

关键词识别(keyword recognition,KWR)[1]是一种连续语音数据流中的关键词语音信号识别技术,可以在公共安全等领域发挥重要作用. 关键词识别有2个技术难点:1)连续语音数据的语义分割,即语音中的词汇分割;2)对于关键词和非关键词的区分识别.
关键词识别技术发展至今方法层出,技术的难度和复杂度也在不断增加. 初期有基于模板匹配的动态时间规整(dynamic time warping,DTW)[2],该方法的明显缺陷是对于语句的语义分割能力差. 相比简单的模板匹配,汪鹏等[3]给出了基于统计模型的隐马尔可夫模型(hidden Markov model,HMM)的模式识别方法. HMM是一种迭代训练模型,这样的迭代训练可以使建立的识别模型对训练数据集具有很强的适应性; 而且,HMM是一种状态数可调的模型,对动态特性的语音数据可以实现有效建模. 改进的关键词识别模型所基于的隐马尔科夫补白模型(HMM/Filler)[4]在语音识别领域应用广泛,是一种针对关键词识别建立的混合结构模型,混合模型对需要进行识别的关键词建立HMM,对其他非关键词使用Filler模型,同时建立trigram语言模型[5]来确定音节组成的关键词. HMM-MAP在HMM基础上通过最大后验概率(maximum a posteriori estimation,MAP)改进而来,可以在每个HMM状态上进行后验概率估计,从而提升HMM的识别精度. 孙彦楠等[6]提出了基于神经网络的关键词识别方法. 神经网络的可训练性很强,但网络的神经元是固定的,因此神经网络模型对不同音节的关键词处理不佳. 近些年,深度学习循环神经网络(recurrent neural network,RNN)[7]在语音识别方面的效果令人惊叹,但由于RNN模型参数量较大,其对硬件要求过高.
本研究以统计模型HMM/Filler为基础,将神经网络Softmax分类器构建的后验概率图与HMM/Filler进行第一次融合得到Posteriorgram-HMM. 将Posteriorgram-HMM与HMM-MAP进行第二次融合,得到Posteriorgram-HMM-MAP.
1. 后验概率图隐马尔科夫融合模型
通过构建和训练神经网络Softmax分类器,使其输出音节的后验概率图模型,并将所得模型融合到HMM/Filler中,得到后验概率图隐马尔科夫模型(Posteriorgram-HMM),Softmax分类器使HMM/Filler对音节具有分类的能力. Softmax分类器输出的后验概率所构成的后验概率图(Posteriorgram),与HMM的声学模型概率共同作用于模型解码.
1.1. 前端处理与多特征提取
Posteriorgram-HMM使用基于双门限法的语音活动检测(voice activity detection,VAD)[8]对语音数据进行简化,以减少计算量并提升识别效率. 为增强对语音信号的表征,使用多特征数据,选取39维梅尔倒谱系数(Mel-frequency cepstral coefficients,MFCC)特征[9]和4维Pitch特征[10]来丰富语音特征,采用倒谱均值方差归一化(cepstrum mean variance normalization,CMVN)来消除信道差异,以减少噪声. HMM的训练使用原始提取的特征即可,但神经网络的训练需要对原始特征进行预处理,以满足其对数据输入格式的要求.
1.2. 特征矢量等长分段
由于神经网络的输入固定,训练需要固定长度的特征数据矢量,但是关键词的语音数据是不定长度的. 因此,使用文献[11]中的音节分割方法将关键词的特征矢量进行等长处理. 效仿HMM的三输入状态,将43维特征矢量按0.25 ∶ 0.50 ∶ 0.25进行分段,这样的划分可以保证首部与尾部有足够的缓冲并使中间部分保留充足的特征信息. 将划分成后的3段特征矢量进行纵向相接(即在维度上进行叠加),43维特征矢量就变成了原来的3倍(129维),此时横向上特征数据等长,音节的等长分段如图1所示. 神经网络的输入节点数与特征的维度对应,因此神经网络输入层含有129个神经元;而音节的种类对应输入节点数,因此输出层共含有408个神经元.
图 1
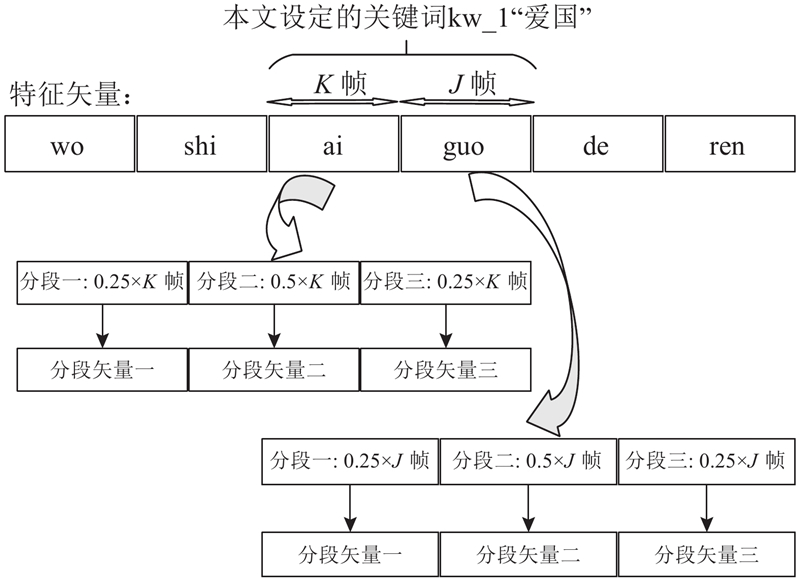
1.3. 评价标准与实验数据
使用识别率作为模型的评价标准,设模型对所有关键词正确识别数为NS,所有关键词的标注总数为NM,则模型综合识别率φ的计算公式为
设模型对某个关键词的正确识别数为 NT,此关键词的标注数量为 NP,则模型对此关键词的识别率ψ的计算公式为
综合识别率为判断模型对所有关键词表现的指标,关键词识别率则是判断模型对单个关键词表现的指标. 本研究使用清华大学中文语音数据集THCHS-30完成关键词识别模型的训练和测试,首先挑选部分词汇作为模型设定的关键词. 训练集包含2 409个已标注的关键词,测试集包含587个已标注关键词. 实验选取的关键词列表如表1所示,其中,Ntrain为关键词训练样本数,Ntest为关键词测试样本数.
表 1 实验选取的关键词列表
Tab.1
| 编号 | 关键词 | 音节 | Ntrain | Ntest |
| kw_1 | 爱国 | ai guo | 51 | 12 |
| kw_2 | 爱情 | ai qing | 42 | 11 |
| kw_3 | 安全 | an quan | 30 | 8 |
| kw_4 | 八十 | ba shi | 62 | 14 |
| kw_5 | 白天 | bai tian | 56 | 17 |
| kw_6 | 彬彬有礼 | bin bin you li | 18 | 4 |
| kw_7 | 采访 | cai fang | 70 | 21 |
| kw_8 | 藏起来 | cang qi lai | 46 | 10 |
| kw_9 | 差别 | cha bie | 67 | 19 |
| kw_10 | 长江 | chang jiang | 85 | 24 |
| kw_11 | 成功 | cheng gong | 97 | 29 |
| kw_12 | 吃饭 | chi fan | 175 | 49 |
| kw_13 | 大多数 | da duo shu | 95 | 24 |
| kw_14 | 大夫 | dai fu | 39 | 10 |
| kw_15 | 大海 | dai hai | 134 | 31 |
| kw_16 | 单词 | dan ci | 63 | 14 |
| kw_17 | 返回 | fan hui | 98 | 19 |
| kw_18 | 犯罪分子 | fan zui fen zi | 55 | 14 |
| kw_19 | 父母亲 | fu mu qin | 93 | 32 |
| kw_20 | 改变 | gai bian | 183 | 46 |
| kw_21 | 科学 | ke xue | 86 | 18 |
| kw_22 | 老师 | lao shi | 112 | 26 |
| kw_23 | 乱七八糟 | luan qi ba zao | 63 | 17 |
| kw_24 | 每天 | mei tian | 152 | 30 |
| kw_25 | 平均 | ping jun | 161 | 30 |
| kw_26 | 四川省 | si chuan sheng | 43 | 9 |
| kw_27 | 兴趣 | xing qu | 76 | 11 |
| kw_28 | 眼睛 | yan jing | 62 | 15 |
| kw_29 | 找不到 | zhao bu dao | 95 | 23 |
1.4. Softmax分类器与HMM/Filler融合
神经网络结合Softmax[12]是一种解决多分类问题的方式. Softmax函数表达式为
式中:z为一个样本的特征向量,j为类别,K为类别总数,
针对汉语中的408个音节建立Softmax分类器,神经网络结合Softmax分类器的模型结构如图2所示. 图中,输入神经元个数I =129,2个隐含层H1和H2各包含200个神经元,原始输出层O含有408个输出,经过Softmax层分类后得到最终在每类音节上的概率大小,记为Pc1~Pc408.
图 2
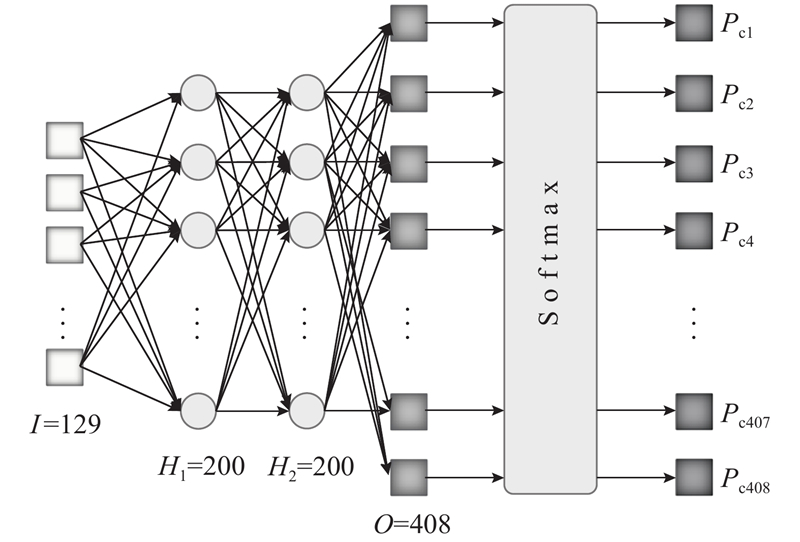
图 2 408个音节的Softmax分类器模型示意图
Fig.2 Diagram of Softmax classifier model for 408 syllables
使用Sigmoid函数作为全连接神经网络激活函数,目标函数为所有输出节点的误差平方:
式中:
将Softmax分类器输出的条件概率的最大值作为后验概率Pmax,与HMM中的声学模型概率Pacou_1共同作用于Viterbi解码[14]. 通过概率融合的方式将后验概率和声学模型概率进行融合,得到融合模型的最终解码概率Pdeco_1. 概率融合公式如下.
式中:Pdeco_1就是作用于Posteriorgram-HMM融合模型的解码概率,λ为调整Softmax分类器对融合解码作用程度的融合参数.
图 3
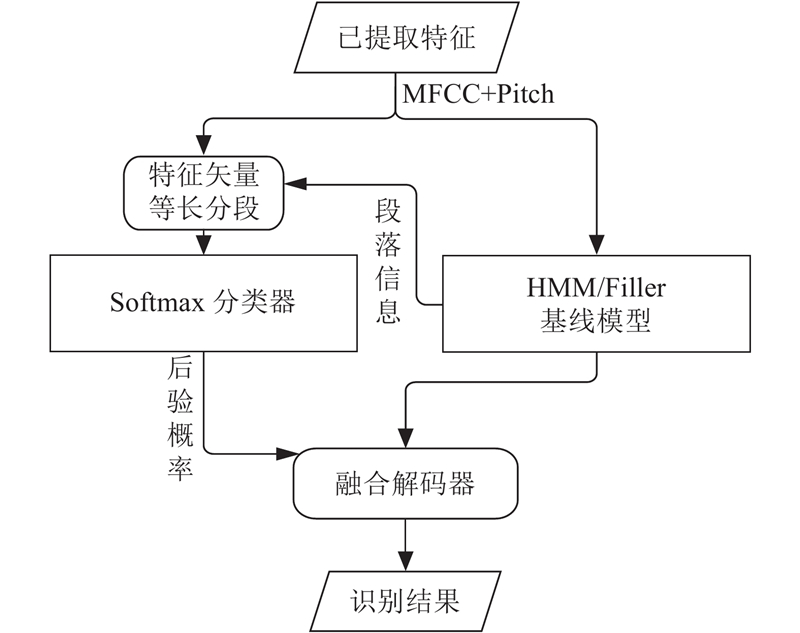
图 4
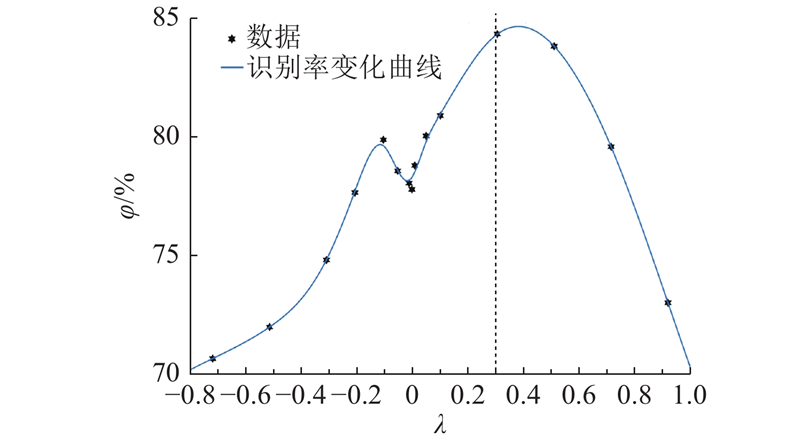
图 4 融合参数 λ 对综合识别率影响的拟合曲线
Fig.4 Fitting curve for effect of fusion parameter λ on comprehensive recognition rate
2. 最大后验概率图隐马尔科夫模型
关键词识别的语音标注样本是语音数据流中的关键词数据,而这些关键词数据在连续的语音数据中是有限的,因此,HMM/Filler的训练数据较少。训练数据的不足会导致模型的欠拟合,从而影响模型的识别率.
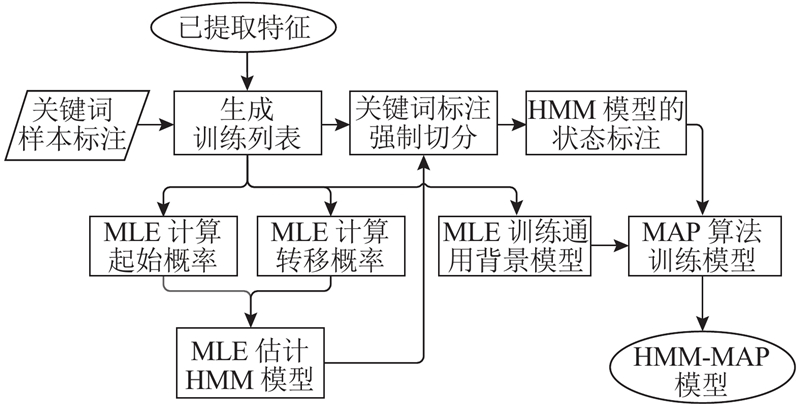
Gauvain等[15]针对模型训练数据不足的问题提出了一种由最大后验概率(Maximum a posteriori estimation,MAP)改进的HMM,即HMM-MAP. HMM-MAP相对于HMM/Filler的不同就是,在构建HMM时使用MAP来代替先前使用的极大似然估计(maximum likelihood estimate,MLE),而对于非关键词模型依然使用Filler模型. 在实际模型训练中,由于每个关键词的音节长度不同,即HMM的先验结构未知,采用MAP处理的部分只能是关键词HMM每个状态上的高斯混合模型(Gaussian mixture model,GMM)[16]分布,而对于HMM中的起始概率和转移概率则继续采用极大似然估计. 在对GMM进行MAP过程时,由于数据库中只对每个关键词样本进行了标注,需要使用强制切分(force align,FA)调整标注与语音数据的位置,将标注对齐到样本的每个状态上,得到每个状态上的训练样本. 之后,对状态上的GMM先验分布进行估计. 在训练高斯混合模型时,首先训练得到一个混合度很高的通用背景模型(universal background model,UBM),然后根据每个状态上的训练样本数据来选择最近的前N个高斯模型,组成一个高斯混合模型,作为该状态上的先验分布.
已知每个状态上的GMM的训练数据和先验分布,使用MAP算法估计GMM参数的计算公式如下:
式中:xt为一个训练样本,i为训练样本上的一个状态,ωi为此状态上的样本波长,Ni(xt)为样本xt 上i状态出现的条件概率, M为训练样本总数,m为训练样本序号,T为样本周期,αi为估值参数,γ为关键词声纹参数.
参考式(4)~(6)中GMM的参数估计方法,HMM-MAP使用HMM状态标注对HMM中的参数进行先验估计,得到HMM-MAP. HMM-MAP训练流程如图5所示.
图 5
将HMM-MAP与第一次融合后的Posteriorgram-HMM进行第二次融合,得到Posteriorgram-HMM-MAP. 第二次融合使用的2个基线模型都具有独立进行关键词识别的能力,为协调2个模型的融合程度,引入参数β作为融合参数来调整2个模型对于融合解码的作用程度,所提出的概率融合公式为
式中:Pacou_2为HMM-MAP中模型输出的声学模型的解码概率,Pdeco_2为Posteriorgram-HMM-MAP的融合解码概率.
设定β的值分别为0,0.1,…,0.9,其他模型参数不变,得到β对应的 Posteriorgram-HMM-MAP综合识别率,使用Matlab绘图工具进行曲线拟合,得到拟合曲线如图6所示. 可知,在β从0增加到0.4这个过程中,即当HMM-MAP的作用程度开始提升时,模型的识别率开始上升,这样的双基线模型的识别率相较于单基线模型有所提升;但是当β从0.4增加到0.9时,Posteriorgram-HMM-MAP的识别率开始大幅下降,这是因为Posteriorgram-HMM的作用程度下降,模型由HMM-MAP主导,而HMM-MAP没有与Softmax音节分类器融合,故模型识别率开始下降. 综上,Posteriorgram-HMM-MAP在融合参数β为0.4时达到最佳,Posteriorgram-HMM-MAP框图如图7所示.
图 6
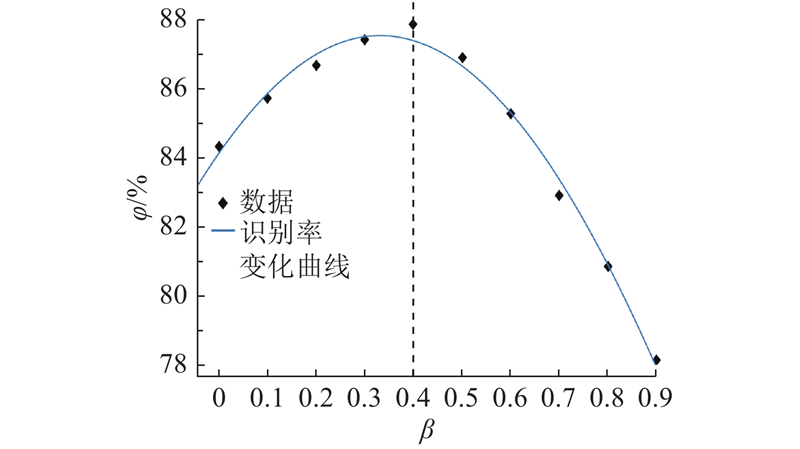
图 6 融合参数 β 对综合识别率影响的拟合曲线
Fig.6 Fitting curve for effect of fusion parameter β on comprehensive recognition rate
图 7
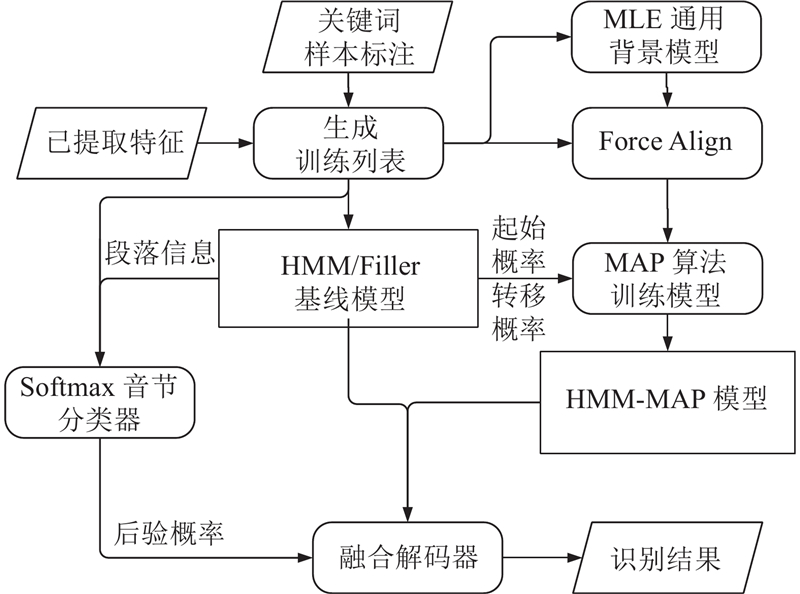
3. 实验分析
首先对Posteriorgram-HMM进行训练,设定Filler模型的高斯混合度为512,HMM中每个状态的高斯数为8,一次融合参数λ=0.3,二次融合参数β=0.4,使用THCHS-30训练集进行训练;然后使用训练模型对测试集进行关键词识别,得到的Posteriorgram-HMM和Posteriorgram-HMM-MAP的关键词识别率如表2所示.
表 2 不同模型的关键词识别率对比
Tab.2
| 编号 | Posteriorgram-HMM | Posteriorgram-HMM-MAP | |||
| NT | ψ /% | NT | ψ /% | ||
| kw_1 | 9 | 84.31 | 11 | 91.67 | |
| kw_2 | 8 | 78.57 | 10 | 90.90 | |
| kw_3 | 6 | 75.00 | 6 | 75.00 | |
| kw_4 | 12 | 85.71 | 12 | 85.71 | |
| kw_5 | 14 | 82.14 | 15 | 88.24 | |
| kw_6 | 4 | 100.00 | 4 | 100.00 | |
| kw_7 | 18 | 85.71 | 18 | 85.71 | |
| kw_8 | 9 | 90.00 | 10 | 100.00 | |
| kw_9 | 15 | 78.95 | 15 | 78.95 | |
| kw_10 | 20 | 83.33 | 22 | 91.67 | |
| kw_11 | 23 | 79.31 | 24 | 82.76 | |
| kw_12 | 44 | 89.79 | 42 | 85.71 | |
| kw_13 | 20 | 84.21 | 21 | 87.50 | |
| kw_14 | 8 | 80.00 | 10 | 100.00 | |
| kw_15 | 28 | 90.30 | 28 | 90.32 | |
| kw_16 | 11 | 78.57 | 13 | 92.86 | |
| kw_17 | 15 | 78.95 | 16 | 84.21 | |
| kw_18 | 12 | 90.90 | 13 | 92.86 | |
| kw_19 | 26 | 81.25 | 29 | 90.62 | |
| kw_20 | 43 | 94.54 | 41 | 89.13 | |
| kw_21 | 14 | 77.78 | 16 | 88.89 | |
| kw_22 | 22 | 84.62 | 23 | 88.46 | |
| kw_23 | 14 | 82.35 | 16 | 94.12 | |
| kw_24 | 26 | 86.67 | 25 | 83.33 | |
| kw_25 | 25 | 83.33 | 25 | 83.33 | |
| kw_26 | 8 | 90.69 | 9 | 100.00 | |
| kw_27 | 9 | 81.81 | 9 | 81.81 | |
| kw_28 | 12 | 80.00 | 13 | 86.67 | |
| kw_29 | 19 | 82.61 | 20 | 86.96 | |
1)Posteriorgram-HMM-MAP的综合识别率达87.88%,Posteriorgram-HMM的综合识别率达84.33%,而HMM/Filler的综合识别率为77.59%. 根据模型综合识别率的对比,二次融合得到的Posteriorgram-HMM-MAP在训练数据较少的情况下具有很好的识别效果,Posteriorgram-HMM在与Softmax音节分类器融合后,其识别效果优于HMM/Filler.
2)表2中训练样本较少的关键词(如:kw_1、kw_2、kw_3、kw_14)在训练时由于加入了HMM-MAP增强训练,相较于一次融合模型,对这些关键词的识别率均提升了2%~10%.
4. 结 语
本文提出了一种由神经网络Softmax分类器输出的后验概率图和HMM-MAP二次融合HMM/Filler的Posteriorgram-HMM-MAP关键词识别模型,实验结果表明:当一次融合参数λ=0.3且二次融合参数β=0.4时,Posteriorgram-HMM-MAP的识别效果最佳,模型综合识别率可达87.88%,相比一次融合的Posteriorgram-HMM提升了3.55%,相比HMM/Filler提升了10.29%.
本文所提出的改进方法对基于统计模型的关键词识别具有一定借鉴价值. 由于模型对Softmax分类器和HMM的训练是分开的,训练过程较为繁琐,今后的识别模型改进可使用其他分类器来提升训练速度和识别率.
参考文献
基于DTW的语音关键词检出
[J].
Spoken term detection based on DTW
[J].
基于离散HMM的非特定人关键词提取语音识别系统
[J].
Discrete HMM based speaker independent keyword spotting speech recognition system
[J].
基于深度神经网络的关键词识别系统
[J].
Keyword recognition system based on deep neural network
[J].
基于双门限算法的端点检测改进研究
[J].DOI:10.3969/j.issn.1672-9722.2017.11.030 [本文引用: 1]
Research and improvement on endpoint detection based on dual-threshold algorithm
[J].DOI:10.3969/j.issn.1672-9722.2017.11.030 [本文引用: 1]
基于改进MFCC特征的语音识别算法
[J].
A speech recognition algorithm based on improved MFCC
[J].
Pitch-normalized acoustic features for robust children ’s speech recognition
[J].DOI:10.1109/LSP.2017.2705085 [本文引用: 1]
Text classification based on deep belief network and softmax regression
[J].
基于Viterbi改进算法的汉语数码语音识别模型
[J].
The research on improved Viterbi algorithm for Chinese digital speech recognition system
[J].
Maximum a posteriori estimation for multivariate gaussian mixture observations of Markov chains
[J].DOI:10.1109/89.279278 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}