|
|
|
| Low resource speech synthesis using ConvNeXt decoder and fundamental frequency prediction |
Meng WANG( ),Jian YANG*() ),Jian YANG*() |
| School of Information Science and Engineering, Yunnan University, Kunming 650504, China |
|
|
|
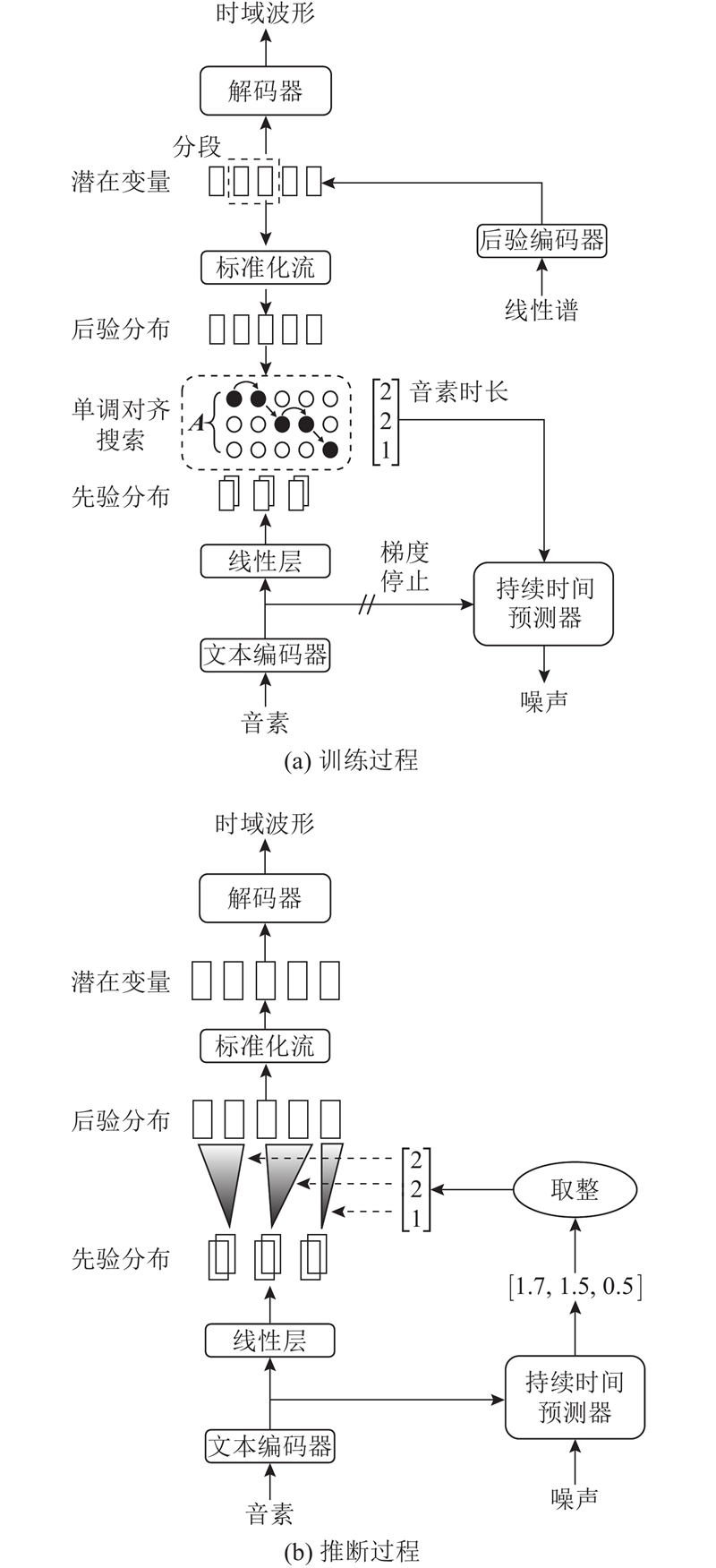
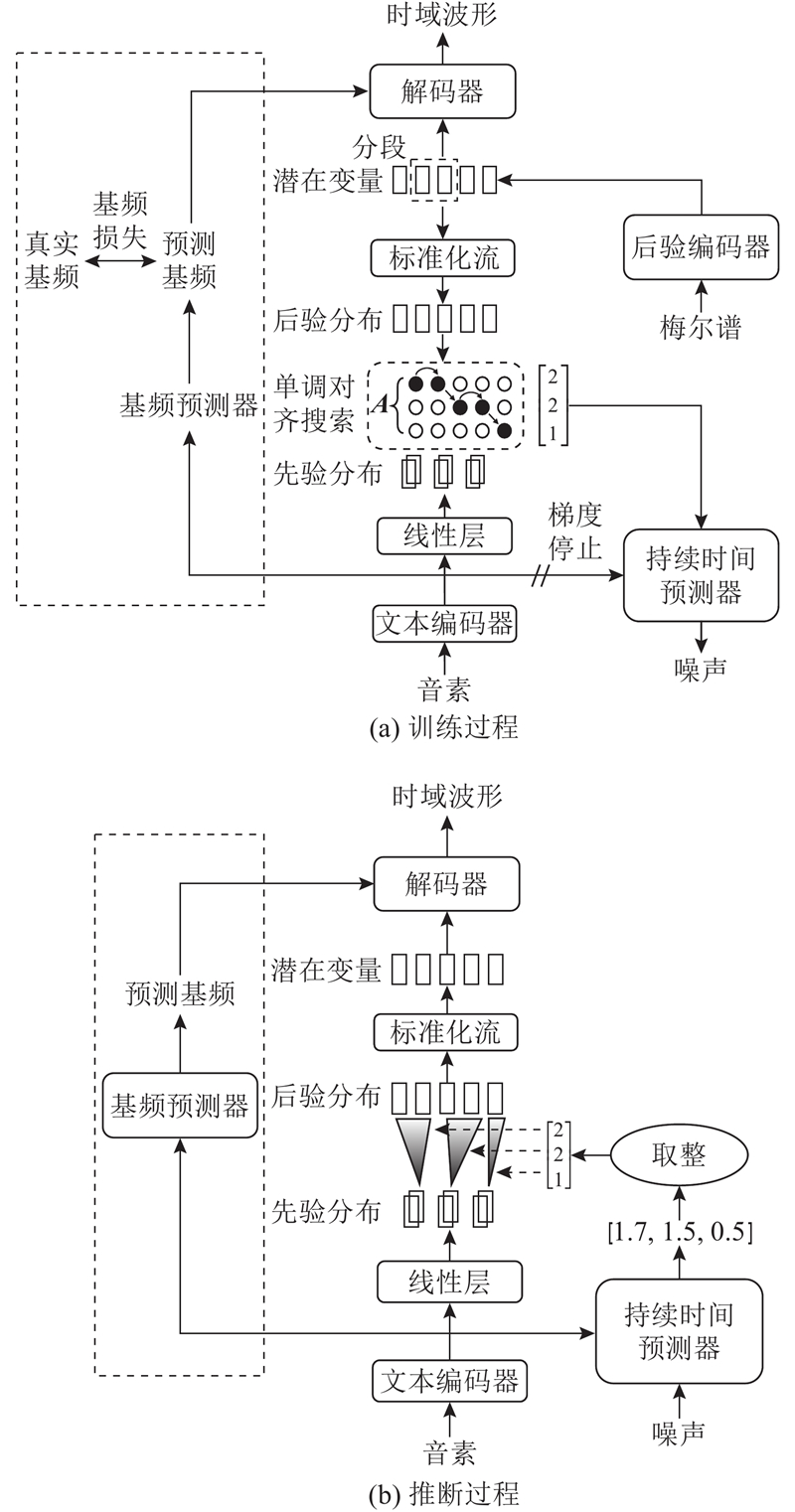
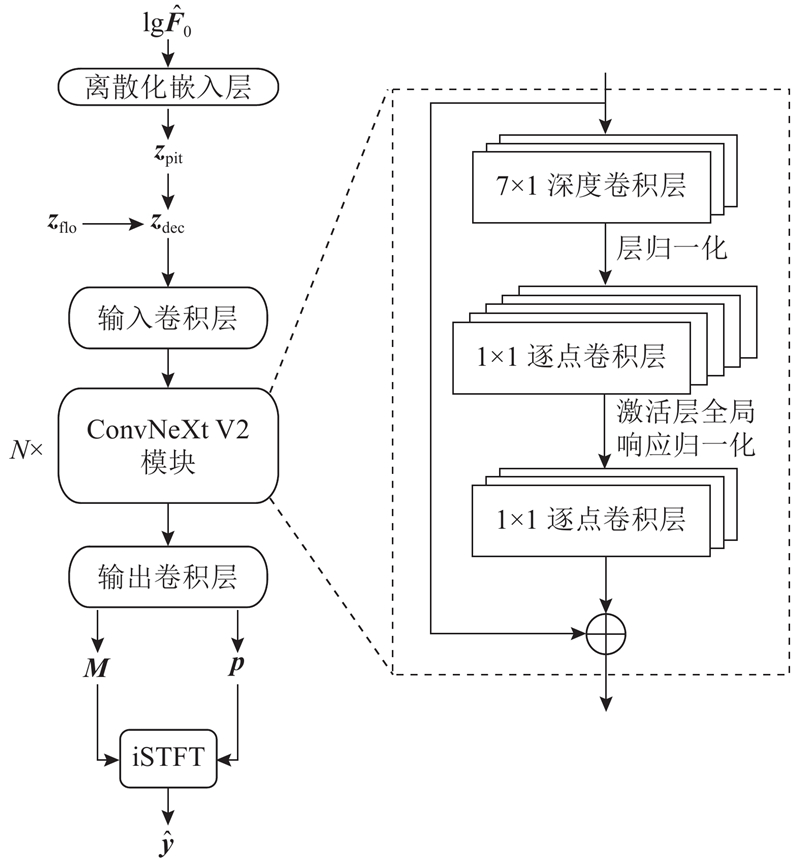
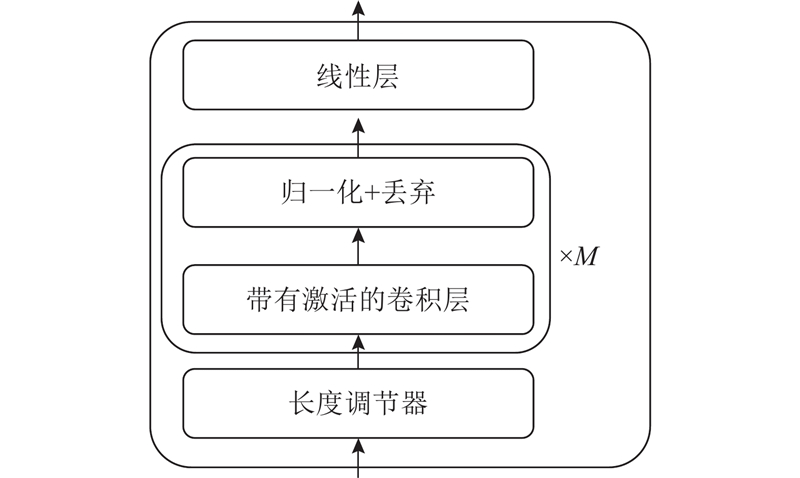
Abstract An improved model was proposed to enhance the speech naturalness of the existing models, specifically targeting the challenge of synthesizing speech for low-resource languages. VITS was employed as a baseline model, and the transposed convolutions in the original decoder were replaced by the ConvNeXt V2 modules to reduce aliasing artifacts. A new decoder was built by applying the inverse short-time Fourier transform (iSTFT) to enhance the naturalness and fluency of the synthesized speech. A frame-level fundamental frequency (F0) predictor was integrated into the model, and the output of the predictor was discretized and then transformed into a high-dimensional vector. The vector was combined with the vector output from the flow module in VITS and then fed into the new decoder. An extra F0 loss function was also introduced to capture and model tone variations. The improved model was trained and assessed using Burmese, Vietnamese, and Thai languages. Results of model performance comparison experiments show that the method outperforms the existing models in terms of speech synthesis quality.
|
|
Received: 29 August 2024
Published: 27 October 2025
|
|
|
| Fund: 国家重点研发计划资助项目(2020AAA0107901);云南大学第十五届研究生科研创新项目(KC-23236037). |
|
Corresponding Authors:
Jian YANG
E-mail: wangmeng_boo9@stu.ynu.edu.cn;jianyang@ynu.edu.cn
|
采用ConvNeXt解码器和基频预测的低资源语音合成
现有模型合成低资源语言的语音自然度低,为此提出改进模型. 以VITS为基线模型,使用ConvNeXt V2模块替换原模型解码器中的转置卷积模块以降低混叠干扰,应用逆短时傅立叶变换(iSTFT)构建新的解码器以提升合成语音的自然流畅性. 将帧级别的基频预测器引入模型,离散化预测器输出并转换为高维向量,再与VITS中流模块的输出向量拼接后送入所构建解码器结构中. 添加基频损失函数以捕捉和模拟声调. 使用缅甸语、越南语和泰语数据集训练并评估所提改进模型. 模型性能对比实验结果表明,所提改进模型的语音合成效果优于现有模型.
关键词:
语音合成,
低资源语言,
VITS,
ConvNeXt,
基频建模
|
|
| [1] |
BYAMBADORJ Z, NISHIMURA R, AYUSH A, et al. Multi-speaker TTS system for low-resource language using cross-lingual transfer learning and data augmentation [C]// Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Tokyo: IEEE, 2021: 849–853.
|
|
|
| [2] |
GOKAY R, YALCIN H. Improving low resource Turkish speech recognition with data augmentation and TTS [C]// Proceedings of the 16th International Multi-Conference on Systems, Signals and Devices. Istanbul: IEEE, 2019: 357–360.
|
|
|
| [3] |
SHEN J, PANG R, WEISS R J, et al. Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions [C]// Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing. Calgary: IEEE, 2018: 4779–4783.
|
|
|
| [4] |
REN Y, HU C X, TAN X, et al. FastSpeech 2: fast and high-quality end-to-end text to speech [EB/OL]. (2022−08−08)[2024−08−25]. https://arxiv.org/pdf/2006.04558.
|
|
|
| [5] |
KIM J, KIM S, KONG J, et al. Glow-TTS: a generative flow for text-to-speech via monotonic alignment search [C]// 34th Conference on Neural Information Processing Systems. Vancouver: [s.n.], 2020: 1−11.
|
|
|
| [6] |
KIM J, KONG J, SON J. Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech [EB/OL]. (2021−06−11)[2024−08−25]. https://arxiv.org/pdf/2106.06103.
|
|
|
| [7] |
KATUMBA A, KAGUMIRE S, NAKATUMBA-NABENDE J, et al Building text-to-speech models for low-resourced languages from crowdsourced data[J]. Applied AI Letters, 2025, 6 (2): e117
doi: 10.1002/ail2.117
|
|
|
| [8] |
KONG J, KIM J, BAE J. HiFi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis [C]// 34th Conference on Neural Information Processing Systems. Vancouver: [s.n.], 2020: 1−12.
|
|
|
| [9] |
MORRISON M, KUMAR R, KUMAR K, et al. Chunked autoregressive GAN for conditional waveform synthesis [EB/OL]. (2022−03−03)[2024−08−25]. https://arxiv.org/pdf/2110.10139.
|
|
|
| [10] |
KARRAS T, AITTALA M, LAINE S, et al. Alias-free generative adversarial networks [EB/OL]. [2021−10−18][2024−08−25]. https://arxiv.org/pdf/2106.12423.
|
|
|
| [11] |
TAN X, QIN T, SOONG F, et al. A survey on neural speech synthesis [EB/OL]. (2021−07−23)[2024−08−25]. https://arxiv.org/pdf/2106.15561.
|
|
|
| [12] |
LEE J, JUNG W, CHO H, et al. PITS: variational pitch inference without fundamental frequency for end-to-end pitch-controllable TTS [EB/OL]. (2023−06−06)[2024−11−20]. https://arxiv.org/pdf/2302.12391.
|
|
|
| [13] |
WOO S, DEBNATH S, HU R, et al. ConvNeXt V2: co-designing and scaling ConvNets with masked autoencoders [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 16133–16142.
|
|
|
| [14] |
VAN DEN OORD A, DIELEMAN S, ZEN H, et al. WaveNet: a generative model for raw audio [EB/OL]. (2016−09−19)[2024−08−25]. https://arxiv.org/pdf/1609.03499.
|
|
|
| [15] |
KANEKO T, TANAKA K, KAMEOKA H, et al. iSTFTNet: fast and lightweight mel-spectrogram vocoder incorporating inverse short-time Fourier transform [C]// Proceedings of the ICASSP 2022 - 2022 IEEE International Conference on Acoustics, Speech and Signal Processing. Singapore: IEEE, 2022: 6207–6211.
|
|
|
| [16] |
SIUZDAK H. Vocos: closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis [EB/OL]. (2024−05−29)[2024−08−25]. https://arxiv.org/pdf/2306.00814v3.
|
|
|
| [17] |
DONAHUE J, DIELEMAN S, BIŃKOWSKI M, et al. End-to-end adversarial text-to-speech [EB/OL]. (2021−03−17)[2024−08−25]. https://arxiv.org/pdf/2006.03575.
|
|
|
| [18] |
NGUYEN T T T, TRAN D D, RILLIARD A, et al. Intonation issues in HMM-based speech synthesis for Vietnamese [C]// Spoken Language Technologies for Under-Resourced Languages. Petersburg: [s.n.], 2014: 98−104.
|
|
|
| [19] |
NGUYEN T V, NGUYEN B Q, PHAN K H, et al Development of Vietnamese speech synthesis system using deep neural networks[J]. Journal of Computer Science and Cybernetics, 2019, 34 (4): 349- 363
doi: 10.15625/1813-9663/34/4/13172
|
|
|
| [20] |
TRANG N T T, KY N H, RILLIARD A, et al. Prosodic boundary prediction model for Vietnamese text-to-speech [C]// Proceedings of the Interspeech 2021. [S.l.]: ISCA, 2021: 3885−3889.
|
|
|
| [21] |
PHUONG P N, QUANG C T, DO Q T, et al. A study on neural-network-based text-to-speech adaptation techniques for Vietnamese [C]// Proceedings of the 24th Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA2021). Singapore: IEEE, 2021: 199−205.
|
|
|
| [22] |
WIN Y, LWIN H P, MASADA T. Myanmar text-to-speech system based on Tacotron (end-to-end generative model) [C]// Proceedings of the International Conference on Information and Communication Technology Convergence. Jeju: IEEE, 2020: 572−577.
|
|
|
| [23] |
HLAING A, PA W Word representations for neural network based Myanmar text-to-speech system[J]. International Journal of Intelligent Engineering and Systems, 2020, 13 (2): 239- 249
doi: 10.22266/ijies2020.0430.23
|
|
|
| [24] |
HLAING A M, PA W P, THU Y K. Enhancing Myanmar speech synthesis with linguistic information and LSTM-RNN [C]// Proceedings of the 10th ISCA Workshop on Speech Synthesis. [S.l.]: ISCA, 2019: 189−193.
|
|
|
| [25] |
JANYOI P, THANGTHAI A. Investigation of an input sequence on Thai neural sequence-to-sequence speech synthesis [C]// Proceedings of the 24th Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA2021). Singapore: IEEE, 2021: 218−223.
|
|
|
| [26] |
CHOMPHAN S, KOBAYASHI T. Implementation and evaluation of an HMM-based Thai speech synthesis system [C]// Proceedings of the Interspeech 2007. [S.l.]: ISCA, 2007: 2849−2852.
|
|
|
| [27] |
TESPRASIT V, CHAROENPORNSAWAT P, SORNLERTLAMVANICH V. A context-sensitive homograph disambiguation in Thai text-to-speech synthesis [C]// Proceedings of the 2003 Human Language Technology Conference of the North American Chapter of the Association for Computational Linguistics. Edmonton: ACL, 2003: 103−105.
|
|
|
| [28] |
DHIAULHAQ M A, GINANJAR R R, LOVENIA H, et al. Indonesia expressive text to speech system based on global style token and Tacotron 2 [C]// Proceedings of the 8th International Conference on Advanced Informatics: Concepts, Theory and Applications. Bandung: IEEE, 2021: 1–6.
|
|
|
| [29] |
LANCUCKI A. FastPitch: parallel text-to-speech with pitch prediction [C]// Proceedings of the ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing. Toronto: IEEE, 2021: 6588−6592.
|
|
|
| [30] |
SKERRY-RYAN R J, BATTENBERG E, XIAO Y, et al. Towards end-to-end prosody transfer for expressive speech synthesis with Tacotron [EB/OL]. (2018−03−24)[2024−08−25]. https://arxiv.org/pdf/1803.09047.
|
|
|
| [31] |
HAN M S, KIM K O Phonetic variation of Vietnamese tones in disyllabic utterances[J]. Journal of Phonetics, 1974, 2 (3): 223- 232
doi: 10.1016/S0095-4470(19)31272-0
|
|
|
| [32] |
KIRBY J P Vietnamese (Hanoi Vietnamese)[J]. Journal of the International Phonetic Association, 2011, 41 (3): 381- 392
doi: 10.1017/S0025100311000181
|
|
|
| [33] |
LUKSANEEYANAWIN S. Intonation in Thai [M]// HIRST D, DI CRISTO A. Intonation systems: a survey of twenty languages. Cambridge: Cambridge University Press, 1998: 379−397.
|
|
|
| [34] |
GREEN A D. Word, foot, and syllable structure in Burmese [C]// Studies in Burmese linguistics. Canberra: Pacific Linguistics, 2005: 1–24.
|
|
|
| [35] |
BRUNELLE M, KIRBY J Tone and phonation in Southeast Asian languages[J]. Language and Linguistics Compass, 2016, 10 (4): 191- 207
doi: 10.1111/lnc3.12182
|
|
|
| [36] |
MORISE M, KAWAHARA H, KATAYOSE H. Fast and reliable F0 estimation method based on the period extraction of vocal fold vibration of singing voice and speech [C]// 35th Audio Engineering Society International Conference 2009: Audio for Games. London: Curran Associates, Inc. , 2009: 77−81.
|
|
|
| [37] |
KUBICHEK R. Mel-cepstral distance measure for objective speech quality assessment [C]// Proceedings of the Proceedings of IEEE Pacific Rim Conference on Communications Computers and Signal Processing. Victoria: IEEE, 1993: 125–128.
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|