[1]
梁礼明, 詹涛, 雷坤, 等 多分辨率融合输入的U型视网膜血管分割算法
[J]. 电子与信息学报 , 2023 , 45 (5 ): 1795 - 1806
DOI:10.11999/JEIT220470
[本文引用: 1]
LIANG Liming, ZHAN Tao, LEI Kun, et al Multi-resolution fusion input U-shaped retinal vessel segmentation algorithm
[J]. Journal of Electronics & Information Technology , 2023 , 45 (5 ): 1795 - 1806
DOI:10.11999/JEIT220470
[本文引用: 1]
[2]
MAPAYI T, VIRIRI S, TAPAMO J R. Adaptive thresholding technique for retinal vessel segmentation based on GLCM-energy information [J]. Computational and Mathematical Methods in Medicine , 2015: 597475.
[本文引用: 1]
[3]
ODSTRCILIK J, KOLAR R, BUDAI A, et al Retinal vessel segmentation by improved matched filtering: evaluation on a new high-resolution fundus image database
[J]. IET Image Processing , 2013 , 7 (4 ): 373 - 383
DOI:10.1049/iet-ipr.2012.0455
[本文引用: 1]
[5]
ZHAO J, YANG J, AI D, et al Automatic retinal vessel segmentation using multi-scale superpixel chain tracking
[J]. Digital Signal Processing , 2018 , 81 : 26 - 42
DOI:10.1016/j.dsp.2018.06.006
[本文引用: 1]
[6]
RELAN D, MACGILLIVRAY T, BALLERINI L, et al. Automatic retinal vessel classification using a least square-support vector machine in VAMPIRE [C]// Proceedings of the 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society . Chicago: IEEE, 2014: 142–145.
[本文引用: 1]
[7]
梁礼明, 刘博文, 杨海龙, 等 基于多特征融合的有监督视网膜血管提取
[J]. 计算机学报 , 2018 , 41 (11 ): 2566 - 2580
DOI:10.11897/SP.J.1016.2018.02566
[本文引用: 1]
LIANG Liming, LIU Bowen, YANG Hailong, et al Supervised blood vessel extraction in retinal images based on multiple feature fusion
[J]. Chinese Journal of Computers , 2018 , 41 (11 ): 2566 - 2580
DOI:10.11897/SP.J.1016.2018.02566
[本文引用: 1]
[8]
王万良, 王铁军, 陈嘉诚, 等 融合多尺度和多头注意力的医疗图像分割方法
[J]. 浙江大学学报: 工学版 , 2022 , 56 (9 ): 1796 - 1805
[本文引用: 1]
WANG Wanliang, WANG Tiejun, CHEN Jiacheng, et al Medical image segmentation method combining multi-scale and multi-head attention
[J]. Journal of Zhejiang University: Engineering Science , 2022 , 56 (9 ): 1796 - 1805
[本文引用: 1]
[9]
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [M]// Lecture notes in computer science . Cham: Springer, 2015: 234–241.
[本文引用: 2]
[11]
ZHANG H, FANG W, LI J A microvascular segmentation network based on pyramidal attention mechanism
[J]. Sensors , 2024 , 24 (12 ): 4014
DOI:10.3390/s24124014
[本文引用: 1]
[12]
LI J, LI A, LIU Y, et al An adaptive fundus retinal vessel segmentation model capable of adapting to the complex structure of blood vessels
[J]. Biomedical Signal Processing and Control , 2025 , 101 : 107150
DOI:10.1016/j.bspc.2024.107150
[本文引用: 1]
[13]
PAN P, ZHANG C, SUN J, et al Multi-scale conv-attention U-Net for medical image segmentation
[J]. Scientific Reports , 2025 , 15 : 12041
DOI:10.1038/s41598-025-96101-8
[本文引用: 1]
[14]
HUANG L, MIRON A, HONE K, et al. Segmenting medical images: from UNet to res-UNet and nnUNet [C]// Proceedings of the IEEE 37th International Symposium on Computer-Based Medical Systems . Guadalajara: IEEE, 2024: 483–489.
[本文引用: 1]
[15]
VASWANI A, SHAZEER N, PARAMAR N, et al. Attention is all you need [EB/OL]. (2023-08-02) [2025-02-26]. https://arxiv.org/abs/1706.03762.
[本文引用: 1]
[16]
CHEN J, LU Y, YU Q, et al. TransUNet: Transformers make strong encoders for medical image segmentation [EB/OL]. (2021-02-08) [2025-03-12]. https://arxiv.org/abs/2102.04306.
[本文引用: 1]
[17]
SHI Z, LI Y, ZOU H, et al TCU-Net: Transformer embedded in convolutional U-shaped network for retinal vessel segmentation
[J]. Sensors , 2023 , 23 (10 ): 4897
DOI:10.3390/s23104897
[本文引用: 1]
[18]
TANG W, DENG H, HUANG Z, et al Medical image segmentation method based on full perceived dynamic network
[J]. Engineering Applications of Artificial Intelligence , 2025 , 142 : 109867
DOI:10.1016/j.engappai.2024.109867
[本文引用: 1]
[19]
LI Y, XU L, JIN Y, et al Diffusion probabilistic learning with gate-fusion Transformer and edge-frequency attention for retinal vessel segmentation
[J]. IEEE Transactions on Instrumentation and Measurement , 2024 , 73 : 2523513
[本文引用: 1]
[20]
ZHANG F, PANAHI A, GAO G FsaNet: frequency self-attention for semantic segmentation
[J]. IEEE Transactions on Image Processing , 2023 , 32 : 4757 - 4772
DOI:10.1109/TIP.2023.3305090
[本文引用: 2]
[21]
KARIMIJAFARBIGLOO S, AZAD R, KAZEROUNI A, et al. MS-Former: multi-scale self-guided Transformer for medical image segmentation [C]// Medical Imaging with Deep Learning . Paris: PMLR, 2024: 680–694.
[本文引用: 2]
[22]
CHEN Z, HE Z, LU Z DEA-net: single image dehazing based on detail-enhanced convolution and content-guided attention
[J]. IEEE Transactions on Image Processing , 2024 , 33 : 1002 - 1015
DOI:10.1109/TIP.2024.3354108
[本文引用: 2]
[23]
ZHANG X, ZHOU X, LIN M, et al. ShuffleNet: an extremely efficient convolutional neural network for mobile devices [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6848–6856.
[本文引用: 1]
[24]
OKTAY O, SCHLEMPER J, FOLGOC L, et al. Attention U-Net: learning where to look for the pancreas [EB/OL]. (2018-05-20) [2025-03-14]. https://arxiv.org/abs/1804.03999.
[本文引用: 1]
[25]
LIU W, YANG H, TIAN T, et al Full-resolution network and dual-threshold iteration for retinal vessel and coronary angiograph segmentation
[J]. IEEE Journal of Biomedical and Health Informatics , 2022 , 26 (9 ): 4623 - 4634
DOI:10.1109/JBHI.2022.3188710
[本文引用: 1]
[26]
LI Y, ZHANG Y, LIU J Y, et al Global Transformer and dual local attention network via deep-shallow hierarchical feature fusion for retinal vessel segmentation
[J]. IEEE Transactions on Cybernetics , 2023 , 53 (9 ): 5826 - 5839
DOI:10.1109/TCYB.2022.3194099
[本文引用: 1]
[27]
LIANG L, LU B, WU J, et al SFIT-Net: spatial reconstruction feature interaction transformer retinal vessel segmentation algorithm
[J]. Biomedical Signal Processing and Control , 2025 , 106 : 107688
DOI:10.1016/j.bspc.2025.107688
[本文引用: 3]
[29]
AZAD R, ARIMOND R, AGHDAM E K, et al. DAE-Former: dual attention-guided efficient transformer for medical image segmentation [M]// Predictive intelligence in medicine . Cham: Springer, 2023: 83–95.
[本文引用: 3]
[30]
ZHANG H, ZHANG J, ZHONG X, et al MSM-TDE: multi-scale semantics mining and tiny details enhancement network for retinal vessel segmentation
[J]. Complex & Intelligent Systems , 2025 , 11 (1 ): 114
[本文引用: 3]
[31]
QIN L, LI Y, LIN C BINet: bio-inspired network for retinal vessel segmentation
[J]. Biomedical Signal Processing and Control , 2025 , 100 : 107003
DOI:10.1016/j.bspc.2024.107003
[本文引用: 3]
[33]
JIAN M, XU W, NIE C, et al DAU-Net: a novel U-Net with dual attention for retinal vessel segmentation
[J]. Biomedical Physics & Engineering Express , 2025 , 11 (2 ): 025009
[本文引用: 3]
多分辨率融合输入的U型视网膜血管分割算法
1
2023
... 视网膜血管是人体内唯一能够在非创伤性条件下被直接观察到的深层血管,其血管直径、曲率和分支模式等独特的几何特征,为糖尿病视网膜病变、高血压性视网膜病变等疾病的诊断和监测提供了直观而有效的依据. 眼科医生可以通过对眼底图像中的微血管进行分割,实现眼底疾病的精确治疗. 但是视网膜血管的形态结构复杂多变,血管与背景之间的像素对比度较低,且存在噪声干扰问题,导致其难以被准确分割[1 ] . 因此,亟待开发精准、高效的视网膜血管分割算法. ...
多分辨率融合输入的U型视网膜血管分割算法
1
2023
... 视网膜血管是人体内唯一能够在非创伤性条件下被直接观察到的深层血管,其血管直径、曲率和分支模式等独特的几何特征,为糖尿病视网膜病变、高血压性视网膜病变等疾病的诊断和监测提供了直观而有效的依据. 眼科医生可以通过对眼底图像中的微血管进行分割,实现眼底疾病的精确治疗. 但是视网膜血管的形态结构复杂多变,血管与背景之间的像素对比度较低,且存在噪声干扰问题,导致其难以被准确分割[1 ] . 因此,亟待开发精准、高效的视网膜血管分割算法. ...
1
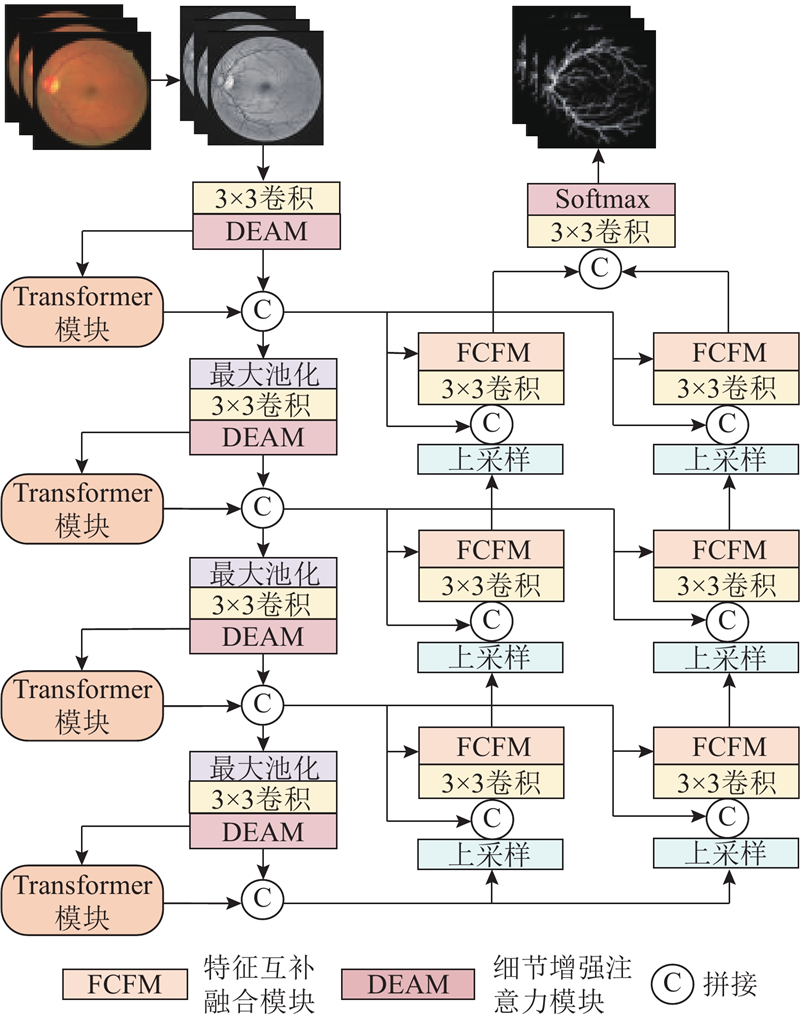
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
Retinal vessel segmentation by improved matched filtering: evaluation on a new high-resolution fundus image database
1
2013
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
Multi-scale retinal vessel segmentation using line tracking
1
2010
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
Automatic retinal vessel segmentation using multi-scale superpixel chain tracking
1
2018
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
1
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
基于多特征融合的有监督视网膜血管提取
1
2018
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
基于多特征融合的有监督视网膜血管提取
1
2018
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
融合多尺度和多头注意力的医疗图像分割方法
1
2022
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
融合多尺度和多头注意力的医疗图像分割方法
1
2022
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
2
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
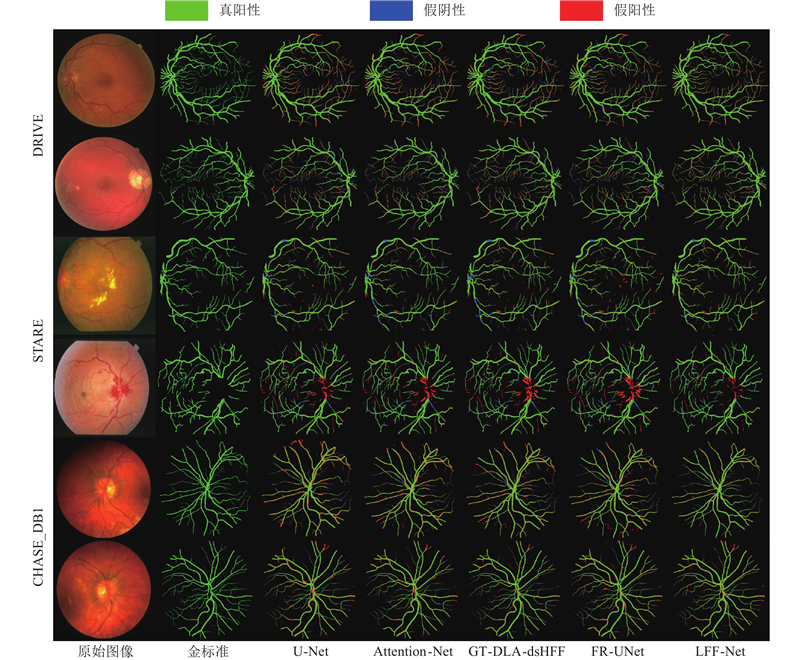
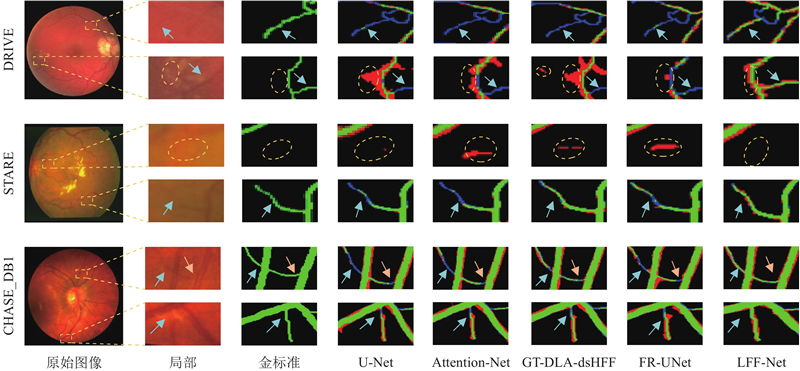
... 为了验证所提算法在视网膜血管分割任务中的有效性,在相同的实验环境下对LFF-Net与U-Net[9 ] 、Attention U-Net[24 ] 、FR-UNet[25 ] 和GT-DLA-dsHFF[26 ] 这4种模型进行对比实验. 其中,U-Net为所提算法的基准模型,Attention U-Net为在U-Net基础上引入注意力机制的变体模型,FR-UNet为视网膜血管分割任务中的经典模型,GT-DLA-dsHFF为在U-Net基础上引入Transformer的变体模型. 不同算法的可视化分割结果如图7 所示. 其中真阳性表示真实的血管区域,假阴性为未被检测出的血管区域,假阳性为背景区域. ...
MAGF-Net: a multiscale attention-guided fusion network for retinal vessel segmentation
1
2023
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
A microvascular segmentation network based on pyramidal attention mechanism
1
2024
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
An adaptive fundus retinal vessel segmentation model capable of adapting to the complex structure of blood vessels
1
2025
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
Multi-scale conv-attention U-Net for medical image segmentation
1
2025
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
1
... 目前,视网膜血管分割方法可以分为2类:无监督学习方法和有监督学习方法. 无监督学习方法无须依赖预先标注的数据,包括阈值分割[2 ] 、匹配滤波法[3 ] 、形态学处理[4 ] 和血管跟踪[5 ] 等方法. 这类方法主要依据图像局部的亮度与纹理信息进行分割,虽然直观且容易实现,但是在处理复杂血管结构及低对比度区域时,其分割效果不尽理想. 相比之下,传统的有监督学习方法依托专家标注的数据,利用支持向量机[6 ] 和随机森林[7 ] 等方法对血管与背景进行分类,能够在一定程度上提高分割性能. 随着深度学习技术的不断发展,卷积神经网络因其自动特征学习能力及对多样化眼底图像的适应性,在医学图像处理领域得到了广泛的应用[8 ] . Ronneberger等[9 ] 设计U-Net模型,在血管分割精度上取得了较大突破,其跳跃连接机制有效融合了低频与高频特征. Li等[10 ] 将卷积块与通道注意力模块相结合,以进一步增强血管特征提取能力. Zhang等[11 ] 采用金字塔通道注意力机制,使网络能够充分捕捉各层级信息. Li等[12 ] 提出自适应血管结构的新型视网膜血管分割模型,通过拟合复杂血管形态,提高了血管分割精度. 上述改进算法虽然取得了较好的血管分割效果,但是U-Net架构本身在捕捉全局依赖关系和抑制噪声干扰方面仍然存在不足[13 -14 ] . ...
1
... Transformer模型[15 ] 因其自注意力机制在全局信息建模上展现出较大优势,逐渐被应用于医学图像分割领域. TransUNet模型[16 ] 将U-Net和Transformer相结合,在编码器阶段利用CNN提取特征,随后通过Transformer模块增强局部细节. TCU-Net模型[17 ] 采用交叉融合Transformer模块替代传统的U-Net跳跃连接,以实现多尺度血管特征间的信息交互,从而丰富了血管特征. Tang等[18 ] 构建复合Transformer,通过局部细节增强和多尺度编码,实现了图像细节特征及多尺度信息的高效感知. Li等[19 ] 结合门控融合Transformer和边缘频率注意力模块,对来自不同编码器的全局特征进行融合,以提升模型对血管结构的识别能力. 尽管上述方法在血管分割性能上取得了较为明显的进展,但是仍然存在局限性:1)在编码部分,连续下采样和卷积操作导致血管特征信息丢失;2)由于低对比度区域的血管信息表达不足,难以捕获微细血管的细节信息;3)传统解码路径在恢复多尺度特征的过程中,对血管信息融合不充分,且背景噪声干扰严重. ...
1
... Transformer模型[15 ] 因其自注意力机制在全局信息建模上展现出较大优势,逐渐被应用于医学图像分割领域. TransUNet模型[16 ] 将U-Net和Transformer相结合,在编码器阶段利用CNN提取特征,随后通过Transformer模块增强局部细节. TCU-Net模型[17 ] 采用交叉融合Transformer模块替代传统的U-Net跳跃连接,以实现多尺度血管特征间的信息交互,从而丰富了血管特征. Tang等[18 ] 构建复合Transformer,通过局部细节增强和多尺度编码,实现了图像细节特征及多尺度信息的高效感知. Li等[19 ] 结合门控融合Transformer和边缘频率注意力模块,对来自不同编码器的全局特征进行融合,以提升模型对血管结构的识别能力. 尽管上述方法在血管分割性能上取得了较为明显的进展,但是仍然存在局限性:1)在编码部分,连续下采样和卷积操作导致血管特征信息丢失;2)由于低对比度区域的血管信息表达不足,难以捕获微细血管的细节信息;3)传统解码路径在恢复多尺度特征的过程中,对血管信息融合不充分,且背景噪声干扰严重. ...
TCU-Net: Transformer embedded in convolutional U-shaped network for retinal vessel segmentation
1
2023
... Transformer模型[15 ] 因其自注意力机制在全局信息建模上展现出较大优势,逐渐被应用于医学图像分割领域. TransUNet模型[16 ] 将U-Net和Transformer相结合,在编码器阶段利用CNN提取特征,随后通过Transformer模块增强局部细节. TCU-Net模型[17 ] 采用交叉融合Transformer模块替代传统的U-Net跳跃连接,以实现多尺度血管特征间的信息交互,从而丰富了血管特征. Tang等[18 ] 构建复合Transformer,通过局部细节增强和多尺度编码,实现了图像细节特征及多尺度信息的高效感知. Li等[19 ] 结合门控融合Transformer和边缘频率注意力模块,对来自不同编码器的全局特征进行融合,以提升模型对血管结构的识别能力. 尽管上述方法在血管分割性能上取得了较为明显的进展,但是仍然存在局限性:1)在编码部分,连续下采样和卷积操作导致血管特征信息丢失;2)由于低对比度区域的血管信息表达不足,难以捕获微细血管的细节信息;3)传统解码路径在恢复多尺度特征的过程中,对血管信息融合不充分,且背景噪声干扰严重. ...
Medical image segmentation method based on full perceived dynamic network
1
2025
... Transformer模型[15 ] 因其自注意力机制在全局信息建模上展现出较大优势,逐渐被应用于医学图像分割领域. TransUNet模型[16 ] 将U-Net和Transformer相结合,在编码器阶段利用CNN提取特征,随后通过Transformer模块增强局部细节. TCU-Net模型[17 ] 采用交叉融合Transformer模块替代传统的U-Net跳跃连接,以实现多尺度血管特征间的信息交互,从而丰富了血管特征. Tang等[18 ] 构建复合Transformer,通过局部细节增强和多尺度编码,实现了图像细节特征及多尺度信息的高效感知. Li等[19 ] 结合门控融合Transformer和边缘频率注意力模块,对来自不同编码器的全局特征进行融合,以提升模型对血管结构的识别能力. 尽管上述方法在血管分割性能上取得了较为明显的进展,但是仍然存在局限性:1)在编码部分,连续下采样和卷积操作导致血管特征信息丢失;2)由于低对比度区域的血管信息表达不足,难以捕获微细血管的细节信息;3)传统解码路径在恢复多尺度特征的过程中,对血管信息融合不充分,且背景噪声干扰严重. ...
Diffusion probabilistic learning with gate-fusion Transformer and edge-frequency attention for retinal vessel segmentation
1
2024
... Transformer模型[15 ] 因其自注意力机制在全局信息建模上展现出较大优势,逐渐被应用于医学图像分割领域. TransUNet模型[16 ] 将U-Net和Transformer相结合,在编码器阶段利用CNN提取特征,随后通过Transformer模块增强局部细节. TCU-Net模型[17 ] 采用交叉融合Transformer模块替代传统的U-Net跳跃连接,以实现多尺度血管特征间的信息交互,从而丰富了血管特征. Tang等[18 ] 构建复合Transformer,通过局部细节增强和多尺度编码,实现了图像细节特征及多尺度信息的高效感知. Li等[19 ] 结合门控融合Transformer和边缘频率注意力模块,对来自不同编码器的全局特征进行融合,以提升模型对血管结构的识别能力. 尽管上述方法在血管分割性能上取得了较为明显的进展,但是仍然存在局限性:1)在编码部分,连续下采样和卷积操作导致血管特征信息丢失;2)由于低对比度区域的血管信息表达不足,难以捕获微细血管的细节信息;3)传统解码路径在恢复多尺度特征的过程中,对血管信息融合不充分,且背景噪声干扰严重. ...
FsaNet: frequency self-attention for semantic segmentation
2
2023
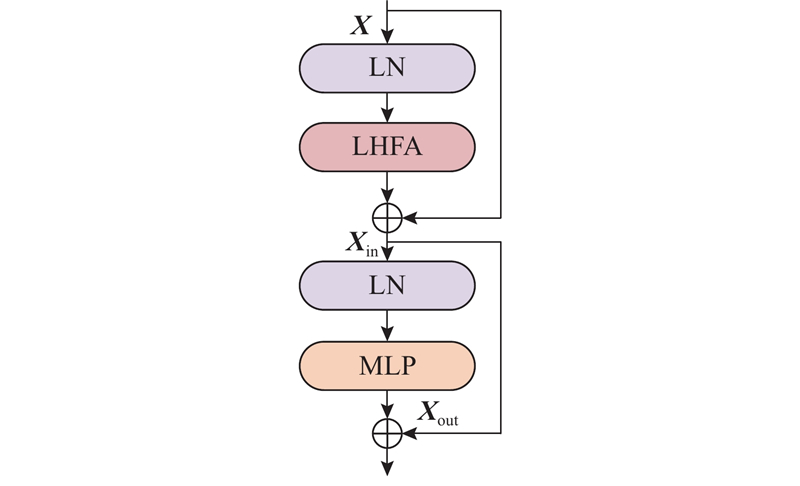
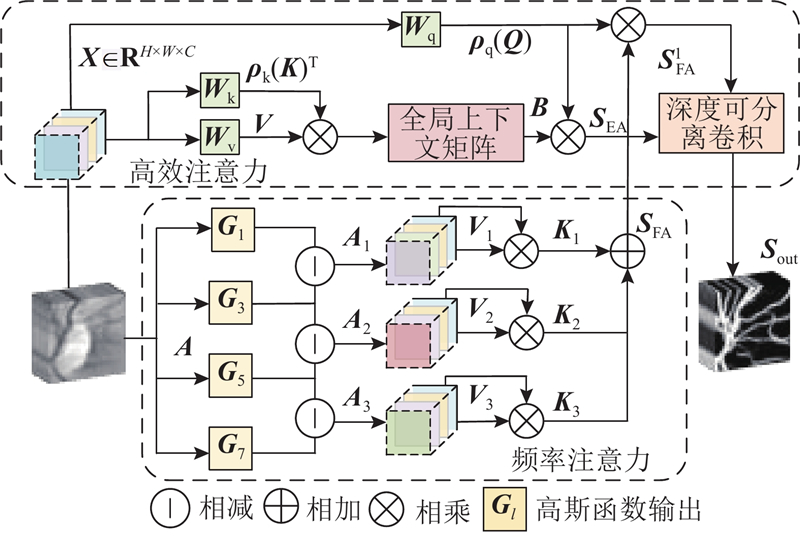
... 现有Transformer中的传统自注意力机制虽然能有效解决局部特征差异,但是忽视了纹理和边缘等高频信息,且自注意力机制具有二次计算复杂性,会产生冗余特征. Zhang等[20 ] 提出频率注意力机制,通过在频域内对不同频率成分进行分离处理,强化高频细节特征的表达. Karimijafarbigloo等[21 ] 提出高效注意力机制,在提供等效自注意力表示的同时,有效缓解了计算复杂性问题. 受文献[20 ]、[21 ]启发,结合ViT结构,提出轻量高频Transformer (ligh-tweight high-frequency Transformer, LHFT),旨在提升网络对血管细节语义特征的识别和捕获能力,并降低计算复杂度,其结构如图2 所示. ...
... 提出高效注意力机制,在提供等效自注意力表示的同时,有效缓解了计算复杂性问题. 受文献[20 ]、[21 ]启发,结合ViT结构,提出轻量高频Transformer (ligh-tweight high-frequency Transformer, LHFT),旨在提升网络对血管细节语义特征的识别和捕获能力,并降低计算复杂度,其结构如图2 所示. ...
2
... 现有Transformer中的传统自注意力机制虽然能有效解决局部特征差异,但是忽视了纹理和边缘等高频信息,且自注意力机制具有二次计算复杂性,会产生冗余特征. Zhang等[20 ] 提出频率注意力机制,通过在频域内对不同频率成分进行分离处理,强化高频细节特征的表达. Karimijafarbigloo等[21 ] 提出高效注意力机制,在提供等效自注意力表示的同时,有效缓解了计算复杂性问题. 受文献[20 ]、[21 ]启发,结合ViT结构,提出轻量高频Transformer (ligh-tweight high-frequency Transformer, LHFT),旨在提升网络对血管细节语义特征的识别和捕获能力,并降低计算复杂度,其结构如图2 所示. ...
... ]、[21 ]启发,结合ViT结构,提出轻量高频Transformer (ligh-tweight high-frequency Transformer, LHFT),旨在提升网络对血管细节语义特征的识别和捕获能力,并降低计算复杂度,其结构如图2 所示. ...
DEA-net: single image dehazing based on detail-enhanced convolution and content-guided attention
2
2024
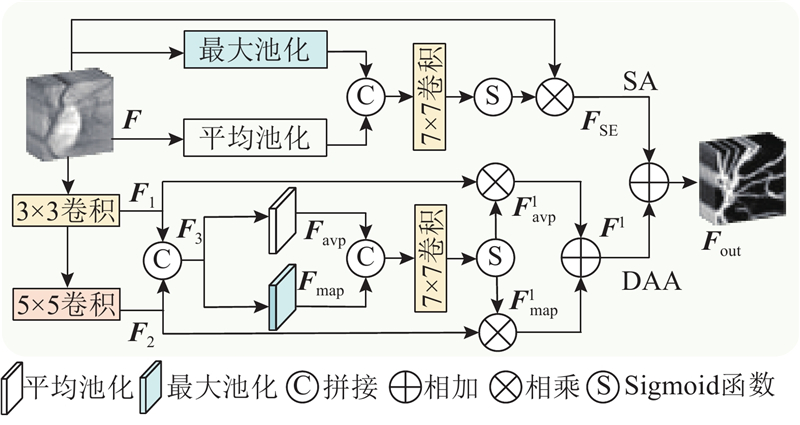
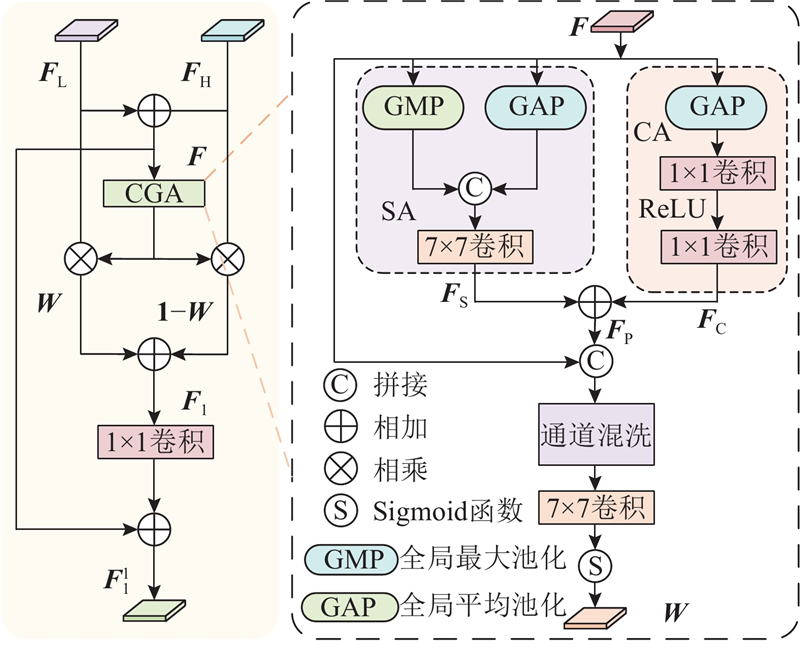
... 在U-Net结构中,跳跃连接机制虽然可以传递信息,但是难以解决低层特征与高层特征在感受野与信息表达上的不匹配问题. Chen等[22 ] 提出内容引导注意力(content-guided attention, CGA)模块,通过生成空间重要性图(spatial importance map, SIM),对低层和高层特征进行自适应加权融合,在增强重要特征的同时,平衡了低层细节信息与高层语义信息. 受文献[22 ]和残差结构的启发,设计特征互补融合模块(feature complementary fusion module, FCFM),其结构如图5 所示. ...
... 提出内容引导注意力(content-guided attention, CGA)模块,通过生成空间重要性图(spatial importance map, SIM),对低层和高层特征进行自适应加权融合,在增强重要特征的同时,平衡了低层细节信息与高层语义信息. 受文献[22 ]和残差结构的启发,设计特征互补融合模块(feature complementary fusion module, FCFM),其结构如图5 所示. ...
1
... 式中:$ {\text{GA}}{{\text{P}}_{\text{S}}} $ $ {\text{GM}}{{\text{P}}_{\text{S}}} $ $ {\text{GA}}{{\text{P}}_{\text{C}}} $ $ {{\boldsymbol{F}}_{\text{S}}} $ $ {{\boldsymbol{F}}_{\text{C}}} $ $ {{\boldsymbol{F}}_{\text{P}}} $ . 最后,采用通道混洗(channel shuffle, CS)操作[23 ] ,将特征$ {{\boldsymbol{F}}_{\text{P}}} $ F W
1
... 为了验证所提算法在视网膜血管分割任务中的有效性,在相同的实验环境下对LFF-Net与U-Net[9 ] 、Attention U-Net[24 ] 、FR-UNet[25 ] 和GT-DLA-dsHFF[26 ] 这4种模型进行对比实验. 其中,U-Net为所提算法的基准模型,Attention U-Net为在U-Net基础上引入注意力机制的变体模型,FR-UNet为视网膜血管分割任务中的经典模型,GT-DLA-dsHFF为在U-Net基础上引入Transformer的变体模型. 不同算法的可视化分割结果如图7 所示. 其中真阳性表示真实的血管区域,假阴性为未被检测出的血管区域,假阳性为背景区域. ...
Full-resolution network and dual-threshold iteration for retinal vessel and coronary angiograph segmentation
1
2022
... 为了验证所提算法在视网膜血管分割任务中的有效性,在相同的实验环境下对LFF-Net与U-Net[9 ] 、Attention U-Net[24 ] 、FR-UNet[25 ] 和GT-DLA-dsHFF[26 ] 这4种模型进行对比实验. 其中,U-Net为所提算法的基准模型,Attention U-Net为在U-Net基础上引入注意力机制的变体模型,FR-UNet为视网膜血管分割任务中的经典模型,GT-DLA-dsHFF为在U-Net基础上引入Transformer的变体模型. 不同算法的可视化分割结果如图7 所示. 其中真阳性表示真实的血管区域,假阴性为未被检测出的血管区域,假阳性为背景区域. ...
Global Transformer and dual local attention network via deep-shallow hierarchical feature fusion for retinal vessel segmentation
1
2023
... 为了验证所提算法在视网膜血管分割任务中的有效性,在相同的实验环境下对LFF-Net与U-Net[9 ] 、Attention U-Net[24 ] 、FR-UNet[25 ] 和GT-DLA-dsHFF[26 ] 这4种模型进行对比实验. 其中,U-Net为所提算法的基准模型,Attention U-Net为在U-Net基础上引入注意力机制的变体模型,FR-UNet为视网膜血管分割任务中的经典模型,GT-DLA-dsHFF为在U-Net基础上引入Transformer的变体模型. 不同算法的可视化分割结果如图7 所示. 其中真阳性表示真实的血管区域,假阴性为未被检测出的血管区域,假阳性为背景区域. ...
SFIT-Net: spatial reconstruction feature interaction transformer retinal vessel segmentation algorithm
3
2025
... Comparison of vessel segmentation results of proposed algorithm and state-of-the-art algorithms on three datasets
Tab.2 数据集 模型 ACC/% SE/% SP/% AUC/% F1/% DRIVE SFIT-Net[27 ] 97.07 81.59 98.55 98.75 82.97 PA-Net[28 ] 95.82 82.84 98.07 98.33 83.93 DAE-Former[29 ] 95.92 79.28 98.46 97.80 83.73 MSM-TDE[30 ] 96.66 84.92 97.23 97.80 79.30 BINet[31 ] 96.06 86.92 97.37 — 84.25 MSTP-Net[32 ] 96.91 83.68 98.18 — 82.58 DAU-Net[33 ] 95.85 81.55 98.15 98.18 82.99 LFF-Net 97.12 80.23 98.74 98.83 82.99 STARE SFIT-Net[27 ] 97.50 82.18 98.92 99.10 83.37 PA-Net[28 ] 97.09 88.13 98.05 99.08 85.61 DAE-Former[29 ] 97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37
BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
27 ]
97.50 82.18 98.92 99.10 83.37 PA-Net[28 ] 97.09 88.13 98.05 99.08 85.61 DAE-Former[29 ] 97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
27 ]
97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
PA-Net: a hybrid architecture for retinal vessel segmentation
3
2025
... Comparison of vessel segmentation results of proposed algorithm and state-of-the-art algorithms on three datasets
Tab.2 数据集 模型 ACC/% SE/% SP/% AUC/% F1/% DRIVE SFIT-Net[27 ] 97.07 81.59 98.55 98.75 82.97 PA-Net[28 ] 95.82 82.84 98.07 98.33 83.93 DAE-Former[29 ] 95.92 79.28 98.46 97.80 83.73 MSM-TDE[30 ] 96.66 84.92 97.23 97.80 79.30 BINet[31 ] 96.06 86.92 97.37 — 84.25 MSTP-Net[32 ] 96.91 83.68 98.18 — 82.58 DAU-Net[33 ] 95.85 81.55 98.15 98.18 82.99 LFF-Net 97.12 80.23 98.74 98.83 82.99 STARE SFIT-Net[27 ] 97.50 82.18 98.92 99.10 83.37 PA-Net[28 ] 97.09 88.13 98.05 99.08 85.61 DAE-Former[29 ] 97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37
BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
28 ]
97.09 88.13 98.05 99.08 85.61 DAE-Former[29 ] 97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
28 ]
96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
3
... Comparison of vessel segmentation results of proposed algorithm and state-of-the-art algorithms on three datasets
Tab.2 数据集 模型 ACC/% SE/% SP/% AUC/% F1/% DRIVE SFIT-Net[27 ] 97.07 81.59 98.55 98.75 82.97 PA-Net[28 ] 95.82 82.84 98.07 98.33 83.93 DAE-Former[29 ] 95.92 79.28 98.46 97.80 83.73 MSM-TDE[30 ] 96.66 84.92 97.23 97.80 79.30 BINet[31 ] 96.06 86.92 97.37 — 84.25 MSTP-Net[32 ] 96.91 83.68 98.18 — 82.58 DAU-Net[33 ] 95.85 81.55 98.15 98.18 82.99 LFF-Net 97.12 80.23 98.74 98.83 82.99 STARE SFIT-Net[27 ] 97.50 82.18 98.92 99.10 83.37 PA-Net[28 ] 97.09 88.13 98.05 99.08 85.61 DAE-Former[29 ] 97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37
BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
29 ]
97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
29 ]
96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
MSM-TDE: multi-scale semantics mining and tiny details enhancement network for retinal vessel segmentation
3
2025
... Comparison of vessel segmentation results of proposed algorithm and state-of-the-art algorithms on three datasets
Tab.2 数据集 模型 ACC/% SE/% SP/% AUC/% F1/% DRIVE SFIT-Net[27 ] 97.07 81.59 98.55 98.75 82.97 PA-Net[28 ] 95.82 82.84 98.07 98.33 83.93 DAE-Former[29 ] 95.92 79.28 98.46 97.80 83.73 MSM-TDE[30 ] 96.66 84.92 97.23 97.80 79.30 BINet[31 ] 96.06 86.92 97.37 — 84.25 MSTP-Net[32 ] 96.91 83.68 98.18 — 82.58 DAU-Net[33 ] 95.85 81.55 98.15 98.18 82.99 LFF-Net 97.12 80.23 98.74 98.83 82.99 STARE SFIT-Net[27 ] 97.50 82.18 98.92 99.10 83.37 PA-Net[28 ] 97.09 88.13 98.05 99.08 85.61 DAE-Former[29 ] 97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37
BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
30 ]
97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
30 ]
96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
BINet: bio-inspired network for retinal vessel segmentation
3
2025
... Comparison of vessel segmentation results of proposed algorithm and state-of-the-art algorithms on three datasets
Tab.2 数据集 模型 ACC/% SE/% SP/% AUC/% F1/% DRIVE SFIT-Net[27 ] 97.07 81.59 98.55 98.75 82.97 PA-Net[28 ] 95.82 82.84 98.07 98.33 83.93 DAE-Former[29 ] 95.92 79.28 98.46 97.80 83.73 MSM-TDE[30 ] 96.66 84.92 97.23 97.80 79.30 BINet[31 ] 96.06 86.92 97.37 — 84.25 MSTP-Net[32 ] 96.91 83.68 98.18 — 82.58 DAU-Net[33 ] 95.85 81.55 98.15 98.18 82.99 LFF-Net 97.12 80.23 98.74 98.83 82.99 STARE SFIT-Net[27 ] 97.50 82.18 98.92 99.10 83.37 PA-Net[28 ] 97.09 88.13 98.05 99.08 85.61 DAE-Former[29 ] 97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37
BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
31 ]
96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
31 ]
96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
Multi-scale three-path network (MSTP-Net): a new architecture for retinal vessel segmentation
3
2025
... Comparison of vessel segmentation results of proposed algorithm and state-of-the-art algorithms on three datasets
Tab.2 数据集 模型 ACC/% SE/% SP/% AUC/% F1/% DRIVE SFIT-Net[27 ] 97.07 81.59 98.55 98.75 82.97 PA-Net[28 ] 95.82 82.84 98.07 98.33 83.93 DAE-Former[29 ] 95.92 79.28 98.46 97.80 83.73 MSM-TDE[30 ] 96.66 84.92 97.23 97.80 79.30 BINet[31 ] 96.06 86.92 97.37 — 84.25 MSTP-Net[32 ] 96.91 83.68 98.18 — 82.58 DAU-Net[33 ] 95.85 81.55 98.15 98.18 82.99 LFF-Net 97.12 80.23 98.74 98.83 82.99 STARE SFIT-Net[27 ] 97.50 82.18 98.92 99.10 83.37 PA-Net[28 ] 97.09 88.13 98.05 99.08 85.61 DAE-Former[29 ] 97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37
BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
32 ]
97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
32 ]
97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
DAU-Net: a novel U-Net with dual attention for retinal vessel segmentation
3
2025
... Comparison of vessel segmentation results of proposed algorithm and state-of-the-art algorithms on three datasets
Tab.2 数据集 模型 ACC/% SE/% SP/% AUC/% F1/% DRIVE SFIT-Net[27 ] 97.07 81.59 98.55 98.75 82.97 PA-Net[28 ] 95.82 82.84 98.07 98.33 83.93 DAE-Former[29 ] 95.92 79.28 98.46 97.80 83.73 MSM-TDE[30 ] 96.66 84.92 97.23 97.80 79.30 BINet[31 ] 96.06 86.92 97.37 — 84.25 MSTP-Net[32 ] 96.91 83.68 98.18 — 82.58 DAU-Net[33 ] 95.85 81.55 98.15 98.18 82.99 LFF-Net 97.12 80.23 98.74 98.83 82.99 STARE SFIT-Net[27 ] 97.50 82.18 98.92 99.10 83.37 PA-Net[28 ] 97.09 88.13 98.05 99.08 85.61 DAE-Former[29 ] 97.06 82.66 98.66 98.97 84.78 MSM-TDE[30 ] 97.26 86.90 98.22 98.09 83.70 BINet[31 ] 96.16 82.76 97.76 — 81.33 MSTP-Net[32 ] 97.61 86.03 98.58 — 84.68 DAU-Net[33 ] 97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37
BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
33 ]
97.12 85.80 98.43 99.08 86.20 LFF-Net 97.62 80.48 99.02 99.12 83.73 CHASE_DB1 SFIT-Net[27 ] 97.53 82.19 98.56 98.81 80.76 PA-Net[28 ] 96.77 85.70 97.79 98.75 83.08 DAE-Former[29 ] 96.60 83.28 97.92 98.70 81.61 MSM-TDE[30 ] 96.67 86.02 97.53 96.45 78.05 BINet[31 ] 96.04 83.93 97.34 — 80.47 MSTP-Net[32 ] 97.45 84.85 98.30 — 80.74 DAU-Net[33 ] 97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...
... [
33 ]
97.00 83.64 98.35 98.94 84.99 LFF-Net 97.65 81.30 98.75 98.99 81.37 BINet设计有特征增强网络,通过多方向卷积来强化低对比度区域中的血管细节,并采用双并行编码路径,充分利用各层特征,以实现高效的多级局部特征提取. 由表2 可知,BINet在DRIVE数据集上的SE和F1指标达到了最优值,在STARE和CHASE_DB1数据集上,其SE指标高于LFF-Net,但是BINet的其余指标均低于LFF-Net,说明LFF-Net在保持较高灵敏度的同时,能够更好地平衡精确率和其余指标,整体分割性能较好. PA-Net采用轻量级并联Transformer结构,同时提取视网膜血管分割所需的长程依赖关系和局部细节信息,并利用自适应血管特征融合模块缓解采样层引起的血管信息损失问题,因而PA-Net在3个数据集上的SE和F1指标均高于LFF-Net,且其SE指标在STARE数据集上达到最优值,但是其余指标均低于LFF-Net,说明LFF-Net在视网膜血管分割中更为可靠. DAU-Net采用具有双重注意力的增强型U形网络,通过2个高效注意力模块突出血管区域特征,抑制伪影干扰,其SE指标在3个数据集上高于LFF-Net,且F1指标在STARE和CHASE_DB1数据集上达到了最优值,但是其余指标在3个数据集上均低于LFF-Net,说明LFF-Net能够实现更为准确和稳定的血管分割效果. MSM-TDE中设计有多尺度语义挖掘和细节增强网络,以更好地表征血管形态变化,使模型能够有效地捕获微细血管信息,其SE指标在3个数据集上高于LFF-Net,在CHASE_DB1数据集中达到了最优值,但是LFF-Net的其余指标均高于MSM-TDE,说明LFF-Net的整体分割精度更高,在视网膜血管分割任务中更稳健. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}