

随着太阳能的广泛利用,太阳能电池产业得到迅猛发展. 由于工艺、生产环境等因素,导致太阳能电池存在不同类别的缺陷,大大降低太阳能电池的转换效率和使用寿命,太阳能电池缺陷检测[1]成为生产过程中的重要环节. 电致发光[2](electroluminescence,EL)技术能够让太阳能电池的内部缺陷在红外相机下成像,促进了太阳电池缺陷检测技术的发展. 在现有的太阳能电池缺陷检测技术中,传统人工特征[3]设计方法是主要的检测手段,但这些检测方法对数据挖掘不充分,导致检测精度低. 近年来,通过深度学习方法[4]自动充分提取数据特征,大幅度提升了太阳能电池缺陷的检测精度. 实际生产中出现的太阳能电池缺陷具有稀疏性,使得缺陷样本和正常样本极不均衡,这样的数据用于深度学习方法训练易导致过拟合现象[5].
解决过拟合的方法之一是通过数据增强方法对不均衡样本进行样本数量扩充. 传统的图像数据增强[6]方法通过对已知样本进行旋转、平移、翻转、对比度变换及加入噪声等方法来增加已知数据集的数量,这些方法局限在已知数据的特征空间范围,使其不能对具有复杂纹理背景的样本的特征进行充分的表示. 近年来,基于生成对抗网络[7](generative adversarial network,GAN)的数据增强方法被提出,它通过学习能够生成与训练样本具有相似分布的数据,为现有数据增强技术提供潜在且有价值的补充[8]. 研究者们通过对行人检测数据[9]、SAR数据[10]、医学数据[11]及文本数据[12]等进行增强,使得基于GAN的数据增强方法得到广泛的应用和推广.
本文为了解决太阳能电池缺陷样本和正常样本不均衡问题,提出负样本引导的生成对抗网络(negative sample guided generative adversarial network,NSGGAN)模型,将太阳能电池缺陷样本作为正样本,非缺陷样本为负样本. 通过引入太阳能电池负样本,在判别器的损失函数中增加负样本的引导损失项,有效增强对正样本特征的表达,提升生成样本的多样性;自适应的判别器权值约束方法对训练过程中的判别器权值系数进行自适应范围控制,使得模型更好地平衡生成器和判别器之间的表达能力,提高生成样本的质量.
1. 相关工作
GAN由Goodfellow等[7]提出,原理来自于零和博弈. 它由生成器
式中:
GAN对于真实样本的分布具有极强的模拟能力,在数据增强方面具有巨大的潜力,相继有各领域的研究学者们用GAN进行数据增强,并取得一定的研究成果. 通常基于GAN的数据增强方法是将待增强数据作为GAN的训练数据,通过训练GAN模型,使得模型中的生成器能够生成类似于待增强数据分布的样本. Wang等[13]利用WGAN对不均衡的计算机断层扫描图像——肺结节图像进行过采样,以增加样本数据中少样本类的数量,提升CNN的分类精度;Han等[14]利用DCGAN和WGAN对多序列脑磁共振图像进行生成,可以同时针对序列中的几张图进行处理,提高诊断可靠性;Rezaei等[15]针对医学图像中的数据不均衡问题,利用CGAN对数据的真假反馈学习医学图像的特征表达;同时通过精炼网络对生成样本进行提炼得到增强的数据,降低检测过程中对非病症数据的误检率.
受以上研究学者的启发,本文致力于将GAN应用于太阳能电池缺陷数据增强. 太阳能电池缺陷通过红外相机进行采集,与非缺陷样本数据数量相差很大,导致太阳能电池缺陷数据与非缺陷数据存在数据不均衡性. 不同于Rezaei等[15]使用条件生成对抗网络和精炼网络的数据增强方式,本文利用非缺陷样本引导网络训练,生成新的缺陷样本数据,从而实现太阳能电池缺陷数据的数据增强.
2. NSGGAN
本文的NSGGAN模型结构如图1所示. 图中,
图 1
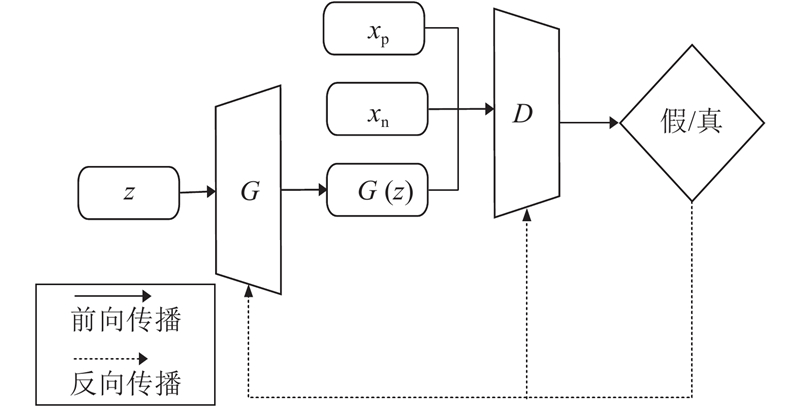
介绍引入负样本引导后的模型损失函数以及平衡生成器和判别器的自适应权值约束方法.
2.1. 模型损失函数
提出的NSGGAN模型不需要在生成器
式中:
式中:
图 2
2.2. 自适应权值约束
式中:
将判别器参数限制在一个固定的范围是为了平衡对抗过程中生成器与判别器的表示能力,该方法的难点是参数
提出自适应权值约束方法,自适应地调节模型对判别器权值的约束范围,平衡判别器和生成器的特征表达能力,自适应权值约束为
式中:
3. 实验分析
3.1. 模型参数选择
为了量化GAN模型的数据增强性能,将增强后的数据输入CNN进行分类,对比增强前、后的分类指标. 使用的CNN分类模型为LeNet-5模型的变体,将原模型的sigmoid激活函数改为Relu函数,并在激活函数之前加入批量标准化层,全连接层的dropout率为0.5. CNN分类模型的训练参数如下:优化器Adam,学习率为0.000 1,一阶衰减指数为0.5,训练迭代8 000次.
3.2. 性能评估指标
3.2.1. 生成质量评价指标
使用Shmelkov等[21]的3种生成质量评估指标:最大均值差异(MMD)、Wasserstein距离(WD)和最近邻留一法(1-NN)的分类精度p1-NN,对GAN生成样本的质量进行评估. 最大均值差异定义为
MMD用于度量在某一核函数
分布
式中:
WD越小表示2个分布更相似,即生成质量更接近真实样本.
最近邻留一法是将总样本数N中抽取1个样本作为验证,其余样本作为训练,直至所有样本均被用于验证. 1-NN分类精度用于评估2个分布的相似程度,精度为0~1.0. 给定2类样本
3.2.2. CNN分类模型评价指标
使用F测度F(F-measure)评估数据增强前、后CNN分类模型的性能,以此来评估对比方法的数据增强性能. F定义如下:
式中:
其中
3.3. 太阳能电池EL缺陷生成质量及增强效果评估
本文的太阳能电池EL数据集包括100张带有隐裂缺陷和1 000张非缺陷的太阳能电池EL灰度图像,图像大小为1 024×1 024像素. 将太阳能电池EL数据统一裁剪成64×64像素的图片,缺陷样本共300张,非缺陷样本共36 000张. 如图3所示为太阳能电池EL数据裁剪后的缺陷样本和非缺陷样本.
图 3

3.3.1. 引导样本规模的影响分析
在太阳能电池EL缺陷数据增强效果评估之前,将F作为选择负样本规模的评价指标,对NSGGAN所需引导样本(负样本)的规模进行实验分析. 分别选取20、50、100和200个正样本(缺陷样本)以及不同数量的负样本(正常样本),训练NSGGAN. CNN分类器的训练集为使用预训练的NSGGAN生成10 000个正样本和随机从样本集中选取的10 000个负样本,测试集为剩余的100个正样本和6 000个负样本,实验记录并计算在不同情况下的F,结果如图4所示. 图中,n、s分别为负样本数和正样本数.
图 4
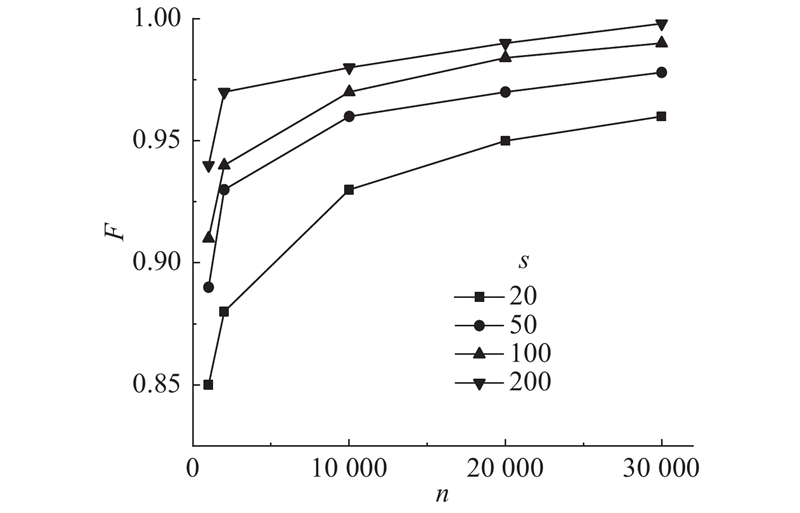
图 4 不同数量负样本引导的F-measure曲线
Fig.4 F-measure curves of different numbers of negative samples
从图4可以看出,训练集中引导负样本数量的增加,F曲线呈上升趋势;由此可见,引导负样本越多,提出的NSGGAN模型数据增强效果越好. 当负样本数目一定时,随着正样本数的增多,F越大,表明该方法在正样本数越多的情况下,效果越好.
3.3.2. 生成质量评价
利用DCGAN、WGAN-GP、FOGAN和NSGGAN对太阳能电池EL缺陷数据进行生成,生成图像的结果如图5所示. 可以看出,利用各种比较的模型均能够生成视觉上与正样本相似的图像.
图 5

图 5 DCGAN、WGAN-GP、FOGAN和NSGGAN生成太阳能电池EL缺陷样本
Fig.5 Generated EL image samples of solar cells by DCGAN,WGAN-GP,FOGAN and NSGGAN
表 1 各模型在太阳能电池EL缺陷数据上的生成质量
Tab.1
| 方法 | s | p1-NN | MMD | WD |
| DCGAN | 20 | 0.81 | 0.35 | 4.3 |
| DCGAN | 50 | 0.79 | 0.33 | 4.0 |
| DCGAN | 100 | 0.76 | 0.31 | 3.8 |
| DCGAN | 200 | 0.75 | 0.30 | 3.6 |
| WGAN-GP | 20 | 0.73 | 0.32 | 4.2 |
| WGAN-GP | 50 | 0.73 | 0.31 | 3.9 |
| WGAN-GP | 100 | 0.72 | 0.28 | 3.7 |
| WGAN-GP | 200 | 0.69 | 0.27 | 3.5 |
| FOGAN | 20 | 0.68 | 0.29 | 3.8 |
| FOGAN | 50 | 0.65 | 0.25 | 3.4 |
| FOGAN | 100 | 0.61 | 0.20 | 3.1 |
| FOGAN | 200 | 0.58 | 0.18 | 2.9 |
| NSGGAN | 20 | 0.53 | 0.20 | 3.3 |
| NSGGAN | 50 | 0.53 | 0.18 | 3.2 |
| NSGGAN | 100 | 0.53 | 0.17 | 3.1 |
| NSGGAN | 200 | 0.52 | 0.15 | 2.8 |
在生成质量评价指标中,WD和MMD越小,说明生成质量越高;在p1-NN≥0.5的情况下,越接近0.5表示生成质量越好. 从表1可以看出,当正样本数量相同时,FOGAN的各生成质量指标较DCGAN和WGAN-GP小,p1-NN均未低于0.5,因此FOGAN比DCGAN和WGAN-GP具有更好的生成质量. 当正样本数一定时,NSGGAN比FOGAN的指标更小,具有更好的生成质量,因此提出的负样本引导的GAN模型在生成样本的质量上具有一定的竞争力.
3.3.3. 数据增强性能评价
表 2 太阳能电池EL样本集
Tab.2
| 方法 | GAN训练集 | CNN训练集 | CNN测试集 | |||||
| s | n | s | n | s | n | |||
| 没有数据增强 | − | − | s | 10 000 | 300−s | 6 000 | ||
| 传统数据增强方法 | s | − | 10 000 | 10 000 | 300−s | 6 000 | ||
| DCGAN增强方法 | s | − | 10 000 | 10 000 | 300−s | 6 000 | ||
| WGAN-GP增强方法 | s | − | 10 000 | 10 000 | 300−s | 6 000 | ||
| FOGAN增强方法 | s | − | 10 000 | 10 000 | 300−s | 6 000 | ||
| NSGGAN增强方法 | s | 20 000 | 10 000 | 10 000 | 300−s | 6 000 | ||
图 6
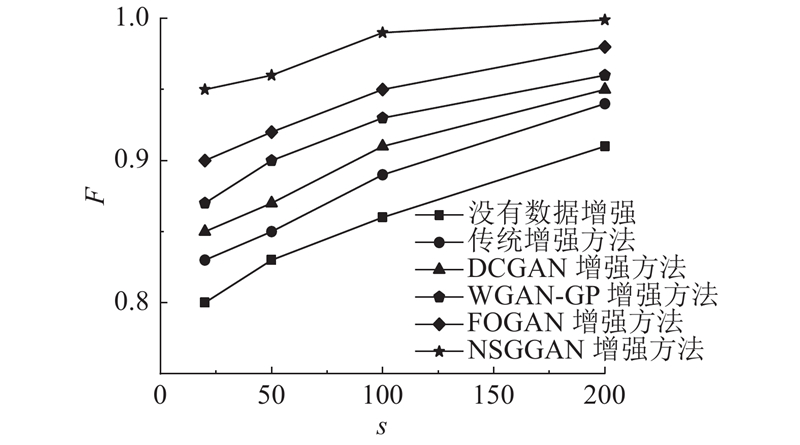
图 6 不同数量正样本下各方法在太阳能电池EL数据集的F测度曲线
Fig.6 F-measure curves of solar cell EL dataset for different methods under different positive samples
从图6可以看出,随着正样本数目的增加,各方法的F的差距变小,这表明随着正样本数量的增加,CNN获得更好的分类效果. 当正样本数量相同时,基于GAN增强相比于传统方法具有更好的增强效果;利用提出的NSGGAN获得的F均高于DCGAN、WGAN-GP和FOGAN方法. 特别地,当正样本数量为20时,NSGGAN数据增强后的F为0.96,相较于未增强方法的F提升15%,相较于DCGAN、WGAN-GP和FOGAN分别提升10%、8%和5%. 由此可得,相比于其他比较的方法,NSGGAN具有更突出的数据增强的性能.
3.3.4. 模型改进的有效性验证
为了验证提出的负样本引导和自适应权值约束的有效性,在太阳能电池EL缺陷数据集上对比DCGAN、加入负样本引导的DCGAN(DCGAN+NSG)、加入传统的权值裁剪的DCGAN(DCGAN+clip)、加入自适应权值裁剪方法的DCGAN(DCGAN+adaptive_clip)、加入负样本引导与传统权值裁剪方法的DCGAN(DCGAN + NSG + clip)以及加入负样本引导与自适应权值约束的DCGAN(NSGGAN)等方法的生成质量指标和F. 其中,用于训练各对比模型的正样本为20个,负样本为20 000个;CNN分类模型的训练集包括增强后的10 000个正样本以及从数据集中抽取的10 000个负样本;测试集为280个正样本和6 000个负样本. 实验结果如表3、4所示,最好结果由粗体显示.
表 3 各方法在太阳能电池EL数据集的F测度
Tab.3
| 对比方法 | F |
| DCGAN | 0.85 |
| DCGAN + NSG | 0.89 |
| DCGAN + clip | 0.91 |
| DCGAN + adaptive_clip | 0.92 |
| DCGAN+NSG + clip | 0.93 |
| NSGGAN | 0.96 |
表 4 各方法在太阳能电池EL缺陷数据集上的生成质量
Tab.4
| 对比方法 | p1-NN | MMD | WD |
| DCGAN | 0.81 | 0.35 | 4.3 |
| DCGAN + NSG | 0.75 | 0.29 | 3.8 |
| DCGAN + clip | 0.74 | 0.27 | 3.5 |
| DCGAN +adaptive_clip | 0.71 | 0.25 | 3.5 |
| DCGAN + NSG+ clip | 0.69 | 0.22 | 3.3 |
| NSGGAN | 0.53 | 0.18 | 3.1 |
3.4. NSGGAN在其他数据集上的性能评估
除太阳能电池EL数据集外,在带钢表面缺陷数据集[23]和DAGM2007[24]公共织物数据集上对提出的NSGGAN作了进一步验证. 其中表面缺陷数据集包含400个带钢缺陷数据及14 000张非缺陷数据,大小为64×64像素的灰度图像;DAGM2007数据集为各种均质纹理下的布匹数据库,该数据为6类无缺陷布匹数据1 000张及各类相应的6类缺陷各600张,大小为512×512像素的灰度图片. 选取类别1缺陷样本,裁剪大小为64×64像素,包括700张缺陷样本和20 000张非缺陷样本. 在2个数据集上分别随机选择缺陷样本各20个作为正样本,非缺陷样本各80%作为负样本训练DCGAN、WGAN-GP、FOGAN和NSGGAN,各模型生成样本如图7所示. 可以看出,DCGAN、WGAN-GP和NSGGAN 3种模型均能够生成与原始样本相似的图像,但FOGAN生成的2类样本在视觉上没有其他3种方法好,且生成的DAGM2007数据纹理不连续. 生成结果表明,当样本量极少时,DCGAN、WGAN-GP和NSGGAN较FOGAN具有更强的泛化能力.
图 7

图 7 DCGAN、WGAN-GP、FOGAN和NSGGAN生成的样本
Fig.7 Generated samples by DCGAN,WGAN-GP,FOGAN and NSGGAN
表 5 各模型在带钢表面缺陷数据集上的生成质量
Tab.5
| 方法 | s | p1-NN | MMD | WD |
| DCGAN | 20 | 0.83 | 0.42 | 5.1 |
| DCGAN | 50 | 0.80 | 0.40 | 4.9 |
| DCGAN | 100 | 0.78 | 0.37 | 4.5 |
| DCGAN | 200 | 0.76 | 0.36 | 4.3 |
| WGAN-GP | 20 | 0.78 | 0.41 | 4.7 |
| WGAN-GP | 50 | 0.76 | 0.40 | 4.5 |
| WGAN-GP | 100 | 0.75 | 0.39 | 4.4 |
| WGAN-GP | 200 | 0.73 | 0.36 | 4.2 |
| FOGAN | 20 | 0.85 | 0.46 | 5.3 |
| FOGAN | 50 | 0.74 | 0.42 | 4.8 |
| FOGAN | 100 | 0.70 | 0.37 | 4.3 |
| FOGAN | 200 | 0.67 | 0.35 | 4.0 |
| NSGGAN | 20 | 0.59 | 0.28 | 3.6 |
| NSGGAN | 50 | 0.58 | 0.27 | 3.5 |
| NSGGAN | 100 | 0.58 | 0.24 | 3.2 |
| NSGGAN | 200 | 0.55 | 0.23 | 3.0 |
表 6 各模型在DAGM2007数据集上的生成质量
Tab.6
| 方法 | s | p1-NN | MMD | WD |
| DCGAN | 20 | 0.88 | 0.53 | 5.4 |
| DCGAN | 50 | 0.87 | 0.51 | 5.2 |
| DCGAN | 100 | 0.85 | 0.50 | 5.5 |
| DCGAN | 200 | 0.83 | 0.47 | 4.8 |
| WGAN-GP | 20 | 0.85 | 0.51 | 4.9 |
| WGAN-GP | 50 | 0.83 | 0.47 | 4.6 |
| WGAN-GP | 100 | 0.82 | 0.45 | 4.5 |
| WGAN-GP | 200 | 0.80 | 0.44 | 4.3 |
| FOGAN | 20 | 0.90 | 0.56 | 5.8 |
| FOGAN | 50 | 0.86 | 0.50 | 5.5 |
| FOGAN | 100 | 0.83 | 0.46 | 5.0 |
| FOGAN | 200 | 0.78 | 0.43 | 4.5 |
| NSGGAN | 20 | 0.75 | 0.46 | 4.4 |
| NSGGAN | 50 | 0.73 | 0.43 | 4.2 |
| NSGGAN | 100 | 0.70 | 0.42 | 4.0 |
| NSGGAN | 200 | 0.68 | 0.40 | 3.9 |
在2个数据集上分别测试没有数据增强、传统的旋转和翻转的增强方法、DCGAN增强方法、WGAN-GP增强方法、FOGAN增强方法以及本文提出的NSGGAN增强方法在不同正样本数目情况下的F,结果如图8所示.
图 8
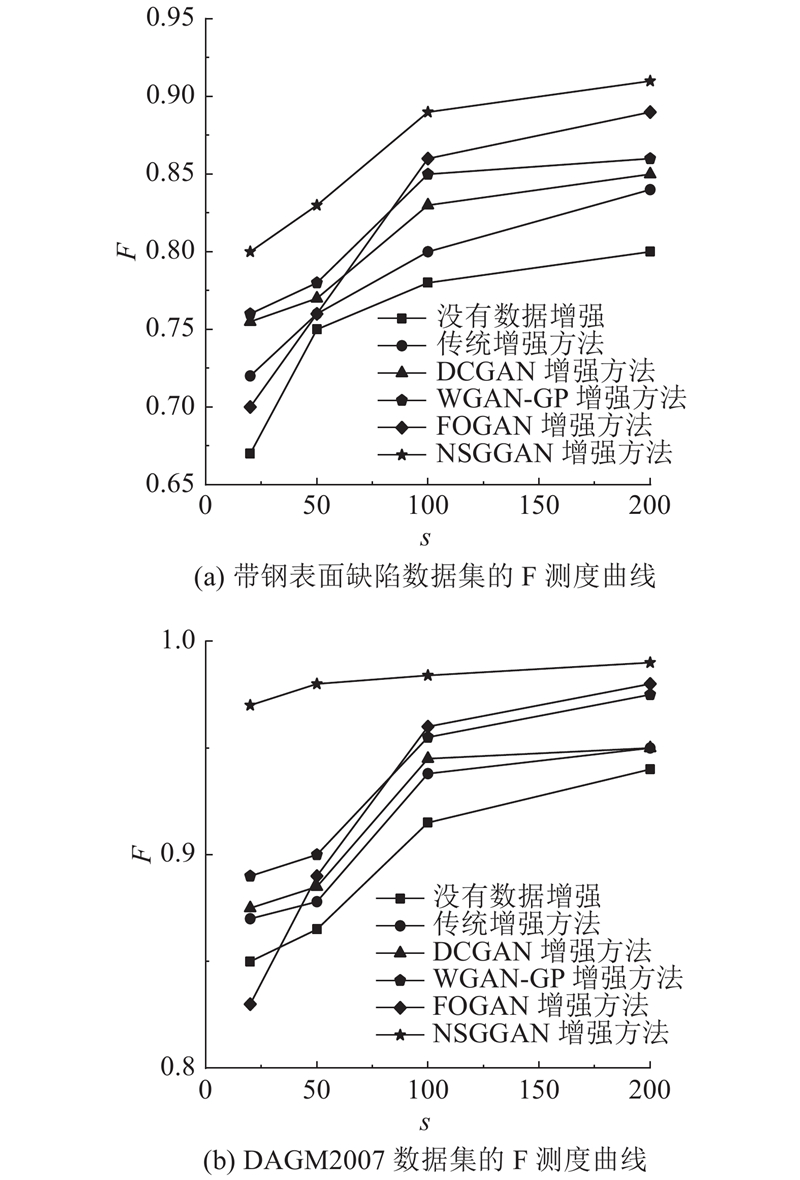
图 8 不同数量正样本下不同方法的F测度曲线
Fig.8 F-measure curves of different methods under different numbers of positive samples
从图8可以看出,不管是带钢表面缺陷数据集,还是DAGM2007数据集,在相同正样本数下,数据增强方法的F均高于没有进行数据增强的方法;基于GAN数据增强方法的F均高于传统数据增强方法. 在正样本数从20增加到200的过程中,各对比模型的F均逐渐上升. 当正样本数相同时,NSGGAN的F优于其他5种方法. 由此可见,提出的NSGGAN方法在各数据集上,较其他比较方法都表现出了更好的F曲线.
综上所述,提出的NSGGAN模型在其他数据集上表现出良好的生成质量及分类精度,具有一定的泛化能力.
4. 结 语
针对太阳能电池EL缺陷数据不均衡带来的过拟合问题,本文提出基于负样本引导的NSGGAN的数据增强方法. 负样本引导的策略可以有效提升模型对正样本特征的表达能力,增加模型生成样本的多样性;利用自适应的权值约束的方法对判别器的权值进行自适应调整,平衡生成器和判别器的能力,使得模型训练过程更加稳定,进一步提升模型生成样本的质量.
通过实验结果证明,本文提出的NSGGAN模型能够有效提升模型的生成质量和多样性;在太阳能电池EL数据集上,相较于DCGAN、WGAN-GP、和FOGAN有一定的竞争力. NSGGAN在带钢表面缺陷数据集和DAGM2007数据集上的验证结果优于其他对比的方法,表明NSGGAN具有一定的泛化能力. NSGGAN可以用于工业生产过程中的缺陷数据增强,利用与缺陷数据同源的正常数据和少量缺陷数据对少量缺陷数据进行增强,能够有效提升深度学习模型的分类精度.
参考文献
Defect detection in multi-crystal solar cells using clustering with uniformity measures
[J].DOI:10.1016/j.aei.2015.01.014 [本文引用: 1]
电致发光缺陷检测仪的成像性能评估
[J].DOI:10.3788/OPE.20172506.1418 [本文引用: 1]
Evaluation of imaging performance for electroluminescence defect detector
[J].DOI:10.3788/OPE.20172506.1418 [本文引用: 1]
Machine-vision-based identify-cation for wafer tracking in solar cell manufacturing
[J].DOI:10.1016/j.rcim.2013.01.009 [本文引用: 1]
基于层次聚类的不平衡数据加权过采样方法
[J].
Weighted oversampling method based on hierarchical clustering for unbalanced data
[J].
基于深度学习的太阳能电池片表面缺陷检测方法
[J].
Solar cells surface defects detection based on deep learning
[J].
Data augmentation using generative adversarial networks (CycleGAN) to improve generalizability in CT segmentation tasks
[J].DOI:10.1038/s41598-018-37186-2 [本文引用: 1]
WGAN-based synthetic minority over-sampling technique: improving semantic fine-grained classification for lung nodules in CT images
[J].
A method for improving CNN-based image recognition using DCGAN
[J].
First order generative adversarial networks
[J].
Classification of manufacturing defects in multicrystalline solar cells with novel feature descriptor
[J].DOI:10.1109/TIM.2019.2900961 [本文引用: 1]
A simple guidance template-based defect detection method for strip steel surfaces
[J].
A fast and robust convolutional neural network-based defect detection model in product quality control
[J].DOI:10.1007/s00170-017-0882-0 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}