[1]
RAMACHANDRA R, BUSCH C Presentation attack detection methods for face recognition systems: a comprehensive survey
[J]. ACM Computing Surveys (CSUR) , 2017 , 50 (1 ): 1 - 37
DOI:10.1145/3009967
[本文引用: 4]
[2]
卢子谦, 陆哲明, 沈冯立, 等 人脸反欺诈活体检测综述
[J]. 信息安全学报 , 2020 , 5 (2 ): 18 - 27
[本文引用: 1]
LU Zi-qian, LU Zhe-ming, SHEN Feng-li, et al A survey of face anti-spoofing
[J]. Journal of Cyber Security , 2020 , 5 (2 ): 18 - 27
[本文引用: 1]
[3]
ZHANG Z W, YAN J J, LIU S F, et al. A face antispoofing database with diverse attacks[C]// 2012 5th IAPR International Conference on Biometrics (ICB) . Phuket: IEEE, 2012: 26-31.
[本文引用: 2]
[4]
BOULKENAFET Z, AKHTAR Z, FENG X Y, et al Face anti-spoofing in biometric systems
[J]. Biometric Security and Privacy , 2017 , 299 - 321
[本文引用: 2]
[5]
GALBALLY J, MARCEL S. Face anti-spoofing based on general image quality assessment[C]// 2014 22nd International Conference on Pattern Recognition (ICPR) . Columbia: IEEE, 2014: 1173-1178.
[本文引用: 1]
[6]
DI W, HU H, JAIN A K Face spoof detection with image distortion analysis
[J]. IEEE Transactions on Information Forensics and Security , 2015 , 10 (4 ): 746 - 761
DOI:10.1109/TIFS.2015.2400395
[本文引用: 3]
[7]
MAATTA J Face spoofing detection from single images using texture and local shape analysis
[J]. IET Biometrics , 2012 , 1 (1 ): 3 - 10
DOI:10.1049/iet-bmt.2011.0009
[本文引用: 1]
[8]
RAGHAVENDRA R, RAJA K B, BUSCH C Presentation attack detection for face recognition using light field camera
[J]. IEEE Transactions on Image Processing , 2015 , 24 (3 ): 1060 - 1075
DOI:10.1109/TIP.2015.2395951
[9]
CHINGOVSKA I, ANJOS A, MARCEL S. On the effectiveness of local binary patterns in face anti-spoofing[C]// Proceedings of International Conference of Biometrics Special Interest Group (BIOSIG) . Darmstadt: IEEE, 2012: 1-7.
[本文引用: 1]
[10]
BOULKENAFET Z, KOMULAINEN J, HADID A. Face anti-spoofing based on color texture analysis[C]// 2015 IEEE International Conference on Image Processing (ICIP) . Quebec City: IEEE, 2015: 2636-2640.
[本文引用: 3]
[11]
GRAGNANIELLO D, POGGI G, SANSONE C, et al An investigation of local descriptors for biometric spoofing detection
[J]. IEEE Transactions on Information Forensics and Security , 2015 , 10 (4 ): 849 - 863
DOI:10.1109/TIFS.2015.2404294
[本文引用: 1]
[12]
BOULKENAFET Z, KOMULAINEN J, HADID A Face antispoofing using speeded-up robust features and fisher vector encoding
[J]. IEEE Signal Processing Letters , 2016 , 24 (2 ): 141 - 145
[本文引用: 1]
[13]
PATEL K, HAN H, JAIN A K Secure face unlock: spoof detection on smartphones
[J]. IEEE Transactions on Information Forensics and Security , 2016 , 11 (10 ): 2268 - 2283
DOI:10.1109/TIFS.2016.2578288
[本文引用: 1]
[14]
YANG J, LEI Z, LI S Z Learn convolutional neural network for face anti-spoofing
[J]. Computer Sicence , 2014 , 9281 : 373 - 384
[本文引用: 3]
[15]
LI L, FENG X Y, BOULKENAFET Z, et al. An original face anti-spoofing approach using partial convolutional neural network[C]// 2016 6th International Conference on Image Processing Theory, Tools and Applications (IPTA) . Oulu: IEEE, 2016.
[16]
ATOUM Y, LIU Y J, JOURABLOO A, et al. Face anti-spoofing using patch and depth-based CNNs[C]// 2017 IEEE International Joint Conference on Biometrics (IJCB) . Denver: IEEE, 2017: 319-328.
[本文引用: 1]
[17]
LIU Y J, JOURABLOO A, LIU X M. Learning deep models for face anti-spoofing: binary or auxiliary supervision[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Salt Lake City: IEEE, 2018: 389-398.
[本文引用: 1]
[18]
CHEN H, HU G, LEI Z, et al Attention-based two-stream convolutional networks for face spoofing detection
[J]. IEEE Transactions on Information Forensics and Security , 2019 , 15 : 578 - 593
[本文引用: 5]
[20]
SHAO R, LAN X, LI J, et al. Multi-adversarial discriminative deep domain generalization for face presentation attack detection[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . Long Beach: IEEE, 2019: 10023-10031.
[本文引用: 1]
[21]
WANG Z, ZHAO C, QIN Y, et al. Exploiting temporal and depth information for multi-frame face anti-spoofing[EB/OL]. [2021-07-01]. https://arxiv.org/abs/1811.05118v3.
[22]
WANG Z Z, YU Z T, ZHAO C X, et al. Deep spatial gradient and temporal depth learning for face anti-spoofing[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . Seattle: IEEE, 2020: 5042-5051.
[23]
YU Z T, ZHAO C X, WANG Z Z, et al. Searching central difference convolutional networks for face anti-spoofing[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . Seattle: IEEE, 2020: 5295-5305.
[本文引用: 1]
[24]
SHEN T, HUANG Y Y, TONG Z J. Facebagnet: bag-of-local-features model for multi-modal face anti-spoofing[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) . Long Beach: IEEE, 2019: 1611-1616.
[本文引用: 1]
[25]
ZHANG S, LIU A, WAN J, et al Casia-surf: a large-scale multi-modal benchmark for face anti-spoofing
[J]. IEEE Transactions on Biometrics, Behavior, and Identity Science , 2020 , 2 (2 ): 182 - 193
DOI:10.1109/TBIOM.2020.2973001
[26]
皮家甜, 杨杰之, 杨琳希, 等 基于多模态特征融合的轻量级人脸活体检测方法
[J]. 计算机应用 , 2020 , 40 (12 ): 3658 - 3665
[本文引用: 1]
PI Jia-tian, YANG Jie-zhi, YANG Lin-xi, at el Lightweight face liveness detection method based on multi-modal feature fusion
[J]. Journal of Computer Applications , 2020 , 40 (12 ): 3658 - 3665
[本文引用: 1]
[27]
BOULKENAFET Z, KOMULAINEN J, LI L, et al. Oulu-npu: a mobile face presentation attack database with real-world variations[C]// 2017 12th IEEE International Conference on Automatic Face and Gesture Recognition . Washington: IEEE, 2017: 612-618.
[本文引用: 1]
[28]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection[C]// Proceedings of the IEEE International Conference on Computer Vision (ICCV) . Venice: IEEE, 2017: 2980-2988.
[本文引用: 1]
[29]
PEREIRA T D, ANJOS A, DE MARTINO J M, et al. Can face anti-spoofing countermeasures work in a real world scenario?[C]// 2013 International Conference on Biometrics (ICB) . Madrid: IEEE, 2013: 1-8.
[本文引用: 2]
[30]
KOMULAINEN J, HADID A, PIETIKAINEN M, et al. Complementary countermeasures for detecting scenic face spoofing attacks[C]// 2013 International Conference on Biometrics (ICB) . Madrid: IEEE, 2013: 1-7.
[本文引用: 1]
[31]
GEORGE A, MARCEL S. Deep pixel-wise binary supervision for face presentation attack detection[C]// 2019 International Conference on Biometrics (ICB) . Crete: IEEE, 2019: 1-8.
[本文引用: 1]
[32]
BOULKENAFET Z, KOMULAINEN J, HADID A Face spoofing detection using colour texture analysis
[J]. IEEE Transactions on Information Forensics and Security , 2016 , 11 (8 ): 1818 - 1830
DOI:10.1109/TIFS.2016.2555286
[本文引用: 1]
[33]
JOURABLOO A, LIU Y J, LIU X M. Face de-spoofing: anti-spoofing via noise modeling[C]// Proceedings of the Eurpoean Conference of Computer Vision (ECCV ). Munich: [s.n.], 2018: 290-306.
[本文引用: 1]
Presentation attack detection methods for face recognition systems: a comprehensive survey
4
2017
... 人脸识别是一种生物身份认证技术,相比指纹识别、声纹识别,人脸识别以其便捷、非接触、高准确率和高处理速度等特点在实际中得到广泛应用. 然而,单纯的人脸识别系统无法防范人脸照片和人脸视频攻击,为此,往往须结合人脸活体检测对人脸打印照片、电子照片或视频等欺诈手段进行防范[1 -2 ] . ...
... 人脸活体检测可以分成3大类实现方式:基于硬件辅助的方式、基于用户配合的方式以及静默活体检测的方式. 基于硬件辅助的方式须配备深度摄像头、3D结构光、热红外摄像头等辅助设备,在提升了部署成本的同时限制了其应用范围[1 , 4 ] . 基于用户配合的方式需要频繁的用户交互,人脸识别过程时间较长,用户体验不够友好[1 , 4 ] . 静默活体检测的方式通过分析活体与非活体人脸图像的色彩和纹理差异性特征进行真伪判别,其成本低廉、部署简易、用户友好,是一种理想的人脸活体检测任务实现方式,也一直是研究的热点. ...
... [1 , 4 ]. 静默活体检测的方式通过分析活体与非活体人脸图像的色彩和纹理差异性特征进行真伪判别,其成本低廉、部署简易、用户友好,是一种理想的人脸活体检测任务实现方式,也一直是研究的热点. ...
... Performance comparison of different methods on OULU-NPU dataset
Tab.5 方法 APCER/% BPCER/% ACER/% MixedFASNet[1 ] 9.7000 2.5000 6.1000 DeepPixBiS[31 ] 11.4000 0.6000 6.0000 MSR-Attention[18 ] 7.6000 2.2000 4.9000 BaseNet-Fusion 6.6667 2.5000 4.5833
3.4.2. 跨数据集测试 为了进一步验证采取多分类对模型泛化能力的提升,在数据集之间进行交叉验证,一是在CASIA-FASD上训练模型,在Replay-Attack数据集上进行测试;二是在Replay-Attack数据集上训练,在CASIA-FASD数据集上进行测试. 采取EER作为泛化性能的评价指标,实验结果如表6 所示. 可以看出,与采用基于二分类的方法相比,采用基于多分类的方法,ResNet-18和BaseNet网络模型中均有不同程度的错误率下降. ...
人脸反欺诈活体检测综述
1
2020
... 人脸识别是一种生物身份认证技术,相比指纹识别、声纹识别,人脸识别以其便捷、非接触、高准确率和高处理速度等特点在实际中得到广泛应用. 然而,单纯的人脸识别系统无法防范人脸照片和人脸视频攻击,为此,往往须结合人脸活体检测对人脸打印照片、电子照片或视频等欺诈手段进行防范[1 -2 ] . ...
人脸反欺诈活体检测综述
1
2020
... 人脸识别是一种生物身份认证技术,相比指纹识别、声纹识别,人脸识别以其便捷、非接触、高准确率和高处理速度等特点在实际中得到广泛应用. 然而,单纯的人脸识别系统无法防范人脸照片和人脸视频攻击,为此,往往须结合人脸活体检测对人脸打印照片、电子照片或视频等欺诈手段进行防范[1 -2 ] . ...
2
... 现实中人脸识别主要面临3种攻击手段[3 ] :打印攻击、展示攻击和3D面具攻击. 打印攻击将人脸图像打印在纸张上,通过弯曲、旋转、剪除眼睛等区域的方式来欺骗人脸识别系统. 展示攻击通过手机、平板电子设备上的人脸照片或视频进行攻击. 3D面具攻击通过制作人脸3D面具进行攻击,由于其制作复杂、成本较高,在生活中较少出现. 本研究主要针对前2种攻击手段进行研究,这也是国内外学者研究的重点. ...
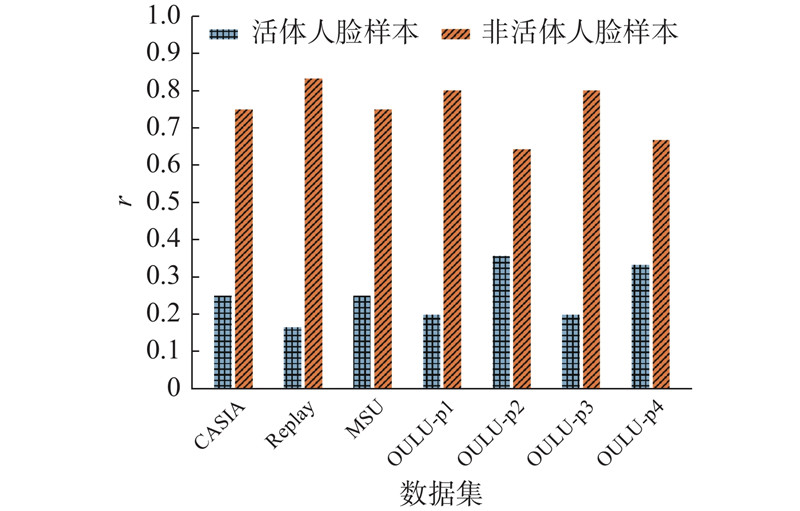
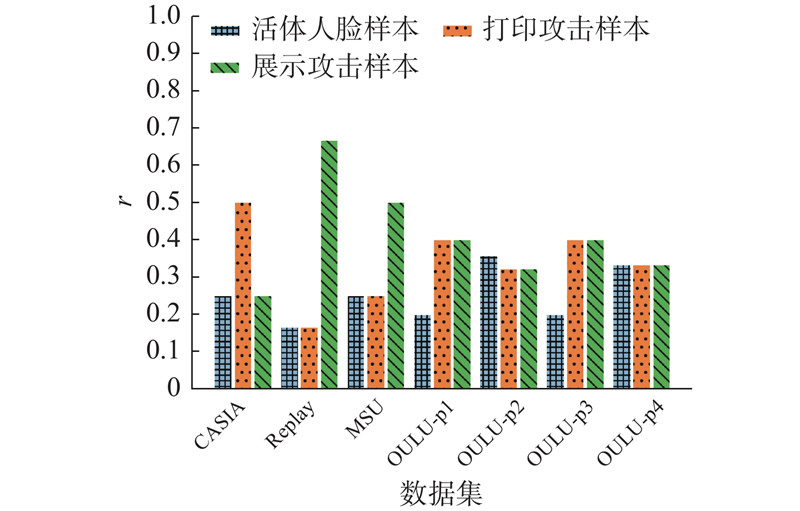
... 根据目前主流数据集中样本的分布情况(3D攻击样本较少),将非活体人脸样本按照图像特征差异细分成打印攻击样本和展示攻击样本2类,人脸活体检测任务从二分类任务转换成多分类任务. 研究涉及CASIA-FASD[3 ] 、Replay-Attack[9 ] 、MSU-MFSD[6 ] 和OULU-NPU这4个公开数据集,其类别数目分布如图2 、3 所示. 图中,r 为样本数目比率,OULU-p1~OULU-p4为将OULU-NPU中样本按照采集环境不同划分出的4种不同测试协议子数据集. 可以看出,相比二分类,多分类任务中各个类别样本的数目变得更加均衡. ...
Face anti-spoofing in biometric systems
2
2017
... 人脸活体检测可以分成3大类实现方式:基于硬件辅助的方式、基于用户配合的方式以及静默活体检测的方式. 基于硬件辅助的方式须配备深度摄像头、3D结构光、热红外摄像头等辅助设备,在提升了部署成本的同时限制了其应用范围[1 , 4 ] . 基于用户配合的方式需要频繁的用户交互,人脸识别过程时间较长,用户体验不够友好[1 , 4 ] . 静默活体检测的方式通过分析活体与非活体人脸图像的色彩和纹理差异性特征进行真伪判别,其成本低廉、部署简易、用户友好,是一种理想的人脸活体检测任务实现方式,也一直是研究的热点. ...
... , 4 ]. 静默活体检测的方式通过分析活体与非活体人脸图像的色彩和纹理差异性特征进行真伪判别,其成本低廉、部署简易、用户友好,是一种理想的人脸活体检测任务实现方式,也一直是研究的热点. ...
1
... 基于图像质量分析的方式依据的原理是,非活体人脸样本是通过活体人脸样本二次采集得到的,打印攻击容易导致色彩、人脸细节特征的变形与丢失,展示攻击在识别过程容易产生摩尔纹、大片高光图像噪声,导致被识别图像质量下降. Galbally等 [5 ] 选取了14种图像质量统计特征进行活体判别,Di等 [6 ] 融合镜面反射特征、模糊度特征、色矩特征和色彩多样性特征4类图像质量评估统计特征,并通过集成多个分类器设计了一个有效的人脸活体检测算法. 基于传统图像纹理特征的方式依据的原理是,非活体人脸图像与活体人脸图像由于二次采集在图像纹理细节上存在差异,通过设计特定的图像纹理特征来区分活体和非活体. 研究人员利用局部二值模式(local binary pattern, LBP)[7 -10 ] 、方向梯度直方图(histogram of oriented gradient, HOG)[11 ] 、加速鲁棒特征(speed up robust features, SURF)[12 ] 、尺度不变特征变换(scale-invariant feature transform, SIFT)[13 ] 等多种特征,在RGB、HSV和YCrCb不同色彩空间中提取图像纹理特征,并结合支持向量机(support vector machine, SVM)和线性判别分析(linear discriminant analysis, LDA)设计出了多种不同的活体检测算法. 基于上述2类方式的活体检测算法通过统计或人工设计得到的图像特征较为单一,容易受到数据集拍摄设备、光照条件、背景环境等因素影响,在这些因素发生变化时算法性能会急剧下降,难以应用到复杂多变的实际场景中. ...
Face spoof detection with image distortion analysis
3
2015
... 基于图像质量分析的方式依据的原理是,非活体人脸样本是通过活体人脸样本二次采集得到的,打印攻击容易导致色彩、人脸细节特征的变形与丢失,展示攻击在识别过程容易产生摩尔纹、大片高光图像噪声,导致被识别图像质量下降. Galbally等 [5 ] 选取了14种图像质量统计特征进行活体判别,Di等 [6 ] 融合镜面反射特征、模糊度特征、色矩特征和色彩多样性特征4类图像质量评估统计特征,并通过集成多个分类器设计了一个有效的人脸活体检测算法. 基于传统图像纹理特征的方式依据的原理是,非活体人脸图像与活体人脸图像由于二次采集在图像纹理细节上存在差异,通过设计特定的图像纹理特征来区分活体和非活体. 研究人员利用局部二值模式(local binary pattern, LBP)[7 -10 ] 、方向梯度直方图(histogram of oriented gradient, HOG)[11 ] 、加速鲁棒特征(speed up robust features, SURF)[12 ] 、尺度不变特征变换(scale-invariant feature transform, SIFT)[13 ] 等多种特征,在RGB、HSV和YCrCb不同色彩空间中提取图像纹理特征,并结合支持向量机(support vector machine, SVM)和线性判别分析(linear discriminant analysis, LDA)设计出了多种不同的活体检测算法. 基于上述2类方式的活体检测算法通过统计或人工设计得到的图像特征较为单一,容易受到数据集拍摄设备、光照条件、背景环境等因素影响,在这些因素发生变化时算法性能会急剧下降,难以应用到复杂多变的实际场景中. ...
... 根据目前主流数据集中样本的分布情况(3D攻击样本较少),将非活体人脸样本按照图像特征差异细分成打印攻击样本和展示攻击样本2类,人脸活体检测任务从二分类任务转换成多分类任务. 研究涉及CASIA-FASD[3 ] 、Replay-Attack[9 ] 、MSU-MFSD[6 ] 和OULU-NPU这4个公开数据集,其类别数目分布如图2 、3 所示. 图中,r 为样本数目比率,OULU-p1~OULU-p4为将OULU-NPU中样本按照采集环境不同划分出的4种不同测试协议子数据集. 可以看出,相比二分类,多分类任务中各个类别样本的数目变得更加均衡. ...
... Performance comparison of different methods on CASIA-FASD and Replay-Attack dataset
Tab.4 方法 Replay-Attack CASIA-FASD EER/% HTER/% EER/% LBP-TOP[29 ] 7.900 7.600 10.000 CNN[14 ] 6.100 2.100 7.400 IDA[6 ] − 7.400 − Motion+LBP[30 ] 4.500 5.110 − Color-LBP[10 ] 0.400 2.900 6.200 MSR-Attention[18 ] 0.210 0.389 3.145 BaseNet-Fusion 1.000 0.500 2.961
表 5 不同方法在OULU-NPU数据集上的性能对比 ...
Face spoofing detection from single images using texture and local shape analysis
1
2012
... 基于图像质量分析的方式依据的原理是,非活体人脸样本是通过活体人脸样本二次采集得到的,打印攻击容易导致色彩、人脸细节特征的变形与丢失,展示攻击在识别过程容易产生摩尔纹、大片高光图像噪声,导致被识别图像质量下降. Galbally等 [5 ] 选取了14种图像质量统计特征进行活体判别,Di等 [6 ] 融合镜面反射特征、模糊度特征、色矩特征和色彩多样性特征4类图像质量评估统计特征,并通过集成多个分类器设计了一个有效的人脸活体检测算法. 基于传统图像纹理特征的方式依据的原理是,非活体人脸图像与活体人脸图像由于二次采集在图像纹理细节上存在差异,通过设计特定的图像纹理特征来区分活体和非活体. 研究人员利用局部二值模式(local binary pattern, LBP)[7 -10 ] 、方向梯度直方图(histogram of oriented gradient, HOG)[11 ] 、加速鲁棒特征(speed up robust features, SURF)[12 ] 、尺度不变特征变换(scale-invariant feature transform, SIFT)[13 ] 等多种特征,在RGB、HSV和YCrCb不同色彩空间中提取图像纹理特征,并结合支持向量机(support vector machine, SVM)和线性判别分析(linear discriminant analysis, LDA)设计出了多种不同的活体检测算法. 基于上述2类方式的活体检测算法通过统计或人工设计得到的图像特征较为单一,容易受到数据集拍摄设备、光照条件、背景环境等因素影响,在这些因素发生变化时算法性能会急剧下降,难以应用到复杂多变的实际场景中. ...
Presentation attack detection for face recognition using light field camera
0
2015
1
... 根据目前主流数据集中样本的分布情况(3D攻击样本较少),将非活体人脸样本按照图像特征差异细分成打印攻击样本和展示攻击样本2类,人脸活体检测任务从二分类任务转换成多分类任务. 研究涉及CASIA-FASD[3 ] 、Replay-Attack[9 ] 、MSU-MFSD[6 ] 和OULU-NPU这4个公开数据集,其类别数目分布如图2 、3 所示. 图中,r 为样本数目比率,OULU-p1~OULU-p4为将OULU-NPU中样本按照采集环境不同划分出的4种不同测试协议子数据集. 可以看出,相比二分类,多分类任务中各个类别样本的数目变得更加均衡. ...
3
... 基于图像质量分析的方式依据的原理是,非活体人脸样本是通过活体人脸样本二次采集得到的,打印攻击容易导致色彩、人脸细节特征的变形与丢失,展示攻击在识别过程容易产生摩尔纹、大片高光图像噪声,导致被识别图像质量下降. Galbally等 [5 ] 选取了14种图像质量统计特征进行活体判别,Di等 [6 ] 融合镜面反射特征、模糊度特征、色矩特征和色彩多样性特征4类图像质量评估统计特征,并通过集成多个分类器设计了一个有效的人脸活体检测算法. 基于传统图像纹理特征的方式依据的原理是,非活体人脸图像与活体人脸图像由于二次采集在图像纹理细节上存在差异,通过设计特定的图像纹理特征来区分活体和非活体. 研究人员利用局部二值模式(local binary pattern, LBP)[7 -10 ] 、方向梯度直方图(histogram of oriented gradient, HOG)[11 ] 、加速鲁棒特征(speed up robust features, SURF)[12 ] 、尺度不变特征变换(scale-invariant feature transform, SIFT)[13 ] 等多种特征,在RGB、HSV和YCrCb不同色彩空间中提取图像纹理特征,并结合支持向量机(support vector machine, SVM)和线性判别分析(linear discriminant analysis, LDA)设计出了多种不同的活体检测算法. 基于上述2类方式的活体检测算法通过统计或人工设计得到的图像特征较为单一,容易受到数据集拍摄设备、光照条件、背景环境等因素影响,在这些因素发生变化时算法性能会急剧下降,难以应用到复杂多变的实际场景中. ...
... Performance comparison of different methods on CASIA-FASD and Replay-Attack dataset
Tab.4 方法 Replay-Attack CASIA-FASD EER/% HTER/% EER/% LBP-TOP[29 ] 7.900 7.600 10.000 CNN[14 ] 6.100 2.100 7.400 IDA[6 ] − 7.400 − Motion+LBP[30 ] 4.500 5.110 − Color-LBP[10 ] 0.400 2.900 6.200 MSR-Attention[18 ] 0.210 0.389 3.145 BaseNet-Fusion 1.000 0.500 2.961
表 5 不同方法在OULU-NPU数据集上的性能对比 ...
... Cross-testing of different methods under Replay-Attack and CASIA-FASD dataset
Tab.7 方法 EER/% 训练: CASIA 训练: Replay LBP-TOP[29 ] 49.700 60.6000 CNN[14 ] 48.500 39.6000 Color-LBP[10 ] 47.000 39.6000 Color-Texture[32 ] 30.300 37.7000 FaceDs[33 ] 28.500 41.1000 MSR-Attention[18 ] 36.200 34.7000 BaseNet-Fusion 27.875 38.5185
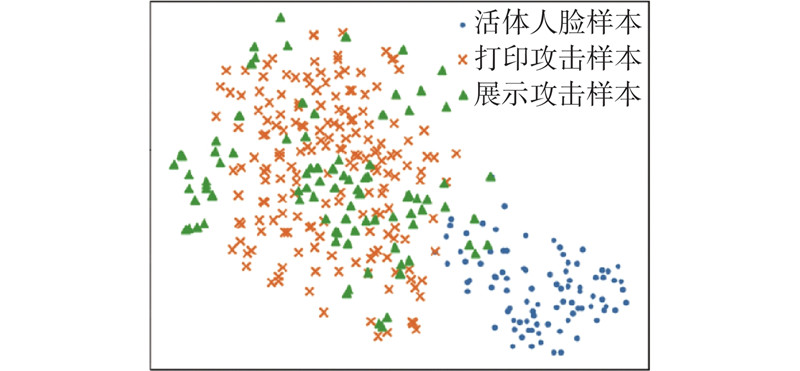
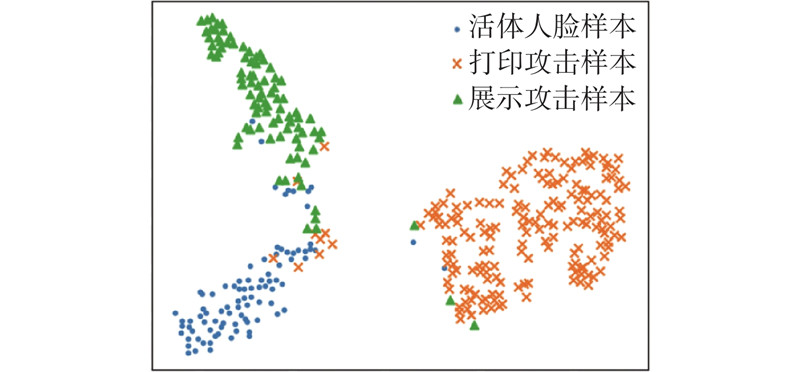
如图6 、7 所示为对BaseNet网络模型提取到的分类特征向量采取主成分分析(principal component analysis,PCA)特征降维后的样本分布,图6 为基于二分类方法的样本分布,图7 为基于多分类方法的样本分布. 可以看出,打印攻击和展示攻击具有各自的共性欺诈特征,通过多分类能够较好地将这2类样本区分开,使得人脸检测算法能够更好地识别出非活体攻击,从而提升模型的鲁棒性. ...
An investigation of local descriptors for biometric spoofing detection
1
2015
... 基于图像质量分析的方式依据的原理是,非活体人脸样本是通过活体人脸样本二次采集得到的,打印攻击容易导致色彩、人脸细节特征的变形与丢失,展示攻击在识别过程容易产生摩尔纹、大片高光图像噪声,导致被识别图像质量下降. Galbally等 [5 ] 选取了14种图像质量统计特征进行活体判别,Di等 [6 ] 融合镜面反射特征、模糊度特征、色矩特征和色彩多样性特征4类图像质量评估统计特征,并通过集成多个分类器设计了一个有效的人脸活体检测算法. 基于传统图像纹理特征的方式依据的原理是,非活体人脸图像与活体人脸图像由于二次采集在图像纹理细节上存在差异,通过设计特定的图像纹理特征来区分活体和非活体. 研究人员利用局部二值模式(local binary pattern, LBP)[7 -10 ] 、方向梯度直方图(histogram of oriented gradient, HOG)[11 ] 、加速鲁棒特征(speed up robust features, SURF)[12 ] 、尺度不变特征变换(scale-invariant feature transform, SIFT)[13 ] 等多种特征,在RGB、HSV和YCrCb不同色彩空间中提取图像纹理特征,并结合支持向量机(support vector machine, SVM)和线性判别分析(linear discriminant analysis, LDA)设计出了多种不同的活体检测算法. 基于上述2类方式的活体检测算法通过统计或人工设计得到的图像特征较为单一,容易受到数据集拍摄设备、光照条件、背景环境等因素影响,在这些因素发生变化时算法性能会急剧下降,难以应用到复杂多变的实际场景中. ...
Face antispoofing using speeded-up robust features and fisher vector encoding
1
2016
... 基于图像质量分析的方式依据的原理是,非活体人脸样本是通过活体人脸样本二次采集得到的,打印攻击容易导致色彩、人脸细节特征的变形与丢失,展示攻击在识别过程容易产生摩尔纹、大片高光图像噪声,导致被识别图像质量下降. Galbally等 [5 ] 选取了14种图像质量统计特征进行活体判别,Di等 [6 ] 融合镜面反射特征、模糊度特征、色矩特征和色彩多样性特征4类图像质量评估统计特征,并通过集成多个分类器设计了一个有效的人脸活体检测算法. 基于传统图像纹理特征的方式依据的原理是,非活体人脸图像与活体人脸图像由于二次采集在图像纹理细节上存在差异,通过设计特定的图像纹理特征来区分活体和非活体. 研究人员利用局部二值模式(local binary pattern, LBP)[7 -10 ] 、方向梯度直方图(histogram of oriented gradient, HOG)[11 ] 、加速鲁棒特征(speed up robust features, SURF)[12 ] 、尺度不变特征变换(scale-invariant feature transform, SIFT)[13 ] 等多种特征,在RGB、HSV和YCrCb不同色彩空间中提取图像纹理特征,并结合支持向量机(support vector machine, SVM)和线性判别分析(linear discriminant analysis, LDA)设计出了多种不同的活体检测算法. 基于上述2类方式的活体检测算法通过统计或人工设计得到的图像特征较为单一,容易受到数据集拍摄设备、光照条件、背景环境等因素影响,在这些因素发生变化时算法性能会急剧下降,难以应用到复杂多变的实际场景中. ...
Secure face unlock: spoof detection on smartphones
1
2016
... 基于图像质量分析的方式依据的原理是,非活体人脸样本是通过活体人脸样本二次采集得到的,打印攻击容易导致色彩、人脸细节特征的变形与丢失,展示攻击在识别过程容易产生摩尔纹、大片高光图像噪声,导致被识别图像质量下降. Galbally等 [5 ] 选取了14种图像质量统计特征进行活体判别,Di等 [6 ] 融合镜面反射特征、模糊度特征、色矩特征和色彩多样性特征4类图像质量评估统计特征,并通过集成多个分类器设计了一个有效的人脸活体检测算法. 基于传统图像纹理特征的方式依据的原理是,非活体人脸图像与活体人脸图像由于二次采集在图像纹理细节上存在差异,通过设计特定的图像纹理特征来区分活体和非活体. 研究人员利用局部二值模式(local binary pattern, LBP)[7 -10 ] 、方向梯度直方图(histogram of oriented gradient, HOG)[11 ] 、加速鲁棒特征(speed up robust features, SURF)[12 ] 、尺度不变特征变换(scale-invariant feature transform, SIFT)[13 ] 等多种特征,在RGB、HSV和YCrCb不同色彩空间中提取图像纹理特征,并结合支持向量机(support vector machine, SVM)和线性判别分析(linear discriminant analysis, LDA)设计出了多种不同的活体检测算法. 基于上述2类方式的活体检测算法通过统计或人工设计得到的图像特征较为单一,容易受到数据集拍摄设备、光照条件、背景环境等因素影响,在这些因素发生变化时算法性能会急剧下降,难以应用到复杂多变的实际场景中. ...
Learn convolutional neural network for face anti-spoofing
3
2014
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
... Performance comparison of different methods on CASIA-FASD and Replay-Attack dataset
Tab.4 方法 Replay-Attack CASIA-FASD EER/% HTER/% EER/% LBP-TOP[29 ] 7.900 7.600 10.000 CNN[14 ] 6.100 2.100 7.400 IDA[6 ] − 7.400 − Motion+LBP[30 ] 4.500 5.110 − Color-LBP[10 ] 0.400 2.900 6.200 MSR-Attention[18 ] 0.210 0.389 3.145 BaseNet-Fusion 1.000 0.500 2.961
表 5 不同方法在OULU-NPU数据集上的性能对比 ...
... Cross-testing of different methods under Replay-Attack and CASIA-FASD dataset
Tab.7 方法 EER/% 训练: CASIA 训练: Replay LBP-TOP[29 ] 49.700 60.6000 CNN[14 ] 48.500 39.6000 Color-LBP[10 ] 47.000 39.6000 Color-Texture[32 ] 30.300 37.7000 FaceDs[33 ] 28.500 41.1000 MSR-Attention[18 ] 36.200 34.7000 BaseNet-Fusion 27.875 38.5185
如图6 、7 所示为对BaseNet网络模型提取到的分类特征向量采取主成分分析(principal component analysis,PCA)特征降维后的样本分布,图6 为基于二分类方法的样本分布,图7 为基于多分类方法的样本分布. 可以看出,打印攻击和展示攻击具有各自的共性欺诈特征,通过多分类能够较好地将这2类样本区分开,使得人脸检测算法能够更好地识别出非活体攻击,从而提升模型的鲁棒性. ...
1
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
1
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
Attention-based two-stream convolutional networks for face spoofing detection
5
2019
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
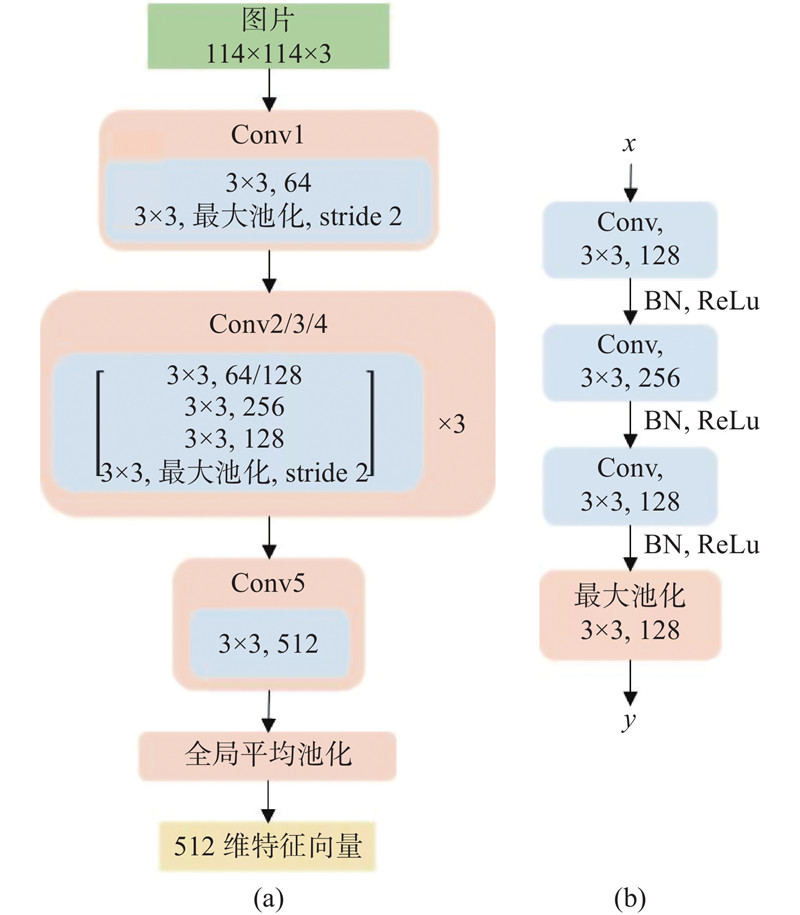
... 通过不同色彩空间的图像能够提取不同纹理偏向的图像特征,借鉴Chen等[18 ] 的思想,基于BaseNet网络设计了一个双流融合(Baselvet-Fusion)网络模型,分别提取RGB和YCrCb色彩空间的图像特征,并进行自适应的特征融合构成最终的分类特征向量. 网络模型如图4 所示. ...
... Performance comparison of different methods on CASIA-FASD and Replay-Attack dataset
Tab.4 方法 Replay-Attack CASIA-FASD EER/% HTER/% EER/% LBP-TOP[29 ] 7.900 7.600 10.000 CNN[14 ] 6.100 2.100 7.400 IDA[6 ] − 7.400 − Motion+LBP[30 ] 4.500 5.110 − Color-LBP[10 ] 0.400 2.900 6.200 MSR-Attention[18 ] 0.210 0.389 3.145 BaseNet-Fusion 1.000 0.500 2.961
表 5 不同方法在OULU-NPU数据集上的性能对比 ...
... Performance comparison of different methods on OULU-NPU dataset
Tab.5 方法 APCER/% BPCER/% ACER/% MixedFASNet[1 ] 9.7000 2.5000 6.1000 DeepPixBiS[31 ] 11.4000 0.6000 6.0000 MSR-Attention[18 ] 7.6000 2.2000 4.9000 BaseNet-Fusion 6.6667 2.5000 4.5833
3.4.2. 跨数据集测试 为了进一步验证采取多分类对模型泛化能力的提升,在数据集之间进行交叉验证,一是在CASIA-FASD上训练模型,在Replay-Attack数据集上进行测试;二是在Replay-Attack数据集上训练,在CASIA-FASD数据集上进行测试. 采取EER作为泛化性能的评价指标,实验结果如表6 所示. 可以看出,与采用基于二分类的方法相比,采用基于多分类的方法,ResNet-18和BaseNet网络模型中均有不同程度的错误率下降. ...
... Cross-testing of different methods under Replay-Attack and CASIA-FASD dataset
Tab.7 方法 EER/% 训练: CASIA 训练: Replay LBP-TOP[29 ] 49.700 60.6000 CNN[14 ] 48.500 39.6000 Color-LBP[10 ] 47.000 39.6000 Color-Texture[32 ] 30.300 37.7000 FaceDs[33 ] 28.500 41.1000 MSR-Attention[18 ] 36.200 34.7000 BaseNet-Fusion 27.875 38.5185
如图6 、7 所示为对BaseNet网络模型提取到的分类特征向量采取主成分分析(principal component analysis,PCA)特征降维后的样本分布,图6 为基于二分类方法的样本分布,图7 为基于多分类方法的样本分布. 可以看出,打印攻击和展示攻击具有各自的共性欺诈特征,通过多分类能够较好地将这2类样本区分开,使得人脸检测算法能够更好地识别出非活体攻击,从而提升模型的鲁棒性. ...
应用卷积神经网络的人脸活体检测算法研究
1
2018
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
应用卷积神经网络的人脸活体检测算法研究
1
2018
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
1
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
1
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
1
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
Casia-surf: a large-scale multi-modal benchmark for face anti-spoofing
0
2020
基于多模态特征融合的轻量级人脸活体检测方法
1
2020
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
基于多模态特征融合的轻量级人脸活体检测方法
1
2020
... 基于卷积神经网络的方式将人脸活体检测当作二分类任务,借助深度网络模型实现真假判别. 研究人员采取CaffeNet、VGG、残差网络(residual neural network, ResNet)、循环神经网络(recurrent neural network, RNN)、长短期记忆网络(long short-term memory, LSTM)等网络结构提取图像抽象纹理特征[14 -19 ] . 基于二分类损失函数对网络模型进行监督学习,在数据集内部测试中能取得更优的分类性能,但是在跨数据集测试中模型性能下降,泛化能力仍然存在大的提升空间. 为了促使网络模型学习到更多的分类细节特征,研究人员又引入人脸深度监督信息[16 , 20 -23 ] ,通过算法模拟得到的人脸深度图作为辅助监督信息训练网络,使得模型泛化能力得到提升;也有研究人员采取rPPG辅助信息[17 ] ,或者通过多模态特征融合的方式提升算法的鲁棒性[18 , 24 -26 ] . ...
1
... 非活体人脸样本是由活体人脸样本通过不同欺诈方式二次采集获取的,不同的欺诈方式会呈现出不同的信息损失和样本特征. 打印攻击由于打印质量容易产生色彩偏差、人脸细节特征弥散;展示攻击由于电子设备屏幕影响容易产生摩尔纹和大片反光现象. 如图1 所示为OULU-NPU[27 ] 数据集中的不同类型人脸图像. 可以看出,活体人脸图像色彩均衡、细节清晰,打印攻击图像呈现暗黄色彩偏差,展示攻击呈现白光和摩尔纹噪声. ...
1
... 由图4 可以看出,采取二分类划分人脸数据集会导致活体与非活体样本数目比率失衡. 为了探讨类别不均衡问题对人脸活体检测任务的影响,分别采用FocalLoss和交叉熵作为损失函数[28 ] 训练网络模型,通过对测试集的检测,进行结果的对比. Focal Loss是针对正负样本不均衡问题而进行的二分类损失函数,表达式如下: ...
2
... Performance comparison of different methods on CASIA-FASD and Replay-Attack dataset
Tab.4 方法 Replay-Attack CASIA-FASD EER/% HTER/% EER/% LBP-TOP[29 ] 7.900 7.600 10.000 CNN[14 ] 6.100 2.100 7.400 IDA[6 ] − 7.400 − Motion+LBP[30 ] 4.500 5.110 − Color-LBP[10 ] 0.400 2.900 6.200 MSR-Attention[18 ] 0.210 0.389 3.145 BaseNet-Fusion 1.000 0.500 2.961
表 5 不同方法在OULU-NPU数据集上的性能对比 ...
... Cross-testing of different methods under Replay-Attack and CASIA-FASD dataset
Tab.7 方法 EER/% 训练: CASIA 训练: Replay LBP-TOP[29 ] 49.700 60.6000 CNN[14 ] 48.500 39.6000 Color-LBP[10 ] 47.000 39.6000 Color-Texture[32 ] 30.300 37.7000 FaceDs[33 ] 28.500 41.1000 MSR-Attention[18 ] 36.200 34.7000 BaseNet-Fusion 27.875 38.5185
如图6 、7 所示为对BaseNet网络模型提取到的分类特征向量采取主成分分析(principal component analysis,PCA)特征降维后的样本分布,图6 为基于二分类方法的样本分布,图7 为基于多分类方法的样本分布. 可以看出,打印攻击和展示攻击具有各自的共性欺诈特征,通过多分类能够较好地将这2类样本区分开,使得人脸检测算法能够更好地识别出非活体攻击,从而提升模型的鲁棒性. ...
1
... Performance comparison of different methods on CASIA-FASD and Replay-Attack dataset
Tab.4 方法 Replay-Attack CASIA-FASD EER/% HTER/% EER/% LBP-TOP[29 ] 7.900 7.600 10.000 CNN[14 ] 6.100 2.100 7.400 IDA[6 ] − 7.400 − Motion+LBP[30 ] 4.500 5.110 − Color-LBP[10 ] 0.400 2.900 6.200 MSR-Attention[18 ] 0.210 0.389 3.145 BaseNet-Fusion 1.000 0.500 2.961
表 5 不同方法在OULU-NPU数据集上的性能对比 ...
1
... Performance comparison of different methods on OULU-NPU dataset
Tab.5 方法 APCER/% BPCER/% ACER/% MixedFASNet[1 ] 9.7000 2.5000 6.1000 DeepPixBiS[31 ] 11.4000 0.6000 6.0000 MSR-Attention[18 ] 7.6000 2.2000 4.9000 BaseNet-Fusion 6.6667 2.5000 4.5833
3.4.2. 跨数据集测试 为了进一步验证采取多分类对模型泛化能力的提升,在数据集之间进行交叉验证,一是在CASIA-FASD上训练模型,在Replay-Attack数据集上进行测试;二是在Replay-Attack数据集上训练,在CASIA-FASD数据集上进行测试. 采取EER作为泛化性能的评价指标,实验结果如表6 所示. 可以看出,与采用基于二分类的方法相比,采用基于多分类的方法,ResNet-18和BaseNet网络模型中均有不同程度的错误率下降. ...
Face spoofing detection using colour texture analysis
1
2016
... Cross-testing of different methods under Replay-Attack and CASIA-FASD dataset
Tab.7 方法 EER/% 训练: CASIA 训练: Replay LBP-TOP[29 ] 49.700 60.6000 CNN[14 ] 48.500 39.6000 Color-LBP[10 ] 47.000 39.6000 Color-Texture[32 ] 30.300 37.7000 FaceDs[33 ] 28.500 41.1000 MSR-Attention[18 ] 36.200 34.7000 BaseNet-Fusion 27.875 38.5185
如图6 、7 所示为对BaseNet网络模型提取到的分类特征向量采取主成分分析(principal component analysis,PCA)特征降维后的样本分布,图6 为基于二分类方法的样本分布,图7 为基于多分类方法的样本分布. 可以看出,打印攻击和展示攻击具有各自的共性欺诈特征,通过多分类能够较好地将这2类样本区分开,使得人脸检测算法能够更好地识别出非活体攻击,从而提升模型的鲁棒性. ...
1
... Cross-testing of different methods under Replay-Attack and CASIA-FASD dataset
Tab.7 方法 EER/% 训练: CASIA 训练: Replay LBP-TOP[29 ] 49.700 60.6000 CNN[14 ] 48.500 39.6000 Color-LBP[10 ] 47.000 39.6000 Color-Texture[32 ] 30.300 37.7000 FaceDs[33 ] 28.500 41.1000 MSR-Attention[18 ] 36.200 34.7000 BaseNet-Fusion 27.875 38.5185
如图6 、7 所示为对BaseNet网络模型提取到的分类特征向量采取主成分分析(principal component analysis,PCA)特征降维后的样本分布,图6 为基于二分类方法的样本分布,图7 为基于多分类方法的样本分布. 可以看出,打印攻击和展示攻击具有各自的共性欺诈特征,通过多分类能够较好地将这2类样本区分开,使得人脸检测算法能够更好地识别出非活体攻击,从而提升模型的鲁棒性. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}