

车辆运动轨迹的预测对于无人驾驶车辆的导航规划有非常重要的意义,比如:提前发现可能产生的碰撞,从而采取合适策略避免,增强无人驾驶车辆的安全性. 相较行人轨迹预测而言,车辆轨迹预测对于无人驾驶的应用场景更加实用,如高速路上的无人驾驶车辆避障、复杂交通路口的车辆通行等,并且行人的速度一般较慢,预测其未来轨迹可以允许的误差范围相对较大,而车辆速度一般较快,更加准确地预测其短期内的未来轨迹显得尤为重要.
车辆轨迹预测是指根据给定车辆的一段历史轨迹,预测其将来可能的轨迹. 传统的轨迹预测方式包括卡尔曼滤波器、马尔科夫链预测等,这类预测方法往往不能充分地利用历史轨迹信息,并且有一定的假设条件. 如线性卡尔曼滤波器仅根据当前时刻的状态不断地进行迭代,虽然预测速度很快,但长时间预测时精度不高. 基于社会力模型的方法借鉴引力势场法[1-2],根据吸引力和排斥力的方式对个体之间的关系进行建模;模型假定最终的轨迹终点会对个体产生吸引力,并使其往目标方向移动,而其他个体的排斥力则会防止碰撞的发生. 这类方法简单直观,但往往会陷入局部最优点,并且吸引力和排斥力的大小和方向也是通过手工构造的函数来计算,因而难以对复杂的现实环境进行建模. 由Hochreiter等[3]提出的长短期时间记忆网络LSTM可以更加有效地处理时间序列的问题,现有大多数较好的轨迹预测算法都是基于LSTM的改进. Social LSTM是由Alahi等[4]于2016年提出的用于行人轨迹预测的网络,通过将邻近行人的隐层信息进行带有空间方位的池化,引入周围行人对自身轨迹的影响,该网络效果显著,已经成为许多算法的基准模型. Xu等[5]则对Social LSTM中提出的池化层进行改进,用环形区域代替方形网格进行池化,使得池化层更加合理. Deo等[6]认为卷积和池化能保持预测空间的局部特征,因而使用卷积层和池化层替代全连接层提取周围个体的相关信息,并成功将其应用在车辆轨迹预测中,取得了较好的效果. 由Gupta等[7]于2018年提出的Social GAN则引入生成对抗网络来得到更加真实的预测轨迹. 此外还有考虑到环境静态障碍物的轨迹预测模型,如Scene LSTM[8]、SS LSTM[9],这类方法一般应用在固定的场景中,通过神经网络提取图像中静态障碍物的信息,在轨迹预测时避开这些区域. 在考虑邻近车辆的影响时,也可以使用注意力机制来选择较为重要的邻居车辆信息,并非仅仅通过距离远近来判断邻居车辆的重要性. 因为在实际环境中某一个体的决策并不仅仅与其空间位置有关,还与其运动速度、运动方向、运动意图有关. 如Fernando等[10]通过“软”和“硬”注意力机制来考虑周围个体信息,通过计算其隐层相似度来决定该邻居的重要性.
本文基于注意力机制,通过计算周围车辆历史轨迹隐层和目标车辆历史轨迹隐层的余弦相似度来获取周围车辆对目标车辆运动的影响,给邻居车辆赋予不同的权重,增加关于邻居车辆的全局特征信息. 此外还对传统的Encoder-Decoder框架进行改进,引入针对历史轨迹的注意力机制,使得每一时刻的输出都能考虑到与其最相关的历史轨迹点,从而提升轨迹预测的精度.本研究首先介绍相关的基础算法,并对提出的改进模型进行介绍,将改进算法和其他经典算法进行实验对比分析,并进行总结.
1. 相关算法介绍
1.1. Social Pooling和Social LSTM介绍
Alahi等[4]提出了Social LSTM,该算法的创新点在于对周围邻居信息的利用. 通过对周围个体进行网格化的拼接,进行一种保留了空间信息的池化,将个体周围的邻居信息纳入到当前轨迹预测中来. 这种做法极大地提升了轨迹预测的效果,详细做法如图1所示:在构建训练数据集的时候,对每个个体的周围邻居进行一种带有空间位置信息的排列. 假定图1中黑色点为需要预测轨迹的目标,其余的点为其周围邻居. 以框内黑点为中心,选取一定范围内的邻居进行考虑,如图1(a)中的三角形Q1、方块Q2和多边形Q3,而点Q4因为距离太远而不予考虑. 将目标的周围环境按照方位划分为4份,每一个区域里面的邻居按照距离远近排列,如图1(b)所示;将每个区域按照一定顺序(如:顺时针)进行排列,如图1(c)所示,即可组成带有空间方位信息的训练数据集. Social LSTM的网络结构如图2所示,将经过Social Pooling生成的数据集通过编码层LSTM网络提取隐藏层信息,然后将信息通过全连接层映射到固定的向量长度,并将其与目标本身通过编码层LSTM网络提取的隐层信息进行合并,最后输入到解码器对应的LSTM网络进行循环预测.
图 1
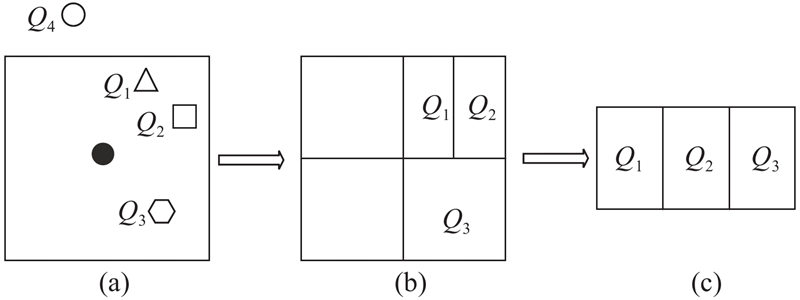
图 2
1.2. Convolutional Social LSTM介绍
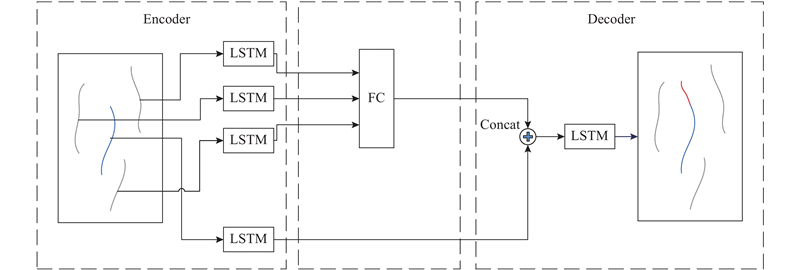
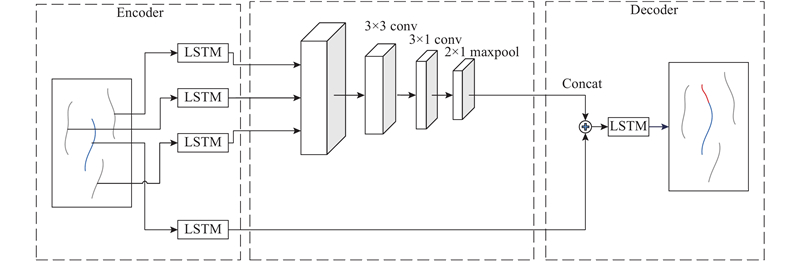
Social LSTM将所有邻居车辆的位置信息通过划分空间网格进行拼接构成数据集,然后使用全连接层来提取邻居信息. Deo[6]等认为这样做会打乱邻居车辆之间的相对位置信息,使得模型在测试集上的泛化能力降低. 为了解决该缺陷,使用卷积层和池化层来提取邻居信息:卷积层能提取邻居车辆的局部特征信息,保留了空间的相对位置不变形;而池化层则能进一步保持特征局部平移不变形,从而增加模型在测试集上的泛化能力,网络结构如图3所示. 使用编码器中的LSTM网络对目标车和邻居车的历史轨迹提取隐层特征,然后使用卷积层和池化层对邻居车辆的隐层特征进行特征提取,得到邻居车辆的局部空间信息特征,再将其与目标车辆本身的隐层信息进行合并,最后输入到解码器中的LSTM网络中进行轨迹预测.
图 3
2. 基于注意力机制的车辆轨迹预测模型
2.1. 数据预处理
首先给出某车辆的一段历史轨迹:
式中:
目标是预测该车辆未来一段时刻的轨迹:
式中:
在进行实际网络训练时,需要对训练数据进行预处理,将预测车辆的真实位置转化为预测相对车辆当前位置
对于目标车辆的历史轨迹:
对于目标车辆的未来轨迹:
式中:
对于目标车辆的周围邻居:
式中:
对于网络预测得到的输出则需要将其恢复为真实值,乘上相应的归一化系数并转化为实际坐标值:
式中:
2.2. 基于注意力机制的轨迹预测模型
图 4
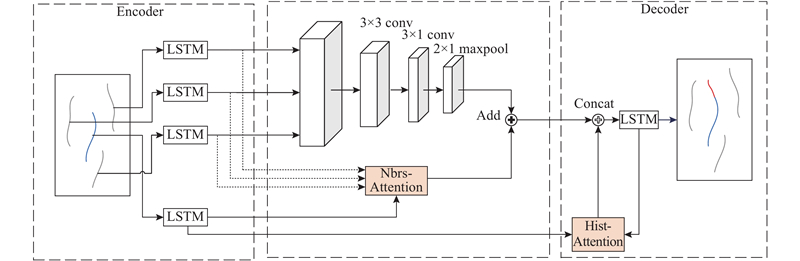
图 4 基于注意力机制的轨迹预测模型
Fig.4 Trajectory prediction model based on attention mechanism
2.2.1. 编码器模块
编码器由全连接层和LSTM单元组成,将二维空间的车辆轨迹点
式中:FC为全连接层映射函数,LSTM为网络映射函数,
2.2.2. 注意力卷积池化模块
算法Social LSTM中采用的全连接层更多的是用于提取整体数据的信息,而Convolutional Social LSTM中采用的卷积池化层更多的是用于提取局部特征的信息,两者都不够全面,并且都未考虑到车辆之间的差异性. 因而本文提出“Nbrs-Attention”模块,采用注意力机制对邻居车辆信息的重要性进行打分;选取所有邻居车辆的历史隐层和目标车辆的历史隐层进行相似度计算;将相似度作为数值掩码,对所有邻居车辆的隐层加权求和,并将其融入由卷积池化提取的车辆局部特征信息,作为完整的邻居车辆信息. 具体过程如下.
由第2.2.1节中编码器可以得到某条轨迹对应的历史隐层:
目标车辆所有邻居的历史隐层可表示为
式中:
将邻居车辆的隐层加权求和,并将得到的值与通过卷积池化层提取得到的邻居车辆的空间信息相加作为完整的邻居信息,如下所示:
式中:
2.2.3. 解码器模块
解码器模块采用LSTM作为基础结构,并引入“Hist-Attention”模块,采用图2所示的改进后的Encoder-Decoder框架来对输出值进行预测. 目标车辆的历史隐层为
由于都是同一车辆的运动信息,直接采用点积计算向量相似度,再由softmax归一化,作为向量权重,加权求和即可得到此刻的中间编码特征
联合式(11)中提取得到的邻居信息
式中:
2.3. 模型损失函数
2.3.1. 负对数似然损失
本文借鉴Graves等[11]提出的观点,用二元高斯分布来拟合输出坐标
式中:
根据极大似然估计,LSTM模型的参数可以通过最小化负对数概率损失来求得:
根据混合高斯分布可以计算概率分布:
式中:
式中:
2.3.2. 均方误差损失
计算预测轨迹和真实轨迹之间的均方误差作为损失函数. 为了防止数值取值太大使得网络训练时只关注到变化较快、数值较大的车辆轨迹,在训练期间直接使用网络预测的输出来对均方误差进行计算,即采用式(15)中预测的
3. 实验结果对比
3.1. 数据集介绍
NGSIM(Next Generation Simulation)是美国联邦公路管理局(FHWA)于2000年发起的模拟计划,该计划收集了大量现实世界的车辆轨迹数据,意在支持交通场景的仿真建模. 本研究采用NGSIM提供的US101[12]和I80[13]两个数据集来进行实验. US101是加利福利亚州洛杉矶的好莱坞高速公路,采集数据的研究区域长度约为640 m,整个区域由5条主线通道组成,8个同步数码摄像机安装在路边36层楼的顶部记录通经过该区域的车辆. I80是加利福利亚州旧金山海湾区域的一条公路,采集数据的研究区域约为500 m,区域由6条高速公路车道组成,包括1条高占用车辆(HOV)车道,7个同步数码摄像机安装在路边30层楼的顶部记录经过该区域的车辆.
每个数据集都包括高速公路上一段时间内过往所有车辆的轨迹,数据集采样频率为10 Hz,每个数据集长为45 min. 数据集分为3段,每段15 min,包括稀疏、中等稠密和稠密等3种交通状况. 数据集提供了车辆的世界坐标、速度和车道信息. 实验时将2个数据集合并起来作为一个整体进行训练和测试,选取每8 s的轨迹片段作为一个训练样本,其中将前3 s数据作为历史轨迹数据,后5 s数据作为未来轨迹数据. 将数据集按照7∶1∶2的比例拆分为训练集、验证集和测试集.
3.2. 模型训练细节
实验时为了降低训练复杂度,需要对样本的历史轨迹和将来轨迹进行降采样. 原始数据集中采样频率为10 Hz,每秒包括10个点,在实验时每隔0.2 s选取一个点保留,最终一个样本包括3 s共16个点的历史轨迹和5 s共25个点的未来轨迹. 实验在GTX1080 Ti显卡上进行训练,训练时使用ADAM对神经网络进行优化,学习率设定为0.001,Batch 大小取为128,参数在所有实验中都保持不变. 实验时为了加速训练,在“Hist Attention”模块中并没有对每个未来轨迹的点都和历史轨迹作注意力机制的运算,而是每隔一段时间进行一次计算,该间隔时间取为1 s. 实验时分段采用均方误差损失和负对数似然损失进行训练,即先使用均方误差损失训练,达到一定的迭代数量之后再换用负对数似然损失进行训练.
3.3. 实验结果对比
为了验证本文方法改进的效果,采用几种经典的轨迹预测算法作为对比参照,列举如下.
1)KF:采用线性卡尔曼滤波预测轨迹,不需要训练.
2)LSTM:采用基于Encoder-Decoder框架的LSTM进行轨迹预测.
3)Fc_pool:表示Social LSTM,采用全连接层来提取邻居信息.
4)Conv_pool:表示Convolution Social LSTM,采用卷积和池化提取邻居信息.
5)Nbrs_conv:基于Conv_pool网络,引入“Nbrs-Attention”模块改进原始的邻居信息提取方式.
6)Hist_Nbrs_conv:在Nbrs_conv基础上,引入“Hist-Attention”模块,在预测轨迹时计算解码器隐层和历史轨迹隐层的相似度,为每一时刻的预测选出最相关的历史节点.
3.3.1. 模型整体偏差对比
实验时采用均方误差(MSE)进行评估,对各模型5 s的预测轨迹作对比,每隔1 s进行一次结果统计,采样频率为每秒5个点,最后计算25个点的平均均方误差
表 1 各模型轨迹预测均方误差对比
Tab.1
| 预测算法 | 1 s | 2 s | 3 s | 4 s | 5 s | |
| KF | 1.936 | 3.860 | 5.779 | 7.704 | 9.648 | 5.013 |
| LSTM | 0.698 | 1.691 | 2.981 | 4.567 | 6.465 | 2.741 |
| Fc_pool | 0.673 | 1.518 | 2.584 | 3.910 | 5.524 | 2.382 |
| Conv_pool | 0.661 | 1.472 | 2.509 | 3.821 | 5.406 | 2.324 |
| Nbrs_conv | 0.635 | 1.448 | 2.470 | 3.751 | 5.306 | 2.280 |
| Hist_Nbrs_conv | 0.629 | 1.432 | 2.454 | 3.730 | 5.265 | 2.263 |
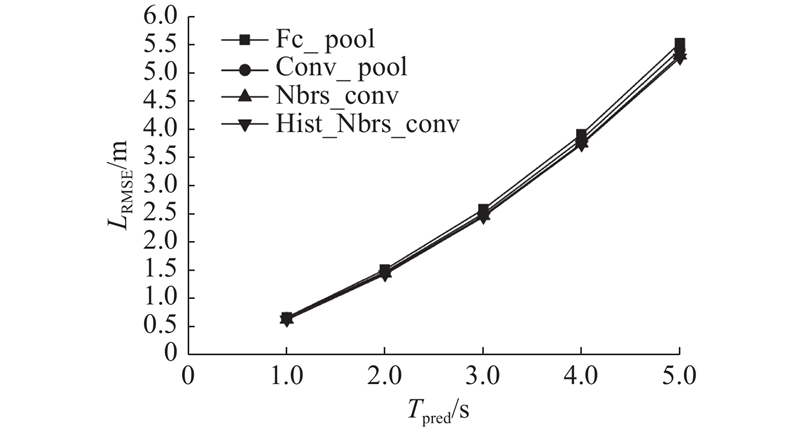
从表1中可见,随着模型的改进,预测轨迹相对真实轨迹的偏离程度在不断缩减,单点误差和整体误差都在不断变小. 线性卡尔曼滤波因只考虑了当前点的信息而无法满足复杂的场景变化,结果较差. LSTM使用了历史轨迹信息,能较好地捕捉到时序的变化,结果相比卡尔曼滤波大有提升. Fc_pool基于带有网格方位的训练数据,融入了周围邻居的信息,提升了预测效果. Conv_pool将Fc_pool中的全连接层替换为卷积层和池化层,更加充分地利用了周围邻居的信息,效果进一步提升. 本文提出的Nbrs_conv在Conv_pool的基础上引入注意力机制,获取周围车辆的重要性,在原始特征中增加了全局的车辆特征,使得预测轨迹的偏差更小. Hist_Nbrs_conv对传统的Encoder-Decoder框架进行改进,引入关于目标车辆历史轨迹的注意力机制,使得每一次预测不再是使用相同的中间编码,而是使用与当前时刻最相关的历史节点信息,使得轨迹预测更加准确. 图5对表1中的部分数据进行了可视化,可以看到改进后的算法误差更小,轨迹更加准确.
图 5
3.3.2. 轨迹预测实际结果对比
选取Conv_pool和Hist_Nbrs_conv某次轨迹预测的结果进行展示如图6所示. 其中,w为路宽,l为路长. 图中展示了同向3个车道的轨迹预测实例. 其中标有A的车辆为目标车辆,其他黑色车辆为其邻居. 以当前时刻目标车辆的位置为原点,各邻居车辆3 s的历史轨迹如黑色点线所示,目标车辆3 s的历史轨迹和5 s的真实将来轨迹如黑色实线所示,黑色虚线则为经过模型预测得到的目标车辆未来5 s的轨迹. 可以看到,本文提出的Hist_Nbrs_conv改进算法确实能得到比原始的Conv_pool更加精准的轨迹.
图 6
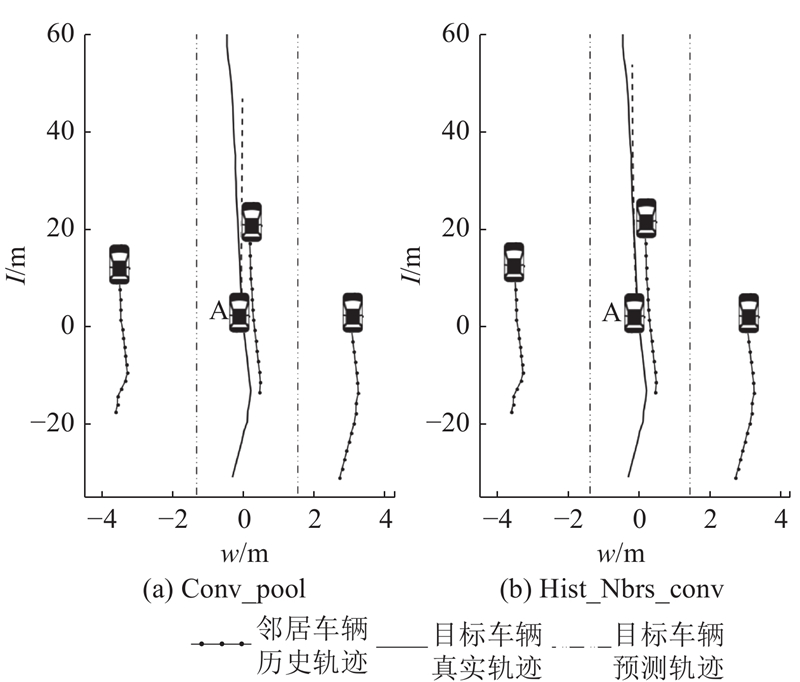
图 6 真实数据集上模型轨迹预测结果对比
Fig.6 Comparison of model trajectory prediction results on real data sets
3.3.3. 模型耗时对比
轨迹预测对实时性要求较高,本文测试了多个模型的运行速度,按照预测一个批次约128条轨迹的平均耗时来统计,其中卡尔曼滤波耗时0.002 s,LSTM耗时0.06 s,Fc_pool耗时0.064 s,Fc_pool耗时0.066 s,Nbrs_conv耗时0.067 s,而Hist_Nbrs_conv耗时0.083 s. 由此可知,传统的卡尔曼滤波虽然精度欠佳,但其预测速度是最快的,而且不需要进行离线训练. 随着模型的改进,预测时间不断增加,其中Fc_pool、Conv_pool和Nbrs_conv几种方法的预测时间几乎一致,差别在毫秒级别. 相对而言,Hist_Nbrs_conv则较为耗时,原因在于“Hist-Attention”模块实现时需要每隔1 s对所有历史数据计算一次相关性,以此重新构造中间隐层向量,但其预测时耗仍然满足实时性的要求.
3.4. 注意力权重探讨
为了进一步探究车辆轨迹预测模型的效果,对模型注意力机制的权重分布进行定性和定量分析.
3.4.1. “Nbrs-Attention”权重分布
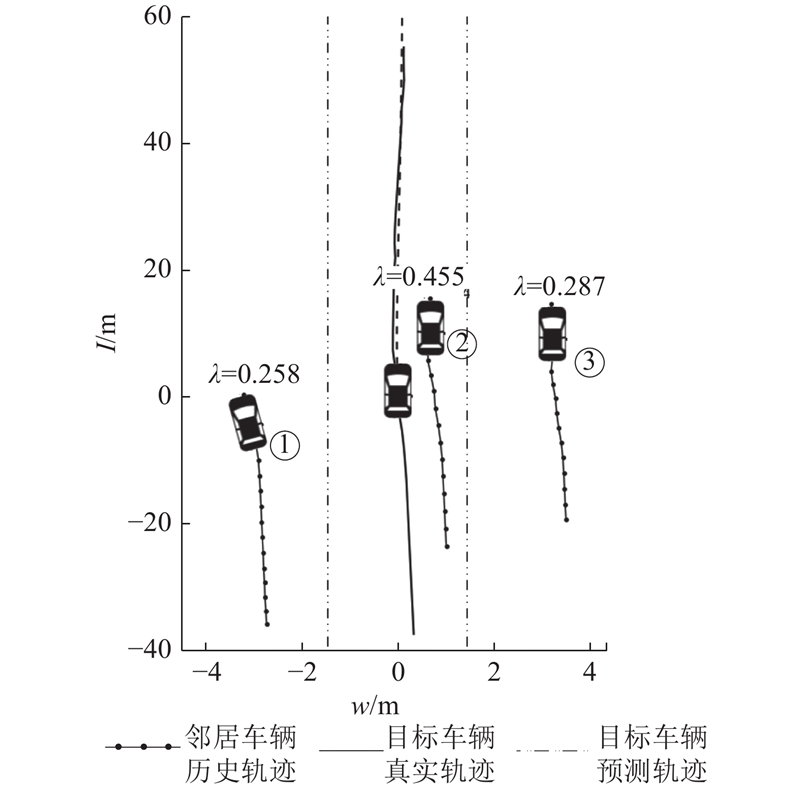
如图7所示为采用Hist_Nbrs_conv进行轨迹预测得到的结果,轨迹上的数字为周围邻居车辆对目标车辆的注意力权重,以λ表示,权重总和为1. 其中2号车辆权重为0.455,由图可知2号车辆距离目标车辆最近且为同车道,其对本车的影响也最大,符合直观感觉. 而1号和3号由于是在相邻车道,并且1号车辆有远离目标车辆的迹象,因而3号车辆的权重为0.287,稍大于1号车辆的注意力权重0.258. 若不采用注意力机制而直接对邻居车辆的信息进行提取,则会将所有邻居的权重视为等同,没有利用到车辆之间潜在的相关性,这对于轨迹预测而言是不利的. 本文通过采用车辆的历史隐层信息进行相似度计算,可以较好地捕获邻居车辆和本车之间的相关性,获取车辆之间的潜在关联,提升轨迹预测的精度.
图 7
3.4.2. “Hist-Attention”权重分布
如图8所示为某条轨迹“Hist-Attention”中不同时刻的权重分布. 实验时每隔1 s更新一次历史轨迹节点的权重,对于长度为5 s的轨迹需要进行4次权重的计算,图8从上往下,分别是预测时间为1、2、3、4 s时的注意力权重. 可以看到,随着时间的推移,每个点为的权重在不断变化,偏向前面的轨迹点权重在逐渐变小,而后面的轨迹点权重则在逐渐变大,这表明久远的历史信息在逐渐被遗忘,对于更远的将来,需要较近的历史信息才能起作用. 同时权重的分布也不是均匀的,可能某些点在预测轨迹的过程中显得更加重要,比如历史轨迹中的拐点等. 相比传统Encoder-Decoder框架仅使用固定的中间变量,加入“Hist-Attention”后各时刻采用的中间变量都有差异,使得每次预测都能找到与其最为相关的历史信息. 虽然LSTM经过信息的逐层传递,也可以对重要信息进行保留,对不重要信息进行删减,但其得到的中间变量是固定不变的,并且难以进行可视化呈现,无法直观地判断历史数据中的关键节点,而本文引入的“Hist-Attention”改进可以较好地解决该问题.
图 8
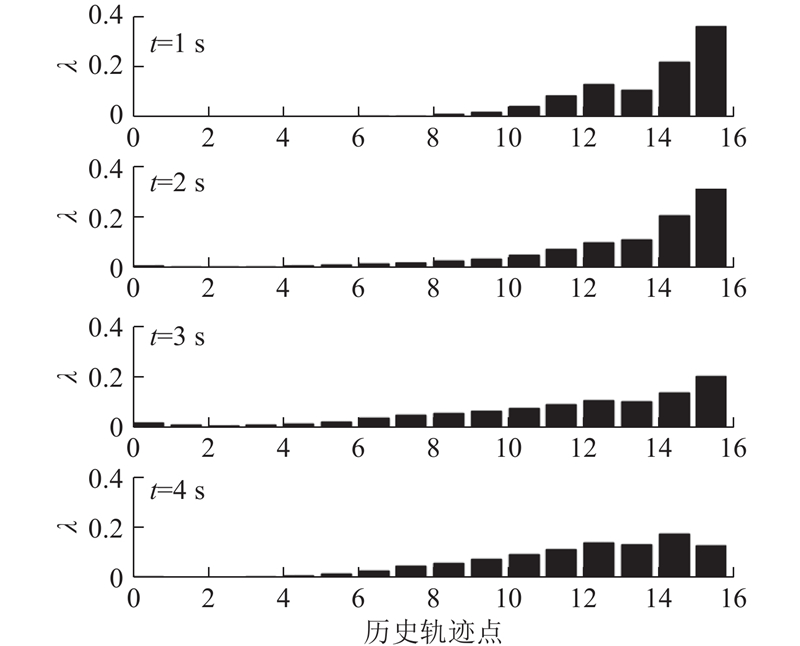
图 8 不同时刻下的历史轨迹的权重分布
Fig.8 Weight distribution of historical trajectories at different times
4. 结 语
本文通过实验证明,在原始的卷积池化网络基础上引入注意力机制后能较好地提升轨迹预测算法的精度. 目前该算法只能应用于车辆运动较为简单的场景,如:高速公路,对于频繁变向、加减速等情形,依然难以有效预测车辆未来轨迹,对这类复杂场景需要引入更多的信息(如:路面信息),才能较好地预测车辆未来轨迹.
参考文献
Social force model for pedestrian dynamics
[J].DOI:10.1103/PhysRevE.51.4282 [本文引用: 1]
Long short-term memory
[J].DOI:10.1162/neco.1997.9.8.1735 [本文引用: 1]
Soft+ hardwired attention: an LSTM framework for human trajectory prediction and abnormal event detection
[J].DOI:10.1016/j.neunet.2018.09.002 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}