

在兴趣点(point of interest,POI)预测任务中,可以将POI预测转换成时间序列预测问题[4],依靠循环神经网络和注意力机制来挖掘用户的访问模式[5]. Xie等[6]提出STAR-HiT,通过分层Transformer架构对签到序列中的多粒度时空上下文进行递归建模. Xu等[7]利用堆叠多层Transformer,建模轨迹中非连续访问的时空关系. 这类方法在处理交互信息及全局POI关联时存在局限性,因此后续研究逐渐基于图神经网络(graph neural network,GNN)开展研究. GNN通过构建全局POI转换图和用户相似度图,采用图卷积方式提升用户和POI的表示能力[8],使模型能够同时捕捉访问路径和POI间的交互关系[9-10],但模型对计算和存储的需求较高. 为了解决资源问题,提出将GNN或GCN与注意力机制相结合[11]. Luo等[12]对连续兴趣点和非连续兴趣点采用双重注意力机制. Liu等[13]通过自注意力机制专注于最相似和最重要的用户,以捕获更多个性化的偏好. Lim等[14]融合空间、时间和用户偏好信息,引入图注意力机制.
近期,DeepSeek-R1推理模型在多场景中的应用,证明通过激发大语言模型自身的反思能力来提高任务预测精度是可行的[17]. 本文提出融合大语言模型与轻量模型协同优化的兴趣点轨迹预测框架(LLM reflective fusion architecture,LLM-RFA). 该框架通过三阶段协同推理机制,实现高效、精准的兴趣点轨迹预测.
1. 方法设计
表 1 POI预测方法的数据维度覆盖性对比
Tab.1
| 方法 | 历史轨迹 | 时间信息 | 空间信息 | 位置属性 | 群体影响 |
| FPMC | ☑ | ☑ | ☒ | ☒ | ☒ |
| DeepMove | ☑ | ☑ | ☒ | ☒ | ☒ |
| LSTPM | ☑ | ☑ | ☑ | ☒ | ☒ |
| STAN | ☑ | ☑ | ☑ | ☒ | ☒ |
| Graph-Flashback | ☑ | ☑ | ☑ | ☑ | ☒ |
| GETNext | ☑ | ☑ | ☑ | ☑ | ☒ |
| STHGCN | ☑ | ☑ | ☑ | ☑ | ☒ |
| ROTAN | ☑ | ☑ | ☑ | ☑ | ☒ |
| LLM4POI | ☑ | ☑ | ☑ | ☑ | ☑ |
| LLM - RFA | ☑ | ☑ | ☑ | ☑ | ☑ |
为了有效捕捉用户移动模式中的潜在行为意图,建立三阶段协同推理机制,实现高效精准的POI轨迹预测. 各个阶段依赖于POI的含义、用户历史轨迹、时间信息及群体对个体的影响. 整体框架如图1所示.
图 1
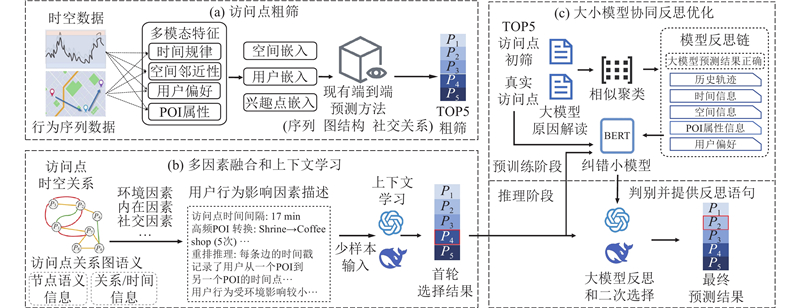
1.1. 访问点粗筛
为了生成高质量的候选POI集合,受到基于旋转的时序注意力网络(rotation-based temporal attention network, ROTAN)[23]的启发,通过旋转操作(rotation operation)和时序注意力机制(temporal attention)捕捉用户行为中的时间特异性模式,提升预测精度. 旋转是通过单位复数建模的,给定嵌入向量
式中:
ROTAN通过旋转操作,将时间信息直接嵌入POI语义空间,避免了传统方法中时间特征与空间特征的拼接问题,为大语言模型决策发挥优势奠定了基础.
1.2. 多因素融合和上下文学习
为了使大语言模型可以更好地理解轨迹任务,在大语言模型推理之前构建时序图,让大语言模型学习用户的时序模式. 将用户轨迹视为图G(Node, Edge, Timestamp). 其中,节点Node是兴趣点 (POI),属性包含id、类别、地理位置(经纬度). 边Edge是用户在不同时间点的移动轨迹,属性包含时间戳、停留时长. 时序维度Timestamp是通过时间戳构建边的顺序,形成序列. 打乱用户的历史访问兴趣点的顺序,并将轨迹图进行编码. 将图的特征与任务以提示词(Prompt)的形式输入大语言模型,分析该用户的时序模式. 图结构输入模式与时序模式学习提示词如下.
<Shuffled_pois>: Given that the user has visited the following POIs in their historical trajectory (with the order shuffled): TS
<Trajectory rearrangement>:Please rearrange these POIs based on the time - series graph information and analyze the basis for ordering (such as time intervals, spatial distances).
<Trajectory Graph Input>:Detailed information of the trajectory graph: GIN
Nodes (Time, Location, POI Info):(PID, PC, coordinates: (LA, LO))
Edges: u -> v
Timestamp: TC
Interval: TIN
Number of Nodes: GN
Feature Dimension: GE
其中,TS为被打乱的用户历史轨迹,GIN为结构图输入的信息,PID为兴趣点ID,PC表示兴趣点含义,LA、LO为兴趣点的经、纬度坐标,u→v表示2个点之间有边,TC为访问兴趣点的时间戳,TIN为两点之间的时间间隔,GN为图的节点数量,GE为图的维度信息.
受到对比式语言-图像预训练(contrastive language-image pre-training, CLIP)[26]的启发,将用户签到数据与时空数据这类异构信息转换为自然语言问答的形式,构建提示词的基础框架. 将原始数据中的关键要素,如时间、用户标识、兴趣点ID等,转化为场景化描述. 融合轨迹重排任务学习到的时序知识,形成基础信息与规律总结的双层输入结构. 采用长思维链(chain-of-thought, CoT)[27]的小样本提示作为示例,在提示词中嵌入用户历史访问规律,引导模型生成首次预测结果. 提示词(prompt)与输入格式如图2所示. 其中,UID表示用户ID,TMAX表示兴趣点最容易被访问的时间段,PK表示上一步得到的时序知识.
图 2

图 2 大语言模型提示与用户签到数据结构
Fig.2 Large language model prompt and user check-in data structure
1.3. 大小模型协同反思的优化
为了提升大语言模型(LLM)在轨迹预测任务中的鲁棒性与泛化能力,设计轻量级纠正模型协同优化框架. 如图1所示,基于文本聚类方法构建轻量级纠正模型的训练数据,利用纠正模型的输出作为反馈信号,驱动大语言模型进行反思修正,从而无须进行大语言模型微调就能提升预测准确性. 反思机制分为3个阶段,形成语言反馈闭环.
1)语言化反思生成阶段. 大语言模型基于首次预测生成可解释的反思文本,明确错误原因并通过聚类算法生成几类模板.
2)反馈解析阶段. 轻量级纠正模型输出判断转化为上述结构化语言.
3)反馈决策衔接阶段. 结构化语言作为大语言模型二次预测的引导提示,替代通用提示,确保调整规则被精确执行.
聚类算法通过三阶段优化,实现高维稀疏文本空间向低维紧致语义空间的映射. 采用改进的TF-IDF加权词袋模型与深度语义嵌入的联合表示:设文档集合为
式中:
式中:
式中:
式中:
设计基于监督学习的轻量级纠正小模型,用于判别LLM预测结果的合理性. 输入数据包括大语言模型的输入及大语言模型预测结果. 输入通过BERT的分词器(Tokenizer),将其编码为输入向量. 输入格式为:Input=Tokenize(Question,Top5,Predict). 其中,Question表示大语言模型的Question输入,Top5为粗筛POI列表,Predict为大语言模型的预测结果. 将编码后的输入向量输入BERT模型,提取文本特征:
式中:
式中:
式中:
损失函数采用交叉熵损失函数进行训练:
式中:
LLM-RFA框架的整体伪代码如下所示.
输入:数据集D (NYC/TKY/CA);End_to_end_model(传统端到端模型);Corrector_model (BERT轻量级纠正模型);LLM(大语言基座模型) 输出:用户下一个将要去的POI点Final_POI 1:计算特征:prob_time_slot(poi)(poi时段访问概率)、group_pattern (群体高频poi) 2:访问点粗筛 3:Emb = Embedding(poi.emb, poi.timestamp) 4:POI_candidates = End_to_end_model(Emb, u.history_trajectory,5) 5:LLM首次预测 6:构建用户轨迹图G = (Node, Edge, Timestamp) 7:shuffled_pois = Shuffle(u.history_trajectory.poi_sequence) //打乱用户历史POI序列 8:Traj_graph_str = Encode(G) //编码图结构 9:temporal_knowledge=LLM.Generate(promptpattern) //引导学习时序知识 10:编码内外因素:internal_factors(个体历史行为)、external_factors(群体/区域特征) 11:LLM_predinitial = LLM.Generate(promptpred) //首次预测 12:大小模型协同优化 13:promptreflect = Text_clustering(error_reason) //语言化反思生成 14: Correction_result = Corrector_model(promptpred, POI_candidates, LLM_predinitial) 15:if Correction_result == true 16: then Final_POP = LLM_predinitial 17:else promptreflect = Corrector_model_Feedback(Correction_result) //反馈解析 18:LLM_pred = LLM.Generate(promptreflect) //反馈决策 19: Final_POI = LLM_pred
2. 性能评估
2.1. 实验准备
表 2 3个真实数据集的统计数据
Tab.2
| 数据集 | Users | POIs | Check-ins | Records |
| NYC | ||||
| TKY | ||||
| CA |
图 3
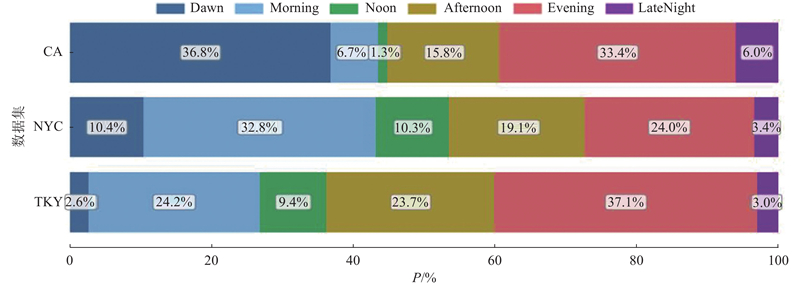
数据集包含签到记录,这些记录包括用户id、POI_id、纬度、经度和时间戳,每个用户的签到记录按照时间戳的顺序排列成为每日序列. 从数据中进行数据统计,统计每个POI点被访问的时间段的概率以及用户历史访问POI点的规律,将粗筛结果与特征信息转化为自然语言描述,构建大语言模型决策与轻量级纠正模型的数据集.
采用基于排名的评价指标,Accuracy@1 (Acc@1). 设测试集中有
在POI预测任务中,Acc@1越高,说明模型能够更准确地预测用户的下一个访问地点.
平均倒数排名(mean reciprocal rank, MRR)是排序任务中常用的评价指标,用于衡量模型对正确结果的排序能力,计算公式为
式中:Q 为查询总数,
在访问点初筛模块中已隐含ACC@5,表示真实的未来位置出现在模型给出的最有可能的5个预测结果中的概率的评估指标. 从表3可以看出,访问点初筛模块中ACC@5较ACC@1有非常大的提升,表明初筛模型已经具备良好的排序基础.
表 3 3个真实数据集上的位置预测结果
Tab.3
| 方法 | TKY | NYC | CA | ||||||||
| Acc@1 | Acc@5 | MRR | Acc@1 | Acc@5 | MRR | Acc@1 | Acc@5 | MRR | |||
| FPMC | |||||||||||
| DeepMove | |||||||||||
| LSTPM | |||||||||||
| STAN | |||||||||||
| Flashback | |||||||||||
| Graph-Flashback | |||||||||||
| GETNext | |||||||||||
| STHGCN | |||||||||||
| ROTAN | |||||||||||
| LLM4POI | — | — | — | — | — | — | |||||
| LLM-RFA(Deepseek-R1) | |||||||||||
| LLM-RFA(Qwen) | |||||||||||
| LLM-RFA(Gpt-4o) | |||||||||||
| LLM-RFA(Gpt-4) | |||||||||||
2.2. 基线方法
采用10个基线模型进行实验.
FPMC[18]:结合矩阵分解和一阶马尔可夫链,捕捉用户的总体偏好和他们的序列行为.
DeepMove[19]:结合门控循环单元和注意力机制来进行预测.
LSTPM[20]:结合长期和短期的序列方法来进行预测.
STAN[12]:这个双层注意力架构利用签到的时空信息,捕捉POI之间的相互依赖关系.
Flashback[30]:基于RNN的方法,利用时空上下文进行回顾性位置预测,从而利用丰富的时空信息.
Graph-Flashback[31]:将获取的POI转换图集成到基于RNN的框架中,增强对序列转换模式的理解.
GETNext[21]:基于Transformer架构,利用用户轨迹图及POI转换概率图,改进下一个POI预测.
STHGCN[22]:使用超图捕获用户内部和用户之间的轨迹,将超图结构编码与时空信息相结合.
ROTAN[23]:通过旋转操作将POI嵌入映射到时间敏感的向量空间,结合时序注意力机制动态捕捉用户行为中的时间特异性模式.
LLM4POI[15]:通过微调时空数据,将POI预测任务转换为问答任务. LLM4POI采用大语言模型的微调方法,训练参数量大,时间成本高,需要较大的硬件支持,无法按照原论文的参数复现结果,因此遵循原论文中的实验数据.
采用3种不同的大语言模型作为实验基座,分别是Qwen-turbo、GPT-4和DeepSeek-R1. 记录大语言模型直接预测的结果与纠错之后的结果,对比展示纠错模块的效果. 在纠错小模型的训练中,将批量大小设置为16,轮数设置为50. 为了进一步增强方法,使用Adam优化器,初始学习率为2×10−5,基础结构包含12层 Transformer 编码器,隐藏层维度为768. 模型的整体架构采用预训练模型加分类头的设计. 通过BERT模型提取文本特征,并使用pooler_output作为句子级表示. 通过dropout层(dropout率为0.1)进行正则化处理. 通过全连接层,将768维的特征映射到与标签类别数相等的输出维度,实现分类任务. 对于所有的基线模型,遵循原始论文中指定的默认超参数配置,确保每种方法都经历相同数量的训练周期.
2.3. 实验结果
如表3所示为3个数据集上基线方法和本文方法的性能,最佳结果用粗体表示,次佳结果用下划线表示. 为了达到最佳的预测结果,使用ACC@5最高的初筛模型(Rotan与STHGCN)生成初筛兴趣点,开展实验. 如图4所示为不同模型的Acc@1及MRR对比. 大语言模型的输出形式更聚焦利用语义理解与推理能力输出精准结果,因此不具备生成5个结果的条件. 从实验数据可以发现,DeepSeek-R1的实验结果普遍优于传统基线方法与其他模型方法. 在NYC数据集上,与最先进的基线方法(LLM4POI)相比略有差距,但优于其他基线模型. 经过分析发现,LLM4POI通过数据集特定微调,能够针对性优化热门地点的预测权重,而本文方法缺乏针对此类分布的自适应调整. 本研究在LLM-RFA(DeepSeek-R1)上新增头/长尾POI细分指标,取前20%标注为头部POI,后50%标注为长尾 POI,实验结果如表4所示. 可以看出,在NYC数据集上,头部POI的预测效果远优于尾部POI的预测效果,因此微调方法针对热门地点优化的优势将被放大. 尽管本框架缺乏热门POI自适应优化机制,但在整体中保持稳定的预测精度,在 TKY 与 CA 标准公开数据集上,较现有主流方法实现了预测性能的显著提升,体现了LLM-RFA框架对不同POI分布场景的泛化性.
图 4
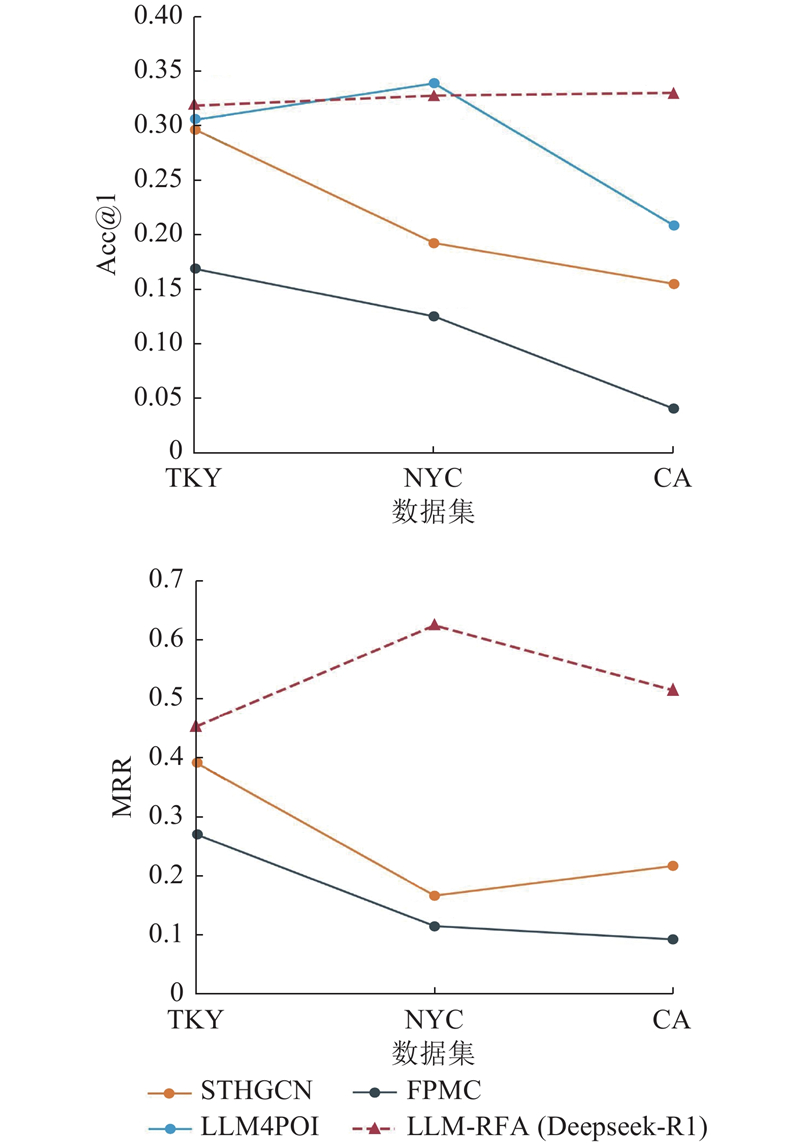
图 4 不同数据集下各方法的Acc@1和MRR对比
Fig.4 Comparison of Acc@1 and MRR of different method across different dataset
表 4 头/长尾 POI 细分指标的Acc@1实验数据
Tab.4
| 方法 | TKY | NYC | CA | |||||
| 头 | 长尾 | 头 | 长尾 | 头 | 长尾 | |||
| LLM-RFA (Deepseek-R1) | ||||||||
表 5 轻量级模型训练的准确率
Tab.5
| 数据集 | A | |||
| Qwen | Gpt-4o | Gpt-4 | Deepseek-R1 | |
| TKY | ||||
| NYC | ||||
| CA | ||||
图 5
表 6 训练消耗时长统计表
Tab.6
| 方法 | 推理延迟/s | 训练时长/s |
| LLM4POI | 1.3467 | |
| Rotan | 37.09 | |
| LLM-RFA |
为了验证轻量级纠正模型的作用,如表7所示为各种大模型基座下使用轻量级纠正模型纠错前、后的实验数据对比. 从实验数据可以看出,利用轻量级纠正模型,可以提升约4%~5%的预测准确率,能够有效提高大语言模型预测的准确率,同时训练参数量小,时间成本远低于大语言模型的微调.
表 7 纠错前、后的Acc@1对比
Tab.7
| 方法 | TKY | NYC | CA | |||||
| 纠正前 | 纠正后 | 纠正前 | 纠正后 | 纠正前 | 纠正后 | |||
| LLM-RFA(Deepseek-R1) | ||||||||
| LLM-RFA(Qwen) | ||||||||
| LLM-RFA(Gpt-4o) | ||||||||
| LLM-RFA(Gpt-4) | ||||||||
为了验证用户的社交关系以及群体影响信息对框架整体预测性能的影响,分别在Deepseek-R1上设计LLM-RFAS和LLM-RFAG 2组消融模型开展实验. LLM-RFAS不考虑用户的偏好,验证内部因素对模型性能的影响. LLM-RFAG不考虑群体对个体的影响,验证外部因素对模型性能的影响. 使用Acc@1作为预测性能的评价指标,实验结果如表8所示. 可以看出,LLM-RFA在3个数据集上的Acc@1大于其他2种消融模型,证明内部因素与外部因素对POI预测的最终效果是至关重要的.
表 8 内外因消融实验结果
Tab.8
| 方法 | TKY | NYC | CA | |||||
| Acc@1 | MRR | Acc@1 | MRR | Acc@1 | MRR | |||
| LLM-RFA(Deepseek-R1) | ||||||||
| LLM-RFAS | ||||||||
| LLM-RFAG | ||||||||
为了进一步探索框架中各组件对结果的影响,设计2组消融实验,实验数据如表9所示. 其中,LLM-RFA(Deepseek-R1)-S表示替换粗筛方法为基线对比方法中的GETNext,LLM-RFA(Deepseek-R1)-N表示删除了其中的多因素融合和上下文学习部分中的用户轨迹重排任务.
表 9 各组件消融实验结果
Tab.9
| 方法 | TKY | NYC | CA | |||||
| Acc@1 | MRR | Acc@1 | MRR | Acc@1 | MRR | |||
| LLM-RFA(Deepseek-R1) | ||||||||
| LLM-RFA(Deepseek-R1)-S | ||||||||
| LLM-RFA(Deepseek-R1)-N | ||||||||
从表9可以看出,LLM-RFA(Deepseek-R1)框架在TKY、NYC、CA数据集的Acc@1和MRR指标上,均优于替换粗筛方法的 LLM-RFA(Deepseek-R1)-S与删除影响因素解构及用户轨迹重排的LLM-RFA(Deepseek-R1)-N. 这表明框架中的访问点粗筛方法、影响因素解构、用户轨迹重排等组件,对提升POI预测精度具有重要作用.
3. 结 语
提出融合大语言模型与轻量级纠正模型协同反思的轨迹预测方法 LLM-RFA. 实验结果表明,LLM-RFA在NYC、TKY、CA数据集上的Acc@1准确率上超越多数现有方法,且无须针对特定数据集微调即可实现高效融合,展现出对不同密度POI的高适配性、高资源利用率与强泛化性能. 未来可以进一步融合实时交通、天气、地形等多模态动态信息,优化长尾POI预测精度,推动算法在城市通勤优化、公共服务优化、犯罪行为预测等场景中的深度应用.
参考文献
Participatory cultural mapping based on collective behavior data in location-based social networks
[J].
Urban human mobility: data-driven modeling and prediction
[J].
Hierarchical transformer with spatio-temporal context aggregation for next point-of-interest recommendation
[J].
Spatio-temporal transformer recommender: next location recommendation with attention mechanism by mining the spatio-temporal relationship between visited locations
[J].DOI:10.3390/ijgi12020079 [本文引用: 1]
基于图卷积网络和终点诱导的行人轨迹预测
[J].DOI:10.11772/j.issn.1001-9081.2024050650 [本文引用: 1]
Pedestrian trajectory prediction based on graph convolutional network and endpoint induction
[J].DOI:10.11772/j.issn.1001-9081.2024050650 [本文引用: 1]
用于行人轨迹预测的时空多图融合的稀疏图卷积网络
[J].DOI:10.3778/j.issn.1002-8331.2411-0227 [本文引用: 1]
Spatial-temporal multi-graph fusion sparse graph convolutional network for pedestrian trajectory prediction
[J].DOI:10.3778/j.issn.1002-8331.2411-0227 [本文引用: 1]
KDRank: knowledge-driven user-aware POI recommendation
[J].DOI:10.1016/j.knosys.2023.110884 [本文引用: 1]
Real-time short-term pedestrian trajectory prediction based on gait biomechanics
[J].DOI:10.3390/s22155828 [本文引用: 1]
Field theory for recurrent mobility
[J].DOI:10.1038/s41467-019-11841-2 [本文引用: 1]
Chain-of-thought prompting elicits reasoning in large language models
[J].DOI:10.59350/bkm9q-11k47 [本文引用: 1]
Modeling user activity preference by leveraging user spatial temporal characteristics in LBSNs
[J].DOI:10.1109/TSMC.2014.2327053 [本文引用: 2]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}