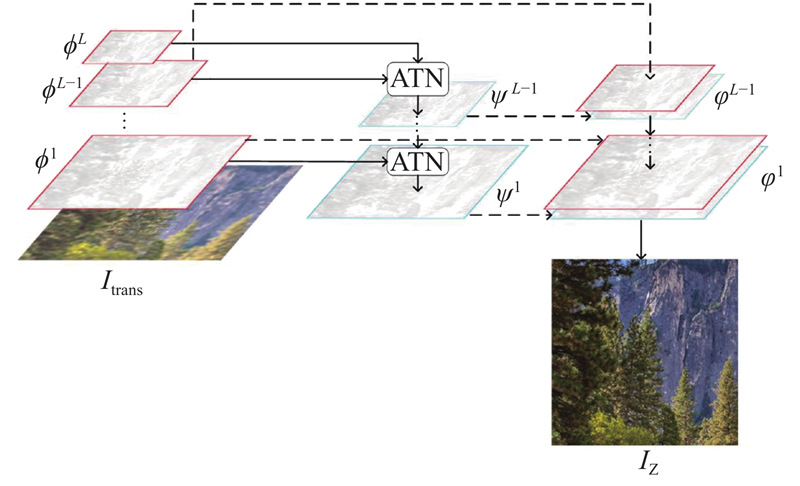
(1) $ \left.\begin{array}{c} {\psi ^{L - 1}} = f\left( {{\phi ^{L - 1}},{\phi ^L}} \right),\\ {\psi ^{L - 2}} = f\left( {{\phi ^{L - 2}},{\psi ^{L - 1}}} \right),\\ {\vdots }\\ {\psi ^1} = f\left( {{\phi ^1},{\psi ^2}} \right) = f\left( {{\phi ^1}, \cdots f\left( {{\phi ^{L - 1}},{\phi ^L}} \right)} \right). \end{array}\right\} $
[2]
LI X New edge-directed interpolation
[J]. IEEE Transactions on Image Processing , 2001 , 10 (10 ): 1521 - 1527
DOI:10.1109/83.951537
[本文引用: 1]
[3]
DONG C, LOY C, HE K, et al Image super-resolution using deep convolutional networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2016 , 38 (2 ): 295 - 307
DOI:10.1109/TPAMI.2015.2439281
[本文引用: 1]
[4]
KIM J, LEE J, LEE K. Accurate image super-resolution using very deep convolutional networks[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Las Vegas: IEEE, 2016: 1646-1654.
[本文引用: 1]
[5]
LEDIG C, THEIS L, HUSZAR F, et al. Photo-realistic single image super-resolution using a generative adversarial network[C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Hawaii: IEEE, 2017: 4681-4690.
[本文引用: 1]
[6]
YU S, MOON B, KIM D, et al Continuous digital zooming of asymmetric dual camera images using registration and variational image restoration
[J]. Multidimensional Systems and Signal Processing , 2018 , 29 (4 ): 1959 - 1987
DOI:10.1007/s11045-017-0534-4
[本文引用: 1]
[7]
MOON B, YU S, KO S, et al Continuous digital zooming using local self-similarity-based superresolution for an asymmetric dual camera system
[J]. Journal of the Optical Society of America A-optics Image Science and Vision , 2017 , 34 (6 ): 991 - 1003
DOI:10.1364/JOSAA.34.000991
[本文引用: 1]
[8]
MA H, LI Q, XU Z, et al Photo-realistic continuous digital zooming for an asymmetrical dual camera system
[J]. Optics and Laser Technology , 2019 , 109 : 110 - 122
DOI:10.1016/j.optlastec.2018.07.056
[本文引用: 1]
[9]
赫贵然, 李奇, 冯华君, 等 基于CNN特征提取的双焦相机连续数字变焦
[J]. 浙江大学学报: 工学版 , 2019 , 53 (6 ): 1182 - 1189
URL
[本文引用: 5]
HE Gui-ran, LI Qi, FENG Hua-jun, et al Dual-focal camera continuous digital zoom based on CNN and feature extraction
[J]. Journal of Zhejiang University: Engineering Science , 2019 , 53 (6 ): 1182 - 1189
URL
[本文引用: 5]
[10]
ZHANG Z, WANG Z, LIN Z, et al. Image super-resolution by neural texture transfer[C]// 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Long Bench: IEEE, 2019: 7982-7991.
[本文引用: 2]
[11]
YANG F, YANG H, FU J, et al. Learning texture transformer network for image super-resolution[C]// 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Seattle: IEEE, 2020: 5791-5800.
[本文引用: 5]
[12]
ZENG Y, FU J, CHAO H, et al. Learning pyramid-context encoder network for high-quality image inpainting[C]// 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Long Bench: IEEE, 2019: 1486-1494.
[本文引用: 4]
[13]
YI Z, TANG Q, AZIZI S, et al. Contextual residual aggregation for ultra high-resolution image inpainting[C]// 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Seattle: IEEE, 2020: 7508-7517.
[本文引用: 1]
[14]
PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: feature learning by inpainting[C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Las Vegas: IEEE, 2016: 2536-2544.
[本文引用: 1]
[15]
SATOSHI I, EDGAR S, HIROSHI I Globally and locally consistent image completion
[J]. ACM Transactions on Graphics , 2017 , 36 (4 ): 107
[16]
YU J, LIN Z, YANG J, et al. Generative image inpainting with contextual attention[C]// 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) . Salt Lake City: IEEE, 2018: 5505-5514.
[本文引用: 2]
[17]
GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of wasserstein GANs[C]// Thirty-first Conference on Neural Information Processing Systems . Long Bench: NIPS, 2017: 5767-5677.
[本文引用: 1]
[18]
JUSTIN J, ALEXANDRE A, LI F. Perceptual losses for real-time style transfer and super-resolution[C]// The 14th European Conference on Computer Vision . Amsterdam: IEEE, 2016: 694–711.
[本文引用: 1]
Cubic convolution interpolation for digital image processing
1
1981
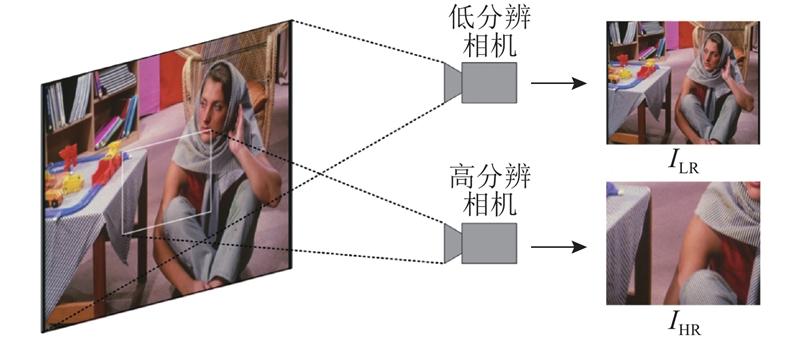
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
New edge-directed interpolation
1
2001
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
Image super-resolution using deep convolutional networks
1
2016
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
1
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
1
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
Continuous digital zooming of asymmetric dual camera images using registration and variational image restoration
1
2018
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
Continuous digital zooming using local self-similarity-based superresolution for an asymmetric dual camera system
1
2017
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
Photo-realistic continuous digital zooming for an asymmetrical dual camera system
1
2019
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
基于CNN特征提取的双焦相机连续数字变焦
5
2019
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
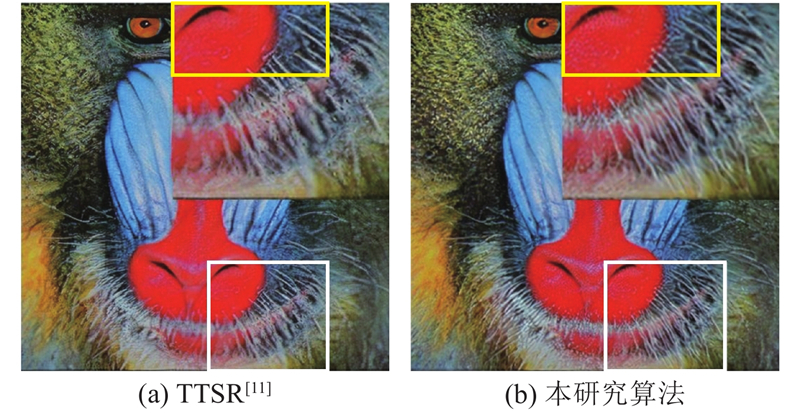
... 对本研究提出的连续数字变焦算法流程进行仿真实验,将实验结果与传统插值算法、基于参考图像的超分辨算法TTSR[11 ] 进行比较,并在一些实验中与其他双焦图像连续数字变焦算法[9 ] 的结果进行比较. 连续变焦的仿真结果如图5 所示. 同时,为了体现本研究算法在不同图像中的鲁棒性,选取不同图像不同变焦倍率进行仿真实验,结果如图6 所示. 图中,白色框内代表长焦相机视场. 此外,使用定量评价指标峰值信噪比(peak signal to noise ratio,PSNR)对不同变焦倍率下图像整体质量以及长焦相机视场内、外区域图像质量分别进行评价,结果如表1 、2 所示.可以看出,利用本研究算法得到的变焦图像可以更好地还原被拍摄景物的整体纹理细节,且在长焦相机视场外的细节恢复效果上具有明显优势,相比于其他算法,本研究算法恢复的细节更加清晰、锐利. 这是因为在语义信息较为明确的情况下,图像修复算法更可能提供空间分辨率和长焦相机视场内图像近似的修复图像,前提是该纹理细节在长焦相机视场内有相似纹理. 这里所说的相似纹理,不仅包括视觉上可以直观看到的相似纹理,也包括通过编码器生成的特征图中相似的特征. 如图7 所示为该问题进一步的仿真结果示例. 图中,中央方框内为长焦相机视场区域. 可以看出,粗线框内头巾的花纹部分在长焦相机视场内、外部分并不相同,且存在桌布花纹的干扰,本研究的算法可以较好地修复长焦相机视场外的花纹,且未明显出现花纹反向或者模糊的情况. ...
... PSNR of different zoom magnifications and algorithms
Tab.1 算法 ×1.2 ×1.4 ×1.6 ×1.8 ×2.0 ×2.2 ×2.4 ×2.6 ×2.8 ×3.0 ×3.2 ×3.4 ×3.6 ×3.8 双三次插值 35.01 32.93 31.49 30.38 29.55 28.87 28.31 27.89 27.51 27.19 26.89 26.60 26.35 26.07 TTSR[11 ] 39.79 36.73 34.53 33.27 32.15 31.29 30.56 29.98 29.53 29.19 28.87 28.55 28.29 27.96 文献[9 ]算法 39.11 36.29 34.05 33.11 32.03 31.07 30.19 29.53 29.02 28.68 28.22 27.89 27.43 27.18 本研究算法 39.46 36.33 34.18 33.25 32.32 31.56 30.89 30.17 29.71 29.43 29.06 28.77 28.50 28.05
表 2 不同算法长焦相机视场内外的峰值信噪比 ...
... PSNR of inside and outside field of view of long-focal camera
Tab.2 视场 算法 ×1.5 ×2.0 ×2.5 ×3.0 ×3.5 长焦相机视场内 双三次插值 32.03 29.81 28.06 27.12 26.49 TTSR[11 ] 37.57 34.23 32.04 30.41 29.88 文献[9 ]算法 36.56 33.44 31.10 29.39 28.53 本研究算法 37.75 34.21 31.93 30.28 29.71 长焦相机视场外 双三次插值 32.25 29.42 27.94 27.26 26.47 TTSR[11 ] 35.21 31.45 29.08 27.62 27.93 文献[9 ]算法 34.80 31.54 29.01 27.76 27.31 本研究算法 34.72 31.69 29.58 28.33 28.24
图 7 长焦相机视场外纹理修复效果对比 ...
... 文献[
9 ]算法
34.80 31.54 29.01 27.76 27.31 本研究算法 34.72 31.69 29.58 28.33 28.24 图 7 长焦相机视场外纹理修复效果对比 ...
基于CNN特征提取的双焦相机连续数字变焦
5
2019
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
... 对本研究提出的连续数字变焦算法流程进行仿真实验,将实验结果与传统插值算法、基于参考图像的超分辨算法TTSR[11 ] 进行比较,并在一些实验中与其他双焦图像连续数字变焦算法[9 ] 的结果进行比较. 连续变焦的仿真结果如图5 所示. 同时,为了体现本研究算法在不同图像中的鲁棒性,选取不同图像不同变焦倍率进行仿真实验,结果如图6 所示. 图中,白色框内代表长焦相机视场. 此外,使用定量评价指标峰值信噪比(peak signal to noise ratio,PSNR)对不同变焦倍率下图像整体质量以及长焦相机视场内、外区域图像质量分别进行评价,结果如表1 、2 所示.可以看出,利用本研究算法得到的变焦图像可以更好地还原被拍摄景物的整体纹理细节,且在长焦相机视场外的细节恢复效果上具有明显优势,相比于其他算法,本研究算法恢复的细节更加清晰、锐利. 这是因为在语义信息较为明确的情况下,图像修复算法更可能提供空间分辨率和长焦相机视场内图像近似的修复图像,前提是该纹理细节在长焦相机视场内有相似纹理. 这里所说的相似纹理,不仅包括视觉上可以直观看到的相似纹理,也包括通过编码器生成的特征图中相似的特征. 如图7 所示为该问题进一步的仿真结果示例. 图中,中央方框内为长焦相机视场区域. 可以看出,粗线框内头巾的花纹部分在长焦相机视场内、外部分并不相同,且存在桌布花纹的干扰,本研究的算法可以较好地修复长焦相机视场外的花纹,且未明显出现花纹反向或者模糊的情况. ...
... PSNR of different zoom magnifications and algorithms
Tab.1 算法 ×1.2 ×1.4 ×1.6 ×1.8 ×2.0 ×2.2 ×2.4 ×2.6 ×2.8 ×3.0 ×3.2 ×3.4 ×3.6 ×3.8 双三次插值 35.01 32.93 31.49 30.38 29.55 28.87 28.31 27.89 27.51 27.19 26.89 26.60 26.35 26.07 TTSR[11 ] 39.79 36.73 34.53 33.27 32.15 31.29 30.56 29.98 29.53 29.19 28.87 28.55 28.29 27.96 文献[9 ]算法 39.11 36.29 34.05 33.11 32.03 31.07 30.19 29.53 29.02 28.68 28.22 27.89 27.43 27.18 本研究算法 39.46 36.33 34.18 33.25 32.32 31.56 30.89 30.17 29.71 29.43 29.06 28.77 28.50 28.05
表 2 不同算法长焦相机视场内外的峰值信噪比 ...
... PSNR of inside and outside field of view of long-focal camera
Tab.2 视场 算法 ×1.5 ×2.0 ×2.5 ×3.0 ×3.5 长焦相机视场内 双三次插值 32.03 29.81 28.06 27.12 26.49 TTSR[11 ] 37.57 34.23 32.04 30.41 29.88 文献[9 ]算法 36.56 33.44 31.10 29.39 28.53 本研究算法 37.75 34.21 31.93 30.28 29.71 长焦相机视场外 双三次插值 32.25 29.42 27.94 27.26 26.47 TTSR[11 ] 35.21 31.45 29.08 27.62 27.93 文献[9 ]算法 34.80 31.54 29.01 27.76 27.31 本研究算法 34.72 31.69 29.58 28.33 28.24
图 7 长焦相机视场外纹理修复效果对比 ...
... 文献[
9 ]算法
34.80 31.54 29.01 27.76 27.31 本研究算法 34.72 31.69 29.58 28.33 28.24 图 7 长焦相机视场外纹理修复效果对比 ...
2
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
... 判别器:本研究采用和SRNTT[10 ] 相同的判别器结构. ...
5
... 目前,实际使用的双焦相机连续数字变焦算法主要可以分为2类,第1类算法主要通过传统的图像插值算法和基于深度学习的图像超分辨算法,直接提升短焦相机拍摄的低分辨图像的分辨率. 在插值算法方面,Keys等[1 -2 ] 通过对双线性插值和双三次插值算法进行改进,发明了较多自适应的插值算法. Dong等[3 -4 ] 提出基于深度学习的图像超分辨算法,通过卷积神经网络模型直接进行从低分辨图像到高分辨图像的端到端的学习. 在卷积神经网络的基础上,Ledig等[5 ] 提出基于对抗生成网络的图像超分辨技术,运用生成器和判别器互相博弈学习产生更符合自然图像特点的图像,并对纹理区域进行大胆的猜测,使最终输出的图像具有较好的视觉效果. 第2类算法利用高分辨长焦相机拍摄的图像的细节信息,来提升数字变焦后图像的视觉效果. Yu等[6 ] 利用配准和块搜索的策略,对长焦相机视场内的图像进行分辨率提升,并使用传统的单帧超分辨算法对处于长焦相机视场外的部分进行处理. 为了提升视觉效果,Moon等[7 ] 提出长焦相机图像到短焦相机图像的退化模型,估计退化点扩散函数,在配准长短焦相机的图像后,以此为依据使用传统的图像恢复算法进行图像复原. Ma等[8 ] 在配准的基础上,将长焦和短焦相机的图像进行频带分解,在每个频带内进行图像修复,最终得到变焦图像. 赫贵然等[9 ] 利用特征层提取和特征块匹配的算法,运用卷积神经网络将长焦相机图像中特征块的特征信息迁移到短焦相机图像匹配的区域,并以修复后的短焦图像为基础进行数字变焦. 此外,Zhang等[10 -11 ] 提出基于参考图像的超分辨算法,利用参考图像的相似特征来提升超分辨图像的质量. ...
... 对本研究提出的连续数字变焦算法流程进行仿真实验,将实验结果与传统插值算法、基于参考图像的超分辨算法TTSR[11 ] 进行比较,并在一些实验中与其他双焦图像连续数字变焦算法[9 ] 的结果进行比较. 连续变焦的仿真结果如图5 所示. 同时,为了体现本研究算法在不同图像中的鲁棒性,选取不同图像不同变焦倍率进行仿真实验,结果如图6 所示. 图中,白色框内代表长焦相机视场. 此外,使用定量评价指标峰值信噪比(peak signal to noise ratio,PSNR)对不同变焦倍率下图像整体质量以及长焦相机视场内、外区域图像质量分别进行评价,结果如表1 、2 所示.可以看出,利用本研究算法得到的变焦图像可以更好地还原被拍摄景物的整体纹理细节,且在长焦相机视场外的细节恢复效果上具有明显优势,相比于其他算法,本研究算法恢复的细节更加清晰、锐利. 这是因为在语义信息较为明确的情况下,图像修复算法更可能提供空间分辨率和长焦相机视场内图像近似的修复图像,前提是该纹理细节在长焦相机视场内有相似纹理. 这里所说的相似纹理,不仅包括视觉上可以直观看到的相似纹理,也包括通过编码器生成的特征图中相似的特征. 如图7 所示为该问题进一步的仿真结果示例. 图中,中央方框内为长焦相机视场区域. 可以看出,粗线框内头巾的花纹部分在长焦相机视场内、外部分并不相同,且存在桌布花纹的干扰,本研究的算法可以较好地修复长焦相机视场外的花纹,且未明显出现花纹反向或者模糊的情况. ...
... PSNR of different zoom magnifications and algorithms
Tab.1 算法 ×1.2 ×1.4 ×1.6 ×1.8 ×2.0 ×2.2 ×2.4 ×2.6 ×2.8 ×3.0 ×3.2 ×3.4 ×3.6 ×3.8 双三次插值 35.01 32.93 31.49 30.38 29.55 28.87 28.31 27.89 27.51 27.19 26.89 26.60 26.35 26.07 TTSR[11 ] 39.79 36.73 34.53 33.27 32.15 31.29 30.56 29.98 29.53 29.19 28.87 28.55 28.29 27.96 文献[9 ]算法 39.11 36.29 34.05 33.11 32.03 31.07 30.19 29.53 29.02 28.68 28.22 27.89 27.43 27.18 本研究算法 39.46 36.33 34.18 33.25 32.32 31.56 30.89 30.17 29.71 29.43 29.06 28.77 28.50 28.05
表 2 不同算法长焦相机视场内外的峰值信噪比 ...
... PSNR of inside and outside field of view of long-focal camera
Tab.2 视场 算法 ×1.5 ×2.0 ×2.5 ×3.0 ×3.5 长焦相机视场内 双三次插值 32.03 29.81 28.06 27.12 26.49 TTSR[11 ] 37.57 34.23 32.04 30.41 29.88 文献[9 ]算法 36.56 33.44 31.10 29.39 28.53 本研究算法 37.75 34.21 31.93 30.28 29.71 长焦相机视场外 双三次插值 32.25 29.42 27.94 27.26 26.47 TTSR[11 ] 35.21 31.45 29.08 27.62 27.93 文献[9 ]算法 34.80 31.54 29.01 27.76 27.31 本研究算法 34.72 31.69 29.58 28.33 28.24
图 7 长焦相机视场外纹理修复效果对比 ...
... [
11 ]
35.21 31.45 29.08 27.62 27.93 文献[9 ]算法 34.80 31.54 29.01 27.76 27.31 本研究算法 34.72 31.69 29.58 28.33 28.24 图 7 长焦相机视场外纹理修复效果对比 ...
4
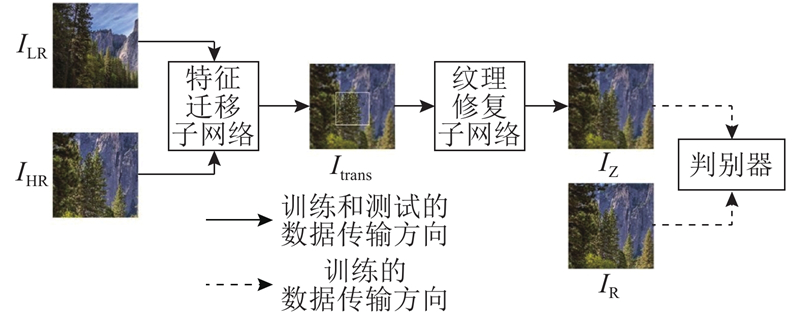
... 为了解决上述问题,把双焦相机连续数字变焦问题拆分成长焦相机视场内的特征迁移问题和长焦相机视场外的纹理修复问题,借鉴基于上下文语义的图像修复算法[12 -13 ] 的思路,利用长焦相机图像的纹理信息修复短焦相机图像,并在2个问题上使用相似的网络结构来降低长焦相机视场内外细节视觉效果的差异. ...
... 随着深度学习的不断发展,研究者将其运用到图像修复中[14 -16 ] ,Zeng等[12 ] 根据低层特征具有更丰富的纹理细节,高层特征具有更抽象的语义这一情况,提出金字塔结构的图像修复网络,运用注意力(attention)机制,将高层特征逐层次用于指导低层特征的补全. 相较于图像修复算法须首先结合待修复区域周边信息来尽可能准确地获得待修复区域的语义,在本研究的连续数字变焦问题中,可以直接将上采样后的短焦相机图像作为待修复图像,利用短焦相机图像原有的准确的语义信息将长焦相机图像的纹理细节迁移到短焦相机图像上,从而获得高质量的变焦后图像. ...
... 网络采用生成式对抗网络的框架,整体结构如图2 所示,该网络主要由三部分组成:特征迁移子网络、纹理修复子网络和判别器. 其中特征迁移子网络和纹理修复子网络借鉴了文献[12 ]中用到的图像修复网络的结构. ...
... 式中: $q_j^n$ $R_{\rm{h}}^n$ j 个小块. 此外,本研究还根据文献[12 ]中的网络使用4组具有不同空洞间隔的空洞卷积来整合不同尺度的上下文信息,这样的设计确保了最终重建的特征中结构与上下文的一致性,从而提升修复效果. ...
1
... 为了解决上述问题,把双焦相机连续数字变焦问题拆分成长焦相机视场内的特征迁移问题和长焦相机视场外的纹理修复问题,借鉴基于上下文语义的图像修复算法[12 -13 ] 的思路,利用长焦相机图像的纹理信息修复短焦相机图像,并在2个问题上使用相似的网络结构来降低长焦相机视场内外细节视觉效果的差异. ...
1
... 随着深度学习的不断发展,研究者将其运用到图像修复中[14 -16 ] ,Zeng等[12 ] 根据低层特征具有更丰富的纹理细节,高层特征具有更抽象的语义这一情况,提出金字塔结构的图像修复网络,运用注意力(attention)机制,将高层特征逐层次用于指导低层特征的补全. 相较于图像修复算法须首先结合待修复区域周边信息来尽可能准确地获得待修复区域的语义,在本研究的连续数字变焦问题中,可以直接将上采样后的短焦相机图像作为待修复图像,利用短焦相机图像原有的准确的语义信息将长焦相机图像的纹理细节迁移到短焦相机图像上,从而获得高质量的变焦后图像. ...
Globally and locally consistent image completion
0
2017
2
... 随着深度学习的不断发展,研究者将其运用到图像修复中[14 -16 ] ,Zeng等[12 ] 根据低层特征具有更丰富的纹理细节,高层特征具有更抽象的语义这一情况,提出金字塔结构的图像修复网络,运用注意力(attention)机制,将高层特征逐层次用于指导低层特征的补全. 相较于图像修复算法须首先结合待修复区域周边信息来尽可能准确地获得待修复区域的语义,在本研究的连续数字变焦问题中,可以直接将上采样后的短焦相机图像作为待修复图像,利用短焦相机图像原有的准确的语义信息将长焦相机图像的纹理细节迁移到短焦相机图像上,从而获得高质量的变焦后图像. ...
... 式中:f 为ATN模块的操作,研究[16 ] 已经证实利用这种跨层的注意力转移和金字塔填充机制,可以提升缺失区域的视觉和语义连贯性. ...
1
... 生成对抗网络可以生成清晰且视觉上令人满意的图像. 本研究采用WGAN-GP网络[17 ] ,生成对抗损失可以表示为 ...
1
... 感知损失利用预训练完成的VGG19网络[18 ] ,已经被证明可以改善图像的视觉效果,更好地还原出图像的纹理细节,可以表示为 ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}