

复杂网络能够用于表示人际关系网、引文网络等复杂系统. 近些年在复杂网络研究领域涌现出许多新任务,例如社团发现、链路预测、智能推荐,传统的复杂网络研究方法通常依赖于网络的统计特性或者人工设定的特征,在处理这些任务时不够灵活高效. 图嵌入技术的出现,为复杂网络的研究提供了崭新的思路.
图是一种数据结构,多数复杂网络能够用图来表示. 图包含节点的集合与节点之间连边的集合,节点的特征用特征矩阵表示,节点之间的连接关系用邻接矩阵表示. 图嵌入又称网络嵌入、网络表示学习,其目的是利用邻接矩阵和特征矩阵中的信息为图中节点学习到有效的表示或编码,这些表示和编码即图的嵌入[1]. 图的嵌入可作为下游机器学习或数据挖掘任务的输入.
已有的图嵌入方法大多数基于因式分解、随机游走或深度学习[2]. 基于因式分解的方法将节点之间的连接表示成矩阵,通过分解矩阵来学习节点的表示. Belkin等[3]假设相连节点的表示相近,将嵌入的优化问题转化为拉普拉斯矩阵特征向量求解问题. Roweis等[4-5]提出基于因式分解的图嵌入方法. 基于随机游走的方法主要有Perozzi等[6]提出的DeepWalk和Grover等[7]提出的node2vec,这类方法先在图中采样出大量的随机游走序列,再最大化随机游走序列的似然概率,使得在一个短随机游走上同现的节点拥有相似嵌入. 在基于深度学习的方法中较知名的是Kipft等[8]提出的图卷积网络(graph convolutional networks,GCN),涉及的“卷积”这一概念来源于机器视觉领域的卷积神经网络. 另外,Defferrard等[9-10]也将深度学习技术应用到了图数据上.
GraphSAGE[11]所代表的基于深度学习的聚合式图嵌入方法是近两年新兴的方法,它利用图卷积网络捕获局部信息,通过聚合节点的邻域信息为节点生成嵌入. 为了简化节点的选择过程,在构建邻域时多采用均匀采样函数,即在各节点的邻居节点集中随机采样部分节点作为其邻域. 随机采样的方法运算复杂度较低,但忽略了邻居节点自身性质的差异.
本研究提出非均匀邻居节点采样方法,在采样过程中考虑度值,通过优先采样与隐藏节点后的随机采样相结合解决上述问题. 将所提方法应用于图嵌入过程,并在Reddit、蛋白质交互作用(protein-protein interaction,PPI)数据集上验证该方法对嵌入质量的提升效果.
1. 节点嵌入的生成
在图
式中:
图嵌入即将图中的节点表示成低维向量
图 1
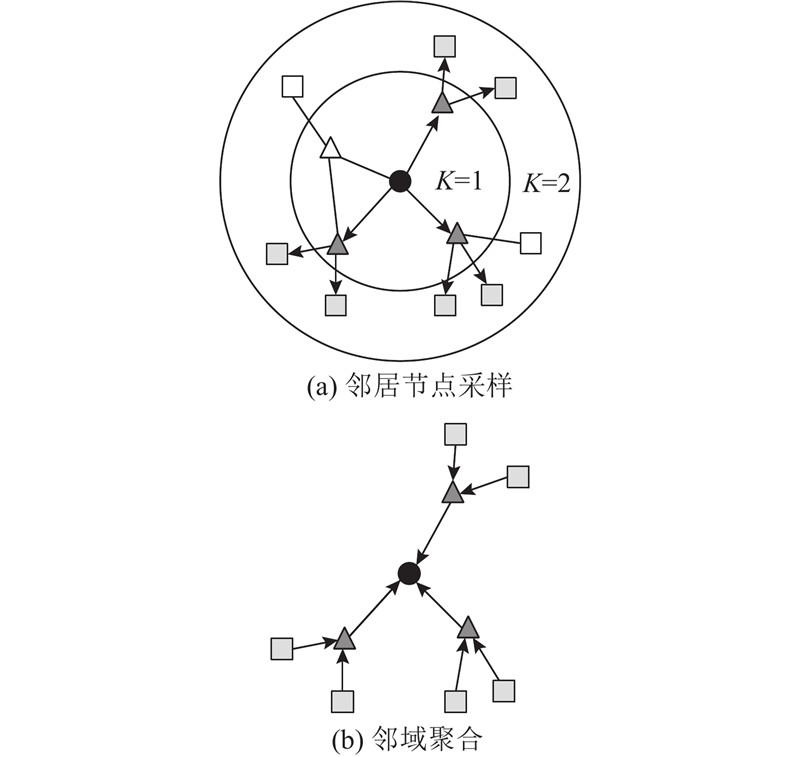
1.1. 非均匀邻居节点采样
图数据中各节点的邻居数不统一,在较大的图中,节点的邻居数量庞大,须分别对各节点的邻居进行采样,构建出大小统一、便于计算的局部邻域. 此邻域与卷积神经网络中的接收域在概念上相似,在网络的各层中它的大小往往是固定的.
对图数据中每个待生成嵌入的目标节点而言,各邻居节点在点介数、度值、集聚系数等性质上存在差异,表征的局部信息也不同. 如果单纯地随机采样这些邻居节点,则可能导致包含更多信息的节点被忽略,或者导致对构建嵌入没有帮助的节点被选择. 因此,须采用非均匀采样方法构建高质量的节点邻域.
本研究采用邻域与局部图的连接强度来衡量邻域的质量. 对于简单的树状图,邻域与局部图的连接强度的定义为
式中:
节点的度值等于与节点直接相连的连边数,若图中各节点之间的连边为单连边,则度值等于与该节点直接相连的节点数,即
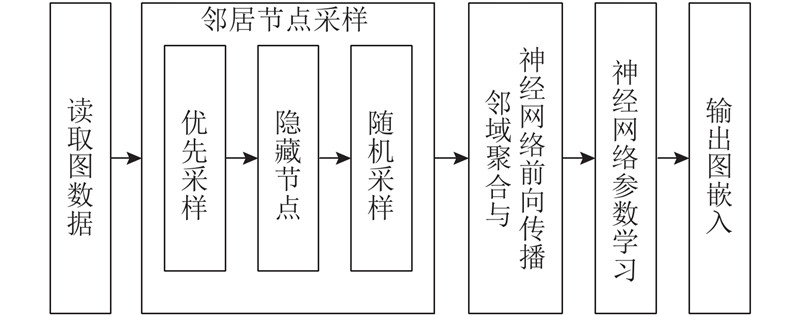
度值是节点的重要属性之一,能够反映节点在图中的重要程度. 一般来说,度值较大的节点包含更多的局部结构信息,对生成有效的嵌入更有帮助. 提高邻域与局部图的连接强度的一个有效方式是提高度值较大的节点被采样的概率,同时降低度值较小的节点被采样的概率. 为了解决上述问题,本研究提出优先采样与隐藏节点后的随机采样相结合的方法,采用该方法为图数据生成嵌入的流程框图如图2所示.
图 2
在邻居节点集中优先采样部分度值较大的节点,并隐藏度值较小的节点,之后再随机采样剩余的节点. 该方法的具体步骤如算法1所示. 1)将目标节点
算法1 邻居节点采样
输入:节点v的邻居节点集
输出:节点
N(v)= { }
for
return
在算法1中并没有直接采样度值最大的S个节点,而是保留了一部分随机采样的节点,目的是保留一定的采样随机性,避免主观因素对采样结果产生过多的影响,防止产生较高的倾向性误差,使得最终构建出的节点邻域更能代表节点的局部信息. 不同图数据中节点的平均邻居数存在差异,优先采样数和隐藏节点数可以根据图数据的具体情况进行设置.
相比均匀采样方法,采用算法1构建出的节点邻域与局部图的连接强度更大,因此对目标节点的局部结构的表征效果更好. 在实际操作中,通常由多个节点的邻域组成一个矩阵,通过对矩阵进行运算来实现邻居节点采样.
1.2. 邻域聚合与前向传播
在采用非均匀邻居节点采样方法为各个目标节点构建邻域后,将邻域中节点的特征聚合起来,将聚合后的邻域特征与目标节点在上一次迭代中的特征结合,传递到图神经网络层中. 利用神经网络的层级传播机制,各目标节点迭代地聚合图中越来越远处的信息,最终生成节点的新表示. 算法2如下.
算法2 邻域聚合
输入:图
输出:节点
for
for
end
end
算法2描述了邻域聚合及神经网络前向传播的过程[11]. 算法2的输入为图
1.3. 参数学习
采用Mikolov等[12]提出的负采样优化算法对图神经网络的参数进行优化学习. 负采样算法出现在目标函数内,它的优化目标是最大化正样本的概率同时最小化负样本的概率,反映在图中即鼓励相近的节点拥有相似的嵌入,同时强制相隔远的节点拥有相异的嵌入:
式中:
2. 实 验
将所提出的非均匀邻居节点采样方法应用于图嵌入过程,将生成的嵌入馈送给下游分类器,通过分类的效果衡量生成的图嵌入的质量. 在实验中采用PPI数据集与Reddit数据集,实验基本在TensorFlow框架下完成.
2.1. 数据集
1)Reddit是大型社交新闻网站,用户可以在不同的子版块中发表帖子或对帖子的评论,不同的子版块可以视为不同的社区. Reddit数据集中共有232 965个节点,每个节点代表1个帖子,若有同一个用户在2个帖子下发表评论,则这2个帖子对应的节点之间存在连接. 针对Reddit数据集的任务的目标是将帖子分类到对应的社区.
2)在PPI数据集中,一个节点表示一种蛋白质,若蛋白质之间存在交互作用,则对应的节点之间存在连边. PPI的121个子图对应不同的人体组织,已知一种蛋白质可能存在于多种人体组织中,因此PPI数据集中的节点可以同时属于多个子图,针对PPI数据集的任务可以视为重叠社团划分任务.
2.2. 实验过程及设置
1)邻居节点采样. 采用所提出的方法为图中各节点构建邻域,同时为了验证隐藏节点这一步骤对算法1的必要性,尝试将这一步骤去掉后进行试验. 称使用完整算法1的嵌入方法为NonUniform,去掉隐藏节点这一步骤的方法为NonUniform-1.
2)网络结构. 采用的图神经网络仅有2层,即
3)学习过程. 考虑到数据集较大,在实验中采用minibatch方法对节点进行分批训练,批次大小为512. 采用随机梯度下降对目标函数进行学习,在负采样优化中各节点的负样本数
4)下游分类器. 在学习结束后,将网络输出的节点嵌入馈送到下游的逻辑斯蒂分类器中,通过分类的F1分数衡量节点嵌入的质量.
对于实验中涉及到的其他超参数,根据验证的效果选择最佳值,其中神经网络的学习率为0.000 01,随机失活值和权重衰减值均为0,minibatch的验证频率为5 000.
2.3. 实验结果及分析
表 1 Reddit数据集的F1分数实验结果
Tab.1
| 方法 | F1分数 | 方法 | F1分数 | |
| Random | 0.043 | GraphSAGE | 0.897 | |
| DeepWalk | 0.324 | NonUniform | 0.917 | |
| RawFeatures | 0.585 |
表 2 PPI数据集的F1分数实验结果
Tab.2
| 方法 | F1分数 | 方法 | F1分数 | |
| Random | 0.396 | RawFeatures | 0.422 | |
| GraphSAGE | 0.447 | NonUniform | 0.458 |
在2个数据集上同时试验方法NonUniform. 在大型图数据集Reddit上,采用所提出的方法得到的嵌入分类F1分数为0.917,优于几个基线方法. 图嵌入的分类结果在重叠社团数据集PPI上也取得了一定改进,但由于逻辑斯蒂分类器的限制性,各类方法在PPI数据集上取得的F1分数均不高. 重叠社团的划分难度比非重叠社团的要大,因此所提出方法在PPI数据集上的提升效果没有在Reddit数据集上的明显. 通过对比可以看出,相比其他类型的方法,基于图卷积网络的聚合式图嵌入方法在嵌入效果上有着显著的优越性.
在Reddit数据集及PPI数据集上对比NonUniform与NonUniform-1方法的嵌入分类效果. 如表3所示,与NonUniform-1方法相比,NonUniform方法在2个数据集上均取得了更高的F1分数,说明在优先采样后对节点集中部分的节点进行隐藏是必要的,这一步骤对整个算法具有积极作用.
表 3 NonUniform与NonUniform-1方法的F1分数差别
Tab.3
| 数据集 | F1分数 | |
| NonUniform | NonUniform-1 | |
| 0.917 | 0.911 | |
| PPI | 0.458 | 0.453 |
3. 结 论
(1)所提出方法在大型图数据集Reddit及重叠社团数据集PPI上取得的嵌入分类F1分数均高于几个基线任务,证实基于度值的非均匀邻居节点采样方法能够有效提升为节点构建的邻域的质量,进而提升图嵌入的质量.
(2)所提出方法在PPI数据集上的提升效果没有在Reddit数据集上的明显,原因在于重叠社团划分的难度较高.
(3)所提出方法仅在度值维度上考虑了非均匀采样的方式,在以后的工作中可以研究基于不同节点性质的采样方法,或者将整张图的结构、特征均考虑进采样过程中.
参考文献
Representation learning on graphs: methods and applications
[J].
Graph embedding techniques, applications, and performance: a survey
[J].
Nonlinear dimensionality reduction by locally linear embedding
[J].DOI:10.1126/science.290.5500.2323 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}