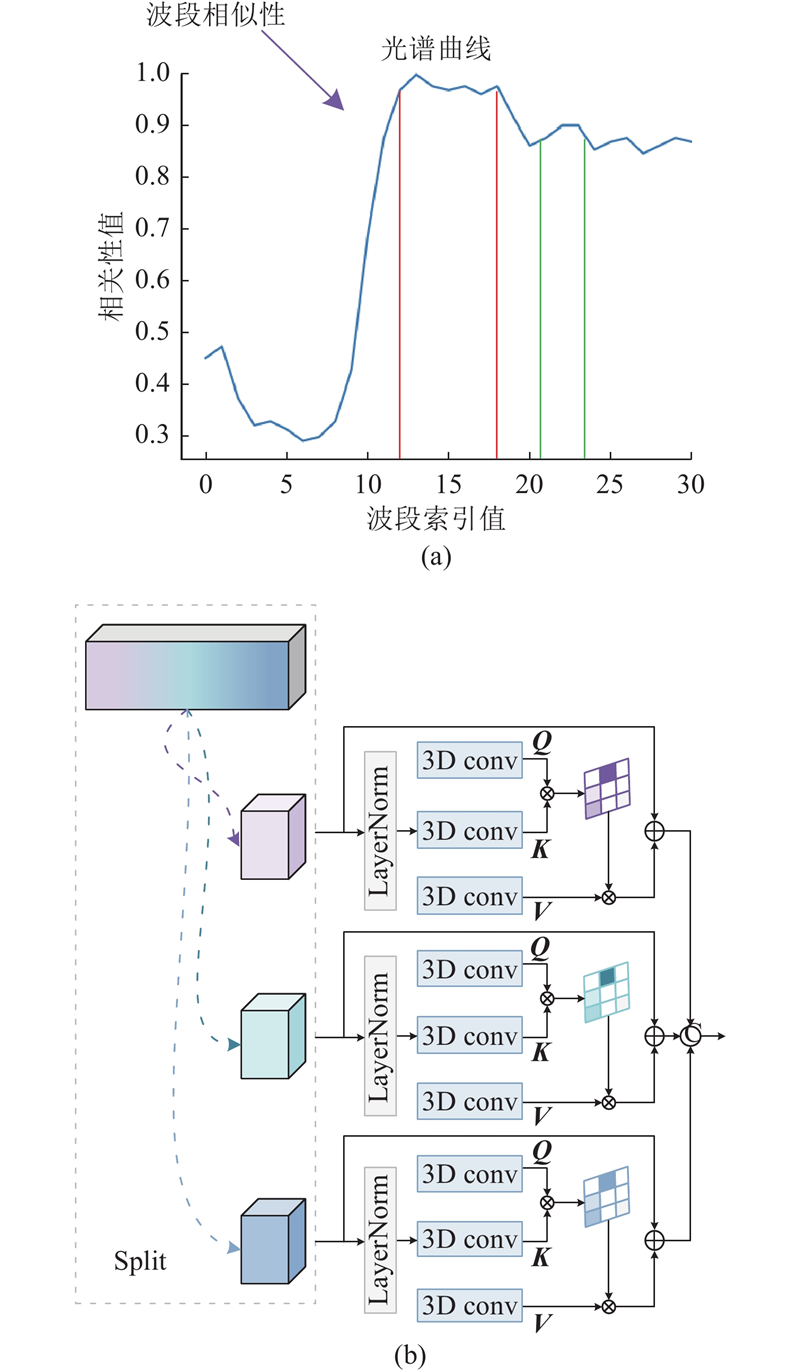
(15) $\begin{split} {\boldsymbol{Q}}_{j},{\boldsymbol{K}}_{j},{\boldsymbol{V}}_{j}=&3\mathrm{DConv}(\mathrm{LN}(\boldsymbol{F}_{j,k}^{})),\\& 3\mathrm{DConv}(\mathrm{LN}(\boldsymbol{F}_{j,k}^{})),\\& 3\mathrm{DConv}(\mathrm{LN}(\boldsymbol{F}_{j,k}^{})),\end{split} $
式中:$ \mathrm{Split}(\cdot ) $ $ {\boldsymbol{F}}_{\text{spat}} $ $ \boldsymbol{F}_{\text{spat}}^{j}(j\in \{1,2,3\}) $ $ {{E}}_{\mathrm{N}}(\cdot ) $ $ \boldsymbol{F}_{j,k}^{} $ $ j $ $ k $ $ \mathrm{LN}(\cdot ) $ $ 3\mathrm{DConv}(\cdot ) $ $ {\boldsymbol{Q}}_{j}\in {\bf{R}}^{B\times C\times DHW} $ $ \boldsymbol{K}_{j}^{}\in {\bf{R}}^{B\times C\times DHW} $ $ {\boldsymbol{V}}_{j}\in {\bf{R}}^{B\times C\times DHW} $ $ j $ $ B $ $ C $ $ D $ $ H $ $ W $ $ {T}(\cdot ) $ $ {\hat{\boldsymbol{F}}}_{j,k}^{} $ $ (j\in \{1,2,3\}) $ $ \otimes $ $ \oplus $ $ {\boldsymbol{F}}_{\text{spat,spect}} $ $ \mathrm{Concat}(\cdot ) $
[1]
WANG Z, CHEN J, HOI S C H Deep learning for image super-resolution: a survey
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2021 , 43 (10 ): 3365 - 3387
DOI:10.1109/TPAMI.2020.2982166
[本文引用: 1]
[3]
胡明志, 孙俊, 杨彪, 等 基于CNN和Transformer聚合的遥感图像超分辨率重建
[J]. 浙江大学学报: 工学版 , 2025 , 59 (5 ): 938 - 946
DOI:10.3785/j.issn.1008-973X.2025.05.007
[本文引用: 1]
HU Mingzhi, SUN Jun, YANG Biao, et al Super-resolution reconstruction of remote sensing image based on CNN and Transformer aggregation
[J]. Journal of Zhejiang University: Engineering Science , 2025 , 59 (5 ): 938 - 946
DOI:10.3785/j.issn.1008-973X.2025.05.007
[本文引用: 1]
[4]
HONG D, GAO L, YOKOYA N, et al More diverse means better: multimodal deep learning meets remote-sensing imagery classification
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2021 , 59 (5 ): 4340 - 4354
DOI:10.1109/TGRS.2020.3016820
[本文引用: 1]
[5]
ZHUANG L, NG M K, FU X, et al Hy-demosaicing: hyperspectral blind reconstruction from spectral subsampling
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2021 , 60 : 5515815
[本文引用: 1]
[6]
DENG S Q, DENG L J, WU X, et al PSRT: pyramid shuffle-and-reshuffle transformer for multispectral and hyperspectral image fusion
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2023 , 61 : 5503715
DOI:10.1109/tgrs.2023.3244750
[本文引用: 1]
[7]
吕鑫栋, 李娇, 邓真楠, 等 基于改进Transformer的结构化图像超分辨网络
[J]. 浙江大学学报: 工学版 , 2023 , 57 (5 ): 865 - 874,910
DOI:10.3785/j.issn.1008-973X.2023.05.002
[本文引用: 1]
LV Xindong, LI Jiao, DENG Zhennan, et al Structured image super-resolution network based on improved Transformer
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (5 ): 865 - 874,910
DOI:10.3785/j.issn.1008-973X.2023.05.002
[本文引用: 1]
[8]
LI S, DIAN R, FANG L, et al Fusing hyperspectral and multispectral images via coupled sparse tensor factorization
[J]. IEEE Transactions on Image Processing , 2018 , 27 (8 ): 4118 - 4130
[本文引用: 1]
[9]
DIAN R, LI S, FANG L, et al Multispectral and hyperspectral image fusion with spatial-spectral sparse representation
[J]. Information Fusion , 2019 , 49 : 262 - 270
DOI:10.1016/j.inffus.2018.11.012
[本文引用: 1]
[10]
PALSSON F, SVEINSSON J R, ULFARSSON M O Multispectral and hyperspectral image fusion using a 3-D-convolutional neural network
[J]. IEEE Geoscience and Remote Sensing Letters , 2017 , 14 (5 ): 639 - 643
DOI:10.1109/LGRS.2017.2668299
[本文引用: 1]
[11]
ZHANG X, HUANG W, WANG Q, et al SSR-NET: spatial-spectral reconstruction network for hyperspectral and multispectral image fusion
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2020 , 59 (7 ): 5953 - 5965
DOI:10.1109/tgrs.2020.3018732
[本文引用: 2]
[12]
DIAN R, LI S, KANG X Regularizing hyperspectral and multispectral image fusion by CNN denoiser
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2021 , 32 (3 ): 1124 - 1135
DOI:10.1109/TNNLS.2020.2980398
[本文引用: 2]
[13]
YU H, LING Z, ZHENG K, et al Unsupervised hyperspectral and multispectral image fusion with deep spectral-spatial collaborative constraint
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2024 , 62 : 5534114
DOI:10.1109/tgrs.2024.3472226
[本文引用: 1]
[14]
YAN J, ZHANG K, SUN Q, et al Spatial-spectral unfolding network with mutual guidance for multispectral and hyperspectral image fusion
[J]. Pattern Recognition , 2025 , 161 : 111277
DOI:10.1016/j.patcog.2024.111277
[本文引用: 1]
[15]
LI J, ZHENG K, GAO L, et al Enhanced deep image prior for unsupervised hyperspectral image super-resolution
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2025 , 63 : 5504218
[本文引用: 2]
[16]
HU J F, HUANG T Z, DENG L J, et al Fusformer: a transformer-based fusion network for hyperspectral image super-resolution
[J]. IEEE Geoscience and Remote Sensing Letters , 2022 , 19 : 6012305
[本文引用: 3]
[17]
MA Q, JIANG J, LIU X, et al Learning a 3D-CNN and Transformer prior for hyperspectral image super-resolution
[J]. Information Fusion , 2023 , 100 : 101907
DOI:10.1016/j.inffus.2023.101907
[本文引用: 1]
[18]
JIA S, MIN Z, FU X Multiscale spatial-spectral transformer network for hyperspectral and multispectral image fusion
[J]. Information Fusion , 2023 , 96 : 117 - 129
DOI:10.1016/j.inffus.2023.03.011
[本文引用: 1]
[19]
SUN L, ZHOU J, YE Q, et al MDC-FusFormer: multiscale deep cross-fusion transformer network for hyperspectral and multispectral image fusion
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2024 , 62 : 5528914
DOI:10.1109/tgrs.2024.3451551
[本文引用: 1]
[20]
WANG X, ZHANG F, ZHANG K, et al Learning spatial-spectral dual adaptive graph embedding for multispectral and hyperspectral image fusion
[J]. Pattern Recognition , 2024 , 151 : 110365
DOI:10.1016/j.patcog.2024.110365
[本文引用: 2]
[21]
LIU S, SHAO T, LIU S, et al An asymptotic multiscale symmetric fusion network for hyperspectral and multispectral image fusion
[J]. IEEE Transactions on Geoscience and Remote Sensing , 2025 , 63 : 5503016
[本文引用: 1]
[22]
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2021: 9992–10002.
[本文引用: 1]
[23]
MA Q, JIANG J, LIU X, et al Reciprocal transformer for hyperspectral and multispectral image fusion
[J]. Information Fusion , 2024 , 104 : 102148
DOI:10.1016/j.inffus.2023.102148
[本文引用: 2]
[24]
LIU Z, WANG W, MA Q, et al Rethinking 3D-CNN in hyperspectral image super-resolution
[J]. Remote Sensing , 2023 , 15 (10 ): 2574
DOI:10.3390/rs15102574
[本文引用: 1]
[25]
ANUL HAQ M, BEN HADJ HASSINE S, MALEBARY S J, et al 3D-CNNHSR: a 3-dimensional convolutional neural network for hyperspectral super-resolution
[J]. Computer Systems Science and Engineering , 2023 , 47 (2 ): 2689 - 2705
DOI:10.32604/csse.2023.039904
[本文引用: 1]
[26]
YASUMA F, MITSUNAGA T, ISO D, et al Generalized assorted pixel camera: postcapture control of resolution, dynamic range, and spectrum
[J]. IEEE Transactions on Image Processing , 2010 , 19 (9 ): 2241 - 2253
DOI:10.1109/TIP.2010.2046811
[本文引用: 1]
[27]
CHAKRABARTI A, ZICKLER T. Statistics of real-world hyperspectral images [C]// CVPR 2011 . Colorado Springs: IEEE, 2011: 193–200.
[本文引用: 1]
[28]
XIE Q, ZHOU M, ZHAO Q, et al. Multispectral and hyperspectral image fusion by MS/HS fusion net [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 1585–1594.
[本文引用: 1]
[29]
WANG W, ZENG W, HUANG Y, et al. Deep blind hyperspectral image fusion [C]// IEEE/CVF International Conference on Computer Vision . Seoul: IEEE, 2019: 4149-4158.
[本文引用: 1]
[30]
ZHANG L, NIE J, WEI W, et al. Unsupervised adaptation learning for hyperspectral imagery super-resolution [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition . Seattle: IEEE, 2020: 3070–3079.
[本文引用: 1]
Deep learning for image super-resolution: a survey
1
2021
... 高光谱成像技术能同时获取同一场景中数百个连续且狭窄的光谱波段信息,在多个图像分析领域内展现出巨大的应用潜力[1 ] . 然而受成像机制限制,高光谱图像普遍存在空间分辨率不足的固有缺陷. 近年来,多源数据融合技术已成为突破该技术瓶颈的重要研究方向,即通过结合高分辨率多光谱图像(high resolution multispectral image, HR-MSI)的空间细节与低分辨率高光谱图像(low resolution hyperspectral image, LR-HSI)的光谱特征,最终融合出高分辨率的高光谱图像[2 ] (high resolution hyperspectral image, HR-HSI). 这种方法不仅扩展了高光谱图像的应用范围,还提高了其在环境监测[3 ] 、资源探查[4 ] 、军事国防[5 ] 等关键领域的实用性和准确性[6 -7 ] . ...
Multispectral and hyperspectral image fusion in remote sensing: a survey
1
2023
... 高光谱成像技术能同时获取同一场景中数百个连续且狭窄的光谱波段信息,在多个图像分析领域内展现出巨大的应用潜力[1 ] . 然而受成像机制限制,高光谱图像普遍存在空间分辨率不足的固有缺陷. 近年来,多源数据融合技术已成为突破该技术瓶颈的重要研究方向,即通过结合高分辨率多光谱图像(high resolution multispectral image, HR-MSI)的空间细节与低分辨率高光谱图像(low resolution hyperspectral image, LR-HSI)的光谱特征,最终融合出高分辨率的高光谱图像[2 ] (high resolution hyperspectral image, HR-HSI). 这种方法不仅扩展了高光谱图像的应用范围,还提高了其在环境监测[3 ] 、资源探查[4 ] 、军事国防[5 ] 等关键领域的实用性和准确性[6 -7 ] . ...
基于CNN和Transformer聚合的遥感图像超分辨率重建
1
2025
... 高光谱成像技术能同时获取同一场景中数百个连续且狭窄的光谱波段信息,在多个图像分析领域内展现出巨大的应用潜力[1 ] . 然而受成像机制限制,高光谱图像普遍存在空间分辨率不足的固有缺陷. 近年来,多源数据融合技术已成为突破该技术瓶颈的重要研究方向,即通过结合高分辨率多光谱图像(high resolution multispectral image, HR-MSI)的空间细节与低分辨率高光谱图像(low resolution hyperspectral image, LR-HSI)的光谱特征,最终融合出高分辨率的高光谱图像[2 ] (high resolution hyperspectral image, HR-HSI). 这种方法不仅扩展了高光谱图像的应用范围,还提高了其在环境监测[3 ] 、资源探查[4 ] 、军事国防[5 ] 等关键领域的实用性和准确性[6 -7 ] . ...
基于CNN和Transformer聚合的遥感图像超分辨率重建
1
2025
... 高光谱成像技术能同时获取同一场景中数百个连续且狭窄的光谱波段信息,在多个图像分析领域内展现出巨大的应用潜力[1 ] . 然而受成像机制限制,高光谱图像普遍存在空间分辨率不足的固有缺陷. 近年来,多源数据融合技术已成为突破该技术瓶颈的重要研究方向,即通过结合高分辨率多光谱图像(high resolution multispectral image, HR-MSI)的空间细节与低分辨率高光谱图像(low resolution hyperspectral image, LR-HSI)的光谱特征,最终融合出高分辨率的高光谱图像[2 ] (high resolution hyperspectral image, HR-HSI). 这种方法不仅扩展了高光谱图像的应用范围,还提高了其在环境监测[3 ] 、资源探查[4 ] 、军事国防[5 ] 等关键领域的实用性和准确性[6 -7 ] . ...
More diverse means better: multimodal deep learning meets remote-sensing imagery classification
1
2021
... 高光谱成像技术能同时获取同一场景中数百个连续且狭窄的光谱波段信息,在多个图像分析领域内展现出巨大的应用潜力[1 ] . 然而受成像机制限制,高光谱图像普遍存在空间分辨率不足的固有缺陷. 近年来,多源数据融合技术已成为突破该技术瓶颈的重要研究方向,即通过结合高分辨率多光谱图像(high resolution multispectral image, HR-MSI)的空间细节与低分辨率高光谱图像(low resolution hyperspectral image, LR-HSI)的光谱特征,最终融合出高分辨率的高光谱图像[2 ] (high resolution hyperspectral image, HR-HSI). 这种方法不仅扩展了高光谱图像的应用范围,还提高了其在环境监测[3 ] 、资源探查[4 ] 、军事国防[5 ] 等关键领域的实用性和准确性[6 -7 ] . ...
Hy-demosaicing: hyperspectral blind reconstruction from spectral subsampling
1
2021
... 高光谱成像技术能同时获取同一场景中数百个连续且狭窄的光谱波段信息,在多个图像分析领域内展现出巨大的应用潜力[1 ] . 然而受成像机制限制,高光谱图像普遍存在空间分辨率不足的固有缺陷. 近年来,多源数据融合技术已成为突破该技术瓶颈的重要研究方向,即通过结合高分辨率多光谱图像(high resolution multispectral image, HR-MSI)的空间细节与低分辨率高光谱图像(low resolution hyperspectral image, LR-HSI)的光谱特征,最终融合出高分辨率的高光谱图像[2 ] (high resolution hyperspectral image, HR-HSI). 这种方法不仅扩展了高光谱图像的应用范围,还提高了其在环境监测[3 ] 、资源探查[4 ] 、军事国防[5 ] 等关键领域的实用性和准确性[6 -7 ] . ...
PSRT: pyramid shuffle-and-reshuffle transformer for multispectral and hyperspectral image fusion
1
2023
... 高光谱成像技术能同时获取同一场景中数百个连续且狭窄的光谱波段信息,在多个图像分析领域内展现出巨大的应用潜力[1 ] . 然而受成像机制限制,高光谱图像普遍存在空间分辨率不足的固有缺陷. 近年来,多源数据融合技术已成为突破该技术瓶颈的重要研究方向,即通过结合高分辨率多光谱图像(high resolution multispectral image, HR-MSI)的空间细节与低分辨率高光谱图像(low resolution hyperspectral image, LR-HSI)的光谱特征,最终融合出高分辨率的高光谱图像[2 ] (high resolution hyperspectral image, HR-HSI). 这种方法不仅扩展了高光谱图像的应用范围,还提高了其在环境监测[3 ] 、资源探查[4 ] 、军事国防[5 ] 等关键领域的实用性和准确性[6 -7 ] . ...
基于改进Transformer的结构化图像超分辨网络
1
2023
... 高光谱成像技术能同时获取同一场景中数百个连续且狭窄的光谱波段信息,在多个图像分析领域内展现出巨大的应用潜力[1 ] . 然而受成像机制限制,高光谱图像普遍存在空间分辨率不足的固有缺陷. 近年来,多源数据融合技术已成为突破该技术瓶颈的重要研究方向,即通过结合高分辨率多光谱图像(high resolution multispectral image, HR-MSI)的空间细节与低分辨率高光谱图像(low resolution hyperspectral image, LR-HSI)的光谱特征,最终融合出高分辨率的高光谱图像[2 ] (high resolution hyperspectral image, HR-HSI). 这种方法不仅扩展了高光谱图像的应用范围,还提高了其在环境监测[3 ] 、资源探查[4 ] 、军事国防[5 ] 等关键领域的实用性和准确性[6 -7 ] . ...
基于改进Transformer的结构化图像超分辨网络
1
2023
... 高光谱成像技术能同时获取同一场景中数百个连续且狭窄的光谱波段信息,在多个图像分析领域内展现出巨大的应用潜力[1 ] . 然而受成像机制限制,高光谱图像普遍存在空间分辨率不足的固有缺陷. 近年来,多源数据融合技术已成为突破该技术瓶颈的重要研究方向,即通过结合高分辨率多光谱图像(high resolution multispectral image, HR-MSI)的空间细节与低分辨率高光谱图像(low resolution hyperspectral image, LR-HSI)的光谱特征,最终融合出高分辨率的高光谱图像[2 ] (high resolution hyperspectral image, HR-HSI). 这种方法不仅扩展了高光谱图像的应用范围,还提高了其在环境监测[3 ] 、资源探查[4 ] 、军事国防[5 ] 等关键领域的实用性和准确性[6 -7 ] . ...
Fusing hyperspectral and multispectral images via coupled sparse tensor factorization
1
2018
... 高光谱图像(hyperspectral image, HSI)和多光谱图像(multispectral image, MSI)的融合方法大致分为2类:传统方法和深度学习方法. 传统方法分为基于矩阵分解的方法[8 ] 和基于张量分解的方法[9 ] . 传统方法在处理遥感图像融合时,过程解释性强且运行效率高效,但往往依赖于手工制作的先验知识,而且其有效性通常受到先验知识准确性的限制. ...
Multispectral and hyperspectral image fusion with spatial-spectral sparse representation
1
2019
... 高光谱图像(hyperspectral image, HSI)和多光谱图像(multispectral image, MSI)的融合方法大致分为2类:传统方法和深度学习方法. 传统方法分为基于矩阵分解的方法[8 ] 和基于张量分解的方法[9 ] . 传统方法在处理遥感图像融合时,过程解释性强且运行效率高效,但往往依赖于手工制作的先验知识,而且其有效性通常受到先验知识准确性的限制. ...
Multispectral and hyperspectral image fusion using a 3-D-convolutional neural network
1
2017
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
SSR-NET: spatial-spectral reconstruction network for hyperspectral and multispectral image fusion
2
2020
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
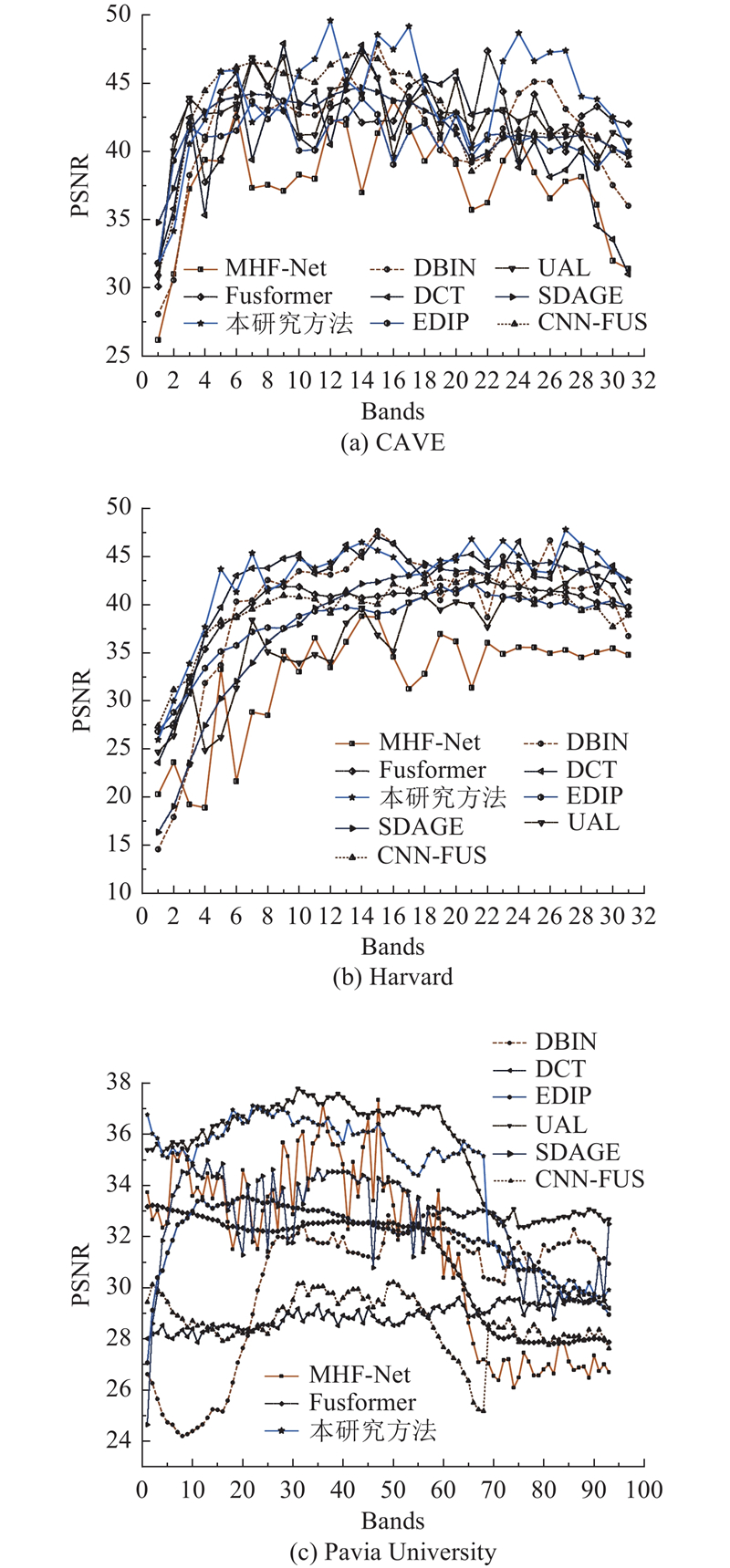
... 采用3个遥感数据集进行实验,哥伦比亚大学计算机视觉实验室(CAVE)数据集[26 ] 、Harvard数据集[27 ] 以及真实数据集 (Pavia University数据集[11 ] ). 对于CAVE数据集和Harvard数据集,使用尼康D700相机的光谱响应函数R 生成HR-MSI. 使用多个尺寸(3$ \times $ 3 、5$ \times $ 5 、7$ \times $ 7 、9$ \times $ 9) 的模糊核,对HR-HSI进行处理,再下采样8倍得到LR-HSI. ...
Regularizing hyperspectral and multispectral image fusion by CNN denoiser
2
2021
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
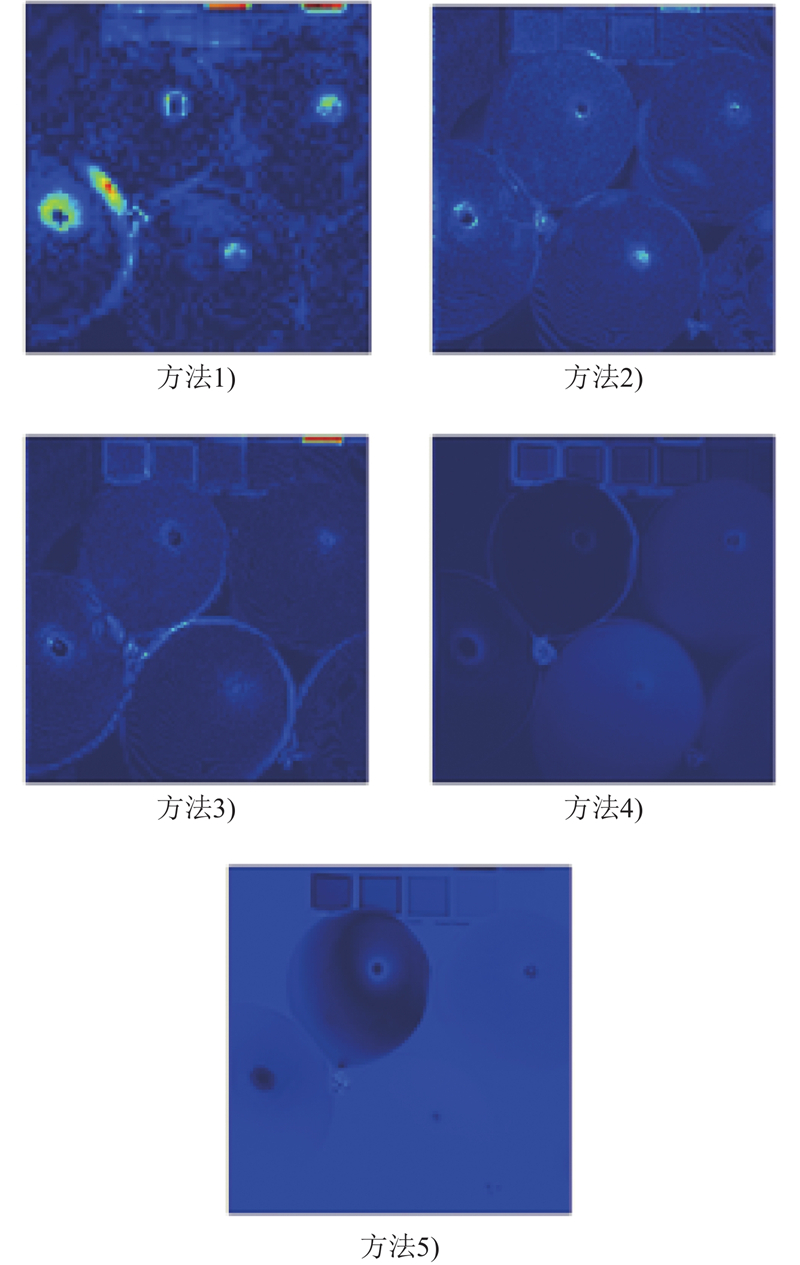
... 将本研究所提方法与8种方法进行对比,如MHF-net[28 ] 、DBIN[29 ] 、CNN-FUS[12 ] 、UAL[30 ] 、Fusformer[16 ] 、DCT[23 ] 、SDAGE[20 ] 以及EDIP[15 ] ,所有对比方法均在相同的参数设置和实验环境下进行测试. 本研究从定性结果和定量分析2方面衡量算法的优劣,其中定量分析采用4个评估指标,峰值信噪比(peak signal-to-noise ratio,PSNR)、光谱角映射(spectral angle mapper,SAM)、相对全局误差(error relative to the global absolute sum, ERGAS)和结构相似性(structural similarity index, SSIM). PSNR通过比较原始图像和失真图像的均方误差来衡量图像质量,PSNR越大,表示图像质量越好. SAM用来度量2个光谱向量之间的角度差异,值越小表示2个光谱向量越相似. ERGAS是测量融合结果与全分辨率高光谱图像之间的平均误差和动态范围变化的全局指标,值越小,表示结果越好. SSIM通过比较2个图像在结构、亮度和对比度方面的差异来度量图像相似度,值越接近1表示2个图像越相似. ...
Unsupervised hyperspectral and multispectral image fusion with deep spectral-spatial collaborative constraint
1
2024
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
Spatial-spectral unfolding network with mutual guidance for multispectral and hyperspectral image fusion
1
2025
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
Enhanced deep image prior for unsupervised hyperspectral image super-resolution
2
2025
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
... 将本研究所提方法与8种方法进行对比,如MHF-net[28 ] 、DBIN[29 ] 、CNN-FUS[12 ] 、UAL[30 ] 、Fusformer[16 ] 、DCT[23 ] 、SDAGE[20 ] 以及EDIP[15 ] ,所有对比方法均在相同的参数设置和实验环境下进行测试. 本研究从定性结果和定量分析2方面衡量算法的优劣,其中定量分析采用4个评估指标,峰值信噪比(peak signal-to-noise ratio,PSNR)、光谱角映射(spectral angle mapper,SAM)、相对全局误差(error relative to the global absolute sum, ERGAS)和结构相似性(structural similarity index, SSIM). PSNR通过比较原始图像和失真图像的均方误差来衡量图像质量,PSNR越大,表示图像质量越好. SAM用来度量2个光谱向量之间的角度差异,值越小表示2个光谱向量越相似. ERGAS是测量融合结果与全分辨率高光谱图像之间的平均误差和动态范围变化的全局指标,值越小,表示结果越好. SSIM通过比较2个图像在结构、亮度和对比度方面的差异来度量图像相似度,值越接近1表示2个图像越相似. ...
Fusformer: a transformer-based fusion network for hyperspectral image super-resolution
3
2022
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
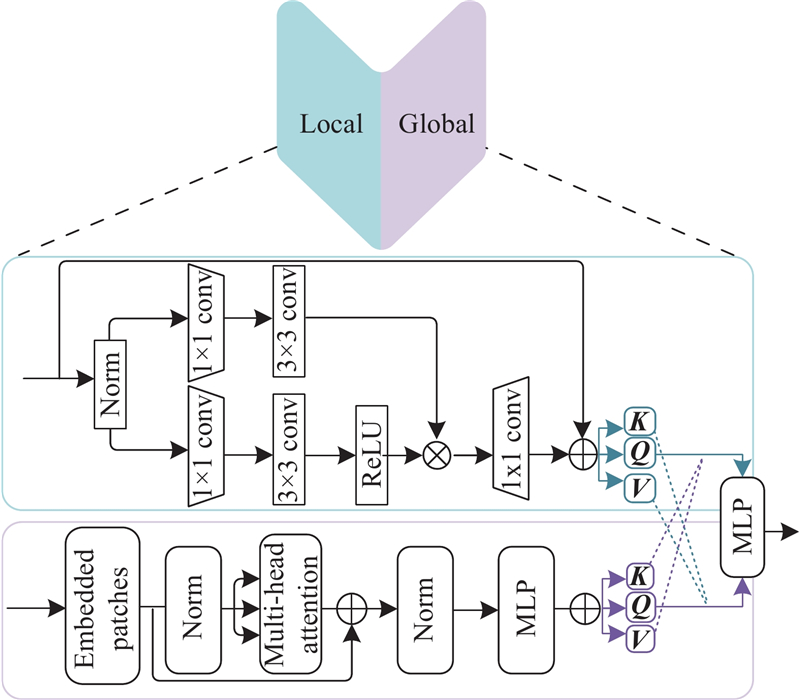
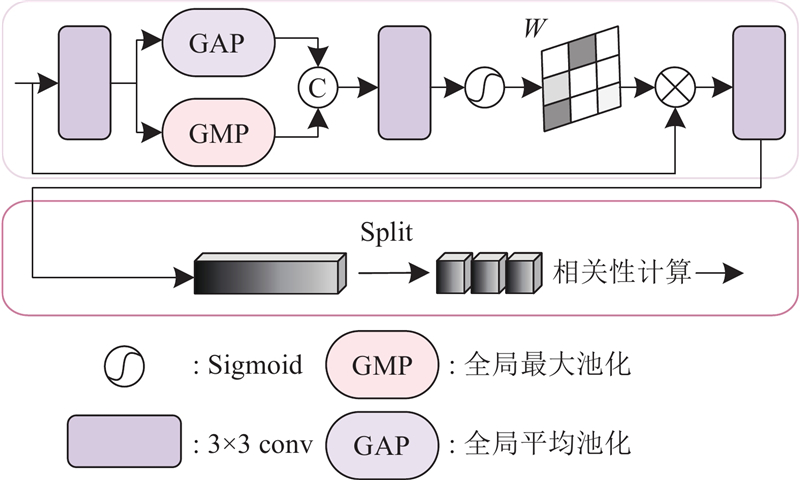
... 空间与光谱联合先验(joint spatial and spectral priorities, SSJP)由设计的空间注意力和光谱注意力机制串联构成,如图3 所示. 前者用于挖掘高光谱数据的空间信息,后者用于提取光谱相关性. 为了避免空间信息丢失,目前一些主流方法将多源图像特征通过跳跃连接的方式一起处理[16 ,23 ] ,本研究方法将HR-MSI的初始特征与多级主干特征一并输入到联合先验模块中,从而能够有效地挖掘和利用空间信息. ...
... 将本研究所提方法与8种方法进行对比,如MHF-net[28 ] 、DBIN[29 ] 、CNN-FUS[12 ] 、UAL[30 ] 、Fusformer[16 ] 、DCT[23 ] 、SDAGE[20 ] 以及EDIP[15 ] ,所有对比方法均在相同的参数设置和实验环境下进行测试. 本研究从定性结果和定量分析2方面衡量算法的优劣,其中定量分析采用4个评估指标,峰值信噪比(peak signal-to-noise ratio,PSNR)、光谱角映射(spectral angle mapper,SAM)、相对全局误差(error relative to the global absolute sum, ERGAS)和结构相似性(structural similarity index, SSIM). PSNR通过比较原始图像和失真图像的均方误差来衡量图像质量,PSNR越大,表示图像质量越好. SAM用来度量2个光谱向量之间的角度差异,值越小表示2个光谱向量越相似. ERGAS是测量融合结果与全分辨率高光谱图像之间的平均误差和动态范围变化的全局指标,值越小,表示结果越好. SSIM通过比较2个图像在结构、亮度和对比度方面的差异来度量图像相似度,值越接近1表示2个图像越相似. ...
Learning a 3D-CNN and Transformer prior for hyperspectral image super-resolution
1
2023
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
Multiscale spatial-spectral transformer network for hyperspectral and multispectral image fusion
1
2023
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
MDC-FusFormer: multiscale deep cross-fusion transformer network for hyperspectral and multispectral image fusion
1
2024
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
Learning spatial-spectral dual adaptive graph embedding for multispectral and hyperspectral image fusion
2
2024
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
... 将本研究所提方法与8种方法进行对比,如MHF-net[28 ] 、DBIN[29 ] 、CNN-FUS[12 ] 、UAL[30 ] 、Fusformer[16 ] 、DCT[23 ] 、SDAGE[20 ] 以及EDIP[15 ] ,所有对比方法均在相同的参数设置和实验环境下进行测试. 本研究从定性结果和定量分析2方面衡量算法的优劣,其中定量分析采用4个评估指标,峰值信噪比(peak signal-to-noise ratio,PSNR)、光谱角映射(spectral angle mapper,SAM)、相对全局误差(error relative to the global absolute sum, ERGAS)和结构相似性(structural similarity index, SSIM). PSNR通过比较原始图像和失真图像的均方误差来衡量图像质量,PSNR越大,表示图像质量越好. SAM用来度量2个光谱向量之间的角度差异,值越小表示2个光谱向量越相似. ERGAS是测量融合结果与全分辨率高光谱图像之间的平均误差和动态范围变化的全局指标,值越小,表示结果越好. SSIM通过比较2个图像在结构、亮度和对比度方面的差异来度量图像相似度,值越接近1表示2个图像越相似. ...
An asymptotic multiscale symmetric fusion network for hyperspectral and multispectral image fusion
1
2025
... 近年来,深度学习的方法凭借其强大的特征提取能力和自适应学习能力,为高光谱与多光谱图像融合提供了新的解决方案. 深度学习方法主要分为基于卷积神经网络(convolutional neural network,CNN)的方法和基于Transformer的方法. 对于基于CNN的方法,Palsson等[10 ] 注意到HSI在光谱维度中的重要性,提出基于三维卷积神经网络(3d convolutional neural network,3D-CNN)的融合方法,为了降低3D-CNN的计算复杂度,在融合前使用主成分分析进行降维. Zhang等[11 ] 设计了含跨模式消息插入、空间重构和光谱重建网络的融合框架,通过空间损失和光谱损失提升HSI和MSI融合效率. 为了充分利用多尺度空间信息,Dian等[12 ] 通过奇异值分解提取低维光谱子空间,用CNN去噪器优化系数,实现高光谱图像的超分辨率重建. Yu等[13 ] 提出无监督深度融合方法,设计分组卷积增强模块和三维注意力因子动态卷积核,消除辐射差异并增强特征提取能力. 为了探究空间域与光谱域的相关性,Yan等[14 ] 将不同模态信息视为互补组件,通过半二次分裂和梯度下降算法优化模型,借助CNN探索深层特征空间,实现跨模态信息交互与融合. 此外,Li等[15 ] 提出增强型深度图像先验网络,采用两阶段方案生成配对训练样本,使用双U形架构捕捉高光谱先验. 对于Transformer的方法,Hu等[16 ] 首次将Transformer应用于图像融合,通过估计空间残差降低训练负担. Ma等[17 ] 用Transformer学习HSI先验,结合近端梯度算法和展开网络求解HR-HSI模型. Jia等[18 ] 提出多尺度空间和频谱Transformer网络,通过双分支分别提取光谱特征与空间特征,并采用自监督预训练策略提升网络性能与泛化能力. 为了克服CNN在捕捉全局信息和复杂特征方面的局限性,Sun等[19 ] 提出多尺度深度交叉融合网络,通过注意力块交互不同尺度特征重建高分辨率图像. 此外,Wang等[20 ] 利用非局部自相似性和光谱带相关性,通过构建空间和光谱图来重建HR-HSI. Liu等[21 ] 设计渐近多尺度对称融合网络,通过多流特征在相同尺度层逐步进行HSI和MSI之间的信息交互,并利用多尺度双向条纹卷积进一步细化边缘特征. ...
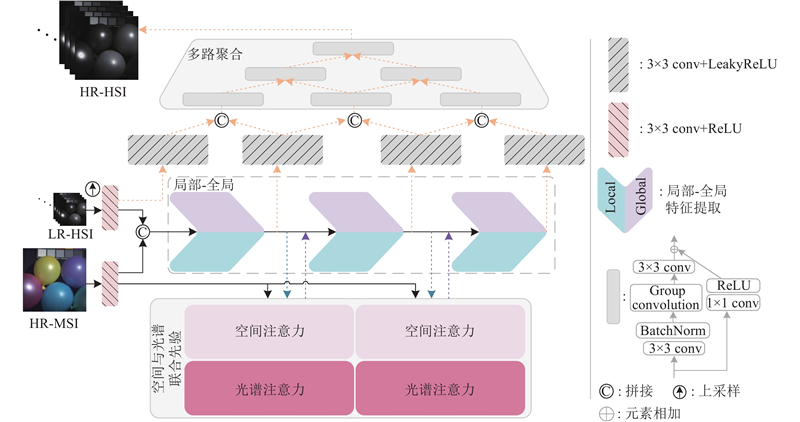
1
... 针对以上问题,本研究提出全局与局部相结合的主干网络,通过设计的局部瓶颈控制单元与Transformer[22 ] 协同的并联结构,增强模型对于局部细节的表征能力,还通过自注意力机制,强化对全局结构和上下文的理解. 为了增强融合图像的信息保真度,通过提出的空间与光谱联合先验,充分捕捉图像中的空间相关性和光谱特性,确保关键的光谱特征得以保留. 再利用多路径聚合网络并行处理各级特征,通过自下而上的路径聚合,有效利用不同层次的特征信息,得到兼具丰富的光谱信息和空间信息的融合图像. ...
Reciprocal transformer for hyperspectral and multispectral image fusion
2
2024
... 空间与光谱联合先验(joint spatial and spectral priorities, SSJP)由设计的空间注意力和光谱注意力机制串联构成,如图3 所示. 前者用于挖掘高光谱数据的空间信息,后者用于提取光谱相关性. 为了避免空间信息丢失,目前一些主流方法将多源图像特征通过跳跃连接的方式一起处理[16 ,23 ] ,本研究方法将HR-MSI的初始特征与多级主干特征一并输入到联合先验模块中,从而能够有效地挖掘和利用空间信息. ...
... 将本研究所提方法与8种方法进行对比,如MHF-net[28 ] 、DBIN[29 ] 、CNN-FUS[12 ] 、UAL[30 ] 、Fusformer[16 ] 、DCT[23 ] 、SDAGE[20 ] 以及EDIP[15 ] ,所有对比方法均在相同的参数设置和实验环境下进行测试. 本研究从定性结果和定量分析2方面衡量算法的优劣,其中定量分析采用4个评估指标,峰值信噪比(peak signal-to-noise ratio,PSNR)、光谱角映射(spectral angle mapper,SAM)、相对全局误差(error relative to the global absolute sum, ERGAS)和结构相似性(structural similarity index, SSIM). PSNR通过比较原始图像和失真图像的均方误差来衡量图像质量,PSNR越大,表示图像质量越好. SAM用来度量2个光谱向量之间的角度差异,值越小表示2个光谱向量越相似. ERGAS是测量融合结果与全分辨率高光谱图像之间的平均误差和动态范围变化的全局指标,值越小,表示结果越好. SSIM通过比较2个图像在结构、亮度和对比度方面的差异来度量图像相似度,值越接近1表示2个图像越相似. ...
Rethinking 3D-CNN in hyperspectral image super-resolution
1
2023
... 在光谱注意力方面,由于高光谱图像的光谱之间存在着较强的相关性,而传统注意力机制在处理高光谱数据时,未能充分挖掘光谱间的独特相关性,因此本研究提出基于光谱分组的注意力机制方法,如图4 所示. 具体而言,先对光谱进行预划分,再采用信息熵来衡量每个波段重要程度,每组内选出信息熵较高的若干波段,每一组波段都包含了局部光谱的相关信息. 针对每一组波段,采用3D卷积操作分别计算$ {\boldsymbol{Q}}_{j} $ $ {\boldsymbol{K}}_{j} $ $ {\boldsymbol{V}}_{j} $ [24 -25 ] . 随后,计算每组波段内的相似度,以衡量不同光谱位置之间的相互关联程度. 最终,将经过注意力机制处理后的每组波段的特征进行拼接,整合成完整的特征表示,这一设计不仅能够突出重要的光谱特征,还能通过捕捉光谱间的依赖关系,增强融合图像的光谱细节表达,以上过程表达式如下. ...
3D-CNNHSR: a 3-dimensional convolutional neural network for hyperspectral super-resolution
1
2023
... 在光谱注意力方面,由于高光谱图像的光谱之间存在着较强的相关性,而传统注意力机制在处理高光谱数据时,未能充分挖掘光谱间的独特相关性,因此本研究提出基于光谱分组的注意力机制方法,如图4 所示. 具体而言,先对光谱进行预划分,再采用信息熵来衡量每个波段重要程度,每组内选出信息熵较高的若干波段,每一组波段都包含了局部光谱的相关信息. 针对每一组波段,采用3D卷积操作分别计算$ {\boldsymbol{Q}}_{j} $ $ {\boldsymbol{K}}_{j} $ $ {\boldsymbol{V}}_{j} $ [24 -25 ] . 随后,计算每组波段内的相似度,以衡量不同光谱位置之间的相互关联程度. 最终,将经过注意力机制处理后的每组波段的特征进行拼接,整合成完整的特征表示,这一设计不仅能够突出重要的光谱特征,还能通过捕捉光谱间的依赖关系,增强融合图像的光谱细节表达,以上过程表达式如下. ...
Generalized assorted pixel camera: postcapture control of resolution, dynamic range, and spectrum
1
2010
... 采用3个遥感数据集进行实验,哥伦比亚大学计算机视觉实验室(CAVE)数据集[26 ] 、Harvard数据集[27 ] 以及真实数据集 (Pavia University数据集[11 ] ). 对于CAVE数据集和Harvard数据集,使用尼康D700相机的光谱响应函数R 生成HR-MSI. 使用多个尺寸(3$ \times $ 3 、5$ \times $ 5 、7$ \times $ 7 、9$ \times $ 9) 的模糊核,对HR-HSI进行处理,再下采样8倍得到LR-HSI. ...
1
... 采用3个遥感数据集进行实验,哥伦比亚大学计算机视觉实验室(CAVE)数据集[26 ] 、Harvard数据集[27 ] 以及真实数据集 (Pavia University数据集[11 ] ). 对于CAVE数据集和Harvard数据集,使用尼康D700相机的光谱响应函数R 生成HR-MSI. 使用多个尺寸(3$ \times $ 3 、5$ \times $ 5 、7$ \times $ 7 、9$ \times $ 9) 的模糊核,对HR-HSI进行处理,再下采样8倍得到LR-HSI. ...
1
... 将本研究所提方法与8种方法进行对比,如MHF-net[28 ] 、DBIN[29 ] 、CNN-FUS[12 ] 、UAL[30 ] 、Fusformer[16 ] 、DCT[23 ] 、SDAGE[20 ] 以及EDIP[15 ] ,所有对比方法均在相同的参数设置和实验环境下进行测试. 本研究从定性结果和定量分析2方面衡量算法的优劣,其中定量分析采用4个评估指标,峰值信噪比(peak signal-to-noise ratio,PSNR)、光谱角映射(spectral angle mapper,SAM)、相对全局误差(error relative to the global absolute sum, ERGAS)和结构相似性(structural similarity index, SSIM). PSNR通过比较原始图像和失真图像的均方误差来衡量图像质量,PSNR越大,表示图像质量越好. SAM用来度量2个光谱向量之间的角度差异,值越小表示2个光谱向量越相似. ERGAS是测量融合结果与全分辨率高光谱图像之间的平均误差和动态范围变化的全局指标,值越小,表示结果越好. SSIM通过比较2个图像在结构、亮度和对比度方面的差异来度量图像相似度,值越接近1表示2个图像越相似. ...
1
... 将本研究所提方法与8种方法进行对比,如MHF-net[28 ] 、DBIN[29 ] 、CNN-FUS[12 ] 、UAL[30 ] 、Fusformer[16 ] 、DCT[23 ] 、SDAGE[20 ] 以及EDIP[15 ] ,所有对比方法均在相同的参数设置和实验环境下进行测试. 本研究从定性结果和定量分析2方面衡量算法的优劣,其中定量分析采用4个评估指标,峰值信噪比(peak signal-to-noise ratio,PSNR)、光谱角映射(spectral angle mapper,SAM)、相对全局误差(error relative to the global absolute sum, ERGAS)和结构相似性(structural similarity index, SSIM). PSNR通过比较原始图像和失真图像的均方误差来衡量图像质量,PSNR越大,表示图像质量越好. SAM用来度量2个光谱向量之间的角度差异,值越小表示2个光谱向量越相似. ERGAS是测量融合结果与全分辨率高光谱图像之间的平均误差和动态范围变化的全局指标,值越小,表示结果越好. SSIM通过比较2个图像在结构、亮度和对比度方面的差异来度量图像相似度,值越接近1表示2个图像越相似. ...
1
... 将本研究所提方法与8种方法进行对比,如MHF-net[28 ] 、DBIN[29 ] 、CNN-FUS[12 ] 、UAL[30 ] 、Fusformer[16 ] 、DCT[23 ] 、SDAGE[20 ] 以及EDIP[15 ] ,所有对比方法均在相同的参数设置和实验环境下进行测试. 本研究从定性结果和定量分析2方面衡量算法的优劣,其中定量分析采用4个评估指标,峰值信噪比(peak signal-to-noise ratio,PSNR)、光谱角映射(spectral angle mapper,SAM)、相对全局误差(error relative to the global absolute sum, ERGAS)和结构相似性(structural similarity index, SSIM). PSNR通过比较原始图像和失真图像的均方误差来衡量图像质量,PSNR越大,表示图像质量越好. SAM用来度量2个光谱向量之间的角度差异,值越小表示2个光谱向量越相似. ERGAS是测量融合结果与全分辨率高光谱图像之间的平均误差和动态范围变化的全局指标,值越小,表示结果越好. SSIM通过比较2个图像在结构、亮度和对比度方面的差异来度量图像相似度,值越接近1表示2个图像越相似. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}