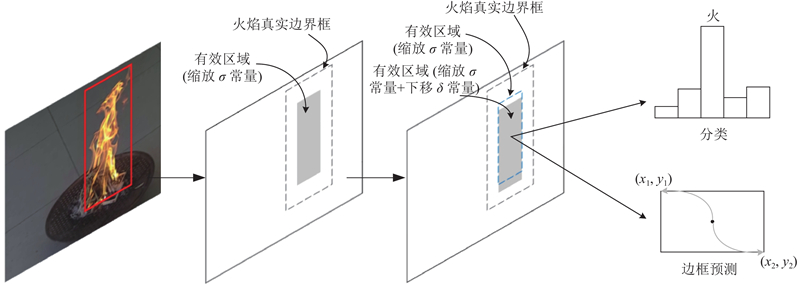
监督信号的定义与FoveaBox和FSAF网络中的类似. 在原始图像,火焰真实框用b 表示,b = (x 1 , y 1 , x 2 , y 2 ),(x 1 , y 1 )与(x 2 , y 2 )分别表示图像中火焰区域左上角点与右下角点的坐标. 在网络训练的过程中,火焰区域b 会被分配到不同的金字塔特征层Pl (l = 3, 4, 5, 6, 7)中进行监督学习. b 投影到金字塔特征图Pl 上的区域 $b_p^l$ $\left( {x_{{p_1}}^l,y_{{p_1}}^l,x_{{p_2}}^l,y_{{p_2}}^l} \right)$ $b_p^l = b/2_{}^l$ . 定义有效区域 $b_{\rm{e}}^l = \left( {x_{{{\rm{e}}_1}}^l,y_{{{\rm{e}}_1}}^l,x_{{{\rm{e}}_2}}^l,y_{{{\rm{e}}_2}}^l} \right)$ $b_p^l$ σ 后,再向下偏移一个常数δ ,如图2 所示. 最终有效区域的坐标计算公式为
[1]
SEEBAMRUNGSAT J, PRAISING S, RIYAMONGKOL P. Fire detection in the buildings using image processing [C]// 2014 3rd ICT International Student Project Conference . Thailand: IEEE, 2014: 95-98.
[本文引用: 1]
[2]
HASHEMZADEH M, ZADEMEHDI A Fire detection for video surveillance applications using ICA K-medoids-based color model and efficient spatio-temporal visual features
[J]. Expert Systems with Applications , 2019 , 130 : 60 - 78
DOI:10.1016/j.eswa.2019.04.019
[本文引用: 3]
[3]
KIM B, LEE J A video-based fire detection using deep learning models
[J]. Applied Sciences , 2019 , 9 (14 ): 2862
DOI:10.3390/app9142862
[本文引用: 1]
[4]
WU S, ZHANG L. Using popular object detection methods for real time forest fire detection [C]// 2018 11th International Symposium on Computational Intelligence and Design . Hangzhou: IEEE, 2018: 280-284.
[本文引用: 1]
[5]
LAW H, DENG J. CornerNet: detecting objects as paired keypoints [C]// Proceedings of the European Conference on Computer Vision . Munich: Springer, 2018: 734-750.
[本文引用: 2]
[6]
ZHU C, HE Y, SAVVIDES M. Feature selective anchor-free module for single-shot object detection [C]// Proceedings of the IEEE International Conference on Computer Vision . Long Beach: IEEE, 2019: 840-849.
[本文引用: 1]
[7]
TIAN Z, SHEN C, CHEN H, et al. FCOS: fully convolutional one-stage object detection [C]// Proceedings of the IEEE International Conference on Computer Vision . Seoul: IEEE, 2019: 9627-9636.
[本文引用: 1]
[8]
KONG T, SUN F, LIU H, et al. FoveaBox: beyond anchor-based object detector [EB/OL]. [2019-04-08]. https://arxiv.org/ftp/arxiv/papers/1904/1904.03797.pdf.
[本文引用: 1]
[9]
SANDLER M, HOWARD A, ZHU M, et al. MobileNetV2: inverted residuals and linear bottlenecks [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4510-4520.
[本文引用: 1]
[10]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2980-2988.
[本文引用: 2]
[11]
LIN T Y, DOLLAR P, GIRSHICK R, et al. Feature pyramid networks for object detection [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Honolulu: IEEE, 2017: 2117-2125.
[本文引用: 1]
[12]
DAI J, QI H, XIONG Y, et al. Deformable convolutional networks [C]// Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 764-773.
[本文引用: 1]
[13]
SUN F, KONG T, HUANG W, et al Feature pyramid reconfiguration with consistent loss for object detection
[J]. IEEE Transactions on Image Processing , 2019 , 28 (10 ): 5041 - 5051
DOI:10.1109/TIP.2019.2917781
[本文引用: 1]
[14]
NAIR V, HINTON G E. Rectified linear units improve restricted boltzmann machines [C]// Proceedings of the 27th International Conference on Machine Learning . Haifa: ACM, 2010: 807-814.
[本文引用: 1]
[15]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
[本文引用: 2]
[16]
LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft coco: common objects in context [C]// European Conference on Computer Vision . Swizterland: Springer, 2014: 740-755.
[本文引用: 1]
[17]
REDMON J, FARHADI A. Yolov3: an incremental improvement [EB/OL]. [2018-04-08]. https://arxiv.org/pdf/1804.02767.pdf.
[本文引用: 1]
[18]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot multibox detector [C]// European Conference on Computer Vision . Amsterdam: Springer, 2016: 21-37.
[本文引用: 1]
[19]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770-778.
[本文引用: 1]
[20]
NEWELL A, YANG K, DENG J. Stacked hourglass networks for human pose estimation [C]// European Conference on Computer Vision . Amsterdam: Springer, 2016: 483-499.
[本文引用: 1]
[21]
SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [C]// International Conference on Learning Representations . San Diego: ICLR, 2015: 1–14.
[本文引用: 1]
[22]
BORGES P V K, IZQUIERDO E A probabilistic approach for vision-based fire detection in videos
[J]. IEEE Transactions on Circuits and Systems for Video Technology , 2010 , 20 (5 ): 721 - 731
DOI:10.1109/TCSVT.2010.2045813
[本文引用: 2]
[23]
TRUONG T X, KIM J M Fire flame detection in video sequences using multi-stage pattern recognition techniques
[J]. Engineering Applications of Artificial Intelligence , 2012 , 25 (7 ): 1365 - 1372
DOI:10.1016/j.engappai.2012.05.007
[本文引用: 1]
[24]
吴茜茵, 严云洋, 杜静, 等 多特征融合的火焰检测算法
[J]. 智能系统学报 , 2015 , 10 (2 ): 240 - 247
[本文引用: 1]
WU Xi-yin, YAN Yun-yang, DU Jing, et al Fire detection based on fusion of multiple features
[J]. CAAI Transactions on Intelligent Systems , 2015 , 10 (2 ): 240 - 247
[本文引用: 1]
[25]
KONG S G, JIN D, LI S, et al Fast fire flame detection in surveillance video using logistic regression and temporal smoothing
[J]. Fire Safety Journal , 2016 , 79 : 37 - 43
DOI:10.1016/j.firesaf.2015.11.015
[本文引用: 1]
[26]
梅建军, 张为 基于ViBe与机器学习的早期火灾检测算法
[J]. 光学学报 , 2018 , 38 (7 ): 60 - 67
[本文引用: 2]
MEI Jian-jun, ZHANG Wei Early fire detection algorithm based on ViBe and machine learning
[J]. Acta Optica Sinica , 2018 , 38 (7 ): 60 - 67
[本文引用: 2]
1
... 基于视频图像检测火灾的研究已有数年,早期,研究者主要依据相应的场景手工提取火焰的静态、动态等特征来对火焰进行描述,或者结合机器学习的方法设计合适的分类器来作进一步的判别. 比如Seebamrungsat等[1 ] 基于火焰的颜色特征分析,以HSV颜色模型和YCbCr颜色模型为基础,设计火的分类规则,这种方法明显优于在RGB颜色空间下的模型. Mahdi等[2 ] 利用基于颜色信息的K聚类方法提取出了候选区域,结合火焰的运动信息和时空特征设计准确识别火焰的方法. 这些方法大都是基于对火的浅层特征的提取,属于启发式的方法,鲁棒性较差,很难适应于复杂场景下的火灾检测. 随着深度学习技术的不断发展,人们渐渐转向利用卷积神经网络来进行图像型火灾检测. Kim等[3 ] 提出结合R-CNN和LSTM神经网络的火灾检测方法,其中R-CNN网络用于判别疑似区域和非火区域,LSTM网络通过提取视频连续帧的特征,对R-CNN的结果作进一步的筛选. Wu等[4 ] 尝试使用Faster RCNN、Yolo、SSD等经典目标检测算法进行火灾检测. 上述基于深度学习的火灾检测算法主要存在以下3个问题. ...
Fire detection for video surveillance applications using ICA K-medoids-based color model and efficient spatio-temporal visual features
3
2019
... 基于视频图像检测火灾的研究已有数年,早期,研究者主要依据相应的场景手工提取火焰的静态、动态等特征来对火焰进行描述,或者结合机器学习的方法设计合适的分类器来作进一步的判别. 比如Seebamrungsat等[1 ] 基于火焰的颜色特征分析,以HSV颜色模型和YCbCr颜色模型为基础,设计火的分类规则,这种方法明显优于在RGB颜色空间下的模型. Mahdi等[2 ] 利用基于颜色信息的K聚类方法提取出了候选区域,结合火焰的运动信息和时空特征设计准确识别火焰的方法. 这些方法大都是基于对火的浅层特征的提取,属于启发式的方法,鲁棒性较差,很难适应于复杂场景下的火灾检测. 随着深度学习技术的不断发展,人们渐渐转向利用卷积神经网络来进行图像型火灾检测. Kim等[3 ] 提出结合R-CNN和LSTM神经网络的火灾检测方法,其中R-CNN网络用于判别疑似区域和非火区域,LSTM网络通过提取视频连续帧的特征,对R-CNN的结果作进一步的筛选. Wu等[4 ] 尝试使用Faster RCNN、Yolo、SSD等经典目标检测算法进行火灾检测. 上述基于深度学习的火灾检测算法主要存在以下3个问题. ...
... 为了进一步验证本文算法对火灾检测的有效性,笔者在Bilkent大学的VisiFire公开数据集( http://signal.ee.bilkent.edu.tr/VisiFire/ )上对比了文献[2 ],[22 ~26 ]及本文所提算法的检测效果. 受篇幅限制,只选取其中的8段使用频率较高的视频进行对比分析,如图6 所示. ...
... Comparison of fire detection results of existing fire detection algorithms and proposed algorith
Tab.3 算法 TPR/% TNR/% 图6(a) 图6(b) 图6(c) 图6(d) 图6(e) 图6(f) 图6(g) 图6(h) 文献[22 ] 94.59 − 92.25 − 95.45 − − − 文献[23 ] 94.98 − 93.00 − 96.50 − − − 文献[24 ] 91.20 − − 88.60 95.80 − − − 文献[25 ] 95.70 − 93.10 − 100 − − − 文献[26 ] 93.00 − 91.00 − 100 − − 100 文献[2 ] 100 94.29 96.15 − 100 95.20 − − 本文 100 96.15 94.75 97.95 99.49 97.41 100 100
从与经典目标检测算法和现有火灾检测算法的对比可以看出,本文算法检测率和误报率的综合性能更好. 相比于其他算法,本文提出的算法不仅检测精度高,能够检测出多种情景下的火焰,而且抗干扰能力强,不易受灯光、人员、车辆等物体影响. 除此之外,本文算法运行速度可以达到24.6帧/s,能够满足实时检测的需求,而且经过实际测试,本文提出的算法模型大小仅为34.01MB,可以很方便的应用到实际火灾检测中来,是一个十分有效的火灾检测算法. ...
A video-based fire detection using deep learning models
1
2019
... 基于视频图像检测火灾的研究已有数年,早期,研究者主要依据相应的场景手工提取火焰的静态、动态等特征来对火焰进行描述,或者结合机器学习的方法设计合适的分类器来作进一步的判别. 比如Seebamrungsat等[1 ] 基于火焰的颜色特征分析,以HSV颜色模型和YCbCr颜色模型为基础,设计火的分类规则,这种方法明显优于在RGB颜色空间下的模型. Mahdi等[2 ] 利用基于颜色信息的K聚类方法提取出了候选区域,结合火焰的运动信息和时空特征设计准确识别火焰的方法. 这些方法大都是基于对火的浅层特征的提取,属于启发式的方法,鲁棒性较差,很难适应于复杂场景下的火灾检测. 随着深度学习技术的不断发展,人们渐渐转向利用卷积神经网络来进行图像型火灾检测. Kim等[3 ] 提出结合R-CNN和LSTM神经网络的火灾检测方法,其中R-CNN网络用于判别疑似区域和非火区域,LSTM网络通过提取视频连续帧的特征,对R-CNN的结果作进一步的筛选. Wu等[4 ] 尝试使用Faster RCNN、Yolo、SSD等经典目标检测算法进行火灾检测. 上述基于深度学习的火灾检测算法主要存在以下3个问题. ...
1
... 基于视频图像检测火灾的研究已有数年,早期,研究者主要依据相应的场景手工提取火焰的静态、动态等特征来对火焰进行描述,或者结合机器学习的方法设计合适的分类器来作进一步的判别. 比如Seebamrungsat等[1 ] 基于火焰的颜色特征分析,以HSV颜色模型和YCbCr颜色模型为基础,设计火的分类规则,这种方法明显优于在RGB颜色空间下的模型. Mahdi等[2 ] 利用基于颜色信息的K聚类方法提取出了候选区域,结合火焰的运动信息和时空特征设计准确识别火焰的方法. 这些方法大都是基于对火的浅层特征的提取,属于启发式的方法,鲁棒性较差,很难适应于复杂场景下的火灾检测. 随着深度学习技术的不断发展,人们渐渐转向利用卷积神经网络来进行图像型火灾检测. Kim等[3 ] 提出结合R-CNN和LSTM神经网络的火灾检测方法,其中R-CNN网络用于判别疑似区域和非火区域,LSTM网络通过提取视频连续帧的特征,对R-CNN的结果作进一步的筛选. Wu等[4 ] 尝试使用Faster RCNN、Yolo、SSD等经典目标检测算法进行火灾检测. 上述基于深度学习的火灾检测算法主要存在以下3个问题. ...
2
... 针对当前利用神经网络进行火灾检测算法中的不足,借鉴目前目标检测领域中CornerNet[5 ] 、FSAF[6 ] 、FCOS[7 ] 、FoveaBox[8 ] 等网络采用的Anchor-Free(无锚框)网络结构,即舍弃网络中anchor,直接预测物体所属类别和位置的一种网络形式;本文提出采用Anchor-Free网络结构形式的火灾检测算法. 该算法采用MobileNetV2[9 ] 作为特征提取网络,通过逐点预测的方式取代了在图像上遍历大量anchor的方式;在分类子网络中引入形变卷积模块来解决特征不对齐问题,使用特征选择模块选择更合适的金字塔特征层进行学习、预测. ...
... 为了验证本文算法的有效性,与现有的经典目标检测算法模型在本文数据集上进行对比实验,目标检测模型包含YoloV3[17 ] 、SSD[18 ] 等主流模型. 由于网络计算量过大,无法满足火灾检测实时性要求,对比实验中没有选取以ResNet[19 ] 、Hourglass[20 ] 等为主干网络的网络模型,比如Faster RCNN[15 ] 、CornerNet[5 ] 等. 相关测试结果见表2 . ...
1
... 针对当前利用神经网络进行火灾检测算法中的不足,借鉴目前目标检测领域中CornerNet[5 ] 、FSAF[6 ] 、FCOS[7 ] 、FoveaBox[8 ] 等网络采用的Anchor-Free(无锚框)网络结构,即舍弃网络中anchor,直接预测物体所属类别和位置的一种网络形式;本文提出采用Anchor-Free网络结构形式的火灾检测算法. 该算法采用MobileNetV2[9 ] 作为特征提取网络,通过逐点预测的方式取代了在图像上遍历大量anchor的方式;在分类子网络中引入形变卷积模块来解决特征不对齐问题,使用特征选择模块选择更合适的金字塔特征层进行学习、预测. ...
1
... 针对当前利用神经网络进行火灾检测算法中的不足,借鉴目前目标检测领域中CornerNet[5 ] 、FSAF[6 ] 、FCOS[7 ] 、FoveaBox[8 ] 等网络采用的Anchor-Free(无锚框)网络结构,即舍弃网络中anchor,直接预测物体所属类别和位置的一种网络形式;本文提出采用Anchor-Free网络结构形式的火灾检测算法. 该算法采用MobileNetV2[9 ] 作为特征提取网络,通过逐点预测的方式取代了在图像上遍历大量anchor的方式;在分类子网络中引入形变卷积模块来解决特征不对齐问题,使用特征选择模块选择更合适的金字塔特征层进行学习、预测. ...
1
... 针对当前利用神经网络进行火灾检测算法中的不足,借鉴目前目标检测领域中CornerNet[5 ] 、FSAF[6 ] 、FCOS[7 ] 、FoveaBox[8 ] 等网络采用的Anchor-Free(无锚框)网络结构,即舍弃网络中anchor,直接预测物体所属类别和位置的一种网络形式;本文提出采用Anchor-Free网络结构形式的火灾检测算法. 该算法采用MobileNetV2[9 ] 作为特征提取网络,通过逐点预测的方式取代了在图像上遍历大量anchor的方式;在分类子网络中引入形变卷积模块来解决特征不对齐问题,使用特征选择模块选择更合适的金字塔特征层进行学习、预测. ...
1
... 针对当前利用神经网络进行火灾检测算法中的不足,借鉴目前目标检测领域中CornerNet[5 ] 、FSAF[6 ] 、FCOS[7 ] 、FoveaBox[8 ] 等网络采用的Anchor-Free(无锚框)网络结构,即舍弃网络中anchor,直接预测物体所属类别和位置的一种网络形式;本文提出采用Anchor-Free网络结构形式的火灾检测算法. 该算法采用MobileNetV2[9 ] 作为特征提取网络,通过逐点预测的方式取代了在图像上遍历大量anchor的方式;在分类子网络中引入形变卷积模块来解决特征不对齐问题,使用特征选择模块选择更合适的金字塔特征层进行学习、预测. ...
2
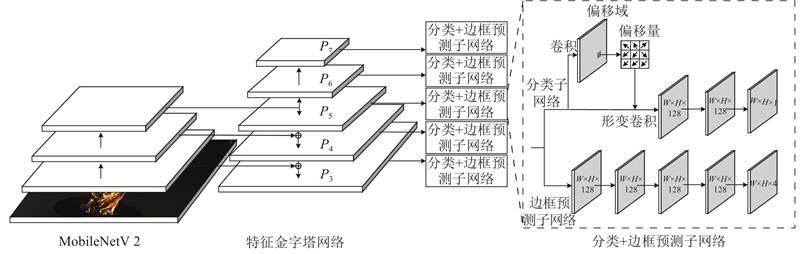
... 采用Anchor-Free网络结构的火灾检测算法网络模型结构如图1 所示. 该网络模型采用和RetinaNet[10 ] 类似的结构,包含1个负责提取特征的主干网络和2个分别负责分类和边框预测的子网络. MobileNetV2轻量网络作为基础特征提取网络,对经预处理的图片进行初步特征提取. 火焰形状大小多变,早期尺寸较小,如果仅仅基于特征提取网络单个高层特征对信息进行分类与判别,将无法准确提取火焰特征. 为解决这个问题,在MobileNetV2网络后引入特征金字塔结构(feature pyramid networks,FPN)[11 ] . FPN采用自顶向下以及横向连接的结构,既能利用高层的强语义特征,又能利用低层的高分辨率信息,利于初期小火的检测. FPN的每个特征金字塔层都可以用来预测不同尺度的目标,图1 中,FPN共利用P 3 到P 7 5个特征层,其中Pl (l = 3, 4, 5, 6, 7)代表该层分辨率是原图的1/2l
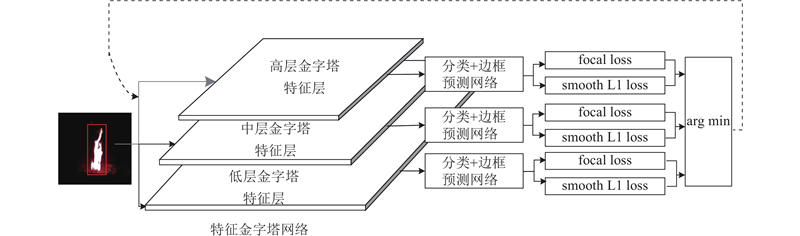
... 在分类网络的训练过程中,位于有效区域内的像素点标签设为1,表示火这类物体,有效区域外的像素点均设为0,表示负样本. 一般来说,有效区域的面积仅占特征图的很小一部分,如果在训练过程中设置有效区域内点的权重与有效区域外点的权重相同,将出现正负样本比例严重失衡的问题. 使用focal loss[10 ] 作为分子网络训练时的损失函数. ...
1
... 采用Anchor-Free网络结构的火灾检测算法网络模型结构如图1 所示. 该网络模型采用和RetinaNet[10 ] 类似的结构,包含1个负责提取特征的主干网络和2个分别负责分类和边框预测的子网络. MobileNetV2轻量网络作为基础特征提取网络,对经预处理的图片进行初步特征提取. 火焰形状大小多变,早期尺寸较小,如果仅仅基于特征提取网络单个高层特征对信息进行分类与判别,将无法准确提取火焰特征. 为解决这个问题,在MobileNetV2网络后引入特征金字塔结构(feature pyramid networks,FPN)[11 ] . FPN采用自顶向下以及横向连接的结构,既能利用高层的强语义特征,又能利用低层的高分辨率信息,利于初期小火的检测. FPN的每个特征金字塔层都可以用来预测不同尺度的目标,图1 中,FPN共利用P 3 到P 7 5个特征层,其中Pl (l = 3, 4, 5, 6, 7)代表该层分辨率是原图的1/2l
1
... 图1 虚线框中上半部分是负责火焰分类的子网络. 分类子网络从FPN结构中接收特征图之后,通过可形变卷积[12 ] 解决特征不对齐[13 ] 和标准卷积形状固定的问题. 在可形变卷积后使用2个3×3的卷积核,生成大小为W ×H ×128的特征图,卷积层使用ReLU[14 ] 作为激活函数. 使用1个3×3大小的卷积核,生成大小为W ×H ×1的特征图,特征图中每个点表示被归为火焰的概率. 图1 虚线框中下半部分是负责边框预测的子网络. 边框预测子网络与分类子网络并行,用来预测目标点与火焰真实框之间的偏移量. 边框预测子网络共有5层,与RetinaNet中边框预测网络一致,均使用3×3大小的卷积核,激活函数使用ReLU,前4层大小为W ×H ×128,最后一层的大小为W ×H ×4,为每个点生成一个表示位置信息[x 1 , y 1 , x 2 , y 2 ]的四维向量. ...
Feature pyramid reconfiguration with consistent loss for object detection
1
2019
... 图1 虚线框中上半部分是负责火焰分类的子网络. 分类子网络从FPN结构中接收特征图之后,通过可形变卷积[12 ] 解决特征不对齐[13 ] 和标准卷积形状固定的问题. 在可形变卷积后使用2个3×3的卷积核,生成大小为W ×H ×128的特征图,卷积层使用ReLU[14 ] 作为激活函数. 使用1个3×3大小的卷积核,生成大小为W ×H ×1的特征图,特征图中每个点表示被归为火焰的概率. 图1 虚线框中下半部分是负责边框预测的子网络. 边框预测子网络与分类子网络并行,用来预测目标点与火焰真实框之间的偏移量. 边框预测子网络共有5层,与RetinaNet中边框预测网络一致,均使用3×3大小的卷积核,激活函数使用ReLU,前4层大小为W ×H ×128,最后一层的大小为W ×H ×4,为每个点生成一个表示位置信息[x 1 , y 1 , x 2 , y 2 ]的四维向量. ...
1
... 图1 虚线框中上半部分是负责火焰分类的子网络. 分类子网络从FPN结构中接收特征图之后,通过可形变卷积[12 ] 解决特征不对齐[13 ] 和标准卷积形状固定的问题. 在可形变卷积后使用2个3×3的卷积核,生成大小为W ×H ×128的特征图,卷积层使用ReLU[14 ] 作为激活函数. 使用1个3×3大小的卷积核,生成大小为W ×H ×1的特征图,特征图中每个点表示被归为火焰的概率. 图1 虚线框中下半部分是负责边框预测的子网络. 边框预测子网络与分类子网络并行,用来预测目标点与火焰真实框之间的偏移量. 边框预测子网络共有5层,与RetinaNet中边框预测网络一致,均使用3×3大小的卷积核,激活函数使用ReLU,前4层大小为W ×H ×128,最后一层的大小为W ×H ×4,为每个点生成一个表示位置信息[x 1 , y 1 , x 2 , y 2 ]的四维向量. ...
Faster R-CNN: towards real-time object detection with region proposal networks
2
2017
... 在进行目标边框预测时,对于落在有效区域内的点(x , y ),定义监督信号 ${d_t} = ({t_{{x_1}}},\;{t_{{y_1}}},\;{t_{{x_2}}},\;{t_{{y_2}}})$ . 其中 ${t_{{x_1}}}{\text{、}}\;{t_{{y_1}}}{\text{、}}\;{t_{{x_2}}}{\text{、}}\;{t_{{y_2}}}$ x , y )点到 $b_p^l$ [15 ] 作为边框预测子网络训练时的损失函数. ...
... 为了验证本文算法的有效性,与现有的经典目标检测算法模型在本文数据集上进行对比实验,目标检测模型包含YoloV3[17 ] 、SSD[18 ] 等主流模型. 由于网络计算量过大,无法满足火灾检测实时性要求,对比实验中没有选取以ResNet[19 ] 、Hourglass[20 ] 等为主干网络的网络模型,比如Faster RCNN[15 ] 、CornerNet[5 ] 等. 相关测试结果见表2 . ...
1
... 针对火灾检测任务,目前尚未有公开的专用数据集,因此,按照MS COCO数据集[16 ] 格式标准建立场景丰富的火焰目标检测数据集. 数据集图片来源于42段实际火灾现场视频和95段模拟火灾视频,包括工厂、超市、学校、地铁站、停车场等上百个场景,涉及室内、室外、白天、夜晚、运动物体干扰、颜色干扰、灯光干扰等多种情况,共计13 655张图像,其中训练集10 070张,测试集3 585张,训练集与测试集图片来自于不同视频片段. 为了防止过拟合情况的发生,训练阶段时对图片进行了随机翻转、缩放、随机裁剪等数据增强操作. ...
1
... 为了验证本文算法的有效性,与现有的经典目标检测算法模型在本文数据集上进行对比实验,目标检测模型包含YoloV3[17 ] 、SSD[18 ] 等主流模型. 由于网络计算量过大,无法满足火灾检测实时性要求,对比实验中没有选取以ResNet[19 ] 、Hourglass[20 ] 等为主干网络的网络模型,比如Faster RCNN[15 ] 、CornerNet[5 ] 等. 相关测试结果见表2 . ...
1
... 为了验证本文算法的有效性,与现有的经典目标检测算法模型在本文数据集上进行对比实验,目标检测模型包含YoloV3[17 ] 、SSD[18 ] 等主流模型. 由于网络计算量过大,无法满足火灾检测实时性要求,对比实验中没有选取以ResNet[19 ] 、Hourglass[20 ] 等为主干网络的网络模型,比如Faster RCNN[15 ] 、CornerNet[5 ] 等. 相关测试结果见表2 . ...
1
... 为了验证本文算法的有效性,与现有的经典目标检测算法模型在本文数据集上进行对比实验,目标检测模型包含YoloV3[17 ] 、SSD[18 ] 等主流模型. 由于网络计算量过大,无法满足火灾检测实时性要求,对比实验中没有选取以ResNet[19 ] 、Hourglass[20 ] 等为主干网络的网络模型,比如Faster RCNN[15 ] 、CornerNet[5 ] 等. 相关测试结果见表2 . ...
1
... 为了验证本文算法的有效性,与现有的经典目标检测算法模型在本文数据集上进行对比实验,目标检测模型包含YoloV3[17 ] 、SSD[18 ] 等主流模型. 由于网络计算量过大,无法满足火灾检测实时性要求,对比实验中没有选取以ResNet[19 ] 、Hourglass[20 ] 等为主干网络的网络模型,比如Faster RCNN[15 ] 、CornerNet[5 ] 等. 相关测试结果见表2 . ...
1
... Comparison of fire detection results of the representative object detection algorithms and proposed algorith
Tab.2 算法 主干网络 AP50 /% 单张图片检测时间/ms YoloV3 DarkNet-53 89.2 38.4 SSD300 Vgg[21 ] 85.0 27.6 ReinaNet-MobileNet MobileNetV2 87.3 41.5 本文 MobileNetV2 90.1 40.7
为了进一步验证本文算法对火灾检测的有效性,笔者在Bilkent大学的VisiFire公开数据集( http://signal.ee.bilkent.edu.tr/VisiFire/ )上对比了文献[2 ],[22 ~26 ]及本文所提算法的检测效果. 受篇幅限制,只选取其中的8段使用频率较高的视频进行对比分析,如图6 所示. ...
A probabilistic approach for vision-based fire detection in videos
2
2010
... 为了进一步验证本文算法对火灾检测的有效性,笔者在Bilkent大学的VisiFire公开数据集( http://signal.ee.bilkent.edu.tr/VisiFire/ )上对比了文献[2 ],[22 ~26 ]及本文所提算法的检测效果. 受篇幅限制,只选取其中的8段使用频率较高的视频进行对比分析,如图6 所示. ...
... Comparison of fire detection results of existing fire detection algorithms and proposed algorith
Tab.3 算法 TPR/% TNR/% 图6(a) 图6(b) 图6(c) 图6(d) 图6(e) 图6(f) 图6(g) 图6(h) 文献[22 ] 94.59 − 92.25 − 95.45 − − − 文献[23 ] 94.98 − 93.00 − 96.50 − − − 文献[24 ] 91.20 − − 88.60 95.80 − − − 文献[25 ] 95.70 − 93.10 − 100 − − − 文献[26 ] 93.00 − 91.00 − 100 − − 100 文献[2 ] 100 94.29 96.15 − 100 95.20 − − 本文 100 96.15 94.75 97.95 99.49 97.41 100 100
从与经典目标检测算法和现有火灾检测算法的对比可以看出,本文算法检测率和误报率的综合性能更好. 相比于其他算法,本文提出的算法不仅检测精度高,能够检测出多种情景下的火焰,而且抗干扰能力强,不易受灯光、人员、车辆等物体影响. 除此之外,本文算法运行速度可以达到24.6帧/s,能够满足实时检测的需求,而且经过实际测试,本文提出的算法模型大小仅为34.01MB,可以很方便的应用到实际火灾检测中来,是一个十分有效的火灾检测算法. ...
Fire flame detection in video sequences using multi-stage pattern recognition techniques
1
2012
... Comparison of fire detection results of existing fire detection algorithms and proposed algorith
Tab.3 算法 TPR/% TNR/% 图6(a) 图6(b) 图6(c) 图6(d) 图6(e) 图6(f) 图6(g) 图6(h) 文献[22 ] 94.59 − 92.25 − 95.45 − − − 文献[23 ] 94.98 − 93.00 − 96.50 − − − 文献[24 ] 91.20 − − 88.60 95.80 − − − 文献[25 ] 95.70 − 93.10 − 100 − − − 文献[26 ] 93.00 − 91.00 − 100 − − 100 文献[2 ] 100 94.29 96.15 − 100 95.20 − − 本文 100 96.15 94.75 97.95 99.49 97.41 100 100
从与经典目标检测算法和现有火灾检测算法的对比可以看出,本文算法检测率和误报率的综合性能更好. 相比于其他算法,本文提出的算法不仅检测精度高,能够检测出多种情景下的火焰,而且抗干扰能力强,不易受灯光、人员、车辆等物体影响. 除此之外,本文算法运行速度可以达到24.6帧/s,能够满足实时检测的需求,而且经过实际测试,本文提出的算法模型大小仅为34.01MB,可以很方便的应用到实际火灾检测中来,是一个十分有效的火灾检测算法. ...
多特征融合的火焰检测算法
1
2015
... Comparison of fire detection results of existing fire detection algorithms and proposed algorith
Tab.3 算法 TPR/% TNR/% 图6(a) 图6(b) 图6(c) 图6(d) 图6(e) 图6(f) 图6(g) 图6(h) 文献[22 ] 94.59 − 92.25 − 95.45 − − − 文献[23 ] 94.98 − 93.00 − 96.50 − − − 文献[24 ] 91.20 − − 88.60 95.80 − − − 文献[25 ] 95.70 − 93.10 − 100 − − − 文献[26 ] 93.00 − 91.00 − 100 − − 100 文献[2 ] 100 94.29 96.15 − 100 95.20 − − 本文 100 96.15 94.75 97.95 99.49 97.41 100 100
从与经典目标检测算法和现有火灾检测算法的对比可以看出,本文算法检测率和误报率的综合性能更好. 相比于其他算法,本文提出的算法不仅检测精度高,能够检测出多种情景下的火焰,而且抗干扰能力强,不易受灯光、人员、车辆等物体影响. 除此之外,本文算法运行速度可以达到24.6帧/s,能够满足实时检测的需求,而且经过实际测试,本文提出的算法模型大小仅为34.01MB,可以很方便的应用到实际火灾检测中来,是一个十分有效的火灾检测算法. ...
多特征融合的火焰检测算法
1
2015
... Comparison of fire detection results of existing fire detection algorithms and proposed algorith
Tab.3 算法 TPR/% TNR/% 图6(a) 图6(b) 图6(c) 图6(d) 图6(e) 图6(f) 图6(g) 图6(h) 文献[22 ] 94.59 − 92.25 − 95.45 − − − 文献[23 ] 94.98 − 93.00 − 96.50 − − − 文献[24 ] 91.20 − − 88.60 95.80 − − − 文献[25 ] 95.70 − 93.10 − 100 − − − 文献[26 ] 93.00 − 91.00 − 100 − − 100 文献[2 ] 100 94.29 96.15 − 100 95.20 − − 本文 100 96.15 94.75 97.95 99.49 97.41 100 100
从与经典目标检测算法和现有火灾检测算法的对比可以看出,本文算法检测率和误报率的综合性能更好. 相比于其他算法,本文提出的算法不仅检测精度高,能够检测出多种情景下的火焰,而且抗干扰能力强,不易受灯光、人员、车辆等物体影响. 除此之外,本文算法运行速度可以达到24.6帧/s,能够满足实时检测的需求,而且经过实际测试,本文提出的算法模型大小仅为34.01MB,可以很方便的应用到实际火灾检测中来,是一个十分有效的火灾检测算法. ...
Fast fire flame detection in surveillance video using logistic regression and temporal smoothing
1
2016
... Comparison of fire detection results of existing fire detection algorithms and proposed algorith
Tab.3 算法 TPR/% TNR/% 图6(a) 图6(b) 图6(c) 图6(d) 图6(e) 图6(f) 图6(g) 图6(h) 文献[22 ] 94.59 − 92.25 − 95.45 − − − 文献[23 ] 94.98 − 93.00 − 96.50 − − − 文献[24 ] 91.20 − − 88.60 95.80 − − − 文献[25 ] 95.70 − 93.10 − 100 − − − 文献[26 ] 93.00 − 91.00 − 100 − − 100 文献[2 ] 100 94.29 96.15 − 100 95.20 − − 本文 100 96.15 94.75 97.95 99.49 97.41 100 100
从与经典目标检测算法和现有火灾检测算法的对比可以看出,本文算法检测率和误报率的综合性能更好. 相比于其他算法,本文提出的算法不仅检测精度高,能够检测出多种情景下的火焰,而且抗干扰能力强,不易受灯光、人员、车辆等物体影响. 除此之外,本文算法运行速度可以达到24.6帧/s,能够满足实时检测的需求,而且经过实际测试,本文提出的算法模型大小仅为34.01MB,可以很方便的应用到实际火灾检测中来,是一个十分有效的火灾检测算法. ...
基于ViBe与机器学习的早期火灾检测算法
2
2018
... 为了进一步验证本文算法对火灾检测的有效性,笔者在Bilkent大学的VisiFire公开数据集( http://signal.ee.bilkent.edu.tr/VisiFire/ )上对比了文献[2 ],[22 ~26 ]及本文所提算法的检测效果. 受篇幅限制,只选取其中的8段使用频率较高的视频进行对比分析,如图6 所示. ...
... Comparison of fire detection results of existing fire detection algorithms and proposed algorith
Tab.3 算法 TPR/% TNR/% 图6(a) 图6(b) 图6(c) 图6(d) 图6(e) 图6(f) 图6(g) 图6(h) 文献[22 ] 94.59 − 92.25 − 95.45 − − − 文献[23 ] 94.98 − 93.00 − 96.50 − − − 文献[24 ] 91.20 − − 88.60 95.80 − − − 文献[25 ] 95.70 − 93.10 − 100 − − − 文献[26 ] 93.00 − 91.00 − 100 − − 100 文献[2 ] 100 94.29 96.15 − 100 95.20 − − 本文 100 96.15 94.75 97.95 99.49 97.41 100 100
从与经典目标检测算法和现有火灾检测算法的对比可以看出,本文算法检测率和误报率的综合性能更好. 相比于其他算法,本文提出的算法不仅检测精度高,能够检测出多种情景下的火焰,而且抗干扰能力强,不易受灯光、人员、车辆等物体影响. 除此之外,本文算法运行速度可以达到24.6帧/s,能够满足实时检测的需求,而且经过实际测试,本文提出的算法模型大小仅为34.01MB,可以很方便的应用到实际火灾检测中来,是一个十分有效的火灾检测算法. ...
基于ViBe与机器学习的早期火灾检测算法
2
2018
... 为了进一步验证本文算法对火灾检测的有效性,笔者在Bilkent大学的VisiFire公开数据集( http://signal.ee.bilkent.edu.tr/VisiFire/ )上对比了文献[2 ],[22 ~26 ]及本文所提算法的检测效果. 受篇幅限制,只选取其中的8段使用频率较高的视频进行对比分析,如图6 所示. ...
... Comparison of fire detection results of existing fire detection algorithms and proposed algorith
Tab.3 算法 TPR/% TNR/% 图6(a) 图6(b) 图6(c) 图6(d) 图6(e) 图6(f) 图6(g) 图6(h) 文献[22 ] 94.59 − 92.25 − 95.45 − − − 文献[23 ] 94.98 − 93.00 − 96.50 − − − 文献[24 ] 91.20 − − 88.60 95.80 − − − 文献[25 ] 95.70 − 93.10 − 100 − − − 文献[26 ] 93.00 − 91.00 − 100 − − 100 文献[2 ] 100 94.29 96.15 − 100 95.20 − − 本文 100 96.15 94.75 97.95 99.49 97.41 100 100
从与经典目标检测算法和现有火灾检测算法的对比可以看出,本文算法检测率和误报率的综合性能更好. 相比于其他算法,本文提出的算法不仅检测精度高,能够检测出多种情景下的火焰,而且抗干扰能力强,不易受灯光、人员、车辆等物体影响. 除此之外,本文算法运行速度可以达到24.6帧/s,能够满足实时检测的需求,而且经过实际测试,本文提出的算法模型大小仅为34.01MB,可以很方便的应用到实际火灾检测中来,是一个十分有效的火灾检测算法. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}