

计算机视觉技术在泥石流预警领域的应用研究已经取得初步进展,但仍然存在诸多问题. Pham等[3]结合YOLOv3模型与帧间差分法实现泥石流的测速,但泥石流数据完全依赖低效的人工手动标注,且识别模型未能针对泥石流的特有流体形态进行优化. 何明杰等[4]在YOLOX模型中引入ASFF注意力机制,有效提升了高原山地灾害场景下的小目标检测能力,但该方法的计算复杂度较高,导致模型推理速度下降,难以满足灾害监测对实时性的严苛要求. 在泥石流数据自动标注方法研究方面,张领先等[5]基于OpenCV边缘检测算法实现静态目标的自动标注,然而该方法无法适应流体目标在运动过程中的动态形变特性. 陈庆林等[6]针对视频数据标注效率低的问题,提出检测-跟踪的半自动标注框架,该方法虽然提升了视频数据的标注效率,但采用的KCF跟踪算法在处理流体目标时存在严重的跟踪漂移问题,影响数据标注的质量.
现有研究表明,泥石流等流体目标的检测面临2大瓶颈:在数据标注上,流体的非结构化流动特性使传统静态标注方法难以捕捉其连续形变,导致标注效率与精度不足;在模型性能上,泥石流等流体的遮挡、运动模糊及背景干扰使现有检测模型难以表征其多尺度动态特征,对不规则边界的定位能力弱,难以满足灾害预警对精度与实时性的要求. 针对以上问题,提出融合流体目标自动标注与轻量化YOLOv8n的泥石流检测框架. 主要贡献有:1)在数据标注方面,提出基于流体运动轨迹预设多尺度采集框的动态视频帧截取策略,结合改进的二分类筛选模型构建流体目标数据自动标注方案,实现对泥石流目标的高效标注. 2)在模型设计上,提出结合特征金字塔池化模块(spatial pyramid pooling-fast, SPPF)的轻量化全局自注意力模块(lightweight global self-attention, LGSA),同时,融合GhostNetV2轻量化设计与ParameterNet动态参数机制,构建专用于泥石流检测的C2f_GhostNetV2模块. 引入Shape-IoU损失函数,通过形状感知的边界框回归策略,进一步提高模型检测精度. 3)构建并开源包含8 064张标注样本的泥石流数据集,地址为:
1. 流体目标自动标注方法
对于刚体静态目标,可以借助LabelImg、LabelMe等标注工具进行人工标注;对于刚体运动目标可以采用人工结合传统目标跟踪算法的方式实现半自动或自动标注. 对于流体目标,其动态演变过程常以视频序列的形式采集,若采用人工标注则需要逐帧选择并核对,标注效率低、工作量大且易出错;若采用传统基于静态标注框结合目标跟踪的方法,则难以准确捕捉流体的连续形变,易导致流体边界模糊和运动轨迹标注失准. 以泥石流为研究对象,分别使用传统静态标注框结合帧间差法[7]、跟踪-学习-检测算法(tracking-learning-detection,TLD)[8]和核相关滤波算法(kernelized correlation filters,KCF)[9]对泥石流目标进行跟踪与标注. 如图1所示,帧间差法对非结构化流体的渐变运动不敏感,容易对其他运动区域进行错误分割;TLD目标检测算法在应用流体目标剧烈形变时容易发生模型漂移,导致无法准确跟踪和标注目标对象;KCF算法依赖于固定特征的更新,难以适应流体目标持续变化的表观特征. 利用流体运动轨迹的连续性[10],提出融合多尺度动态采集与智能筛选的自动标注方法,用于泥石流等流体目标的标注. 该方法通过预设多尺度采集框自适应截取视频帧,并结合改进的二分类筛选模型(引入负样本扩展与精度优先机制),构建自动化标注流程,整个过程涵盖“数据采集-数据筛选-标签标注与转化”3个阶段,如图2所示.
图 1

1.1. 数据采集过程
在流体运动目标检测中,流体头部区域集中显著的运动特征与形变信息,实现对该区域的精确识别与定位成为流体目标检测的关键. 准确标注流体头部区域,不仅能够为构建高性能检测网络提供高质量的训练样本,还可显著增强网络对复杂流体运动的表征能力. 值得注意的是,在特定流动条件下(如泥石流沿山谷或河道运动),流体的宏观运动轨迹往往呈现出较为清晰且可预测的路径特征. 基于这一特性,可沿流体流动路径预先布设数据采集区域,以实现对流场信息的精准捕捉. 如图3所示,以泥石流为例,具体说明流体目标数据的采集过程.
图 2
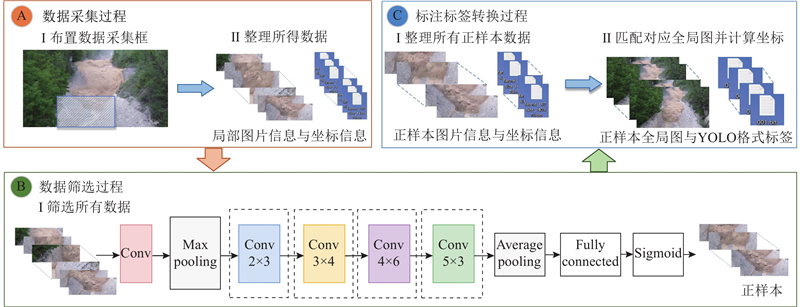
图 3
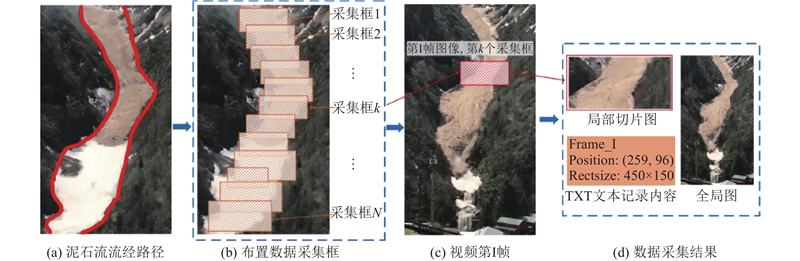
2)每个数据采集框自视频起始帧激活后进入持续采集状态,同步执行2项任务:①截取全局场景图像;②提取采集框内局部区域的切片图像. 同时,通过动态编号管理机制生成TXT数据文件,记录当前帧编号、框体像素坐标(左上角点位置)及尺寸(宽W、高H)等关键信息. 如图3(c)和(d)所示,在第I帧中,第k个采集框会自动截取该帧全局图像并获取对应的局部切片,同时在TXT文件中存储框体位置、尺寸与序列信息,建立与图像的索引关系,为后续图像分类与坐标计算提供支持.
1.2. 数据筛选过程
1.2.1. 二分类筛选模型的构建
图 4

1)初始部分采用7×7卷积层,并执行最大池化操作,实现初步特征提取与降维.
2)第2~5部分为4个残差层(Conv2至Conv5),分别包含3、4、6、3个残差块. 各残差块采用Bottleneck结构(1×1–3×3–1×1卷积顺序),在保持网络深度的同时缓解梯度消失问题.
图 5
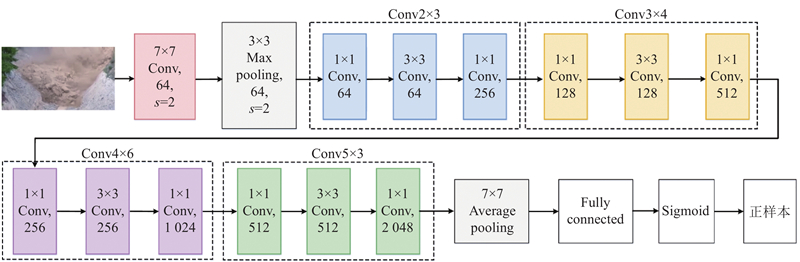
3)第6部分为全局平均池化层,第7部分为全连接层,通过特征图的空间降维和参数压缩,显著减少模型参数量以防止过拟合. 所有卷积层后均加入批归一化(batch normalization, BN)以加速收敛;7×7卷积层及各残差块末端均使用ReLU激活函数增强非线性. 最终输出层采用Sigmoid函数,直接输出正/负样本概率,以适配二分类任务.
1.2.2. 筛选策略
二分类筛选网络的判别性能直接影响最终标注结果的精度和可靠性,为了提升二分类筛选网络的判别能力,在训练过程中采用如下优化策略.
1)扩展负样本的阈值范围. 原二分类模型依据预测框与真实框的交并比(IoU)划分正负样本,将IoU
2)精度优先的样本筛选机制. 针对训练数据量大的特点,在训练中贯彻精度优先原则,通过牺牲部分正样本召回率来保障高准确率. 具体而言,该机制在训练阶段主动过滤低置信度的正样本,使最终筛选结果保持极高的正样本纯度.
1.2.3. 筛选过程
基于1.2.2节中的筛选策略,采用迭代优化的方式实现正样本的筛选,如图6中所示. 设经1.1步骤后采集得到的数据集为A,对数据集A进行少量人工筛选,得到部分正、负样本构成的初始训练集B,利用该训练集训练得到初始二分类筛选模型M. 将初始负样本阈值设置为IoU
图 6
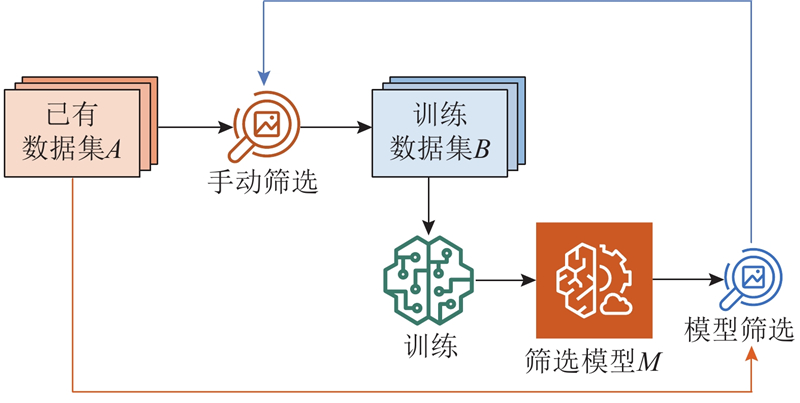
将以上过程重复执行5个迭代周期S,每轮采用不同的数据集参数和负样本IoU阈值H,具体如表1中所示. 正样本数量为T,负样本数量为F. 经过多轮迭代优化,最终得到负样本范围扩展至IoU
表 1 二分类筛选模型参数设置
Tab.1
| S | T | F | H |
| 1 | 100 | 100 | [0,0.5) |
| 2 | 200 | 300 | [0,0.6) |
| 3 | 300 | 400 | [0,0.7) |
| 4 | 400 | 500 | [0,0.8) |
| 5 | 500 | 600 | [0,0.9) |
通过以上迭代流程,最终构建高纯度的泥石流头部正样本数据集,该数据集剔除了绝大多数干扰样本,为后续模型训练提供可靠的数据支撑.
1.3. 标签转化过程
经过1.2节的正样本筛选后,结合1.1节获取的样本坐标及尺寸关键信息,构建最终的标注数据集. 设图像的宽度为
式(1)最终生成标准化的流体目标标注格式
2. 轻量化实时泥石流检测模型
泥石流检测网络的关键在于兼顾实时性与检测精度,并针对泥石流的特殊形态和复杂环境进行优化. 基于YOLOv8n模型提出用于泥石流检测的轻量化改进方案,其网络架构如图7所示. 具体改进包括以下3个方面.
图 7
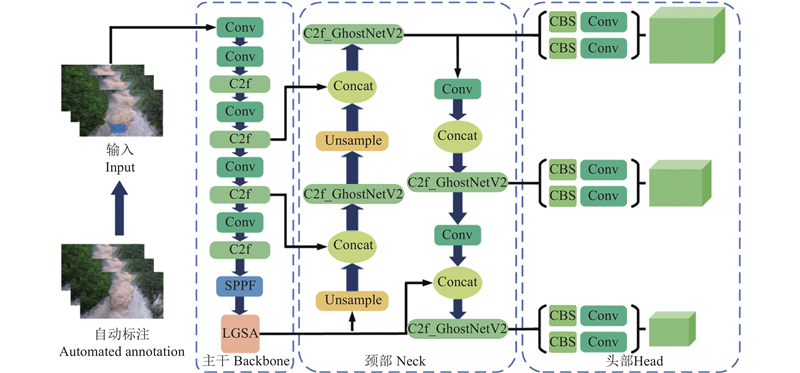
1)针对复杂场景下的特征提取问题,提出轻量化全局自注意力模块(LGSA),并与特征金字塔池化模块SPPF相结合,通过建立跨区域特征关联,增强了目标的全局上下文表征能力,有效提升了模型对遮挡、模糊等干扰的鲁棒性.
3)针对泥石流目标的非规则形态特征,采用Shape-IoU损失函数[15]替代传统回归损失函数,通过融合目标形状相似度和尺寸比例约束,显著提升了边界框的定位精度.
2.1. 轻量化全局自注意力机制
在自然场景下的泥石流监测中,监测设备通常布设于沟道附近,集成超声泥位计、光伏面板及通信模块等组件. 此类部署方式易导致采集图像存在遮挡、质量下降与细节模糊等问题. 尽管现有目标检测模型(如YOLO)中的SPPF模块通过多尺度最大池化并行提取局部上下文信息,能够有效捕捉泥石流边缘与纹理等细节特征,但其局部操作难以建模远距离像素间的空间依赖关系,在运动模糊或遮挡场景下容易造成误检或漏检. 为此,提出基于Transformer架构[16]的轻量化全局自注意力模块(lightweight global self-attention, LGSA),其结构如图8所示. 该模块通过全图像素级注意力权重计算,建立跨区域的长程依赖关系,理解如遮挡区域与可见区域之间、泥石流主体与背景之间的全局上下文关系,有效增强了模型的全局表征能力.
图 8
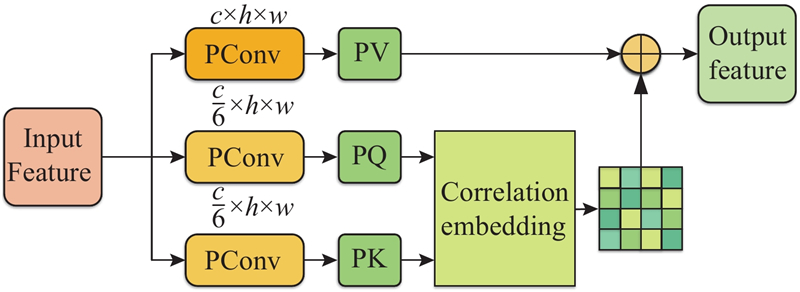
LGSA模块的核心设计包含以下关键步骤:输入特征通过大小分别为
式中:
用所得到的注意力权重
式(4)利用学习到的长程依赖关系聚合原始特征,突出与泥石流检测密切相关的信息(如流动前沿和主体区域特征),同时抑制无关背景与噪声,有效提升了检测头在复杂场景下的识别与定位精度.
2.2. C2f_GhostNetV2模块
如图9(a)所示,在YOLOv8模型的特征融合网络中,C2f模块采用多个Bottleneck单元密集串联的方式以增强特征提取的能力,但该设计显著增加了模块的参数量和计算复杂度,且过深的串联结构易导致通道间信息冗余,限制模型的检测性能. 针对上述问题,引入GhostNetV2轻量化模块与ParameterNet动态参数扩展策略,构建具有双路协同机制的增强型轻量化单元GhostNetBottleneckV2模块,以替代原C2f中的传统Bottleneck结构,形成改进后的C2f_GhostNetV模块. 如图9(b)所示,该复合模块通过特征解耦与参数动态扩展的协同机制,实现模型性能与计算效率的同步优化.
图 9
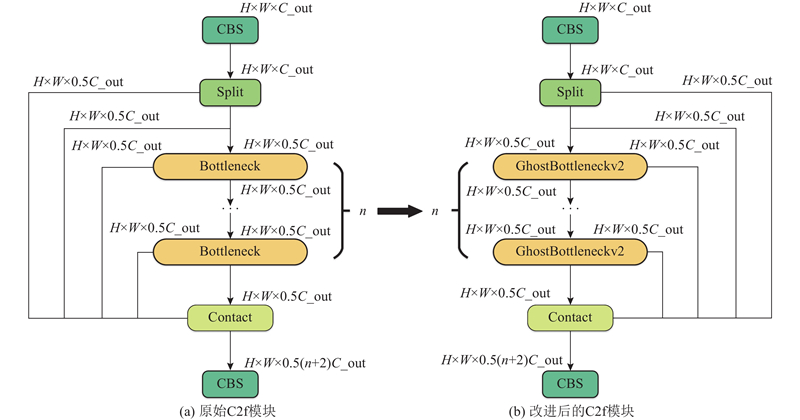
图 9 改进前和改进后的C2f网络结构图
Fig.9 Structure diagrams of C2f network before and after improvement
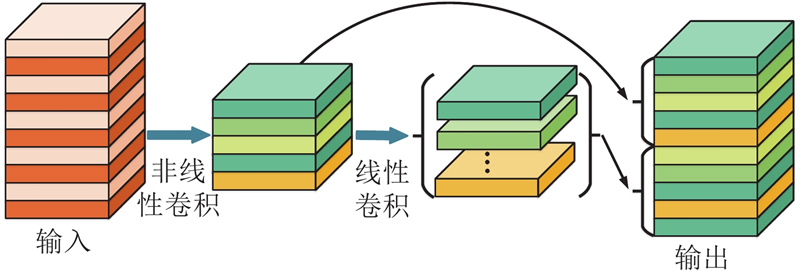
1)GhostNetV2轻量化模块的引入:如图10所示,该模块使用非线性卷积压缩特征层,通过线性卷积生成补充特征,融合原始与生成特征输出,在保证性能的同时降低约50%的内存占用.
图 10
2)ParameterNet动态参数扩展策略的引入:在传统卷积神经网络中,卷积核权重是静态固定的,可表示为
式中:
该机制的核心思想是构建包含M个专家卷积核的可学习核库,通过输入数据自适应地生成动态权重系数
具体而言,输入特征X首先通过全局平均池化压缩为向量,再经轻量级MLP与softmax生成动态权重.
2.3. Shape-IoU损失函数
在目标检测任务中,损失函数用于度量预测结果与真实标签之间的差异. 然而,在泥石流检测中,由于目标形态具有高度不规则性,传统的IoU度量在几何适应性方面表现出明显不足. 如图11(a)和(b)所示,2个尺寸相同但空间分布不同的预测框(分别位于GT锚框的长边和短边方向),即使IoU值相同,其未重叠面积也存在显著差异,导致检测质量明显不同. 实验表明,图11(b)的检测结果在形状匹配度上优于图11(a),这说明锚框的形状特征对检测性能具有重要影响. 为了解决复杂背景下泥石流目标形状不规则所导致的预测误差问题,引入Shape-IoU损失函数[15],通过综合考虑边界框的形状以及尺度因素,以此来提升边界框的定位精度.
图 11

假设预测框(Anchor)和真实框(GT)的关系如图12中所示.
图 12
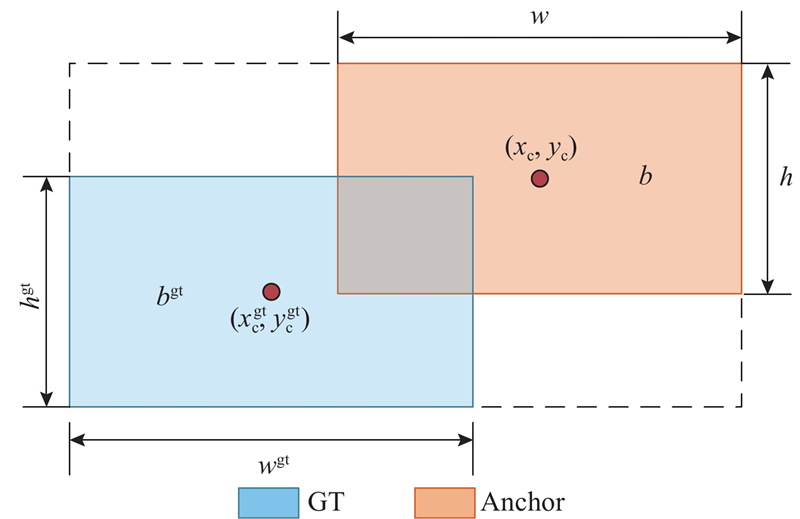
1)计算水平和垂直方向的权重系数ww和hh:
式中:
2)计算形状感知的中心点距离惩罚项系数
式中:
3)计算形状加权的长宽差异惩罚系数
式中:
(4)融合距离惩罚系数
由式(12)可知,Shape-IoU损失函数在标准IoU基础上引入距离与形状惩罚系数,增强了对目标形状的几何约束. 该约束能够有效引导模型学习泥石流特有的形态特征(如长条状、不规则边界等),从而提升检测与定位的准确性.
3. 实验和分析
3.1. 实验参数与模型评估指标
在Windows10操作系统下,基于PyTorch 2.1.1和CUDA 12.1开展模型开发与训练. 集成开发环境为PyCharm 2023,Python版本为3.8.19. 硬件配置包括Intel i7-13700KF处理器(基础频率3.4 GHz)和NVIDIA GeForce RTX 4080S显卡(16 GB显存). 实验参数设置如下:批次大小(batch size)为80,数据加载线程数(workers)为8,训练轮次(epochs)为1 000,初始学习率(initial learning rate)设为0.01,其余超参数均保持框架默认配置.
实验中采用准确率P、召回率R、平均精度均值mAP@0.5、模型计算量(用FLOPs衡量)和参数量(Params)作为模型的评价指标. 其中准确率P和召回率R为
式中:TP为原样本中正样本被预测为正样本的数量,FP为原样本中负样本被错误预测为正样本的数量,FN为原样本中正样本被错误预测为负样本的数量. 平均精度均值mAP为
式中:N为类别数,AP为精确率-召回率(P-R)曲线与坐标轴围成的面积,
3.2. 自动标注方法验证
3.2.1. 二分类筛选模型性能验证
表 2 基准参数设置
Tab.2
| 参数 | 含义 | 数值 |
| FG_THRESH | 正样本IoU阈值 | [0.9,1.0] |
| BG_THRESH_LO | 负样本IoU阈值 | 依表1设定 |
| NMS_THRESH | 非极大值抑制阈值 | 0.9 |
| BATCHSIZE | 图片目标批次大小 | 256 |
| NUM_SAMPLES | 总样本数量 | 153 667 |
实验结果如图13所示,随着负样本判别阈值范围从[0,0.5)扩展至[0,0.9),模型的mAP@0.5从不足0.45著显提升至0.80,这是由于放宽阈值后,模型能够学习更多的困难样本特征(如低IoU的模糊样本),增强了模型对复杂背景的判别能力. 实验表明,二分类模型优化策略通过优化负样本阈值、动态调整样本比例及选择性保留正样本,显著提升了样本标注质量,解决传统标注方案中负难样本表征不足的问题,为后续泥石流检测模型的训练提供可靠的数据.
图 13
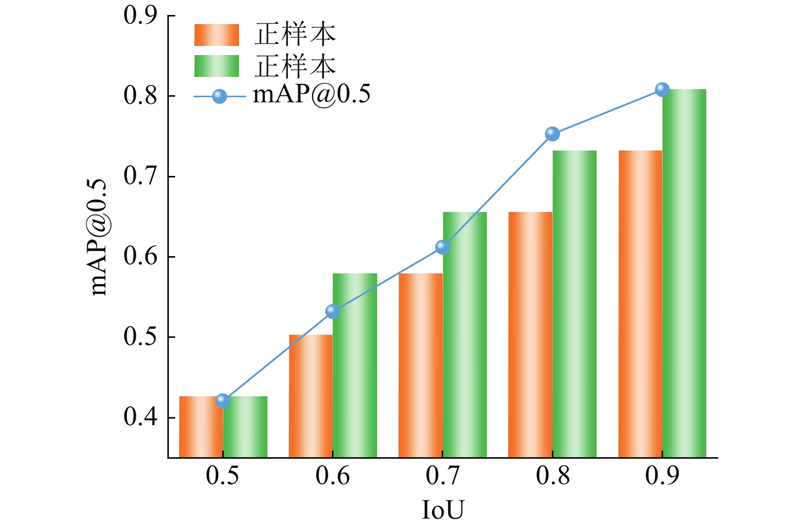
图 13 相同数据集下的不同筛选条件结果图
Fig.13 Results under different filtering conditions on same dataset
3.2.2. 标注结果的可视化验证
新提出的自动标注方法严格遵循Labelme格式生成标注数据,确保与主流标注工具兼容. 为了验证标注质量,采用Labelme对所有自动生成的样本进行初步目视检查,确认其基本满足泥石流目标的标注要求;随机抽取500张标注样本进行详细人工核验,重点关注不同场景下目标识别的准确性及边界贴合度. 抽样结果显示,自动标注框与泥石流头部主体区域的平均IoU超过85%,整体合格率大于96%. 部分标注结果如图14所示,可见该方法能够准确框定不同场景下的泥石流主体区域,且边界贴合度较高. 综上所述,自动标注方法不仅为泥石流检测研究提供高质量标准数据集,其技术方案还可推广至滑坡、洪水等其它流体类目标的智能标注任务.
图 14

图 14 采用自主标注方法的部分标注结果
Fig.14 Results of partial annotation based on self- annotation method
3.3. 泥石流检测模型性能测试
3.3.1. 注意力机制对比实验
为了验证新提出的LGSA(轻量化全局自注意力)模块在泥石流检测任务中的有效性,选取CBAM、SE、CA、SimAM和EMA 5种主流注意力机制进行对比实验,分析不同模块在复杂场景下的特征提取能力. 为了确保实验对比的公平性,所有注意力模块(包括LGSA)均被部署在模型架构的相同位置(位于Backbone部分的SPPF模块之后). 实验采用统一的自建泥石流数据集,并保持完全一致的训练参数设置,实验结果如表3所示. 从中可以看出,LGSA模块在保持计算量相近的情况下,mAP@0.5达到83.3%,相比于基础模型YOLOv8n(82.0%)提升了1.3%,并优于次优的CBAM(82.7%)0.6%. 这是由于LGSA通过轻量化全局自注意力机制建立跨区域长程依赖关系,能够更精准地聚焦泥石流主体区域并抑制复杂背景干扰,从而提高检测精度. LGSA在计算效率与检测精度之间取得平衡,为泥石流检测任务提供更优的注意力解决方案.
表 3 不同注意力机制对比实验结果
Tab.3
| 注意力机制 | FLOPs/G | Params/M | mAP@0.5/% |
| YOLOv8n | 8.2 | 3.0 | 82.0 |
| +CBAM | 8.3 | 3.0 | 82.7 |
| +SE | 8.2 | 3.0 | 81.8 |
| +SimAM | 8.2 | 3.0 | 81.3 |
| +EMA | 8.3 | 3.0 | 82.5 |
| +LGSA | 8.3 | 3.0 | 83.3 |
3.3.2. 消融实验
为了验证LGSA注意力模块、C2f_GhostNetV2模块及Shape-IoU损失函数对泥石流检测性能的影响,以YOLOv8n为基线模型设计渐进式消融实验,逐步引入各改进模块并系统分析其性能变化,结果如表4所示. 其中,FPS表示检测速度. 从中可以看出,单独引入LSGA模块后,模型通过融合更多细节特征使mAP@0.5值提升了1.3%,达到83.3%. 进一步融合C2f_GhostNetV2模块后,mAP@0.5值虽略降至82.5%,但模型参数量(Params)从3.0 M显著减少到2.6 M,计算量(FLOPs)由8.2 G降至7.3 G,检测速度也从223.63帧/s增至231.41帧/s. 这一压缩显著降低了模型的内存与存储开销,为在资源受限的移动设备上部署提供关键优势. 引入Shape-IoU损失函数,通过更贴合泥石流目标形状的损失计算方式,有效补偿模型简化带来的精度损失. 该损失函数与LGSA结合时,mAP@0.5进一步提升至85.8%. 当LGSA、C2f_GhostNetV2与Shape-IoU三者共同融合时,mAP@0.5大幅提升至86.7%,较基线模型提升了4.7%. 此时模型仍保持2.6 M参数量、7.3 G计算量,以及230.89帧/s的高检测速度. 以上性能的提升主要得益于:LGSA模块有效融合细节特征,C2f_GhostNetV2结构在压缩模型的同时保持推理速度,以及Shape-IoU损失函数提升了定位精度. 三者协同作用,在精度、效率与部署友好性之间取得平衡. 为了进一步验证模型改进效果,采用Grad-CAM可视化方法生成模型改进前后的特征热力图,如图15所示. 改进前模型存在关注区域分散和定位偏差问题,而改进后模型能够更精准地聚焦于泥石流目标的关键特征区域. 这一优化表明,改进模型在特征提取与目标定位方面具有更强的判别能力.
表 4 消融对比实验结果
Tab.4
| LGSA | C2f_GhostNetV2 | Shape-IoU | mAP@0.5/% | FLOPs/G | Params/M | FPS/(帧·s−1) |
| — | — | — | 82.0 | 8.2 | 3.0 | 223.63 |
| √ | — | — | 83.3 | 8.3 | 3.0 | 217.92 |
| √ | √ | — | 82.5 | 7.3 | 2.6 | 231.41 |
| √ | — | √ | 85.8 | 8.3 | 3.0 | 216.97 |
| — | √ | √ | 84.3 | 7.2 | 2.6 | 235.68 |
| √ | √ | √ | 86.7 | 7.3 | 2.6 | 230.89 |
图 15

图 15 模型改进前后的泥石流检测热力图
Fig.15 Heatmaps of debris flow detection before and after model improvement
3.3.3. 不同模型对比实验
将新提出的泥石流检测模型命名为YOLOv8-Mudslide,为了验证该模型在泥石流检测任务中的性能,选取Faster R-CNN、SSD、YOLOv5n、YOLOv8系列、YOLOv10n、RefineDet[17]和RT-DETR-R18[18]共8种主流模型进行实验对比. 实验着重从模型检测精度、计算效率及实时性3个维度进行综合评估,所有对比实验均在统一的自建泥石流数据集上完成,并保持相同的训练参数设置,具体结果如表5所示. 通过对各模型性能指标的综合分析可以看出,Faster R-CNN、SSD、YOLOv8m和RT-DETR-R18等模型虽然展现出较高的检测精度(mAP@0.5在83.8%~86.5%),但其参数量(19.8 M~108.2 M)和计算复杂度(56.9 G~163.8 G FLOPs)显著偏高,导致检测速度(28.28~113.64帧/s)难以满足实时检测场景的需求. 轻量级模型YOLOv5n、YOLOv10n和RefineDet虽然在模型效率方面表现较好(2.3~26 M Params,6.7~10.2 G FLOPs),但其检测精度(mAP@0.5在78.2%~82.5%)与工程需求仍存在明显差距(较新模型低4.2%~8.5%). 相比之下,YOLOv8-Mudslide模型展现出显著的竞争优势:在保持优异检测精度(86.7% mAP@0.5)的同时,仅需2.6 M参数和7.3 G FLOPs的计算开销,即可实现230.89帧/s的实时检测性能,其综合表现显著优于对比模型,能够满足对检测精度和实时性的双重需求.
表 5 相同数据集下的不同模型对比实验结果
Tab.5
| 模型 | P/% | R/% | mAP@0.5/% | Params/M | FLOPs/G | FPS/(帧·s−1) |
| Faster R-CNN | 73.5 | 82.8 | 84.05 | 108.2 | 163.8 | 28.28 |
| SSD | 83.2 | 81.2 | 86.5 | 91.6 | 135.2 | 45.65 |
| YOLOv5n | 74.1 | 83.3 | 80.2 | 2.5 | 7.1 | 233.51 |
| YOLOv8n | 71.2 | 80.7 | 82.0 | 3.1 | 8.2 | 223.63 |
| YOLOv8m | 71.3 | 80.6 | 84.2 | 25.8 | 79.1 | 92.64 |
| YOLOv10n | 73.3 | 82.3 | 82.5 | 2.3 | 6.7 | 214.32 |
| RefineDet[17] | 70.2 | 76.8 | 78.2 | 26 | 10.2 | 56.27 |
| RT-DETR-R18[18] | 78.3 | 81.4 | 83.8 | 19.8 | 56.9 | 113.64 |
| YOLOv8-Mudslide | 72.3 | 82.8 | 86.7 | 2.6 | 7.3 | 230.89 |
4. 结 语
泥石流灾害的实时精准检测是提升地质灾害预警效能的关键技术难题. 新提出的流体目标自动标注方法有效解决非刚性目标标注的技术难题,同时所开发的轻量化检测模型在保持mAP@0.5达到86.7%的精度前提下,实现230.89帧/s的实时检测性能. 这些研究成果不仅为地质灾害智能预警提供可靠的技术支持,其方法论框架还可推广应用于其他流体灾害监测领域,具有一定的科学价值与工程应用前景. 虽取得一定成果,但存在2个方面局限:一是未涵盖山坡型泥石流(斗状流域、无显著流通区),导致自动识别方法面临挑战;二是数据集场景有限,制约模型泛化性能. 未来将从3个方面改进:融合计算机视觉与传统地质勘探、传感器监测,构建更全面鲁棒的预警体系;扩充多样化、典型性场景数据集以增强泛化能力;探索红外成像与先进算法结合,提升夜间及低能见度条件下的监测效能.
参考文献
The consequences of debris flows in Brazil: a historical analysis based on recorded events in the last 100 years
[J].DOI:10.1007/s10346-022-01984-7 [本文引用: 1]
Exploring the initiating mechanism, monitoring equipment and warning indicators of gully-type debris flow for disaster reduction: a review
[J].DOI:10.1007/s11069-024-06742-7 [本文引用: 1]
Debris flow detection and velocity estimation using deep convolutional neural network and image processing
[J].DOI:10.1007/s10346-022-01931-6 [本文引用: 1]
融合YOLOX和ASFF的高原山地灾害检测模型
[J].DOI:10.13409/j.cnki.jdpme.20230105002 [本文引用: 1]
A plateau mountain disaster detection model by integrating YOLOX and ASFF
[J].DOI:10.13409/j.cnki.jdpme.20230105002 [本文引用: 1]
基于图像自动标注与改进YOLO v5的番茄病害识别系统
[J].
Tomato disease recognition system based on image automatic labeling and improved YOLOv5
[J].
融合检测与跟踪的半自动视频目标标注
[J].
Semi-automatic video target annotation by combining detection and tracking
[J].
A systematic algorithm for moving object detection with application in real-time surveillance
[J].DOI:10.1007/s42979-020-0118-5 [本文引用: 1]
Tracking-learning-detection
[J].
Critical overview of visual tracking with kernel correlation filter
[J].DOI:10.3390/technologies9040093 [本文引用: 1]
Research on faster RCNN object detection based on hard example mining
[J].
GhostNetv2: Enhance cheap operation with long-range attention
[J].
Transattunet: multi-level attention-guided u-net with transformer for medical image segmentation
[J].

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}