

随着社会经济的发展和人民生活水平的提高,智能手机越来越普及,换机周期不断缩短. 根据中国电信浙江地区用户数据统计可知,截至2018年12月31日,用户平均换机周期约为21个月,平均换机次数为3.1次. 移动终端及配套产品的销售已成为电信运营商的战略核心,准确预测用户换机有利于运营商提升移动终端销量,扩大市场规模.
1)只利用用户静态属性建模用户画像. Zhao等[4]将用户自然属性(如年龄、入网时长、家庭成员数量等)和当前使用的移动终端属性(如终端品牌、价格、发售时间等)等静态属性输入,使用深度信念网络(deep belief networks,DBN)进行终端换机预测. 该类方法忽略了用户的行为信息,无法建模动态的用户画像.
2)引入用户动态属性,计算动态用户行为数据的统计特征,展现用户的行为规律和模式. Hadden等[5-7]的研究表明,利用用户通话、流量、App使用等行为数据的统计特征能够构建更具表征力的用户画像,提升下游任务的性能. Yang等[8]统计用户在每天不同时间段各类App使用时长的分布,使用风险回归模型预测用户多久后更换手机. Huang等[9]在构建用户画像时引入用户通话、消费行为数据,考虑用户近7日、60日日平均通话时长和日平均消费金额,使用朴素贝叶斯(naive Bayes)算法预测用户流失. Vaefiadis等[10-11]统计用户每天不同时间段的通话次数和通话时长,用于预测用户流失和推荐电信产品.
上述电信用户画像建模方法或是忽略了用户行为信息,或是只引入了行为数据统计特征,无法显示建模用户行为序列的变化趋势,在一定程度上造成了信息损失. 针对以上问题,本文提出基于深度神经网络的多因素融合终端换机预测模型(multi-factor aware mobile terminal replacement prediction model,MRPM). 该模型使用LSTM网络提取用户通话、流量使用行为序列特征,构建有效的序列表示。使用全连接网络融合用户自然属性、行为序列特征和历史换机信息,充分利用影响用户换机的多种因素,进行用户换机预测.
1. 模型介绍
1.1. 问题定义
令当前日期为
式中:
1.2. 特征相关性分析
基于中国电信浙江地区的用户数据,分析用户换机行为与部分特征之间的关系.
2019年1月换机与不换机用户的年龄分布如图1(a)所示. 换机用户的平均年龄比不换机的用户小3.8岁,45岁以下换机用户比例高于不换机用户,45岁以上不换机用户比例高于换机用户. 这表明年龄是影响用户换机的重要因素.
图 1
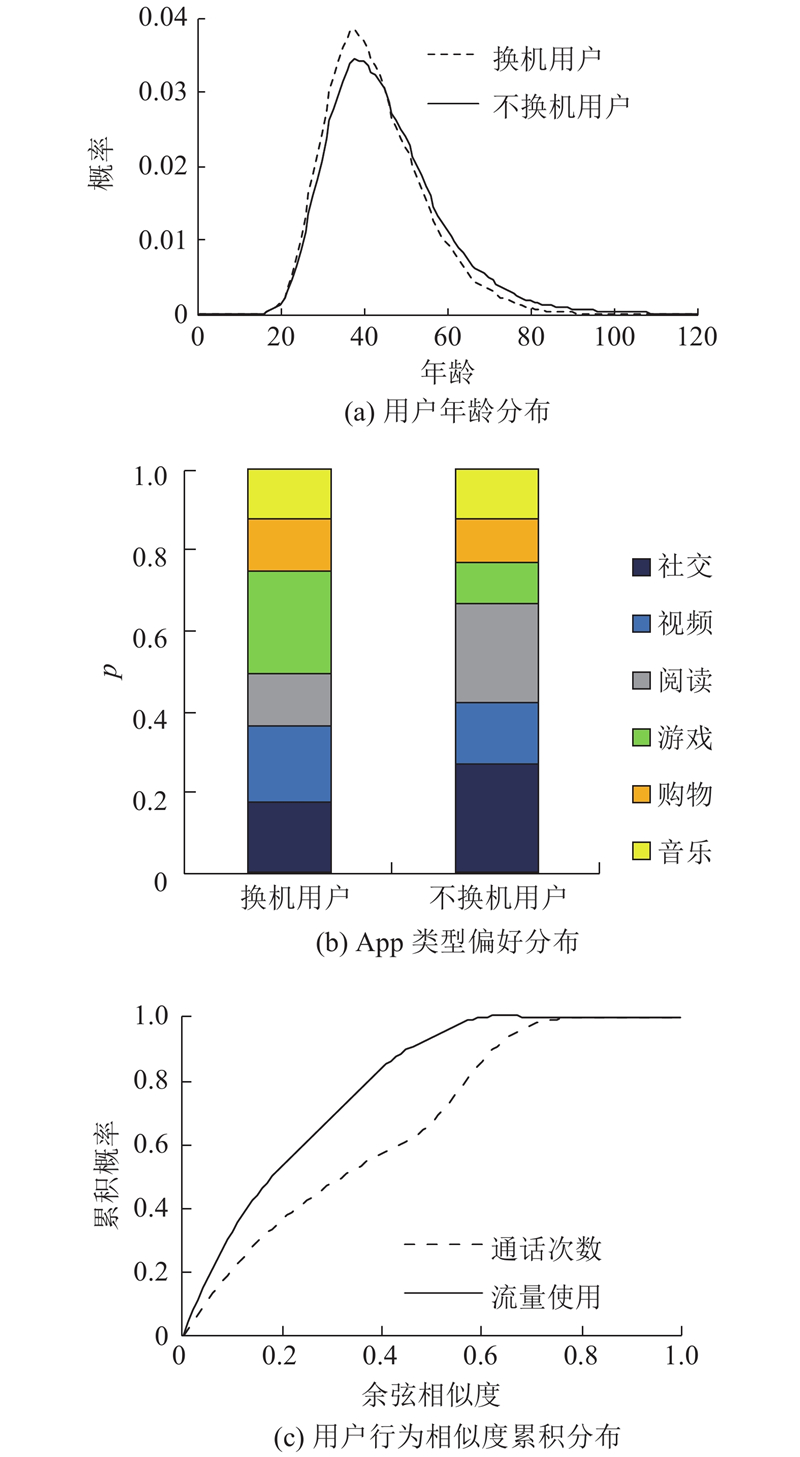
图 1 换机行为与用户特征相关性
Fig.1 Correlations between terminal replacement and user features
App类型偏好表示用户使用时长最久的一类App. 换机与不换机用户的App类别偏好如图1(b)所示. 图中,p为App类型偏好比例。App类型偏好有较大差异,换机用户游戏类App偏好比例(24.99%)显著高于不换机用户(10.20%),不换机用户阅读、社交类App偏好(分别为24.27%和26.74%)比例显著高于换机用户(分别为12.83%和17.55%).
统计2019−01−07(周一)—2019−01−13(周日)的用户每日通话次数和流量使用,任意2个用户之间上述行为序列余弦相似度的累积概率分布如图1(c)所示. 可以看出,超过60%的用户对通话次数序列的余弦相似度小于0.44,超过60%的用户对流量使用序列的余弦相似度小于0.25. 这表明用户之间通话、流量使用行为模式具有显著差异,因此引入用户行为数据有利于更有效地建模用户画像,开展用户换机预测.
1.3. 框架分析
模型的框架如图2所示. 对用户自然属性进行预处理,得到用户自然属性编码。对终端属性进行预处理,得到终端属性编码,根据用户历史换机记录中用户使用的终端对应的终端属性编码及其他相关特征,构建用户历史换机信息编码。将预处理后的用户通话、流量使用序列输入LSTM网络,得到通话、流量使用行为序列特征表示。将用户自然属性编码、行为序列特征表示和历史换机信息编码拼接,送入全连接网络进行特征融合,预测用户是否换机.
图 2

1.4. 数据预处理
终端换机预测模型使用的数据包括用户自然属性、用户通话、流量行为数据和用户历史换机记录. 在数据预处理阶段,对用户自然属性进行预处理,得到用户自然属性编码. 对于用户换机记录,对终端属性进行预处理,得到终端属性编码;根据用户历史换机记录中用户历史上使用的终端对应的终端属性编码及其他相关特征,构建用户历史换机信息编码;对于用户通话、流量行为数据,选取180 d的通话、流量使用数据,构建通话、流量使用行为序列,进行归一化和粗化,作为行为序列特征提取模块的输入.
1.4.1. 用户自然属性
表 1 用户自然属性和终端属性说明
Tab.1
| 类别 | 属性 | 说明 |
| 用户自然属性 | 性别 | 男/女 |
| 年龄 | 0~100 岁 | |
| 入网时长 | 0~240 个月 | |
| 是否为亲情网用户 | 是/否 | |
| 同客户下C网个数 | 0~20 个 | |
| App类型偏好 | 社交、视频、阅读等 | |
| 终端属性 | 品牌 | 华为、苹果、小米等 |
| 价格 | 0~15000 元 | |
| 屏幕尺寸 | 0~6.95 英寸 | |
| 网别 | 3G/4G | |
| 像素 | 0~4000万像素 |
1.4.2. 用户历史换机记录
对用户历史换机记录编码时,需要考虑用户每一条换机记录对应的终端信息,因此对终端属性进行编码. 其中终端属性说明如表1所示. 对于离散属性(如品牌、网别),直接进行独热编码;对于连续属性(如价格、屏幕尺寸),通过等频分箱划分为5个区间再进行独热编码。将所有属性的编码拼接后,得到终端
图 3
除此之外,用户的换机周期模式是影响换机的重要因素,计算用户历史平均换机时间间隔
1.4.3. 用户行为数据
用户行为数据包括通话数据和流量使用数据,以天为单位,分别记录用户通话、流量使用行为的相关指标. 其中,通话行为数据包括呼出次数、呼出时长、呼入次数、呼入时长,流量使用行为数据包括流量使用次数、流量使用时长、上行流量、下行流量. 选取过去180 d的通话、流量使用数据,构成通话、流量使用行为序列. 对每个序列进行最大最小归一化处理,使得处理后的数据归一化到[0,1.0],公式如下:
式中:
在模型训练时,步长过多的序列会显著增加模型计算的复杂度[17]. 根据经验,将时间跨度为180 d的行为序列每5天计算平均值,将原始步长为180的序列粗化至步长为36.
1.5. 模型设计
1.5.1. 行为序列特征提取模块设计
如图2所示,行为序列特征提取模块从高维的用户通话、流量使用行为数据中提取低维的行为序列特征表示,用于有效地建模电信用户画像,开展用户换机预测.
循环神经网络(recurrent neural network,RNN)是专门处理序列数据的深度神经网络. 变体长短期记忆(long short-term memory,LSTM)神经网络可以发现,序列数据中的长期依赖能够有效解决模型训练时的梯度消失问题[18]. 如图4所示,使用多层LSTM网络提取用户行为序列特征,通话、流量使用行为序列特征提取模块采用相同的网络结构. 在LSTM网络中,将上一时刻的状态输入到下一LSTM单元中,保留了数据的序列信息,利用多层LSTM网络提升了模型的拟合能力. 在LSTM网络最后一层,使用Sigmoid函数将最后一个单元的输出进行归一化,作为行为序列特征表示. 为了平衡模型的拟合能力和复杂度,使用3层LSTM网络.
图 4
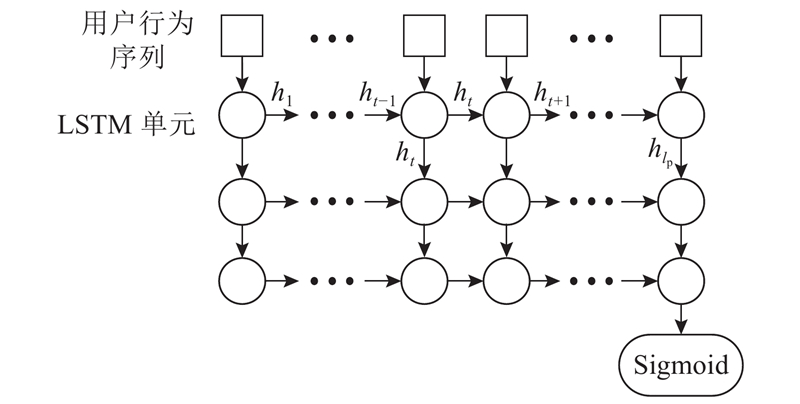
1.5.2. 特征融合模块设计
如图2所示,特征融合模块使用全连接网络,对构建和提取的特征表示(用户自然属性编码、行为序列特征表示和历史换机信息编码)进行融合,预测用户未来30 d内是否换机.
具体做法如下。将用户自然属性编码、行为序列特征表示和历史换机信息编码拼接成一个向量,输入到全连接网络中。其中全连接网络共3层,包含2层隐藏层(激活函数为LeakyReLU)和1层输出层(神经元数为1,激活函数为Sigmoid),输出结果为[0,1.0],表示用户未来30 d内换机的概率. 隐藏层使用LeakyReLU激活函数代替常用的ReLU,是为了避免后者在训练过程中使神经元坏死的情况.
2. 实验分析
2.1. 数据集
随机采样20万入网时间早于2017年12月31日且活跃天数超过入网时长40%的中国电信浙江地区用户,用于构建实验数据集. 将用户在2019年1月1日—2019年1月30日是否换机作为标签,其中换机用户约占全体用户的3.9%. 对于每个用户,选取自然属性、历史换机记录和2018年7月4日—2018年12月31日(时间跨度为180 d)的通话、流量使用数据构建数据集. 其中样本总数为20万,正、负样本比例约为1∶25.
2.2. 实验设置
模型通过以TensorFlow为后端的高层神经网络API(Keras)来实现. 网络的训练采用Nvidia RTX2080Ti显卡,显存为11 GB,硬件平台的处理器采用Intel(R)Xeon(R)Gold 5118 CPU,内存为128 GB.
用户自然属性编码
表 2 模型超参数设置
Tab.2
| 网络层 | 超参数 |
| LSTM层 | units=d |
| 全连接层 | 第1层:units=64;Activation=LeakyReLU( 第2层:units=32;Activation=LeakyReLU( 第3层:units=1;Activation=Sigmoid |
2.3. 评估指标
实验采用十折交叉验证来验证模型性能. 具体做法如下:将数据集随机打乱后分为十等份,轮流将其中9份作为训练数据,1份作为测试数据,开展实验.
考虑到数据集中样本类别的不平衡,使用精确率P、召回率R、F1和P-R曲线,评估不同方法的性能. 精确率为预测换机正确的样本数除以预测为换机的样本数,召回率为预测换机正确的样本数除以真实标签为换机的样本数。F1的计算方法如下:
2.4. LSTM输出维度d的影响
LSTM输出维度d表示模型中传递用户通话、流量使用行为序列特征信息量的大小. 若d的取值过大,模型容易过拟合且增大了计算开销;若d的取值过小,则模型无法充分表示行为序列特征. 为了研究d对模型性能的影响,将d依次从8逐步增长到64,增量为8. 模型的F1变化趋势如图5所示.
图 5
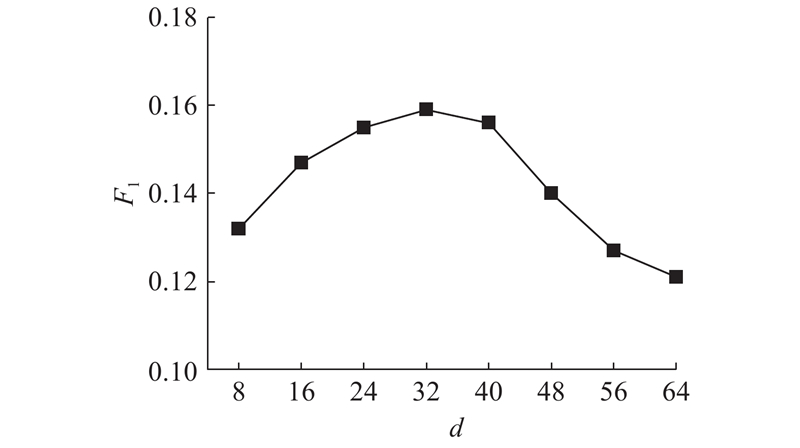
从实验结果可以看出,当d=32时,F1取得最大值0.159,模型性能最好. 在后续实验中,d设置为32.
2.5. 不同因素的影响
为了研究不同因素对终端换机预测模型性能的影响程度,设计了MRPM的3种变体:MPRM-U、MPRM-S和MPRM-H. 这3种变体分别忽略了用户自然属性、行为序列特征和历史换机信息的影响.
这3种变体的性能如表3所示,同时考虑3种因素可以提高模型性能. 当召回率设置为0.135时,同时考虑3种因素分别比忽略用户自然属性、行为序列信息和历史换机信息提升了16.3%、22.3%和86.4%;根据不同因素的重要程度从高到低排序:历史换机信息>行为序列信息>用户自然属性. 实验结论如下. 1)历史换机信息对预测用户换机最重要,这主要由于大多数用户换机是有计划、有规律的,今后的换机行为往往与历史换机模式吻合. 2)利用用户行为序列信息能够显著提高换机预测的精确度,这表明用户换机往往会受到其对手机使用的倚赖程度影响. 3)除此之外,用户自然属性能够在一定程度上反映用户的消费习惯和社会角色,预测用户换机时需要考虑这些信息.
表 3 忽略不同因素对模型性能的影响
Tab.3
| 方法 | P | R | F1 |
| MRPM-U | 0.165 | 0.135 | 0.148 |
| MRPM-S | 0.157 | 0.135 | 0.145 |
| MRPM-H | 0.103 | 0.135 | 0.117 |
| MRPM | 0.192 | 0.135 | 0.159 |
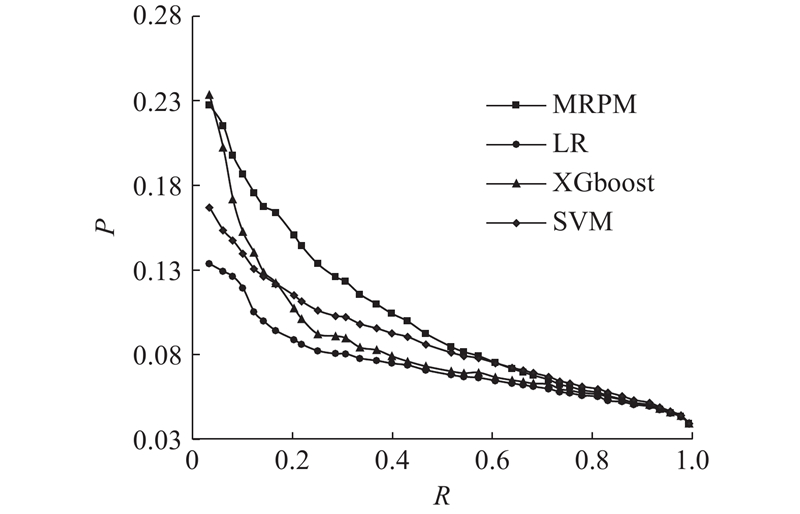
2.6. 实验结果对比
将提出的MRPM与传统的终端换机预测模型进行对比. 用于对比的基线模型如下.
2)基于支持向量机的多因素感知预测模型(SVM):类似Huang等[9]提出的基于支持向量机的多因素感知用户流失预测模型. 利用结论1)中所描述的特征输入支持向量机模型,预测用户是否换机.
3)基于极端梯度提升的多因素感知预测模型(XGBoost):类似Huang等[9]提出的基于支持极端梯度提升的多因素感知用户流失预测模型. 利用结论1)中所描述的特征输入极端梯度提升模型,预测用户是否换机.
表 4 用户行为数据统计特征
Tab.4
| 数据集 | 统计特征 |
| 用户通话数据 | 近30 日日平均通话次数 |
| 近180 日日平均通话次数 | |
| 近30 日日平均通话时长 | |
| 近180 日日平均通话时长 | |
| 近30 日当日较上日通话次数平均增长率 | |
| 近180 日当日较上日通话次数平均增长率 | |
| 近30 日当日较上日通话时长平均增长率 | |
| 近180 日当日较上日通话时长平均增长率 | |
| 用户流量使用数据 | 近30 日日平均上行流量 |
| 近180 日日平均上行流量 | |
| 近30 日日平均下行流量 | |
| 近180 日日平均下行流量 | |
| 近30 日当日较上日上行流量平均增长率 | |
| 近180 日当日较上日上行流量平均增长率 | |
| 近30 日当日较上日下行流量平均增长率 | |
| 近180 日当日较上日下行流量平均增长率 |
表 5 召回率为0.135时不同模型的精确率和F1
Tab.5
| 方法 | P | R | F1 |
| LR | 0.105 | 0.135 | 0.118 |
| SVM | 0.121 | 0.135 | 0.128 |
| XGBoost | 0.143 | 0.135 | 0.139 |
| MRPM | 0.192 | 0.135 | 0.159 |
图 6
3. 结 语
本文提出基于深度神经网络的多因素感知终端换机预测模型. 该模型考虑影响用户换机的多种因素,设计基于LSTM的用户行为序列特征提取模块,利用用户通话、流量使用序列信息,避免了传统方法构建用户行为数据统计特征时造成信息损失.
本文提出的终端换机预测模型有进一步的拓展空间. 对于今后的工作,将重点探索以下3个方向:1)引入更多影响用户换机的特征,如用户自然属性中引入收入信息、家庭信息等;2)设计更具有表征能力的模型,如引入注意力机制使得模型能够自动选择更重要的特征;3)模型通用化,进一步改进模型,使其能够应用于电信用户画像建模的多种应用场景.
参考文献
Reaping the benefits of big data in telecom
[J].DOI:10.1186/s40537-016-0048-1 [本文引用: 1]
Churn prediction: does technology matter
[J].
A hybrid fuzzy-based personalized recommender system for telecom products/services
[J].DOI:10.1016/j.ins.2013.01.025 [本文引用: 1]
Customer churn prediction in telecommunications
[J].DOI:10.1016/j.eswa.2011.08.024 [本文引用: 4]
A comparison of machine learning techniques for customer churn prediction
[J].DOI:10.1016/j.simpat.2015.03.003 [本文引用: 1]
Model of customer churn prediction on support vector machine
[J].DOI:10.1016/S1874-8651(09)60003-X [本文引用: 1]
From big smartphone data to worldwide research: the mobile data challenge
[J].DOI:10.1016/j.pmcj.2013.07.014 [本文引用: 1]
Long short-term memory
[J].DOI:10.1162/neco.1997.9.8.1735 [本文引用: 1]
分级式代价敏感决策树及其在手机换机预测中的应用
[J].
Hierarchical cost sensitive decision tree and its application in the prediction of the mobile phone replacement
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}