

随着道路和车辆的增加,交通事故越来越多,人们生命财产安全受到较大威胁. 据统计,全球每年交通事故导致大约120万人死亡、5 000万人受伤,交通事故已然成为全球“第一杀手”[1]. 随着科技的发展,准确预测交通事故的发生已成为人们关注的焦点. 及时预测交通事故,可以显著降低财产损失,保障人类生命安全. 基于此,交通事故预测模型的构建受到越来越多学者的关注[2]. 主要预测方法包括传统的预测方法和当前主流的深度学习方法. 传统的预测方法通过单个或者多个数据来预测交通事故,这些方式通常适用于交通事故数据具有明显趋势的情况,有差分整合移动平均自回归模型(autoregressive integrated moving average model,ARIMA)和灰度模型[3-4]. 张艳艳等[5]利用ARIAM建立水上交通事故预测模型;Becker等[6-7]利用灰度模型建立交通事故预测模型. 随着数据科学的蓬勃发展,深度学习方法在解决分类和回归问题中得到广泛应用. 与浅层方法相比[8],深度学习方法在提取数据隐藏的自然结构和固有的抽象特征方面具有更好的性能. 因此,深度学习方法在交通事故预测领域具有广阔的应用前景. 近几年受深度学习的启发,采用深度学习方法如长短期记忆(long short-term memory,LSTM)网络和反向传播神经(back propagation,BP)网络来建立交通事故预测模型. Wang等[9-14]利用神经网络建立交通事故预测模型. 陈海龙等[15]利用BP网络构建预测模型对交通事故进行预测;Zhao等[16-17]利用LSTM网络进行交通事故预测. BP网络和LSTM神经网络能够实现交通事故的预测,但交通事故的影响因素较多,具有较强的不确定性、非线性、动态性和时变特性[18],无论是传统的机器学习方法还是深度学习方法对于预测大规模、非线性动态时变性的数据都较困难.
本研究提出双尺度长短期记忆网络的交通事故量预测模型. 双尺度方程是有效的数据处理方式,LSTM网络是深度学习领域的主流神经网络. 利用LSTM网络的非线性处理能力可以获得较好的预测结果. 本研究的创新之处在于将双尺度方程和LSTM网络在交通事故预测中进行结合,提高预测性能. 研究详细框架如下:1)利用双尺度分解方程将原始交通事故时间序列分解成若干子层,目的是降低原始交通事故数据的非平稳性,为深度学习预测提供更多稳定的子层数据;2)利用LSTM网络完成对低频子层数据的预测;3)利用双尺度重构方程对LSTM网络预测结果进行重构得到最终预测值.
1. 基于双尺度长短期记忆网络的交通事故量预测模型
双尺度长短期记忆(dual scale-LSTM,DS-LSTM)网络的交通事故数量预测模型框架如图1所示. 图中,
图 1
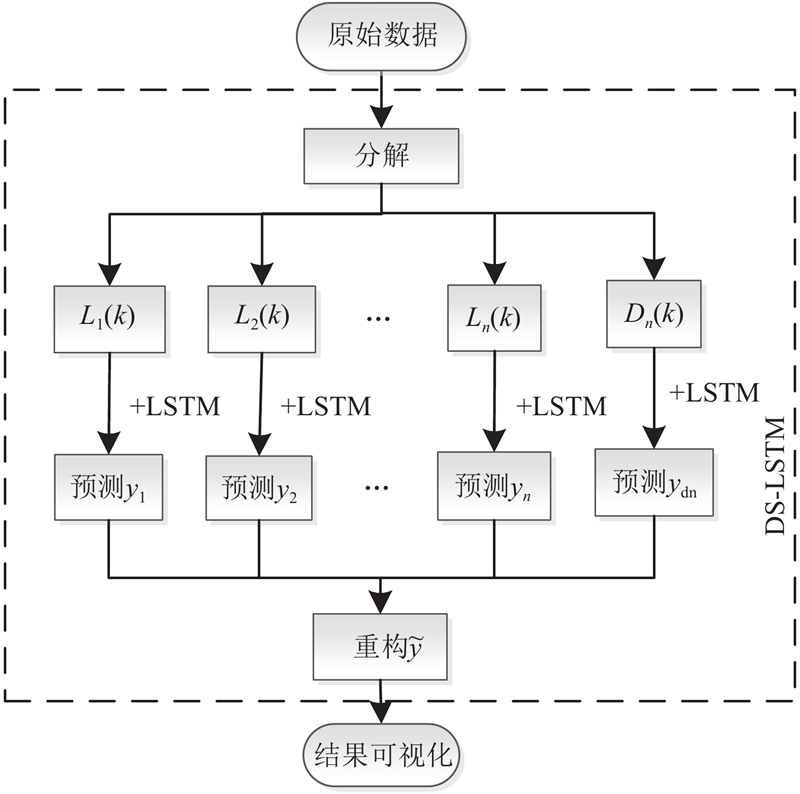
1.1. 双尺度分解与重构
式中:
当
设
设
假设给定离散信号
式中:f(t)为原始数据函数,cj(k)为原始数据上的分解函数,φj,k(t)为分解函数的父波,an为得到的分解序列的权值参数.
定义函数
式中:
根据重构原理,由式(5)、(8)推导出重构方程:
设下列形式的信号
对上式两边同乘
同理可得
最终预测值和权重分别为
式中:下标
1.2. LSTM
LSTM由循环神经网络(recurrent neural network, RNN)优化演变而来,原始RNN的隐藏层只有一个状态,对于短期输入较敏感,若对RNN增加一个状态,使其对长期输入也敏感,则能使得RNN具有长期记忆功能. LSTM主要由输入门、遗忘门、输出门组成,结构如图2所示:
图 2
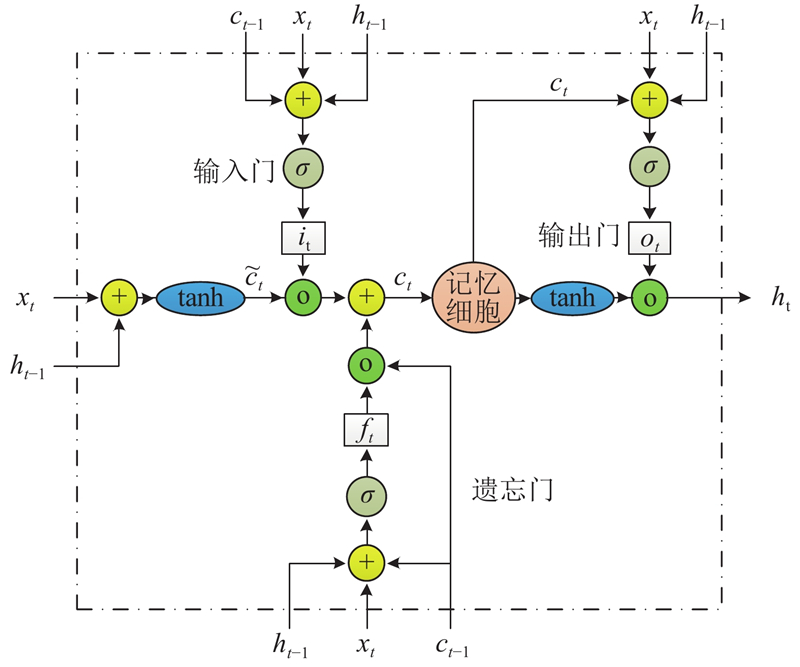
一个记忆块在
式中:
通过式(9)~(11)将原始数据分解成
1.3. 预测性能标准
式中:
2. 实验与分析
2.1. 数据描述
采用Kaggle比赛公开的2011~2015年利兹和UK地区的交通事故数据. 使用2011~2014年数据集训练预测模型,2015年数据集测试预测模型. 2个数据集的数据量和数据复杂度不同,利兹数据集训练数据有10万条,测试数据有4000条;UK数据集训练数据有50万条,测试数据有1万条. 本研究主要使用2个数据集中的事故发生时天气状态、事故发生的道路表面状态和事故发生量等数据项.
2.2. 实验与结论
为了测试DS-LSTM的有效性,须确定该模型的参数—训练次数(epochs). 由于数据的差异性,在达到较好的训练结果时模型参数有一定的差异.
如表1所示,随着epochs的增加,混合模型准确度有所提高,但当达到一定值之后,准确度会下降. 在使用利兹数据集时,当epochs=900时DS-LSTM模型的预测准确度较高;在使用UK数据集时,当epochs=700时DS-LSTM模型预测准确度最高.
表 1 DS-LSTM模型在不同epochs下的准确度
Tab.1
| epochs | ACC/% | |
| 利兹数据集 | UK数据集 | |
| 400 | 74.8891 | 84.8406 |
| 500 | 79.3250 | 85.2503 |
| 600 | 79.9246 | 85.9217 |
| 700 | 81.5287 | 88.1876 |
| 800 | 82.0915 | 88.0292 |
| 900 | 83.2079 | 88.0172 |
| 1000 | 82.2952 | 85.4329 |
2.2.1. 利兹数据集
当epochs=900时,4种交通事故预测模型结果如图3所示. 图中,N为事故量,T为时间月份,左上角小图为1月1日—1月30日的事故发生量的局部放大结果,D为时间日期. 可以看出,DS-LSTM模型预测结果相较于(LSTM、GRU、SAEs)模型更加接近真实值.
图 3
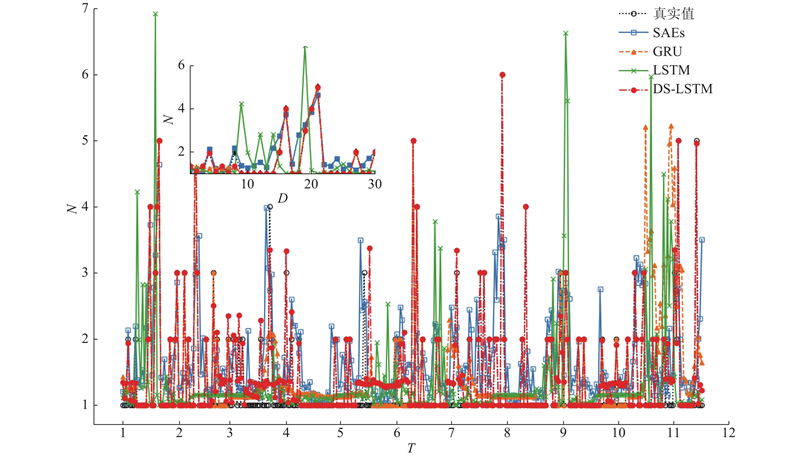
图 3 epochs为900时的事故量(利兹数据集)
Fig.3 Accident number with epochs of 900 (Leeds database)
2.2.2. UK数据集
当epochs=700时,4种交通事故的预测模型结果如图4所示. 图中,左上角小图为1月1日—1月30日事故发生量的局部放大结果. 可以看出,DS-LSTM模型的预测结果相较于其他3个模型(LSTM、GRU、SAEs)更加接近真实值.
图 4
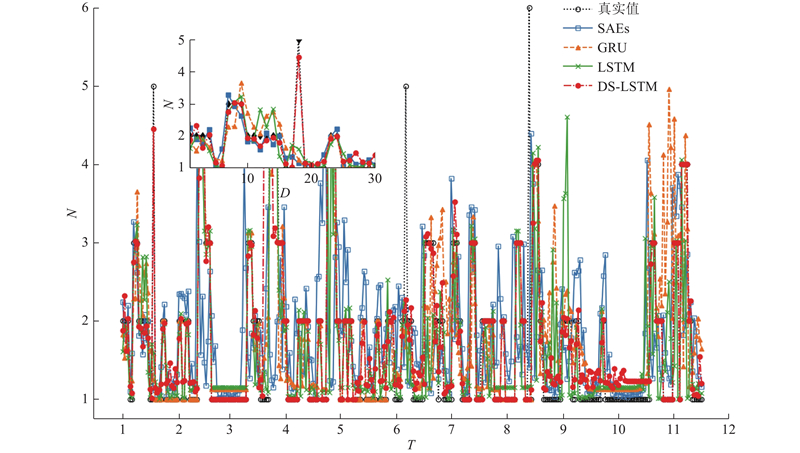
图 4 epochs为700时的事故量(UK数据集)
Fig.4 Accident number with epochs of 700 (UK database)
当根据常用的模型评价标准,达到最优预测模型时,各模型的性能指标如表2所示. 由表1、2可以看出,同一个数据集DS-LSTM的预测模型精度要高于LSTM、GRU和SAEs模型. 例如,当利兹数据集的epochs=900时,预测模型DS-LSTM性能指标相较于LSTM:MAE降低0.1061、MSE降低0.3771、RMSE降低0.3105,可以看出DS-LSTM的预测性能较好,在相同参数下准确度为83.2079%,相较于LSTM提高约6%、相较于GRU提高约38%、相较于SAEs提高约30%;当UK数据集的epochs=700时,预测模型DS-LSTM性能指标相较于LSTM:MAE降低0.3235、MSE降低0.5306、RMSE降低0.4925,可以看出DS-LSTM的预测性能较好,在相同参数下准确度为88.187 0%,相较于LSTM提高约28%,相较于GRU提高约38%,相较于SAEs提高约33%.
表 2 不同数据集下的模型特性
Tab.2
| 模型 | UK,epochs=700 | Leeds,epochs=900 | |||||||
| MAE | MSE | RMSE | ACC/% | MAE | MSE | RMSE | ACC/% | ||
| LSTM | 0.5135 | 0.6161 | 0.7849 | 60.8588 | 0.4288 | 0.5811 | 0.7622 | 76.7608 | |
| GRU | 0.6531 | 1.2837 | 1.1330 | 50.2231 | 1.0072 | 2.2285 | 1.4928 | 45.4190 | |
| SAEs | 0.5872 | 0.8195 | 0.9052 | 55.2421 | 0.8611 | 1.4739 | 1.2140 | 53.3366 | |
| DS-LSTM | 0.1900 | 0.0855 | 0.2924 | 88.1876 | 0.3227 | 0.2040 | 0.4517 | 83.2079 | |
通过以上实验结果得出,在不同epochs情况和不同数据集下,本研究所提出的混合模型DS-LSTM的预测性能相对于其他模型有显著提高,由此证明该模型的有效性和鲁棒性.
3. 结 语
提出新的交通事故量预测模型. 这种预测模型对于道路交通事故有较好的预测效果,利用4种预测模型对2个数据集进行测试. 实验结果表明混合模型DS-LSTM相比LSTM、GRU和SAEs等预测模型,准确率有显著提高.
后续将进一步研究交通数据集的特征提取和处理方法. 比如有效提取事故数据集中影响交通事故的天气、路面状况信息,并利用其他深度学习优化方法提高交通事故预测的准确率;降低本研究提出的混合模型训练时间,提高模型性能.
参考文献
Incidence and trend of road traffic injuries and related deaths in Kuwait: 2000–2009
[J].DOI:10.1016/j.injury.2011.09.023 [本文引用: 1]
Road traffic accident prediction modelling: a literature review
[J].
Application of ARIMA model in forecasting traffic accidents
[J].
Smoothing strategies combined with ARIMA and neural networks to improve the forecasting of traffic accidents
[J].
基于 ARIMA 模型的水上交通事故预测
[J].
Waterborne traffic accident prediction based on ARIMA model
[J].
Grey systems theory time series prediction applied to road traffic safety in Germany
[J].DOI:10.1016/j.ifacol.2016.07.039 [本文引用: 1]
基于灰色马尔科夫模型的交通事故预测研究
[J].
Study on traffic accident prediction based on grey Markov model
[J].
Predicting road traffic accidents using artificial neural network models
[J].
Citywide cellular traffic prediction based on densely connected convolutional neural networks
[J].DOI:10.1109/LCOMM.2018.2841832
Impact of data loss for prediction of traffic flow on an urban road using neural networks
[J].
改进 BP 神经网络在交通事故预测中的研究
[J].
Study on improved BP neural network in traffic accident prediction
[J].
LSTM network: a deep learning approach for short-term traffic forecast
[J].DOI:10.1049/iet-its.2016.0208 [本文引用: 1]
An architecture for emergency event prediction using LSTM recurrent neural networks
[J].DOI:10.1016/j.eswa.2017.12.037 [本文引用: 1]
Severity prediction of traffic accident using an artificial neural network
[J].DOI:10.1002/for.2425 [本文引用: 1]
Fast wavelet transforms and numerical algorithms I
[J].DOI:10.1002/cpa.3160440202 [本文引用: 1]
A theory for multiresolution signal decomposition: the wavelet representation
[J].
Early model of traffic sign reminder based on neural network
[J].DOI:10.12928/telkomnika.v10i4.864 [本文引用: 1]
Root mean square error (RMSE) or mean absolute error (MAE)? : arguments against avoiding RMSE in the literature
[J].DOI:10.5194/gmd-7-1247-2014 [本文引用: 1]
Combining weather condition data to predict traffic flow: a GRU-based deep learning approach
[J].DOI:10.1049/iet-its.2017.0313 [本文引用: 1]
Traffic flow prediction with big data: a deep learning approach
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}