|
|
|
| Fault tolerant optimization of active backup for Flink stream processing framework |
Guang-xuan LIU1,2,3( ),Shan HUANG1,2,3,*(),Jia-li HU1,2,3,Xiao-dong DUAN1,2,3 ),Shan HUANG1,2,3,*(),Jia-li HU1,2,3,Xiao-dong DUAN1,2,3 |
1. College of Computer Science and Technology, Dalian Minzu University, Dalian 116600, China
2. State Ethnic Affairs Commission Key Laboratory of Big Data Applied Technology, Dalian 116600, China
3. Dalian Key Laboratory of Digital Technology for National Culture , Dalian 116600, China |
|
|
|
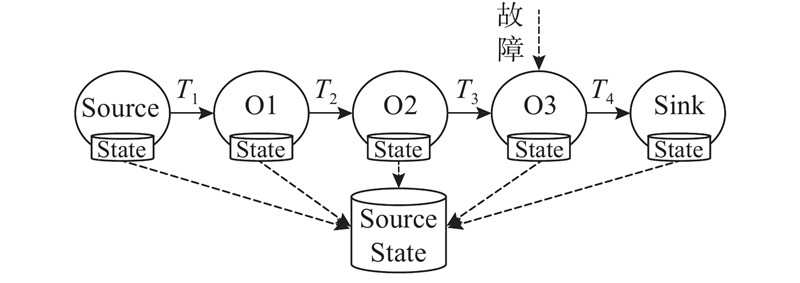
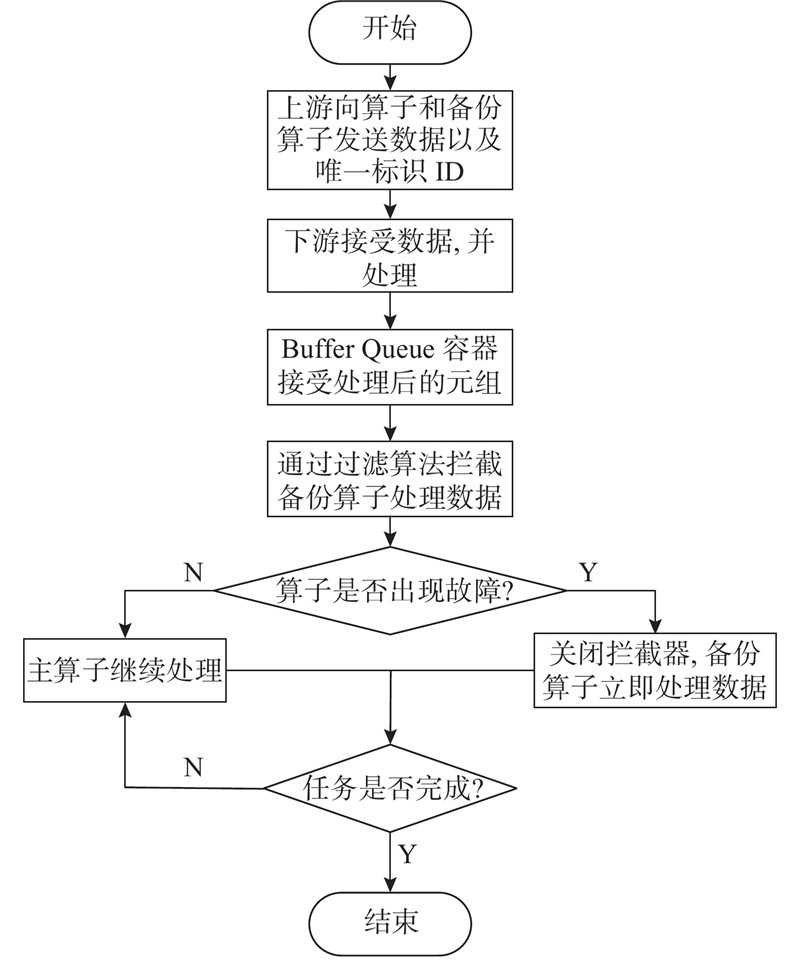
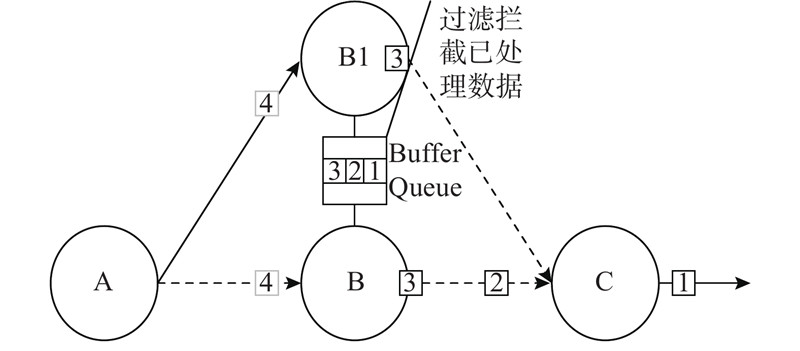
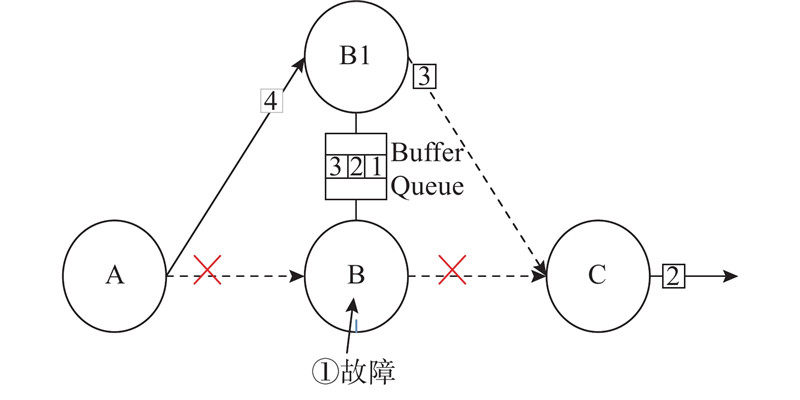
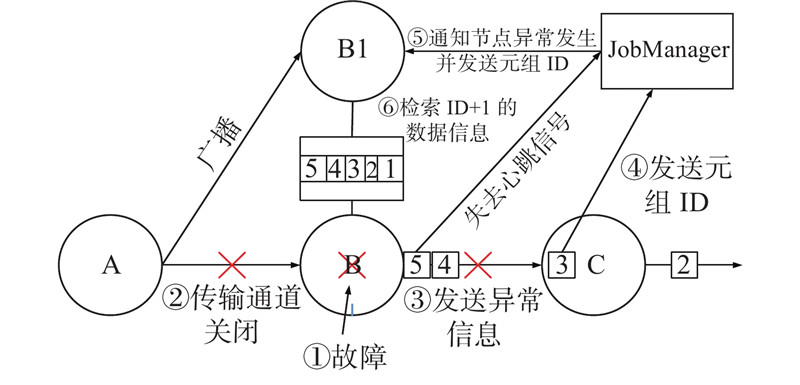
Abstract A fault-tolerant strategy based on cache queue was proposed, aiming at the problem of low efficiency of stream processing job recovery due to global rollback after Flink task fails. In the job, the operator with the longest recovery time is taken as the key operator, the processed data are stored in the buffer queue, and active backup is performed for it. The backup operator will also accept the data from the upstream to reach the the effect that the job can be restored instantaneously after a failure. In order to solve the additional consumption caused by active backup, a data filtering algorithm was proposed. The backup operator will retrieve the current data from the cache component before processing the data each time to determine whether to continue processing. When the Flink operator itself fails, it will use the buffer queue in the strategy and Flink’s JobManager to send the data information at the time of the failure to the backup operator. When the backup operator receives the data, it will realize the effect of instant recovery. The strategy was evaluated on four evaluation indicators. Compared with the failure recovery mode of Flink1.8, the proposed strategy had a significant improvement in Flink task failure recovery. The recovery efficiency was increased by 56.3%, 51.3%, 46.2% and 45.8% under failure times of 1, 2, 3 and 4 separately. And the proposed strategy brings only a very small price in terms of processing delay, CPU utilization and memory usage.
|
|
Received: 18 July 2021
Published: 03 March 2022
|
|
|
|
Corresponding Authors:
Shan HUANG
E-mail: liuguangxuan_ustl@163.com;huangshan@dlnu.edu.cn
|
面向Flink流处理框架的主动备份容错优化
针对Flink任务出现故障后因为全局卷回使流处理作业恢复效率低的问题,提出基于缓存队列的容错策略. 在作业中找出恢复时间最长的算子作为关键算子,将其处理过的数据存储到缓存队列中,并为其进行主动备份,备份算子同时接受来自上游的数据以达到在故障后作业可以瞬时恢复的效果. 为了解决主动备份带来的额外消耗,提出数据过滤算法,备份算子在每次处理数据前会到缓存组件中检索当前数据,以判断是否继续处理. 当Flink算子自身出现故障后,利用策略中的缓存队列与Flink的JobManager将故障发生时的数据信息发送给备份算子,在备份算子接收到数据后,实现即时恢复的效果. 利用4项评价指标对策略进行评估,结果表明,与Flink1.8的故障恢复模式相比,所提策略在Flink任务故障恢复速度上有显著提升,当故障次数分别为1、2、3、4时,恢复效率分别提高56.3%、51.3%、46.2%和45.8%;而在处理时延、CPU利用率以及内存使用率方面仅产生极小的代价.
关键词:
Apache Flink,
流处理容错,
主动备份,
故障恢复,
缓存队列
|
|
| [1] |
DEAN J, GHEMAWAT S MapReduce: a flexible data processing tool[J]. Communications of the ACM, 2010, 53 (1): 72- 77
doi: 10.1145/1629175.1629198
|
|
|
| [2] |
ZAHARIA M, CHOWDHURY M, FRANKLIN M J, et al Spark: cluster computing with working sets[J]. HotCloud, 2010, 10: 95
|
|
|
| [3] |
KATSIFODIMOS A, SCHELTER S. Apache Flink: stream analytics at scale [C]// IEEE International Conference on Cloud Engineering Workshop. Berlin: IC2EW, 2016: 28-38.
|
|
|
| [4] |
CHINTAPALLI S, DAGIT D, EVANS B, et al. Benchmarking streaming computation engines: storm, flink and spark streaming [C]// 2016 IEEE International Parallel and Distributed Processing Symposium Worshops. Chicago: IPDPSW, 2016: 1789-1792.
|
|
|
| [5] |
CHANDY K M, LAMPORT L Distributed snapshots: determining global states of a distributed system[J]. ACM Transactions on Computer Systems, 2016, 3 (1): 63- 75
|
|
|
| [6] |
BALAZINSKA M, BALAKRISHNAN H, MADDEN S R, et al Fault-tolerance in the Borealis distributed stream processing system[J]. ACM Transactions on Database Systems, 2008, 33 (1): 81- 124
|
|
|
| [7] |
HWANG J H, CETINTEMEL U, ZDONIK S. Fast and highly-available stream processing over wide area networks [C]// 2008 IEEE 24th International Conference on Data Engineering. Cancun: ICDE, 2008: 804-813.
|
|
|
| [8] |
HEINZE T, ZIA M, KRAHN R, et al. An adaptive replication scheme for elastic data stream processing systems [C]// Proceedings of the 9th ACM International Conference on Distributed Event-based Systems. Oslo: DEBS, 2015 : 150-161.
|
|
|
| [9] |
CHANDRAMOULI B, GOLDSTEIN J Shrink: prescribing resiliency solutions for streaming[J]. Proceedings of the VLDB Endowment, 2017, 10 (5): 505- 516
|
|
|
| [10] |
BENOIT A, RAINA S K, ROBERT Y Efficient checkpoint/verification patterns[J]. International Journal of High Performance Computing Applications, 2017, 31 (1): 52- 65
doi: 10.1177/1094342015594531
|
|
|
| [11] |
AKBER S M A , CHEN H , WANG Y , et al. Minimizing overheads of checkpoints in distributed stream processing systems [C]// 2018 IEEE 7th International Conference on Cloud Networking. Tokyo: CloudNet, 2018: 1-4.
|
|
|
| [12] |
ZHUANG Y, WEI X, LI H, et al. An optimal checkpointing model with online OCI adjustment for stream processing applications [C]// International Conference on Computer Communication and Networks. Hangzhou: ICCCN, 2018: 1-9.
|
|
|
| [13] |
LOMBARDI F, ANIELLO L, BONOMI S, et al Elastic symbiotic scaling of operators and resources in stream processing systems[J]. IEEE Transactions on Parallel and Distributed Systems, 2018, 29 (99): 572- 585
|
|
|
| [14] |
刘智亮. 面向流数据处理的动态自适应检查点机制研究[D]. 吉林: 吉林大学, 2017.
LIU Zhi-liang . Research on adaptive checkpoint mechanism for large-scale streaming data processing [D]. Jilin: Jilin University, 2017.
|
|
|
| [15] |
郭文鹏, 赵宇海, 王国仁, 等 面向Flink迭代计算的高效容错处理技术[J]. 计算机学报, 2020, 43 (11): 2101- 2118
GUO Wen-peng, ZHAO Yu-hai, WANG Guo-ren, et al Efficient fault-tolerant processing technology for Flink iterative computing[J]. Chinese Journal of Computers, 2020, 43 (11): 2101- 2118
doi: 10.11897/SP.J.1016.2020.02101
|
|
|
| [16] |
HAN D Z, CHEN X G, LEI Y X, et al Real-time data analysis system based on Spark Streaming and its application[J]. Journal of Computer Applications, 2017, 37 (5): 1263- 1269
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|