|
|
|
| Graph contrastive learning based on negative-sample-free loss and adaptive augmentation |
Tian-qi ZHOU( ),Yan YANG*(),Ji-jie ZHANG,Shao-wei YIN,Zeng-qiang GUO ),Yan YANG*(),Ji-jie ZHANG,Shao-wei YIN,Zeng-qiang GUO |
| College of Computer Science and Technology, Heilongjiang University, Harbin 150000, China |
|
|
|
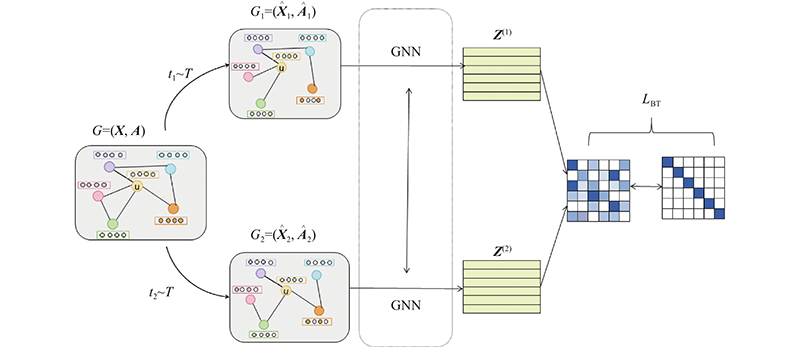
Abstract A graph contrastive learning framework based on negative-sample-free loss and adaptive augmentation was proposed to address the problems of random enhancement of the input graph and the need to construct losses using negative samples in graph contrastive learning methods. In the framework, the centrality of the node degree in the input graph was used to generate two views by adaptive enhancement, which avoided the deletion of important nodes and edges by random enhancement and thus improved the robustness of the framework . The embedding matrix of the two views was obtained using the same weight encoder network without specifying. A cross-correlation-based loss function which did not rely on non-symmetric neural network architectures was used to guide the framework learning. Negative samples were not required in this loss function, avoiding that negative samples became more challenging to define in the case of graphs and that negative samples increased the computational and storage burden of constructing losses. Results showed that the proposed framework outperformed many baseline methods in terms of classification accuracy in the node classification experiments on three citation datasets.
|
|
Received: 28 July 2022
Published: 28 February 2023
|
|
|
| Fund: 黑龙江省自然科学基金-联合引导项目(LH2020F043) |
|
Corresponding Authors:
Yan YANG
E-mail: 2201816@s.hlju.edu.cn;yangyan@hlju.edu.cn
|
基于无负样本损失和自适应增强的图对比学习
针对图对比学习方法中对输入图进行随机增强和须利用负样本构造损失的问题,提出基于无负样本损失和自适应增强的图对比学习框架.该框架利用输入图中节点度的中心性进行自适应增强以生成2个视图,避免随机增强对重要的节点和边进行删除从而影响生成视图的质量,以提高框架的鲁棒性.利用相同权重编码器网络得到2个视图的嵌入矩阵,无须进行指定. 利用基于互相关的损失函数指导框架学习,该损失函数不依赖于非对称神经网络架构,无须用负样本构造损失函数,从而避免在图的情况下难以定义的负样本变得更具有挑战性,以及负样本构造损失会增大计算和存储负担的问题.所提框架在3个引文数据集上进行节点分类实验,结果表明,其在分类准确性方面优于很多基线方法.
关键词:
自监督学习,
对比学习,
图神经网络,
自适应增强,
节点分类
|
|
| [1] |
XU K, HU W, LESKOVEC J, et al. How powerful are graph neural networks [C]// Proceedings of the 7th International Conference on Learning Representations. New Orleans: [s.n.], 2019: 1-17.
|
|
|
| [2] |
ABU-EL-HAIJA S, PEROZZI B, KAPOOR A, et al. Mixhop: higher-order graph convolutional architectures via sparsified neighborhood mixing [C]// Proceedings of the 36th International Conference on Machine Learning. Long Beach: PMLR , 2019: 21-29.
|
|
|
| [3] |
YOU J, YING R, LESKOVEC J. Position-aware graph neural networks [C]// Proceedings of the 36th International Conference on Machine Learning. Long Beach: PMLR, 2019: 7134-7143.
|
|
|
| [4] |
张雁操, 赵宇海, 史岚 融合图注意力的多特征链接预测算法[J]. 计算机科学与探索, 2022, 16 (5): 1096- 1106
ZHANG Yan-cao, ZHAO Yu-hai, SHI Lan Multi-feature based link prediction algorithm fusing graph attention[J]. Journal of Frontiers of Computer Science and Technology, 2022, 16 (5): 1096- 1106
doi: 10.3778/j.issn.1673-9418.2012092
|
|
|
| [5] |
KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [C]// Proceedings of the 5th International Conference on Learning Representations. Toulon: [s. n. ], 2017: 1-14.
|
|
|
| [6] |
VELICKOVIC P, FEDUS W, HAMILTON W L, et al. Deep graph Infomax [C]// Proceedings of the 7th International Conference on Learning Representations. New Orleans: [s.n.], 2019: 1-17.
|
|
|
| [7] |
YOU Y, CHEN T L, SUI Y D, et al. Graph contrastive learning with augmentations [C]// Advances in Neural Information Processing Systems. [s.l.]: MIT Press, 2020: 1-12.
|
|
|
| [8] |
HASSANI K, AHMADI A H K. Contrastive multi-view representation learning on graphs [C]// Proceedings of the 37th International Conference on Machine Learning. [s.l.]: PMLR, 2020: 4116-4126.
|
|
|
| [9] |
ZHU Y Q, XU Y C, LIU Q, et al. Graph contrastive learning with adaptive augmentation [C]// Proceedings of the 2021 World Wide Web Conference. [s.l.]: ACM, 2021: 2069-2080.
|
|
|
| [10] |
ZHU Y Q, XU Y C, YU F, et al. Deep graph contrastive representation learning [EB/OL]. [2022-03-21]. https://arxiv.org/abs/2006.04131.
|
|
|
| [11] |
THAKOOR S, TALLEC C, AZAR M G, et al. Bootstrapped representation learning on graphs [EB/OL]. [2021-02-18]. https://arxiv.org/abs/2102.06514.
|
|
|
| [12] |
BIELAK P, KAJDANOWICZ T, CHAWLA N V. Graph Barlow Twins: a self-supervised representation learning framework for graphs [EB/OL]. [2021-06-10]. https://arxiv.org/abs/2106.02466.
|
|
|
| [13] |
PEROZZI B, AL-RFOU R, SKIENA S. Deepwalk: online learning of social representations [C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. NewYork: ACM, 2014: 701-710.
|
|
|
| [14] |
GROVER A, LESKOVEC J. Node2vec: scalable feature learning for networks [C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. San Francisco: ACM, 2016: 855-864.
|
|
|
| [15] |
GRILL J B, ALTCHE F, TALLEC C, et al. Bootstrap Your Own Latent: a new approach to self-supervised learning [C]// Advances in Neural Information Proceedings Systems. [s.l.]: MIT Press, 2020: 1-35.
|
|
|
| [16] |
HJELM R, FEDOROV A, LAVOIE-MARCHILDON S, et al. Learning deep representations by mutual information estimation and maximization [C]// Proceedings of the 7th International Conference on Learning Representations. New Orleans: [s.n.], 2019: 1-24.
|
|
|
| [17] |
VELICKOVIC P, CUCURULL G, CASANOVA A, et al. Graph attention networks [C]// Proceedings of the 6th International Conference on Learning Representations. Vancouver: [s.n.], 2018: 1-12.
|
|
|
| [18] |
TSAI Y H, BAI S J, MORENCY L P, et al. A note on connecting Barlow Twins with negative-sample-free contrastive learning [EB/OL]. [2021-05-04]. https://arxiv.org/abs/2104.13712.
|
|
|
| [19] |
HAMILTON W L, YING Z, LESKOVEC J. Inductive representation learning on large graphs [C]// Advances in Neural Information Processing Systems. Long Beach: MIT Press, 2017: 1024-1034.
|
|
|
| [20] |
PENG Z, HUANG W, LUO M, et al. Graph representation learning via graphical mutual information maximization [C]// Proceedings of the 2020 World Wide Web Conference. Taipei: ACM, 2020: 259-270.
|
|
|
| [21] |
WAN S, PAN S, YANG J, et al. Contrastive and generative graph convolutional networks for graph-based semi-supervised learning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [s.l.]: AAAI, 2021: 10049-10057.
|
|
|
| [22] |
孙学全, 冯英浚 多层感知器的灵敏度分析[J]. 计算机学报, 2001, 24 (9): 951- 958
SUN Xue-quan, FENG Ying-jun Sensitivity analysis of multilayer perception[J]. Chinese Journal of Computers, 2001, 24 (9): 951- 958
doi: 10.3321/j.issn:0254-4164.2001.09.009
|
|
|
| [23] |
徐冰冰, 岑科廷, 黄俊杰, 等 图卷积神经网络综述[J]. 计算机学报, 2020, 43 (5): 755- 780
XU Bing-bing, CEN Ke-ting, HUANG Jun-jie, et al A survey on graph convolutional neural network[J]. Chinese Journal of Computers, 2020, 43 (5): 755- 780
doi: 10.11897/SP.J.1016.2020.00755
|
|
|
| [24] |
YANG Z W, COHEN W, SALAKHUTDINOV R. Revisiting semi-supervised learning with graph embeddings [C]// Proceedings of 33nd International Conference on Machine Learning. New York: [s.n.], 2016: 40-48.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|