

近年来,深度学习模型在径流预测中取得了显著进展. 其中,长短期记忆网络(LSTM)[20-23]通过引入门控机制有效解决了传统循环神经网络(recurrent neural network,RNN)梯度问题,能够出色地捕捉长短期依赖关系[24-26]. 但在处理极长序列时仍存在稳定性问题. 为此,研究者们开发了多种混合架构以融合不同模型的优势. 王万良等[27]提出结合时间卷积网络(temporal convolutional network,TCN)和LSTM的模型能够同时捕捉局部和长期依赖关系. Dai等[28]提出基于双阶段注意力(dual-stage attention,DSA)的多模态深度学习(mutimodal deep learning,MDL)模型DSAMDL,该模型结合了一维卷积、双向长短期记忆网络(bidirectional long short-term memory,Bi-LSTM)和DSA的优势,提高了预测的可靠性和可解释性.
尽管现有模型能够处理非线性关系,但在提取非平稳径流序列特征时仍显不足. 且其训练过程需要耗费大量时间以寻找最优解,为此,信号分解方法与优化算法被广泛应用于深度学习模型. 变分模态分解(variational mode decomposition,VMD)[29-30]通过频域分解有效地改善了水文序列非平稳问题[31];Yu等[32]提出基于自适应傅里叶分解模型(adaptive Fourier decomposition model,AFDM)和多尺度时间卷积网络(multi-scale temporal convolutional network,MTCN)的AFDM-MTCN模型,并采用麻雀搜索算法(sparrow search algorithm,SSA)优化,但SSA存在收敛速度较慢、易陷入局部最优的问题,限制了模型预测精度的进一步提升.
针对上述问题,提出结合多特征融合(multi-feature fusion,MFF)和牛顿-拉夫逊优化(Newton-Raphson-based optimizer,NRBO)算法的LSTM模型MFF-NRBO-LSTM. 运用VMD分解历史径流序列,提取不同频率成分并与其他关键特征融合,并将NRBO应用于径流预测模型的超参数优化. 最终将所提模型应用于黄河流域径流预测,并通过对比和消融验证模型的有效性.
1. 研究区域
黄河作为中国第二长河,也是世界著名河流之一,起源于青海省巴颜喀拉山脉,干流全长约5 464 km,流经青海、宁夏、内蒙古、陕西、山西、河南和山东等省份,最终在山东省东营市垦利区流入渤海. 黄河流域面积约752 400 km2,支流繁多,含沙量很高. 黄河中下游地区的降雨量分布不均,容易引发洪涝和干旱灾害.
在黄河流域的众多研究站点中,花园口与利津具有特殊地位. 花园口站位于河南省郑州市,是黄河中下游的分界点,既承接了上游高原山地的来水来沙,又临近下游平原地区,是监测水文地形过渡变化的关键节点;而利津站位于山东省东营市,靠近黄河入海口,作为黄河入海前的最后一道“关卡”,其径流数据反映了整个黄河流域的水量及水沙输送的最终状态. 如图1所示,2个站点分别代表黄河中游与下游的典型水文地理特征,流域地形复杂多变,从高原、山地到平原,有着丰富的地貌特征,具有良好的代表性.
图 1
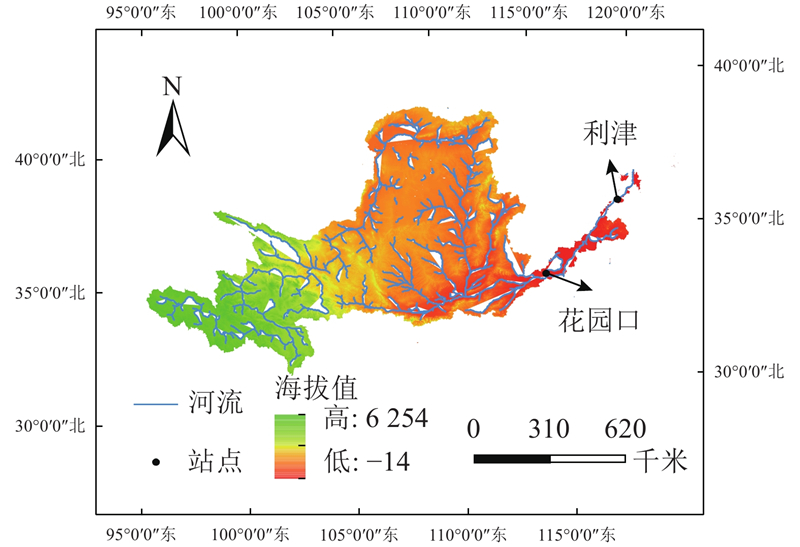
图 1 黄河流域地形地貌及水文站分布
Fig.1 Topography and distribution of hydrological stations in Yellow River Basin
表 1 站点经纬度坐标
Tab.1
| 站名 | 经度 | 纬度 |
| 花园口 | 113.66 | 34.90 |
| 利津 | 118.26 | 37.49 |
2. 相关技术
2.1. 影响因子相关性分析
Spearman秩相关系数[34]是一种非参数统计方法,用于衡量2个变量之间的单调关系. Spearman不要求变量之间存在线性关系,而是关注变量之间的单调性. 该方法通过将数据转换为秩(排名)来计算相关性,从而避免了异常值对结果的影响.
1) 排名:将2个变量的数据分别进行排序,并为每个数据点赋予秩. 如果数据中存在重复值,则为这些重复值分配相同的平均排名.
2) 计算秩差:对于每对数据点,计算它们在2个变量中的排名差值:
3) 计算相关系数:
式中:
2.2. 变分模态分解
VMD是一种非递归信号分解方法,其核心是通过构建变分优化问题,将时序自适应分解为若干具有特定中心频率和带宽的固有模式函数(intrinsic mode function,IMF):
式中:
该方法通过希尔伯特变换构造变分模型,并结合维纳滤波技术[35]约束IMF带宽,其优化目标是最小化各IMF中心频率带宽之和,同时满足模态分量之和等于原始信号的约束. 在求解过程中,引入二次惩罚项及拉格朗日乘子,其数学模型可表示为
式中:
2.3. LSTM模型
LSTM通过引入门控机制和记忆细胞改进RNN,有效捕捉序列中的长期依赖关系,其核心由输入门、遗忘门和输出门构成. 假设上一时刻的输出为
式中:
根据上个时间点的输出
式中:
式中:
式中:
2.4. NRBO优化算法
Sowmya等[36]提出基于牛顿-拉夫逊方法的新型优化算法NRBO. 该算法将种群分为探索者和开发者2种角色. 探索者负责在搜索空间中寻找新的潜在解,开发者利用这些发现来完善搜索过程. 探索者更新机制为
式中:
式中:NRSR为牛顿-拉弗森搜索规则,用于指导开发者向更好的解迁移. 陷阱避免算子(trap avoidance operator,TAO)更新规则为
式中:
3. 研究方法
采用相关性分析方法筛选模型的输入特征,并对历史径流序列进行VMD,将径流数据分解为多个IMF分量,捕捉径流在不同变化趋势下的信号特征,去除高频噪音,保留主要趋势. 将经过筛选的其他输入特征与IMF分量进行融合,构成多维特征矩阵. 为了进一步优化模型的性能,采用NRBO对LSTM的关键参数进行寻优,增强模型对径流变化规律的学习能力. 将各分量分别输入到优化的LSTM模型进行预测,并将各个预测结果进行叠加,得到最终的预测值.
3.1. 数据处理和特征提取
1) 数据的缺失值和异常值处理:径流数据的完整性会影响预测的精度,为了提高数据质量,采用Python中的KNNImputer方法填充缺失值. 由于缺失比例极小,填充后的数据在统计特征与时序结构方面仍满足建模要求. 部分异常值可能反映极端气候或特殊水文事件,具有重要信息价值,予以保留,以提升模型对复杂特征的识别能力.
2) 数据的相关性分析:为了深入分析径流量的影响因素,采用Spearman方法对花园口和利津2个站点的水文数据进行相关性分析. 假定输入特征序列为
式中:
3) 数据集划分:数据经过预处理后,按时间序列顺序将数据集的70%划分为训练集,数据集的15%划分为验证集,数据集剩下的15%划分为测试集,避免随机划分导致时序信息泄露,如图2所示,图中Q表示流量,t表示时间.
图 2
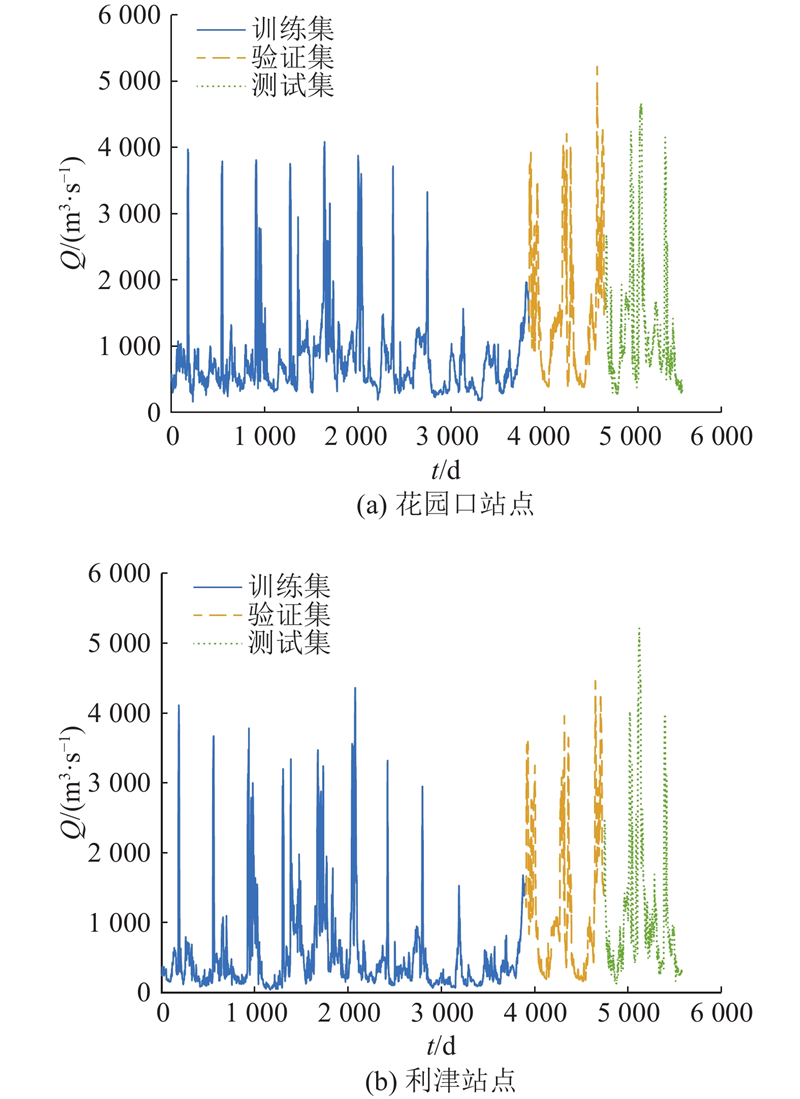
4) 归一化处理:采用最小−最大归一化方法将数据缩放到[0,1]区间,消除特征间量纲差异,提升模型稳定性与收敛效率.
式中:
3.2. 基于VMD的MFF方法
为了充分挖掘多特征数据对径流趋势的影响,提出基于VMD的MFF方法,具体流程如下.
1) VMD的镜像延拓:在VMD算法执行过程中,信号边界处易产生模态混叠与失真问题. 为了有效缓解该问题,采用镜像延拓策略对输入信号进行预处理. 具体步骤如下:针对长度为
2) VMD分解:原始径流序列
式中:
3) 滑动窗口构建时序特征矩阵与直接多步预测:为了实现1、2、3 d的预见期的直接多步预测,采用滑动窗口技术对历史步长
式中:
4) 独立建模与结果融合:每个IMF分量的特征矩阵
上述过程将水文数据和IMF分量融合在同一特征空间中,构建多维信息特征矩阵. 该矩阵作为模型的输入,不仅增强了模型理解时序数据复杂结构的能力,还能够为后续预测提供更完整的信息. 通过融合多特征数据,模型能够更准确地捕捉在不同的预见期内径流量与水文因子之间的复杂关系,从而显著提升预测精度和泛化能力. 此外,利用多维信息可以增强模型的可解释性,使预测过程更加透明,有助于更好地理解模型决策所依据的物理规律与数据特征.
3.3. LSTM模型结构
构建深度学习模型,该模型由LSTM、ReLU激活函数、全连接层和回归层组成. LSTM层被用于捕捉径流时序数据的长期依赖关系;ReLU激活函数提供非线性变换以增强模型的表达能力;全连接层通过线性组合提取高阶特征;回归层则将模型输出映射到预测结果. 如图3所示.
图 3
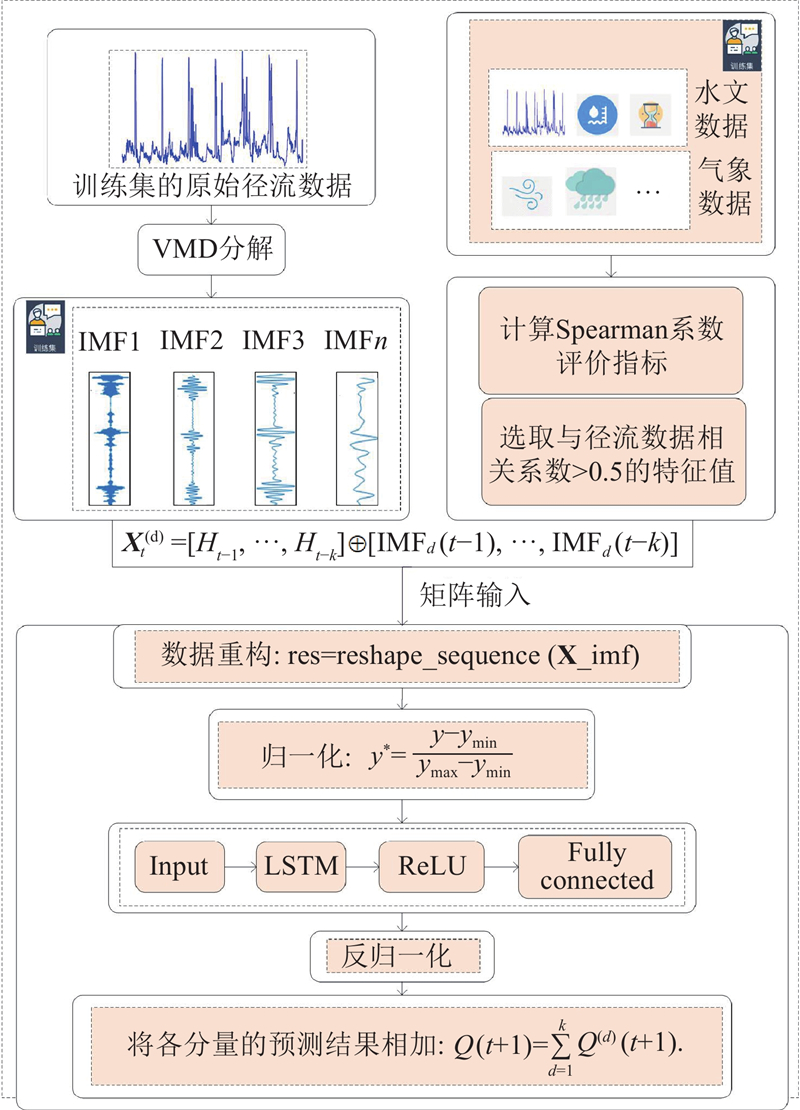
图 3 多特征融合和LSTM的预测框架
Fig.3 Forecasting framework of multi-feature fusion and LSTM
3.4. 基于NRBO的LSTM动态优化
在MFF的基础上,将NRBO应用于LSTM的关键超参数(隐藏层单元数、学习率和训练epoch数)优化. NRBO具备强大的全局搜索能力,能够有效地克服传统优化算法易陷入局部最优的问题,从而提升模型的超参数寻优效率. 与此同时,LSTM以优异的时序建模能力,能够充分捕捉径流时间序列的长期依赖性和复杂非线性特征. 两者结合可以提高径流预测模型的泛化能力和预测精度,实现对流域径流变化的更准确模拟和预估.
具体优化过程如图4所示. 将每个粒子编码为1组LSTM超参数组合,通过计算该组合下LSTM在验证集上的均方根误差(root mean square error,RMSE)作为适应度函数,算法以预设的最大迭代次数MaxIt作为停止条件,在每次迭代中,NRBO根据适应度值更新粒子位置,动态调整超参数组合,并记录当前全局最优适应度及其对应的超参数. 当迭代次数达到MaxIt时,算法终止,输出最优超参数组合用于LSTM训练. 通过该策略,既能保证算法在可控计算资源下完成寻优,又可避免因过早收敛导致的次优解问题. 此阶段中,NRBO在LSTM优化上采用多种方法.
图 4
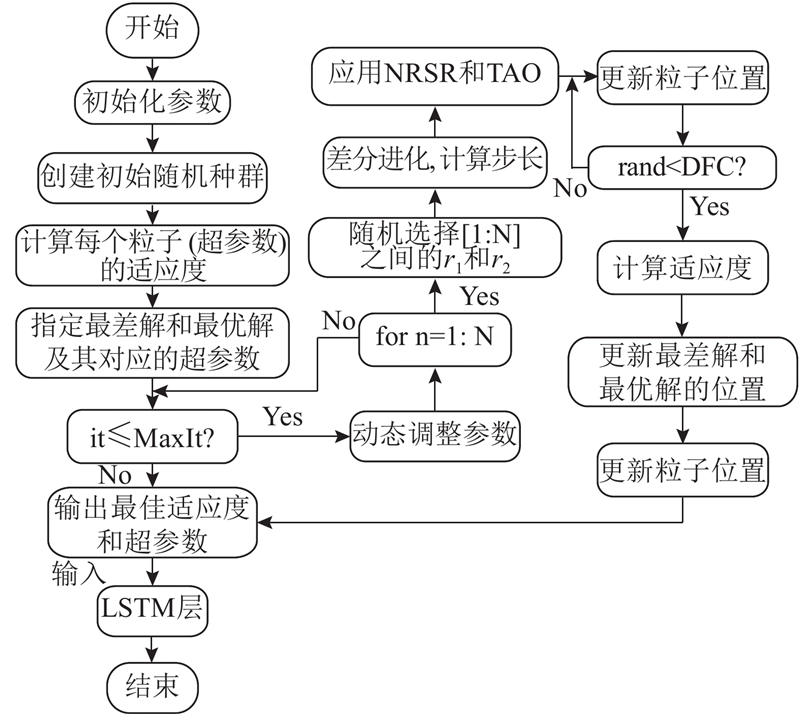
3.4.1. 非线性动态参数实时优化方法
传统的优化算法通常采用固定参数或线性衰减的方法来平衡搜索和开发,易导致模型陷入局部最优解或收敛速度过慢,影响泛化能力. 引入基于NRBO的非线性动态衰减权重因子
式中:it为当前迭代次数,MaxIt为最大迭代次数.
根据当前迭代次数与最大迭代次数的关系动态调整. 权重因子大时算法侧重全局搜索,权重因子小时转向局部微调. 通过自适应调节搜索范围,平衡模型搜索与开发权重,满足训练不同阶段的需求,实现LSTM模型最佳参数寻优,提升收敛速度与泛化能力.
3.4.2. 自适应学习率动态规划方法
传统的LSTM模型训练时多使用固定学习率,无法适应不同训练阶段的需求,导致训练效率低下. 通过引入基于NRSR的自适应学习率动态规划方法,计算当前位置与最佳位置的差异,并结合随机数生成动态步长,使LSTM在不同训练阶段自动调整学习率,有效提升训练效率.
3.4.3. 双随机扰动机制
传统优化算法在迭代过程中容易陷入局部最优解,缺乏有效的机制来帮助粒子逃离局部最优解. 为此,引入基于NRBO的双随机扰动机制,该机制通过在方向和强度2个方面引入随机性,并结合
3.4.4. 向量化和矩阵运算
在高维搜索空间中,传统的粒子位置更新方法依赖逐元素操作,计算效率低,在NRBO算法中引入向量化操作和矩阵运算,将多个粒子更新合并为单个矩阵运算,减少了循环和条件判断开销. 在LSTM应用中,这种高效的计算方式可以缩短训练时间.
4. 实验参数设置
选取4种常用的评价指标:RMSE、平均绝对百分比误差(mean absolute percentage error,MAPE)、平均绝对误差(mean absolute error,MAE)和纳什效率系数(Nash-Sutcliffe efficiency coefficient,NSE).
式中:
基于NRBO优化LSTM的损失函数采用均方误差(mean square error,MSE):
在LSTM的优化过程中,所使用的目标函数
式中:
模型训练环境如下:处理器为Inter Core i9-10900K CPU和NVIDIA GeForce RTX 1660 Laptop GPU,内存为64 GB. 模型的初始参数如下:VMD的分解层数为5层;CNN模型的卷积核大小为2,输出通道数为16;TCN模型包含2个一维卷积层,每个卷积层使用大小为2的卷积核,输出通道数为16. CNN、TCN和LSTM的隐藏层层数为70,初始学习率为0.01,最大训练轮数为70,L2正则化参数为1×10−7,梯度阈值设置为1,学习率调整策略为分段常数,学习率降低周期为60. 优化算法的种群数量为100,最大迭代次数为6,变量为最佳隐藏单元数目、最佳训练周期和最佳初始学习率,参数的上限分别为500、500、0.01,下限分别为15、50、0.000 1.
5. 结果与分析
5.1. 相关性分析
通过图5的相关性分析,可以发现,2个站点的水位和流量的相关性最高,而其他特征值和流量的相关系数不足0.5. 因此,将水位和流量作为后续研究的输入特征.
图 5
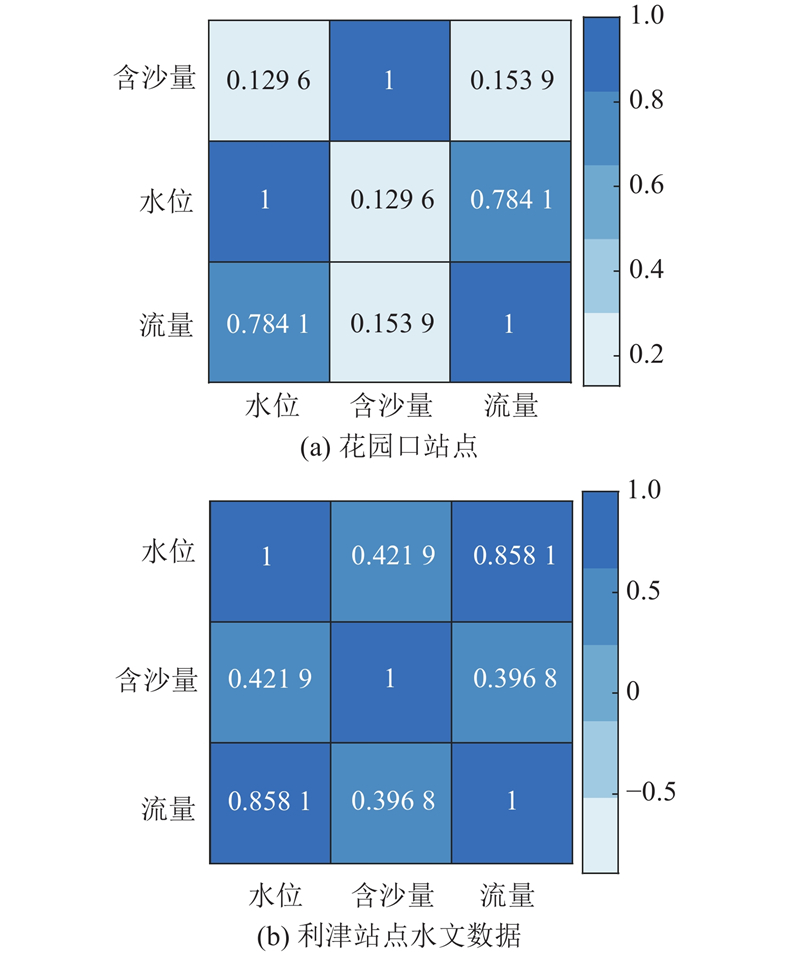
图 5 花园口和利津站水文数据的相关性分析
Fig.5 Correlation analysis of hydrological data between Huayuankou and Lijin Stations
5.2. 对比实验及分析
为了全面评估模型的性能,将MFF-NRBO-LSTM与随机森林(random forest,RF)[37]、卷积神经网络(CNN)[38-39]、TCN、TCN-LSTM、LSTM、MFF-LSTM、MFF-SSA-LSTM和MFF-黑翅鸢算法(black kite algorithm,BKA)[40]-LSTM这8种模型进行对比. 当预见期为1 d时,结果如表2所示,MFF-NRBO-LSTM模型在所有评价指标上均表现最优,说明该模型的预测精度最高. 与单一的LSTM模型相比,MFF-NRBO-LSTM模型的RMSE、MAE和MAPE分别下降了74.68%、74.59%、70.98%,NSE提升了5.56%.
表 2 各模型在测试集上的1 d预见期性能评价结果
Tab.2
| 模型 | 花园口 | 利津 | |||||||
| RMSE | MAE | MAPE | NSE | RMSE | MAE | MAPE | NSE | ||
| RF | 301.368 6 | 152.467 2 | 0.112 5 | 0.907 9 | 261.708 0 | 135.698 8 | 0.122 9 | 0.933 4 | |
| CNN | 281.343 0 | 141.966 0 | 0.108 3 | 0.919 7 | 201.703 6 | 106.062 8 | 0.106 1 | 0.960 4 | |
| TCN | 267.640 8 | 131.018 9 | 0.108 6 | 0.927 3 | 204.422 5 | 105.637 6 | 0.120 7 | 0.959 4 | |
| TCN-LSTM | 269.727 5 | 131.594 5 | 0.103 3 | 0.926 2 | 212.500 0 | 114.145 7 | 0.111 2 | 0.956 1 | |
| LSTM | 267.388 6 | 131.654 0 | 0.110 2 | 0.927 5 | 200.944 3 | 104.585 3 | 0.105 7 | 0.960 7 | |
| MFF-LSTM | 134.740 5 | 77.958 8 | 0.066 0 | 0.979 5 | 116.979 6 | 53.791 3 | 0.068 8 | 0.985 5 | |
| MFF-SSA-LSTM | 80.723 3 | 37.219 4 | 0.029 4 | 0.992 6 | 78.314 8 | 33.306 1 | 0.041 4 | 0.993 5 | |
| MFF-BKA-LSTM | 84.636 9 | 38.968 8 | 0.033 3 | 0.991 9 | 86.887 8 | 34.992 7 | 0.029 4 | 0.992 0 | |
| MFF-NRBO-LSTM | 61.289 6 | 31.822 4 | 0.028 3 | 0.995 8 | 55.684 4 | 27.875 0 | 0.034 2 | 0.996 7 | |
MFF-LSTM模型在引入MFF后,增强了模型的时域分解能力,能够有效地提取径流序列中复杂的时序特征,精准捕捉径流变化趋势,提升模型对径流序列动态变化的学习与预测能力. 与原始的LSTM相比,MFF-LSTM的RMSE、MAE和MAPE分别下降了45.70%、44.68%、37.51%,而NSE提升了4.09%. 验证了MFF方法在特征提取和噪声抑制方面的有效性. 进一步地,MFF-NRBO-LSTM的RMSE、MAE和MAPE相较于MFF-SSA-LSTM和MFF-BKA-LSTM分别降低了29.12%、17.37%、4.63%,说明NRBO算法在径流预测方面优于SSA和BKA算法. 如表2和3所示,当预见期为1、2、3 d时,MFF-NRBO-LSTM模型的精度均为最高.
表 3 各模型在测试集上的2 和 3 d预见期性能评价结果
Tab.3
| 模型 | 2 d | 3 d | |||||||||
| 花园口 | 利津 | 花园口 | 利津 | ||||||||
| RMSE | NSE | RMSE | NSE | RMSE | NSE | RMSE | NSE | ||||
| RF | 437.774 4 | 0.805 4 | 386.129 4 | 0.854 9 | 535.451 5 | 0.709 2 | 481.175 6 | 0.774 8 | |||
| CNN | 398.110 3 | 0.839 1 | 340.881 0 | 0.886 9 | 487.641 7 | 0.758 8 | 433.588 5 | 0.817 1 | |||
| TCN | 411.112 9 | 0.828 4 | 378.179 3 | 0.860 8 | 505.366 6 | 0.741 0 | 437.845 3 | 0.813 5 | |||
| TCN-LSTM | 403.074 9 | 0.835 1 | 344.661 5 | 0.884 4 | 492.761 4 | 0.753 7 | 437.448 9 | 0.813 9 | |||
| LSTM | 409.039 9 | 0.830 1 | 335.820 8 | 0.830 1 | 500.632 2 | 0.745 8 | 433.363 7 | 0.817 3 | |||
| MFF-LSTM | 136.870 8 | 0.972 8 | 121.582 1 | 0.972 8 | 215.398 6 | 0.947 7 | 217.145 9 | 0.950 2 | |||
| MFF-SSA-LSTM | 154.234 2 | 0.978 9 | 121.582 1 | 0.978 9 | 227.501 3 | 0.941 6 | 170.716 3 | 0.969 2 | |||
| MFF-BKA-LSTM | 155.409 7 | 0.973 2 | 126.920 3 | 0.973 2 | 221.533 3 | 0.944 7 | 196.019 8 | 0.959 4 | |||
| MFF-NRBO-LSTM | 116.784 9 | 0.984 6 | 109.921 0 | 0.971 4 | 196.854 0 | 0.956 3 | 164.402 4 | 0.971 4 | |||
图 6
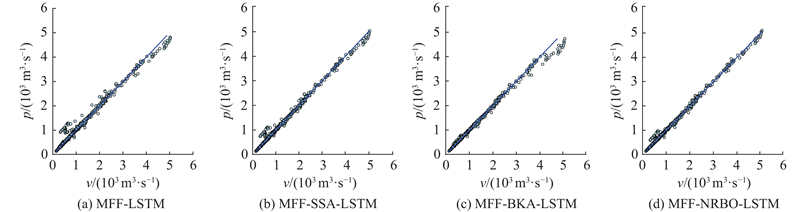
图 6 花园口预见期为1 d的预测值和实测值的散点分布图
Fig.6 Scatter plots of forecasted vs. observed values with one-day lead time at Huayuankou station
图 7
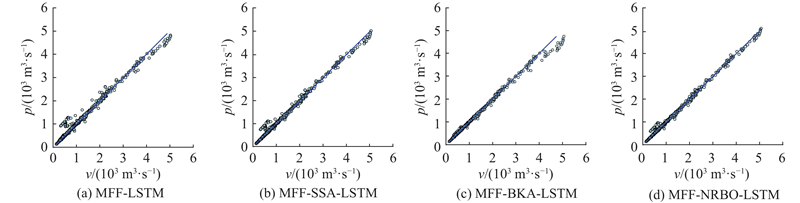
图 7 利津预见期为1 d的预测值和实测值的散点分布图
Fig.7 Scatter plots of forecasted vs. observed values with one-day lead time at Lijin station
5.3. 消融实验
消融实验从单独引入NRBO和MFF这2个关键组件出发,进一步验证各部分对模型性能的贡献. 如表4所示,NRBO-LSTM相比LSTM的RMSE、MAE和MAPE分别下降了9.81%、6.37%和3.21%,NSE则有所提高,表明NRBO-LSTM具备较强的参数优化能力. 引入MFF后,MFF-NRBO-LSTM比NRBO-LSTM的RMSE、MAE和MAPE分别下降了71.91%、72.81%和70.12%,NSE提升了4.04%,说明MFF能够聚焦多特征数据关键信息,并能够显著提高预测精度.
表 4 各模型在测试集上的1 d预见期的消融实验结果
Tab.4
| 站点 | 算法 | RMSE | MAE | MAPE | NSE |
| 花园口 | LSTM | 267.388 6 | 131.654 0 | 0.110 2 | 0.927 5 |
| MFF-LSTM | 134.740 5 | 77.958 8 | 0.066 0 | 0.979 5 | |
| NRBO-LSTM | 216.410 0 | 114.240 0 | 0.100 0 | 0.954 0 | |
| MFF-NRBO-LSTM | 61.289 6 | 31.822 4 | 0.028 3 | 0.995 8 | |
| 利津 | LSTM | 200.944 3 | 104.585 3 | 0.105 7 | 0.960 7 |
| MFF-LSTM | 116.979 6 | 53.791 3 | 0.068 8 | 0.985 5 | |
| NRBO-LSTM | 199.833 0 | 105.086 6 | 0.108 7 | 0.961 2 | |
| MFF-NRBO-LSTM | 55.684 4 | 27.875 0 | 0.034 2 | 0.996 7 |
6. 结 语
为了克服现有预测模型在提取多特征数据特征方面的局限性,并提升日径流预测的精度,创新性地提出MFF-NRBO-LSTM多步预测模型,该模型集成了MFF和NRBO优化2大阶段. 在MFF阶段,通过MFF方法丰富模型的信息来源,使MFF-NRBO-LSTM能够更全面地理解数据的结构,从而显著增强了对序列特征的捕捉能力. 同时,NRBO对LSTM的超参数进行了精细调整,不仅增强了模型的全局搜索能力,也显著提升了预测性能. 为了验证该模型在日径流多步预测中的适用性,对黄河流域的花园口和利津水文站这2个具有代表性的站点进行预见期为1~3 d的多步预测,实验结果显示,MFF-NRBO-LSTM与其他8种对比模型相比,预测精度最高,误差最小. 有效验证了该模型的实际应用价值.
尽管本研究重点突出了NRBO在提升LSTM预测精度方面的显著优势,但未来的研究可以进一步探索该模型在收敛速度和计算复杂度方面的表现. 通过全面评估其在水文预测任务中的适用性和效率,可以为模型的选择和优化提供更为科学的依据,从而推动水文预测技术的进步和发展.
参考文献
Rainfall–runoff prediction at multiple timescales with a single long short-term memory network
[J].DOI:10.5194/hess-25-2045-2021 [本文引用: 1]
基于LSTM与牛顿迭代的两轴系统轮廓误差控制
[J].
Contour error control of two-axis system based on LSTM and Newton iteration
[J].
Streamflow and rainfall forecasting by two long short-term memory-based models
[J].DOI:10.1016/j.jhydrol.2019.124296 [本文引用: 1]
改进时间卷积网络和长短时记忆网络的泸水河流域月径流量预测模型
[J].
Monthly runoff prediction model for the lushui river basin based on Improved Temporal Convolution Network and Long Short-Term Memory Network
[J].
Multimodal deep learning water level forecasting model for multiscale drought alert in Feiyun River basin
[J].DOI:10.1016/j.eswa.2023.122951 [本文引用: 1]
A hybrid model for runoff prediction using variational mode decomposition and artificial neural network
[J].DOI:10.1134/S0097807821050171 [本文引用: 1]
An application of the participatory approach to develop an integrated water resources management (IWRM) system for the drought-affected region of Bangladesh
[J].DOI:10.1016/j.heliyon.2023.e14260 [本文引用: 1]
Probabilistic interval estimation of design floods under non-stationary conditionsby an integrated approach
[J].DOI:10.2166/nh.2021.007 [本文引用: 1]
Monthly runoff forecasting using variational deconposition coupled with gray wolf optimizer-based long short-term memory neural networks
[J].DOI:10.1007/s11269-022-03133-0 [本文引用: 1]
Development of a stochastic hydrological modeling system for improving ensemble streamflow prediction
[J].DOI:10.1016/j.jhydrol.2022.127683 [本文引用: 1]
Accounting for soil moisture in rainfall-runoff modelling of urban areas
[J].DOI:10.1016/j.jhydrol.2020.125122 [本文引用: 1]
Daily runoff prediction based on the adaptive fourier deconposition method and mutiscale temporal convolutional network
[J].DOI:10.1007/s11356-023-28936-5 [本文引用: 1]
Data-driven approaches for runoff prediction using distributed data
[J].DOI:10.1007/s00477-021-01993-3 [本文引用: 1]
Short-term runoff prediction with GRU and LSTM networks without requiring time step optimization during sample generation
[J].DOI:10.1016/j.jhydrol.2020.125188 [本文引用: 1]
An ensemble CNN-LSTM and GRU adaptive weighting model based improved sparrow search algorithm for predicting runoff using historical meteorological and runoff data as input
[J].DOI:10.1016/j.jhydrol.2023.129977 [本文引用: 1]
A hybrid prediction model for residential electricity consumption using holt-winters and extreme learning machine
[J].DOI:10.1016/j.apenergy.2020.115383 [本文引用: 1]
Prophet-EEMD-LSTM based method for predicting energy consumption in the paint workshop
[J].DOI:10.1016/j.asoc.2023.110447
A runoff prediction model based on nonhomogeneous markov chain
[J].DOI:10.1007/s11269-022-03091-7 [本文引用: 1]
VTNet: A multi-domain information fusion model for long-term multi-variate time series forecasting with application in irrigation water level
[J].DOI:10.1016/j.asoc.2024.112251 [本文引用: 1]
Evaluation of SVM, ELM and four tree-based ensemble models for predicting daily reference evapotranspiration using limited meteorological data in different climates of China
[J].DOI:10.1016/j.agrformet.2018.08.019 [本文引用: 1]
Prediction of flood quantiles at ungauged catchments for the contiguous USA using artificial neural networks
[J].
Influence of random forest hyperparameterization on short-term runoff forecasting in an andean mountain catchment
[J].
Multi-step short-term wind speed forecasting based on multi-stage decomposition coupled with stacking-ensemble learning approach
[J].
Cooperative ensemble learning model improves electric short-term load forecasting
[J].
Analysis and prediction of rainfall trends over Bangladesh using Mann–Kendall, Spearman’s rho tests and ARIMA model
[J].DOI:10.1007/s00703-016-0479-4 [本文引用: 1]
Variational mode decomposition
[J].
基于相关向量机和模糊综合评价的路况预测模型
[J].
Model based onrelevance vector machine and fuzzy comprehensive evaluation forroad condition prediction
[J].
Performance evaluation of hybrid GA–SVM and GWO–SVM models to predict earthquake-induced liquefaction potential of soil: a multi-dataset investigation
[J].
A new method for runoff prediction error correction based on LS-SVM and a 4D copula joint distribution
[J].DOI:10.1016/j.jhydrol.2021.126223 [本文引用: 1]
Newton-Raphson-based optimizer: A new population-based metaheuristic algorithm for continuous optimization problems
[J].DOI:10.1016/j.engappai.2023.107532 [本文引用: 1]
Short-term forecasting of household water demand in the UK using an interpretable machine learning approach
[J].DOI:10.1061/(ASCE)WR.1943-5452.0001325 [本文引用: 1]
基于Gram矩阵的T-CNN时间序列分类方法
[J].
T-CNN time series classification method based on Gram matrix
[J].
Ensemble learning methods using the Hodrick–Prescott filter for fault forecasting in insulators of the electrical power grids
[J].
基于神经网络的建筑能耗混合预测模型
[J].
基于小波变换和优化CNN的风电齿轮箱故障诊断
[J].
Fault diagnosis of wind power gearbox based on wavelet transform and improved CNN
[J].
Hybrid prediction model of building energy consumption based on neural network
[J].
Exploring a long short-term memory based encoder-decoder framework for muti-step-ahead flood forecasting
[J].DOI:10.1016/j.jhydrol.2020.124631
Feature extraction using an RNN autoencoder for skeleton-based abnormal gait recognition
[J].DOI:10.1109/ACCESS.2020.2967845 [本文引用: 1]
Runoff predictions in ungauged basins using sequence-to-sequence models
[J].DOI:10.1016/j.jhydrol.2021.126975 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}