|
|
|
| Short text optimized topic model for service clustering |
Jia-wei LU1,2( ),Jia-hong ZHENG1,Duan-ni LI1,Jun XU1,Gang XIAO1,2,*() ),Jia-hong ZHENG1,Duan-ni LI1,Jun XU1,Gang XIAO1,2,*() |
1. College of Computer Science and Technology, Zhejiang University of Technology, Hangzhou 310023, China
2. College of Mechanical and Electrical Engineering, China Jiliang University, Hangzhou 310018, China |
|
|
|
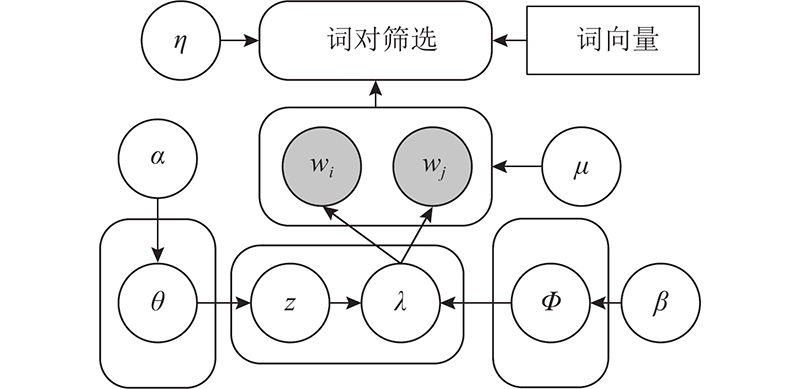
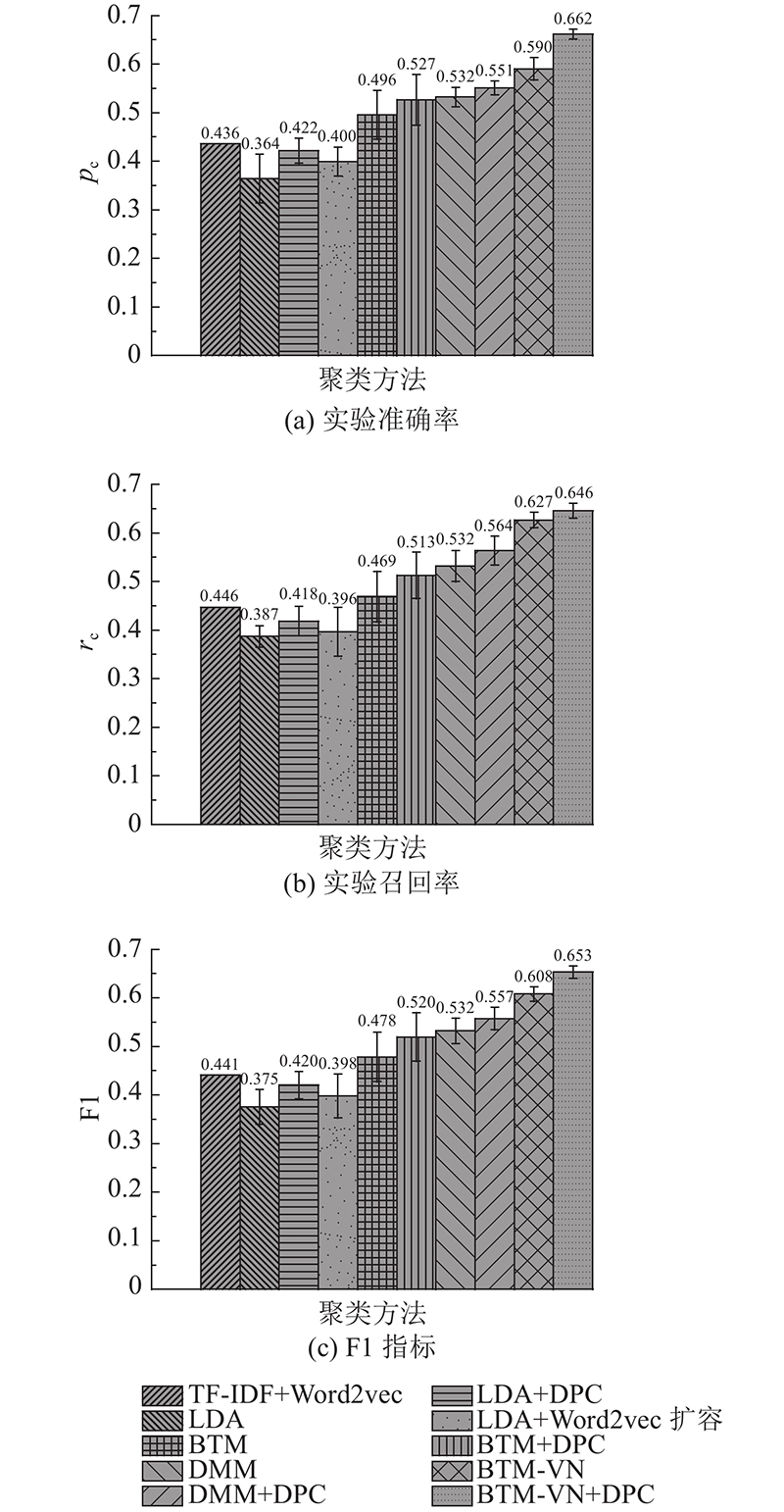
Abstract A biterm topic model with word vector and noise filtering (BTM-VN) was proposed, in order to mine high-quality latent topics, improve the accuracy of service clustering, and solve sparsity and noise problems caused by the short text feature of service description documents, Based on biterms, BTM-VN expanded the service description documents and obtained additional semantic information. A strategy for calculating the probability of representative biterms based on topic distribution information was designed. By calculating a representative biterms matrix in the sampling process, the weight of the representative biterms at the current topic was improved to reduce the interference of noise words in the service description document. Moreover, word embeddings were integrated to filter the biterms, reducing the number of biterms with low co-occurrence meaning and solving the biterm-based topic model’s problem which causes high time consumption. Finally, an optimized density peak clustering algorithm was used to cluster the topic distribution matrix trained by BTM-VN. Experimental results show that, the service clustering method based on BTM-VN performs better on real-world dataset than existing methods according to three clustering evaluation metrics.
|
|
Received: 18 January 2022
Published: 03 January 2023
|
|
|
| Fund: 国家自然科学基金资助项目(61976193);国家社会科学基金资助项目(22BMZ038);浙江省自然科学基金资助项目(LY19F020034);浙江省重点研发计划项目(2021C03136) |
|
Corresponding Authors:
Gang XIAO
E-mail: viivan@zjut.edu.cn;xg@zjut.edu.cn
|
面向服务聚类的短文本优化主题模型
为了获取高质量的隐式主题结果,提高服务聚类精度,解决服务描述文档文本短带来的语义稀疏性与噪声问题,提出词向量与噪声过滤优化的词对主题模型(BTM-VN). 该模型以词对为基础,拓展服务描述文档,获取额外的语义信息,设计利用主题分布信息进行代表词对概率计算的策略,通过在采样过程中计算代表词对矩阵,提高代表词对在当前主题的权重,降低噪声词对服务描述文档主题获取的干扰. 利用词向量筛选待训练的词对集合,减少共现意义低的词对组合,解决词对主题模型耗时较长的问题. 使用优化的密度峰值聚类算法对经BTM-VN训练后的服务主题分布矩阵进行聚类. 实验结果表明,基于BTM-VN的服务聚类方法在3种聚类评价指标上的表现均优于传统的服务聚类算法.
关键词:
服务聚类,
主题模型,
短文本优化,
代表词对,
词向量
|
|
| [1] |
曹步清, 肖巧翔, 张祥平, 等 融合 SOM 功能聚类与 DeepFM 质量预测的 API 服务推荐方法[J]. 计算机学报, 2019, 42 (6): 1367- 1383
CAO Bu-qing, XIAO Qiao-xiang, ZHANG Xiang-ping, et al An API service recommendation method via combining self-organization map-based functionality clustering and deep factorization machine-based quality prediction[J]. Chinese Journal of Computers, 2019, 42 (6): 1367- 1383
doi: 10.11897/SP.J.1016.2019.01367
|
|
|
| [2] |
RUPASINGHA R A H M, PAIK I, KUMARA B T G S Specificity-aware ontology generation for improving Web service clustering[J]. IEICE Transactions on Information and Systems, 2018, E101.D (8): 2035- 2043
doi: 10.1587/transinf.2017EDP7395
|
|
|
| [3] |
石敏, 刘建勋, 周栋, 等 基于多重关系主题模型的Web服务聚类方法[J]. 计算机学报, 2019, 42 (4): 820- 836
SHI Min, LIU Jian-Xun, ZHOU Dong, et al Multi-relational topic model-based approach for Web services clustering[J]. Chinese Journal of Computers, 2019, 42 (4): 820- 836
doi: 10.11897/SP.J.1016.2019.00820
|
|
|
| [4] |
CHEN J, GONG Z, LIU W A nonparametric model for online topic discovery with word embeddings[J]. Information Sciences, 2019, 504: 32- 47
doi: 10.1016/j.ins.2019.07.048
|
|
|
| [5] |
BLEI D M, NG A Y, JORDAN M I Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993- 1022
|
|
|
| [6] |
YAN X, GUO J, LAN Y, et al. A biterm topic model for short texts [C]// Proceedings of the 22nd International Conference on World Wide Web. [S.l.]: Association for Computing Machinery, 2013: 1445-1456.
|
|
|
| [7] |
PANG J, LI X, XIE H, et al. SBTM: topic modeling over short texts [C]// International Conference on Database Systems for Advanced Applications. [S. l.]: Springer, 2016: 43-56.
|
|
|
| [8] |
MEHROTRA R, SANNER S, BUNTINE W, et al. Improving LDA topic models for microblogs via tweet pooling and automatic labeling [C]// Proceedings of the 36th International ACM SIGIR Conference on Research and Development in Information Retrieval. [S.l.]: Association for Computing Machinery, 2013: 889-892.
|
|
|
| [9] |
LI X, WANG Y, ZHANG A, et al Filtering out the noise in short text topic modeling[J]. Information Sciences, 2018, 456: 83- 96
doi: 10.1016/j.ins.2018.04.071
|
|
|
| [10] |
LI C, WANG H, ZHANG Z, et al. Topic modeling for short texts with auxiliary word embeddings [C]// Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval. [S.l.]: Association for Computing Machinery, 2016: 165-174.
|
|
|
| [11] |
肖巧翔, 曹步清, 张祥平, 等 基于 Word2Vec 和 LDA 主题模型的 Web 服务聚类方法[J]. 中南大学学报: 自然科学版, 2018, 49 (12): 2979- 2985
XIAO Qiao-xiang, CAO Bu-qing, ZHANG Xiang-ping, et al Web services clustering based on Word2Vec and LDA topic model[J]. Journal of Central South University: Science and Technology, 2018, 49 (12): 2979- 2985
|
|
|
| [12] |
ZUO Y, WU J, ZHANG H, et al. Topic modeling of short texts: a pseudo-document view [C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S. l.]: Association for Computing Machinery, 2016: 2105-2114.
|
|
|
| [13] |
ZHU B, CAI Y, ZHANG H. Sparse biterm topic model for short texts [C]// Asia-Pacific Web and Web-Age Information Management Joint International Conference on Web and Big Data. [S. l.]: Springer, 2021: 227-241.
|
|
|
| [14] |
ZUO Y, LI C, LIN H, et al Topic modeling of short texts: a pseudo-document view with word embedding enhancement[J]. IEEE Transactions on Knowledge and Data Engineering, 2023, 35 (1): 972- 985
|
|
|
| [15] |
NGUYEN D Q, BILLINGSLEY R, DU L, et al Improving topic models with latent feature word representations[J]. Transactions of the Association for Computational Linguistics, 2015, 3: 299- 313
doi: 10.1162/tacl_a_00140
|
|
|
| [16] |
HU R, LIU J, WEN Y. SP-BTM: a specific part-of-speech btm for service clustering [C]// 2020 IEEE International Conference on Parallel and Distributed Processing with Applications, Big Data and Cloud Computing, Sustainable Computing and Communications, Social Computing and Networking. Exeter: IEEE, 2020: 1050-1057.
|
|
|
| [17] |
YIN J, WANG J. A dirichlet multinomial mixture model-based approach for short text clustering [C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. [S.l.]: Association for Computing Machinery, 2014: 233-242.
|
|
|
| [18] |
CHEN J, GONG Z, LIU W A Dirichlet process biterm-based mixture model for short text stream clustering[J]. Applied Intelligence, 2020, 50: 1609- 1619
doi: 10.1007/s10489-019-01606-1
|
|
|
| [19] |
GOLDBERG Y, LEVY O. Word2vec explained: deriving Mikolov et al. ’s negative-sampling word-embedding method [EB/OL]. [2022-01-16]. https://arxiv.org/pdf/1402.3722.pdf.
|
|
|
| [20] |
LU H Y, XIE L Y, KANG N, et al. Don’t forget the quantifiable relationship between words: using recurrent neural network for short text topic discovery [C]// Proceedings of the 31st AAAI Conference on Artificial Intelligence. [S.l.]: AAAI Press, 2017: 1192-1198.
|
|
|
| [21] |
XIA Y, TANG N, HUSSAIN A, et al. Discriminative Bi-term topic model for headline-based social news clustering [C]// Proceedings of the 28th International Florida Artificial Intelligence Research Society Conference. [S.l.]: Association for the Advancement of Artificial Intelligence, 2015: 311-316.
|
|
|
| [22] |
RODRIGUEZ A, LAIO A Clustering by fast search and find of density peaks[J]. Science, 2014, 344 (6191): 1492- 1496
doi: 10.1126/science.1242072
|
|
|
| [23] |
XU H, LIU B, SHU L, et al. Lifelong domain word embedding via meta-learning [C]// Proceedings of the 27th International Joint Conference on Artificial Intelligence. [S.l.]: AAAI Press, 2018: 4510-4516.
|
|
|
| [24] |
NEWMAN D, LAU J H, GRIESER K, et al. Automatic evaluation of topic coherence [C]// HumaN Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Los Angeles: Association of Computional Linguistics, 2010: 100-108.
|
|
|
| [25] |
唐明, 朱磊, 邹显春 基于Word2Vec的一种文档向量表示[J]. 计算机科学, 2016, 43 (6): 214- 217
TANG Ming, ZHU Lei, ZOU Zian-chun Document vector representation based on Word2Vec[J]. Computer Science, 2016, 43 (6): 214- 217
doi: 10.11896/j.issn.1002-137X.2016.06.043
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|