开展抓取检测是为了确定机器人夹持器的位姿,以便机器人可以准确地夹取和移动物体。早期的抓取检测方法通常采用以下2种方式[1 -2 ] :1)直接将输入数据导入已知的抓取模板;2)通过对某些特征空间中的形状特征进行分析来实现抓取检测。然而,上述方法存在一定的局限性,如只适用于已知对象、计算复杂度高等,导致其难以被广泛应用。
随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] 。CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务。文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置。然而,大量的抓取建议造成抓取速度相对较慢。为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率。Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案。
在机器人抓取检测任务中,高效的特征提取方法对于连续抓取配置的生成来说是至关重要的。然而,传统的CNN在局部特征提取上表现优异,但在全局特征提取方面存在局限性。为了提高CNN的全局特征提取能力,现有方法通常采用更深层次的网络和降采样机制,但这会导致模型的空间分辨率下降以及模型的复杂度提高、计算量增加等。因此,有必要探索更加优异的特征提取方法和关系映射模型,以实现机器人对待抓取对象的全局特征和局部特征进行高效建模,从而生成更加合理的抓取配置。
近年来,Transformer的出现提高了神经网络模型获取远程依赖关系信息的能力[14 ] 。Transformer通过自注意力机制和前馈神经网络实现了对长序列的建模,具有良好的全局上下文特征提取能力和并行计算能力,其被广泛应用于自然语言处理领域。为了突破CNN的局限性,学者们将Transformer引入了计算机视觉领域。例如:Dosovitskiy等[15 ] 提出的视觉Transformer(vision Transformer, ViT)首次将标准的Transformer架构应用于视觉任务,取得了令人满意的效果。Zhang等[16 ] 提出了一种CNN与ViT相结合的方法,通过在输入层、前馈层和Transformer顶部引入卷积来加强模型归纳偏置的能力。Liu等[17 ] 提出了Swin-Transformer模型,通过使用移动窗口构建分层特征映射来实现对输入图像的处理,相比于ViT中自注意力计算的二次复杂度,Swin-Transformer实现了线性复杂度。Wang等[18 ] 针对各种密集预测任务,提出了一种金字塔视觉Transformer(pyramid vision Transformer, PVT)。Wu等[19 ] 在PVT的基础上提出了金字塔池化Transformer(P2T),其能够输出多尺度特征。此外,一些研究表明[20 -21 ] ,Transformer架构在某些特定视觉任务中的检测精度超越了CNN。
针对目前机器人在复杂环境下执行多目标抓取任务时仍面临抓取位姿估计不准确的问题,结合Transformer在视觉任务中的出色表现,笔者提出了一种基于Transformer的抓取检测模型——PTGNet(pyramid Transformer grasp network),该模型可通过多模态图像输入实现像素级的抓取位姿输出。为验证PTGNet的准确率和鲁棒性,首先分别在单对象和多对象数据集上对PTGNet进行训练与测试,并与其他模型进行准确率比较。随后,在仿真环境和真实物理环境中开展机械臂抓取实验,以验证PTGNet在实际应用中的可行性,旨在为复杂环境下机器人实现抓取检测任务提供一种可行的解决方案。
1 PTGNet 结构
1.1 PTGNet 概述
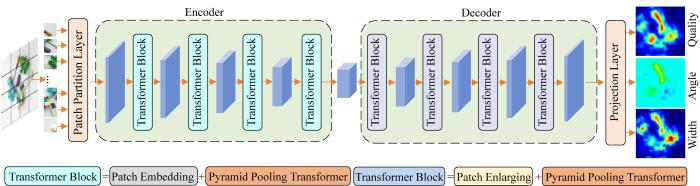
本文所提出的PTGNet采用编码器-解码器结构,其架构如图1 所示。该模型利用注意力层从输入的多通道图像中学习全局上下文信息,以提取对机器人抓取有用的特征信息;在解码过程中,结合编码器获得的特征图,通过上采样来执行像素级的抓取预测。为了更好地结合Transformer技术与机器人视觉抓取任务,本文从以下几个方面对PTGNet的框架进行设计,以提高其抓取检测性能。
图1
图1
PTGNet 结构
Fig.1
PTGNet structure
1)采用级联的编码器-解码器结构。编码器可利用自注意力机制强大的特征提取能力来获取有效的特征信息,并通过解码器推理出像素级的抓取位姿。
2)为了满足实际应用场景中的需求,采用具有金字塔池化(Pyramid Pooling)结构和多头自注意力(multi-head self-attention, MHSA)机制的Transformer模块。MHSA机制具有高度并行计算能力,与金字塔池化技术相结合能够大幅度地提高计算速度,满足实时性要求。
3)利用金字塔池化注意力层对局部和全局信息进行建模,以更好地捕捉全局上下文信息。此外,利用金字塔池化结构还能获取多尺度特征,增加了特征的丰富性和多样性,从而提高了抓取检测的准确性。
1.2 抓取表示
在机器人抓取检测任务中,除了要检测物体的抓取位置外,还要确定机器人夹持器的抓取姿势,故需要一种能够同时表示抓取位置、旋转角度和开口尺寸等信息的方法来表示机器人的抓取位姿。本文采用文献[22 ]中的五维抓取表示方法,即利用1个五维元组来表示抓取信息g :
g = x , y , w , h , θ (1)
式中:x 、y 表示抓取矩形中心点的横、纵坐标,即夹持器位置;θ 表示抓取矩形相对于图像水平方向的旋转角度(取逆时针方向为正方向),即夹持器的方向角;w 表示抓取矩形的宽度,即夹持器的开口距离;h 表示抓取矩形的高度,即夹持器的长度。
对于尺寸已知的夹持器,其抓取信息可简化为g = x , y , w , θ 13 ],本文将二维图像空间中的抓取信息G 表示为:
G = Q , A , W ∈ R 3 × W 1 × H 1 (2)
式中:Q 表示图像中所有像素的抓取质量的集合,抓取质量的取值为0~1之间的分数;A 、W 分别表示所有像素的抓取角度和抓取宽度的集合;W 1 、H 1 分别表示输入图像的宽度和高度。
1.3 编码器
在将多通道图像输入编码器之前,通过补丁分区层(Patch Partition Layer)将其分割成大小固定且不重叠的补丁(Patch)。具体地,对于一张高度为H 1 、宽度为W 1 、通道数为C 的图像,其可被分割成大小为p ×p ×C 的补丁,其中p 为正整数,则整张图像被分成了N (N =H 1 W 1 /p 2 )个补丁。每个补丁均为p ×p ×C 的三维矩阵,经展平拉直后可展开成含p ×p ×C 个元素的一维向量。随后,该一维向量被送入编码器中由1个线性投影层和1个可学习的位置编码组成的补丁嵌入(Patch Embedding)模块,从而将特征维度从p ×p ×C 扩展为C 1 ,最后输入Transformer层进行处理。
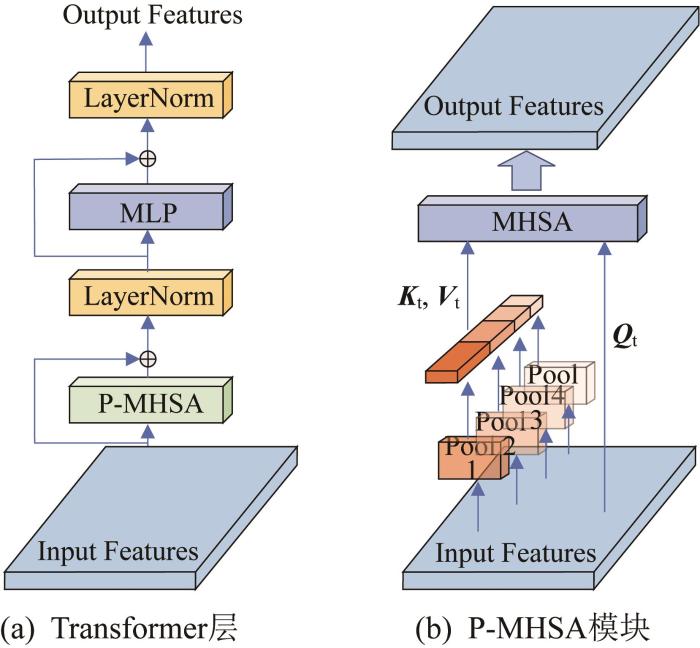
编码器由相同的Transformer层堆叠而成,每2个Transformer层之间有1个补丁嵌入模块。每个补丁嵌入模块包含1个补丁组连接操作,用于降低特征图的分辨率。Transformer层的基本组件为MHSA模块。本文将金字塔池化的思想应用到MHSA中,以降低MHSA的计算复杂度,并捕获丰富的全局上下文信息。金字塔池化的Transformer层的结构如图2 (a)所示,主要包含MLP(multi-layer perception,多层感知)模块、LayerNorm(层归一化)模块和P-MHSA(金字塔池化多头自注意力)模块。
图2
图2
金字塔池化的Transformer 层结构
Fig.2
Transformer layer structure with pyramid pooling
根据图2 (a),Transformer层的计算过程如下:
X a t t = L a y e r N o r m X + P - M H S A ( X ) X o u t = L a y e r N o r m X a t t + M L P ( X a t t ) (3)
式中: X X att 、 X out 分别表示P-MHSA模块的输入、输出和Transformer层的输出。
P-MHSA模块的结构如图2 (b)所示。首先,将输入 X X
P 1 = A v g P o o l 1 ( X ) P 2 = A v g P o o l 2 ( X ) ⋮ P n = A v g P o o l n ( X ) (4)
式中:P 1 P 2 P n n 表示池化层数目。
然后,将得到的金字塔池化特征图输入到深度卷积中,以进行相对位置编码:
P i p o s = D W C o n v P i + P i , i = 1 , 2 , ⋯ , n (5)
式中:DWConv表示卷积核大小为3×3的深度卷积,P i p o s
接着,将所有金字塔池化特征图展平并连接为序列 P P X P X X P
P = L a y e r N o r m C o n c a t P 1 p o s , P 2 p o s , ⋯ , P n p o s (6)
最后,P-MHSA模块通过线性变换将原始输入特征映射到查询向量 Q t 、键向量 K t 和值向量 V t ,以便开展后续的自注意力计算。上述向量的定义如下:
Q t = X W Q , K t = P W K , V t = P W V (7)
M = S o f t m a x Q t × K t T d K × V t (8)
式中: WQ 、 WK 、 WV Q t 、 K t 和 V t 的权重矩阵, M d K K t 的通道维度。
由于 K t 和 V t 的长度比 X K t 和 V t 包含了高度抽象的多尺度信息,使得P-MHSA模块具有更强的全局上下文信息建模能力。
1.4 解码器
解码器的功能是将从编码器中获取的特征图转化为机器人夹持器的抓取位姿。同样的,解码器也是由相同的Transformer层堆叠而成的,在每2个Transformer层之间都有1个补丁扩张(Patch Enlarging)模块,以增大特征图的分辨率,并在将特征图输入线性投射层之前,将特征图的分辨率扩大到与网络输入的RGB-D图像相同。Transformer层能够在更高抽象层次上理解图像,并通过学习感兴趣区域的特征来生成抓取热图,共生成3张与输入图像大小相同的抓取热图:抓取质量热图(Quality)、抓取角度热图(Angle)和抓取宽度热图(Width)。其中,抓取质量集合Q 中的像素范围为0~1,抓取宽度集合W 中的像素值属于[0, 100],抓取角度集合A 中的像素值属于[-π/2, π/2]。为了使每个像素的抓取角度θ 在该区间内一一映射,将θ 解码成sin 2θ 和cos 2θ 两个分量,则最终的抓取角度θ = 0.5 a r c t a n ( s i n 2 θ / c o s 2 θ ) G 与真实抓取信息G ^ F : X ' → G ^ X ′为输入数据。定义损失函数如下:
L G , G ^ = 1 m ∑ j = 1 m z k , j (9)
z k , j = 0.5 k - k ^ 2 , k - k ^ < 1 k - k ^ - 0.5 , 其他 (10)
式中:k 表示预测值,k ^ k ∈ { Q , W , A } m 表示训练样本数。
最终的抓取位置通过检索抓取质量热图中最高置信度对应的位置来确定,随后从抓取角度热图和抓取宽度热图中提取相应位置对应的预测抓取角度和抓取宽度,定义为:
S = a r g m a x p o s Q (11)
使用像素级抓取表示可以快速地获取抓取位姿,同时能够更好地处理物体表面的形状和纹理等细节信息。相较于其他的抓取表示方法,像素级抓取表示能够在一次前向传播中获取全局视觉场景中最佳的抓取位姿,且无需生成多个抓取候选对象,从而避免了因生成候选对象过多而导致计算量过大的问题,这意味着能够有效地处理大规模数据集,从而提高抓取成功率。
2 实验验证
2.1 评价指标
为了统一对比不同抓取检测模型的性能,采用Jiang等[22 ] 提出的矩形度量来评估模型预测的抓取矩形的质量。根据矩形度量,当抓取预测满足以下条件时,认为抓取预测是正确的:
1)预测的抓取角度与真实的抓取角度之间的差异在30°以内。
2)预测的抓取矩形与真实的抓取矩形之间的Jaccard指数大于0.25。Jaccard指数的定义如下:
g p ⋂ g t g p ⋃ g t > 0.25 (12)
式中:g p 表示预测的抓取矩形,g t 表示真实的抓取矩形。
2.2 实施方案
本文提出的PTGNet采用PyTorch 1.7深度学习框架和CUDA 11.0,在具有12 GB显存的NVIDIA Geforce RTX 3060 GPU上进行训练。同时,使用Adam作为优化器,初始学习速率设为0.001,批处理大小设为16。在训练过程中,将90%的数据集作为训练集,剩下的10%作为测试集。在PTGNet中,编码器和解码器均包含4个Transformer层,每层的注意力头数量分别为1,2,4,8;P-MHSA模块中并行池化操作的数量设为4。此外,PTGNet使用不同的池化比来构建不同阶段的Transformer层:第1阶段,池化比为12,16,20,24;第2阶段,池化比为6,8,10,12;第3阶段,池化比为3,4,5,6;最后阶段,池化比为1,2,3,4。
2.3 单对象抓取检测
本文采用2种典型的单对象抓取数据集来评估PTGNet的性能,即Cornell数据集[11 ] 和Jacquard数据集[23 ] 。
1)Cornell数据集。Cornell数据集包含244个不同对象在不同位姿下的885张RGB图像及对应的D图像,每个对象均标注多个抓取矩形。由于Cornell数据集相对较小,为了避免过拟合,采用数据增强方式,如随机剪切、翻转和随机亮度等,以增加图像数量。
2)Jacquard数据集。Jacquard数据集是一个由CAD(computer aided design,计算机辅助设计)模型组成的模拟抓取数据集,包含约11 000个对象在不同场景下的54 000张RGB-D图像,且每张图像均标记了真实的抓取矩形,共标注了约110万个抓取矩形。由于Jacquard数据集的规模足够大,无需进行数据扩充来避免过拟合问题。
为了与相关文献的结果进行比较,采用图像分割和对象分割方式对Cornell数据集进行划分。
1)图像分割。将Cornell数据集中所有的图像随机划分为训练集和测试集。因此,在测试过程中可能会出现与训练集中相同的物体,但该物体的放置姿势与训练集中不同,可用于测试模型对新位姿的检测性能。
2)对象分割。将Cornell数据集中所有的图像按物体类别进行划分。因此,在测试过程中不会出现与训练集中相同的物体,可用于测试模型对新物体的泛化能力。
由于Cornell数据集相对较小,本文采用五倍交叉验证,同时考虑输入模式和时间,以确保与其他抓取检测模型进行准确率对比时更加公平和全面。不同抓取检测模型在Cornell数据集上的准确率如表1 所示。由表1 可知,当PTGNet只以D图像作为输入时,其准确率达到了95.4%,当以RGB-D图像作为输入时,准确率达到了98.2%。不同抓取检测模型在Jacquard数据集上的准确率如表2 所示。表2 结果同样表明,PTGNet的性能比传统CNN优异,且在以RGB、D和RGB-D三种图像作为输入时表现良好。综上,具有自注意力机制的抓取检测模型更适用于视觉抓取任务,但由于Transformer架构通常具有较多的可学习参数和较高的计算复杂度,需要较多的计算资源来处理大规模参数,因此具有自注意力机制的PTGNet与GR-ConvNet(generative residual convolutional neural network,生成残差卷积神经网络)之间在推理速度上还存在一定的差距。
为了更加直观地了解PTGNet的性能,对PTGNet在Cornell数据集和Jacquard数据集上的部分检测结果进行了可视化处理,分别如图3 和图4 所示,从上至下分别为抓取图像(Grasp)、抓取质量热图(Quality)、抓取角度热图(Angle)和抓取宽度热图(Width)。
图3
图3
PTGNet 在Cornell 数据集上的部分检测结果
Fig.3
Partial detection results of PTGNet on Cornell dataset
图4
图4
PTGNet 在Jacquard 数据集上的部分检测结果
Fig.4
Partial detection results of PTGNet on Jacquard dataset
2.4 多对象抓取检测
考虑到机器人在实际应用中需要在复杂的多目标环境下执行抓取任务,本文采用杂乱场景下的多目标数据集来测试PTGNet的性能,并与GG-CNN和GR-ConvNet进行比较。
首先,利用文献[31 ]中的多对象(multi-object)数据集对PTGNet的性能进行测试,并与GG-CNN和GR-ConvNet的检测结果进行对比。多对象数据集是按照Cornell数据集的方式进行收集的,共包含97张RGB-D图像,每张图像中至少包含3个不同的物体。上述3种抓取检测模型在多对象数据集上的部分检测结果如图5 所示。
图5
图5
不同抓取检测模型在多对象数据集上的部分检测结果
Fig.5
Partial detection results of different grasping detection models on multi-object dataset
为了进一步测试PTGNet的性能,利用文献[32 ]中的杂乱(clutter)数据集进行分析。该数据集包含505张RGB-D图像,所有对象均随机放置,且每张图像中至少包含1个物体。3种抓取检测模型在杂乱数据集上的部分检测结果如图6 所示。不同抓取检测模型在2种多目标数据集上的准确率如表3 所示。
图6
图6
不同抓取检测模型在杂乱数据集上的部分检测结果
Fig.6
Partial detection results of different grasping detection models on clutter dataset
上述检测结果显示,在复杂的多目标任务场景中,GG-CNN和GR-ConvNet存在一定的局限性。这2种模型缺少自注意力机制,感受野和上下文信息感知能力有限,导致难以实现抓取区域的准确检测和聚焦,且无法有效地分割抓取物体和背景,进而造成一些物体无法被准确地检测到。此外,这2种模型也无法准确地检测物体的方向,可能会导致预测抓取矩形的旋转角度、大小与实际物体存在较大偏差,这些因素均会对机器人成功执行抓取任务产生影响。而本文提出的PTGNet基本可以克服以上缺陷。P-MHSA模块中自注意力机制的强大特性使PTGNet具备更强的全局上下文建模能力,可在全局范围内感知目标与环境的关系。与基于卷积组件的抓取检测模型相比,PTGNet不仅能够准确地识别不同物体的形状和大小,而且能准确地分割物体与背景,从而实现准确的抓取定位。此外,PTGNet在面对多目标的复杂环境时表现出更好的鲁棒性。
2.5 仿真实验
为了进一步评估PTGNet和GG-CNN的性能,采用PyBullet模块搭建仿真环境,以开展机械臂抓取实验。仿真环境中包括具有Robotiq 2F-85夹持器的UR5e机械臂和RGB-D相机,分别用于执行抓取任务和感知待抓取模拟对象。待抓取模拟对象是基于OCRTOC(open cloud robot table organization challenge,云端机器人桌面整理挑战赛)[33 ] 提供的数据创建的。
在每次仿真实验开始前,先为机械臂设置初始位姿,并指示机械臂在抓取物体后将其放到目标位置处。然后,随机选择物体并以任意位姿放置在工作区域内,分别使用PTGNet和GG-CNN对工作区域内物体的抓取位姿进行预测,并选择具有最高抓取质量得分的抓取矩形作为最佳抓取位姿来执行抓取任务,以将物体放到目标位置处。
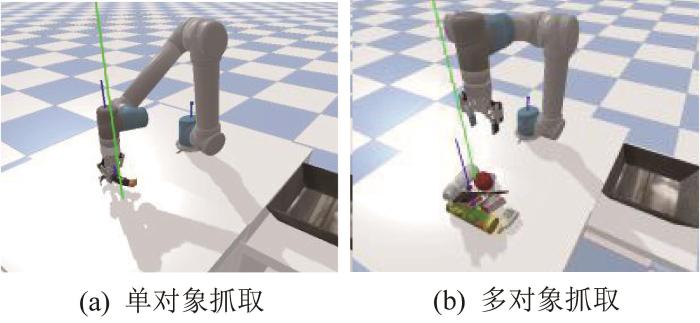
为了评估PTGNet和GG-CNN在不同场景下的性能和鲁棒性,在单对象和多对象任务场景下开展测试,如图7 所示。在单对象任务场景中,随机选择一个物体并将其放在工作区域内,然后机械臂执行抓取和放置任务。在多对象任务场景中,随机选择多个物体并将其随机放置在工作区域内,然后机械臂反复执行抓取和放置任务,直到工作区域内没有物体。在2种任务场景下,机械臂分别基于PTGNet和GG-CNN执行180次抓取,并评估2种抓取检测模型的性能,结果如表4 所示。由表4 可知,所提出的PTGNet在单对象和多对象任务场景下的性能均显著优于GG-CNN,基于PTGNet的机械臂的抓取成功率分别提高了14.7个和17.2个百分点。
图7
图7
仿真环境下的机械臂抓取实验
Fig.7
Robot arm grasping experiment in simulation environment
2.6 现实实验
为了进一步验证PTGNet在实际应用中的准确性和适用性,在真实物理环境下采用Kinova Jaco2轻型机械臂和Inter RealSense D435i相机来开展抓取实验。为了确保对可抓取物体的良好视觉覆盖,将相机安装在机械臂的末端夹持器上,并在每次执行抓取任务前都拍摄工作区域内(640×480)像素的RGB图像和D图像。
为了有效地测试PTGNet的性能,在多目标杂乱场景下开展机械臂抓取实验,如图8 所示。在实验中,待抓取的目标对象由不同形状的物体构成,包括盒体和球体等形状规则的物体以及形状不规则的物体,共9种物体。将目标物体随机放置在工作区域内的不同位置和方向上,且物体类型均未知。在每次抓取实验中,PTGNet根据Inter RealSense D435i相机获取的RGB-D图像输出最佳的抓取位姿,随后机械臂根据规划轨迹运动至最佳抓取位姿。若机械臂将物体抓起并放到目标位置处,则视为抓取成功。通过这种实验方式,可客观评估PTGNet在实际应用中对复杂环境和未知物体的适应能力。
图8
图8
真实物理环境下的机械臂抓取实验
Fig.8
Robot arm grasping experiment in real physical environment
在本次实验中,机械臂基于PTGNet共执行180次抓取,记录成功抓取次数并计算抓取成功率,并与其他文献的结果进行对比,结果如表5 所示。结果表明,基于PTGNet的机械臂抓取成功率高达93.3%,显著高于其他抓取检测模型。由此说明,基于Transformer的抓取检测模型在实际应用中具有良好的泛化能力和移植性。实验结果进一步验证了本文方法的实用性和有效性。
3 结 论
本文提出了一种基于Transformer的抓取检测模型——PTGNet,该模型采用编码器-解码器结构,充分利用了Transformer强大的全局上下文建模能力,能够获取准确的抓取位姿估计,可有效地提高机器人在复杂环境中执行多物体抓取任务的成功率。
在Cornell和Jacquard数据集上的测试结果表明,PTGNet分别实现了98.2%和94.8%的检测准确率,明显优于其他抓取检测模型。在多目标数据集上的测试结果验证了PTGNet在处理复杂环境下的多目标抓取任务时的有效性。在仿真和真实物理环境下开展的机械臂抓取实验进一步验证了PTGNet在多目标检测和抓取方面的有效性和泛化能力。综上可知,所提出的PTGNet具有可行性和实用性,可为机器人在复杂环境中执行多目标视觉抓取任务提供有力的支持。同时,本文结果也为Transformer模块在其他视觉任务中的应用提供了参考。
参考文献
View Option
[1]
BICCHI A KUMAR V Robotic grasping and contact: a review
[C]//IEEE International Conference on Robotics and Automation . San Francisco, CA, Apr . 24 -28 , 2000 .
[本文引用: 1]
[2]
BUCHHOLZ D FUTTERLIEB M WINKELBACH S et al Efficient bin-picking and grasp planning based on depth data
[C]//2013 IEEE International Conference on Robotics and Automation . Karlsruhe , May 6-10 , 2013 .
[本文引用: 1]
[4]
李明 ,鹿朋 ,朱龙 ,等 基于RGB-D融合的密集遮挡抓取检测
[J].控制与决策 ,2023 ,38 (10 ):2867 -2874 .
[本文引用: 1]
LI M LU P ZHU L et al Densely occluded grasping objects detection based on RGB-D fusion
[J]. Control and Decision , 2023 , 38 (10 ): 2867 -2874 .
[本文引用: 1]
[5]
楚红雨 ,冷齐齐 ,张晓强 ,等 融入注意力机制的多模特征机械臂抓取位姿检测
[J].控制与决策 ,2024 ,39 (3 ):777 -785 .
[本文引用: 1]
CHU H Y LENG Q Q ZHANG X Q et al Multi-modal feature robotic arm grasping pose detection with attention mechanism
[J]. Control and Decision , 2024 , 39 (3 ): 777 -785 .
[本文引用: 1]
[6]
KUMRA S KANAN C Robotic grasp detection using deep convolutional neural networks
[C]//2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . Vancouver, Sep . 24 -28 , 2017 .
[本文引用: 2]
[7]
REDMON J ANGELOVA A Real-time grasp detection using convolutional neural networks
[C]//2015 IEEE International Conference on Robotics and Automation (ICRA) . Seattle, WA , May 26-30 , 2015 .
[本文引用: 1]
[8]
ZHANG H LAN X BAI S et al ROI-based robotic grasp detection for object overlapping scenes
[C]//2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . Macau, Nov . 3 -8 , 2019 .
[本文引用: 2]
[9]
ASIF U TANG J B HARRER S GraspNet: an efficient convolutional neural network for real-time grasp detection for low-powered devices
[C]//Proceedings of the 27th International Joint Conference on Artificial Intelligence . Stockholm, Jul . 13 -19 , 2018 .
[本文引用: 1]
[10]
ZHU X SUN L FAN Y et al 6-DOF contrastive grasp proposal network
[C]//2021 IEEE International Conference on Robotics and Automation (ICRA). Xi'an, May 30-Jun . 5 , 2021 .
[11]
LENZ I LEE H SAXENA A Deep learning for detecting robotic grasps
[J]. The International Journal of Robotics Research , 2015 , 34 (4/5 ): 705 -724 .
[本文引用: 4]
[12]
PARK D SEO Y SHIN D et al A single multi-task deep neural network with post-processing for object detection with reasoning and robotic grasp detection
[C]//2020 IEEE International Conference on Robotics and Automation(ICRA). Paris , May 31-Aug . 31 , 2020 .
[本文引用: 1]
[13]
MORRISON D CORKE P LEITNER J Learning robust, real-time, reactive robotic grasping
[J]. The International Journal of Robotics Research , 2020 , 39 (2/3 ): 183 -201 .
[本文引用: 5]
[14]
VASWANI A SHAZEER N PARMAR N et al Attention is all you need
[J]. Advances in Neural Information Processing Systems , 2017 , 30 : 1 -15 .
[本文引用: 1]
[15]
DOSOVITSKIY A BEYER L KOLESNIKOV A et al An image is worth 16 × 16 words: Transformers for image recognition at scale
[C]//International Conference on Learning Representations . Online , May 3-7 , 2021 .
[本文引用: 1]
[16]
ZHANG Z ZHANG H ZHAO L et al Nested hierarchical Transformer: towards accurate, data-efficient and interpretable visual understanding
[J]. Proceedings of the AAAI Conference on Artificial Intelligence. [S.l. ]: AAAI, 2022 : 3417 -3425 .
[本文引用: 1]
[17]
LIU Z LIN Y CAO Y et al Swin Transformer: hierarchical vision Transformer using shifted windows
[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal, QC, Oct . 10 -17 , 2021 .
[本文引用: 1]
[18]
WANG W XIE E LI X et al Pyramid vision Transformer: a versatile backbone for dense prediction without convolutions
[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal, QC, Oct . 10 -17 , 2021 .
[本文引用: 1]
[19]
WU Y H LIU Y ZHAN X et al P2T: pyramid pooling Transformer for scene understanding
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 2022(8 ): 1 -12 .
[本文引用: 1]
[20]
SI C YU W ZHOU P et al Inception Transformer
[J]. Advances in Neural Information Processing Systems , 2022 , 35 : 23495 -23509 .
[本文引用: 1]
[21]
YUAN L HOU Q JIANG Z et al Volo: vision outlooker for visual recognition
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2022 , 45 (5 ): 6575 -6586 .
[本文引用: 1]
[22]
JIANG Y MOSESON S SAXENA A Efficient grasping from RGBD images: learning using a new rectangle representation
[C]//2011 IEEE International Conference on Robotics and Automation . Shanghai , May 9-13 , 2011 .
[本文引用: 3]
[23]
DEPIERRE A DELLANDRÉA E CHEN L Jacquard: a large scale dataset for robotic grasp detection
[C]//2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . Madrid, Oct . 1 -5 , 2018 .
[本文引用: 2]
[24]
WANG Z LI Z WANG B et al Robot grasp detection using multimodal deep convolutional neural networks
[J]. Advances in Mechanical Engineering , 2016 , 8 (9 ): 1 -12 .
[本文引用: 1]
[25]
ASIF U BENNAMOUN M SOHEL F A RGB-D object recognition and grasp detection using hierarchical cascaded forests
[J]. IEEE Transactions on Robotics , 2017 , 33 (3 ): 547 -564 .
[本文引用: 1]
[26]
KARAOGUZ H JENSFELT P Object detection approach for robot grasp detection
[C]//2019 International Conference on Robotics and Automation (ICRA) . Montreal, QC , May 20-24 , 2019 .
[本文引用: 1]
[27]
GUO D SUN F LIU H et al A hybrid deep architecture for robotic grasp detection
[C]//2017 IEEE International Conference on Robotics and Automation (ICRA). Singapore , May 29-Jun . 2 , 2017 .
[本文引用: 1]
[28]
KUMRA S JOSHI S SAHIN F Antipodal robotic grasping using generative residual convolutional neural network
[C]//2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . Las Vegas, NV, Oct . 25 -29 , 2020 .
[本文引用: 3]
[29]
ZHOU X LAN X ZHANG H et al Fully convolutional grasp detection network with oriented anchor box
[C]//2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) . Madrid, Oct . 1 -5 , 2018 .
[本文引用: 1]
[30]
AINETTER S FRAUNDORFER F End-to-end trainable deep neural network for robotic grasp detection and semantic segmentation from RGB
[C]//2021 IEEE International Conference on Robotics and Automation (ICRA). Xi'an, May 30-Jun . 5 , 2021 .
[本文引用: 1]
[31]
CHU F J XU R VELA P A Real-world multiobject, multigrasp detection
[J]. IEEE Robotics and Automation Letters , 2018 , 3 (4 ): 3355 -3362 .
[本文引用: 2]
[32]
WANG D LIU C CHANG F et al High-performance pixel-level grasp detection based on adaptive grasping and grasp-aware network
[J]. IEEE Transactions on Industrial Electronics , 2021 , 69 (11 ): 11611 -11621 .
[本文引用: 1]
[33]
LIU Z LIU W QIN Y et al Ocrtoc: a cloud-based competition and benchmark for robotic grasping and manipulation
[J]. IEEE Robotics and Automation Letters , 2021 , 7 (1 ): 486 -493 .
[本文引用: 1]
Robotic grasping and contact: a review
1
2000
... 开展抓取检测是为了确定机器人夹持器的位姿,以便机器人可以准确地夹取和移动物体.早期的抓取检测方法通常采用以下2种方式[1 -2 ] :1)直接将输入数据导入已知的抓取模板;2)通过对某些特征空间中的形状特征进行分析来实现抓取检测.然而,上述方法存在一定的局限性,如只适用于已知对象、计算复杂度高等,导致其难以被广泛应用. ...
Efficient bin-picking and grasp planning based on depth data
1
2013
... 开展抓取检测是为了确定机器人夹持器的位姿,以便机器人可以准确地夹取和移动物体.早期的抓取检测方法通常采用以下2种方式[1 -2 ] :1)直接将输入数据导入已知的抓取模板;2)通过对某些特征空间中的形状特征进行分析来实现抓取检测.然而,上述方法存在一定的局限性,如只适用于已知对象、计算复杂度高等,导致其难以被广泛应用. ...
基于改进Mask Scoring R-CNN的铲齿磨损检测研究
1
2022
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
基于改进Mask Scoring R-CNN的铲齿磨损检测研究
1
2022
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
基于RGB-D融合的密集遮挡抓取检测
1
2023
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
基于RGB-D融合的密集遮挡抓取检测
1
2023
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
融入注意力机制的多模特征机械臂抓取位姿检测
1
2024
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
融入注意力机制的多模特征机械臂抓取位姿检测
1
2024
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
Robotic grasp detection using deep convolutional neural networks
2
2017
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
Real-time grasp detection using convolutional neural networks
1
2015
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
ROI-based robotic grasp detection for object overlapping scenes
2
2019
... Comparison of accuracy of different grasping detection models on Jacquard dataset
Table 2 文献 模型1) 准确率/% 检测用时/ms 文献[23 ] Jacquard(RGB-D) 74.2 文献[13 ] GG-CNN2(D) 84.0 20 文献[29 ] FCGN, ResNet-101(RGB) 91.8 117 文献[30 ] Det Seg Refine(RGB) 92.95 32.3 文献[8 ] ROI-GD(RGB) 93.6 文献[28 ] GR-ConvNet(RGB-D) 94.6 20 本文 PTGNet(D) 93.3 41.5 PTGNet(RGB) 93.7 41.9 PTGNet(RGB-D) 94.8 42.5
1)模型名称后括号中表示输入图像的类型. ...
... Comparison of grasping success rate of robot arm in real physical environment
Table 5 文献 抓取成功率/% 检测用时/ms 文献[11 ] 89.0(89/100) 1 350 文献[31 ] 89.0(89/100) 120 文献[8 ] 90.6(29/32) 40 文献[13 ] 92.0(110/120) 19 文献[28 ] 93.0(93/100) 20 本文 93.3(168/180) 41.1
<strong>3</strong> 结 论 本文提出了一种基于Transformer的抓取检测模型——PTGNet,该模型采用编码器-解码器结构,充分利用了Transformer强大的全局上下文建模能力,能够获取准确的抓取位姿估计,可有效地提高机器人在复杂环境中执行多物体抓取任务的成功率. ...
GraspNet: an efficient convolutional neural network for real-time grasp detection for low-powered devices
1
2018
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
6-DOF contrastive grasp proposal network
5
Deep learning for detecting robotic grasps
4
2015
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
... 本文采用2种典型的单对象抓取数据集来评估PTGNet的性能,即Cornell数据集[11 ] 和Jacquard数据集[23 ] . ...
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
... Comparison of grasping success rate of robot arm in real physical environment
Table 5 文献 抓取成功率/% 检测用时/ms 文献[11 ] 89.0(89/100) 1 350 文献[31 ] 89.0(89/100) 120 文献[8 ] 90.6(29/32) 40 文献[13 ] 92.0(110/120) 19 文献[28 ] 93.0(93/100) 20 本文 93.3(168/180) 41.1
<strong>3</strong> 结 论 本文提出了一种基于Transformer的抓取检测模型——PTGNet,该模型采用编码器-解码器结构,充分利用了Transformer强大的全局上下文建模能力,能够获取准确的抓取位姿估计,可有效地提高机器人在复杂环境中执行多物体抓取任务的成功率. ...
A single multi-task deep neural network with post-processing for object detection with reasoning and robotic grasp detection
1
31
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
Learning robust, real-time, reactive robotic grasping
5
2020
... 随着深度学习算法的快速发展,卷积神经网络(convolutional neural network, CNN)在机器人视觉感知领域取得了显著效果[3 ] .CNN可以自主地从图像中学习特征,通过最大程度地利用图像信息来获取高度抽象和鲁棒的视觉特征,且不需要预定义的特征,能够直接预测彩色(RGB)图像或深度(depth, D)图像中所有可能的抓取配置[4 -5 ] ,可以很好地处理未知对象的抓取任务.文献[6 -11 ]通过引入深度神经网络的两阶段策略来执行抓取检测任务,即生成大量抓取候选框并评估其质量,以识别最佳的抓取配置.然而,大量的抓取建议造成抓取速度相对较慢.为此,Park等[12 ] 提出了一种基于单阶段深度神经网络的机器人抓取检测方法,该方法可以同时预测不同对象的位置、抓取配置以及操作关系,避免了多阶段深度神经网络架构的复杂性和低效率.Morrison等[13 ] 开发了一种生成式抓取卷积神经网络(generative grasping convolutional neural network, GG-CNN)来执行抓取检测任务,其可为机器人视觉抓取提供一种轻量级的实时解决方案. ...
... 对于尺寸已知的夹持器,其抓取信息可简化为g = x , y , w , θ . 为了便于抓取,按照文献[13 ],本文将二维图像空间中的抓取信息G 表示为: ...
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
... Comparison of accuracy of different grasping detection models on Jacquard dataset
Table 2 文献 模型1) 准确率/% 检测用时/ms 文献[23 ] Jacquard(RGB-D) 74.2 文献[13 ] GG-CNN2(D) 84.0 20 文献[29 ] FCGN, ResNet-101(RGB) 91.8 117 文献[30 ] Det Seg Refine(RGB) 92.95 32.3 文献[8 ] ROI-GD(RGB) 93.6 文献[28 ] GR-ConvNet(RGB-D) 94.6 20 本文 PTGNet(D) 93.3 41.5 PTGNet(RGB) 93.7 41.9 PTGNet(RGB-D) 94.8 42.5
1)模型名称后括号中表示输入图像的类型. ...
... Comparison of grasping success rate of robot arm in real physical environment
Table 5 文献 抓取成功率/% 检测用时/ms 文献[11 ] 89.0(89/100) 1 350 文献[31 ] 89.0(89/100) 120 文献[8 ] 90.6(29/32) 40 文献[13 ] 92.0(110/120) 19 文献[28 ] 93.0(93/100) 20 本文 93.3(168/180) 41.1
<strong>3</strong> 结 论 本文提出了一种基于Transformer的抓取检测模型——PTGNet,该模型采用编码器-解码器结构,充分利用了Transformer强大的全局上下文建模能力,能够获取准确的抓取位姿估计,可有效地提高机器人在复杂环境中执行多物体抓取任务的成功率. ...
Attention is all you need
1
2017
... 近年来,Transformer的出现提高了神经网络模型获取远程依赖关系信息的能力[14 ] .Transformer通过自注意力机制和前馈神经网络实现了对长序列的建模,具有良好的全局上下文特征提取能力和并行计算能力,其被广泛应用于自然语言处理领域.为了突破CNN的局限性,学者们将Transformer引入了计算机视觉领域.例如:Dosovitskiy等[15 ] 提出的视觉Transformer(vision Transformer, ViT)首次将标准的Transformer架构应用于视觉任务,取得了令人满意的效果.Zhang等[16 ] 提出了一种CNN与ViT相结合的方法,通过在输入层、前馈层和Transformer顶部引入卷积来加强模型归纳偏置的能力.Liu等[17 ] 提出了Swin-Transformer模型,通过使用移动窗口构建分层特征映射来实现对输入图像的处理,相比于ViT中自注意力计算的二次复杂度,Swin-Transformer实现了线性复杂度.Wang等[18 ] 针对各种密集预测任务,提出了一种金字塔视觉Transformer(pyramid vision Transformer, PVT).Wu等[19 ] 在PVT的基础上提出了金字塔池化Transformer(P2T),其能够输出多尺度特征.此外,一些研究表明[20 -21 ] ,Transformer架构在某些特定视觉任务中的检测精度超越了CNN. ...
An image is worth 16 × 16 words: Transformers for image recognition at scale
1
2021
... 近年来,Transformer的出现提高了神经网络模型获取远程依赖关系信息的能力[14 ] .Transformer通过自注意力机制和前馈神经网络实现了对长序列的建模,具有良好的全局上下文特征提取能力和并行计算能力,其被广泛应用于自然语言处理领域.为了突破CNN的局限性,学者们将Transformer引入了计算机视觉领域.例如:Dosovitskiy等[15 ] 提出的视觉Transformer(vision Transformer, ViT)首次将标准的Transformer架构应用于视觉任务,取得了令人满意的效果.Zhang等[16 ] 提出了一种CNN与ViT相结合的方法,通过在输入层、前馈层和Transformer顶部引入卷积来加强模型归纳偏置的能力.Liu等[17 ] 提出了Swin-Transformer模型,通过使用移动窗口构建分层特征映射来实现对输入图像的处理,相比于ViT中自注意力计算的二次复杂度,Swin-Transformer实现了线性复杂度.Wang等[18 ] 针对各种密集预测任务,提出了一种金字塔视觉Transformer(pyramid vision Transformer, PVT).Wu等[19 ] 在PVT的基础上提出了金字塔池化Transformer(P2T),其能够输出多尺度特征.此外,一些研究表明[20 -21 ] ,Transformer架构在某些特定视觉任务中的检测精度超越了CNN. ...
Nested hierarchical Transformer: towards accurate, data-efficient and interpretable visual understanding
1
2022
... 近年来,Transformer的出现提高了神经网络模型获取远程依赖关系信息的能力[14 ] .Transformer通过自注意力机制和前馈神经网络实现了对长序列的建模,具有良好的全局上下文特征提取能力和并行计算能力,其被广泛应用于自然语言处理领域.为了突破CNN的局限性,学者们将Transformer引入了计算机视觉领域.例如:Dosovitskiy等[15 ] 提出的视觉Transformer(vision Transformer, ViT)首次将标准的Transformer架构应用于视觉任务,取得了令人满意的效果.Zhang等[16 ] 提出了一种CNN与ViT相结合的方法,通过在输入层、前馈层和Transformer顶部引入卷积来加强模型归纳偏置的能力.Liu等[17 ] 提出了Swin-Transformer模型,通过使用移动窗口构建分层特征映射来实现对输入图像的处理,相比于ViT中自注意力计算的二次复杂度,Swin-Transformer实现了线性复杂度.Wang等[18 ] 针对各种密集预测任务,提出了一种金字塔视觉Transformer(pyramid vision Transformer, PVT).Wu等[19 ] 在PVT的基础上提出了金字塔池化Transformer(P2T),其能够输出多尺度特征.此外,一些研究表明[20 -21 ] ,Transformer架构在某些特定视觉任务中的检测精度超越了CNN. ...
Swin Transformer: hierarchical vision Transformer using shifted windows
1
2021
... 近年来,Transformer的出现提高了神经网络模型获取远程依赖关系信息的能力[14 ] .Transformer通过自注意力机制和前馈神经网络实现了对长序列的建模,具有良好的全局上下文特征提取能力和并行计算能力,其被广泛应用于自然语言处理领域.为了突破CNN的局限性,学者们将Transformer引入了计算机视觉领域.例如:Dosovitskiy等[15 ] 提出的视觉Transformer(vision Transformer, ViT)首次将标准的Transformer架构应用于视觉任务,取得了令人满意的效果.Zhang等[16 ] 提出了一种CNN与ViT相结合的方法,通过在输入层、前馈层和Transformer顶部引入卷积来加强模型归纳偏置的能力.Liu等[17 ] 提出了Swin-Transformer模型,通过使用移动窗口构建分层特征映射来实现对输入图像的处理,相比于ViT中自注意力计算的二次复杂度,Swin-Transformer实现了线性复杂度.Wang等[18 ] 针对各种密集预测任务,提出了一种金字塔视觉Transformer(pyramid vision Transformer, PVT).Wu等[19 ] 在PVT的基础上提出了金字塔池化Transformer(P2T),其能够输出多尺度特征.此外,一些研究表明[20 -21 ] ,Transformer架构在某些特定视觉任务中的检测精度超越了CNN. ...
Pyramid vision Transformer: a versatile backbone for dense prediction without convolutions
1
2021
... 近年来,Transformer的出现提高了神经网络模型获取远程依赖关系信息的能力[14 ] .Transformer通过自注意力机制和前馈神经网络实现了对长序列的建模,具有良好的全局上下文特征提取能力和并行计算能力,其被广泛应用于自然语言处理领域.为了突破CNN的局限性,学者们将Transformer引入了计算机视觉领域.例如:Dosovitskiy等[15 ] 提出的视觉Transformer(vision Transformer, ViT)首次将标准的Transformer架构应用于视觉任务,取得了令人满意的效果.Zhang等[16 ] 提出了一种CNN与ViT相结合的方法,通过在输入层、前馈层和Transformer顶部引入卷积来加强模型归纳偏置的能力.Liu等[17 ] 提出了Swin-Transformer模型,通过使用移动窗口构建分层特征映射来实现对输入图像的处理,相比于ViT中自注意力计算的二次复杂度,Swin-Transformer实现了线性复杂度.Wang等[18 ] 针对各种密集预测任务,提出了一种金字塔视觉Transformer(pyramid vision Transformer, PVT).Wu等[19 ] 在PVT的基础上提出了金字塔池化Transformer(P2T),其能够输出多尺度特征.此外,一些研究表明[20 -21 ] ,Transformer架构在某些特定视觉任务中的检测精度超越了CNN. ...
P2T: pyramid pooling Transformer for scene understanding
1
2022
... 近年来,Transformer的出现提高了神经网络模型获取远程依赖关系信息的能力[14 ] .Transformer通过自注意力机制和前馈神经网络实现了对长序列的建模,具有良好的全局上下文特征提取能力和并行计算能力,其被广泛应用于自然语言处理领域.为了突破CNN的局限性,学者们将Transformer引入了计算机视觉领域.例如:Dosovitskiy等[15 ] 提出的视觉Transformer(vision Transformer, ViT)首次将标准的Transformer架构应用于视觉任务,取得了令人满意的效果.Zhang等[16 ] 提出了一种CNN与ViT相结合的方法,通过在输入层、前馈层和Transformer顶部引入卷积来加强模型归纳偏置的能力.Liu等[17 ] 提出了Swin-Transformer模型,通过使用移动窗口构建分层特征映射来实现对输入图像的处理,相比于ViT中自注意力计算的二次复杂度,Swin-Transformer实现了线性复杂度.Wang等[18 ] 针对各种密集预测任务,提出了一种金字塔视觉Transformer(pyramid vision Transformer, PVT).Wu等[19 ] 在PVT的基础上提出了金字塔池化Transformer(P2T),其能够输出多尺度特征.此外,一些研究表明[20 -21 ] ,Transformer架构在某些特定视觉任务中的检测精度超越了CNN. ...
Inception Transformer
1
2022
... 近年来,Transformer的出现提高了神经网络模型获取远程依赖关系信息的能力[14 ] .Transformer通过自注意力机制和前馈神经网络实现了对长序列的建模,具有良好的全局上下文特征提取能力和并行计算能力,其被广泛应用于自然语言处理领域.为了突破CNN的局限性,学者们将Transformer引入了计算机视觉领域.例如:Dosovitskiy等[15 ] 提出的视觉Transformer(vision Transformer, ViT)首次将标准的Transformer架构应用于视觉任务,取得了令人满意的效果.Zhang等[16 ] 提出了一种CNN与ViT相结合的方法,通过在输入层、前馈层和Transformer顶部引入卷积来加强模型归纳偏置的能力.Liu等[17 ] 提出了Swin-Transformer模型,通过使用移动窗口构建分层特征映射来实现对输入图像的处理,相比于ViT中自注意力计算的二次复杂度,Swin-Transformer实现了线性复杂度.Wang等[18 ] 针对各种密集预测任务,提出了一种金字塔视觉Transformer(pyramid vision Transformer, PVT).Wu等[19 ] 在PVT的基础上提出了金字塔池化Transformer(P2T),其能够输出多尺度特征.此外,一些研究表明[20 -21 ] ,Transformer架构在某些特定视觉任务中的检测精度超越了CNN. ...
Volo: vision outlooker for visual recognition
1
2022
... 近年来,Transformer的出现提高了神经网络模型获取远程依赖关系信息的能力[14 ] .Transformer通过自注意力机制和前馈神经网络实现了对长序列的建模,具有良好的全局上下文特征提取能力和并行计算能力,其被广泛应用于自然语言处理领域.为了突破CNN的局限性,学者们将Transformer引入了计算机视觉领域.例如:Dosovitskiy等[15 ] 提出的视觉Transformer(vision Transformer, ViT)首次将标准的Transformer架构应用于视觉任务,取得了令人满意的效果.Zhang等[16 ] 提出了一种CNN与ViT相结合的方法,通过在输入层、前馈层和Transformer顶部引入卷积来加强模型归纳偏置的能力.Liu等[17 ] 提出了Swin-Transformer模型,通过使用移动窗口构建分层特征映射来实现对输入图像的处理,相比于ViT中自注意力计算的二次复杂度,Swin-Transformer实现了线性复杂度.Wang等[18 ] 针对各种密集预测任务,提出了一种金字塔视觉Transformer(pyramid vision Transformer, PVT).Wu等[19 ] 在PVT的基础上提出了金字塔池化Transformer(P2T),其能够输出多尺度特征.此外,一些研究表明[20 -21 ] ,Transformer架构在某些特定视觉任务中的检测精度超越了CNN. ...
Efficient grasping from RGBD images: learning using a new rectangle representation
3
2011
... 在机器人抓取检测任务中,除了要检测物体的抓取位置外,还要确定机器人夹持器的抓取姿势,故需要一种能够同时表示抓取位置、旋转角度和开口尺寸等信息的方法来表示机器人的抓取位姿.本文采用文献[22 ]中的五维抓取表示方法,即利用1个五维元组来表示抓取信息g : ...
... 为了统一对比不同抓取检测模型的性能,采用Jiang等[22 ] 提出的矩形度量来评估模型预测的抓取矩形的质量.根据矩形度量,当抓取预测满足以下条件时,认为抓取预测是正确的: ...
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
Jacquard: a large scale dataset for robotic grasp detection
2
2018
... 本文采用2种典型的单对象抓取数据集来评估PTGNet的性能,即Cornell数据集[11 ] 和Jacquard数据集[23 ] . ...
... Comparison of accuracy of different grasping detection models on Jacquard dataset
Table 2 文献 模型1) 准确率/% 检测用时/ms 文献[23 ] Jacquard(RGB-D) 74.2 文献[13 ] GG-CNN2(D) 84.0 20 文献[29 ] FCGN, ResNet-101(RGB) 91.8 117 文献[30 ] Det Seg Refine(RGB) 92.95 32.3 文献[8 ] ROI-GD(RGB) 93.6 文献[28 ] GR-ConvNet(RGB-D) 94.6 20 本文 PTGNet(D) 93.3 41.5 PTGNet(RGB) 93.7 41.9 PTGNet(RGB-D) 94.8 42.5
1)模型名称后括号中表示输入图像的类型. ...
Robot grasp detection using multimodal deep convolutional neural networks
1
2016
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
RGB-D object recognition and grasp detection using hierarchical cascaded forests
1
2017
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
Object detection approach for robot grasp detection
1
2019
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
A hybrid deep architecture for robotic grasp detection
1
2
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
Antipodal robotic grasping using generative residual convolutional neural network
3
2020
... Comparison of accuracy of different grasping detection models on Cornell dataset
Table 1 文献 模型1) 准确率/% 检测用时/ms 图像分割 对象分割 文献[22 ] Fast Search(RGB-D) 60.5 58.3 5 000 文献[13 ] GG-CNN(D) 73.0 69.0 19 文献[11 ] SAE(RGB-D) 73.9 75.6 1 350 文献[24 ] Two-stage closed-loop(RGB-D) 85.3 140 文献[7 ] AlexNet, MultiGrasp(RGB-D) 88.0 87.1 76 文献[25 ] STEM-CaRFs(RGB-D) 88.2 87.5 文献[26 ] GRPN(RGB) 88.7 200 文献[6 ] ResNet-50x2(RGB-D) 89.2 88.9 103 文献[9 ] GraspNet(RGB-D) 90.2 90.6 24 文献[27 ] ZF-Net(RGB-D) 93.2 89.1 文献[28 ] GR-ConvNet(RGB-D) 97.7 96.6 20 本文 PTGNet(D) 95.4 95.0 40.4 PTGNet(RGB) 96.8 95.2 40.7 PTGNet(RGB-D) 98.2 96.9 41.1
1)模型名称后括号中表示输入图像的类型. ...
... Comparison of accuracy of different grasping detection models on Jacquard dataset
Table 2 文献 模型1) 准确率/% 检测用时/ms 文献[23 ] Jacquard(RGB-D) 74.2 文献[13 ] GG-CNN2(D) 84.0 20 文献[29 ] FCGN, ResNet-101(RGB) 91.8 117 文献[30 ] Det Seg Refine(RGB) 92.95 32.3 文献[8 ] ROI-GD(RGB) 93.6 文献[28 ] GR-ConvNet(RGB-D) 94.6 20 本文 PTGNet(D) 93.3 41.5 PTGNet(RGB) 93.7 41.9 PTGNet(RGB-D) 94.8 42.5
1)模型名称后括号中表示输入图像的类型. ...
... Comparison of grasping success rate of robot arm in real physical environment
Table 5 文献 抓取成功率/% 检测用时/ms 文献[11 ] 89.0(89/100) 1 350 文献[31 ] 89.0(89/100) 120 文献[8 ] 90.6(29/32) 40 文献[13 ] 92.0(110/120) 19 文献[28 ] 93.0(93/100) 20 本文 93.3(168/180) 41.1
<strong>3</strong> 结 论 本文提出了一种基于Transformer的抓取检测模型——PTGNet,该模型采用编码器-解码器结构,充分利用了Transformer强大的全局上下文建模能力,能够获取准确的抓取位姿估计,可有效地提高机器人在复杂环境中执行多物体抓取任务的成功率. ...
Fully convolutional grasp detection network with oriented anchor box
1
2018
... Comparison of accuracy of different grasping detection models on Jacquard dataset
Table 2 文献 模型1) 准确率/% 检测用时/ms 文献[23 ] Jacquard(RGB-D) 74.2 文献[13 ] GG-CNN2(D) 84.0 20 文献[29 ] FCGN, ResNet-101(RGB) 91.8 117 文献[30 ] Det Seg Refine(RGB) 92.95 32.3 文献[8 ] ROI-GD(RGB) 93.6 文献[28 ] GR-ConvNet(RGB-D) 94.6 20 本文 PTGNet(D) 93.3 41.5 PTGNet(RGB) 93.7 41.9 PTGNet(RGB-D) 94.8 42.5
1)模型名称后括号中表示输入图像的类型. ...
End-to-end trainable deep neural network for robotic grasp detection and semantic segmentation from RGB
1
5
... Comparison of accuracy of different grasping detection models on Jacquard dataset
Table 2 文献 模型1) 准确率/% 检测用时/ms 文献[23 ] Jacquard(RGB-D) 74.2 文献[13 ] GG-CNN2(D) 84.0 20 文献[29 ] FCGN, ResNet-101(RGB) 91.8 117 文献[30 ] Det Seg Refine(RGB) 92.95 32.3 文献[8 ] ROI-GD(RGB) 93.6 文献[28 ] GR-ConvNet(RGB-D) 94.6 20 本文 PTGNet(D) 93.3 41.5 PTGNet(RGB) 93.7 41.9 PTGNet(RGB-D) 94.8 42.5
1)模型名称后括号中表示输入图像的类型. ...
Real-world multiobject, multigrasp detection
2
2018
... 首先,利用文献[31 ]中的多对象(multi-object)数据集对PTGNet的性能进行测试,并与GG-CNN和GR-ConvNet的检测结果进行对比.多对象数据集是按照Cornell数据集的方式进行收集的,共包含97张RGB-D图像,每张图像中至少包含3个不同的物体.上述3种抓取检测模型在多对象数据集上的部分检测结果如图5 所示. ...
... Comparison of grasping success rate of robot arm in real physical environment
Table 5 文献 抓取成功率/% 检测用时/ms 文献[11 ] 89.0(89/100) 1 350 文献[31 ] 89.0(89/100) 120 文献[8 ] 90.6(29/32) 40 文献[13 ] 92.0(110/120) 19 文献[28 ] 93.0(93/100) 20 本文 93.3(168/180) 41.1
<strong>3</strong> 结 论 本文提出了一种基于Transformer的抓取检测模型——PTGNet,该模型采用编码器-解码器结构,充分利用了Transformer强大的全局上下文建模能力,能够获取准确的抓取位姿估计,可有效地提高机器人在复杂环境中执行多物体抓取任务的成功率. ...
High-performance pixel-level grasp detection based on adaptive grasping and grasp-aware network
1
2021
... 为了进一步测试PTGNet的性能,利用文献[32 ]中的杂乱(clutter)数据集进行分析.该数据集包含505张RGB-D图像,所有对象均随机放置,且每张图像中至少包含1个物体.3种抓取检测模型在杂乱数据集上的部分检测结果如图6 所示.不同抓取检测模型在2种多目标数据集上的准确率如表3 所示. ...
Ocrtoc: a cloud-based competition and benchmark for robotic grasping and manipulation
1
2021
... 为了进一步评估PTGNet和GG-CNN的性能,采用PyBullet模块搭建仿真环境,以开展机械臂抓取实验.仿真环境中包括具有Robotiq 2F-85夹持器的UR5e机械臂和RGB-D相机,分别用于执行抓取任务和感知待抓取模拟对象.待抓取模拟对象是基于OCRTOC(open cloud robot table organization challenge,云端机器人桌面整理挑战赛)[33 ] 提供的数据创建的. ...









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}