[1]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[2]
张彦楠, 黄小红, 马严, 等 基于深度学习的录音文本分类方法
[J]. 浙江大学学报:工学版 , 2020 , 54 (7 ): 1264 - 1271
ZHANG Yan-nan, HUANG Xiao-hong, MA Yan, et al Method with recording text classification based on deep learning
[J]. Journal of Zhejiang University: Engineering Science , 2020 , 54 (7 ): 1264 - 1271
[3]
洪炎佳, 孟铁豹, 黎浩江, 等 多模态多维信息融合的鼻咽癌MR图像肿瘤深度分割方法
[J]. 浙江大学学报:工学版 , 2020 , 54 (3 ): 566 - 573
[本文引用: 1]
HONG Yan-jia, MENG Tie-bao, LI Hao-jiang, et al Deep segmentation method of tumor boundaries from MR images of patients with nasopharyngeal carcinoma using multi-modality and multi-dimension fusion
[J]. Journal of Zhejiang University:Engineering Science , 2020 , 54 (3 ): 566 - 573
[本文引用: 1]
[4]
TIAN Y, KRISHNAN D, ISOLA P. Contrastive representation distillation [EB/OL]. [2021-09-07]. https://arxiv.org/pdf/1910.10699v2.pdf.
[本文引用: 1]
[5]
HINTON G, VINVALS O, DEAN J Distilling the knowledge in a neural network
[J]. Computer Science , 2015 , 14 (7 ): 38 - 39
[本文引用: 1]
[6]
CHEN G, CHOI W, YU X, et al. Learning efficient object detection models with knowledge distillation [C]// Proceedings of the Annual Conference on Neural Information Processing Systems. Long Beach: [s. n.], 2017: 742–751.
[7]
TAN X, REN Y, HE D, et al. Multilingual neural machine translation with knowledge distillation [EB/OL]. [2021-09-07]. https://arxiv.org/pdf/1902.10461v3.pdf.
[8]
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2021-09-07]. https://arxiv.org/pdf/1409.1556.pdf.
[本文引用: 1]
[9]
ROMERO A, BALLAS N, KAHOU S E, et al. FitNets: hints for thin deep nets [C]// Proceedings of the International Conference on Learning Representations . San Diego: [s.n.], 2015: 1–13.
[本文引用: 2]
[10]
WANG T, YUAN L, ZHANG X, et al. Distilling object detectors with fine-grained feature imitation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4928–4937.
[本文引用: 3]
[11]
REN S, HE K, GIRSHICK R, et al. Faster R-CNN: towards real-time object detection with region proposal networks [EB/OL]. [2021-09-07]. https://arxiv.org/pdf/1506.01497.pdf.
[本文引用: 2]
[12]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779-788.
[本文引用: 2]
[13]
JIE H, LI S, GANG S, et al Squeeze-and-excitation networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2020 , 42 (8 ): 2011 - 2023
DOI:10.1109/TPAMI.2019.2913372
[14]
WANG Q, WU B, ZHU P, et al. ECA-Net: efficient channel attention for deep convolutional neural networks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Los Angeles: IEEE, 2020: 11531–11539.
[本文引用: 1]
[15]
HOU Y, MA Z, LIU C, et al. Learning lightweight lane detection CNNs by self attention distillation [C]// Proceedings of the IEEE International Conference on Computer Vision . Seoul: IEEE, 2019: 1013-1021.
[本文引用: 2]
[16]
EVERINGHAM M, ESLAMI S M A, VAN GOOL L, et al The pascal visual object classes challenge: a retrospective
[J]. International Journal of Computer Vision , 2015 , 111 (1 ): 98 - 136
DOI:10.1007/s11263-014-0733-5
[本文引用: 1]
[17]
GEIGER A, LENZ P, URTASUN R. Are we ready for autonomous driving? The KITTI vision benchmark suite [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Providence: IEEE, 2012: 3354-3361.
[本文引用: 1]
[18]
MAO J, XIAO T, JIANG Y, et al. What can help pedestrian detection? [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 3127-3136.
[本文引用: 1]
[19]
SUN R, TANG F, ZHANG X, et al. Distilling object detectors with task adaptive regularization [EB/OL]. [2021-09-07]. https://arxiv.org/pdf/2006.13108.pdf.
[本文引用: 1]
[20]
ZHENG Z, YE R, WANG P, et al. Localization distillation for object detection [EB/OL]. [2021-09-07]. https://arxiv.org/pdf/2102.12252v3.pdf.
[本文引用: 1]
[21]
ZHOU Z, ZHUGE C, GUAN X, et al. Channel distillation: channel-wise attention for knowledge distillation [EB/OL]. [2021-09-07]. https://arxiv.org/pdf/2006.01683v1.pdf.
[本文引用: 1]
1
... 深度卷积神经网络(convolutional neural networks,CNN)以其突出的性能被广泛应用在目标检测任务上[1 -3 ] ,然而庞大的模型参数和沉重的计算负担严重限制目标检测算法在移动机器人、车载摄像头边缘设备上的应用. 随着深度学习技术的发展,采用知识蒸馏(knowledge distillation,KD)技术对模型进行压缩,可以实现知识迁移与网络精简. 在人工智能逐步从理论研究走向大规模应用的背景下,如何利用知识蒸馏进行有效模型压缩已成为倍受关注且具有挑战性的研究热点. ...
多模态多维信息融合的鼻咽癌MR图像肿瘤深度分割方法
1
2020
... 深度卷积神经网络(convolutional neural networks,CNN)以其突出的性能被广泛应用在目标检测任务上[1 -3 ] ,然而庞大的模型参数和沉重的计算负担严重限制目标检测算法在移动机器人、车载摄像头边缘设备上的应用. 随着深度学习技术的发展,采用知识蒸馏(knowledge distillation,KD)技术对模型进行压缩,可以实现知识迁移与网络精简. 在人工智能逐步从理论研究走向大规模应用的背景下,如何利用知识蒸馏进行有效模型压缩已成为倍受关注且具有挑战性的研究热点. ...
多模态多维信息融合的鼻咽癌MR图像肿瘤深度分割方法
1
2020
... 深度卷积神经网络(convolutional neural networks,CNN)以其突出的性能被广泛应用在目标检测任务上[1 -3 ] ,然而庞大的模型参数和沉重的计算负担严重限制目标检测算法在移动机器人、车载摄像头边缘设备上的应用. 随着深度学习技术的发展,采用知识蒸馏(knowledge distillation,KD)技术对模型进行压缩,可以实现知识迁移与网络精简. 在人工智能逐步从理论研究走向大规模应用的背景下,如何利用知识蒸馏进行有效模型压缩已成为倍受关注且具有挑战性的研究热点. ...
1
... 知识蒸馏最早是针对分类任务提出并广泛应用的,该方法以较小的精度损失为代价,将较大的教师模型的知识传递给较小的学生模型,通过最小化教师模型和学生模型间的差异性,使小模型具备良好的性能[4 -8 ] . 广义上,这种差异性表现为教师模型和学生模型在表征能力上的鸿沟,包含结构、数值、特征等多种差异. 因为目标检测任务需要在准确定位的基础上进行分类,所以当把知识蒸馏直接应用于目标检测任务上时,目标区域的差异性会被淹没在过多的非目标区域中,使得优化目标被掩盖,模型难以收敛,传统知识蒸馏方法不再行之有效. 因此,确定优化目标成为知识蒸馏在目标检测任务上应用的关键. ...
Distilling the knowledge in a neural network
1
2015
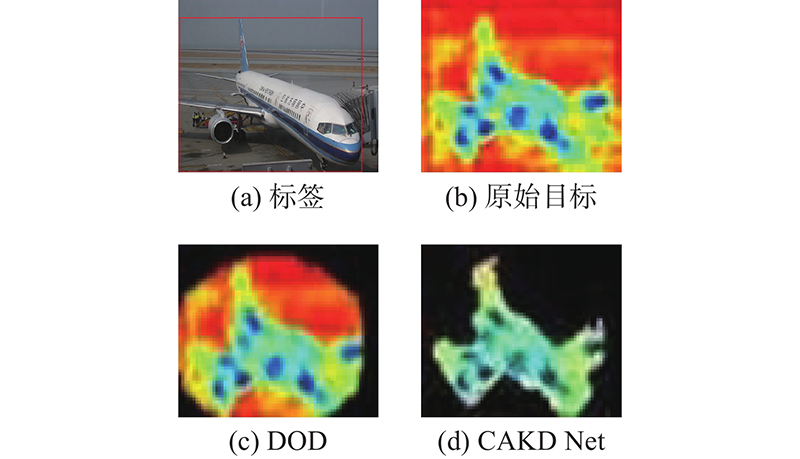
... 在此基础上,设计对比实验,分别采用FitNets[9 ] 、DOD[10 ] 、Task[19 ] 、LD[20 ] 等目标检测知识蒸馏方法和CAKD Net使用VOC07数据集进行测试. 由于Task在模型的不同位置使用知识蒸馏,为了与本研究保持一致,Task在表中的数据为仅骨干网络使用知识蒸馏的实验结果,对比实验结果如表6 所示. 为了更好地展示所提方法的改进,将部分方法的优化目标区域可视化呈现如图4 所示. 图4(b) 为FitNets方法通过使用全部高层特征间的差异作为优化目标,包含非目标区域的大量噪声;图4(c) 为DOD方法在FitNets的基础上进行改进,使用与检测目标相关联的细粒度特征作为优化目标,这种细粒度特征的提取无法准确定位目标的RPN网络,仍然覆盖大量无关的背景区域. Task在图4(c) 的基础上使用高斯掩膜加强前景区域的信息比重,弱化背景区域的干扰,仍然沿用图4(c) 中提取出的区域. LD通过模仿教师网络生成的目标框来加强目标边缘,未对特征图模仿. 图4(d) 为所提方法的优化目标可视化图. 实验结果表明,CARM生成的细粒度区域能准确定位检测目标的位置,且更好地与被检测目标形状吻合,使得优化目标更加明确,有效地提升了学生网络的检测性能. 此外,表6 将Hinton[5 ] 、CD[21 ] 加入对比,Hinton利用学生网络学习教师网络分类结果的概率分布,CD在知识蒸馏中加入通道权重的学习并加强对教师网络正确分类结果的学习. 但这2种方法侧重于分类,应用到目标检测任务时没有很好地加强学生网络对于检测能力的知识蒸馏效果. 实验结果证明了CAKD Net对目标检测任务的适用性. ...
1
... 知识蒸馏最早是针对分类任务提出并广泛应用的,该方法以较小的精度损失为代价,将较大的教师模型的知识传递给较小的学生模型,通过最小化教师模型和学生模型间的差异性,使小模型具备良好的性能[4 -8 ] . 广义上,这种差异性表现为教师模型和学生模型在表征能力上的鸿沟,包含结构、数值、特征等多种差异. 因为目标检测任务需要在准确定位的基础上进行分类,所以当把知识蒸馏直接应用于目标检测任务上时,目标区域的差异性会被淹没在过多的非目标区域中,使得优化目标被掩盖,模型难以收敛,传统知识蒸馏方法不再行之有效. 因此,确定优化目标成为知识蒸馏在目标检测任务上应用的关键. ...
2
... 在应用于目标检测的知识蒸馏方法中,Romero等[9 ] 提出将教师网络和学生网络在高层特征响应上的差异作为优化目标的方法,通过最小化2种特征响应的差异,成功将知识蒸馏应用在目标检测任务上. 在此基础上,Wang等[10 ] 考虑到内在位置的差异,利用锚框在空间域上约束教师网络和学生网络特征响应的范围,将内在位置差异作为优化目标,提升知识蒸馏的效率,显著提高目标检测效率. 然而,上述方法均忽略通道域差异,并且在生成待优化差异目标时,空间域上使用大尺度矩形边界框,不能很好地匹配被检测目标的通道特性及位置形状,导致学生网络在学习过程中仍然包含大量非目标区域的干扰. ...
... 在此基础上,设计对比实验,分别采用FitNets[9 ] 、DOD[10 ] 、Task[19 ] 、LD[20 ] 等目标检测知识蒸馏方法和CAKD Net使用VOC07数据集进行测试. 由于Task在模型的不同位置使用知识蒸馏,为了与本研究保持一致,Task在表中的数据为仅骨干网络使用知识蒸馏的实验结果,对比实验结果如表6 所示. 为了更好地展示所提方法的改进,将部分方法的优化目标区域可视化呈现如图4 所示. 图4(b) 为FitNets方法通过使用全部高层特征间的差异作为优化目标,包含非目标区域的大量噪声;图4(c) 为DOD方法在FitNets的基础上进行改进,使用与检测目标相关联的细粒度特征作为优化目标,这种细粒度特征的提取无法准确定位目标的RPN网络,仍然覆盖大量无关的背景区域. Task在图4(c) 的基础上使用高斯掩膜加强前景区域的信息比重,弱化背景区域的干扰,仍然沿用图4(c) 中提取出的区域. LD通过模仿教师网络生成的目标框来加强目标边缘,未对特征图模仿. 图4(d) 为所提方法的优化目标可视化图. 实验结果表明,CARM生成的细粒度区域能准确定位检测目标的位置,且更好地与被检测目标形状吻合,使得优化目标更加明确,有效地提升了学生网络的检测性能. 此外,表6 将Hinton[5 ] 、CD[21 ] 加入对比,Hinton利用学生网络学习教师网络分类结果的概率分布,CD在知识蒸馏中加入通道权重的学习并加强对教师网络正确分类结果的学习. 但这2种方法侧重于分类,应用到目标检测任务时没有很好地加强学生网络对于检测能力的知识蒸馏效果. 实验结果证明了CAKD Net对目标检测任务的适用性. ...
3
... 在应用于目标检测的知识蒸馏方法中,Romero等[9 ] 提出将教师网络和学生网络在高层特征响应上的差异作为优化目标的方法,通过最小化2种特征响应的差异,成功将知识蒸馏应用在目标检测任务上. 在此基础上,Wang等[10 ] 考虑到内在位置的差异,利用锚框在空间域上约束教师网络和学生网络特征响应的范围,将内在位置差异作为优化目标,提升知识蒸馏的效率,显著提高目标检测效率. 然而,上述方法均忽略通道域差异,并且在生成待优化差异目标时,空间域上使用大尺度矩形边界框,不能很好地匹配被检测目标的通道特性及位置形状,导致学生网络在学习过程中仍然包含大量非目标区域的干扰. ...
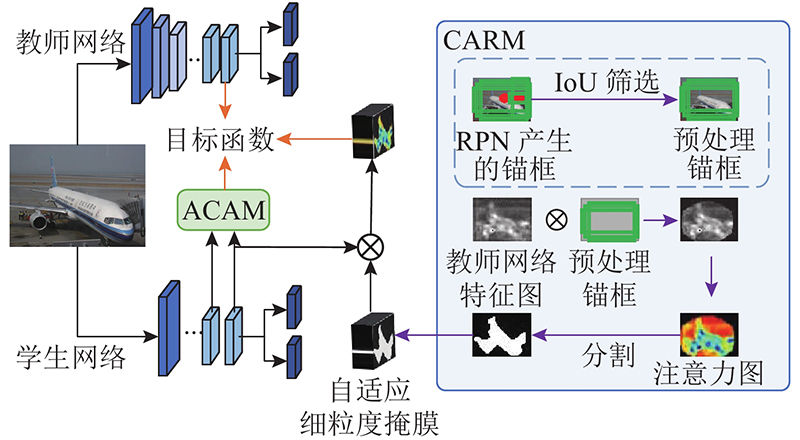
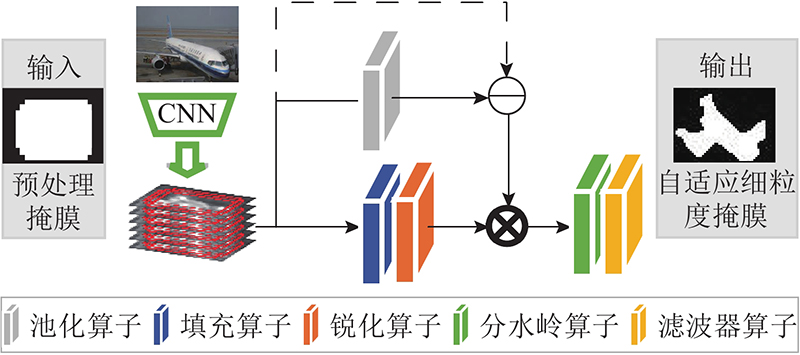
... 如图2 所示,为了从空间上更加明确地定位到优化区域,CARM根据被检测目标自适应地提取匹配目标形状的细粒度区域. 该模块在RPN产生的粗粒度候选区域的基础上,将粗粒度候选区域中与真实标签交并比(intersection over union,IoU)小于阈值的部分视为噪声区域,并对候选区域进行二值化得到预处理掩膜,将预处理掩膜映射到教师网络对应的特征图上,提取自适应细粒度掩膜. 其中IoU阈值参照文献[10 ]设置为0.5. 自适应细粒度掩膜提取步骤如下. 1)对预处理掩膜R M L 对注意力图进行锐化. 3)引入真实标签,引导对检测目标的准确定位,循环利用分水岭算子将锐化后的注意力图划分为n 个独立的区域块,直到n 与真实标签中检测目标的数量N 保持一致. 4)通过滤波器f 对分割结果进行滤波,提取出自适应的细粒度掩膜: ...
... 在此基础上,设计对比实验,分别采用FitNets[9 ] 、DOD[10 ] 、Task[19 ] 、LD[20 ] 等目标检测知识蒸馏方法和CAKD Net使用VOC07数据集进行测试. 由于Task在模型的不同位置使用知识蒸馏,为了与本研究保持一致,Task在表中的数据为仅骨干网络使用知识蒸馏的实验结果,对比实验结果如表6 所示. 为了更好地展示所提方法的改进,将部分方法的优化目标区域可视化呈现如图4 所示. 图4(b) 为FitNets方法通过使用全部高层特征间的差异作为优化目标,包含非目标区域的大量噪声;图4(c) 为DOD方法在FitNets的基础上进行改进,使用与检测目标相关联的细粒度特征作为优化目标,这种细粒度特征的提取无法准确定位目标的RPN网络,仍然覆盖大量无关的背景区域. Task在图4(c) 的基础上使用高斯掩膜加强前景区域的信息比重,弱化背景区域的干扰,仍然沿用图4(c) 中提取出的区域. LD通过模仿教师网络生成的目标框来加强目标边缘,未对特征图模仿. 图4(d) 为所提方法的优化目标可视化图. 实验结果表明,CARM生成的细粒度区域能准确定位检测目标的位置,且更好地与被检测目标形状吻合,使得优化目标更加明确,有效地提升了学生网络的检测性能. 此外,表6 将Hinton[5 ] 、CD[21 ] 加入对比,Hinton利用学生网络学习教师网络分类结果的概率分布,CD在知识蒸馏中加入通道权重的学习并加强对教师网络正确分类结果的学习. 但这2种方法侧重于分类,应用到目标检测任务时没有很好地加强学生网络对于检测能力的知识蒸馏效果. 实验结果证明了CAKD Net对目标检测任务的适用性. ...
2
... 基于锚框的检测器的知识蒸馏方法大多数使用区域候选网络(region proposal network,RPN)生成的边界框来限定优化目标. RPN是基于锚框的检测器的重要组成部分,它为后续的检测任务和分类任务生成粗略的候选区域[11 -12 ] . 事实上,这种粗粒度的候选区域是由矩形或多个矩形组成的,包含大量的背景区域,不能反映被检测目标的真实形状. 检测网络从这样冗杂的特征中捕捉被检测目标时,准确性较低. 因此,仅通过区域候选网络生成的候选区域,约束教师网络和学生网络在特征响应上的差异很难提高知识蒸馏的效率. ...
... 数据集VOC07涵盖日常场景中20个常见的类别,依据Faster R-CNN的训练模式,合并VOC07训练验证集进行训练,并在VOC07测试集上评估所提方法的性能[11 ] . KITTI是具有挑战性的现实世界基准数据集,根据文献[18 ],将KITTI数据集拆分为训练集和验证集,进行模型训练及测试. ...
2
... 基于锚框的检测器的知识蒸馏方法大多数使用区域候选网络(region proposal network,RPN)生成的边界框来限定优化目标. RPN是基于锚框的检测器的重要组成部分,它为后续的检测任务和分类任务生成粗略的候选区域[11 -12 ] . 事实上,这种粗粒度的候选区域是由矩形或多个矩形组成的,包含大量的背景区域,不能反映被检测目标的真实形状. 检测网络从这样冗杂的特征中捕捉被检测目标时,准确性较低. 因此,仅通过区域候选网络生成的候选区域,约束教师网络和学生网络在特征响应上的差异很难提高知识蒸馏的效率. ...
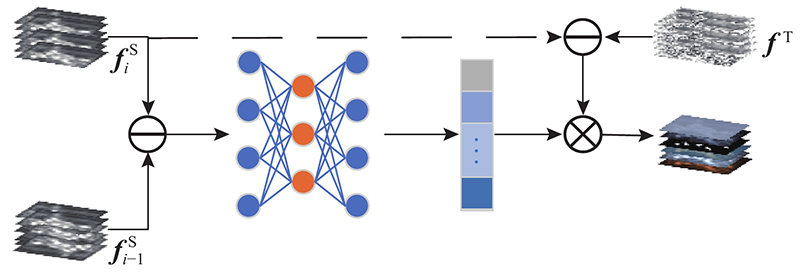
... 注意力机制在提高各种计算机视觉任务的性能方面发挥关键的作用[12 -14 ] . 以往的知识蒸馏方法大多数是将最小化教师网络和学生网络空间分布间的差异性作为优化目标,忽略不同通道贡献度的区别. 受自注意力蒸馏(self attention distillation,SAD)[15 ] 的启发,本研究利用自注意力机制,将空间上的差异性转换到通道域进行交互,从通道域优化知识蒸馏的目标函数. ACAM的结构如图3 所示. 图中, ${\boldsymbol{f}}_{i}^{\mathrm{S}}$ ${\boldsymbol{f}}_{i-1}^{\mathrm{S}}\mathrm{为}{\boldsymbol{f}}_{i}^{\mathrm{S}}$ ${\boldsymbol{f}}^{\mathrm{T}}$ ${\boldsymbol{f}}_{i}^{\mathrm{S}}$ ${\boldsymbol{f}}_{i-1}^{\mathrm{S}}$ ${\boldsymbol{f}}^{\mathrm{T}}$ $ C\times W\times H $ ${C}$ ${W}$ $ H $
Squeeze-and-excitation networks
0
2020
1
... 注意力机制在提高各种计算机视觉任务的性能方面发挥关键的作用[12 -14 ] . 以往的知识蒸馏方法大多数是将最小化教师网络和学生网络空间分布间的差异性作为优化目标,忽略不同通道贡献度的区别. 受自注意力蒸馏(self attention distillation,SAD)[15 ] 的启发,本研究利用自注意力机制,将空间上的差异性转换到通道域进行交互,从通道域优化知识蒸馏的目标函数. ACAM的结构如图3 所示. 图中, ${\boldsymbol{f}}_{i}^{\mathrm{S}}$ ${\boldsymbol{f}}_{i-1}^{\mathrm{S}}\mathrm{为}{\boldsymbol{f}}_{i}^{\mathrm{S}}$ ${\boldsymbol{f}}^{\mathrm{T}}$ ${\boldsymbol{f}}_{i}^{\mathrm{S}}$ ${\boldsymbol{f}}_{i-1}^{\mathrm{S}}$ ${\boldsymbol{f}}^{\mathrm{T}}$ $ C\times W\times H $ ${C}$ ${W}$ $ H $
2
... 注意力机制在提高各种计算机视觉任务的性能方面发挥关键的作用[12 -14 ] . 以往的知识蒸馏方法大多数是将最小化教师网络和学生网络空间分布间的差异性作为优化目标,忽略不同通道贡献度的区别. 受自注意力蒸馏(self attention distillation,SAD)[15 ] 的启发,本研究利用自注意力机制,将空间上的差异性转换到通道域进行交互,从通道域优化知识蒸馏的目标函数. ACAM的结构如图3 所示. 图中, ${\boldsymbol{f}}_{i}^{\mathrm{S}}$ ${\boldsymbol{f}}_{i-1}^{\mathrm{S}}\mathrm{为}{\boldsymbol{f}}_{i}^{\mathrm{S}}$ ${\boldsymbol{f}}^{\mathrm{T}}$ ${\boldsymbol{f}}_{i}^{\mathrm{S}}$ ${\boldsymbol{f}}_{i-1}^{\mathrm{S}}$ ${\boldsymbol{f}}^{\mathrm{T}}$ $ C\times W\times H $ ${C}$ ${W}$ $ H $
... 具体来说,相邻层的注意力图间的差异包含丰富的上下文信息,这些上下文信息蕴含检测目标的位置和粗略轮廓[15 ] . 本研究使用相邻层特征图间的差异作为相应通道的特征表示,用全局平均池化层将这种空间上的差异转换到通道域,这样既消除了空间域中背景噪声的干扰,又有利于通道域交互运算. 使用1×1卷积运算和非线性激活函数ReLu完成交互操作: ...
The pascal visual object classes challenge: a retrospective
1
2015
... 为了评估CAKD Net的性能,选择具有代表性的基于锚框的检测器Faster R-CNN作为检测器框架,采用2个经典的教师−学生网络VGG16-VGG11、ResNet101-ResNet50作为骨干网络,在2个典型的目标检测数据集VOC07、KITTI上进行实验[16 -17 ] . 实验在训练阶段采用所提出的知识蒸馏方法对学生模型进行训练,在测试阶段由学生模型独自进行前向推理. ...
1
... 为了评估CAKD Net的性能,选择具有代表性的基于锚框的检测器Faster R-CNN作为检测器框架,采用2个经典的教师−学生网络VGG16-VGG11、ResNet101-ResNet50作为骨干网络,在2个典型的目标检测数据集VOC07、KITTI上进行实验[16 -17 ] . 实验在训练阶段采用所提出的知识蒸馏方法对学生模型进行训练,在测试阶段由学生模型独自进行前向推理. ...
1
... 数据集VOC07涵盖日常场景中20个常见的类别,依据Faster R-CNN的训练模式,合并VOC07训练验证集进行训练,并在VOC07测试集上评估所提方法的性能[11 ] . KITTI是具有挑战性的现实世界基准数据集,根据文献[18 ],将KITTI数据集拆分为训练集和验证集,进行模型训练及测试. ...
1
... 在此基础上,设计对比实验,分别采用FitNets[9 ] 、DOD[10 ] 、Task[19 ] 、LD[20 ] 等目标检测知识蒸馏方法和CAKD Net使用VOC07数据集进行测试. 由于Task在模型的不同位置使用知识蒸馏,为了与本研究保持一致,Task在表中的数据为仅骨干网络使用知识蒸馏的实验结果,对比实验结果如表6 所示. 为了更好地展示所提方法的改进,将部分方法的优化目标区域可视化呈现如图4 所示. 图4(b) 为FitNets方法通过使用全部高层特征间的差异作为优化目标,包含非目标区域的大量噪声;图4(c) 为DOD方法在FitNets的基础上进行改进,使用与检测目标相关联的细粒度特征作为优化目标,这种细粒度特征的提取无法准确定位目标的RPN网络,仍然覆盖大量无关的背景区域. Task在图4(c) 的基础上使用高斯掩膜加强前景区域的信息比重,弱化背景区域的干扰,仍然沿用图4(c) 中提取出的区域. LD通过模仿教师网络生成的目标框来加强目标边缘,未对特征图模仿. 图4(d) 为所提方法的优化目标可视化图. 实验结果表明,CARM生成的细粒度区域能准确定位检测目标的位置,且更好地与被检测目标形状吻合,使得优化目标更加明确,有效地提升了学生网络的检测性能. 此外,表6 将Hinton[5 ] 、CD[21 ] 加入对比,Hinton利用学生网络学习教师网络分类结果的概率分布,CD在知识蒸馏中加入通道权重的学习并加强对教师网络正确分类结果的学习. 但这2种方法侧重于分类,应用到目标检测任务时没有很好地加强学生网络对于检测能力的知识蒸馏效果. 实验结果证明了CAKD Net对目标检测任务的适用性. ...
1
... 在此基础上,设计对比实验,分别采用FitNets[9 ] 、DOD[10 ] 、Task[19 ] 、LD[20 ] 等目标检测知识蒸馏方法和CAKD Net使用VOC07数据集进行测试. 由于Task在模型的不同位置使用知识蒸馏,为了与本研究保持一致,Task在表中的数据为仅骨干网络使用知识蒸馏的实验结果,对比实验结果如表6 所示. 为了更好地展示所提方法的改进,将部分方法的优化目标区域可视化呈现如图4 所示. 图4(b) 为FitNets方法通过使用全部高层特征间的差异作为优化目标,包含非目标区域的大量噪声;图4(c) 为DOD方法在FitNets的基础上进行改进,使用与检测目标相关联的细粒度特征作为优化目标,这种细粒度特征的提取无法准确定位目标的RPN网络,仍然覆盖大量无关的背景区域. Task在图4(c) 的基础上使用高斯掩膜加强前景区域的信息比重,弱化背景区域的干扰,仍然沿用图4(c) 中提取出的区域. LD通过模仿教师网络生成的目标框来加强目标边缘,未对特征图模仿. 图4(d) 为所提方法的优化目标可视化图. 实验结果表明,CARM生成的细粒度区域能准确定位检测目标的位置,且更好地与被检测目标形状吻合,使得优化目标更加明确,有效地提升了学生网络的检测性能. 此外,表6 将Hinton[5 ] 、CD[21 ] 加入对比,Hinton利用学生网络学习教师网络分类结果的概率分布,CD在知识蒸馏中加入通道权重的学习并加强对教师网络正确分类结果的学习. 但这2种方法侧重于分类,应用到目标检测任务时没有很好地加强学生网络对于检测能力的知识蒸馏效果. 实验结果证明了CAKD Net对目标检测任务的适用性. ...
1
... 在此基础上,设计对比实验,分别采用FitNets[9 ] 、DOD[10 ] 、Task[19 ] 、LD[20 ] 等目标检测知识蒸馏方法和CAKD Net使用VOC07数据集进行测试. 由于Task在模型的不同位置使用知识蒸馏,为了与本研究保持一致,Task在表中的数据为仅骨干网络使用知识蒸馏的实验结果,对比实验结果如表6 所示. 为了更好地展示所提方法的改进,将部分方法的优化目标区域可视化呈现如图4 所示. 图4(b) 为FitNets方法通过使用全部高层特征间的差异作为优化目标,包含非目标区域的大量噪声;图4(c) 为DOD方法在FitNets的基础上进行改进,使用与检测目标相关联的细粒度特征作为优化目标,这种细粒度特征的提取无法准确定位目标的RPN网络,仍然覆盖大量无关的背景区域. Task在图4(c) 的基础上使用高斯掩膜加强前景区域的信息比重,弱化背景区域的干扰,仍然沿用图4(c) 中提取出的区域. LD通过模仿教师网络生成的目标框来加强目标边缘,未对特征图模仿. 图4(d) 为所提方法的优化目标可视化图. 实验结果表明,CARM生成的细粒度区域能准确定位检测目标的位置,且更好地与被检测目标形状吻合,使得优化目标更加明确,有效地提升了学生网络的检测性能. 此外,表6 将Hinton[5 ] 、CD[21 ] 加入对比,Hinton利用学生网络学习教师网络分类结果的概率分布,CD在知识蒸馏中加入通道权重的学习并加强对教师网络正确分类结果的学习. 但这2种方法侧重于分类,应用到目标检测任务时没有很好地加强学生网络对于检测能力的知识蒸馏效果. 实验结果证明了CAKD Net对目标检测任务的适用性. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}