[1]
TIAN Y, ZHANG G, YE H, et al Corrosion of steel rebar in concrete induced by chloride ions under natural environments
[J]. Construction and Building Materials , 2023 , 369 : 130504
DOI:10.1016/j.conbuildmat.2023.130504
[本文引用: 1]
[2]
QIU J, ZHANG W, JING Y Quantitative linear correlation between self-magnetic flux leakage field variation and corrosion unevenness of corroded rebars
[J]. Measurement , 2023 , 218 : 113173
DOI:10.1016/j.measurement.2023.113173
[本文引用: 1]
[3]
EDDY I C, UNDERHILL P R, MORELLI J, et al. Pulsed eddy current response to liftoff in different sizes of concrete embedded rebar [C]// Proceedings of the IEEE SENSORS . Montreal: IEEE, 2019: 1–4.
[本文引用: 1]
[4]
LUO Q, SUN Y, LI P, et al Generalized completed local binary patterns for time-efficient steel surface defect classification
[J]. IEEE Transactions on Instrumentation and Measurement , 2019 , 68 (3 ): 667 - 679
DOI:10.1109/TIM.2018.2852918
[本文引用: 1]
[5]
YIN T, YANG J. Detection of steel surface defect based on faster R-CNN and FPN [C]// Proceedings of the 7th International Conference on Computing and Artificial Intelligence . Tianjin: ACM, 2021: 15–20.
[本文引用: 1]
[6]
胡欣, 周运强, 肖剑, 等 基于改进YOLOv5的螺纹钢表面缺陷检测
[J]. 图学学报 , 2023 , 44 (3 ): 427 - 437
[本文引用: 1]
HU Xin, ZHOU Yunqiang, XIAO Jian, et al Surface defect detection of threaded steel based on improved YOLOv5
[J]. Journal of Graphics , 2023 , 44 (3 ): 427 - 437
[本文引用: 1]
[7]
李相垚, 侯红玲, 杨澳, 等. 面向钢材表面缺陷检测的DCS-YOLOv8算法研究[J/OL]. 机械科学与技术, 2024: 1–10. (2024-10-10) [2025-04-01]. https://link.cnki.net/doi/10.13433/j.cnki.1003-8728.20240128.
[本文引用: 2]
LI Xiangyao, HOU Hongling, YANG Ao, et al. Research on DCS-YOLOv8 algorithm for steel surface defect detection [J/OL]. Mechanical Science and Technology for Aerospace Engineering , 2024: 1–10. (2024-10-10) [2025-04-01]. https://link.cnki.net/doi/10.13433/j.cnki.1003-8728.20240128.
[本文引用: 2]
[8]
刘义艳, 郝婷楠, 贺晨, 等 基于DBBR-YOLO的光伏电池表面缺陷检测
[J]. 图学学报 , 2024 , 45 (5 ): 913 - 921
[本文引用: 1]
LIU Yiyan, HAO Tingnan, HE Chen, et al Photovoltaic cell surface defect detection based on DBBR-YOLO
[J]. Journal of Graphics , 2024 , 45 (5 ): 913 - 921
[本文引用: 1]
[9]
LIU G, HU Y, CHEN Z, et al Lightweight object detection algorithm for robots with improved YOLOv5
[J]. Engineering Applications of Artificial Intelligence , 2023 , 123 : 106217
DOI:10.1016/j.engappai.2023.106217
[本文引用: 1]
[10]
王春梅, 刘欢 YOLOv8-VSC: 一种轻量级的带钢表面缺陷检测算法
[J]. 计算机科学与探索 , 2024 , 18 (1 ): 151 - 160
[本文引用: 2]
WANG Chunmei, LIU Huan YOLOv8-VSC: lightweight algorithm for strip surface defect detection
[J]. Journal of Frontiers of Computer Science and Technology , 2024 , 18 (1 ): 151 - 160
[本文引用: 2]
[11]
TANG Z, ZHANG W, LI J, et al LTSCD-YOLO: a lightweight algorithm for detecting typical satellite components based on improved YOLOv8
[J]. Remote Sensing , 2024 , 16 (16 ): 3101
DOI:10.3390/rs16163101
[本文引用: 2]
[12]
梁礼明, 龙鹏威, 卢宝贺, 等. EHH-YOLOv8s: 一种轻量级的带钢表面缺陷检测算法[J/OL]. 北京航空航天大学学报, 2024: 1–15. (2024-08-08) [2025-04-01]. https://link.cnki.net/doi/10.13700/j.bh.1001-5965.2024.0426
[本文引用: 1]
LIANG Liming, LONG Pengwei, LU Baohe, et al. EHH-YOLOv8s: a lightweight algorithm for strip surface defect detection [J/OL]. Journal of Beijing University of Aeronautics and Astronautics , 2024: 1–15. (2024-08-08) [2025-04-01]. https://link.cnki.net/doi/10.13700/j.bh.1001-5965.2024.0426.
[本文引用: 1]
[13]
PENG H, XIE H, LIU H, et al LGFF-YOLO: small object detection method of UAV images based on efficient local-global feature fusion
[J]. Journal of Real-Time Image Processing , 2024 , 21 (5 ): 167
DOI:10.1007/s11554-024-01550-5
[本文引用: 1]
[14]
刘振江, 张会娟, 姬淼鑫, 等. 轻量级多尺度特征融合增强的空间非合作小目标检测算法[J/OL]. 北京航空航天大学学报, 2024: 1–12. (2024-09-20) [2025-04-01]. https://link.cnki.net/doi/10.13700/j.bh.1001-5965.2024.0509.
[本文引用: 2]
LIU Zhenjiang, ZHANG Huijuan, JI Miaoxin, et al. Lightweight multi-scale feature fusion enhancement algorithm for spatial non-cooperative small target detection [J/OL]. Journal of Beijing University of Aeronautics and Astronautics , 2024: 1–12. (2024-09-20) [2025-04-01]. https://link.cnki.net/doi/10.13700/j.bh.1001-5965.2024.0509.
[本文引用: 2]
[15]
SHI D. TransNeXt: robust foveal visual perception for vision Transformers [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 17773–17783.
[本文引用: 1]
[16]
CAI X, LAI Q, WANG Y, et al. Poly kernel inception network for remote sensing detection [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2024: 27706–27716.
[本文引用: 1]
[17]
CHEN Y, ZHANG C, CHEN B, et al Accurate leukocyte detection based on deformable-DETR and multi-level feature fusion for aiding diagnosis of blood diseases
[J]. Computers in Biology and Medicine , 2024 , 170 : 107917
DOI:10.1016/j.compbiomed.2024.107917
[本文引用: 1]
[18]
王安静, 袁巨龙, 朱勇建, 等 基于改进YOLOv8s的鼓形滚子表面缺陷检测算法
[J]. 浙江大学学报: 工学版 , 2024 , 58 (2 ): 370 - 380
[本文引用: 1]
WANG Anjing, YUAN Julong, ZHU Yongjian, et al Drum roller surface defect detection algorithm based on improved YOLOv8s
[J]. Journal of Zhejiang University: Engineering Science , 2024 , 58 (2 ): 370 - 380
[本文引用: 1]
[19]
LUO X, CAI Z, SHAO B, et al. Unified-IoU: for high-quality object detection [EB/OL]. (2024-08-13) [2025-04-01]. https://arxiv.org/abs/2408.06636.
[本文引用: 1]
[20]
YU W, SI C, ZHOU P, et al MetaFormer baselines for vision
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2024 , 46 (2 ): 896 - 912
DOI:10.1109/TPAMI.2023.3329173
[本文引用: 1]
[21]
PATEL I, PATEL S An optimized deep learning model for flower classification using NAS-FPN and faster R-CNN
[J]. International Journal of Scientific & Technology Research , 2020 , 9 (3 ): 5308 - 5318
[本文引用: 1]
[22]
QIAN X, ZHANG N, WANG W Smooth GIoU loss for oriented object detection in remote sensing images
[J]. Remote Sensing , 2023 , 15 (5 ): 1259
DOI:10.3390/rs15051259
[本文引用: 1]
[23]
PENG H, YU S A systematic IoU-related method: beyond simplified regression for better localization
[J]. IEEE Transactions on Image Processing , 2021 , 30 : 5032 - 5044
DOI:10.1109/TIP.2021.3077144
[本文引用: 1]
[24]
HAN K, WANG Y, TIAN Q, et al. GhostNet: more features from cheap operations [EB/OL]. (2020-03-13) [2025-04-01]. https://arxiv.org/abs/1911.11907.
[本文引用: 1]
[25]
TANG Y, HAN K, GUO J, et al. GhostNetV2: enhance cheap operation with long-range attention [C]// Proceedings of the 36th International Conference on Neural Information Processing Systems . New Orleans: Curran Associates Inc, 2022: 9969–9982.
[本文引用: 1]
[26]
MEHTA S, RASTEGARI M. MobileViT: light-weight, general-purpose, and mobile-friendly vision Transformer [EB/OL]. (2022-03-04) [2025-04-01]. https://arxiv.org/abs/2110.02178.
[本文引用: 2]
[27]
Howard A, SANDLER M, CHU G, et al. Searching for MobileNetV3 [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 1314–1324.
[本文引用: 1]
[28]
QIN D, LEICHNER C, DELAKIS M, et al. MobileNetV4: universal models for the mobile ecosystem [C]// European Conference on Computer Vision . Milan: ECVA, 2025: 78–96.
[本文引用: 1]
[29]
YANG H, LIU J, MEI G, et al Research on real-time detection method of rail corrugation based on improved ShuffleNet V2
[J]. Engineering Applications of Artificial Intelligence , 2023 , 126 : 106825
DOI:10.1016/j.engappai.2023.106825
[本文引用: 1]
[30]
梁礼明, 龙鹏威, 金家新, 等 基于改进YOLOv8s的钢材表面缺陷检测算法
[J]. 浙江大学学报: 工学版 , 2025 , 59 (3 ): 512 - 522
[本文引用: 1]
LIANG Liming, LONG Pengwei, JIN Jiaxin, et al Steel surface defect detection algorithm based on improved YOLOv8s
[J]. Journal of Zhejiang University: Engineering Science , 2025 , 59 (3 ): 512 - 522
[本文引用: 1]
[31]
CHEN H, WANG Y, GUO J, et al. VanillaNet: the power of minimalism in deep learning [EB/OL]. (2023-05-23) [2025-04-01]. https://arxiv.org/abs/2305.12972.
[本文引用: 1]
[32]
CHEN J, KAO S, HE H, et al. Run, don’t walk: chasing higher FLOPS for faster neural networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Vancouver: IEEE, 2023: 12021–12031.
[本文引用: 1]
[33]
MA X, DAI X, BAI Y, et al. Rewrite the stars [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2024: 5694–5703.
[本文引用: 1]
Corrosion of steel rebar in concrete induced by chloride ions under natural environments
1
2023
... 螺纹钢作为一种重要的建筑材料,因其良好的力学性能和耐久性,在基础设施建设领域占据不可替代的位置. 然而,在生产加工过程中,由于设备故障、存储不当和人为操作失误等因素,螺纹钢表面可能会出现划伤、锈迹、结疤等缺陷. 这不仅会影响螺纹钢的机械性能和连接可靠性,而且可能引发建筑结构的安全问题. 因此,实施高效、精准的螺纹钢缺陷检测至关重要[1 ] . ...
Quantitative linear correlation between self-magnetic flux leakage field variation and corrosion unevenness of corroded rebars
1
2023
... 传统的螺纹钢缺陷检测方法依赖于人工筛选,主观性强、检测效率低且容易发生漏检和误检的问题. 随着电子仪器和无损检测技术的发展,漏磁检测[2 ] 、涡流检测[3 ] 等方法已经在工业生产领域的缺陷检测中得到了广泛应用. 机器视觉的发展为螺纹钢表面缺陷检测提供了新的思路,该方法主要通过提取纹理或形状等不同形态的特征来判别缺陷. Luo等[4 ] 提出的广义完备局部二值模式框架增强了缺陷表示能力,但是其噪声抑制效果较为有限. ...
1
... 传统的螺纹钢缺陷检测方法依赖于人工筛选,主观性强、检测效率低且容易发生漏检和误检的问题. 随着电子仪器和无损检测技术的发展,漏磁检测[2 ] 、涡流检测[3 ] 等方法已经在工业生产领域的缺陷检测中得到了广泛应用. 机器视觉的发展为螺纹钢表面缺陷检测提供了新的思路,该方法主要通过提取纹理或形状等不同形态的特征来判别缺陷. Luo等[4 ] 提出的广义完备局部二值模式框架增强了缺陷表示能力,但是其噪声抑制效果较为有限. ...
Generalized completed local binary patterns for time-efficient steel surface defect classification
1
2019
... 传统的螺纹钢缺陷检测方法依赖于人工筛选,主观性强、检测效率低且容易发生漏检和误检的问题. 随着电子仪器和无损检测技术的发展,漏磁检测[2 ] 、涡流检测[3 ] 等方法已经在工业生产领域的缺陷检测中得到了广泛应用. 机器视觉的发展为螺纹钢表面缺陷检测提供了新的思路,该方法主要通过提取纹理或形状等不同形态的特征来判别缺陷. Luo等[4 ] 提出的广义完备局部二值模式框架增强了缺陷表示能力,但是其噪声抑制效果较为有限. ...
1
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
基于改进YOLOv5的螺纹钢表面缺陷检测
1
2023
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
基于改进YOLOv5的螺纹钢表面缺陷检测
1
2023
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
2
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
... 选用公开的NEU-DET钢材表面缺陷数据集对所提模型进行泛化性验证. 该数据集共有1 800张图片,包括裂纹、斑块、内含物、点蚀表面、轧制氧化皮和划痕6种缺陷,数据集划分比例和训练参数设置均与上述实验保持一致. 基准模型YOLOv8n、YOLOv11、本研究算法和DCS-YOLOv8[7 ] 、SDB-YOLOv8s[26 ] 的对比实验结果见表7 . ...
2
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
... 选用公开的NEU-DET钢材表面缺陷数据集对所提模型进行泛化性验证. 该数据集共有1 800张图片,包括裂纹、斑块、内含物、点蚀表面、轧制氧化皮和划痕6种缺陷,数据集划分比例和训练参数设置均与上述实验保持一致. 基准模型YOLOv8n、YOLOv11、本研究算法和DCS-YOLOv8[7 ] 、SDB-YOLOv8s[26 ] 的对比实验结果见表7 . ...
基于DBBR-YOLO的光伏电池表面缺陷检测
1
2024
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
基于DBBR-YOLO的光伏电池表面缺陷检测
1
2024
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
Lightweight object detection algorithm for robots with improved YOLOv5
1
2023
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
YOLOv8-VSC: 一种轻量级的带钢表面缺陷检测算法
2
2024
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
... 为了进一步验证改进的轻量化模型在螺纹钢表面缺陷检测中的高效性,采用自建螺纹钢数据集,选择当前先进的目标检测模型进行对比实验,涵盖了Faster R-CNN、SSD和YOLO系列中较小的模型,包括YOLOv3-Tiny、YOLOv4-Tiny、YOLOv5n、YOLOv6n、YOLOX-Tiny、YOLOv7-Tiny、YOLOv8n、YOLOv9n、YOLOv10n和YOLOv11n,以及YOLOv8-VSC[10 ] 、LTSCD-YOLO[11 ] 和S-YOLO[14 ] ,实验设置与基准模型保持一致. 对比实验结果见表6 . 结果表明,Faster R-CNN、SSD、YOLOv3-Tiny和YOLOv4-Tiny不仅结构复杂,且检测精度较低;YOLOv5n虽然改进了检测性能,但FPS提升有限,精度较低;YOLOX-Tiny的精度略优,但因庞大的参数量导致速度较慢. 相比之下,改进模型在与YOLOv9n、YOLOv10n和YOLOv11n的对比中,mAP@0.5分别提升了3.8、4.0、3.6个百分点,参数量和计算量大幅降低,FPS显著提升. 尽管S-YOLO精度较高,但参数量较高,检测速度不如LTSCD-YOLO. 改进模型以1.4 M的参数量和5.3 G的计算量,达到了94.5%的mAP@0.5值和156帧/s的速度,显著优于其他模型. 综上所述,所提模型表现出较强的竞争力,兼顾轻量化与检测精度,适合部署在计算资源有限的终端设备上. ...
YOLOv8-VSC: 一种轻量级的带钢表面缺陷检测算法
2
2024
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
... 为了进一步验证改进的轻量化模型在螺纹钢表面缺陷检测中的高效性,采用自建螺纹钢数据集,选择当前先进的目标检测模型进行对比实验,涵盖了Faster R-CNN、SSD和YOLO系列中较小的模型,包括YOLOv3-Tiny、YOLOv4-Tiny、YOLOv5n、YOLOv6n、YOLOX-Tiny、YOLOv7-Tiny、YOLOv8n、YOLOv9n、YOLOv10n和YOLOv11n,以及YOLOv8-VSC[10 ] 、LTSCD-YOLO[11 ] 和S-YOLO[14 ] ,实验设置与基准模型保持一致. 对比实验结果见表6 . 结果表明,Faster R-CNN、SSD、YOLOv3-Tiny和YOLOv4-Tiny不仅结构复杂,且检测精度较低;YOLOv5n虽然改进了检测性能,但FPS提升有限,精度较低;YOLOX-Tiny的精度略优,但因庞大的参数量导致速度较慢. 相比之下,改进模型在与YOLOv9n、YOLOv10n和YOLOv11n的对比中,mAP@0.5分别提升了3.8、4.0、3.6个百分点,参数量和计算量大幅降低,FPS显著提升. 尽管S-YOLO精度较高,但参数量较高,检测速度不如LTSCD-YOLO. 改进模型以1.4 M的参数量和5.3 G的计算量,达到了94.5%的mAP@0.5值和156帧/s的速度,显著优于其他模型. 综上所述,所提模型表现出较强的竞争力,兼顾轻量化与检测精度,适合部署在计算资源有限的终端设备上. ...
LTSCD-YOLO: a lightweight algorithm for detecting typical satellite components based on improved YOLOv8
2
2024
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
... 为了进一步验证改进的轻量化模型在螺纹钢表面缺陷检测中的高效性,采用自建螺纹钢数据集,选择当前先进的目标检测模型进行对比实验,涵盖了Faster R-CNN、SSD和YOLO系列中较小的模型,包括YOLOv3-Tiny、YOLOv4-Tiny、YOLOv5n、YOLOv6n、YOLOX-Tiny、YOLOv7-Tiny、YOLOv8n、YOLOv9n、YOLOv10n和YOLOv11n,以及YOLOv8-VSC[10 ] 、LTSCD-YOLO[11 ] 和S-YOLO[14 ] ,实验设置与基准模型保持一致. 对比实验结果见表6 . 结果表明,Faster R-CNN、SSD、YOLOv3-Tiny和YOLOv4-Tiny不仅结构复杂,且检测精度较低;YOLOv5n虽然改进了检测性能,但FPS提升有限,精度较低;YOLOX-Tiny的精度略优,但因庞大的参数量导致速度较慢. 相比之下,改进模型在与YOLOv9n、YOLOv10n和YOLOv11n的对比中,mAP@0.5分别提升了3.8、4.0、3.6个百分点,参数量和计算量大幅降低,FPS显著提升. 尽管S-YOLO精度较高,但参数量较高,检测速度不如LTSCD-YOLO. 改进模型以1.4 M的参数量和5.3 G的计算量,达到了94.5%的mAP@0.5值和156帧/s的速度,显著优于其他模型. 综上所述,所提模型表现出较强的竞争力,兼顾轻量化与检测精度,适合部署在计算资源有限的终端设备上. ...
1
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
1
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
LGFF-YOLO: small object detection method of UAV images based on efficient local-global feature fusion
1
2024
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
2
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
... 为了进一步验证改进的轻量化模型在螺纹钢表面缺陷检测中的高效性,采用自建螺纹钢数据集,选择当前先进的目标检测模型进行对比实验,涵盖了Faster R-CNN、SSD和YOLO系列中较小的模型,包括YOLOv3-Tiny、YOLOv4-Tiny、YOLOv5n、YOLOv6n、YOLOX-Tiny、YOLOv7-Tiny、YOLOv8n、YOLOv9n、YOLOv10n和YOLOv11n,以及YOLOv8-VSC[10 ] 、LTSCD-YOLO[11 ] 和S-YOLO[14 ] ,实验设置与基准模型保持一致. 对比实验结果见表6 . 结果表明,Faster R-CNN、SSD、YOLOv3-Tiny和YOLOv4-Tiny不仅结构复杂,且检测精度较低;YOLOv5n虽然改进了检测性能,但FPS提升有限,精度较低;YOLOX-Tiny的精度略优,但因庞大的参数量导致速度较慢. 相比之下,改进模型在与YOLOv9n、YOLOv10n和YOLOv11n的对比中,mAP@0.5分别提升了3.8、4.0、3.6个百分点,参数量和计算量大幅降低,FPS显著提升. 尽管S-YOLO精度较高,但参数量较高,检测速度不如LTSCD-YOLO. 改进模型以1.4 M的参数量和5.3 G的计算量,达到了94.5%的mAP@0.5值和156帧/s的速度,显著优于其他模型. 综上所述,所提模型表现出较强的竞争力,兼顾轻量化与检测精度,适合部署在计算资源有限的终端设备上. ...
2
... 随着深度学习技术的发展,两阶段目标检测算法因其较高的检测精度被广泛应用于缺陷检测领域. Yin等[5 ] 将特征金字塔网络(feature pyramid network, FPN)与目标检测算法Faster R-CNN结合,并采用感兴趣区域对齐 (region of interest align, RoI align)方法替代感兴趣区域池化方法,优化高、低层特征融合并减少量化误差. 此类算法在精度上表现优异,但是由于需要先进行候选框的筛选,检测速度较慢. 相比之下,单阶段目标检测算法因其较快的推理速度,在实时检测方面有着显著的优势,其中,以YOLO系列为代表的算法在螺纹钢缺陷检测方面已经取得了一定的研究成果. 胡欣等[6 ] 通过在YOLOv5中融合多空间金字塔池化(multi-spatial pyramid pooling, M-SPP)来加强特征提取能力,改进空间和坐标注意力模块以提高对小目标缺陷的关注,有效提升了检测精度. 李相垚等[7 ] 在YOLOv8的基础上引入可变形卷积DCNv2,增强了模型对复杂特征的提取能力,并引入无参数通道注意力机制SimAM来提取更加丰富的全局特征. 刘义艳等[8 ] 将Neck层与Gold-YOLO算法结合,实现了不同层级特征的全局信息聚合,进而提升了特征图间的信息交互效率,增强了模型对全局信息的感知. 为了解决目标检测模型在终端检测设备上的部署问题,Liu等[9 ] 在YOLOv5主干网络中引入C3Ghost和GhostConv模块,减少了模型参数并提升了特征融合的速度. 王春梅等[10 ] 使用轻量级的VanillaNet网络作为YOLOv8n的主干网络,通过减少不必要的分支结构来降低模型的复杂度,并引入空间到深度(space-to-depth, SPD)模块,在减少网络层数的同时加快了模型的推理速度. Tang等[11 ] 将部分卷积(PConv)集成到特征融合模块中,并使用重参数化卷积(RepConv)改进检测头,从而减少参数量,实现模型的轻量化. 梁礼明等[12 ] 采用轻量级的EfficientViT网络作为主干网络,以降低模型复杂度并更好地处理跨尺度特征信息,从而提升检测性能. Peng等[13 ] 通过全局信息融合模块和四叶草融合模块增强模型的全局信息提取与多尺度特征融合能力,并引入LDyHead和RFA-Block优化特征流动路径,提升了检测精度且不增加模型复杂度. 刘振江等[14 ] 提出快速双空间金字塔池化模块,强化目标全局上下文特征的提取,并通过聚合局部和全局特征来提升特征泛化能力,同时采用轻量级下采样模块,以减少参数并增强细粒度特征提取能力. 以上研究对计算量较大的目标检测算法具有一定的启发意义. 然而,在螺纹钢表面缺陷检测领域,面对计算资源受限的终端设备,主流目标检测模型的计算量和参数量仍然偏大;同时,轻量化操作虽然有利于减小模型体积,但是会降低网络的非线性能力,从而损失精度. 因此,如何平衡检测性能与计算资源消耗仍然是当前亟待解决的问题. ...
... 为了进一步验证改进的轻量化模型在螺纹钢表面缺陷检测中的高效性,采用自建螺纹钢数据集,选择当前先进的目标检测模型进行对比实验,涵盖了Faster R-CNN、SSD和YOLO系列中较小的模型,包括YOLOv3-Tiny、YOLOv4-Tiny、YOLOv5n、YOLOv6n、YOLOX-Tiny、YOLOv7-Tiny、YOLOv8n、YOLOv9n、YOLOv10n和YOLOv11n,以及YOLOv8-VSC[10 ] 、LTSCD-YOLO[11 ] 和S-YOLO[14 ] ,实验设置与基准模型保持一致. 对比实验结果见表6 . 结果表明,Faster R-CNN、SSD、YOLOv3-Tiny和YOLOv4-Tiny不仅结构复杂,且检测精度较低;YOLOv5n虽然改进了检测性能,但FPS提升有限,精度较低;YOLOX-Tiny的精度略优,但因庞大的参数量导致速度较慢. 相比之下,改进模型在与YOLOv9n、YOLOv10n和YOLOv11n的对比中,mAP@0.5分别提升了3.8、4.0、3.6个百分点,参数量和计算量大幅降低,FPS显著提升. 尽管S-YOLO精度较高,但参数量较高,检测速度不如LTSCD-YOLO. 改进模型以1.4 M的参数量和5.3 G的计算量,达到了94.5%的mAP@0.5值和156帧/s的速度,显著优于其他模型. 综上所述,所提模型表现出较强的竞争力,兼顾轻量化与检测精度,适合部署在计算资源有限的终端设备上. ...
1
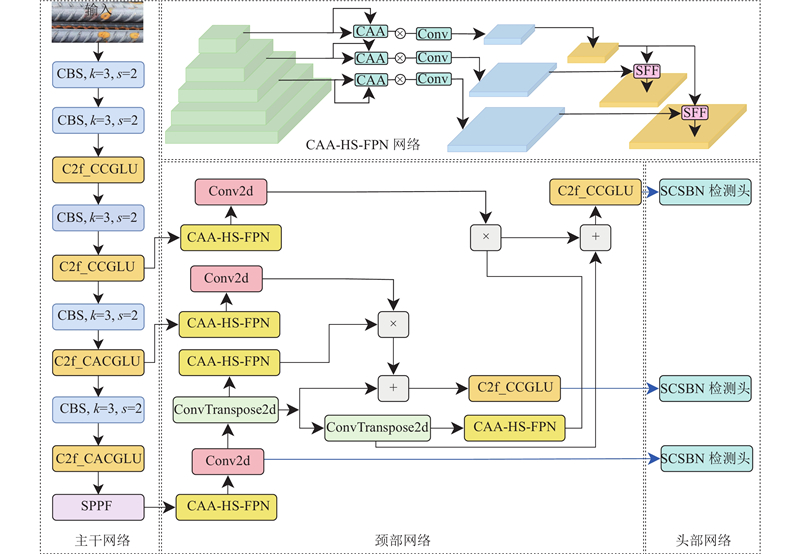
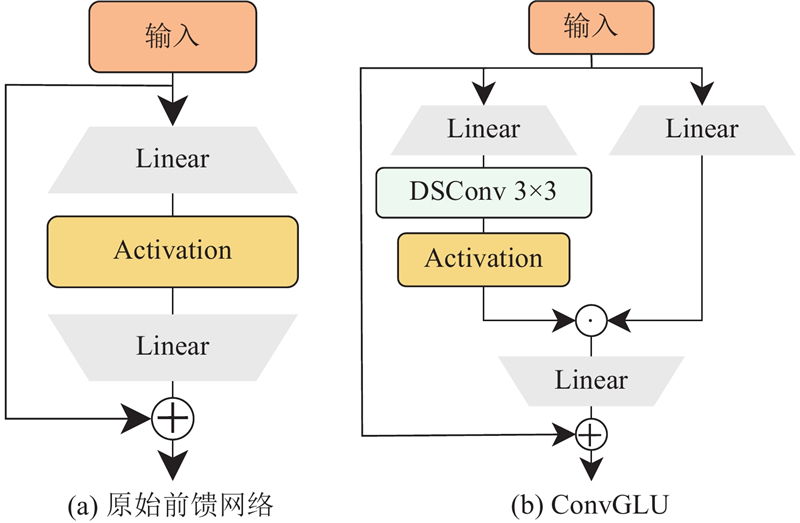
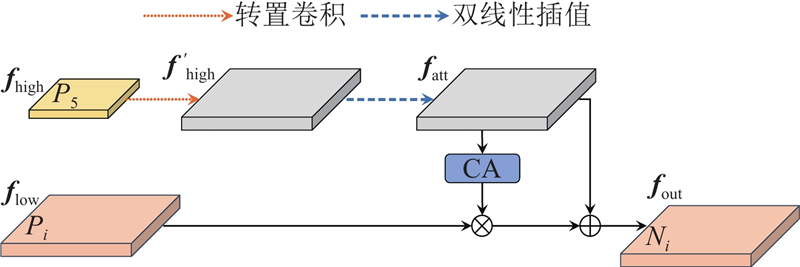
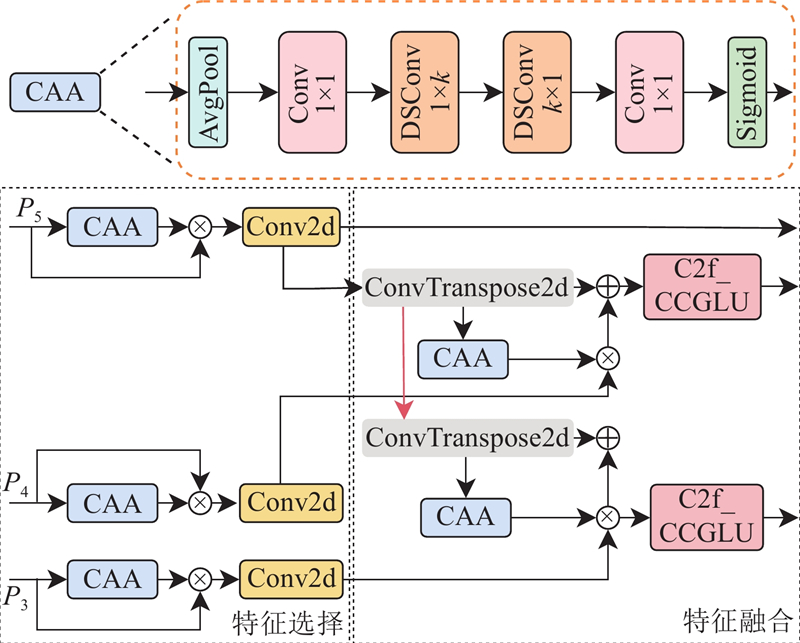
... 鉴于以上研究存在的局限性,以YOLOv8n为基准模型,提出轻量化、高效的螺纹钢表面缺陷检测算法. 1)结合卷积门控线性单元(convolutional gated linear unit, ConvGLU)[15 ] 和自注意力机制重新设计C2f模块,在此基础上构建轻量化的CACGLUFormer主干框架,旨在有效获取全局信息,增强特征提取能力,同时减少模型参数量,加快模型推理速度. 2)采用上下文锚点注意力(context anchor attention, CAA)模块[16 ] 对高层筛选特征金字塔网络(high-level screening-feature pyramid network, HS-FPN)[17 ] 进行改进,通过带状卷积策略聚焦远距离像素信息,并减少信息冗余,提高检测效率. 3)设计轻量化的自适应共享卷积分离批归一化(shared convolutional separate batch normalization, SCSBN)检测头,通过共享参数权重和引入自适应尺度缩放机制,在提升参数利用率的同时保证检测精度. 4)使用Unified-IoU作为边界框损失函数,通过动态权重分配提升密集缺陷检测性能. ...
1
... 鉴于以上研究存在的局限性,以YOLOv8n为基准模型,提出轻量化、高效的螺纹钢表面缺陷检测算法. 1)结合卷积门控线性单元(convolutional gated linear unit, ConvGLU)[15 ] 和自注意力机制重新设计C2f模块,在此基础上构建轻量化的CACGLUFormer主干框架,旨在有效获取全局信息,增强特征提取能力,同时减少模型参数量,加快模型推理速度. 2)采用上下文锚点注意力(context anchor attention, CAA)模块[16 ] 对高层筛选特征金字塔网络(high-level screening-feature pyramid network, HS-FPN)[17 ] 进行改进,通过带状卷积策略聚焦远距离像素信息,并减少信息冗余,提高检测效率. 3)设计轻量化的自适应共享卷积分离批归一化(shared convolutional separate batch normalization, SCSBN)检测头,通过共享参数权重和引入自适应尺度缩放机制,在提升参数利用率的同时保证检测精度. 4)使用Unified-IoU作为边界框损失函数,通过动态权重分配提升密集缺陷检测性能. ...
Accurate leukocyte detection based on deformable-DETR and multi-level feature fusion for aiding diagnosis of blood diseases
1
2024
... 鉴于以上研究存在的局限性,以YOLOv8n为基准模型,提出轻量化、高效的螺纹钢表面缺陷检测算法. 1)结合卷积门控线性单元(convolutional gated linear unit, ConvGLU)[15 ] 和自注意力机制重新设计C2f模块,在此基础上构建轻量化的CACGLUFormer主干框架,旨在有效获取全局信息,增强特征提取能力,同时减少模型参数量,加快模型推理速度. 2)采用上下文锚点注意力(context anchor attention, CAA)模块[16 ] 对高层筛选特征金字塔网络(high-level screening-feature pyramid network, HS-FPN)[17 ] 进行改进,通过带状卷积策略聚焦远距离像素信息,并减少信息冗余,提高检测效率. 3)设计轻量化的自适应共享卷积分离批归一化(shared convolutional separate batch normalization, SCSBN)检测头,通过共享参数权重和引入自适应尺度缩放机制,在提升参数利用率的同时保证检测精度. 4)使用Unified-IoU作为边界框损失函数,通过动态权重分配提升密集缺陷检测性能. ...
基于改进YOLOv8s的鼓形滚子表面缺陷检测算法
1
2024
... YOLOv8是由Ultralytics团队开发的开源网络[18 ] ,集成了检测、分割和实时追踪等任务,继承并优化了YOLO系列模型的核心设计. 相较于之前的YOLO版本,YOLOv8的主要创新在于采用了无锚框(anchor-free)检测方法,取代传统的锚框机制,从而简化了目标位置和大小的预测过程. 通过解耦头(decoupled head)结构,YOLOv8将分类任务与回归任务分离,从而减少了模型训练中的干扰. 此外,YOLOv8在主干网络中采用C2f模块,优化了梯度流,增强了特征提取能力,并减小了网络的计算量. 同时,主干网络的空间金字塔池化快速(spatial pyramid pooling fast, SPPF)模块通过多尺度池化操作增强了模型对不同尺度目标的适应性. 在特征融合网络(即颈部网络)中,YOLOv8移除了部分冗余的下采样层,改进特征融合方式,同时在检测头部分进一步简化网络结构,以确保高效的实时追踪能力. YOLOv8按照网络深度和宽度提供了n、s、m、l、x这5种不同尺寸;经实验对比,为了平衡检测精度与资源消耗,选择YOLOv8n作为螺纹钢表面缺陷检测的基准模型. ...
基于改进YOLOv8s的鼓形滚子表面缺陷检测算法
1
2024
... YOLOv8是由Ultralytics团队开发的开源网络[18 ] ,集成了检测、分割和实时追踪等任务,继承并优化了YOLO系列模型的核心设计. 相较于之前的YOLO版本,YOLOv8的主要创新在于采用了无锚框(anchor-free)检测方法,取代传统的锚框机制,从而简化了目标位置和大小的预测过程. 通过解耦头(decoupled head)结构,YOLOv8将分类任务与回归任务分离,从而减少了模型训练中的干扰. 此外,YOLOv8在主干网络中采用C2f模块,优化了梯度流,增强了特征提取能力,并减小了网络的计算量. 同时,主干网络的空间金字塔池化快速(spatial pyramid pooling fast, SPPF)模块通过多尺度池化操作增强了模型对不同尺度目标的适应性. 在特征融合网络(即颈部网络)中,YOLOv8移除了部分冗余的下采样层,改进特征融合方式,同时在检测头部分进一步简化网络结构,以确保高效的实时追踪能力. YOLOv8按照网络深度和宽度提供了n、s、m、l、x这5种不同尺寸;经实验对比,为了平衡检测精度与资源消耗,选择YOLOv8n作为螺纹钢表面缺陷检测的基准模型. ...
1
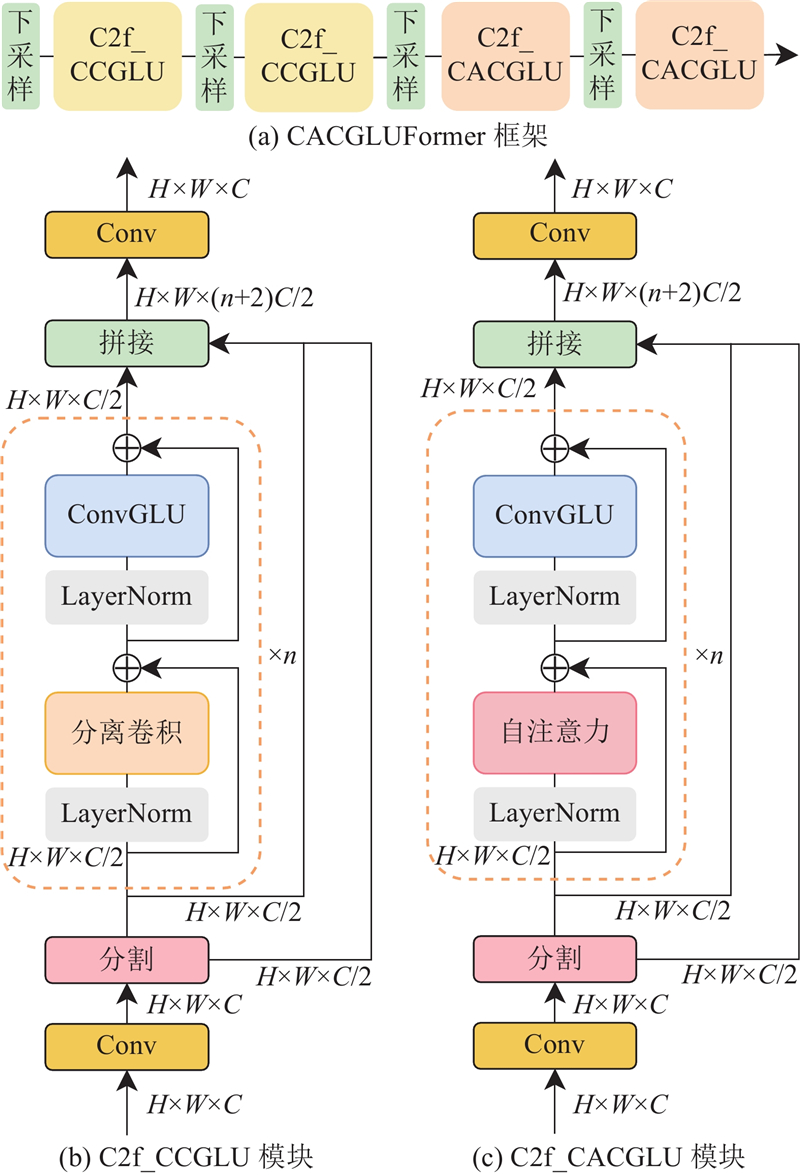
... 首先,基于MetaFormer框架,结合卷积门控线性单元的条件位置编码特性和自注意力机制的动态全局交互能力,设计C2f_CCGLU(C2f_ConvFormer with ConvGLU)、C2f_CACGLU(C2f_CAFormer with ConvGLU)模块,替换原有主干网络中的C2f模块,构建具有全局信息建模能力的CACGLUFormer主干网络,从而有效获取全局信息,在增强特征提取能力的同时减少模型参数量,加快模型推理速度. 其次,采用CAA模块对HS-FPN网络进行改进,替换颈部网络的PANet结构,从而有效聚焦远距离像素信息,增强图像中心区域的特征表达,并通过特征选择减少多尺度融合过程中的信息冗余,提高检测效率. 随后设计轻量化的自适应SCSBN检测头,通过共享参数权重和引入自适应尺度缩放机制,在提升参数利用率的同时保证检测精度. 最后,使用具有动态权重分配的边界框损失函数Unified-IoU[19 ] 替换CIoU,动态地将模型注意力从低质量预测框转移到高质量预测框,提升密集缺陷检测性能. ...
MetaFormer baselines for vision
1
2024
... YOLOv8的主干网络主要由下采样卷积层和残差模块堆叠而成,导致模型体积过大,不利于在资源受限的移动设备上部署. 此外,传统CNN模型难以捕捉长距离依赖关系,限制了全局信息的建模,无法有效获取螺纹钢表面缺陷的全局特征. 为了解决上述问题,重新设计C2f模块,提出C2f_CCGLU和C2f_CACGLU模块,并基于MetaFormer框架[20 ] 构建轻量化主干网络CACGLUFormer. ...
An optimized deep learning model for flower classification using NAS-FPN and faster R-CNN
1
2020
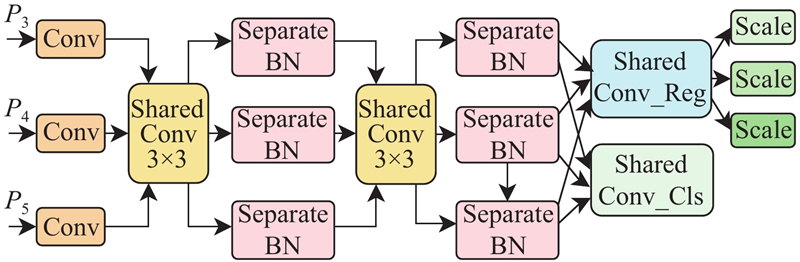
... YOLOv8采用主流解耦头,将分类和回归任务分离,每个分支都通过2个3×3卷积和1个1×1卷积进行特征提取. 此举虽然提升了检测性能,但是导致参数利用率低下. 若使用共享卷积,由于不同层级之间特征的差异性,直接在共享参数时采用BN层会导致其滑动平均值产生误差,而使用组归一化(group normalization, GN)层会增加推理时间. 受特征融合网络NAS-FPN[21 ] 的启发,重新设计轻量化的自适应SCSBN检测头,在共享卷积层的同时使用独立的BN层,使得模型可以更加灵活地调整每个任务的特征分布. 这种做法避免了共享卷积在不同任务中特征学习能力受限的问题,从而在大幅降低参数量的同时保持较高的精度. 检测头的结构如图6 所示. 首先将颈部输出的3个特征层(P 3 ~P 5 )分别通过1×1的卷积,调整为相同的隐藏层通道数,再通过共享卷积汇集不同尺度的特征层进行特征提取,之后分别通过独立的BN(separate BN)层进行归一化,最后将回归分支和分类分支分离. 在分类分支中使用共享的Conv_Cls层预测类别,在回归分支中先通过共享的Conv_Reg层预测边界框,再使用自适应的Scale因子对特征进行动态缩放,调整目标尺度,以定位不同尺寸的缺陷目标. ...
Smooth GIoU loss for oriented object detection in remote sensing images
1
2023
... 边界框回归损失函数作为目标检测模型中定位分支的关键组成部分,对检测器的定位精度具有显著影响,而交并比(intersection over union, IoU)在很大程度上反映了当前预测框与真实框之间的匹配程度. 为了提升回归准确性,研究人员不断在IoU基础上加入中心距离、长宽比等几何因素,相继提出GIoU[22 ] 、CIoU、EIoU[23 ] 、WIoU等一系列IoU损失函数. 但是,仅仅对几何差异进行细化的做法具有一定的局限性,且新引入的几何度量与IoU本身存在潜在关联,直接对两者操作可能会导致过度耦合. 因此,引入与YOLO现有的边界框回归损失相结合的Unified-IoU损失函数,改进YOLOv8网络中原有的CIoU损失函数. ...
A systematic IoU-related method: beyond simplified regression for better localization
1
2021
... 边界框回归损失函数作为目标检测模型中定位分支的关键组成部分,对检测器的定位精度具有显著影响,而交并比(intersection over union, IoU)在很大程度上反映了当前预测框与真实框之间的匹配程度. 为了提升回归准确性,研究人员不断在IoU基础上加入中心距离、长宽比等几何因素,相继提出GIoU[22 ] 、CIoU、EIoU[23 ] 、WIoU等一系列IoU损失函数. 但是,仅仅对几何差异进行细化的做法具有一定的局限性,且新引入的几何度量与IoU本身存在潜在关联,直接对两者操作可能会导致过度耦合. 因此,引入与YOLO现有的边界框回归损失相结合的Unified-IoU损失函数,改进YOLOv8网络中原有的CIoU损失函数. ...
1
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
1
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
2
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
... 选用公开的NEU-DET钢材表面缺陷数据集对所提模型进行泛化性验证. 该数据集共有1 800张图片,包括裂纹、斑块、内含物、点蚀表面、轧制氧化皮和划痕6种缺陷,数据集划分比例和训练参数设置均与上述实验保持一致. 基准模型YOLOv8n、YOLOv11、本研究算法和DCS-YOLOv8[7 ] 、SDB-YOLOv8s[26 ] 的对比实验结果见表7 . ...
1
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
1
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
Research on real-time detection method of rail corrugation based on improved ShuffleNet V2
1
2023
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
基于改进YOLOv8s的钢材表面缺陷检测算法
1
2025
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
基于改进YOLOv8s的钢材表面缺陷检测算法
1
2025
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
1
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
1
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...
1
... 为了验证CACGLUFormer轻量化主干网络的高效性,将其与目前主流的轻量化网络进行对比,包括GhostNet[24 ] 、GhostNetV2[25 ] 、MobileViT[26 ] 、MobileNetV3[27 ] 、MobileNetV4[28 ] 、ShuffleNetV2[29 ] 、EfficientNetV2[30 ] 、VanillaNet[31 ] 、FasterNet[32 ] 、StarNet[33 ] . 用上述网络替换YOLOv8n主干网络,在螺纹钢数据集上进行对比实验,实验结果如表2 所示. 由结果可知,GhostNet、ShuffleNetV2、VanillaNet网络的参数量虽然大幅下降,但是精度随之降低,这是因为这些网络在设计时侧重于极限压缩参数量和计算量,忽略了特征表示能力的维持,从而影响了最终的检测精度. GhostNetV2、MobileNetV3、StarNet的参数量和计算量与所提主干网络相近,但是其mAP@0.5、mAP@0.5-0.95均低于CACGLUFormer,由此可见,提出的轻量化主干网络框架在检测精度和轻量化之间达到了较好的平衡. 在CACGLUFormer框架中,C2f_CCGLU通过分离卷积捕捉局部空间特征并通过ConvGLU调节通道特征,使模型保持了较强的局部特征表示能力. C2f_CACGLU模块进一步引入自注意力机制,增强了模型对全局信息的建模能力,能够有效捕捉长距离依赖关系,且在低维度空间中有效减少了计算开销. 综上所述,提出的轻量化主干网络克服了传统轻量化网络在精度与资源消耗之间的权衡问题,在减少参数量和计算量的同时,保证了优异的检测性能. ...







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}