(10) $ \begin{split} {{{V}}_{i,t}} = & w{{{V}}_{i,t{\rm{ - 1}}}} + {C_{1}}{R_{(0,1)}}{\rm{(}}{{{P}}_{i,t{\rm{ - 1}}}}{\rm{ - }}{{{X}}_{i,t{\rm{ - 1}}}}{\rm{)}} + \\ & {C_2}{R_{(0,1)}}({{{G}}_{t - 1}} - {{{X}}_{i,t - 1}}), \end{split} $
1)定义长度为n 的原始负载时间序列数据集: ${{X}} = \{ {X_1},{X_2},{X_3},{X_4},\cdots,{X_{n - 1}},{X_n}\} $ . 2)利用min-max均一化方法对原始数据进行标准化处理,标准化后的数据表示为: ${{x'}} = $ $ \{ {x'_1},{x'_2},{x'_3},{x'_4},\cdots,{x'_{n - 1}},{x'_n}\} $ . 3)初始化参数. 确定粒子群算法中粒子个数、粒子群算法迭代次数、惯性权重和粒子位置的区间. 4)初始化粒子信息. 初始化每个粒子的位置 ${{{X}}_i} (h_1,h_2)$ ${{{V}}_i}$ h 1 为第1层隐藏层的神经元个数,h 2 为第2层隐藏层的神经元个数;初始化个体和全局最优位置,初始化个体和全局最优适应度. 5)粒子群算法参数更新. 根据后文说明的粒子群算法更新公式对速度、位置和权重进行更新,将超出位置限制范围的粒子重新拉入位置区间中. 6)根据步骤5)中粒子的参数初始化网络,将数据分成训练集和测试集2个部分。使用自适应算法输入训练集样本到模型中进行训练,得到训练后的模型. 输入测试集样本得到预测结果. 7)使用模型评价计算方法得到该参数下模型的评估值Q ,将该评估值作为该粒子的适应度值. 8)重复步骤6)、7),计算得到每个粒子的适应度,如果粒子的适应度小于该粒子的最佳适应度,则将该粒子的最佳适应度更新为当前适应度;如果有粒子的适应度优于全局最优适应度,则将全局最优适应度更新为该粒子的适应度,将全局最优位置更新为该粒子的位置. 9)重复步骤5)~8)直到达到最大迭代次数,用粒子群算法求得的最佳位置作为模型参数来初始化模型,将待预测数据输入到该模型中得到预测值.
[1]
YAN Y Q, GUO P Predicting resource consumption in a Web server using ARIMA model
[J]. Journal of Beijing Institute of Technology , 2014 , 23 (4 ): 502 - 510
[本文引用: 1]
[2]
CALHEIROS R N, MASOUMI E, RANJAN R, et al Workload prediction using ARIMA model and its impact on cloud applications' QoS
[J]. IEEE Transactions on Cloud Computing , 2014 , 3 (4 ): 449 - 458
[本文引用: 1]
[3]
PRASSANNA J, VENKATARAMAN N Adaptive regressive holt–winters workload prediction and firefly optimized lottery scheduling for load balancing in cloud
[J]. Wireless Networks , 2019 , 1 - 19
[本文引用: 1]
[4]
YAZDANIAN P, SHARIFIAN S. Cloud workload prediction using ConvNet and stacked LSTM [C]// 2018 4th Iranian Conference on Signal Processing and Intelligent Systems . Tehran: IEEE, 2018: 83-87.
[本文引用: 1]
[5]
谢晓兰, 张征征, 郑强清, 等 基于APMSSGA-LSTM 的容器云资源预测
[J]. 大数据 , 2019 , 5 (6 ): 62 - 72
[本文引用: 1]
XIE Xiao-lan, ZHANG Zheng-zheng, ZHENG Qiang-qing, et al Container cloud resource prediction based on APMSSGA-LSTM
[J]. Big Data Research , 2019 , 5 (6 ): 62 - 72
[本文引用: 1]
[6]
LIU J, TAN X Y, WANG Y. CSSAP: software aging prediction for cloud services based on ARIMA-LSTM hybrid model [C]// 2019 IEEE International Conference on Web Service s. Milan: IEEE, 2019: 283-290.
[本文引用: 1]
[7]
KUMAR S D, SUBHA D P. Prediction of depression from EEG signal using long short term memory [C]// 2019 3rd International Conference on Trends in Electronics and Informatics . Tirunelveli: IEEE, 2019: 1248-1253.
[本文引用: 1]
[8]
ZIĘBA M, TOMCZAK S K, TOMCZAK J M Ensemble boosted trees with synthetic features generation in application to bankruptcy prediction
[J]. Expert Systems with Applications , 2016 , 58 : 93 - 101
DOI:10.1016/j.eswa.2016.04.001
[本文引用: 1]
[9]
AKYUZ A O, UYSAL M, BULBUL B A, et al. Ensemble approach for time series analysis in demand forecasting: Ensemble learning [C]// 2017 IEEE International Conference on Innovations in Intelligent Systems and Applications . Gdynia: IEEE, 2017: 7-12.
[本文引用: 1]
[10]
BIN Y, YANG Y, SHEN F, et al. Bidirectional long-short term memory for video description [C]// Proceedings of the 24th ACM International Conference on Multimedia . New York: ACM, 2016: 436-440.
[本文引用: 1]
[11]
ZENNAKI O, SEMMAR N, BESACIER L. Inducing multilingual text analysis tools using bidirectional recurrent neural networks [C]// 26th International Conference on Computational Linguistics: Technical Papers . Osaka: COLING. 2016: 450-460.
[12]
SCHUSTER M, PALIWAL K K Bidirectional recurrent neural networks
[J]. IEEE Transactions on Signal Processing , 1997 , 45 (11 ): 2673 - 2681
DOI:10.1109/78.650093
[本文引用: 1]
[13]
SUN W, XU L, HUANG X, et al. Bidirectional LSTM for ionospheric vertical total electron content forecasting [C]// 2017 IEEE Visual Communications and Image Processing . St. Petersburg: IEEE, 2017: 1-4.
[本文引用: 1]
[14]
HU P, TONG J, WANG J, et al. A hybrid model based on CNN and Bi-LSTM for urban water demand prediction [C]// 2019 IEEE Congress on Evolutionary Computation . Wellington: IEEE, 2019: 1088-1094.
[15]
HAN S, ZHANG F, XI J, et al. Short-term vehicle speed prediction based on convolutional bidirectional LSTM networks [C]// 2019 IEEE Intelligent Transportation Systems Conference . Auckland: IEEE, 2019: 4055-4060.
[本文引用: 1]
[16]
KENNEDY J, EBERHART R. Particle swarm optimization [C]// Proceedings of ICNN'95-International Conference on Neural Networks . Perth: IEEE, 1995, 4: 1942-1948.
[本文引用: 1]
[17]
CHEN C, TWYCROSS J, GARIBALDI J M A new accuracy measure based on bounded relative error for time series forecasting
[J]. PloS One , 2017 , 12 (3 ): e0174202
DOI:10.1371/journal.pone.0174202
[本文引用: 1]
[19]
张利彪, 周春光, 马铭, 等 基于粒子群算法求解多目标优化问题
[J]. 计算机研究与发展 , 2004 , 41 (7 ): 1286 - 1291
[本文引用: 1]
ZHANG Li-biao, ZHOU Chun-guang, MA Ming, et al Solving multi-objective optimization problems based on particle swarm optimization
[J]. Journal of Computer Research and Development , 2004 , 41 (7 ): 1286 - 1291
[本文引用: 1]
[20]
DING W, FANG W. Target tracking by sequential random draft particle swarm optimization algorithm [C]// 2018 IEEE International Smart Cities Conference . Kansas City: IEEE, 2018: 1-7.
[21]
何明慧, 徐怡, 王冉, 等 改进的粒子群算法优化神经网络及应用
[J]. 计算机工程与应用 , 2018 , (19 ): 17
[本文引用: 1]
HE Ming-hui, XU Yi, WANG Ran, et al Improved particle swarm optimization neural network and its application
[J]. Computer Engineering and Applications , 2018 , (19 ): 17
[本文引用: 1]
[22]
BAI Q Analysis of particle swarm optimization algorithm
[J]. Computer and Information Science , 2010 , 3 (1 ): 180
[本文引用: 1]
Predicting resource consumption in a Web server using ARIMA model
1
2014
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
Workload prediction using ARIMA model and its impact on cloud applications' QoS
1
2014
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
Adaptive regressive holt–winters workload prediction and firefly optimized lottery scheduling for load balancing in cloud
1
2019
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
1
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
基于APMSSGA-LSTM 的容器云资源预测
1
2019
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
基于APMSSGA-LSTM 的容器云资源预测
1
2019
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
1
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
1
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
Ensemble boosted trees with synthetic features generation in application to bankruptcy prediction
1
2016
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
1
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
1
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
Bidirectional recurrent neural networks
1
1997
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
1
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
1
... 随着云计算时代的到来,越来越多的公司将应用迁移到云计算平台上. 云计算通过使用虚拟化技术将离散的资源整合成资源池,以按需分配的方式实现了用户对计算资源的弹性需求. 云计算的本质是按需求提供服务,实现应用资源在云平台上的自动分配和切换.要实现计算能力动态伸缩需要负载均衡技术. 云计算平台使用负载均衡技术增加了吞吐量,强化了数据处理能力.负载是实现负载均衡所需要的关键指标. 准确预测应用负载可以实现应用容量的流量高峰扩容和流量低谷缩容,从而节约资源成本,减少人工干预,提升云计算平台的可靠性和性能. 现在预测负载数据的方法通常有2类.1)基于时间序列特征的参数型算法.Yan等[1 ] 使用整合移动平均自回归模型(auto-regression and moving average model,ARIMA)算法预测软件系统的资源消耗,比较不同情景下ARIMA算法与人工神经网络、支持向量机的预测效果.Calheiros等[2 ] 设计基于ARIMA算法的云平台工作负载预测模块,通过基于该模型的预测数据进行主动动态资源配置,可以使用尽可能少的资源成本保证用户的应用服务质量.Prassanna等[3 ] 使用HoltWinters算法预测云环境的工作负载. 以上提到的这类算法通过建立数学模型拟合历史时间序列趋势曲线,存在参数难以确定的问题,大多数使用者根据自身经验设置参数.模型最终的准确度受参数的影响较大,同时模型难以对时间序列数据内部复杂的规律进行学习. 2)基于神经网络的时间序列预测算法,例如循环神经网络(recurrent neural network,RNN),长短时记忆(long short-term memory,LSTM)神经网络等. 神经网络类算法在时序数据预测上应用广泛.Yazdanian等[4 ] 结合卷积神经网络(convolutional neural networks,CNN)和LSTM,预测云环境中应用未来的工作负载;谢晓兰等[5 ] 使用自适应概率的多选择策略遗传算法优化LSTM容器云资源预测模型,取得了较高的预测精度.在云环境软件老化和抑郁症预测等其他场景下,神经网络模型取得了良好的预测效果[6 -7 ] . 还有一类算法,例如用增强集成树算法进行破产预测[8 ] ,用集成学习算法提高预测模型的准确度[9 ] ,这类算法通常不用于时序预测问题. 在时间序列预测问题上,传统的神经网络模型无法充分利用序列中的信息,而双向长短时记忆(bidirectional long short-term memory,BiLSTM)神经网络模型可以充分利用上下文数据进行预测,并且已经在多个领域取得了优异的效果[10 -12 ] . BiLSTM已经被运用在时间序列预测领域,并被验证相比于普通神经网络,BiLSTM取得了更高的预测精度[13 -15 ] . ...
1
... 使用神经网络预测时序数据目前存在2个问题.1)学习率和迭代次数难以确定,2)隐藏层层数和隐藏层的神经元个数难以确定. 本研究提出基于多层BiLSTM和改进的粒子群算法的应用负载预测方法(multi-layer bidirectional LSTM and improved PSO algorithm,Pa-BiLSTM),利用改进粒子群算法[16 ] 自动确定最佳隐藏层的神经元个数.结合自适应算法自动调整学习率和迭代次数,提高模型预测精度和加速模型收敛,采用基于基准模型的多指标融合的模型评价方法,验证方法的有效性[17 ] . ...
A new accuracy measure based on bounded relative error for time series forecasting
1
2017
... 使用神经网络预测时序数据目前存在2个问题.1)学习率和迭代次数难以确定,2)隐藏层层数和隐藏层的神经元个数难以确定. 本研究提出基于多层BiLSTM和改进的粒子群算法的应用负载预测方法(multi-layer bidirectional LSTM and improved PSO algorithm,Pa-BiLSTM),利用改进粒子群算法[16 ] 自动确定最佳隐藏层的神经元个数.结合自适应算法自动调整学习率和迭代次数,提高模型预测精度和加速模型收敛,采用基于基准模型的多指标融合的模型评价方法,验证方法的有效性[17 ] . ...
Long short-term memory
1
1997
... 传统的统计和数学方法在分析时间序列时需要在指定的时间窗口上运行,传统的机器学习算法需要大量的特征工程来训练分类器,LSTM神经网络无须特征工程即可学习长期顺序特征;递归神经网络存在梯度消失的问题,使模型无法正常收敛,LSTM解决了这一问题. 基于这些优点,人们开始使用LSTM对时间序列建模[18 ] . ...
基于粒子群算法求解多目标优化问题
1
2004
... 粒子群算法被广泛应用于各种优化问题[19 -21 ] ,本研究使用该算法实现模型参数的自动调优. 每个粒子代表待优化问题的一个可行解,通过粒子个体的简单行为和粒子群内的信息交互求解优化问题. 粒子具有速度和位置2个属性. 粒子的速度表示搜寻最优解的快慢,粒子的速度可以根据粒子历史最优位置和种群历史最优位置进行动态调整,粒子的当前位置即为对应优化问题的一个候选解. 每个粒子单独搜寻的最优解叫作个体极值,粒子群中的最优的个体极值作为当前全局最优解. 通过不断迭代更新速度和位置,最终可以得到满足终止条件的最优解. 第i 个粒子在t 时刻的速度和位置的更新公式为 ...
基于粒子群算法求解多目标优化问题
1
2004
... 粒子群算法被广泛应用于各种优化问题[19 -21 ] ,本研究使用该算法实现模型参数的自动调优. 每个粒子代表待优化问题的一个可行解,通过粒子个体的简单行为和粒子群内的信息交互求解优化问题. 粒子具有速度和位置2个属性. 粒子的速度表示搜寻最优解的快慢,粒子的速度可以根据粒子历史最优位置和种群历史最优位置进行动态调整,粒子的当前位置即为对应优化问题的一个候选解. 每个粒子单独搜寻的最优解叫作个体极值,粒子群中的最优的个体极值作为当前全局最优解. 通过不断迭代更新速度和位置,最终可以得到满足终止条件的最优解. 第i 个粒子在t 时刻的速度和位置的更新公式为 ...
改进的粒子群算法优化神经网络及应用
1
2018
... 粒子群算法被广泛应用于各种优化问题[19 -21 ] ,本研究使用该算法实现模型参数的自动调优. 每个粒子代表待优化问题的一个可行解,通过粒子个体的简单行为和粒子群内的信息交互求解优化问题. 粒子具有速度和位置2个属性. 粒子的速度表示搜寻最优解的快慢,粒子的速度可以根据粒子历史最优位置和种群历史最优位置进行动态调整,粒子的当前位置即为对应优化问题的一个候选解. 每个粒子单独搜寻的最优解叫作个体极值,粒子群中的最优的个体极值作为当前全局最优解. 通过不断迭代更新速度和位置,最终可以得到满足终止条件的最优解. 第i 个粒子在t 时刻的速度和位置的更新公式为 ...
改进的粒子群算法优化神经网络及应用
1
2018
... 粒子群算法被广泛应用于各种优化问题[19 -21 ] ,本研究使用该算法实现模型参数的自动调优. 每个粒子代表待优化问题的一个可行解,通过粒子个体的简单行为和粒子群内的信息交互求解优化问题. 粒子具有速度和位置2个属性. 粒子的速度表示搜寻最优解的快慢,粒子的速度可以根据粒子历史最优位置和种群历史最优位置进行动态调整,粒子的当前位置即为对应优化问题的一个候选解. 每个粒子单独搜寻的最优解叫作个体极值,粒子群中的最优的个体极值作为当前全局最优解. 通过不断迭代更新速度和位置,最终可以得到满足终止条件的最优解. 第i 个粒子在t 时刻的速度和位置的更新公式为 ...
Analysis of particle swarm optimization algorithm
1
2010
... 随着粒子群算法的应用领域快速扩大,该算法早熟收敛,维度灾难,容易陷入局部极值等问题开始显现[22 ] . 传统的粒子群算法使用固定的惯性权重,影响搜索的全局性和收敛速度. 惯性权重非负,惯性权重较大时全局寻优能力强,局部寻优能力弱;惯性权重较小时全局寻优能力弱,局部寻优能力强. 使用变化的惯性权重可以改善该算法的全局和局部寻优性能,改进后的惯性权重计算公式如下: ...


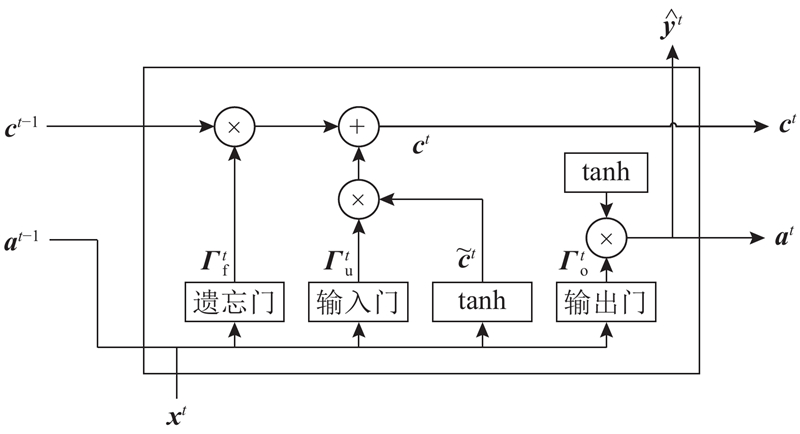
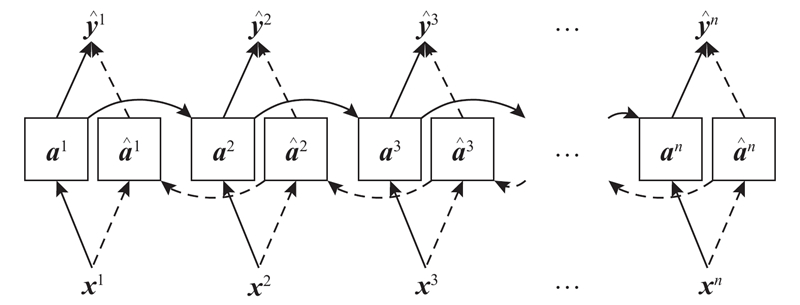
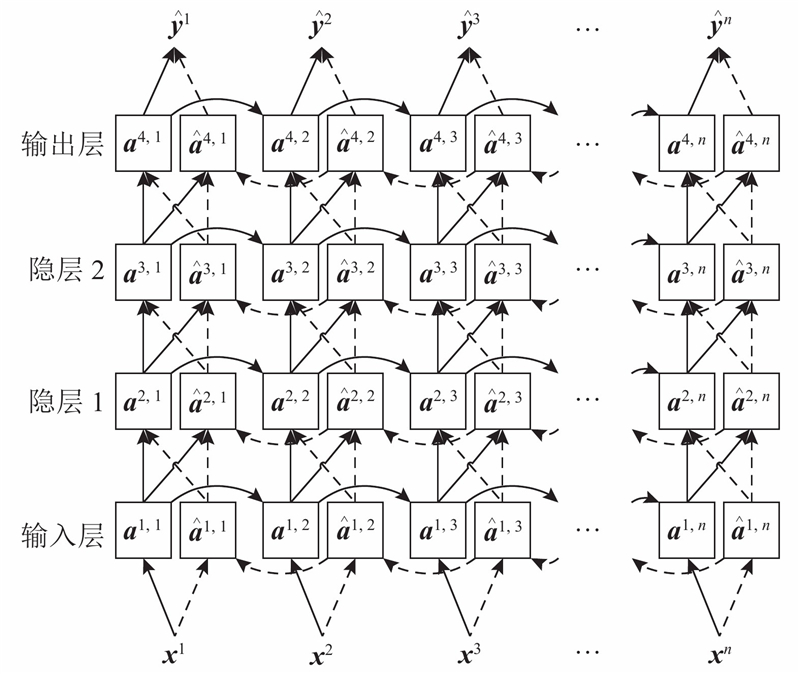

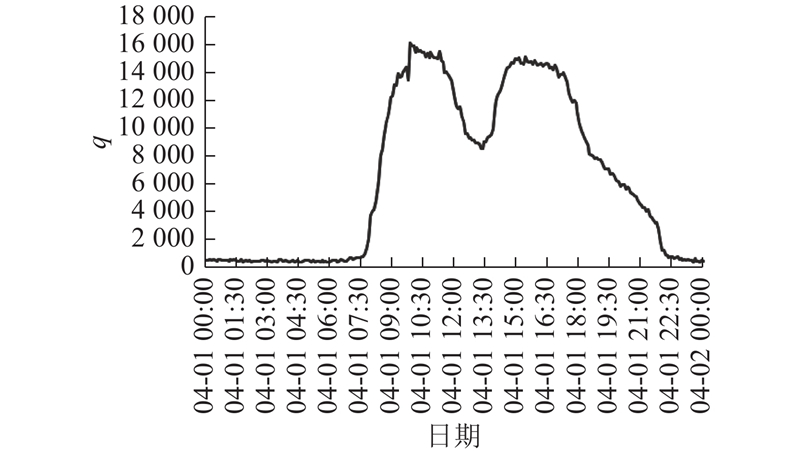

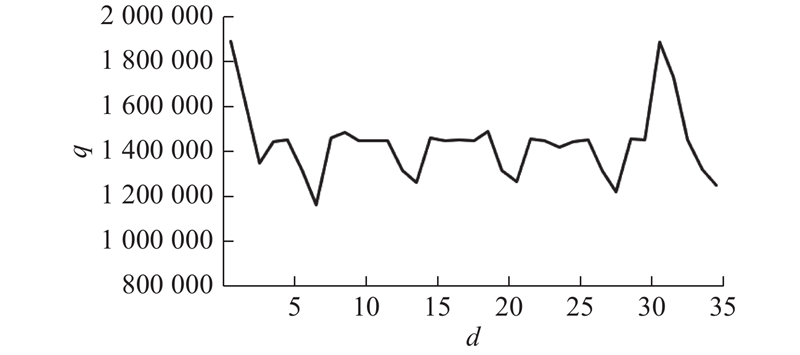
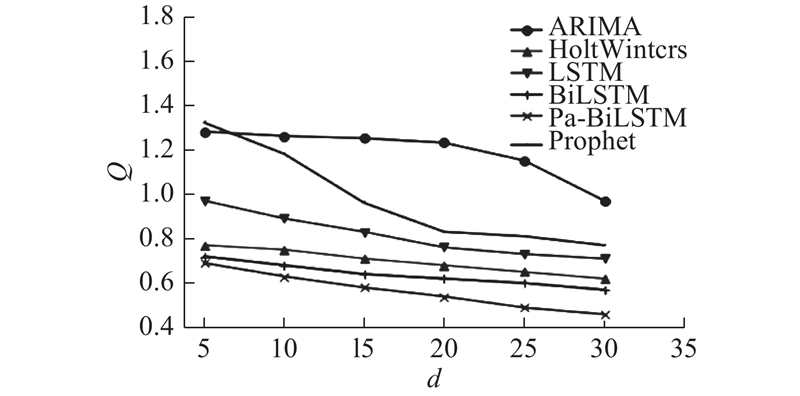
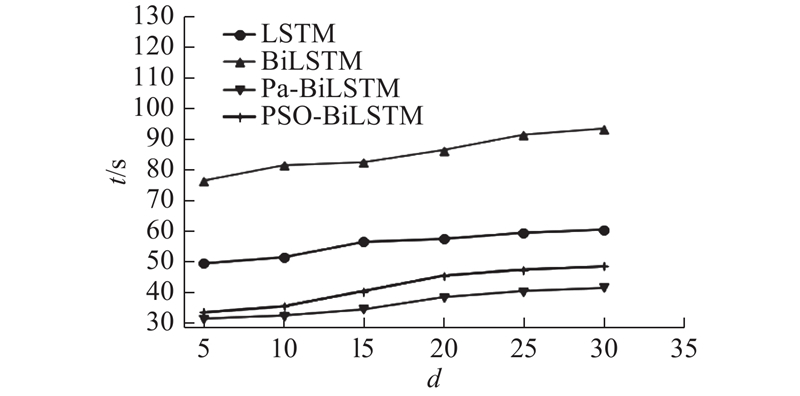
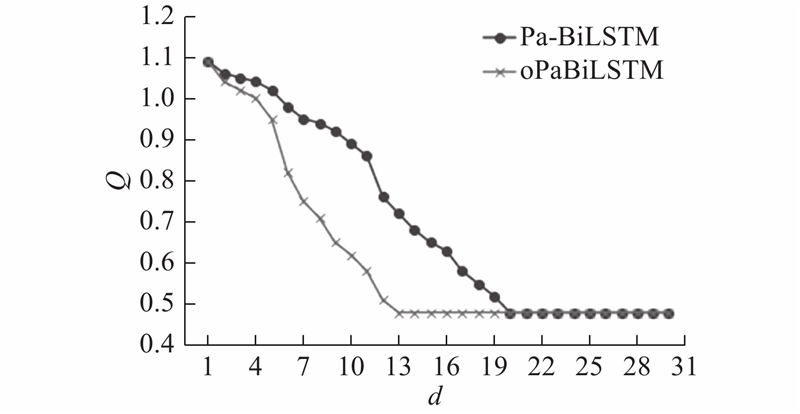

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}