

2011年,美国启动“材料基因组计划”(materials genome initiative,MGI),旨在开发基础设计建设以加速先进材料的发现和部署,并装备下一代材料劳动力[1]. 随着MGI的引入,材料与机器学习[2-3]的结合引领着材料开发的新阶段. 现阶段研究人员面对新的挑战,即如何获取机器学习所需要的大量材料数据. 材料数据通常来自计算数据[4]、文献数据[5]、实验数据,甚至来自失败的实验数据[6]. 目前材料领域还没有适合用于材料实体关系抽取研究工作的公开数据集,因此构建材料领域实体关系抽取数据集是首要工作,本研究主要针对喷射沉积的高硅铝合金材料[7]进行实体关系抽取数据集的构建. 材料科学文献的文件一般包括文本格式、图像格式和标记文件格式,通过综合考虑获取数据的难易度和数据结构,最终确定主要收集PDF文本格式的文件来获取材料数据. 在材料领域的专家指导下制定数据集的构建标准,主要是确定标注的主要内容、实体类型以及关系类型. 试用多种标注工具之后决定采用Brat来标注数据,该工具首先须定义标注的格式,然后根据标注的内容生成材料数据,在材料数据收集完成后须对数据进行预处理,包括分句、分词、实体类型标注以及关系类型标注等. 为了解决上述材料关系抽取数据集问题,主要研究内容分为以下3个部分. 1)收集铝硅合金文献,制定铝硅合金关系抽取数据集构建标准. 2)对材料数据进行预处理,构造铝硅合金关系抽取数据集. 3)在铝硅合金实体关系抽取数据集构建完成后,将该数据集以及公开数据集作为实验数据在Bekoulis等[8]提出的多头选择联合抽取模型上进行对比实验. 在得到实验数据后将其与公开数据集进行比较,然后在多头选择联合抽取模型上加入自注意力机制以提升模型在命名实体识别和关系抽取任务上的表现.
1. 实体关系抽取数据集
实体关系抽取任务已经有一些公开的常用数据集,其中几个常用于命名实体识别和关系抽取任务的公共数据集的数据类型和关系类型如表1所示. 表中,Ne、Nr分别为实体数量和关系数量.
表 1 公开数据集实体数量和关系数量的对比
Tab.1
| 数据集 | Ne | Nr |
| CoNLL-2004 | 4 | 5 |
| ACE04 | 7 | 7 |
| ADE | 2 | 1 |
| DERC | 9 | 2 |
CoNLL(conference on computational natural language learning)会议[9]在2004年发布CoNLL-2004数据集[10]用于实体关系抽取任务,可以同时识别实体和抽取关系[11]. ACE(automatic content extraction)也发布了ACE04数据集[12]用于实体识别和关系抽取任务. 在许多特定领域也有用于关系抽取任务的关系抽取数据集,例如化学[13]和生物医学[14]领域,不良药物事件(adverse drug events,ADE)数据集[15]就是属于医学领域的数据集,包含2类实体(Drugs和Diseases)以及1类关系(Drugs-Disease),任务的目的是识别实体的类型并将每种药物与疾病相关联. DREC(Dutch real estate classifieds)数据集[16]中包含9类实体和2类关系.
2. 铝硅合金关系抽取数据集构建标准
当前存在的公开数据集绝大多数是面向通用领域的,在一些特定领域也有部分标注数据集,然而面向材料领域的公开数据集较少. 针对材料领域,本研究参考公开数据集定义的实体类型和实体关系类型来构建铝硅合金关系抽取数据集. 首先在具有铝硅合金研究经验的专家指导下,根据材料科学文献的特点,制定铝硅合金关系抽取数据集构建标准:首先对材料科学文献进行选择,其次确定标注的主要内容,然后进一步确定数据集的实体类型和关系类型. 铝硅合金构建过程整体框架如图1所示.
图 1
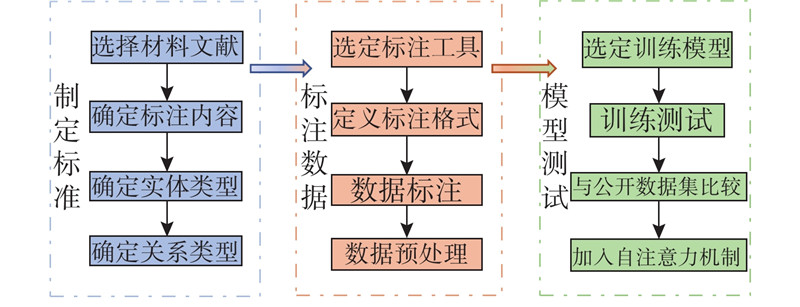
图 1 铝硅合金实体关系抽取数据集整体框架图
Fig.1 Overall framework diagram of extraction dataset of aluminum-silicon alloy entity relationship
2.1. 材料科学文献的选择
材料科学领域研究范围广泛,本研究主要针对铝硅合金在喷射沉积实验中合金的成分、结构、组织、性能之间的相关关系,并对其进行分析和梳理. 通过检索发现材料科学文献的文件类型一般包括文本格式的txt文件(.txt)、doc文件(.doc)、PDF文件(.pdf)、CAJ文件(.caj),图像格式的gif文件(.gif)、jpg文件(.jpg)以及标记文件格式的html文件(.html)和xml文件(.xml). 对比各种材料科学文献的文件类型,pdf格式的文献更容易免费获取;与图像格式的文件相比,也更容易通过pdf格式的文献获取到有效的铝硅合金文献数据. 因此,本研究选择的材料科学文献为铝硅合金喷射沉积实验的相关材料文献,文件格式为pdf.
大部分的科学文献都包含标题、摘要、正文以及参考文献等部分. 其中标题的收集和标注可以为后续工作(例如材料数据库的建设)做铺垫,本研究所须识别的材料实体和抽取的实体关系主要包含在摘要和正文当中. 因此,仅对文献中的标题、摘要和正文进行标注,不考虑标注参考文献,即数据集中不包含铝硅合金材料文献中参考文献的内容.
2.2. 标注的主要内容
在确定文献的格式和文献中须标注的内容后,在铝硅合金的喷射沉积实验文献中,主要关注的是所研究合金的成分、实验过程以及最终的测试结果. 对以下4部分信息进行标注. 1)合金成分. 材料文献会对所研究的合金材料进行概述,包括组成的元素以及元素的含量. 元素含量的表示方法有质量百分比和体积百分比2种,本研究中元素的含量均表示元素的质量百分比. 2)实验过程. 本研究主要关注铝硅合金的喷射沉积实验,标注的实验内容包括喷射沉积实验中各个实验的步骤,以及最终的实验结果. 3)测试结果. 测试部分是在实验完成之后对产品进行性能测试,如表2所示为铝硅合金主要关注的部分性能. 主要标注测试名、测试值、测试图、相. 4)参数. 参数部分主要为实验过程和测试过程中所包含的参数名和参数值.
表 2 铝硅合金主要关注的部分性能
Tab.2
| 性能 | 关键词 | 英文全称 | 缩写 |
| 拉伸 | 抗拉强度 | tensile strength | UTS/Rm/σb |
| 延伸率 | elongation | EL/δ | |
| 硬度 | 维氏硬度 | Vickers hardness | HV |
| 布氏硬度 | Brinell hardness | HB | |
| 洛氏硬度 | Rockwell hardness | HR | |
| 微观组织 | 透射 | transmission electron microscope | TEM |
| 扫描 | scanning electron microscopy | SEM | |
| 光学显微镜 | optical microscope | OM | |
| 电子背散射衍射 | electron back scattering diffraction | EBSD | |
| 热膨胀系数 | − | coefficient of thermal expansion | CTE |
2.3. 实体类型和关系类型
根据制定的标注内容,在材料领域专家的指导下确定须标注的实体类型和关系类型,本研究定义了11种实体类型. 1)合金成分中包括元素、含量、合金3种实体类型;2)实验过程中包括实验、实验结果2种实体类型;3)测试结果中包括测试名、测试值、测试图和相4种实体类型;4)参数中包含2种实体类型,分别为参数名和参数值.
在11种实体类型之间共有13种关系,将13 种关系分为4类关系类型,分别为成分、实验、测试和参数. 1)成分. 包括含量-元素、元素-合金2种关系;2)实验. 包括合金-实验、实验-实验结果、实验-参数名、实验结果-参数名4种关系;3)测试. 包括合金-测试名、测试名-参数名、测试名-测试图、测试名-测试值、测试名-相、相-测试值6种关系;4)参数. 包括参数名-参数值1种关系. 铝硅合金关系抽取数据集中实体类型和关系类型的结构如图2所示.
图 2
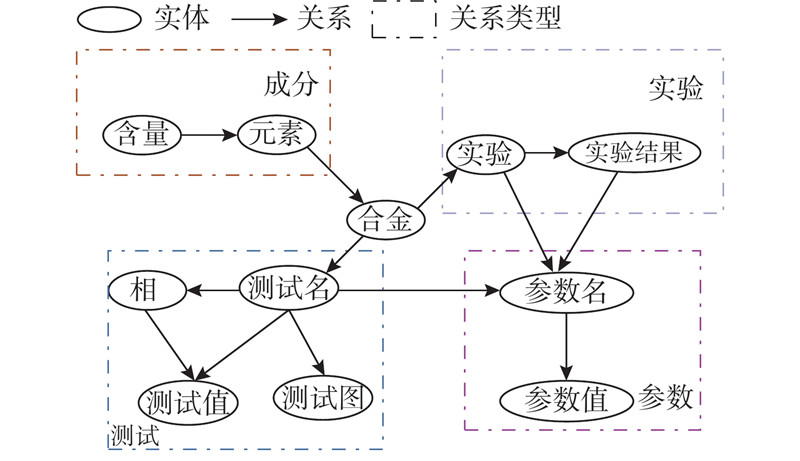
3. 铝硅合金实体关系抽取数据集的数据标注
在确定须标注的实体类型和关系类型之后,开始进行数据标注工作. 将语料库中的每一个句子视为一个序列,序列中的每一个单词视为一个元素,将序列中的每一个元素标注一个标签,即为序列标注(sequence labeling)任务. 常用的序列标注方式包括BIO、BIOSE、IOB等,本研究采用标准的BIO标注方式. 在试用过Prodigy、DeepDive、YEDDA、Brat等标注工具后,采用Brat标注工具来标注语料库中的11种实体类型和13种关系. Brat标注工具用不同颜色来标注不同实体类型,通过将2个实体进行连接来标注出2个实体间的关系,通过手工标注的方式完成实体和关系的标注,如图3所示. 在进行数据标注之前,Brat标注工具要求首先定义标注格式(通过标注工具配置文件进行定义). 在前期的标注过程中发现,实体的英文名称相对较长,会导致标注的工作量无效增加,本研究通过对其英文全称进行简写来定义不同实体类型及关系类型的标注格式(如元素,Element简写为Ele). 11种实体类型和4种关系类型的中文名称、英文名称和对应的标注格式分别如表3、4所示.
图 3
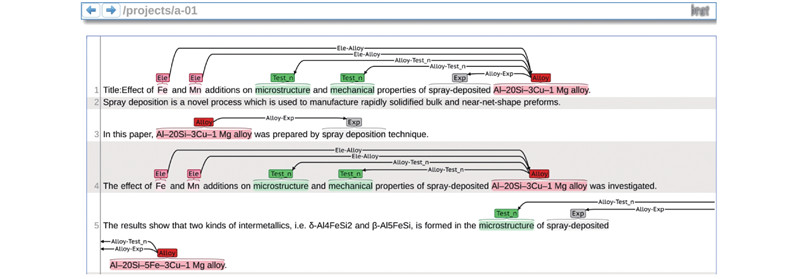
表 3 Brat中实体的标注格式
Tab.3
| 实体 | 英文 | 标注格式 |
| 元素 | Element | Ele |
| 含量 | Content | Con |
| 合金 | Alloy | Alloy |
| 实验 | Experiment | Exp |
| 实验结果 | Experiment_result | Exp_r |
| 参数名 | Parameter_n | Par_n |
| 参数值 | Parameter_v | Par_v |
| 测试名 | Test_n | Test_n |
| 测试值 | Test_v | Test_v |
| 测试图 | Test_f | Test_f |
| 相 | Phase | Phase |
表 4 Brat中关系的标注格式
Tab.4
| 关系类型 | 关系 | 实体1 | 实体2 | 英文 | 标注 |
| 成分 | 含量-元素 | 含量 | 元素 | Content-Element | Con-Ele |
| 成分 | 元素-合金 | 元素 | 合金 | Element-Alloy | Ele-Alloy |
| 实验 | 合金-实验 | 合金 | 实验 | Alloy-Experiment | Alloy-Exp |
| 实验 | 实验-实验结果 | 实验 | 实验结果 | Experiment-Experiment_result | Exp-Exp_r |
| 实验 | 实验结果-参数名 | 实验结果 | 参数名 | Experiment_result-Parameter_n | Exp_r-Par_n |
| 实验 | 实验-参数名 | 实验 | 参数名 | Experiment-Parameter_n | Exp-Par_n |
| 测试 | 合金-测试名 | 合金 | 测试名 | Alloy-Test_n | Alloy-Test_n |
| 测试 | 测试名-参数名 | 测试名 | 参数名 | Test_n-Parameter_n | Test_n-Par_n |
| 测试 | 测试名-测试值 | 测试名 | 测试值 | Test_n-Test_v | Test_n-Test_v |
| 测试 | 测试名-测试图 | 测试名 | 测试图 | Test_n-Test_f | Test_n-Test_f |
| 测试 | 测试名-相 | 测试名 | 相 | Test_n-Phase | Test_n-Phase |
| 测试 | 相-测试值 | 相 | 测试值 | Phase-Test_v | Phase-Test_v |
| 参数 | 参数名-参数值 | 参数名 | 参数值 | Parameter_n-Parameter_v | Par_n-Par_v |
在手工标注完成后,Brat标注工具将自动生成“.ann”和“.conll”2个文件. 通过分词、分句、实体类型标注、关系类型标注等处理方法将2个文件的内容转换为实体关系抽取模型可以读取的格式. 格式结构如图4所示,包括“token_id”、“token”、“BIO”、“relation”和“head”这5列内容:1) “token_id”表示该单词在句子中的顺序号,从0开始计算;2) “token”表示所输入句子中的单词;3) “BIO”表示该实体的实体类型,它也可以表示单词在一种实体类型中的特定位置. 其中“B-实体类型”代表某种类型的实体的开始位置,“I-实体类型”代表某种实体的内部,“O”不代表任何实体类型;4) “relation”表示该token与其他token之间的关系,即构建标准中规定的4类关系类型,不存在关系则为“N”. 在标注时使用13种关系,通过预处理操作,根据关系所属类型分别归类为本研究定义的4类关系类型,分别为composi-tion(成分)、experiment(实验)、parameter(参数)和test(测试). 若该实体具有多种关系,其格式为[“关系1”,“关系2”
图 4
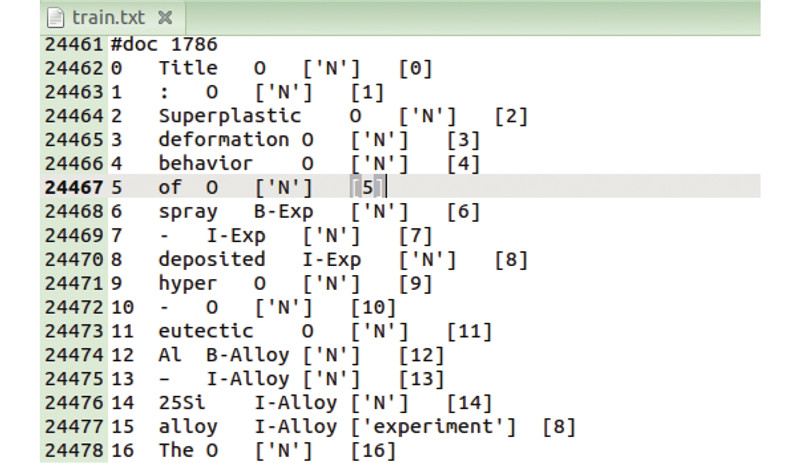
图 4 关系抽取模型读取的数据集格式
Fig.4 Format of dataset read by relational extraction model
4. 铝硅合金关系抽取数据集
本研究所构建的铝硅合金关系抽取数据集共有2246个句子,标注出2522个实体以及1510个关系. 将铝硅合金关系抽取数据集与公开数据集CoNLL-2004进行对比,分别对比数据集的句子数量Ns、Ne、Nr,如表5所示. 可以看出,Al-Si合金关系抽取数据集的整体句子数大于CoNLL-2004数据集的,但实体数仅接近公开数据集实体数的1/2,关系数上也存在一定差距,仍须不断扩充.
表 5 数据集数据量对比
Tab.5
| 数据集 | Ns | Ne | Nr |
| CoNLL-2004 | 1441 | 5347 | 2020 |
| Al-Si合金关系抽取数据集 | 2246 | 2522 | 1510 |
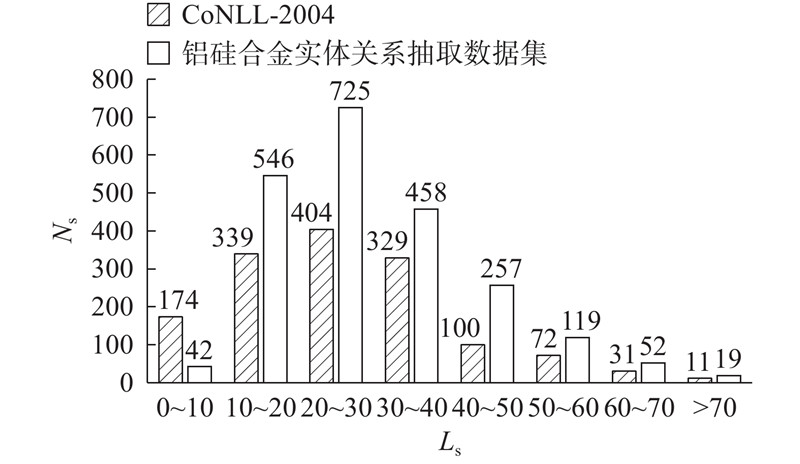
由于句子的长度会对关系抽取模型产生影响,本研究将2个数据集的句子长度也进行对比. 2个数据集的句子的长度的对比如图5所示. 图中,Ls为句子长度,单位为词数. 可以看出,Al-Si合金关系抽取数据集中长度小于10的句子的数量明显少于公共数据集中的,而长度大于10的句子的数量均高于公共数据集中的.
图 5
本研究对铝硅合金实体关系抽取数据集实体类型及关系类型进行示例,分别如表6、7所示,可以看出Al-Si合金关系抽取数据集中数据类型的多样性以及对象的复杂性. 在表7中的关系类型示例中,可以看到句子中存在多个实体以及多个关系. 如果成分(元素-合金)、实验(实验-参数名)、测试(测试名-测试值)和参数(参数名-参数值)中的实体数均超过2个,存在的关系数则不为1,这将导致关系重叠问题. 如实验(实验-参数名)中的实体1(solidification process)与多个实体具有关系,参数(参数名-参数值)中的实体1(testing temperatures)也与多个实体具有关系,这2个句子都存在关系重叠问题. 本研究所采用的多头选择联合抽取模型可以有效解决关系重叠问题.
表 6 铝硅合金关系抽取数据集的实体类型示例
Tab.6
| 实体类型 | 示例 |
| 含量 | However, 3% Mn addition leads to a substantial improvement of the tensile strengths at elevated temperature. |
| 元素 | However, 3% Mn addition leads to a substantial improvement of the tensile strengths at elevated temperature. |
| 合金 | In this paper, Al-20Si-3Cu-1Mg alloy was prepared by spray deposition technique. |
| 实验 | In this paper, Al-20Si-3Cu-1Mg alloy was prepared by spray deposition technique. |
| 实验结果 | Cylindrical samples of 25 mm in diameter and 50 mm in length were machined out from each spray deposit obtained. |
| 测试名 | Fig.1(c) shows the scanning electron microscopy microstructure of the spray-deposited A2 alloy. |
| 测试值 | From table 2, with additions of 5% Fe to Al-20Si-3Cu-1Mg alloy, both the yield and ultimate tensile strengths was increased 55 and 64 MPa at room temperature. |
| 测试图 | Fig.1(c) shows the scanning electron microscopy microstructure of the spray-deposited A2 alloy. |
| 相 | The formation of b-Al5FeSi phase in this transformation is known to be very slow. |
| 参数名 | The testing temperatures were 298, 473 and 573 K. |
| 参数值 | The testing temperatures were 298, 473 and 573 K. |
表 7 铝硅合金关系抽取数据集的关系类型示例
Tab.7
| 关系类型 | 示例 |
| 成分 | 1.(含量-元素)However, 3%(1)Mn(2) addition leads to a substantial improvement of the tensile strengths at elevated temperature. |
| 2.(元素-合金)Effect of Fe(1) and Mn(1) additions on microstructure and mechanical properties of spray-deposition Al-20Si-3Cu-1Mg alloy(2). | |
| 实验 | 1.(合金-实验)In this paper, Al-20Si-3Cu-1Mg alloy(1) was prepared by spray deposition(2) technique. |
| 2.(实验-实验结果)Cylindrical samples(2) of 25 mm in diameter and 50 mm in length were machined out from each spray deposit obtained(1). | |
| 3.(实验-参数名)The solidification process(1) during spray-deposition occurs in two stages: gas atomization (rapid cooling)(2)and droplet consolidation (relatively slow cooling)(2). | |
| 4.(实验结果-参数名)The starting carbon particle(2) were as large as 50 mm, while the TiC particles are less than 0.7 mm in reacted preforms(1). | |
| 测试 | 1.(合金-测试名)The UTSs(2) of the TiC/Al(1) composites were improved over that of the unreinforced Al matrix |
| 2.(测试名-参数名)As shown in Table 2, the UTS(1) of the TiC/Al composites at room temperature(2) was improved over that of the unreinforced Al matrix. | |
| 3.(测试名-测试值)From table 2, with additions of 5% Fe to Al-20Si-3Cu-1Mg alloy, both the yield(1) and ultimate tensile strengths(1) was increased 55(2)and 64 MPa(2) at room temperature. | |
| 4.(测试名-测试图)Fig.1(c)(2) shows the scanning electron microscopy microstructure(1) of the spray-deposited A2 alloy. | |
| 5.(测试名-相)The high volume fraction of metastable d-Al4FeSi2 phase(2) in the spray-deposited microstructure(1) may be attributed to two primary reasons. | |
| 6.(相-测试值)The microstructure of the as-deposited alloy is composed of primary Si (1) with an average size of 12.5 µm(2) and secondary Al phase. | |
| 参数 | 1.(参数名-参数值)The testing temperatures(1) were 298(2), 473(2) and 573 K(2). |
5. 实 验
在多个角度进行对比实验. 具体来说,分别在多头选择联合抽取模型(Multi-head)和基于自注意力的多头选择联合抽取模型(att_Multi_head)上进行命名实体识别(named entity recognition,NER)实验和关系抽取(relation extraction,RE)任务,之后测算铝硅合金实体关系联合抽取数据集在该模型上的精确率(Precision,Pr)、召回率(Recall,Re)、F1值.
5.1. 评估指标
材料实体关系抽取任务的模型评价指标使用Precision、Recall和F1值. 精确率表示模型预测为正的样本中实际上是正样本的比例,召回率表示所有样本中的正样本被模型正确预测的比例. F1值由精确率和召回率的加权几何平均值得到,是平衡准确率和召回率的综合指标. 精确率、召回率和F1值的表达式如下:
式中:T为一类实体被正确分类的实际个数,S为被识别为这一类实体的样本总数,A为样本中的实体实例总数.
5.2. 实验环境
实验是在一台ubuntu操作系统的服务器下运行的,其CPU为Inter Xeon Gold 5120 (56) CPU @2.2 GHz,GPU为Tesla V100,空间大小为16 GB,运行内存大小为256 GB. 使用GPU对模型进行加速运算,所使用的Al-Si合金实体关系联合抽取模型是一个参数较多的深度学习模型,使用GPU可以提高运算速度.
该模型使用的深度学习框架为Tensorflow,其采用数据流图的形式来进行数值计算. 实验的运行环境及版本号如表8所示,其中CUDA与cuDNN用于支持GPU下的Tensorflow框架.
表 8 实验运行环境及版本号
Tab.8
| 安装包 | 版本 | 安装包 | 版本 | |
| CUDA | 10.2 | numpy | 1.19.4 | |
| CuDNN | 7.6.5 | sklearn | 0.22 | |
| Python | 3.6.12 | prettytalbe | 0.7.0 | |
| Tensorflow | 1.15.0 | pandas | 0.24.2 | |
| gensim | 3.4.0 | − | − |
5.3. 实验结果与分析
分别进行4组实验,分别对数据集和实体关系联合抽取模型在数据集上的性能进行多方面的评估.
5.3.1. 实验1
Multi-head在铝硅合金关系抽取数据集和CoNLL-2004数据集上的对比实验. 为了测试铝硅合金关系抽取数据集相较于公开数据集在常用关系抽取模型上的表现,分别将铝硅合金关系抽取数据集和CoNLL-2004数据集作为实验数据,将数据嵌入到多头选择联合抽取模型上进行实体关系联合抽取实验,实验结果如表9所示.可以看出,CoNLL-2004数据集在多头选择实体联合抽取模型上的表现比铝硅合金实体关系抽取数据集更好. 这主要是由于铝硅合金实体关系抽取数据集存在语义与语法复杂和长句子相对公共数据集更多的客观问题,导致其实验结果略低于公开数据集. 但本研究所提出的实体关系抽取数据集的构建方法可以广泛应用于材料领域,对材料领域的数据集构建具有一定的参考价值和实际应用价值.
表 9 数据集实验结果对比
Tab.9
| 数据集 | NER任务 | RE任务 | 总体 | ||||||
| Pr | Re | F1 | Pr | Re | F1 | F1 | |||
| 本研究数据集 | 66.2 | 61.7 | 63.9 | 53.5 | 44.2 | 48.5 | 56.2 | ||
| CoNLL-2004 | 67.7 | 68.7 | 68.2 | 54.1 | 47.8 | 54.8 | 61.5 | ||
5.3.2. 实验2
自注意力机制对铝硅合金实体关系联合抽取模型性能影响的对比实验. 在多头选择实体联合抽取模型的基础上加入了自注意力机制,用来提升模型在数据集上的表现. 对Multi-head模型与att_Multi_head模型进行对比实验. att_Multi_head在Multi-head的基础上进行改进,在编码层加入了自注意力机制. 通过对2个模型的实验结果进行对比,判断自注意力机制对铝硅合金实体关系联合抽取模型性能的影响. att_Multi_head模型的参数与Multi-head模型参数基本保持一致,仅额外增加了参数自注意力层的神经元保留率(Dropout att),并将该参数的值设置为0.5. 实验结果如表10所示. 可以看出,在基础模型的基础上加入自注意力机制可以有效提升Al-Si合金实体关系联合抽取模型的性能. 对比2组实验结果,基于自注意力机制的联合抽取模型的整体F1值达到了62.0%,较基础模型提高了5.8%. 其中,基于自注意力机制的联合抽取模型在NER任务中的F1值提升了3.8%,RE任务的F1值提升了7.8%. 实验证明,基于自注意力机制的Al-Si合金实体关系联合抽取模型能够更好地捕捉Al-Si合金材料科学文献中句子的依赖关系.
表 10 Multi-head模型与att_Multi_head模型实验结果对比
Tab.10
| 模型 | NER任务 | RE任务 | 总体 F1 | |||||
| Pr | Re | F1 | Pr | Re | F1 | |||
| att_Multi_head | 71.3 | 64.4 | 67.7 | 65.2 | 49.5 | 56.3 | 62.0 | |
| Multi-head | 66.2 | 61.7 | 63.9 | 53.5 | 44.2 | 48.5 | 56.2 | |
| 对比 | +5.1 | +2.7 | +3.8 | +11.75 | +5.3 | +7.8 | +5.8 | |
5.3.3. 实验3
表 11 NER任务中各类实体的实验结果
Tab.11
| 实体 | TP | FP | FN | Pr/% | Re/% | F1/% |
| Con(含量) | 15 | 0 | 0 | 1.00 | 1.00 | 1.00 |
| Ele(元素) | 18 | 5 | 3 | 78.26 | 85.71 | 81.81 |
| Alloy(合金) | 37 | 8 | 10 | 82.22 | 78.72 | 80.43 |
| Exp(实验) | 36 | 13 | 13 | 73.46 | 73.46 | 73.46 |
| Exp_r(实验结果) | 0 | 0 | 1 | 0 | 0 | 0 |
| Test_n(测试名) | 52 | 23 | 29 | 69.33 | 64.19 | 66.66 |
| Test_v(测试值) | 6 | 7 | 12 | 46.15 | 33.33 | 38.70 |
| Test_f(测试图) | 18 | 9 | 9 | 66.66 | 66.66 | 66.66 |
| Phase(相) | 31 | 9 | 14 | 77.50 | 68.88 | 72.94 |
| Par_n(参数名) | 13 | 10 | 23 | 56.52 | 36.11 | 44.06 |
| Par_v(参数值) | 13 | 11 | 18 | 54.16 | 41.93 | 47.27 |
| 总计 | 239 | 95 | 132 | 71.34 | 64.44 | 67.71 |
表 12 RE任务中各类关系的实验结果
Tab.12
| 关系 | TP | FP | FN | Pr/% | Re/% | F1/% |
| composition(成分) | 22 | 7 | 9 | 75.86 | 70.96 | 73.33 |
| experiment(实验) | 29 | 12 | 17 | 70.73 | 63.04 | 66.66 |
| test(测试) | 50 | 30 | 63 | 62.50 | 44.24 | 51.81 |
| parameter(参数) | 8 | 9 | 23 | 54.16 | 41.93 | 47.27 |
| 总计 | 109 | 58 | 112 | 65.27 | 49.55 | 56.33 |
由表11的实验结果可以看出:1)Con(含量)、Ele(元素)和Alloy(合金)3种类型的实体的测试指标较高,一方面是因为数据集中合金的含量大多以百分比的形式存在,形式相对简单,另一方面是由于这3类实体的关联性较高. 2)Al-Si合金实体关系抽取数据集中标注的Exp_r(实验结果)类型的实体数量较少,导致随机分配的测试集中只有1个Exp_r实体,3个评估指标均为0,无法进行有效的测试. 本研究仅对文献中的文本数据进行关系抽取,而材料文献中实验结果绝大多数以数值的形式书写,同时保存在表格当中. 因此,该问题是由研究对象本身存在的客观原因导致的. 3)Test_v(测试值)的测试指标较低,一方面是因为数据集中该类型实体数量较少,另一方面是因为测试值中既有数值也有相应的单位,单位的多样性也导致了该类型实体的测试指标较低. 4)Par_n(参数名)同样是由于数据中实体数量较少所导致的测试指标较低. 而Par_v(参数值)与Test_v(测试值)相同,由于实体数量少和单位的多样性导致测试指标低.
由表12的实验结果可以看出:1)composition(成分)的测试指标较高是由于该种关系涉及到的实体识别效果较好,与此同时其关联性较高. 2)本研究已经明确对Al-Si合金的喷射沉积实验文献进行关系抽取, experiment(实验)中主要为挤压、雾化和沉积等实验过程,因此关系类型为实验的测试指标较高. 3)test(测试)中包括合金-测试名、测试名-参数名、测试名-测试值、测试名-测试图、测试名-相以及相-测试值6种关系,种类较多导致该类关系的召回率较低. parameter(参数)的测试指标较低是因为数据集中该类关系数量较少.
5.3.4. 实验4
模型的平均耗时对比实验. 对比基础模型和基于自注意力机制的联合模型的平均开销时间,基础模型的开销时间为122.37 s,基于自注意力机制的联合模型开销时间为150.49 s. 由实验结果可以看出,基于自注意力的联合模型的开销时间与基础模型相比耗时较高. 原因是增加的Attention层加大了模型的计算量.
6. 结 语
实体关系抽取技术可以帮助材料基因组研究人员方便地获取大量材料数据,但是目前没有适合用于铝硅合金实体关系抽取研究工作的公开数据集. 本研究提出一种构建铝硅合金实体关系抽取数据集的方法,给出该数据集的构建过程,以及构建后的数据集结构. 铝硅合金实体关系抽取数据集中共包括2346个句子,2522个实体,1510种关系,可以同时进行实体识别任务和关系抽取任务.
本研究将构建完成的铝硅合金实体关系抽取数据集与CoNLL-2004数据集作为实验数据,在多头选择关系抽取模型上对数据集进行对比实验,基于铝硅合金实体关系抽取数据集存在语义与语法复杂和长句子多于公共数据集的特点,在基础模型上加入了自注意力机制,并进行了2组实验进行评估指标的对比,使模型在命名实体识别任务中的Pr、Re和F1值分别提升了约5.1%、2.7%、3.8%,在关系抽取任务中Pr、Re和F1值分别提升了约11.75%、5.3%和7.8%.
实验结果表明,铝硅合金实体关系抽取数据集可以为实体关系抽取任务提供实验数据. 本研究所提出的铝硅合金实体关系抽取数据集构建方法具有普适性,可以采用该方法构建材料领域数据集. 所构建的数据集可以为材料领域的实体关系抽取研究任务提供数据支撑,具有广阔的应用前景和实际的应用价值.
本研究主要将重心放在铝硅合金实体关系抽取数据集的构建方面,对数据集只进行了少量的实验测试与对比,因此在实验方面略显不足. 下一步将对数据集在不同的深度学习模型上进行实验并对实验结果进行对比,根据实验结果对深度学习模型进行不断优化,同时对数据集进行扩充,以期实现深度学习模型在铝硅合金材料相关领域中的应用.
参考文献
Can artificial intelligence create the next wonder material?
[J].
Fundamentals, materials, and machine learning of polymer electrolyte membrane fuel cell technology
[J].DOI:10.1016/j.egyai.2020.100014 [本文引用: 1]
Big-data science in porous materials: materials genomics and machine learning
[J].DOI:10.1021/acs.chemrev.0c00004 [本文引用: 1]
Fulfilling the promise of the materials genome initiative with high-throughput experimental methodologies
[J].DOI:10.1063/1.4977487 [本文引用: 1]
Materials synthesis insights from scientific literature via text extraction and machine learning
[J].DOI:10.1021/acs.chemmater.7b03500 [本文引用: 1]
Machine-learning-assisted materials discovery using failed experiments
[J].DOI:10.1038/nature17439 [本文引用: 1]
Microstructures and properties of Si-Al alloy for electronic packaging prepared by spray deposition technique
[J].
Joint entity recognition and relation extraction as a multi-head selection problem
[J].DOI:10.1016/j.eswa.2018.07.032 [本文引用: 1]
Introduction to the CoNLL-2002 shared task: language-independent named entity recognition
[J].
Author correction: text-mined dataset of inorganic materials synthesis recipes
[J].DOI:10.1038/s41597-019-0297-x [本文引用: 1]
Exploiting sequence labeling framework to extract document-level relations from biomedical texts
[J].DOI:10.1186/s12859-019-3325-0 [本文引用: 1]
Development of a benchmark corpus to support the automatic extraction of drug-related adverse effects from medical case reports
[J].DOI:10.1016/j.jbi.2012.04.008 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}