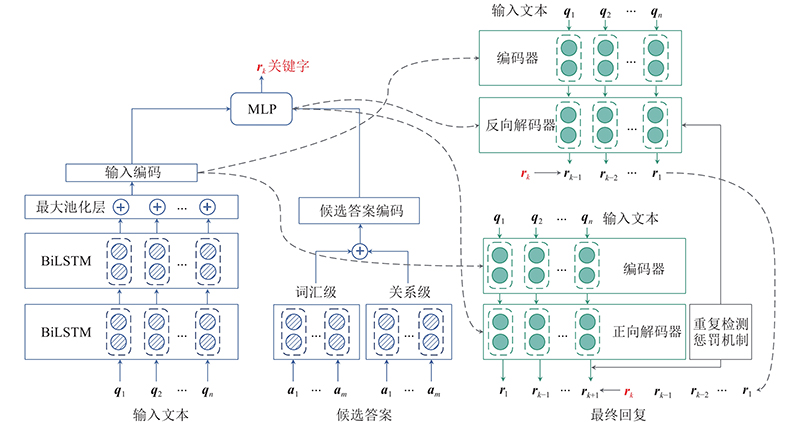
A dialogue generation model based on knowledge transfer and two-direction asynchronous sequence generation was proposed, aiming to the generally meaningless safe replies and the problem of a large number of repetitive words in view of the end-to-end dialogue generation models, and the challenge of introducing external knowledge into the dialogue system. The external knowledge in the knowledge base was fused into the dialogue generation model and explicitly generated in the reply sentences. A pre-trained model based on the question and answering of the knowledge base was used to obtain the knowledge expressions of the input sentences, the knowledge expressions of the candidate answers, and keywords. The keywords were then used in the reply. Two encoder-decoder structure models were proposed, and the keywords were generated explicitly in the dialogue reply by two-direction asynchronous generation. The knowledge expressions and understanding capabilities of the pre-trained model were introduced to capture knowledge information to dialog generation at the encoding and decoding stages. A repetitive detection-penalty mechanism was proposed to reduce the repeated words problem by giving weight to punish the repetitive words. Experimental results show that the model outperforms better than existing methods in both automatic evaluation and manual evaluation indicators.
Keywords:dialogue generation
;
knowledge entity
;
knowledge base question and answer
;
two-direction asynchronous generation
;
sequence-to-sequence model
WANG Yong-chao, CAO Yu, YANG Yu-hui, XU Duan-qing. Dialogue generation model based on knowledge transfer and two-direction asynchronous sequence. Journal of Zhejiang University(Engineering Science)[J], 2022, 56(3): 520-530 doi:10.3785/j.issn.1008-973X.2022.03.011
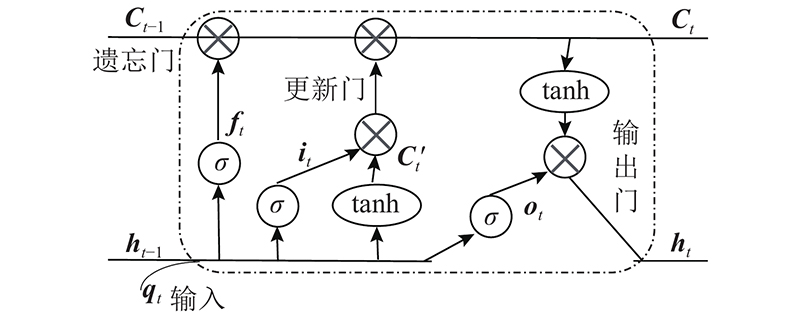
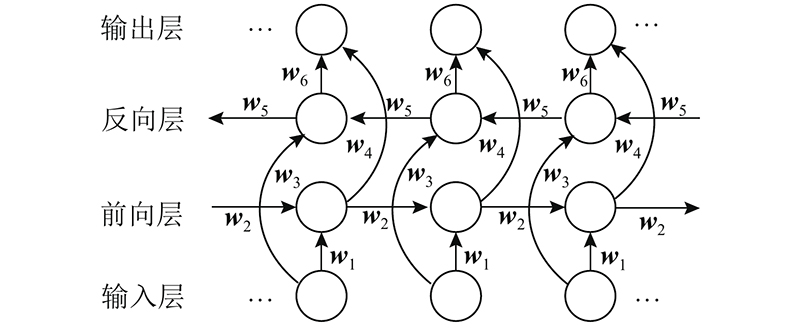
在反向和正向的Seq2Seq模型中,均使用带有双向长短期记忆的循环神经网络进行信息处理,1)便于迁移KBQA的知识编码特征作为额外编码器,2)实验发现BiLSTM在语义理解和特征捕捉上比门控循环单元(gate recurrent unit, GRU)[26]能取得更好的效果,这是因为某一位置的单词预测和选择同时参考前面若干序列和后面若干序列会取得更准确的结果. 使用的BiLSTM的神经元结构和网络结构图分别如图2、3所示.
在进行相关工作总结和实验中发现,在已有的引入知识的生成性对话模型的生成结果中较为严重的问题是存在大量的重复词或短语(如“it’s not a good book book book shelf”)或同一短句重复3遍以上.造成这种现象的原因可能是部分单词或短语从语法上看不仅有一种词性,模型未能防止重复词的产生,导致词汇重叠、语义逻辑不连贯. 为了改善这种情况,在模型中加入重复检测惩罚机制,在生成过程中如果检测到单词或短语的词向量表达与它之前的3个以内的已生成部分有大于2次的重复现象[27],则对其赋予惩罚权重,降低其生成的可能性.惩罚权重的计算如下:
生成样本中出现最多的误差是由于存在语义上的逻辑误差导致的. 比如“I am the fan of the game, but I don’t like the game, so I like the game.” 这样的表述缺乏语义上的合理性,但编码器、解码器结构的生成式模型普遍存在这个问题. 本研究认为这个问题的改善应该结合语言学、逻辑学方面的知识,以减少此类误差的产生.
第2个最常见的误差是由多义词引起的信息量不足或不合理的回答.这个问题在英语环境下尤其明显. 例如,给定输入文本“The new chair of the committee has a lot of great ideas.”,产生的反应是“I don’t like the chair to sit”. 利用知识推理借助知识图谱进行语义理解消歧,也是当今知识图谱的热门研究方向,在后续的研究中可以考虑将知识推理运用到对话生成中以改善生成对话的质量.
FERGUSON G, ALLEN J, MILLER B. TRAINS-95: towards a mixed-initiative planning assistant [C]// Proceedings of the Third Conferece on Artificial Intelligence Planning Systems. Edinburgh: [s.n.], 1996: 70-77.
WANG H, LU Z, LI H, et al. A dataset for research on short-text conversations [C]// Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing. Seattle: ACL, 2013: 935-945.
RITTER A, CHERRY C, DOLAN W B. Data-driven response generation in social media [C]// Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing. Edinburgh: ACL, 2011: 583-593.
SHANG L, LU Z, LI H. Neural responding machine for short-text conversation [C]// Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing. Beijing: ACL, 2015: 1577-1586.
SERBAN I, SORDONI A, BENGIO Y, et al. Building end-to-end dialogue systems using generative hierarchical neural network models [C]// Proceedings of the AAAI Conference on Artificial Intelligence. Phoenix: AAAI, 2016: 3776-3783.
LI J, GALLEY M, BROCKETT C, et al. A diversity-promoting objective function for neural conversation models [C]// The 2016 Conference of the North American Chapter of the Association for Computational Linguistics. San Diego: [s.n.]. 2016: 110-119.
ZHOU H, YOUNG T, HUANG M, et al. Commonsense knowledge aware conversation generation with graph attention [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. Stockholm: [s.n.]. 2018: 4623-4629.
LONG Y, WANG J, XU Z, et al. A knowledge enhanced generative conversational service agent [C]// Proceedings ofthe 6th Dialog System Technology Challenges (DSTC6) Workshop. Long Beach: [s.n.], 2017.
GHAZVININEJAD M, BROCKETT C, CHANG M W, et al. A knowledge-grounded neural conversation model [EB/OL]. [2021-06-22]. https://arxiv.org/pdf/1702.01932.pdf.
ZHU W, MO K, ZHANG Y, et al. Flexible end-to-end dialogue system for knowledge grounded conversation [EB/OL]. [2021-06-23]. https://arxiv.org/pdf/1709.04264v1.pdf.
LIU S, CHEN H, REN Z, et al. Knowledge diffusion for neural dialogue generation [C]// Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Melbourne: [s.n.], 2018: 1489-1498.
LIAN R, XIE M, WANG F, et al. Learning to select knowledge for response generation in dialog systems [C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. Macao: [s.n.], 2019: 5081.
WU S, LI Y, ZHANG D, et al. Diverse and informative dialogue generation with context-specific commonsense knowledge awareness [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: [s.n.], 2020: 5811-5820.
ZHOU S, RONG W, ZHANG J, et al. Topic-aware dialogue generation with two-hop based graph attention [C]// ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Toronto: IEEE, 2021: 7428-7432.
AUER S, BIZER C, KOBILAROV G, et al. DBpedia: a nucleus for a web of open data [M]// ABERER K, CHOI K-S, NOY N, et al. The semantic web. Heidelberg: Springer, 2007: 722-735.
BOSSELUT A, LE BRAS R, CHOI Y. Dynamic neuro-symbolic knowledge graph construction for zero-shot commonsense question answering [C]// Proceedings ofthe 35th AAAI Conference on Artificial Intelligence. Vancouver: AAAI, 2021: 4923-4931.
WANG J, LIU J, BI W, et al. Improving knowledge-aware dialogue generation via knowledge base question answering [EB/OL]. [2021-06-22]. https://arxiv.org/pdf/1912.07491v1.pdf.
CHAUDHURI D, RONY M R A H, LEHMANN J. Grounding dialogue systems via knowledge graph aware decoding with pre-trained transformers [C]// The Semantic Web 18th International Conference. Auckland: Springer, 2021: 323-339.
MOU L, SONG Y, YAN R, et al. Sequence to backward and forward sequences: a content-introducing approach to generative short-text conversation [C]// Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers. Osaka: ACL, 2016: 3349-3358.
YU M, YIN W, HASAN K S, et al. Improved neural relation detection for knowledge base question answering [C]// Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Vancouver: [s.n.], 2017: 571-581.
CHO K, MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha: ACL, 2014: 1724-1734.
BORDES A, USUNIER N, CHOPRA S, et al. Large-scale simple question answering with memory networks [EB/OL]. [2021-06-17]. https://arxiv.org/pdf/1506.02075.pdf.
LI Y, SU H, SHEN X, et al. DailyDialog: a manually labelled multi-turn dialogue dataset [C]// Proceedings ofthe Eighth International Joint Conference on Natural Language Processing. Taipei: AFNLP, 2017: 986-995.
CAI H, CHEN H, SONG Y, et al. Data manipulation: towards effective instance learning for neural dialogue generation via learning to augment and reweight [C]// Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. Online: [s.n.], 2020: 6334-6343.
PENNINGTON J, SOCHER R, MANNING C D. Glove: global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing. Doha: ACL, 2014: 1532-1543.
KINGMA D P, BA J. Adam: a method for stochastic optimization [C]// Proceedings of the3rd International Conference on Learning Representations. San Diego: [s.n.], 2015.
CHEN B, CHERRY C. A systematic comparison of smoothing techniques for sentence-level BLEU [C]// Proceedings of the Ninth Workshop on Statistical Machine Translation. Baltimore: ACL, 2014: 362-367.
... 在反向和正向的Seq2Seq模型中,均使用带有双向长短期记忆的循环神经网络进行信息处理,1)便于迁移KBQA的知识编码特征作为额外编码器,2)实验发现BiLSTM在语义理解和特征捕捉上比门控循环单元(gate recurrent unit, GRU)[26]能取得更好的效果,这是因为某一位置的单词预测和选择同时参考前面若干序列和后面若干序列会取得更准确的结果. 使用的BiLSTM的神经元结构和网络结构图分别如图2、3所示. ...
略谈英语词的重复形式
1
1991
... 在进行相关工作总结和实验中发现,在已有的引入知识的生成性对话模型的生成结果中较为严重的问题是存在大量的重复词或短语(如“it’s not a good book book book shelf”)或同一短句重复3遍以上.造成这种现象的原因可能是部分单词或短语从语法上看不仅有一种词性,模型未能防止重复词的产生,导致词汇重叠、语义逻辑不连贯. 为了改善这种情况,在模型中加入重复检测惩罚机制,在生成过程中如果检测到单词或短语的词向量表达与它之前的3个以内的已生成部分有大于2次的重复现象[27],则对其赋予惩罚权重,降低其生成的可能性.惩罚权重的计算如下: ...
略谈英语词的重复形式
1
1991
... 在进行相关工作总结和实验中发现,在已有的引入知识的生成性对话模型的生成结果中较为严重的问题是存在大量的重复词或短语(如“it’s not a good book book book shelf”)或同一短句重复3遍以上.造成这种现象的原因可能是部分单词或短语从语法上看不仅有一种词性,模型未能防止重复词的产生,导致词汇重叠、语义逻辑不连贯. 为了改善这种情况,在模型中加入重复检测惩罚机制,在生成过程中如果检测到单词或短语的词向量表达与它之前的3个以内的已生成部分有大于2次的重复现象[27],则对其赋予惩罚权重,降低其生成的可能性.惩罚权重的计算如下: ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}