|
|
|
| High-performance lightweight frame extrapolation technique based on optical flow reprojection |
Haoyu QIN( ),Jie GUO*(),Haonan ZHANG,Zesen FENG,Liang PU,Jiawei ZHANG,Yanwen GUO ),Jie GUO*(),Haonan ZHANG,Zesen FENG,Liang PU,Jiawei ZHANG,Yanwen GUO |
| Department of Computer Science and Technology, Nanjing University, Nanjing 210033, China |
|
|
|
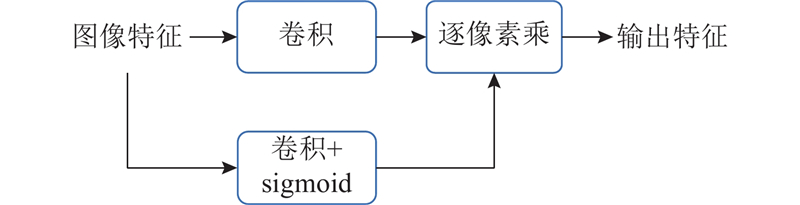
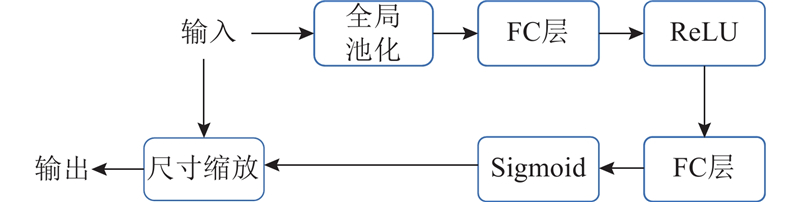
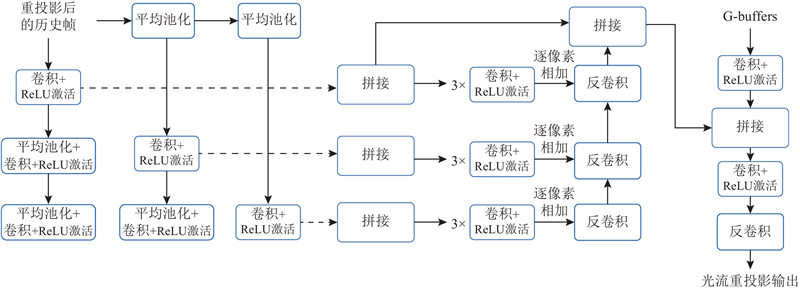
Abstract A high-performance lightweight frame extrapolation technique based on optical flow reprojection was proposed in order to solve the problem of high time overhead in real-time rendering process. An optical flow reprojection module was proposed, which predicted the optical flow information between adjacent frames based on deep learning and applied optical flow reprojection to historical frames. Then the issue of areas such as shadows and highlights lacking motion information was addressed. The proposed method incorporated various lightweight designs, including low-resolution network inference and image inpainting based on SE (squeeze-and-excitation) modules, significantly reducing the computational overhead. The experimental results demonstrate that the proposed method achieves a threefold improvement in time performance compared to state-of-the-art frame extrapolation techniques.
|
|
Received: 01 July 2024
Published: 25 April 2025
|
|
|
| Fund: 中央高校基本科研业务费专项资金资助项目(2024300326). |
|
Corresponding Authors:
Jie GUO
E-mail: 449139777@qq.com;guojie@nju.edu.cn
|
基于光流重投影的高性能轻量级帧外插技术
为了解决实时渲染过程时间开销较大的问题,提出基于光流重投影的高性能轻量级帧外插技术.提出光流重投影模块,基于深度学习预测相邻帧之间的光流信息,对历史帧执行光流重投影,解决了阴影、高光区域没有运动信息的问题. 该方法引入多种轻量化设计,包括低分辨率网络推理、基于SE模块的图像填补,大幅减少了方法的时间开销. 经过实验验证可知,相对于最前沿的帧外插技术,该方法能够达到3倍的时间性能提升.
关键词:
实时渲染,
帧外插,
光流重投影,
图像填补
|
|
| [1] |
SANDY M, ANDERSSON J, BARRÉ-BRISEBOIS C. Directx: evolving microsoft’s graphics platform [C]// Game Developers Conference . San Francisco: IEEE, 2018.
|
|
|
| [2] |
BURGESS J RTX on the NVIDIA Turing GPU[J]. IEEE Micro, 2020, 40 (2): 36- 44
doi: 10.1109/MM.2020.2971677
|
|
|
| [3] |
HARADA T. Hardware-accelerated ray tracing in AMD Radeon ProRender 2.0 [EB/OL]. [2024-06-20]. https://gpuopen.com/learn/radeon-prorender-2-0/.
|
|
|
| [4] |
GUO J, FU X, LIN L, et al. ExtraNet: real-time extrapolated rendering for low-latency temporal supersampling [J]. ACM Transactions on Graphics , 2021, 40(6): 1-16.
|
|
|
| [5] |
BAO W, LAI W S, MA C, et al. Depth-aware video frame interpolation [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Los Angeles: IEEE, 2019.
|
|
|
| [6] |
LEE H, KIM T, CHUNG T Y, et al. AdaCoF: adaptive collaboration of flows for video frame interpolation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020.
|
|
|
| [7] |
NIKLAUS S, MAI L, LIU F. Video frame interpolation via adaptive convolution [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Hawaii: IEEE, 2017.
|
|
|
| [8] |
OCULUS V. Asynchronous spacewarp [EB/OL]. [2024-06-20]. https://developers.meta.com/horizon/blog/asynchronous-spacewarp/.
|
|
|
| [9] |
MEYER S, WANG O, ZIMMER H, et al. Phase-based frame interpolation for video [C]// IEEE Conference on Computer Vision and Pattern Recognition .Washington DC: IEEE, 2015: 1410-1418.
|
|
|
| [10] |
MEYER S, DJELOUAH A, MCWILLIAMS B, et al. PhaseNet for video frame interpolation [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2018: 498-507.
|
|
|
| [11] |
JIANG H, SUN D, JAMPANI V, et al. Super SloMo: high quality estimation of multiple intermediate frames for video interpolation [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2018.
|
|
|
| [12] |
LONG G, KNEIP L, ALVAREZ J M, et al. Learning image matching by simply watching video [C]//LEIBE B, MATAS J, SEBE N, et al. European Conference on Computer Vision . Cham: Springer, 2016: 434-450.
|
|
|
| [13] |
CHOI M, KIM H, HAN B, et al. Channel attention is all you need for video frame interpolation [C]// AAAI Conference on Artificial Intelligence . New York: AAAI, 2020.
|
|
|
| [14] |
KALLURI T, PATHAK D, CHANDRAKER M, et al. FLAVR: flow-agnostic video representations for fast frame interpolation [C]// IEEE Workshop/Winter Conference on Applications of Computer Vision . [S. l.]: IEEE, 2020.
|
|
|
| [15] |
LU L, WU R, LIN H, et al. Video frame interpolation with Transformer [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 3532-3542.
|
|
|
| [16] |
REDA F, KONTKANEN J, TABELLION E, et al. FILM: frame interpolation for large motion [C]// European Conference on Computer Vision . Tel Aviv: Springer, 2022.
|
|
|
| [17] |
DIDYK P, EISEMANN E, RITSCHEL T, et al Perceptually-motivated real-time temporal upsampling of 3D content for high-refresh-rate displays[J]. Computer Graphics Forum, 2010, 29 (2): 713- 722
doi: 10.1111/j.1467-8659.2009.01641.x
|
|
|
| [18] |
DIDYK P, RITSCHEL T, EISEMANN E, et al. Adaptive image-space stereo view synthesis [C]// Proceedings of Vision, Modeling, and Visualization Workshop 2010 . Siegen: [s. n.], 2010.
|
|
|
| [19] |
YANG L, TSE Y C, SANDER P V, et al. Image-based bidirectional scene reprojection [C]// Proceedings of the 2011 SIGGRAPH Asia Conference . Hongkong: ACM, 2011: 1-10.
|
|
|
| [20] |
BOWLES H, MITCHELL K, SUMNER R, et al. Iterative image warping [C]// Computer Graphics Forum. Oxford: Blackwell Publishing Ltd, 2012: 237-246.
|
|
|
| [21] |
NTAVELIS E, ROMERO A, BIGDELI S, et al. AIM 2020 challenge on image extreme inpainting [EB/OL]. [2024-06-20]. http://arxiv.org/abs/2010.01110.
|
|
|
| [22] |
PATHAK D, KRAHENBUHL P, DONAHUE J, et al. Context encoders: feature learning by inpainting [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1604.07379.
|
|
|
| [23] |
ZENG Y, FU J, CHAO H, et al. Learning pyramid-context encoder network for high-quality image inpainting [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1904.07475.
|
|
|
| [24] |
LIU G, REDA F A, SHIH K J, et al. Image inpainting for irregular holes using partial convolutions [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1804.07723.
|
|
|
| [25] |
YU J, LIN Z, YANG J, et al. Free-form image inpainting with gated convolution [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1806.03589.
|
|
|
| [26] |
YU F, KOLTUN V. Multi-scale context aggregation by dilated convolutions [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1511.07122.
|
|
|
| [27] |
REN Y, YU X, ZHANG R, et al. StructureFlow: image inpainting via structure-aware appearance flow [EB/OL]. [2024-06-20]. https://arxiv.org/abs/1908.03852.
|
|
|
| [28] |
LIU H, WANG Y, WANG M, et al. Delving globally into texture and structure for image inpainting [C]// Proceedings of the 30th ACM International Conference on Multimedia . [S. l. ]: ACM, 2022.
|
|
|
| [29] |
PIRNAY J, CHAI K. Inpainting Transformer for anomaly detection [EB/OL]. [2024-06-20]. https://arxiv.org/abs/2104.13897.
|
|
|
| [30] |
LUGMAYR A, DANELLJAN M, ROMERO A, et al. RePaint: inpainting using denoising diffusion probabilistic models [EB/OL]. [2024-06-20]. https://arxiv.org/abs/2201.09865.
|
|
|
| [31] |
HO J, JAIN A, ABBEEL P. Denoising diffusion probabilistic models [[EB/OL]. [2024-06-20]. https://arxiv.org/abs/2006.11239.
|
|
|
| [32] |
GUO J, LAI S, TAO C, et al. Highlight-aware two-stream network for single image SVBRDF acquisition [J]. ACM Transactions on Graphics , 2021, 40(4): 1-14.
|
|
|
| [33] |
ZENG Z, LIU S, YANG J, et al Temporally reliable motion vectors for real-time ray tracing[J]. Computer Graphics Forum, 2021, 40 (2): 79- 90
doi: 10.1111/cgf.142616
|
|
|
| [34] |
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Los Alamitos: IEEE, 2018: 7132-7141.
|
|
|
| [35] |
PASZKE A, GROSS S, MASSA F, et al. PyTorch: an imperative style, high-performance deep learning library [C]//WALLACH H M, LAROCHELLE H, BEYGELZIMER A, et al. Proceedings of the 33rd International Conference on Neural Information Processing Systems. Vancouver: MIT Press, 2019: 8024-8035.
|
|
|
| [36] |
KINGMA D P, BA J. Adam: a method for stochastic optimization [C]// BENGIO Y, LECUN Y. 3rd International Conference on Learning Representations. San Diego: MIT Press, 2015.
|
|
|
| [37] |
SCHIED C, KAPLANYAN A, WYMAN C, et al. Spatiotemporal variance-guided filtering: real-time reconstruction for path-traced global illumination [C]// Proceedings of High Performance Graphics .[S. l.]: ACM, 2017 .
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|