Front. Inform. Technol. Electron. Eng.
2016, 17 (
):
41-54.
(2840KB)
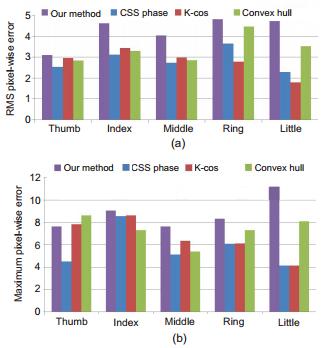
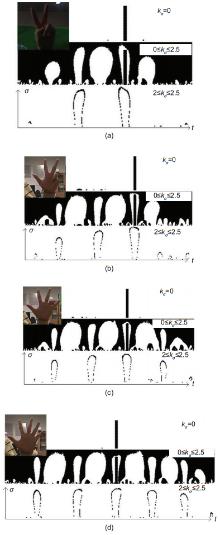
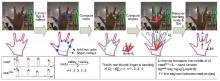
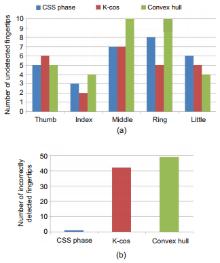
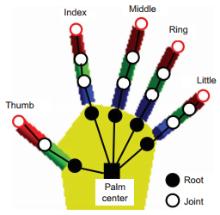
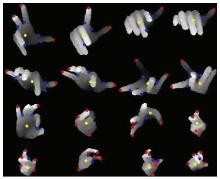
We propose a framework of hand articulation detection from a monocular depth image using curvature scale space (CSS) descriptors. We extract the hand contour from an input depth image, and obtain the fingertips and finger-valleys of the contour using the local extrema of a modified CSS map of the contour. Then we recover the undetected fingertips according to the local change of depths of points in the interior of the contour. Compared with traditional appearance-based approaches using either angle detectors or convex hull detectors, the modified CSS descriptor extracts the fingertips and finger-valleys more precisely since it is more robust to noisy or corrupted data; moreover, the local extrema of depths recover the fingertips of bending fingers well while traditional appearance-based approaches hardly work without matching models of hands. Experimental results show that our method captures the hand articulations more precisely compared with three state-of-the-art appearance-based approaches.







{kind=link}