

敏捷成像卫星是有效载荷固定在卫星上、依靠姿控系统控制卫星整体沿俯仰、滚转和偏航3个轴向摆动的小卫星. 由于姿控技术水平的限制,目前大部分敏捷成像卫星都只有俯仰和滚转2个轴向的自由度. 当敏捷成像卫星运行至观测目标的前方、后方和上方时,均可以对目标进行观测,具有较长的观测时间窗口. 在较长的观测时间窗口内,可以选取其中任何一段时间对目标进行观测,具有较高的观测灵活性. 尤其在密集观测场景下,一次过境的情况下可以完成更多目标的观测,具备更高的任务执行效率[1].
密集观测场景下的敏捷成像卫星任务规划问题相比于非敏捷成像卫星的任务规划问题更复杂,主要表现在以下3个方面. 1)任务观测时间选取有较高的灵活性. 敏捷成像卫星具有较长的时间窗口,观测时间的选取具有更大的解空间. 2)任务之间的耦合度较高. 在密集观测场景下,时间窗口相互重叠,上一任务观测时间的选取会对下一任务是否可观测、实际可用时间窗口的大小和观测时间的选取产生影响. 3)输入任务序列较长. 考虑到求解算法的时间复杂度和任务序列的长度有关,当输入任务序列长度增加时,需要更长的求解时间.
针对密集观测场景下的敏捷成像卫星任务规划问题的复杂性和难点,本文基于深度强化学习(deep reinforcement learning,DRL)的方法,对敏捷成像卫星任务规划问题进行求解. 该方法避免了以上传统方法需要针对特定敏捷成像卫星任务规划问题模型进行手工设计启发式因子的过程,以数据驱动的方式对敏捷成像卫星任务规划问题进行求解. 本文的主要工作包含以下2个方面. 1)综合考虑时间窗口约束、任务转移时卫星姿态调整时间、存储约束和电量约束,对敏捷成像卫星任务规划问题进行建模;2)提出Ind-PN的算法模型,对敏捷成像卫星任务规划问题进行求解,基于Actor Critic强化学习算法[11]对算法模型进行训练,以获得最大的观测收益率.
1. 敏捷成像卫星任务规划问题描述
1.1. 敏捷成像卫星任务规划问题的约束分析
考虑敏捷成像卫星在一次过境时,对一定区域内的密集点目标进行任务规划. 在进行敏捷成像卫星任务规划时,综合考虑以下约束.
1)时间窗口约束. 卫星对每个地面目标有一个可观测的时间窗口,同时考虑任务执行所需要的时间和任务转移时卫星进行姿态调整消耗的时间,任务执行的时间区间要位于任务可观测的时间窗口之内. 2)存储约束. 卫星在执行每个任务时需要消耗存储空间,仅考虑无数据下传的情况下,卫星所消耗的存储空间之和不超过卫星所提供的总存储空间. 3)电量约束. 卫星在执行每个任务时需要消耗电量,在任务转移时卫星进行姿态调整时需要消耗电量,所需消耗的电量与卫星姿态调整的角度和单位角度消耗的电量有关. 仅考虑无在轨充电的情况下,卫星所消耗的电量之和不超过卫星所提供的总电量.
1.2. 敏捷成像卫星任务规划问题的输入输出
将输入任务向量定义为
将每个任务
1.3. 敏捷成像卫星任务规划问题的描述
假设任务转移时卫星进行姿态调整消耗的时间为
图 1
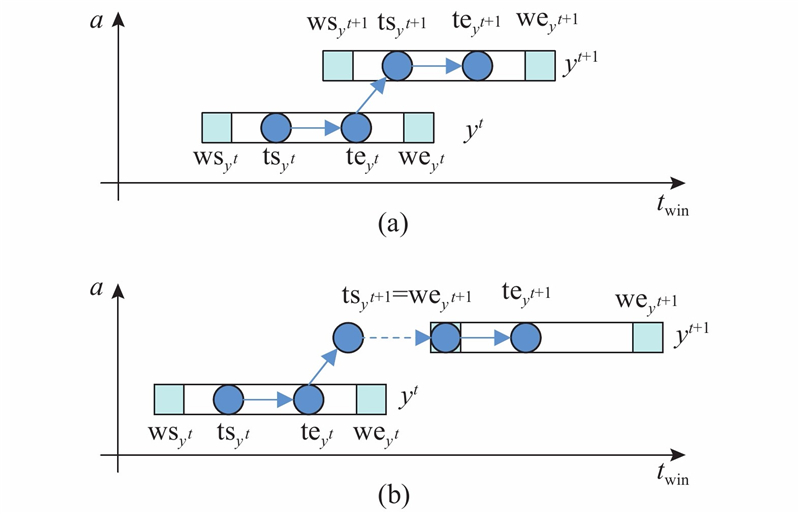
对任务
式中:
若任务
假设卫星的总存储空间为
综合考虑各类约束,将收益率
2. 算法模型结构和训练
2.1. 算法模型整体结构
将敏捷成像卫星任务规划问题建模成序列决策问题,建立序列到序列(sequence to sequence,Seq2Seq)的算法模型结构,包含编码器和解码器2部分. 使用编码器对输入序列进行编码,获取输入样本序列的高维特征表示. 在解码器的每个解码时间步骤
提出的算法模型Ind-PN的整体结构如图2所示,主要分为以下3部分. 1)编码器部分:使用一维卷积层作为嵌入层(embedding layer,EL)并作为算法模型的编码器,将输入序列中每个任务的静态元素和动态元素分别映射为高维向量. 对于每个任务
图 2
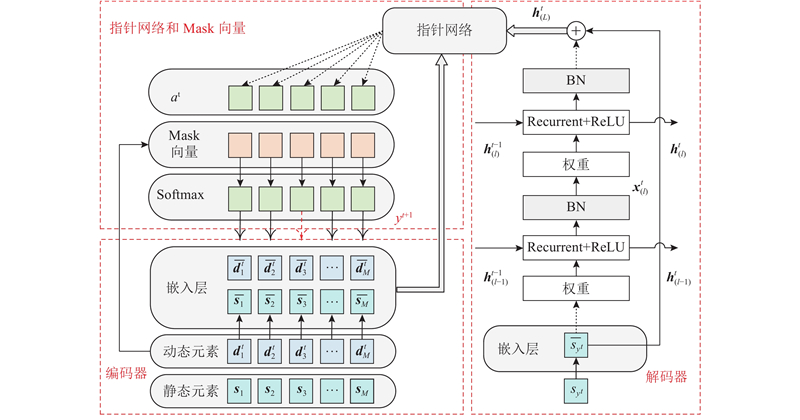
2.2. 解码器
对于传统的循环神经网络(recurrent neural network,RNN),在每个解码时间步骤
式中:
IndRNN是对传统RNN的改进,在每个解码时间步骤
式中:
使用
式中:
其中
第1层输入向量
式中:
最后1层隐含层状态
式中:“
2.3. Pointer Networks机制应用
PN机制[16]的具体计算过程如下.
1)将
式中:
2)中间向量
式中:
3)计算得到下一时间步骤
式中:
2.4. Mask向量
使用Mask向量来考虑敏捷成像卫星任务规划问题中的各类约束,Mask向量的长度和输入序列的长度相等,每位的取值为0或1. 当Mask向量中某位的值为0时,经式(18)计算所得对应的概率为0,可以将对应的任务排除. 在解码时间步骤
算法1:动态元素和Mask向量更新
输入:静态元素
输出:动态元素
1)根据静态元素
2)根据式(1),使用
3)根据静态元素
4)根据式(4),使用
5)使用
6)使用
7)根据
8)将Mask初始化为
9)根据动态元素
10)根据动态元素
11)根据动态元素
12)根据动态元素
将Mask初始化为
2.5. 算法模型训练
假设在满足各类约束的条件下,通过随机策略
模型训练的目标是寻找最优的策略为
使用Actor Critic算法对算法模型进行训练. Actor Critic算法由 2部分神经网络构成,分别如下.
1)Actor网络:即Ind-PN算法模型. 根据输入序列,计算得到对应输入序列各节点的概率分布. 假设Actor网络的参数为
式中:
2)Critic网络:根据输入序列计算,可以获得收益率的评估值. 假设Critic网络的参数为
式中:
Ind-PN算法模型训练的伪代码如下.
算法2:Ind-PN算法模型训练
输入:训练步长
输出:Actor网络参数
1)初始化Actor网络的参数为
2)循环执行以下步骤
3)将参数的梯度初始化为0:
4)从训练数据集
5)将Mask初始化为
6)对于每个训练样本
7)根据式(18)计算得到
8)根据
9)根据式(9)计算获得的收益率
10)根据式(20)、(21)计算参数的梯度:
11)更新参数:
3. 仿真实验和对比
3.1. 任务元素和场景的设定
目前,敏捷成像卫星任务规划领域没有公认的任务测试集合,因此设计可以生成不同长度样本序列的生成器. 根据假设的敏捷成像卫星任务规划场景,对各参数进行设计. 在实际应用场景中,可以根据特定任务规划场景下各任务元素的分布情况和卫星的性能参数对场景参数进行调整,对算法模型重新训练,以保证算法模型对特定任务规划场景下进行任务规划的效果.
假设在敏捷成像卫星任务规划的场景中,时间窗口开始时间为
表 1 各任务元素和场景参数的设定
Tab.1
| 元素 | 设定值 | 数据类型 |
| | | 浮点变量 |
| | | 浮点变量 |
| | | 浮点变量 |
| | | 浮点变量 |
| | | 浮点变量 |
| | | 浮点变量 |
| | | 浮点变量 |
| | 初始设定为1 | 整型变量,取值为0或1 |
| | 初始设定为1 | 整型变量,取值为0或1 |
| | 初始设定为0.5 | 浮点变量 |
| | 初始设定为0.5 | 浮点变量 |
| | 初始设定为0 | 整型变量 |
| | 初始设定为0 | 浮点变量 |
| | 设定为0.2 | 浮点常量 |
| | 设定为0.01 | 浮点常量 |
3.2. 模型训练和推理结果
训练数据集的设定如下:输入样本序列的长度为200,训练样本的数量为105. 模型训练的超参数设定如下:每批训练样本的数量为40,训练的轮次(Epoch)数为10,Actor网络的学习率为5×10−4,Critic网络的学习率为5×10−4,学习率的衰减比率为0.8,学习率的衰减步长为1 000,优化器为Adam[18]. 模型的超参数设定如下:EL的隐含层维度为256,IndRNN的隐含层维度为256,IndRNN的层数为4,PN机制的隐含层维度为256,模型的Dropout比率为0.1. 实验环境的设定如下:操作系统为Ubuntu16.04,CPU为Intel Xeon E5-2620,GPU为RTX2080Ti,深度学习框架为Pytorch.
图 3
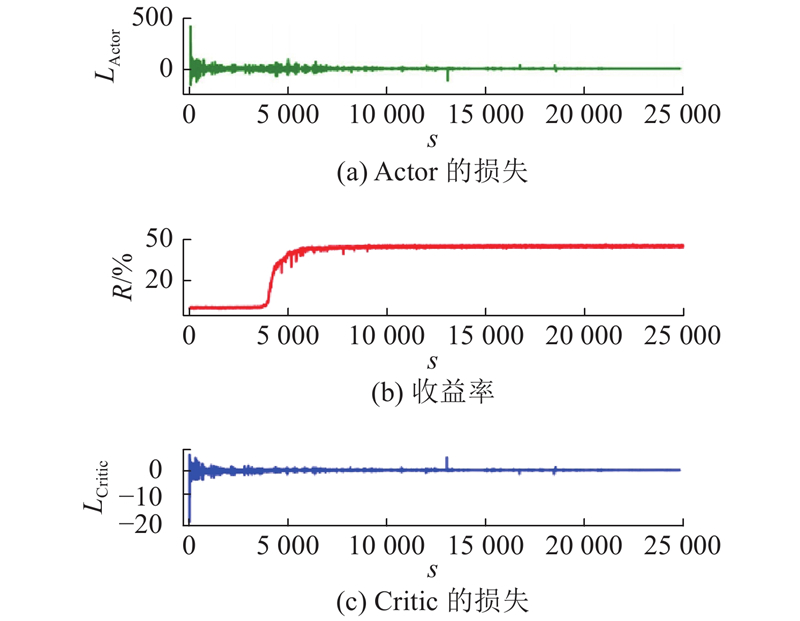
图 3 Ind-PN算法模型训练的收敛曲线
Fig.3 Convergence curve of Ind-PN algorithm model training
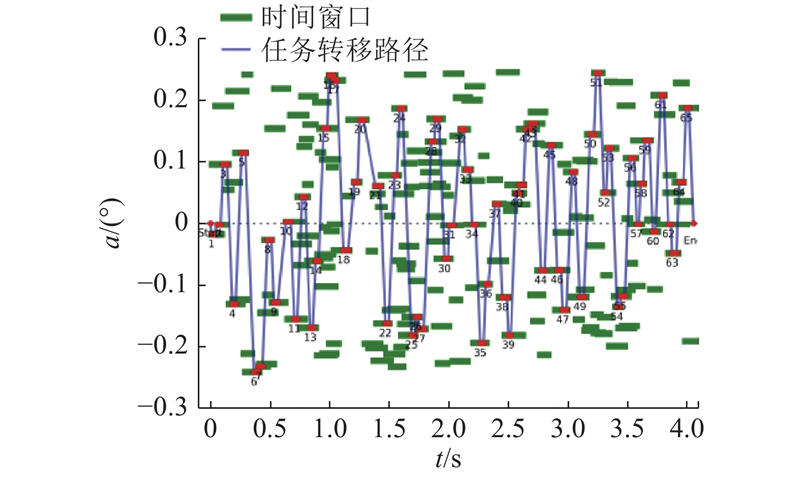
在应急和救灾场景中,目标呈现出在区域内分布密集的特点. 对固定时间跨度内的序列长度进行不同的设置,分别为100和200,对算法在特定场景下的功能进行仿真验证. 在序列长度为200的数据集上训练Ind-PN算法模型,对不同长度的输入样本序列进行推理,推理结果分别如图4、5所示. 图中,
图 4
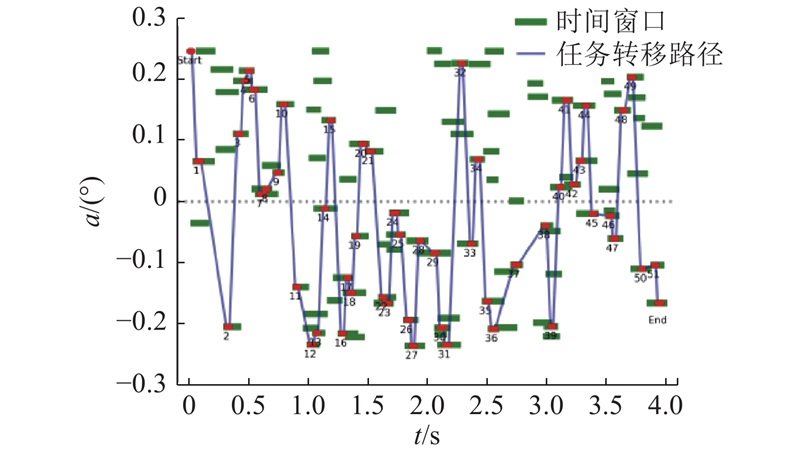
图 5
3.3. 训练算法对比
在REINFORCE算法[19]中,根据输入序列计算得到对应输入序列各节点的概率分布,直接对Ind-PN算法模型的参数
将序列长度设置为200,训练轮次设置为10,解码器设置为4层的IndRNN,进行BN和RES操作. 分别对Actor Critic算法和REINFORCE算法训练过程中Reward和Loss的收敛曲线进行对比,结果如图6所示. 可以看出,与REINFORCE算法相比,Actor Critic算法通过设置Critic网络对收益率的基准进行估计,减小了梯度的方差,降低了训练过程中梯度下降算法的波动性.
图 6
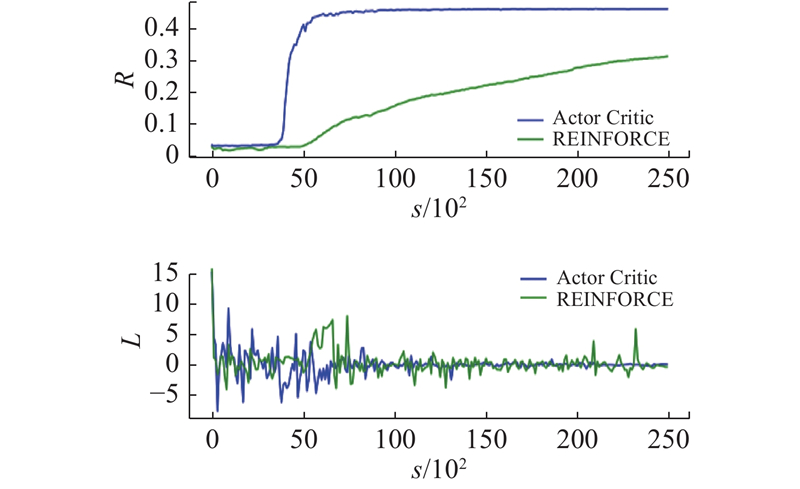
图 6 Reward和Loss收敛曲线对比
Fig.6 Comparison of convergence curves of Reward and Loss
3.4. 算法模型对比
图 7
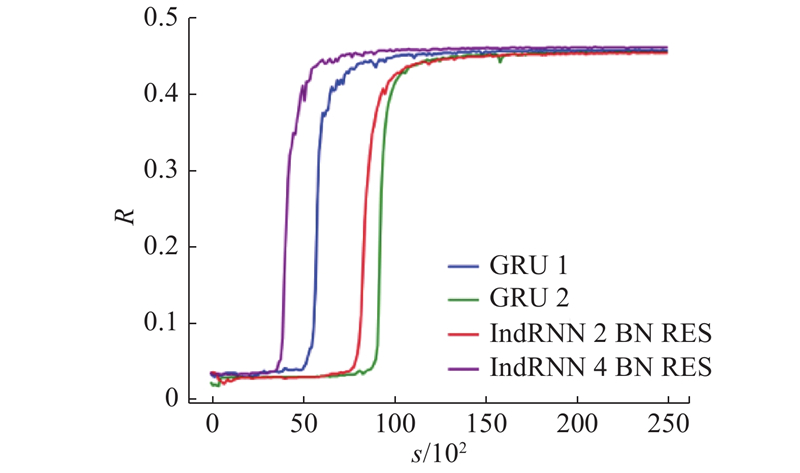
当训练数据集中样本序列的长度为200时,模型获得的收益率对比如表2所示. 当算法模型使用GRU作为解码器时,将层数由1层加深至2层,收益率下降. 当算法模型使用IndRNN作为解码器时,将层数由2层加深至4层,收益率增大. 当算法模型使用4层的IndRNN结构作为解码器,并进行BN和RES操作时,可以获得最高的收益率为46.1%.
表 2 算法模型收益率的对比
Tab.2
| 序列长度 | 解码器 | 层数 | 轮次 | R /% |
| 200 | GRU | 1 | 10 | 45.7 |
| 200 | GRU | 2 | 10 | 45.5 |
| 200 | IndRNN+BN+RES | 2 | 10 | 45.4 |
| 200 | IndRNN+BN+RES | 4 | 10 | 46.1 |
将训练数据集中样本序列的长度设置为400,训练过程中模型收益率的收敛曲线对比如图8所示. 当算法模型使用4层的IndRNN结构作为解码器,并进行BN和RES操作时,模型在训练时可以更快地收敛,获得更高的收益率.
图 8
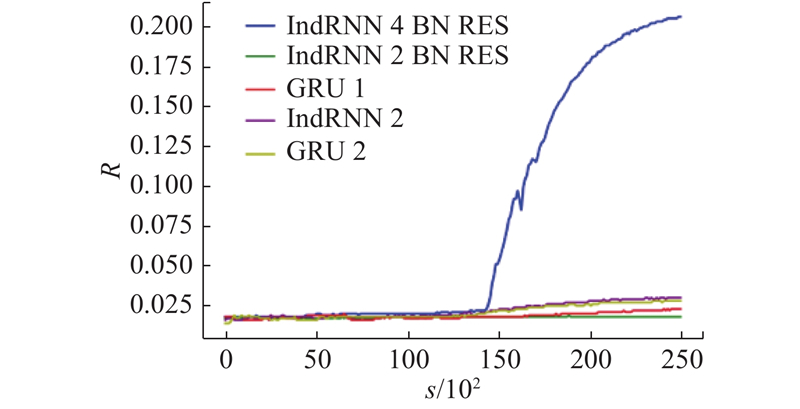
模型获得收益率的对比如表3所示. 由于仿真场景中任务分布的时间跨度是固定的,当序列长度增大时任务间的分布变得更加密集,产生了更多时间窗口冲突的任务. 当样本序列的长度为400时,对于使用不同解码器的算法模型,可以获得的收益率都产生了明显的下降. 当算法模型使用4层的IndRNN结构作为解码器,并进行BN和RES操作时,可以获得最高的收益率为20.6%.
表 3 算法模型收益率的对比
Tab.3
| 序列长度 | 解码器 | 层数 | 轮次 | R /% |
| 400 | GRU | 1 | 10 | 2.3 |
| 400 | GRU | 2 | 10 | 2.8 |
| 400 | IndRNN | 2 | 10 | 3.0 |
| 400 | IndRNN+BN+RES | 2 | 10 | 1.8 |
| 400 | IndRNN+BN+RES | 4 | 10 | 20.6 |
3.5. Ind-PN算法对比蚁群优化算法
赵凡宇等[23]基于蚁群优化(ant colony optimization,ACO)算法,对多目标的卫星任务规划问题进行求解. 在序列长度为400的数据集上训练Ind-PN算法模型(解码器为4层的IndRNN,并进行BN和RES操作,训练10个轮次),对于不同长度的输入样本序列不需要重新训练,可以进行推理并获取规划结果. 为了保证实验对比的有效性,基于ACO算法对提出的敏捷成像卫星任务规划问题模型的求解进行了实现. 针对同样的敏捷成像卫星任务规划问题模型和同样的样本序列,对Ind-PN算法和ACO算法规划结果的收益率和求解时间进行对比. 将输入样本序列的长度分别设置为100、200、300和400,对比结果如表4所示. 表中,tsol为求解时间. 可以看出,在密集观测场景下,与ACO算法相比,对于不同长度的输入序列Ind-PN算法,获得了更高的收益率. 与ACO这类迭代优化算法相比,Ind-PN算法在求解速度上具备明显的优势.
表 4 Ind-PN算法和ACO算法的对比
Tab.4
| 序列长度 | 算法 | R /% | tsol /s |
| 100 | ACO | 56.30 | 9.001 |
| 100 | Ind-PN | 64.50 | 0.328 |
| 200 | ACO | 33.19 | 19.140 |
| 200 | Ind-PN | 41.20 | 0.453 |
| 300 | ACO | 22.32 | 30.342 |
| 300 | Ind-PN | 33.04 | 0.499 |
| 400 | ACO | 15.98 | 38.766 |
| 400 | Ind-PN | 22.63 | 0.578 |
4. 结 语
本文针对敏捷成像卫星任务规划问题求解空间大、输入任务序列长度较长的特点,综合考虑时间窗口约束、任务转移时卫星进行姿态调整的时间、存储约束和电量约束,对敏捷成像卫星任务规划问题进行建模. 基于深度强化学习,对敏捷成像卫星任务规划问题的求解进行了实现,这种数据驱动的方法为求解敏捷成像卫星任务规划问题提供了新的思路. 与启发式的求解算法相比,训练好的模型可以直接对输入序列进行端到端的推理,避免了迭代求解的过程,极大地提高了求解速度. 提出的Ind-PN算法模型使用多层的IndRNN结构作为解码器,在密集观测场景下较长任务序列的求解上具备明显的优势. 实验结果表明,对于长度为200和400的输入任务序列,Ind-PN算法模型均获得了更快的收敛速度和收益率.
下一步的工作是探索更高效的算法模型结构和训练算法,建立更完善的敏捷成像卫星任务规划问题模型,对多星联合的敏捷成像卫星任务规划方法展开研究.
参考文献
敏捷成像卫星调度问题技术综述
[J].
Literature review for autonomous scheduling technology of agile earth observation satellites
[J].
基于改进蚁群算法的敏捷成像卫星任务调度方法
[J].DOI:10.3969/j.issn.1000-6788.2012.11.023 [本文引用: 1]
Agile imaging satellite task scheduling method based on improved ant colony algorithm
[J].DOI:10.3969/j.issn.1000-6788.2012.11.023 [本文引用: 1]
敏捷成像卫星多星密集任务调度方法
[J].
Agile imaging satellite multi-satellite intensive task scheduling method
[J].
Slew path planning of agile-satellite antenna pointing mechanism with optimal real-time data transmission performance
[J].
Area targets observation mission planning of agile satellite considering the drift angle constraint
[J].
Onboard mission planning for agile satellite using modified mixed-integer linear programming
[J].
A new multi-satellite autonomous mission allocation and planning method
[J].DOI:10.1016/j.actaastro.2018.11.001 [本文引用: 1]
敏捷成像卫星密集任务聚类方法
[J].DOI:10.3969/j.issn.1001-506X.2012.05.14 [本文引用: 1]
Agile imaging satellite intensive task clustering method
[J].DOI:10.3969/j.issn.1001-506X.2012.05.14 [本文引用: 1]
基于改进烟花算法的密集任务成像卫星调度方法
[J].
Intensive mission imaging satellite scheduling method based on improved fireworks algorithm
[J].
敏捷凝视卫星密集点目标聚类与最优观测规划
[J].
Agile gaze satellite cluster and optimal observation planning
[J].
在线医疗问答文本的命名实体识别
[J].
Named entity recognition of online medical question and answer text
[J].
Simple statistical gradient-following algorithms for connectionist reinforcement learning
[J].DOI:10.1023/A:1022672621406 [本文引用: 1]
敏捷成像卫星调度的改进量子遗传算法
[J].
Scheduling of agile satellites based on an improved quantum genetic algorithm
[J].
基于遗传禁忌混合算法的敏捷卫星任务规划
[J].DOI:10.3969/j.issn.1674-1579.2019.06.004 [本文引用: 2]
Mission scheduling for agile earth observation satellite based on genetic-tabu hybrid algorithm
[J].DOI:10.3969/j.issn.1674-1579.2019.06.004 [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}