| Computer Technology |
|


|
|
|
| Keyword recognition based on twice fusion of Posteriorgram and filler model |
Tai-bo CHEN( ),Cui-fang ZHANG*() ),Cui-fang ZHANG*() |
| School of Information Science and Technology, Southwest Jiaotong University, Chengdu 611756, China |
|
|
|
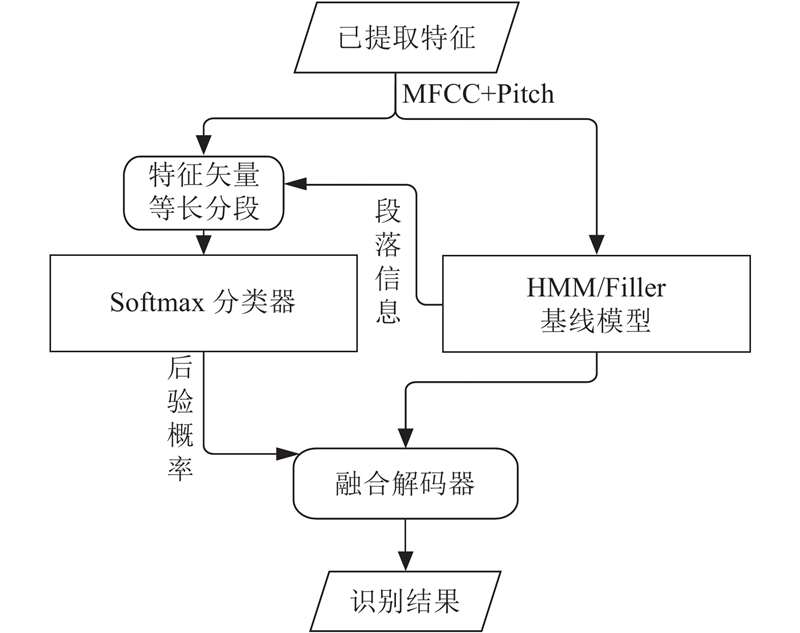
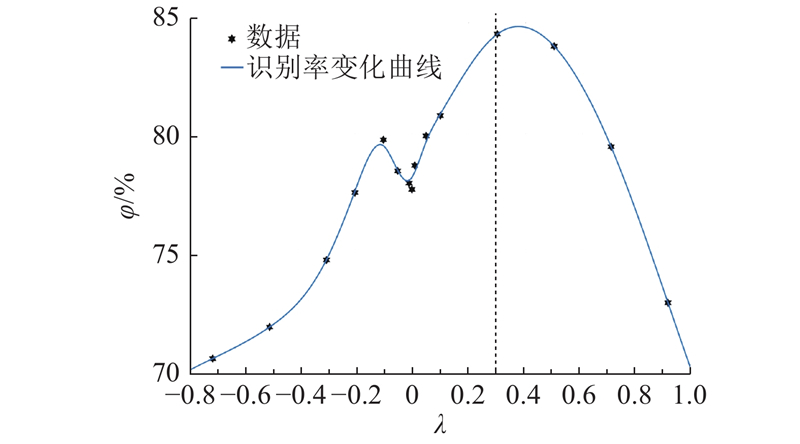
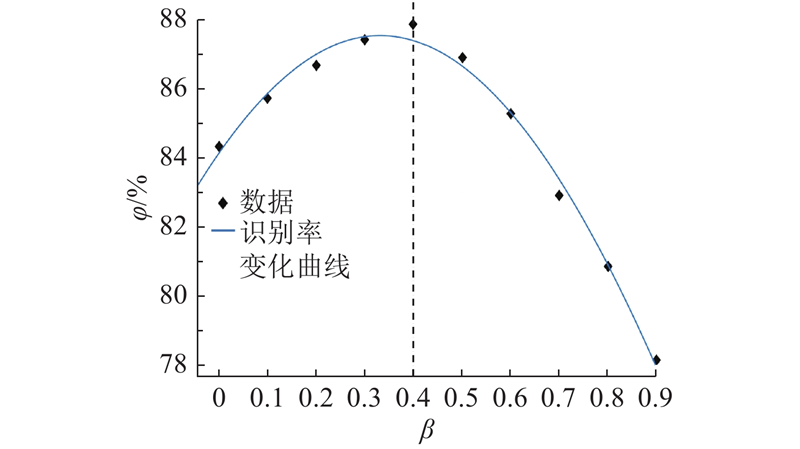
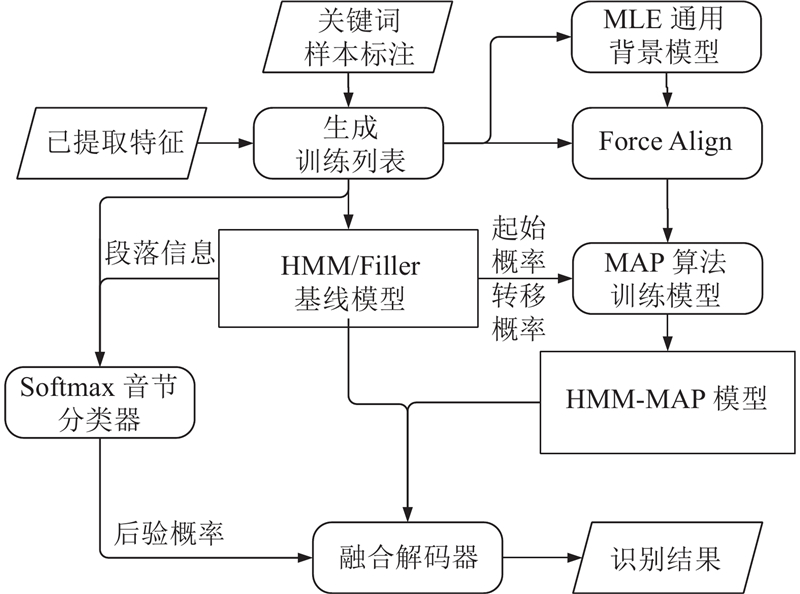
Abstract A fully-connected neural network, combined with Softmax classifier, was used to build a syllable classifier for 408 syllables in Chinese based on hidden Markov filler model (HMM/Filler). With the equal-length processing of the input feature vector of network, the output probability of the Softmax classifier was used as a Posteriorgram, to make first fusion with HMM/Filler model for the Posteriorgram hidden Markov model (Posteriorgram-HMM). Aiming at the problem of less keyword training samples, the Force-Align was used to obtain the training data for each state of HMM. Make second fusion of Maximum a posteriori estimation HMM (HMM-MAP) with Posteriorgram-HMM, and the Posteriorgram hidden Markov model (Posteriorgram-HMM-MAP) was obtained. After being trained on data set, the model was tested with test data. Results show that the comprehensive accuracy of the Posteriorgram-HMM-MAP was increased by 3.55% compared with Posteriorgram-HMM, and 10.29% higher than HMM/Filler.
|
|
Received: 15 May 2019
Published: 06 July 2020
|
|
|
|
Corresponding Authors:
Cui-fang ZHANG
E-mail: booookchen@outlook.com;cfzhang_scce@swjtu.cn
|
后验概率图与补白模型二次融合的关键词识别
使用全连接神经网络结合Softmax分类器对汉语的408个音节建立音节分类器,利用等长处理后的特征向量训练Softmax分类器,将Softmax分类器输出概率作为后验概率图,与隐马尔科夫补白模型(HMM/Filler)进行第一次融合,得到子后验概率图隐马尔科夫模型(Posteriorgram-HMM). 针对关键词训练样本较少的问题,将标注样本进行强制切分,得到HMM每个状态上的训练数据. 将隐马尔科夫最大后验概率基线模型(HMM-MAP)与Posteriorgram-HMM进行第二次融合,提出最大后验概率图隐马尔科夫模型(Posteriorgram-HMM-MAP). 在数据集上训练模型后,使用测试数据对其进行测试. 结果表明:Posteriorgram-HMM-MAP的综合识别率相比Posteriorgram-HMM提升了3.55%,相比HMM/Filler提升了10.29%.
关键词:
关键词识别,
隐马尔可夫模型(HMM),
补白模型,
Softmax分类器,
后验概率图,
最大后验概率(MAP)
|
|
| [1] |
孙成立. 语音关键词识别技术的研究[D]. 北京: 北京邮电大学, 2008.
SUN Cheng-li. A study of speech keyword recognition technology [D]. Beijing: Beijing University of Posts and Telecommunications, 2008.
|
|
|
| [2] |
侯靖勇, 谢磊, 杨鹏, 等 基于DTW的语音关键词检出[J]. 清华大学学报: 自然科学版, 2017, 57 (1): 18- 23
HOU Jing-yong, XlE Lei, YANG Peng, et al Spoken term detection based on DTW[J]. Journal of Tsinghua University: Science and Technology, 2017, 57 (1): 18- 23
|
|
|
| [3] |
汪鹏, 刘加, 刘润生 基于离散HMM的非特定人关键词提取语音识别系统[J]. 吉林大学学报: 理学版, 2003, 41 (3): 347- 351
WANG Peng, LIU Jia, LIU Run-sheng Discrete HMM based speaker independent keyword spotting speech recognition system[J]. Journal of Jilin University: Science Edition, 2003, 41 (3): 347- 351
|
|
|
| [4] |
TOSELLI A H, VIDAL E. Fast HMM-Filler approach for key word spotting in handwritten documents [C] // Proceedings of 2013 12th International Conference on IEEE. NewYork: IEEE, 2013: 341-358.
|
|
|
| [5] |
LIN C Y, HOVY E. Automatic evaluation of summaries using n-gram co-occurrence statistics [C] // Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology-volume. Association for Computational Linguistics, 2003.
|
|
|
| [6] |
孙彦楠, 夏秀渝 基于深度神经网络的关键词识别系统[J]. 计算机系统应用, 2018, 27 (5): 41- 48
SUN Yan-nan, XIA Xiu-yu Keyword recognition system based on deep neural network[J]. Computer Systems and Applications, 2018, 27 (5): 41- 48
|
|
|
| [7] |
GRAVES A, MOHAMED A, HINTON G. Speech recognition with deep recurrent neural networks [C] // 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Vancouver: IEEE, 2013: 6645-6649.
|
|
|
| [8] |
王满洪, 张二华, 王明合 基于双门限算法的端点检测改进研究[J]. 计算机与数字工程, 2017, 45 (11): 2223- 2228
WANG Man-hong, ZHANG Er-hua, WANG Ming-he Research and improvement on endpoint detection based on dual-threshold algorithm[J]. Computer and Digital Engineering, 2017, 45 (11): 2223- 2228
doi: 10.3969/j.issn.1672-9722.2017.11.030
|
|
|
| [9] |
邵明强, 徐志京 基于改进MFCC特征的语音识别算法[J]. 微型机与应用, 2017, 21 (1): 52- 54
SHAO Ming-qiang, XU Zhi-jing A speech recognition algorithm based on improved MFCC[J]. Microcomputer and Its Applications, 2017, 21 (1): 52- 54
|
|
|
| [10] |
SHAHNAWAZUDDIN S, SINHA R, PRADHAN G Pitch-normalized acoustic features for robust children ’s speech recognition[J]. IEEE Signal Processing Letters, 2017, 24 (8): 1128- 1132
doi: 10.1109/LSP.2017.2705085
|
|
|
| [11] |
花静. 基于HMM/SVM混合架构的连续语音识别模型的研究[D]. 哈尔滨: 哈尔滨工业大学, 2006.
HUA Jing. Research on continuous speech recognition based on a hybrid HMM/SVM framework[D]. Harbin: Harbin Institute of Technology, 2006.
|
|
|
| [12] |
JIANG M, LIANG Y, FENG X, et al Text classification based on deep belief network and softmax regression[J]. Neural Computing and Applications, 2016, (7): 1- 10
|
|
|
| [13] |
NEYSHABUR B, SALAKHUTDINOV R R, SREBRO N. Path-SGD: path-normalized optimization in deep neural networks [C] // Advances in Neural Information Processing Systems 28. Montreal: [s.n.], 2015: 2422-2430.
|
|
|
| [14] |
陈洁群 基于Viterbi改进算法的汉语数码语音识别模型[J]. 微型机与应用, 2017, 36 (14): 11- 13
CHEN Jie-qun The research on improved Viterbi algorithm for Chinese digital speech recognition system[J]. Microcomputer and its Applications, 2017, 36 (14): 11- 13
|
|
|
| [15] |
GAUVAIN J L, LEE C H Maximum a posteriori estimation for multivariate gaussian mixture observations of Markov chains[J]. IEEE Transactions on Speech and Audio Processing, 1994, 2 (2): 291- 298
doi: 10.1109/89.279278
|
|
|
|
Viewed |
|
|
|
Full text
|
|
|
|
|
Abstract
|
|
|
|
|
Cited |
|
|
|
|
| |
Shared |
|
|
|
|
| |
Discussed |
|
|
|
|