

手势作为一种简单且易表达的交流方式,在人机交互中,手势信息能够为用户提供更真实、自然的交互体验[1]. 早期,由于硬件和算法的不成熟,对手势识别的研究需要系统构建[2],例如使用数据手套来识别手势,但是数据手套设备过于昂贵,无法与人手实现良好接触,导致识别过程变得复杂. 随着计算机性能的发展和硬件水平的提高,基于视觉的手势识别引起了研究人员的关注[1],相较于数据手套,视觉手势识别设备简单,易于维护. 在基于视觉的手势识别方面,传统方法更多地依赖于图像处理算法和先验知识. 在实际应用中,手势多处于复杂环境下,使得传统的手势识别方法在手势分割上面存在本体与背景之间的不易分割性,导致手势在识别方面难度增加. 随着深度学习的发展,传统方法在复杂背景下识别的困难逐渐减小,研究人员提出高精度的网络结构,例如R-CNN(区域卷积神经网络)[3]、SPP-Net网络(空间金字塔池化网络)[4]和FasterR-CNN[5]等. 这些算法在不断追求高精度的同时,忽视了算法所带来的大量参数. 如果应用到移动端设备,那么除了高精度之外,计算复杂度是需要考虑的重要指标. 研究人员提出一些端到端的深层神经网络,例如,Liu等[6-7]提出SSD(单镜头多盒检测器)和YOLO,以提高检测速度. 当这些模型应用于移动端平台时,速度会明显下降. 原因是由于移动端平台的计算能力和内存资源有限,GPU的性能远远低于PC端,前者的性能至少比后者低1/10. 为了满足移动端和嵌入式平台的应用需求,一些轻量级的卷积神经网络如MobileNet[8]和ShuffleNet[9]等被提出,研究人员对这些轻量级的卷积模型进行了改进,使其在精度和速度之间作了很好的平衡.
目前,YOLOv3[10]是单阶段目标检测方面最受欢迎的一种检测框架,在检测精度和速度方面处于领先地位,在准确度和速度之间达到了很好的均衡效果. 原始YOLOv3模型中的主干网络Darknet-53参数量大,模型占用内存量较大,计算复杂度高,对硬件的计算能力需求大. 针对上述问题,本文提出采用轻量化网络ShuffleNetv2[11]来代替YOLOv3模型中的主干网络DarkNet-53. ShuffleNetv2是一种在ShuffleNetv1及MobileNetv2[12]基础上通过分析两者缺陷进行改进的轻量化网络,具有精度高、速度快的优点. 将轻量化ShuffleNetv2网络集成到YOLOv3模型中构成ShuffleNetv2-YOLOv3模型,使构成的ShuffleNetv2-YOLOv3模型能够在满足检测精度的同时提高模型的检测速度,保证模型准确度与检测速度之间的均衡,最小化网络模型的体积,减小模型对硬件的计算能力需求.
1. ShuffleNetv2-YOLOv3模型原理
1.1. YOLOv3模型原理
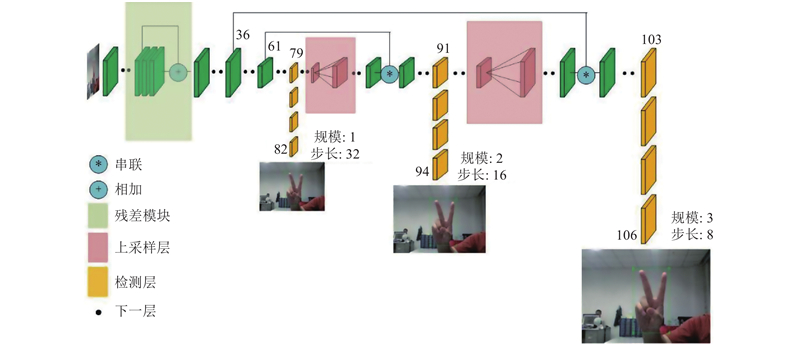
YOLO算法是由Redmon等[7]提出的. 该算法的核心思想是将目标检测任务转化为回归问题,大幅度提高了目标检测的精度和速度. 由于整个网络结构是一个单一的过程,可以直接对目标的检测性能进行端到端的优化. YOLOv3是在YOLOv2[13]的基础上提出的,在保证YOLOv2检测速度的同时,极大地提高了检测精度. YOLOv3是一个完全卷积的网络结构,采用新的主干网络来提取图像特征;借鉴了YOLOv2中Darknet-19的网络结构,通过引用一些其他的残差网络,由连续的1×1和3×3卷积层组合而成,包括大量的短路连接. 通过叠加这些残差网络,组成新的主干网络. 主干网络有53个卷积层,被称为Darknet-53.
在YOLOv3中,使用了Darknet-53前面的52层(未使用全连接层). 为了降低池化带来的梯度负面效果,直接摒弃了池化层,通过使用卷积层的步长来实现降采样. 为了提高算法对小目标检测的精确度,YOLOv3中采用类似FPN[14](特征金字塔)的上采样和融合做法;融合3个尺度,在这3个尺度上进行检测,3个尺度的大小分别为13×13、26×26和52×52,对应小、中、大尺度的目标. 在3个尺度上的Feature map上进行检测. 在类别预测上,使用多标签分类预测包围框可能包含的类. 由于Softmax分类器的性能表现不好,使用独立的Logistic分类器. 在训练过程中,采用二进制交叉熵损失进行类预测. YOLOv3采用残差网络的思想. 多个叠加的残差网络模块的引入和多尺度预测的使用,改善了YOLOv2网络在小目标识别上的缺点. 由于检测的准确性和实时性高,目前该算法是目标检测中最好的算法之一,YOLOv3网络的模型结构如图1所示.
图 1
1.2. ShuffleNetv2-YOLOv3模型设计
由于原始的YOLOv3采用自定义主干网络Darknet-53,该模型的计算复杂度高,对硬件的存储空间要求高. 在原始YOLOv3模型的基础上,提出轻量级的实时目标检测神经网络模型ShuffleNetv2-YOLOv3网络,ShuffleNetv2-YOLOv3模型的整体结构如图2所示.
图 2
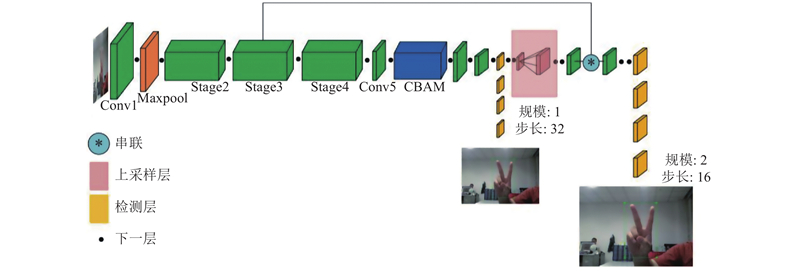
图 2 ShuffleNetv2-YOLOv3模型的整体结构
Fig.2 Overall structure of ShuffleNetv2-YOLOv3 model
ShuffleNetv2-YOLOv3是基于回归思想的端到端的检测框架,将ShuffleNetv2代替Darknet-53作为YOLOv3的主干网络. ShuffleNetv2是基于移动设备而设计的轻量级神经网络,研究模型的复杂度和运行速度以及ShuffleNetv1和MobileNetv2的运行时间. 针对轻量化网络的设计,对ShuffleNetv1进行以下改进. 1)使用1×1卷积代替1×1组卷积. 2)在模块开始时引入新的运算:Channel split. 3)在短路连接中采用串联运算代替加法操作. 该网络中利用不断重复的1×1和3×3卷积来提取特征,采用短路连接来增加网络深度. 在每个短路连接前加入Channel split操作,有效地提高了卷积网络的计算效率,减少庞大的参数. 在短路连接之后加入Channel shuffle模块以混合特征,提高了卷积网络模型的检测精度. Channel split和Channel shuffle的应用,减小了模型的计算复杂度,降低了模型的内存占用率,极大地提高了模型的计算效率.
针对ShuffleNetv2中单元块的下采样,不再采用Channel split,而是直接按原始输入,但每个分支都采用步长为2的深度卷积进行下采样,在之后增加一个1×1卷积进行通道数的调整. 合并在一起后,特征图空间大小减半,但是通道数翻倍.
在ShuffleNetv2-YOLOv3模型的主干网络设计中,由于ShuffleNetv2中设定了每个块的输出通道数,通道数决定模型的复杂程度,如表1所示. 表中,Os为输出尺寸大小,Ks为卷积核尺寸大小,S为步长,R为每一层级叠加次数,Oc为输出通道数. 为了在模型的精度与速度上达到最佳的效果,对每个通道数进行实验对比,确定高质量的模型.
表 1 ShuffleNetv2的网络结构
Tab.1
| 层级 | Os | Ks | S | R | Oc | |||
| 0.5× | 1.0× | 1.5× | 2.0× | |||||
| Image | 416×416 | — | — | — | 3 | 3 | 3 | 3 |
| Conv1 MaxPool | 208×208 104×104 | 3×3 3×3 | 2 2 | 1 1 | 24 24 | 24 24 | 24 24 | 24 24 |
| Stage2 Stage2 | 52×52 52×52 | — — | 2 1 | 1 3 | 48 48 | 116 116 | 176 176 | 244 244 |
| Stage3 Stage3 | 26×26 26×26 | — — | 2 1 | 1 7 | 96 96 | 232 232 | 352 352 | 488 488 |
| Stage4 Stage4 | 13×13 13×13 | — — | 2 1 | 1 3 | 192 192 | 464 464 | 704 704 | 976 976 |
| Conv5 | 13×13 | 1×1 | 1 | 1 | 1024 | 1024 | 1024 | 2048 |
| GlobalPool | 1×1 | 13×13 | — | — | — | — | — | — |
| FC | — | — | — | — | 1000 | 1000 | 1000 | 1000 |
在改进模型中,采用K-means聚类算法重新选择自制数据集的Anchors先验框的长宽比和数量,使其对目标进行精确定位,提高模型的检测精度. 为了能够让模型更关注于目标特征信息,在网络的颈部(主干网络与检测层之间)加入CBAM[15]注意力机制模块来增强网络对空间和通道的关注度,提高模型的精度,保证检测的准确性. CBAM是结合空间和通道的用于前馈卷积神经网络的简单而有效的注意力机制模块. 该模块的主要工作方式如下:给定中间特征图,它会沿着空间和通道这2个独立的维度去依次推断注意力图,将注意力图与输入特征图相乘,进行自适应特征优化. 由于CBAM是轻量级的通用模块,可以将该模块的开销忽略不计,将CBAM模块无缝集成到ShuffleNetv2-YOLOv3模型中,使其可以与主干网络一起进行端到端训练.
在该模型的检测层中,沿用原始YOLOv3的检测层在每个尺度中预测3个先验框,对于自制数据集的类别数,张量元素个数为
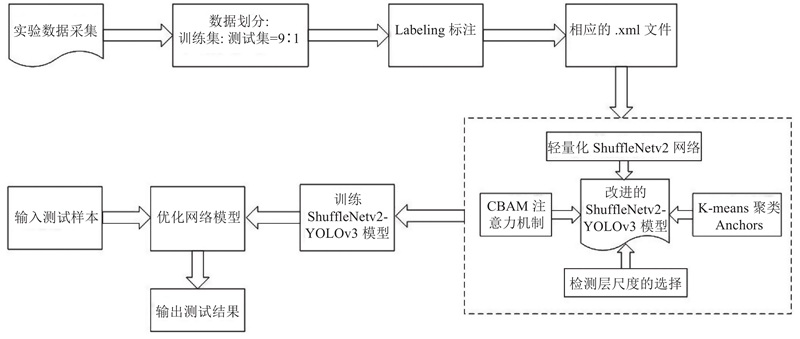
在ShuffleNetv2-YOLOv3模型的设计过程中,将原始的YOLOv3骨干网络Darknet-53用轻量化网络ShuffleNetv2代替. 在网络的颈部加入CBAM注意力机制模块,增强网络对空间和通道的关注度. 通过实验验证以及K-means重新聚类Anchors的尺寸分析可知,在网络的检测层采用2种尺度进行检测. 利用提出模型进行手势识别的流程如图3所示.
图 3
2. 数据集制作与前期准备
2.1. 手势数据集
自制手势数据集通过采用OpenCV库调用摄像头Lenovo EasyCamera进行,每3秒捕获一张图像. 所收集的图像是在不同背景下,通过在拍摄过程中不断调整手势,比如转动一定角度、手指稍微变形等方法,在适当范围内通过前、后移动手势来调整手势与摄像头之间的距离,以增强采集样本的多样性. 自制数据集采集5名不同人员的手势,每名人员共6种手势,它们代表数字手势中0~5的含义,每个类大约有500个样本,总共3 000张图片,每张图片的大小为640×480. 手势数据集的部分样例如图4所示.
图 4

在Microsoft Kinect and Leap Motion数据集中,RGB图像通过微软Kinect设备采集. 数据集中的一部分手势来自美国ASL数据集中的手势. 该数据集包含14个不同的人执行的手势,每个人执行10个不同的手势,每个手势重复10次,总共1 400个手势. 每张图片的大小是1 280×960. 数据集中的部分样例如图5所示.
图 5

图 5 Microsoft Kinect and Leap Motion数据集样例
Fig.5 Samples of Microsoft Kinect and Leap Motion dataset
在Creative Senz3D数据集中,RGB图像由Creative Senz3D相机的RGB摄像头采集得到. 该数据集包含由4个不同的人执行的手势,每个人员执行11个不同的手势,每个手势重复30次,总共有1 320个样本. 每张图片的大小是640×480,数据集中的部分样例如图6所示.
图 6

2.2. 评价指标
本文方法的目的主要是在保证模型精度和速度的同时,减少模型的训练时间和模型内存占比. 在通过mAP(mean average precision)和FPS(frame per second)对模型的测试性能进行评价的同时[20],考虑模型的训练时间和模型内存占比. 具体的表达式如下:
式中:P为准确率,R为召回率,TP为真阳性样本数,FP为假阳性样本数,FN为假阴性数样本. AP表示P-R曲线下的面积,综合考虑精确率和召回率的影响,反映了模型对不同种类识别的好坏程度. mAP表示每个类别AP的平均值,表达在所有类别上的平均好坏程度. FPS表示每秒帧率,即每秒内可以处理的图片数,它用来评估目标检测的速度. 训练时间(training time,TT)是模型从开始迭代到完成设定总迭代次数为之止. 模型内存占比Ws(weight size)表示模型训练完成后的检测权重.
2.3. 算法训练操作环境
本文算法训练的硬件环境如表2所示. 搭建的软件环境如下:Ubuntu16.04、Python、OpenCV和CUDA10.0,框架使用Pytorch和YOLOv3框架.
表 2 算法训练硬件环境配置
Tab.2
| 硬件名称 | 型号 | 数量 |
| Main board | Asus WS X299 SAGE | 1 |
| CPU | Intel I9-9900X | 20 |
| Memory | The Corsair 32 GB DDR4 | 2 |
| CUDA | Geforce RTX 2080Ti | 4 |
| Solid-state drives | Corsair 4.0T | 4 |
| Hard disk | Western digital 976.5 GB | 1 |
3. 实验结果与分析
在模型训练中,手势数据集采用2.1节的自制数据集,数据集大小为3 000张手势图片. 手势数据集的划分采用训练集与测试集,按9∶1的比例进行. 网络输入图像大小为416×416,采用Adam优化器,批处理大小为32,动量因子为0.9,训练迭代300次,最初将学习率设置为10−3,在100次迭代和200次迭代时衰减10倍. 使用随机翻转和调整对比度的数据增强方法,为了减少参数数量,没有使用ImageNet数据集进行预训练,以避免不必要的特征表示[21]. 实验结果表明,无需进行ImageNet预训练,改进模型可以达到与基于ImageNet预训练模型相当的性能. 采用比较实验的方法,利用网络模型YOLOv2、Dar-knet53-YOLOv3、ResNet50-YOLOv3、YOLOv3-ti-ny及其他2种轻量型网络SSD-MobileNetv2、Mob-ileNetv2-YOLOv3[22]与ShuffleNetv2-YOLOv3进行比较实验,对改进模型的性能进行测试,验证改进模型在不同数据集上的有效性.
3.1. ShuffleNetv2输出通道的选择
如表1所示,在轻量化网络ShuffleNetv2的结构中,设定了每个Block的输出通道数,如0.5×、1.0×、1.5×等,可以通过输出通道数调整模型的复杂度. 为了选择模型精度高且内存占比小的结构,将每个Block的输出通道数在ShuffleNetv2-YOLOv3模型上进行训练,模型采用自制数据集进行训练. 模型训练完成后,测试的结果如表3所示. 表中,v为检测速度. 不同主干网络的mAP和模型所占内存大小都不断增加,相对来说,检测速度变化不大. 当在模型中加入CBAM注意力机制后,如表4所示, ShuffleNetv2-1.0×作为主干网络时的mAP最大,达到99.2%. 其他几种因素,如训练时间、模型所占内存大小和检测速度也有较好的优势. 考虑到精度与速度的均衡性和嵌入式设备所需要的内存占比等特性,选择ShuffleNetv2-1.0×作为所需要的主干网络.
表 3 ShuffleNetv2不同的输出通道数之间的测试结果
Tab.3
| 网络模型 | 主干网络 | mAP | TT/h | Ws /MB | v /(帧·s−1) |
| YOLOv3 | ShuffleNetv2-0.5× | 0.952 | 1.482 | 9.7 | 45 |
| YOLOv3 | ShuffleNetv2-1.0× | 0.966 | 1.481 | 14.6 | 45 |
| YOLOv3 | ShuffleNetv2-1.5× | 0.972 | 1.493 | 20.6 | 44 |
| YOLOv3 | ShuffleNetv2-2.0× | 0.978 | 1.645 | 36.0 | 43 |
表 4 ShuffleNetv2+CBAM不同的输出通道数的测试结果
Tab.4
| 网络模型 | 主干网络 | mAP | TT/h | Ws /MB | v /(帧·s−1) |
| YOLOv3+CBAM | ShuffleNetv2-0.5× | 0.979 | 1.587 | 10.2 | 44 |
| YOLOv3+CBAM | ShuffleNetv2-1.0× | 0.992 | 1.594 | 15.1 | 44 |
| YOLOv3+CBAM | ShuffleNetv2-1.5× | 0.990 | 1.620 | 21.1 | 43 |
| YOLOv3+CBAM | ShuffleNetv2-2.0× | 0.987 | 1.680 | 36.5 | 43 |
3.2. 检测层尺度大小的选择
基于YOLOv3本身预测3种不同尺度上的先验框,预测每种尺度上的3个先验框. 沿用YOLOv3在不同尺度上预测的3个先验框,通过结合自制数据集和K-means算法对Anchors进行重新聚类[23- 24]. 9个Anchors和6个Anchors对模型精度的效果如表5所示. 在原始YOLOv3模型中,只更改了主干网络后,可以看出,2种不同的Anchors数量的mAP仅相差0.002,相对来说,6个Anchors的训练时间、模型所占内存大小和检测速度都优于9个Anchors. 在网络中加入CBAM注意力模块机制后,6个Anchors的mAP相较而言高出1个百分点,在其他因素上也优于9个Anchors. 通过实验分析,选定6个Anchors,即采用2种尺度检测层.
表 5 不同Anchors对模型精度的测试结果
Tab.5
| 网络模型 | 主干网络 | mAP | TT/h | Ws /MB | v /(帧·s−1) |
| YOLOv3+6Anchors | ShuffleNetv2-1.0× | 0.966 | 1.481 | 14.6 | 45 |
| YOLOv3+9Anchors | ShuffleNetv2-1.0× | 0.968 | 1.724 | 33.7 | 42 |
| YOLOv3+CBAM+6Anchors | ShuffleNetv2-1.0× | 0.992 | 1.594 | 15.1 | 44 |
| YOLOv3+CBAM+9Anchors | ShuffleNetv2-1.0× | 0.982 | 1.745 | 34.2 | 41 |
3.3. 使用CBAM注意力机制模块的测试结果
采用ShuffleNetv2-YOLOv3作为基本网络,在网络的颈部(主干网络与检测层之间)加入CBAM注意力模块,经模型训练后,测试结果见表6. 可以看出,在加入了CBAM后,模型的mAP从96.6%提高到98.2%. 虽然在训练时间、模型所占内存大小、检测速度上有略微差距,但是通过损失微小的差距,在模型精度上提高了接近2%,这更能实现精度与速度的均衡性. 实验表明,将该模块应用在提出的模型上,提高了模型分类和检测的性能.
表 6 使用CBAM注意力机制模块的测试结果
Tab.6
| 网络模型 | 主干网络 | mAP | TT/h | Ws /MB | v /(帧·s−1) |
| YOLOv3 | ShuffleNetv2-1.0× | 0.966 | 1.481 | 14.6 | 45 |
| YOLOv3+CBAM | ShuffleNetv2-1.0× | 0.982 | 1.534 | 15.1 | 44 |
3.4. 使用K-means聚类Anchors的测试结果
表 7 使用K-means聚类Anchors的测试结果
Tab.7
| 网络模型 | 主干网络 | mAP | TT/h | Ws /MB | v /(帧·s−1) |
| YOLOv3 | Darknet-53 | 0.98 | 4.138 | 246.6 | 41 |
| YOLOv3+K-means | Darknet-53 | 0.99 | 4.104 | 246.6 | 41 |
| YOLOv3+CBAM | ShuffleNetv2-1.0× | 0.982 | 1.534 | 15.1 | 44 |
| YOLOv3+CBAM+ K-means | ShuffleNetv2-1.0× | 0.992 | 1.594 | 15.1 | 44 |
3.5. 不同主干网络的测试结果
通过对不同网络模型和主干网络的比较,验证了ShuffleNetv2-YOLOv3的优点,测试数据集中的测试结果如表8所示. 与YOLOv2相比,YOLOv3的网络结构更加复杂,因此检测速度略低于前者,但是在网络精度上增大了6%. 相对于其他3种骨干网络的YOLOv3模型,以Resnet50作为骨干网络的YOLOv3在检测精度和速度上都略低于原始的YOLOv3,但从模型所占内存的大小和训练时间可以看出,模型参数量小于原始的YOLOv3. 从表8可知,YOLOv3-Tiny的检测速度和模型所占内存大小都优于原始的YOLOv3,但检测精度降低. 通过使用ShuffleNetv2-1.0×作为YOLOv3的骨干网络(建议的ShuffleNetv2-YOLOv3),mAP和FPS达到最佳的效果. 与原YOLOv3相比,虽然mAP仅增加了0.2%,但是模型所占内存大小仅为15.1 MB,相对于原始的YOLOv3,不管是在内存占用率上还是在计算效率上都成倍增加,检测速度比原始YOLOv3高,达到44帧/s. 将改进后的算法ShuffleNetv2-YOLOv3与其他2种轻量化网络SSD-MobileNetv2、MobileNetv2-YOLOv3进行比较. 从表8可以看出,这2种轻量化网络在训练时间、模型占比、mAP及FPS上都低于所改进的网络模型. 将ShuffleNetv2-YOLOv3作为嵌入式设备或移动终端进行手势识别,具有明显的优势.
表 8 不同主干网络的测试结果
Tab.8
| 网络模型 | 主干网络 | mAP | TT/h | Ws /MB | v /(帧·s−1) |
| YOLOv2 | Darknet-19 | 0.930 | 3.105 | 202.4 | 47 |
| YOLOv3-Tiny | Tiny | 0.974 | 1.256 | 34.8 | 46 |
| YOLOv3 | ResNet-50 | 0.984 | 2.821 | 161.2 | 40 |
| YOLOv3 | Darknet-53 | 0.990 | 4.104 | 246.6 | 41 |
| YOLOv3 | MobileNetv2 | 0.955 | 2.051 | 28.0 | 37 |
| SSD | MobileNetv2 | 0.882 | 4.390 | 24.1 | 19 |
| YOLOv3 | ShuffleNetv2-1.0× | 0.992 | 1.594 | 15.1 | 44 |
3.6. ShuffleNetv2-YOLOv3网络模型的测试结果
为了验证所改进的以ShuffleNetv2-1.0×为主干网络的YOLOv3模型的有效性,在自制数据集、Microsoft Kinect and Leap Motion数据集和Creative Senz3D数据集上,开展与原始YOLOv3的比较实验. 实验结果如表9所示. 可以看出,对于自制的数据集,在改进的网络模型下检测精度高于原始YOLOv3模型,检测速度从41帧/s提高到44帧/s,模型所占内存大小从246.6 MB压缩到15.1 MB,训练时间有效缩减;对于Kinect数据集,在改进的网络模型下,mAP保持不变,训练时间和模型所占内存有效缩减,检测速度从11帧/s提高到13帧/s. 对于Senz3D静态手势数据集,通过改进的网络模型检测精度略高于原始YOLOv3模型,检测速度从28帧/s提高到31帧/s,训练时间和模型所占内存大小有效缩减. 实验结果表明,改进的网络模型在精度上不输于原始的YOLOv3模型,检测速度有一定幅度的提升. 训练时间和模型所占内存大小大幅减小,使ShuffleNetv2-YOLOv3模型在嵌入式设备或移动终端下的运行可能性大大增加.
表 9 不同数据集的测试结果
Tab.9
| 数据集 | 网络模型 | 主干网络 | mAP | TT/h | Ws /MB | v /(帧·s−1) |
| 自制数据集 | YOLOv3 | Darknet-53 | 0.990 | 4.104 | 246.6 | 41 |
| 自制数据集 | YOLOv3 | ShuffleNetv2-1.0× | 0.992 | 1.594 | 15.1 | 44 |
| Kinect数据集 | YOLOv3 | Darknet-53 | 0.987 | 2.394 | 246.6 | 11 |
| Kinect数据集 | YOLOv3 | ShuffleNetv2-1.0× | 0.987 | 1.289 | 15.1 | 13 |
| Senz3D数据集 | YOLOv3 | Darknet-53 | 0.990 | 2.136 | 246.6 | 28 |
| Senz3D数据集 | YOLOv3 | ShuffleNetv2-1.0× | 0.991 | 0.966 | 15.1 | 31 |
如表10所示为改进模型与原始模型在硬件性能上的测试结果. 图中,tGPU、tCPU分别为在GPU、CPU上的计算时间. 可知,改进的模型在精度和速度之间达到良好的均衡效果,所提模型的训练时间较原始模型的训练时间从4.104 h减小到1.594 h,模型所占内存仅为15.1 MB. 可以看出,原始YOLOv3在GPU上计算一张416×416图像的时间为22 ms,CPU上的计算时间为170 ms. 改进的模型在GPU上的计算时间为15 ms,在CPU上的计算时间为58 ms,使其有利于在嵌入式设备上部署. 如图7、8所示为使用提出的轻量级模型ShuffleNetv2-YOLOv3进行手势识别的识别结果,如图7所示为单目标手势的识别效果,如图8所示为多目标手势的识别效果. 从图7可以看出,所提模型对单目标手势检测结果的置信度基本可以达到99%以上,手势的检测框基本与手的大小符合. 如图8所示为多目标手势的识别效果. 可以看出,采用所建议的网络模型,在多目标手势检测结果上可以达到与单目标手势相应的识别效果. 通过单目标与多目标手势的识别结果,证明了所设计模型的有效性及采用K-means算法重新聚类尺寸框大小的必要性.
表 10 改进模型在硬件性能上的测试结果
Tab.10
| 网络模型 | 主干网络 | mAP | TT /h | Ws /MB | v /(帧·s−1) | tGPU /ms | tCPU /ms |
| YOLOv3 | Darknet-53 | 0.990 | 4.104 | 246.6 | 41 | 22 | 170 |
| YOLOv3 | ShuffleNetv2-1.0× | 0.992 | 1.594 | 15.1 | 44 | 15 | 58 |
图 7

图 8

4. 结 论
(1)本文提出基于ShuffleNetv2-YOLOv3轻量级神经网络的静态手势实时识别方法. 测试结果表明,提出模型在测试数据集上的检测精度达到99.2%,不弱于原始YOLOv3模型,FPS从41提高到44. 通过采用CBAM注意力机制模块,模型精度从96.6%提高到了98.2%,为模型的分类和定位提供了良好的技术支持. 在模型中使用K-means算法,对自制数据集Anchors进行重新聚类,使得模型的性能达到最佳.
(2)所改进的模型内存占用大小仅为15.1 MB. 对于单张416×416的图像,在GPU上的推理时间为15 ms,CPU上的推理时间为58 ms,有利于部署到嵌入式设备或移动终端. 引入的注意力机制模块从空间和特征两方面加强了对特征信息的关注度,使得模型在目标的分类和定位方面取得了较好的效果.
(3)将不同的主干网络,如Darknet-19、Darknet-53、Resnet50、Tiny及其他2种轻量型网络SSD-MobileNetv2与YOLOv3-MobileNetv2,在识别精度、训练时间、模型所占内存大小和检测速度上进行比较实验,验证了改进算法的可行性和优越性. 通过在不同数据集上进行测试,验证了所提算法的有效性.
参考文献
Gesture recognition based on binocular vision
[J].
Arabic online handwriting recognition (AOHR): a survey
[J].
Spatial pyramid pooling in deep convolutional networks for visual recognition
[J].
Faster R-CNN: towards real-time object detection with region proposal networks
[J].
Hand gesture recognition with jointly calibrated leap motion and depth sensor
[J].
Head-mounted gesture controlled interface for human-computer interaction
[J].
A review of hand gesture and sign language recognition techniques
[J].
An improved tiny-yolov3 pedestrian detection algorithm
[J].DOI:10.1016/j.ijleo.2019.02.038 [本文引用: 1]
基于DSSD的静态手势实时识别方法
[J].
Real-time recognition of static gestures based on DSSD
[J].
A real-time recognition method of static gesture based on DSSD
[J].DOI:10.1007/s11042-020-08725-9 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}