

在过去的数十年里,工业过程中的故障检测中最常用的方法主要是多元统计过程控制(multivariate statistical process control, MSPC)[4-6]. 在MSPC中,主成分分析(principal component analysis, PCA)是应用较广泛的技术[7-8],它通过降低维度的方式,使用霍特林
有许多学者尝试将机器学习的方法应用到过程监控中,如基于反向传播算法的神经网络[16],支持向量机(support vector machine, SVM)与PCA集成的混合方法[17]. Li等[18]将判别核参数应用到k−近邻规则中,用于间歇过程的故障检测. Kim等[19]通过集成高斯混合模型(Gaussian mixture model, GMM)、子空间模型识别(subspace model identification, SMI)分析对多变量的残差,再对混合过程系统中的故障进行故障检测和隔离. 黄健等[20]采用慢特征分析(slow feature analysis, SFA)提取过程的本质特征,再对嫌疑故障特征进行在线加权,取得了较好的故障检测结果.
近年来,深度学习[21]引起研究人员的极大关注. 深度学习也称为深度神经网络(deep neural network, DNN),它具有强大的特征提取能力[22]. 现在,深度学习已经广泛地应用到图像识别、自然语言处理、视频处理等多个领域中[23-24]. 典型的深度学习方法有深度信念网络(deep belief network, DBN)[24]、卷积神经网络(convolutional neural network, CNN)[25]、循环神经网络(recurrent neural network, RNN)[26]、深度自编码器[27]. 深度学习强大的特征学习能力也适用于工业过程的故障检测和诊断,如采用DBN提取时空域中的各个故障特征,并应用于田纳西−伊士曼过程的故障分类[28-29]. CNN可以有效提取图像数据的特征,在故障检测和诊断的任务上也取得了巨大成功[30-31]. 自编码器采用无监督的学习方式,可以降低高维数据的维度. Zhang等[32]使用堆叠降噪自动编码器(stacked denoising auto-encoders, SDAE)将原始空间的变量映射到特征空间和残差空间,并引入k−近邻规则构建2个新统计量进行过程监控.
目前,工业过程上故障检测用到的过程信号大部分是时间序列数据,上述深度学习中的很多方法并未考虑到时间序列的问题,因此在进行特征提取时往往会忽略重要的历史信息. RNN可以通过链式神经网络架构传播历史信息,适合用来处理时间序列数据,但RNN在训练时会出现梯度消失和梯度爆炸的问题. 门控循环单元(gated recurrent unit,GRU)[33]的更新门和重置门设计,避免了梯度消失和梯度爆炸,实现对长时间序列数据的有效预测.
本文提出基于卷积门控循环单元(convolutional gated recurrent unit, ConvGRU)和注意力的自编码器(CGRUA-AE)模型,并将其应用到工业过程故障检测中. ConvGRU用卷积运算代替GRU中的点乘运算,它融合了CNN的卷积功能,同时有效地集成了GRU记忆历史信息的能力,可以从复杂过程信号中实现更有效的特征提取.
1. 注意力卷积门控循环单元自编码器
1.1. 卷积门控循环单元
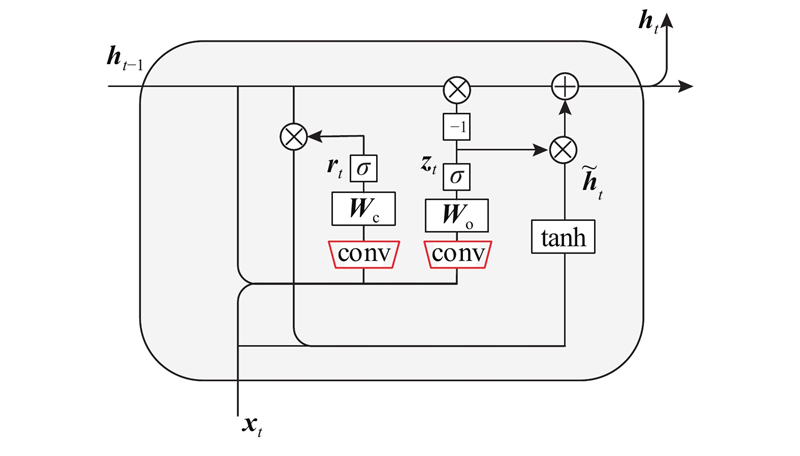
普通LSTM和GRU的内部结构采用接近于全连接的方式,带来严重的信息冗余问题,且这种连接方式忽略了数据中局部像素之间的空间相关性. ConvGRU[35] 将GRU中的全连接的思想扩展到卷积结构中,用卷积运算代替GRU中的点乘运算,ConvGRU的内部结构如图1所示. 图中,rt、zt分别为更新门、重置门,
图 1
1.2. CGRUA-AE网络结构
如图2所示本文提出的CGRUA-AE主要包括编码和解码2个阶段,编码阶段有1个ConvGRU层,解码阶段有1个反卷积GRU(DeconvGRU)层和注意力模块.
图 2
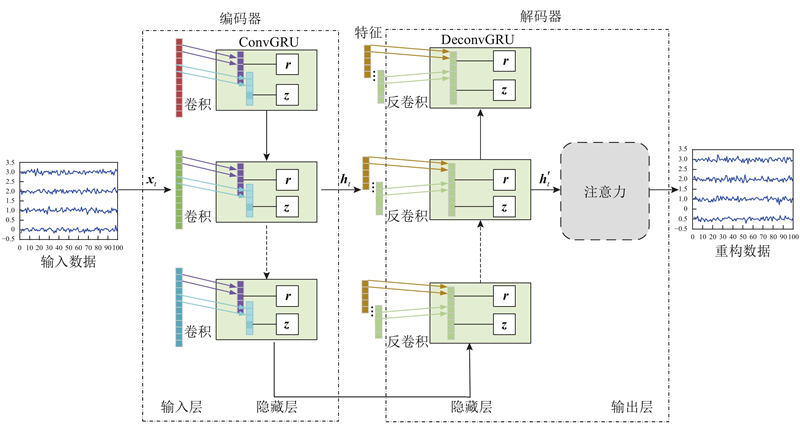
1.2.1. 编码器
ConvGRU对输入数据进行编码,采用卷积核的方式代替全连接提取输入层数据的特征. ConvGRU由多个ConvGRU单元循环组成,每个单元的输入不仅包括当前时刻的输入信息xt,还包括上一个单元的隐藏信息ht-1,再生成新的隐藏信息ht. 每个ConvGRU单元由卷积部分、更新门、重置门等组成.
卷积部分采用卷积核提取数据特征,计算公式为
式中:U、W分别为上一时刻各个门的循环权重、输入权重.
更新门可以有选择性地从隐藏状态中丢弃部分信息,并决定加入新的信息到隐藏状态中,计算公式为
式中:
重置门可以控制遗忘情况,决定需要忘记的信息,计算公式为
由式(1)~(3)ConvGRU确定最终的输出值
式中:
1.2.2. 解码器
DeconvGRU的网络结构与ConvGRU相似,只是用反卷积运算替换卷积运算. 它包含多个DeconvGRU单元,每个单元的输入包括输出数据
反卷积部分使用反卷积核对输入提取特征,计算公式为
式中:
反卷积得到的计算结果通过更新门和重置门的处理,使用式(2)、(3)产生新的隐藏信息,确定最终的输出结果
式中:
1.3. 注意力学习机制
近年来,注意力机制(attention mechanism, AM)被广泛应用于深度学习中[36]. AM通过构建注意力矩阵,使 DNN 在训练时关注重点特征,避免受到非敏感特征的影响. 它的实质是计算注意力的概率分布,对重要的特征分配更多的注意力,突出关键特征对结果的影响.
为了对自编码器提取的特征进行信息筛选,本文采用AM对特征信息动态地调整权重,选择更关键的特征拟合目标函数,如图3所示. 首先采用卷积核大小为N的ConvGRU提取过程信号特征,然后采用DeconvGRU还原特征,最后通过激活函数得到通道注意力图,将其与输入进行矩阵元素依次相乘,得到筛选之后的特征图. AM的计算公式为
式中:softmax为逻辑回归函数,
CGRUA-AE模型的最后一层为全连接层,全连接层融合注意力层输出的特征,得到最终的重构结果Y,计算公式为
式中:B为全连接层的权重。
图 3
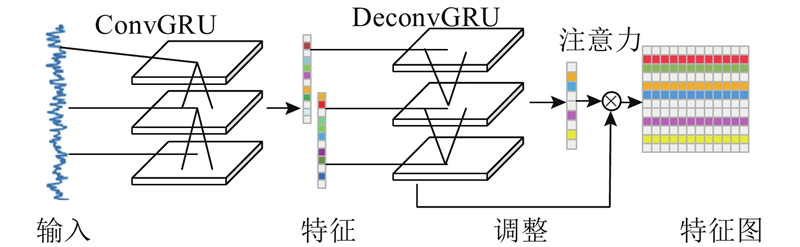
1.4. CGRUA-AE训练
CGRUA-AE模型采用Adam优化器对网络进行训练,它的输出是对原始数据进行编码解码后的重构数据.
算法:CGRUA-AE的训练和测试
输入:训练数据
1) 设定ConvGRU层、DeconvGRU层、注意力层、学习率、全连接层以及批量大小等超参数;
2) 随机初始化CGRUA-AE网络所有权重和偏差;
3) For 训练次数N;
4) 输入训练数据x;
5) 计算编码阶段ConvGRU输出的特征h;
6) 计算解码阶段输出的重构数据
7) 计算重构误差 L;
8) 对网络进行训练,更新参数;
9) End For;
10) 输入测试数据
11) 计算编码阶段ConvGRU输出的特征
12) 计算解码阶段输出的重构数据
输出:特征h,重构数据y.
CGRUA-AE训练时采用均方差(mean square error, MSE)作为模型的损失函数,计算式为
2. 基于CGRUA-AE的监控模型
CGRUA-AE通过编码与解码得到特征数据与重构数据,其计算过程可以简化为
式中:x表示输入数据,
式中:h为编码阶段提取的中间特征;
CGRUA-AE网络的预测误差和SPE统计量计算式分别为
控制图的阈值计算采用核密度估计(kernel density estimation, KDE)[37]的方法. KDE是概率论中用来估计未知数的密度函数,属于非参数检验方法之一. KDE函数的输入数据为正常状态下的
基于CGRUA-AE的过程监控模型如图4所示. 实验包括离线建模和在线监控.
图 4
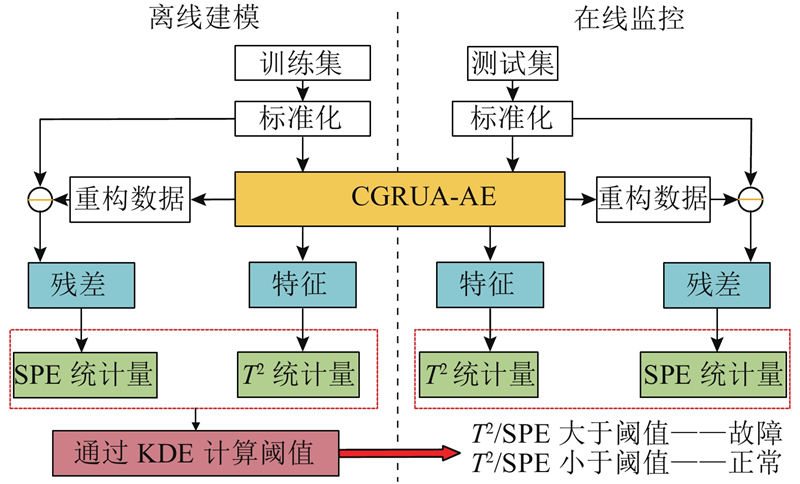
离线建模具体过程如下:1)收集正常状态下的训练数据X,并对X进行归一化处理;2)向CGRUA-AE模型输入训练数据X,使用无监督算法进行训练,保存训练好的模型;3)输入训练数据,提取训练数据的特征和重构数据;4)根据提取的特征数据和重构数据计算
在线监控具体过程如下:1)在线收集测试数据
3. 实验结果与分析
分别采用数值案例和TEP案例对CGRUA-AE的故障检测性能进行验证. 计算机硬件配置:处理器为Intel(R) Core(TM) i5-9400,GPU显卡为NVIDIA GeForce 1050 Ti,计算机内存8 GB,操作系统为Windows10(64-bit),编程语言为Python(版本为3.7.7),软件框架结构为Keras深度学习工具,以Tensorflow深度学习框架作为后端支持,开发软件为Spyder.
3.1. 数值案例
为了模拟实际工业过程数据,该数值案例由大量基本变量组成,并加入噪声,以更好地测试模型提取特征的能力. 数值案例构建如下
式中:
CGRUA-AE模型的ConvGRU、DeconvGRU的卷积核数设为16,学习率设为0.001,批次大小为40. 实验中训练200次后损失值趋于稳定,第200次的损失值为0.000 14,训练时间一共为23.25 s.
3.1.1. 可视化分析
图 5
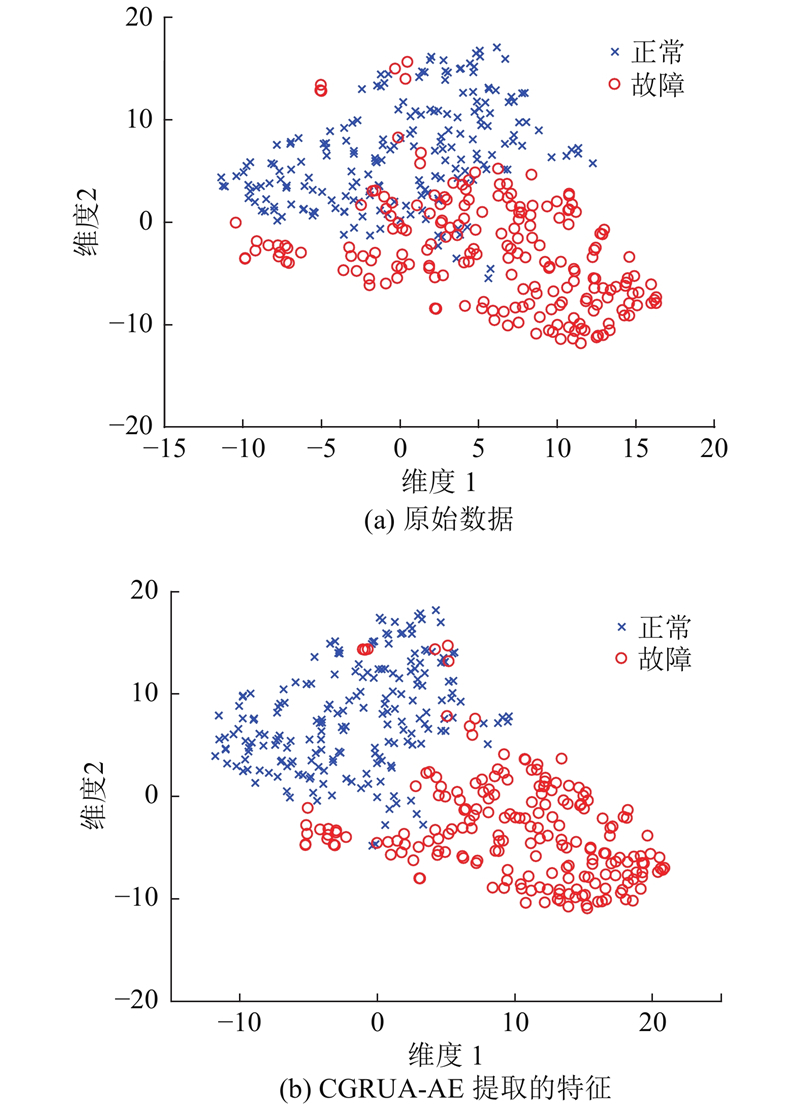
3.1.2. 结果比较
为了验证CGRUA-AE方法的有效性,使用PCA、KPCA、GRU-AE故障检测方法对数值案例进行故障检测,并与CGRUA-AE的检测结果进行比较. 其中,KPCA核函数采用高斯核函数;GRU-AE由2个隐藏神经元数为20的GRU组成,学习率设为0.01. 表1、2分别列出了这4种方法对2种故障的
表 1 4种故障检测方法在T2统计量下的FDR/DR
Tab.1
| 方法 | 故障1 | 故障2 | 平均值 |
| PCA | 0.03/0.41 | 0.03/0.79 | 0.03/0.60 |
| KPCA | 0/0.35 | 0/0.07 | 0/0.21 |
| GRU-AE | 0.01/0.83 | 0.01/0.83 | 0.01/0.83 |
| CGRUA-AE | 0.02/0.98 | 0.02/0.84 | 0.02/0.91 |
表 2 4种故障检测方法在SPE统计量下的FDR/DR
Tab.2
| 方法 | 故障1 | 故障2 | 平均值 |
| PCA | 0.02/0.47 | 0.01/0.81 | 0.015/0.64 |
| KPCA | 0.03/0.92 | 0.01/0.85 | 0.02/0.885 |
| GRU-AE | 0.02/0.96 | 0.02/0.82 | 0.02/0.89 |
| CGRUA-AE | 0.02/0.99 | 0.02/0.87 | 0.02/0.93 |
3.2. 田纳西−伊士曼过程
田纳西−伊士曼过程(Tennessee Eastman process, TEP)于1990年,由美国伊士曼化学公司创建,它是基于实际工业过程的过程控制实例. TEP是系统工程研究领域的基石[39],大量文献引用它作为数据源来进行控制、优化、过程监控、故障诊断等方面的研究. TEP共有53个变量,包括12个操作变量,22个连续测量值和19个成分测量值. TEP数据包括1个正常情况下运行的数据集和在21种不同故障情况下运行得到的故障数据集. 这21个故障中包括16个已知故障(故障1~故障15、故障21)和5个未知故障(故障16~故障20),分为4种类型:阶跃变化、随机变化、慢偏移和阀门黏住.
本文中采用的TEP数据集一共有33个变量,包括22个连续测量值和11个操作变量. 采用常用的18个故障数据集检测方法的有效性. 使用正常情况下的正常数据集(500个样本)作为CGRUA-AE模型的训练集,训练完毕后,再使用其他18个故障数据集(960个样本)进行测试并提取特征. 所有故障数据集的故障均是在第161个样本点引入,即前160个样本为正常数据,后800个样本均为故障数据.
CGRUA-AE模型的ConvGRU的卷积核数设为32,学习率设为0.001,批次大小为50. 实验中训练200次后的损失值为0.000 18,总共用时24.87 s.
TEP中故障5发生时,冷凝器冷却入口温度发生变化,但温度变化会随时间增加逐渐平稳,因此后期的故障一般难以检出. 如图6所示为PCA、KPCA、GRU-AE、CGRUA-AE对TEP中故障5的监控效果,测试数据中前160个样本为正常数据,第161个样本及其后的数据为故障数据. KPCA采用高斯核函数;GRU-AE由2个隐藏神经元数为40的GRU组成,学习率设为0.01. PCA、KPCA、GRU-AE对故障5的检测效果都比较差,无法检测出后期的大量故障数据;CGRUA-AE的检测结果最好,可以检测出所有的故障数据,2种控制图的故障检出率都达到了100%.
图 6
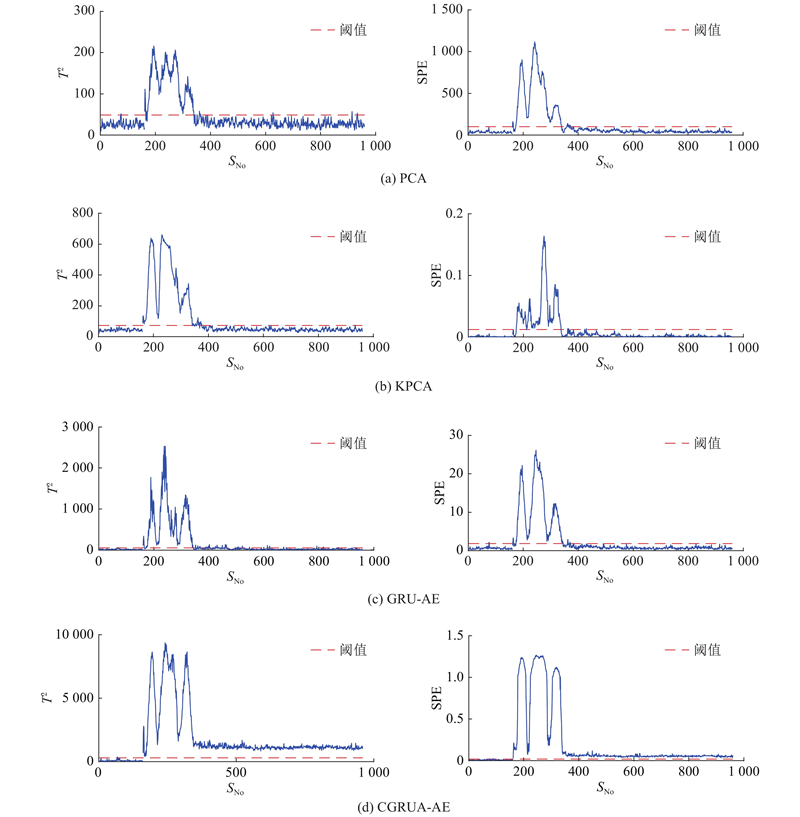
图 6 4种故障检测方法对TEP故障5的监控结果
Fig.6 Monitoring results of four fault detection methods on TEP fault 5
表 3 4种检测方法在T2统计量的TEP故障FDR/DR
Tab.3
| 方法 | 故障类型 | 平均值 | |||
| 阶跃 | 随机变量 | 未知 | 其他 | ||
| PCA | 0.01/0.78 | 0.01/0.72 | 0.02/0.51 | 0.01/0.77 | 0.014/0.69 |
| KPCA | 0.01/0.87 | 0.01/0.77 | 0.02/0.53 | 0.01/0.79 | 0.011/0.739 |
| GRU-AE | 0.02/0.87 | 0.07/0.85 | 0.08/0.67 | 0.04/0.82 | 0.051/0.803 |
| CGRUA-AE | 0.02/1 | 0.03/0.89 | 0.02/0.77 | 0.02/0.82 | 0.023/0.879 |
表 4 4种检测方法在SPE统计量的TEP故障FDR/DR
Tab.4
| 方法 | 故障类型 | 平均值 | |||
| 阶跃 | 随机变量 | 未知 | 其他 | ||
| PCA | 0.01/0.79 | 0.06/0.79 | 0.08/0.57 | 0.04/0.78 | 0.046/0.727 |
| KPCA | 0.01/0.66 | 0.01/0.65 | 0.05/0.45 | 0.01/0.70 | 0.023/0.604 |
| GRU-AE | 0.02/0.89 | 0.02/0.86 | 0.05/0.70 | 0.03/0.81 | 0.029/0.817 |
| CGRUA-AE | 0.02/0.99 | 0.03/0.88 | 0.02/0.86 | 0.01/0.81 | 0.02/0.903 |
除了以上方法,还有大量深度学习的方法已经应用到故障检测领域,如DBN、CNN、SDAE等. 由于LSTM与GRU类似,也能解决RNN存在的梯度消失的问题,继续将所提方法的故障检测结果与DBN、CNN、SDAE、LSTM进行比较. 其中,CNN的网络结构参考文献[30];SDAE的网络结构为“33-30-30-2”,学习率为0.5;DBN的故障检测结果来源于文献[28];LSTM由隐藏层为32的LSTM和1个全连接层组成. 它们的故障检测结果如表5所示,其中CNN、LSTM、SDAE(
表 5 CGRUA-AE与深度学习检测方法的TEP故障FDR/DR
Tab.5
| 方法 | 故障类型 | 平均值 | |||
| 阶跃 | 随机变量 | 未知 | 其他 | ||
| CNN | 0.02/0.86 | 0.03/0.79 | 0.02/0.68 | 0.03/0.80 | 0.025/0.785 |
| LSTM | 0.02/0.94 | 0.03/0.79 | 0.02/0.67 | 0.02/0.80 | 0.019/0.809 |
| SDAE (T2) | 0.02/0.66 | 0.04/0.60 | 0.03/0.45 | 0.04/0.74 | 0.028/0.602 |
| SDAE(SPE) | 0.03/0.88 | 0.05/0.87 | 0.09/0.73 | 0.07/0.85 | 0.061/0.832 |
| DBN (T2) | 0.01/0.87 | 0.01/0.79 | 0.02/0.55 | 0.02/0.81 | 0.014/0.75 |
| DBN(SPE) | 0.01/0.98 | 0.01/0.82 | 0.01/0.78 | 0.01/0.79 | 0.011/0.856 |
| CGRUA-AE (T2) | 0.02/1 | 0.03/0.89 | 0.02/0.77 | 0.02/0.82 | 0.023/0.879 |
| CGRUA-AE(SPE) | 0.02/0.99 | 0.03/0.88 | 0.02/0.86 | 0.01/0.81 | 0.02/0.903 |
3.3. 注意力机制分析
为了更好地分析注意力机制对网络模型的影响,实验中分别研究了加入注意力机制前(CGRU-AE)和加入注意力后(CGRUA-AE)的损失函数下降情况. 采用TEP的训练数据对网络模型进行训练,损失函数为原始数据与重构数据之间的均方误差. 如图7所示为CGRUA-AE与CGRU-AE网络前200次训练的损失函数下降情况,CGRUA-AE初始的损失值小于CGRU-AE,且CGRUA-AE的损失函数下降速度更快. 最终完成迭代以后,CGRUA-AE的损失值明显小于CGRU-AE的. 如表6所示为2种网络基于
图 7
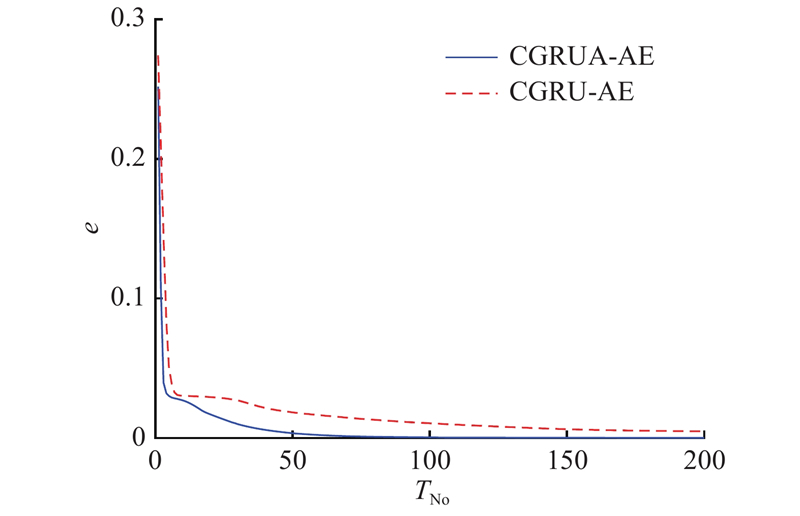
表 6 CGRUA-AE与CGRU-AE的故障检测率
Tab.6
| 统计量 | R/% | |
| CGRU-AE | CGRUA-AE | |
| | 84.3 | 87.9 |
| SPE | 86.6 | 90.3 |
4. 结 论
(1)采用ConvGRU的设计,有效地提高了对信号数据的特征提取能力. 将卷积GRU与自编码器有效地集成,形成高效的无监督学习网络,避免了RNN遗忘长期信息的问题.
(2)在解码器内嵌入注意力机制,可以选择自编码器的关键特征传递到下一层,有效地加强了模型的学习性能,并提高了数据重构的准确性.
(3)将原始非线性空间映射到特征空间和残差空间,开发
(4)目前无法对过程的故障进行分类,下一步研究应结合分类器进行故障诊断.
参考文献
Data-driven adaptive observer for fault diagnosis
[J].
An advanced PLS approach for key performance indicator-related prediction and diagnosis in case of outliers
[J].
Adaptive actuator fault tolerant control for uncertain nonlinear systems with multiple actuators
[J].DOI:10.1016/j.automatica.2015.07.006 [本文引用: 1]
Monitoring and diagnosis process of abnormal consumption on smart power grid
[J].DOI:10.1007/s00521-016-2719-4 [本文引用: 1]
Review on data-driven modeling and monitoring for plant wide industrial processes
[J].DOI:10.1016/j.chemolab.2017.09.021
A review of data-driven fault detection and diagnosis methods: applications in chemical process systems
[J].
Performance-driven distributed PCA process monitoring based on fault-relevant variable selection and bayesian inference
[J].
Nonlinear process fault diagnosis based on serial principal component analysis
[J].DOI:10.1109/TNNLS.2016.2635111 [本文引用: 1]
Quality-related statistical process monitoring method based on global and local partial least-squares projection
[J].DOI:10.1021/acs.iecr.5b02559 [本文引用: 1]
Fault feature extraction using independent component analysis with reference and its application on fault diagnosis of rotating machinery
[J].DOI:10.1007/s00521-014-1726-6 [本文引用: 1]
Semi-supervised Fisher discriminant analysis model for fault classification in industrial processes
[J].DOI:10.1016/j.chemolab.2014.08.008 [本文引用: 1]
Nonlinear process monitoring using kernel principal component analysis
[J].DOI:10.1016/j.ces.2003.09.012 [本文引用: 1]
Parallel PCA–KPCA for nonlinear process monitoring
[J].
Performance analysis of dynamic PCA for closed-loop process monitoring and its improvement by output oversampling scheme
[J].DOI:10.1109/TCST.2017.2765621 [本文引用: 1]
Fault detection and classification using artificial neural networks
[J].DOI:10.1016/j.ifacol.2018.09.380 [本文引用: 1]
Fed-batch fermentation penicillin process fault diagnosis and detection based on support vector machine
[J].
Discriminant diffusion maps based K-nearest-neighbour for batch process fault detection
[J].DOI:10.1002/cjce.23003 [本文引用: 1]
Optimal false alarm-controlled support vector data description for multivariate process monitoring
[J].
基于在线加权慢特征分析的故障检测算法
[J].
Online Weighted Based Slow Feature Analysis Fault Detection Algorithm
[J].
Reducing the dimensionality of data with neural networks
[J].DOI:10.1126/science.1127647 [本文引用: 1]
Deep learning
[J].DOI:10.1038/nature14539 [本文引用: 1]
Flame images for oxygen content prediction of combustion systems using DBN
[J].DOI:10.1021/acs.energyfuels.7b00576 [本文引用: 1]
Automatic pearl classification machine based on a multistream convolutional neural network
[J].DOI:10.1109/TIE.2017.2784394 [本文引用: 2]
ImageNet classification with deep convolutional neural networks
[J].
Drawing and recognizing chinese characters with recurrent neural network
[J].DOI:10.1109/TPAMI.2017.2695539 [本文引用: 1]
An autoencoder approach to learning bilingual word representations
[J].
A deep belief network based fault diagnosis model for complex chemical processes
[J].DOI:10.1016/j.compchemeng.2017.02.041 [本文引用: 2]
A deep belief network-based fault detection method for nonlinear processes
[J].DOI:10.1016/j.ifacol.2018.09.522 [本文引用: 1]
基于一维卷积神经网络深度学习的工业过程故障检测
[J].
Fault detection of industrial process based on deep learning of one-dimensional convolution neural network
[J].
Deep convolutional neural network model based chemical process fault diagnosis
[J].DOI:10.1016/j.compchemeng.2018.04.009 [本文引用: 1]
Automated feature learning for nonlinear process monitoring: an approach using stacked denoising autoencoder and k-nearest neighbor rule
[J].DOI:10.1016/j.jprocont.2018.02.004 [本文引用: 1]
Long short-term memory
[J].DOI:10.1162/neco.1997.9.8.1735 [本文引用: 1]
The application of principal component analysis and kernel density estimation to enhance process monitoring
[J].DOI:10.1016/S0967-0661(99)00191-4 [本文引用: 1]
Visualizing data using t-SNE
[J].
Base control for the Tennessee Eastman problem
[J].DOI:10.1016/0098-1354(94)88019-0 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}