

方面级情感分析(aspect-based sentiment analysis, ABSA)旨在识别文本中目标方面的情感极性. 当前研究主要沿着序列建模和图结构建模2条路线发展. 以LSTM和Transformer为代表的序列建模方法[1-5]借助注意力机制捕捉全局关键语义,但因缺乏显式结构约束,常导致方面词与情感词难以有效对齐. 基于句法依存树的图神经网络(graph neural network, GNN)方法[6-9]虽然能够利用句法捕捉局部结构依赖,但易受解析错误影响,且往往忽略边的语义信息. 为了弥补单一视角的不足,学者们开始探索Transformer和GNN的混合架构[10-13]或引入外部知识[14-21]进行增强. 现有的混合架构多采用简单的并行或串行结构,不能充分挖掘局部结构与全局语义间的层级互补关系. 知识的利用常停留在特征拼接层面,不能实现知识对模型推理过程的深度引导. 这导致当前模型普遍缺乏“先验知识引导-局部句法建模-全局语义推理”的层级化逻辑链条,在面对多跳依赖或情感歧义的复杂场景时表现受限.
为了设计能将外部情感知识与内部句法结构深度融合的统一模型,并通过层级化建模,协同实现“局部情感信号的精准定位”与“全局语义的逻辑推理”,本文提出知识增强的图Transformer网络(knowledge-enhanced graph Transformer network, K-GTNet). 构建知识增强的图结构,通过将外部情感知识与内部句法依赖共同编码至边权重,显式指导后续的图信息传播. 设计层级化的图Transformer模块. 底层的图计算层负责在知识图上聚合局部邻域信息,精准捕捉方面相关的局部情感线索. 顶层的Transformer层对图计算层输出的局部感知特征进行全局上下文建模,实现最终的语义推理与情感判定. 在5个公开数据集上的实验结果验证了K-GTNet的有效性与优越性.
1. 知识增强的图Transformer网络
1.1. K-GTNet模型概述
K-GTNet模型接收句子-方面二元组(Sw, Sa)作为输入,其中Sw ={w1, w2,
K-GTNet的整体架构如图1所示,主要由文本编码器模块(TEM)、知识增强模块(KEM)、图Transformer模块(GTM)和情感分类器模块(SCM)组成.
图 1
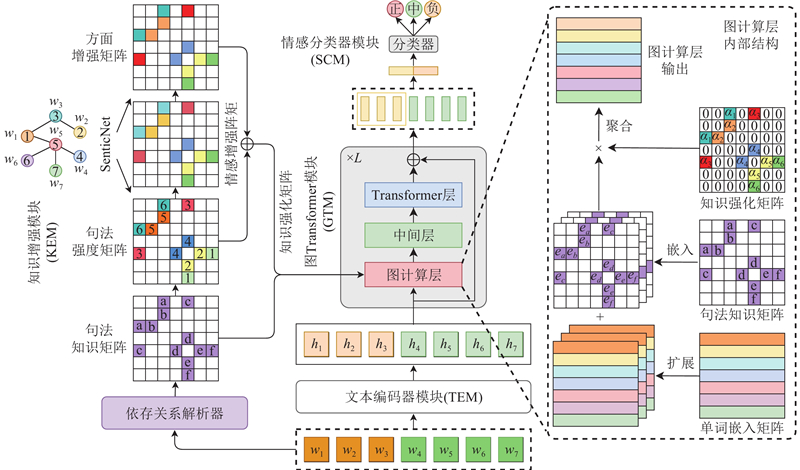
图 1 知识增强图Transformer的方面级情感分析模型架构
Fig.1 Model architecture of knowledge-enhanced graph Transformer for aspect-based sentiment analysis
1.2. 文本编码器模块
TEM的输入是句子-方面二元组(Sw, Sa). 采用BiLSTM和BERT作为文本编码器,提取隐藏的上下文表示. 对于BiLSTM编码器,输入表征包含3种类型的嵌入矩阵:单词嵌入矩阵
对于单词嵌入矩阵E,使用GloVe将句子Sw={w1, w2,
式中:i表示单词wi在句子中的索引位置,js和je为方面项在句子中开始和结束的索引位置.
将句子中所有单词的单词嵌入矩阵E、词性嵌入矩阵T和位置嵌入矩阵P拼接在一起,形成最终的输入表征
式中:dh为单向LSTM输出的隐藏状态向量的维度. 将句子中n个单词的隐藏状态堆叠后,获得输入文本的上下文表示
对于BERT编码器,构建句子-方面对,即将“[CLS] Sw [SEP] Sa [SEP]”作为编码器输入,获取上下文的方面感知隐藏表示. BERT通过动态上下文表征和深层语义建模,为词向量注入强大的语境理解能力. 在初始化词向量的过程中,省略词性嵌入和位置嵌入. TEM模块的输出是文本初始的上下文表征H.
1.3. 知识增强模块
KEM的输入是句子Sw={w1, w2,
式中:d表示单词wi和wj之间的依赖类型(如名词主语nsubj或形容词修饰amod). 若wi和wj之间不存在依赖关系,则邻接矩阵中的对应位置Di,j = 0. 统计语料库中各依赖类型的频次,升序排序,并将其映射为一个正整数,频次越高对应的正整数越大,进而得到句法强度矩阵
在情感知识的获取上,使用SenticNet 7.0知识库. 针对句子中的每个单词wi,在SenticNet中进行精准匹配查找. 若wi存在于SenticNet中,则提取预定义的情感强度Sentic(wi),该值通常为−1~1. 对于那些未在SenticNet中收录的单词,情感强度被设置为0,以避免无关噪声的引入. 利用SenticNet知识库中单词的情感强度来增强邻接矩阵,得到情感增强矩阵
式中:
基于图神经网络的ABSA模型在构建图时经常忽略方面词的关注. 基于SenticNet知识库进一步增强上下文词与方面词之间的情感依赖,得到方面增强矩阵
将方面增强矩阵
1.4. 图Transformer模块
GTM以TEM输出的初始上下文表征H、KEM中构建的D和A作为该模块的输入. GTM由3个部件串联组成:图计算层、中间层和Transformer层. 图计算层显式利用句法信息,强化方面项与直接情感词的关联. Transformer层全局搜索与方面相关的情感信号,处理跨句法分析、多跳路径的复杂依赖. 中间层用于弥合图模型与序列模型之间的输出差异. 上述过程的计算方式如下:
式中:
设计专门用于处理文本的图计算层. 如图1右侧所示为图计算层处理示例的过程. 图计算层的输入包含句法知识矩阵
信息的构造与传递过程如下:
式中:
式中:
1.5. 情感分类器模块
SCM将GTM最后一层的输出Hl作为输入. 对来自同一方面项的单词向量进行平均池化,提取知识增强的方面表征. 计算方式如下:
式中:
将ha输入到softmax函数,计算其在各个情感类别上的概率分布:
式中:Wh、bh分别为全连接层的权重和偏置项. 使用交叉熵与L2正则化函数之和作为损失函数,采用反向传播算法进行训练.
1.6. K-GTNet复杂度分析
K-GTNet模型的整体计算复杂度主要受输入文本长度n、隐藏状态维度d及图Transformer模块的层数L影响. 在TEM中,若采用BERT,则复杂度由内部的自注意力机制和前馈网络主导,为
2. 实验分析
2.1. 数据集介绍
为了验证提出的K-GTNet的性能,在5个公共基准数据集上开展实验. 这5个数据集分别是SemEval 2014 Task 4中的Restaurant14和Laptop14,以及Twitter和SemEval 2015与2016中的Restaurant15和Restaurant16. 每条样本数据包含评论句子、方面项以及该方面项的情感极性. 每个方面项由一个或多个单词组成,情感极性有正向、负向和中性3种类别. 每个数据集都被划分成训练集和测试集,相关的统计信息如表1所示.
表 1 方面级情感分析数据集的统计信息
Tab.1
| 数据集 | 正向 | 负向 | 中性 | |||||
| 训练集 | 测试集 | 训练集 | 测试集 | 训练集 | 测试集 | |||
| Restaurant14 | 728 | 807 | 196 | 637 | 196 | |||
| Laptop14 | 994 | 341 | 870 | 128 | 464 | 169 | ||
| 173 | 173 | 346 | ||||||
| Restaurant15 | 912 | 326 | 256 | 182 | 36 | 34 | ||
| Restaurant16 | 469 | 439 | 117 | 69 | 30 | |||
2.2. 实验设置
在实验设置上,借助Stanford CoreNLP工具来解析句子的依存关系. 对于非BERT模型,采用预训练的GloVe向量,将每个单词映射到300维的向量空间,即de = 300. 为了使模型能够有效地捕捉句法与位置信息,同时控制计算开销,参数dt、dp分别取为30和60. 根据在{30,60,80,100}范围内的对比表现,BiLSTM的隐藏层维度被设置为60. 在训练过程中,将批量大小设置为16,选用Adam优化器进行参数更新,将学习率设置为0.001. 为了抑制过拟合,引入系数为0.000 1的L2正则化项. 此外,所有句子的长度填充或截断至85,可以涵盖绝大多数句子的情感信息. 通过Xavier初始化网络权重,以加速训练过程并提高模型的收敛性. 对于BERT架构,采用“bert-base-uncased”模型,输出为768维词向量. 将输入格式调整为“[CLS] Sw [SEP] Sa [SEP]”,旨在显式引导句子和方向项之间的关系. 针对BERT的微调,使用更小的学习率2×10−5,并设置dropout率为0.5,降低模型过拟合风险.
2.3. 对比模型介绍
为了全面评估K-GTNet的性能,选择以下9个具有代表性的模型进行比较. SenticGCN[14]利用SenticNet情感知识,增强依存边权重. SSEGCN[22]通过构建注意力得分和句法掩码矩阵,增强图卷积网络. GMF-SKIA[23]采用门控机制,将外部情感知识动态融入方面与上下文依赖. KGAN[16]是结合外部知识图谱、句法和上下文信息的知识图谱增强网络. DualGCN[10]设计语义和句法双通道,捕捉结构与语义特征. TextGT[13]是串联图卷积网络和Transformer的方面级情感分析模型. DAGCN[11]基于距离衰减,修剪无关节点. WordTransABSA[20]借助掩码语言模型,检索情感词典. LOSIT[24]构建强化学习的意见诱导树. SenticGCN、GMF-SKIA、KGAN、WordTransABSA和LSOIT均融入了外部先验知识.
2.4. 实验结果与分析
提出的K-GTNet模型在5个数据集上的实验结果如表2所示. 其中,Acc为准确率. 结果表明,K-GTNet在5个数据集上均取得了较高的准确率和F1. 所选的数据集均来源于真实的用户评论和社交媒体推文,验证了K-GTNet在处理真实用户情感方面的有效性和稳健性.
表 2 在5个数据集上与基线模型的对比结果
Tab.2
| 嵌入方式 | 模型 | Restaurant14 | Laptop14 | Restaurant15 | Restaurant16 | ||||||||||
| Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | Acc | F1 | ||||||
| GloVe | SenticGCN (2021) | ||||||||||||||
| SSEGCN (2022) | |||||||||||||||
| KGAN (2023) | |||||||||||||||
| DualGCN (2024) | |||||||||||||||
| TextGT (2024) | |||||||||||||||
| DAGCN (2024) | |||||||||||||||
| K-GTNet (本文) | |||||||||||||||
| BERT | SenticGCN (2021) | ||||||||||||||
| SSEGCN (2022) | |||||||||||||||
| GMF-SKIA (2023) | — | — | — | — | |||||||||||
| KGAN (2023) | |||||||||||||||
| TextGT (2024) | |||||||||||||||
| DAGCN (2024) | |||||||||||||||
| WordTransABSA (2024) | — | — | — | — | |||||||||||
| LSOIT (2024) | — | — | — | — | |||||||||||
| K-GTNet (本文) | |||||||||||||||
基于GloVe嵌入的K-GTNet在Restaurant14、Laptop14和Restaurant16数据集上的F1最优,在Twitter和Restaurant15上次优. 基于BERT嵌入的K-GTNet表现更佳,F1在Restaurant14和Laptop14上最优,在Twitter和Restaurant16上次优. 这种稳定且优秀的表现主要得益于K-GTNet通过外部情感知识和内部句法知识的双重驱动增强图结构,突破纯粹数据驱动模型的语义理解局限. 图计算层与Transformer层的深度融合有效增强了模型从局部到全局的文本建模能力,使模型能够更精准地捕获真实语言中的复杂情感信息.
相较于SSEGCN、DualGCN和TextGT等未注入外部知识的模型,K-GTNet在5个数据集上的平均F1提升了1.0%~4.0%,凸显了先验知识对语义补充和泛化能力强化的积极作用. BERT嵌入模型显著优于GloVe嵌入模型,证实了先验知识对强化模型能力和提升实际应用效果的积极作用.
与SenticGCN、GMF-SKIA和KGAN等注入外部知识的模型相比,K-GTNet在5个数据集上的平均F1提升了0.96%~3.2%,表明K-GTNet在外部知识利用方面效率更高. 这主要归因于K-GTNet将外部知识深度编码到邻接矩阵的边属性,实现情感信息与句法结构的深度融合;其次,图计算层与Transformer层的交替建模,实现了从局部到全局的层次化情感建模,显著增强了模型理解现实世界复杂情感表达的能力.
在Twitter数据集上,K-GTNet的表现略逊于KGAN. 这可能是因为KGAN依赖知识图谱实体推理,更适应口语化表达. 尽管如此,K-GTNet的整体表现依然优于KGAN,并在绝大多数的真实应用数据集上展现出更强的泛化能力和适用性.
2.5. 消融实验
为了评估K-GTNet各组件的贡献,在Restaurant14、Laptop14和Twitter 3个数据集进行消融实验. 实验结果如表3所示,完整的K-GTNet在3个数据集上均取得了最优表现.
表 3 K-GTNet的消融实验结果
Tab.3
| 模型 | Restaurant14 | Laptop14 | ||||||
| Acc | F1 | Acc | F1 | Acc | F1 | |||
| K-GTNet | ||||||||
| K-GTNet w/o Graph | ||||||||
| K-GTNet w/o Transformer | ||||||||
| K-TGNet | ||||||||
| K-GTNet w/o AK | ||||||||
| K-GTNet w/o SK | ||||||||
移除图计算层(K-GTNet w/o Graph),导致F1分别下降了5.1%、2.87%和3.01%,这表明图计算层在句法图上传播情感信号,显式建模方面词与情感词的句法关联,对提升模型性能有重要作用. 移除Transformer层(K-GTNet w/o Transformer),导致F1下降更大(F1分别下降了4.72%、3.65%和3.39%),这证实了Transformer层对捕捉方面词与情感词之间跨距离语义关联和全局语义结构的重要性. 将图计算层与Transformer层的顺序调换(K-TGNet),导致性能下降. 这说明先经过图计算层显式建模句法结构,再由Transformer层整合全局语义的层级递进处理方式是更有效的,以避免破坏原始的结构信息. 此外,移除外部情感知识(K-GTNet w/o AK)或句法结构知识(K-GTNet w/o SK)均导致性能下降. 这表明2种先验知识对K-GTNet的性能增强至关重要,其中句法结构知识的贡献更显著,而外部情感知识提供了词级情感强度的补充指导.
2.6. 超参数分析
为了研究K-GTNet中GTM堆叠层数对模型性能的影响,在3个基准数据集上评估堆叠1~9层GTM的K-GTNet的准确率和F1. 如图2所示,L为层数,堆叠3层GTM的K-GTNet在Restaurant14和Laptop14数据集上取得最优结果,而堆叠7层GTM的K-GTNet在Twitter数据集上效果最佳. 主要原因是Restaurant14和Laptop14数据集为领域内产品评论,文本较长,句法结构较完整,方面词与情感词的依赖关系多通过显式句法路径连接,3层的K-GTNet足以覆盖依存图上2跳或3跳的句法依赖(如直接修饰词或间接修饰词),结合外部情感知识可以精准定位局部情感信号,避免模型过深导致噪声传播. Twitter文本较短,句法不完整(如省略主语、碎片化表达),方面词与情感词的关联常隐含在非结构化线索中. 浅层模型在Twitter数据集中难以从碎片化输入中提取足够多的语义信息,导致关键情感线索的表征不足.
图 2
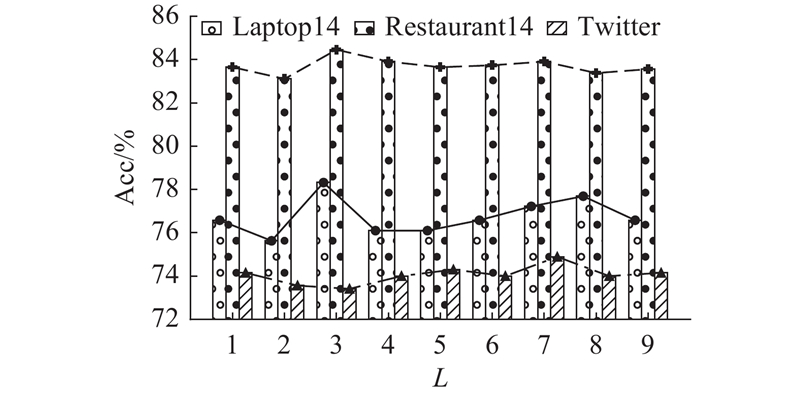
2.7. 可视化分析
在ABSA中,注意力可视化可以直观展示模型是否正确捕捉方面词与情感词的依赖关系. 以句子“I definitely enjoyed the food as well”为例,其中“food”是方面项,且情感极性为正向. 注意力可视化结果如图3所示,颜色越深表示重要性越高. 其中,Satt为注意力分数. 从图3可以看出,“enjoyed”单词的颜色最深且是具有情感色彩的词汇,表明利用提出的K-GTNet,可以建立方面词与情感词之间的联系,并赋予情感词较高的注意力权重,进而准确识别方面项对应的情感极性. 对于“i”、“the”和“as”等无关词,其对应的颜色较浅,表明模型分配给它们的注意力权重较低,可以有效降低它们对方面极性预测的干扰.
图 3
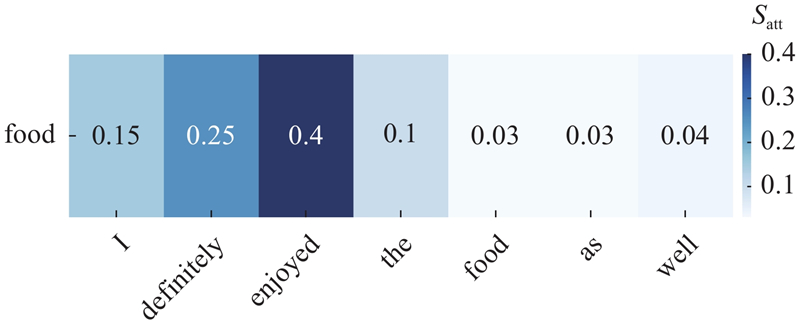
2.8. 时间性能分析
为了评估K-GTNet的计算效率,对时间成本进行分析. 各模型运行时间如表4所示. 其中,ttrain、ttest分别为单次完整训练与测试所需的时间.
表 4 在Laptop14数据集上的运行时间结果
Tab.4
| 模型 | ttrain/s | ttest/s |
| SenticNet | 531.73 | 0.44 |
| SSEGCN | 695.94 | 0.33 |
| KGAN | 2.44 | |
| DualGCN | 747.94 | 0.64 |
| TextGT | 864.97 | 0.78 |
| DAGCN | 0.55 | |
| K-GTNet | 775.43 | 0.64 |
从表4可以看出,K-GTNet的训练耗时为775.43 s. 与KGAN、TextGT和DAGCN相比,K-GTNet在训练效率上展现显著优势. 虽然K-GTNet的训练时间略长于SenticNet、SSEGCN和DualGCN等模型,但考虑到K-GTNet在模型性能(见表2)上的显著提升,该时间成本的适度增加在可接受范围内. 这表明尽管模型引入了外部知识和图Transformer结构,增加了部分计算量,但得益于高效的算法设计,总体时间成本依然保持在合理的区间内. 在测试阶段,K-GTNet的推理时间为0.64 s,与DualGCN持平,并优于TextGT. 这一响应速度足以确保模型在实际应用中快速部署,满足实时性需求. 综上所述,K-GTNet模型在保证性能优势的同时,计算效率也极具竞争力.
2.9. 案例分析
为了进一步验证K-GTNet的有效性,将K-GTNet与SenticNet、KGAN、TextGT、LSOIT模型的分类结果进行对比,具体结果如表5所示.
表 5 K-GTNet与对比模型在数据集上的案例分析结果
Tab.5
| 序号 | 句子 | 真实极性 | SenticGCN | KGAN | TextGT | LSOIT | K-GTNet |
| 1 | I trust the people at Go Sushi , it never disappoints . | 正向 | √ | √ | × | √ | √ |
| 2 | mariah carey Welocmes Twins : Price William asked Kate Middleton if their first public kiss as a married couple was ' , , . | 中性 | × | √ | √ | √ | √ |
| 3 | Put a SSD and use a 21 ' ' LED screen , this set up is silky smooth ! | 中性,中性,正向 | √,×,√ | √,√,× | √,×,× | √,√,× | √,√,√ |
| 4 | The Apple engineers have not yet discovered the delete key . | 负向 | × | √ | √ | √ | √ |
| 5 | just started liking two songs i hated when they first came out - britney spears , sexy bitch - david guetta feat akon . | 负向 | × | √ | × | √ | √ |
在案例1和5中,TextGT因为缺乏外部知识,容易忽略句子中“trust”隐性线索或被“started liking”误导,从而忽视“heated”初始的负面含义. K-GTNet通过引入外部情感知识与上下文全局推理,成功纠正此类误判,证明了该模型在捕捉深层语义方面的优势. 在案例2和4中,面对包含大量噪声的社交文本或“not yet discovered”复杂否定的结构,SenticGCN因过度依赖词典或浅层特征而失效. K-GTNet利用句法结构的显式约束过滤噪声,并将否定知识编码到图结构,准确界定了否定范围与情感倾向. 在案例3中,出现3个方面项且情感分布不一致. K-GTNet通过显式定位方面到情感的句法路径和Transformer层的全局对齐,实现了不同方面情感的精细化区分.
综合上述分析,K-GTNet在处理混合情感、隐性情感以及多方面情感时均展现出显著优势. 这归结于该模型对先验知识、局部建模和全局推理三者递进与互补关系的整合,弥补了传统方法在处理真实世界复杂文本时的局限.
3. 结 语
提出知识增强的图Transformer网络(K-GTNet),将外部情感知识与内部句法知识融合编码到图邻接矩阵的边依赖,结合图计算层的局部结构建模和Transformer层的全局语义推理,构建 “先验知识引导-局部句法建模-全局语义推理”的逻辑框架. 实验结果表明,K-GTNet在5个数据集上表现出极具竞争力的性能. 未来将探索图结构剪枝、Transformer层间参数共享的策略,在保持性能的同时降低计算成本.
参考文献
基于多任务学习与层叠Transformer的多模态情感分析模型
[J].
Multimodal sentiment analysis model based on multi-task learning and stacked cross-modal Transformer
[J].
Knowledge-enabled BERT for aspect-based sentiment analysis
[J].DOI:10.1016/j.knosys.2021.107220 [本文引用: 1]
Base on contextual phrases with cross-correlation attention for aspect-level sentiment analysis
[J].DOI:10.1016/j.eswa.2023.122683
融合Transformer和交互注意力网络的方面级情感分类模型
[J].DOI:10.11992/tis.202303016 [本文引用: 1]
Fusing sentiment knowledge and inter-aspect dependency based on gated mechanism for aspect-level sentiment classification
[J].DOI:10.1016/j.neucom.2023.126462 [本文引用: 1]
LSOIT: lexicon and syntax enhanced opinion induction tree for aspect-based sentiment analysis
[J].DOI:10.1016/j.eswa.2023.121137 [本文引用: 1]
Aspect-level sentiment classification model combining Transformer and interactive attention network
[J].DOI:10.11992/tis.202303016 [本文引用: 1]
Aspect-level sentiment analysis: a survey of graph convolutional network methods
[J].DOI:10.1016/j.inffus.2022.10.004 [本文引用: 1]
Aspect-level sentiment analysis based on aspect-sentence graph convolution network
[J].DOI:10.1016/j.inffus.2023.102143
基于关系门控图卷积网络的方面级情感分析
[J].
Aspect level sentiment analysis based on relation gated graph convolutional network
[J].
DualGCN: exploring syntactic and semantic information for aspect-based sentiment analysis
[J].DOI:10.1109/TNNLS.2022.3219615 [本文引用: 2]
Aspect-based sentiment analysis via affective knowledge enhanced graph convolutional networks
[J].DOI:10.1016/j.knosys.2021.107643 [本文引用: 2]
基于多层次知识增强的方面级情感分析模型
[J].
Aspect-based sentiment analysis model based on multilevel knowledge enhancement
[J].
Knowledge graph augmented network towards multiview representation learning for aspect-based sentiment analysis
[J].DOI:10.1109/TKDE.2023.3250499 [本文引用: 1]
基于多依赖图和知识融合的方面级情感分析模型
[J].
Aspect-based sentiment analysis model based on multi-dependency graph and knowledge fusion
[J].
Aspect-based sentiment analysis by knowledge and attention integrated graph convolutional network
[J].DOI:10.1016/j.asoc.2025.112763
EKBSA: a Chinese sentiment analysis model by enhancing K-BERT
[J].
WordTransABSA: enhancing aspect-based sentiment analysis with masked language modeling for affective token prediction
[J].DOI:10.1016/j.eswa.2023.122289 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}