[1]
袁姮, 于东琪, 高原 面向图像分类的双域特征联合网络
[J]. 模式识别与人工智能 , 2025 , 38 (4 ): 325 - 340
[本文引用: 1]
YUAN Heng, YU Dongqi, GAO Yuan Two-domain feature association networks for image classification
[J]. Pattern Recognition and Artificial Intelligence , 2025 , 38 (4 ): 325 - 340
[本文引用: 1]
[2]
张振利, 胡新凯, 李凡, 等 基于CNN和Efficient Transformer的多尺度遥感图像语义分割算法
[J]. 浙江大学学报: 工学版 , 2025 , 59 (4 ): 778 - 786
DOI:10.3785/j.issn.1008-973X.2025.04.013
[本文引用: 1]
ZHANG Zhenli, HU Xinkai, LI Fan, et al Semantic segmentation algorithm for multiscale remote sensing images based on CNN and Efficient Transformer
[J]. Journal of Zhejiang University: Engineering Science , 2025 , 59 (4 ): 778 - 786
DOI:10.3785/j.issn.1008-973X.2025.04.013
[本文引用: 1]
[3]
顾磊, 夏楠, 江佳鸿, 等 基于时空特征增强的单目标跟踪算法
[J]. 浙江大学学报: 工学版 , 2025 , 59 (11 ): 2418 - 2429
DOI:10.3785/j.issn.1008-973X.2025.11.021
[本文引用: 1]
GU Lei, XIA Nan, JIANG Jiahong, et al Single object tracking algorithm based on spatio-temporal feature enhancement
[J]. Journal of Zhejiang University: Engineering Science , 2025 , 59 (11 ): 2418 - 2429
DOI:10.3785/j.issn.1008-973X.2025.11.021
[本文引用: 1]
[4]
ALMALIOGLU Y, TURAN M, SAPUTRA M R U, et al SelfVIO: self-supervised deep monocular visual–inertial odometry and depth estimation
[J]. Neural Networks , 2022 , 150 : 119 - 136
DOI:10.1016/j.neunet.2022.03.005
[本文引用: 1]
[5]
JIAO L, WANG M, LIU X, et al Multiscale deep learning for detection and recognition: a comprehensive survey
[J]. IEEE Transactions on Neural Networks and Learning Systems , 2025 , 36 (4 ): 5900 - 5920
DOI:10.1109/TNNLS.2024.3389454
[本文引用: 1]
[6]
ZHANG Y, YANG Q A survey on multi-task learning
[J]. IEEE Transactions on Knowledge and Data Engineering , 2022 , 34 (12 ): 5586 - 5609
DOI:10.1109/TKDE.2021.3070203
[本文引用: 1]
[7]
HAURUM J B, MADADI M, ESCALERA S, et al. Multi-task classification of sewer pipe defects and properties using a cross-task graph neural network decoder [C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2022: 2806–2817.
[本文引用: 2]
[8]
STANDLEY T, ZAMIR A, CHEN D, et al. Which tasks should be learned together in multi-task learning? [C]// International Conference on Machine Learning . [S. l.]: PMLR, 2020: 9120–9132.
[本文引用: 1]
[9]
LI W H, BILEN H. Knowledge distillation for multi-task learning [C]//European Conference on Computer Vision . Cham: Springer, 2020: 163–176.
[本文引用: 2]
[10]
HU Z, ZHAO Z, YI X, et al. Improving multi-task generalization via regularizing spurious correlation [C]// Advances in Neural Information Processing Systems . New Orleans: MIT Press, 2022: 11450-11466.
[本文引用: 1]
[11]
GUO M, HAQUE A, HUANG D A, et al. Dynamic task prioritization for multitask learning [C]// European Conference on Computer Vision . Cham: Springer, 2018: 270–287.
[本文引用: 1]
[12]
LIU S, JOHNS E, DAVISON A J. End-to-end multi-task learning with attention [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2020: 1871–1880.
[本文引用: 6]
[13]
LIU B, FENG Y, STONE P, et al. FAMO: fast adaptive multitask optimization [C]// Advances in Neural Information Processing Systems . New Orleans: MIT Press, 2023: 57226–57243.
[本文引用: 4]
[14]
YU T, KUMAR S, GUPTA A, et al. Gradient surgery for multi-task learning [C]//Advances in Neural Information Processing Systems . Vancouver: MIT Press, 2020, 33: 5824–5836.
[本文引用: 1]
[15]
LIU B, LIU X, JIN X, et al. Conflict-averse gradient descent for multi-task learning [C]// Advances in Neural Information Processing Systems . [S. l.]: MIT Press, 2021, 34: 18878–18890.
[本文引用: 1]
[16]
JACOB G M, AGARWAL V, STENGER B. Online knowledge distillation for multi-task learning [C]//Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision . Waikoloa: IEEE, 2023: 2359–2368.
[本文引用: 4]
[17]
ZHANG Y, XIANG T, HOSPEDALES T M, et al. Deep mutual learning [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 4320–4328.
[本文引用: 5]
[18]
FAN D, JAGGI M, MENDLER-DÜNNER C. Collaborative learning via prediction consensus [C]// Advances in Neural Information Processing Systems . New Orleans: MIT Press, 2023: 1988–2009.
[本文引用: 1]
[19]
HINTON G, VINYALS O, DEAN J. Distilling the knowledge in a neural network [EB/OL]. (2015-03-09)[2025-05-24]. https://arxiv.org/abs/1503.02531.
[本文引用: 1]
[20]
LIANG X, WU L, LI J, et al. R-drop: regularized dropout for neural networks [C]// Advances in Neural Information Processing Systems . [S. l.]: MIT Press, 2021, 34: 10890–10905.
[本文引用: 2]
[21]
SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from RGBD images [C]// European Conference on Computer Vision . Florence: Springer, 2012: 746–760.
[本文引用: 1]
[22]
CORDTS M, OMRAN M, RAMOS S, et al. The cityscapes dataset for semantic urban scene understanding [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 3213–3223.
[本文引用: 1]
[23]
CHEN L C, PAPANDREOU G, KOKKINOS I, et al DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 40 (4 ): 834 - 848
DOI:10.1109/tpami.2017.2699184
[本文引用: 2]
[24]
CHEN L C, PAPANDREOU G, SCHROFF F, et al. Rethinking atrous convolution for semantic image segmentation [EB/OL]. (2017-12-05)[2025-05-24]. https://arxiv.org/abs/1706.05587.
[本文引用: 2]
[25]
DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Miami: IEEE, 2009: 248–255.
[本文引用: 1]
[26]
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 770–778.
[本文引用: 1]
[27]
HE K, ZHANG X, REN S, et al. Delving deep into rectifiers: surpassing human-level performance on ImageNet classification [C]//Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2016: 1026–1034.
[本文引用: 1]
[28]
KINGMA D P, BA J. Adam: a method for stochastic optimization [EB/OL]. (2017-01-30)[2025-05-24]. https://arxiv.org/abs/1412.6980.
[本文引用: 1]
[29]
KWON J, KIM J, PARK H, et al. ASAM: adaptive sharpness-aware minimization for scale-invariant learning of deep neural networks [C]// International Conference on Machine Learning . [S. l.]: PMLR, 2021: 5905–5914.
[本文引用: 1]
面向图像分类的双域特征联合网络
1
2025
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
面向图像分类的双域特征联合网络
1
2025
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
基于CNN和Efficient Transformer的多尺度遥感图像语义分割算法
1
2025
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
基于CNN和Efficient Transformer的多尺度遥感图像语义分割算法
1
2025
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
基于时空特征增强的单目标跟踪算法
1
2025
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
基于时空特征增强的单目标跟踪算法
1
2025
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
SelfVIO: self-supervised deep monocular visual–inertial odometry and depth estimation
1
2022
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
Multiscale deep learning for detection and recognition: a comprehensive survey
1
2025
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
A survey on multi-task learning
1
2022
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
2
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
... 在简单实施MTL后,由于一些深层原因(如任务之间存在冲突,多任务网络训练过程中泛化监督信号不稳健),导致模型过拟合[7 ,9 ] . 在MTL中,若任务之间的相关性弱[10 ] 或存在冲突,则将导致在多任务网络训练过程中泛化监督信号不稳健. 此外,导致多任务网络训练过程中泛化监督信号不稳健的因素还包括模型大小和虚假相关特征(导致模型在训练集上表现良好,但在测试集上性能显著下降). 现有的MTL方法大多着力于解决任务之间存在的冲突,主要有任务损失的加权方案[11 -13 ] 、梯度操纵[14 -15 ] 和蒸馏驱动多任务优化[9 ,16 ] . ...
1
... 深度神经网络(deep neural network, DNN)已成为解决众多计算机视觉问题的主要技术,一般情况下,DNN被训练来解决单个特定任务,例如图像分类[1 ] 、图像分割[2 ] 或目标跟踪[3 ] . 在现实世界中,通常会面临几个不是孤立的且密切相关的任务[4 -5 ] . 在这种情况下,可以使用多任务学习(multi task learning, MTL)方法[6 ] 来利用任务之间的相互关系,允许在训练数据不足的情况下[7 -8 ] 获得相似甚至更好的性能. ...
2
... 在简单实施MTL后,由于一些深层原因(如任务之间存在冲突,多任务网络训练过程中泛化监督信号不稳健),导致模型过拟合[7 ,9 ] . 在MTL中,若任务之间的相关性弱[10 ] 或存在冲突,则将导致在多任务网络训练过程中泛化监督信号不稳健. 此外,导致多任务网络训练过程中泛化监督信号不稳健的因素还包括模型大小和虚假相关特征(导致模型在训练集上表现良好,但在测试集上性能显著下降). 现有的MTL方法大多着力于解决任务之间存在的冲突,主要有任务损失的加权方案[11 -13 ] 、梯度操纵[14 -15 ] 和蒸馏驱动多任务优化[9 ,16 ] . ...
... [9 ,16 ]. ...
1
... 在简单实施MTL后,由于一些深层原因(如任务之间存在冲突,多任务网络训练过程中泛化监督信号不稳健),导致模型过拟合[7 ,9 ] . 在MTL中,若任务之间的相关性弱[10 ] 或存在冲突,则将导致在多任务网络训练过程中泛化监督信号不稳健. 此外,导致多任务网络训练过程中泛化监督信号不稳健的因素还包括模型大小和虚假相关特征(导致模型在训练集上表现良好,但在测试集上性能显著下降). 现有的MTL方法大多着力于解决任务之间存在的冲突,主要有任务损失的加权方案[11 -13 ] 、梯度操纵[14 -15 ] 和蒸馏驱动多任务优化[9 ,16 ] . ...
1
... 在简单实施MTL后,由于一些深层原因(如任务之间存在冲突,多任务网络训练过程中泛化监督信号不稳健),导致模型过拟合[7 ,9 ] . 在MTL中,若任务之间的相关性弱[10 ] 或存在冲突,则将导致在多任务网络训练过程中泛化监督信号不稳健. 此外,导致多任务网络训练过程中泛化监督信号不稳健的因素还包括模型大小和虚假相关特征(导致模型在训练集上表现良好,但在测试集上性能显著下降). 现有的MTL方法大多着力于解决任务之间存在的冲突,主要有任务损失的加权方案[11 -13 ] 、梯度操纵[14 -15 ] 和蒸馏驱动多任务优化[9 ,16 ] . ...
6
... 经典的MTL通过同时训练一个共享模型实现多个任务的优化,每个任务有特定的损失函数,优化目标是对所有任务的损失函数进行组合并优化,以更新参数. 任务损失的加权方案通过静态预定义或动态地设置各个任务的损失权重,调控不同任务在所有任务中的影响力. Liu等[12 ] 提出动态权重平均(dynamic weight average, DWA)的方法,通过考虑每个任务的损失变化率,随迭代次数变化得到平均任务权重. 在加权方案DWA中,将任务n 的权重$ {\lambda }_{n} $
... 式中:$ {\lambda }_{n}(t) $ t 次迭代时任务n 的损失权重,N 为任务数量,T 为控制任务权重的温度[19 ] ,$ {w}_{n}(\cdot ) $ $ \infty $ ) 范围内传统监督学习损失的相对下降率,$ L_{\text{C}}^{n}(t) $ t 次迭代时任务n 的传统监督学习损失. 在加权方案DWA中,T 按照文献[12 ]取1.0. ...
... 在计算机视觉MTL的背景下,对提出的方法进行验证和研究,使用不同的多任务设置和真实世界数据集开展实验. 为了评估提出方法相对于其他方法的优劣,对几种对标算法开展相同的实验,包括加权方案DWA[12 ] 、FAMO[13 ] 以及蒸馏驱动多任务优化方法OKD[16 ] . 根据相互学习的特点,受到OTW的启发,提出MLW方案. 为了对不同方案进行比较,考虑到训练过程的随机性,所有实验都使用5个不同的随机种子重复5次,对独立使用加权方案DWA(或FAMO、OTW)的网络进行实验,实验结果用Independent表示. 为了评估最佳方法与其他方法之间的差异是否具有统计学意义,对每个指标结果使用配对样本的t 检验进行检验,所有定量结果均以平均值±标准偏差的形式呈现. ...
... 参照文献[12 ]的训练方法进行实验. 利用所提MDML方法,采用从头开始进行训练和使用ResNet-18和ResNet-34进行训练的方式,因此当MDML从头开始进行训练时,按照文献[27 ]进行网络随机初始化. MDML采用Adam算法[28 ] ,批大小为4. 为了保证网络收敛,当采用ResNet-18和ResNet-34进行训练时训练轮次设置为130,当采用从头开始训练的方式时训练轮次设置为200. 对传统监督学习损失和模仿损失进行分析,将分割、深度和法线的模仿损失权重分别设置为0.000 1、10和10. 全局学习率$ \eta $ 12 ,13 ,16 ]取为10−4 ,以保证模型训练的公平性. ...
... 参照文献[12 ,13 ,16 ]取为10−4 ,以保证模型训练的公平性. ...
... 与文献[12 ]一致,语义分割评估指标采用平均交并联(mIoU)和像素精度(pAcc),深度估计指标采用绝对误差(abs)和相对误差(rel),表面法线估计指标采用平均角偏差(Mean)和中值角偏差(Median). ...
4
... 在简单实施MTL后,由于一些深层原因(如任务之间存在冲突,多任务网络训练过程中泛化监督信号不稳健),导致模型过拟合[7 ,9 ] . 在MTL中,若任务之间的相关性弱[10 ] 或存在冲突,则将导致在多任务网络训练过程中泛化监督信号不稳健. 此外,导致多任务网络训练过程中泛化监督信号不稳健的因素还包括模型大小和虚假相关特征(导致模型在训练集上表现良好,但在测试集上性能显著下降). 现有的MTL方法大多着力于解决任务之间存在的冲突,主要有任务损失的加权方案[11 -13 ] 、梯度操纵[14 -15 ] 和蒸馏驱动多任务优化[9 ,16 ] . ...
... Liu等[13 ] 提出快速自适应多任务优化算法(fast adaptive multitask optimization, FAMO),利用历史损失来更新任务权重,确保所有任务的优化进度大致相同,避免计算所有任务梯度. 具体地,当给定任务损失$ \{{l}_{n}\}_{n=1}^{N} $ $ \alpha $ $ \gamma $ $ {{\boldsymbol{d}}}$ ${\boldsymbol{z}}\left( t \right) = {\rm{Softmax }}\left( {{\boldsymbol{d}}\left( {{t}} \right)} \right) $
... 在计算机视觉MTL的背景下,对提出的方法进行验证和研究,使用不同的多任务设置和真实世界数据集开展实验. 为了评估提出方法相对于其他方法的优劣,对几种对标算法开展相同的实验,包括加权方案DWA[12 ] 、FAMO[13 ] 以及蒸馏驱动多任务优化方法OKD[16 ] . 根据相互学习的特点,受到OTW的启发,提出MLW方案. 为了对不同方案进行比较,考虑到训练过程的随机性,所有实验都使用5个不同的随机种子重复5次,对独立使用加权方案DWA(或FAMO、OTW)的网络进行实验,实验结果用Independent表示. 为了评估最佳方法与其他方法之间的差异是否具有统计学意义,对每个指标结果使用配对样本的t 检验进行检验,所有定量结果均以平均值±标准偏差的形式呈现. ...
... 参照文献[12 ]的训练方法进行实验. 利用所提MDML方法,采用从头开始进行训练和使用ResNet-18和ResNet-34进行训练的方式,因此当MDML从头开始进行训练时,按照文献[27 ]进行网络随机初始化. MDML采用Adam算法[28 ] ,批大小为4. 为了保证网络收敛,当采用ResNet-18和ResNet-34进行训练时训练轮次设置为130,当采用从头开始训练的方式时训练轮次设置为200. 对传统监督学习损失和模仿损失进行分析,将分割、深度和法线的模仿损失权重分别设置为0.000 1、10和10. 全局学习率$ \eta $ 12 ,13 ,16 ]取为10−4 ,以保证模型训练的公平性. ...
1
... 在简单实施MTL后,由于一些深层原因(如任务之间存在冲突,多任务网络训练过程中泛化监督信号不稳健),导致模型过拟合[7 ,9 ] . 在MTL中,若任务之间的相关性弱[10 ] 或存在冲突,则将导致在多任务网络训练过程中泛化监督信号不稳健. 此外,导致多任务网络训练过程中泛化监督信号不稳健的因素还包括模型大小和虚假相关特征(导致模型在训练集上表现良好,但在测试集上性能显著下降). 现有的MTL方法大多着力于解决任务之间存在的冲突,主要有任务损失的加权方案[11 -13 ] 、梯度操纵[14 -15 ] 和蒸馏驱动多任务优化[9 ,16 ] . ...
1
... 在简单实施MTL后,由于一些深层原因(如任务之间存在冲突,多任务网络训练过程中泛化监督信号不稳健),导致模型过拟合[7 ,9 ] . 在MTL中,若任务之间的相关性弱[10 ] 或存在冲突,则将导致在多任务网络训练过程中泛化监督信号不稳健. 此外,导致多任务网络训练过程中泛化监督信号不稳健的因素还包括模型大小和虚假相关特征(导致模型在训练集上表现良好,但在测试集上性能显著下降). 现有的MTL方法大多着力于解决任务之间存在的冲突,主要有任务损失的加权方案[11 -13 ] 、梯度操纵[14 -15 ] 和蒸馏驱动多任务优化[9 ,16 ] . ...
4
... 在简单实施MTL后,由于一些深层原因(如任务之间存在冲突,多任务网络训练过程中泛化监督信号不稳健),导致模型过拟合[7 ,9 ] . 在MTL中,若任务之间的相关性弱[10 ] 或存在冲突,则将导致在多任务网络训练过程中泛化监督信号不稳健. 此外,导致多任务网络训练过程中泛化监督信号不稳健的因素还包括模型大小和虚假相关特征(导致模型在训练集上表现良好,但在测试集上性能显著下降). 现有的MTL方法大多着力于解决任务之间存在的冲突,主要有任务损失的加权方案[11 -13 ] 、梯度操纵[14 -15 ] 和蒸馏驱动多任务优化[9 ,16 ] . ...
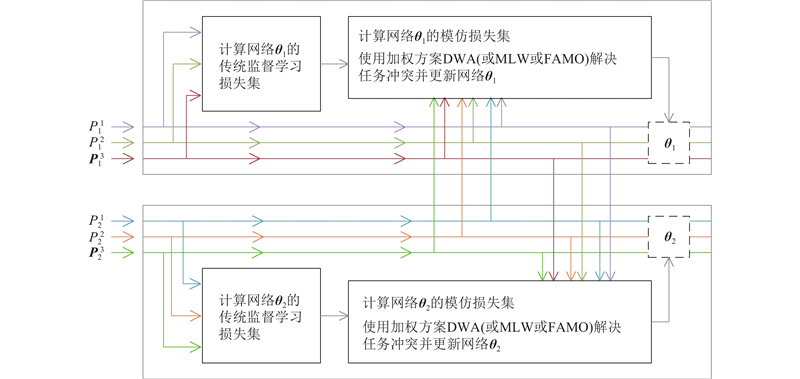
... 1)对于每个多任务网络$ {\boldsymbol{\theta}} $ n ,计算2个多任务网络$ {{\boldsymbol{\theta}} }_{1} $ $ {{\boldsymbol{\theta}} }_{2} $ $ \{L_{{\mathrm{C}}{1}}^{n}(t)\}_{n=1}^{N} $ $ \{L_{{\mathrm{C}}{2}}^{n}(t)\}_{n=1}^{N} $ . 除使用加权方案DWA和FAMO之外,还使用相互学习权重(mutual learning weighting, MLW)解决MTL中的梯度冲突问题. 受线上知识蒸馏(online knowledge distillation, OKD)方法[16 ] 中线上任务权重(online task weighting, OTW)的启发,将任务加权用于多任务网络$ {{\boldsymbol{\theta}} }_{1} $ $ {{\boldsymbol{\theta}} }_{2} $ t 时多任务网络$ {{\boldsymbol{\theta}} }_{1} $ $ {{\boldsymbol{\theta}} }_{2} $ n 个任务的传统监督学习损失为$ L_{{\mathrm{C}}{1}}^{n}(t) $ $ L_{{\mathrm{C}}{2}}^{n}(t) $ n 个任务在迭代t 时的任务权重MLW可以由网络$ {{\boldsymbol{\theta}} }_{1} $ $ {{\boldsymbol{\theta}} }_{2} $
... 在计算机视觉MTL的背景下,对提出的方法进行验证和研究,使用不同的多任务设置和真实世界数据集开展实验. 为了评估提出方法相对于其他方法的优劣,对几种对标算法开展相同的实验,包括加权方案DWA[12 ] 、FAMO[13 ] 以及蒸馏驱动多任务优化方法OKD[16 ] . 根据相互学习的特点,受到OTW的启发,提出MLW方案. 为了对不同方案进行比较,考虑到训练过程的随机性,所有实验都使用5个不同的随机种子重复5次,对独立使用加权方案DWA(或FAMO、OTW)的网络进行实验,实验结果用Independent表示. 为了评估最佳方法与其他方法之间的差异是否具有统计学意义,对每个指标结果使用配对样本的t 检验进行检验,所有定量结果均以平均值±标准偏差的形式呈现. ...
... 参照文献[12 ]的训练方法进行实验. 利用所提MDML方法,采用从头开始进行训练和使用ResNet-18和ResNet-34进行训练的方式,因此当MDML从头开始进行训练时,按照文献[27 ]进行网络随机初始化. MDML采用Adam算法[28 ] ,批大小为4. 为了保证网络收敛,当采用ResNet-18和ResNet-34进行训练时训练轮次设置为130,当采用从头开始训练的方式时训练轮次设置为200. 对传统监督学习损失和模仿损失进行分析,将分割、深度和法线的模仿损失权重分别设置为0.000 1、10和10. 全局学习率$ \eta $ 12 ,13 ,16 ]取为10−4 ,以保证模型训练的公平性. ...
5
... 在图像识别领域,深度相互学习[17 ] (deep mutual learning, DML)及其衍生方法[18 ] 强调多网络间的对等协作与信息共享. Zhang等[17 ] 指出,每个网络从不同的初始条件开始学习不同的表示,因此它们对下一个最有可能的类的概率估计结果不同. DML根据每个训练实例的同类找出并匹配其他最有可能的类,在网络训练过程中增加每个学生网络的后验熵,提供持续且稳健的泛化监督信号,有助于它们收敛到更鲁棒的最小值,从而更好地泛化到测试数据. ...
... [17 ]指出,每个网络从不同的初始条件开始学习不同的表示,因此它们对下一个最有可能的类的概率估计结果不同. DML根据每个训练实例的同类找出并匹配其他最有可能的类,在网络训练过程中增加每个学生网络的后验熵,提供持续且稳健的泛化监督信号,有助于它们收敛到更鲁棒的最小值,从而更好地泛化到测试数据. ...
... 为了提高网络$ {{\boldsymbol{\theta}} }_{1} $ [17 ] 提出使用另一个对等网络$ {{\boldsymbol{\theta}} }_{2} $ $ {p}_{2} $ $ {{\boldsymbol{\theta}} }_{1} $ $ {{\boldsymbol{\theta}} }_{2} $ $ {L}_{\mathrm{C}1}+{D}_{\rm{KL}}({p}_{2}\parallel {p}_{1}) $ $ {L}_{\mathrm{C}2}+{D}_{\rm{KL}}({p}_{1}\parallel {p}_{2}) $ $ {D}_{\rm{KL}}({p}_{2}\parallel {p}_{1}) $ $ {D}_{\rm{KL}}({p}_{1}\parallel {p}_{2}) $ $ {{\boldsymbol{\theta}} }_{1} $ $ {{\boldsymbol{\theta}} }_{2} $ $ {p}_{1} $ $ {p}_{2} $
... 计算模仿损失的对齐函数,在类别和实例识别任务中使用单向或对称KL散度. 该对齐函数已经成功应用于部分工作中[17 ,20 ] ,用于强制每个学生网络的类别后验概率与其他学生网络的类别概率保持一致[17 ] ,或强制Dropout生成的不同子模型的输出分布[20 ] 彼此一致. 在MTL中,由于不同任务具有不同的输出形式,具体地,语义分割输出是分类分布,深度估计是回归输出,表面法线估计输出是归一化的方向向量. 这表示不是所有任务的输出都适合用KL散度对齐,一般情况下,语义分割使用对称KL散度对齐,深度估计使用均方误差(mean squared error, MSE)函数对齐2个多任务网络的深度输出,表面法线估计使用余弦相似度衡量方向一致性. 图1 给出MDML同时训练3个任务时的结构图. ...
... [17 ],或强制Dropout生成的不同子模型的输出分布[20 ] 彼此一致. 在MTL中,由于不同任务具有不同的输出形式,具体地,语义分割输出是分类分布,深度估计是回归输出,表面法线估计输出是归一化的方向向量. 这表示不是所有任务的输出都适合用KL散度对齐,一般情况下,语义分割使用对称KL散度对齐,深度估计使用均方误差(mean squared error, MSE)函数对齐2个多任务网络的深度输出,表面法线估计使用余弦相似度衡量方向一致性. 图1 给出MDML同时训练3个任务时的结构图. ...
1
... 在图像识别领域,深度相互学习[17 ] (deep mutual learning, DML)及其衍生方法[18 ] 强调多网络间的对等协作与信息共享. Zhang等[17 ] 指出,每个网络从不同的初始条件开始学习不同的表示,因此它们对下一个最有可能的类的概率估计结果不同. DML根据每个训练实例的同类找出并匹配其他最有可能的类,在网络训练过程中增加每个学生网络的后验熵,提供持续且稳健的泛化监督信号,有助于它们收敛到更鲁棒的最小值,从而更好地泛化到测试数据. ...
1
... 式中:$ {\lambda }_{n}(t) $ t 次迭代时任务n 的损失权重,N 为任务数量,T 为控制任务权重的温度[19 ] ,$ {w}_{n}(\cdot ) $ $ \infty $ ) 范围内传统监督学习损失的相对下降率,$ L_{\text{C}}^{n}(t) $ t 次迭代时任务n 的传统监督学习损失. 在加权方案DWA中,T 按照文献[12 ]取1.0. ...
2
... 计算模仿损失的对齐函数,在类别和实例识别任务中使用单向或对称KL散度. 该对齐函数已经成功应用于部分工作中[17 ,20 ] ,用于强制每个学生网络的类别后验概率与其他学生网络的类别概率保持一致[17 ] ,或强制Dropout生成的不同子模型的输出分布[20 ] 彼此一致. 在MTL中,由于不同任务具有不同的输出形式,具体地,语义分割输出是分类分布,深度估计是回归输出,表面法线估计输出是归一化的方向向量. 这表示不是所有任务的输出都适合用KL散度对齐,一般情况下,语义分割使用对称KL散度对齐,深度估计使用均方误差(mean squared error, MSE)函数对齐2个多任务网络的深度输出,表面法线估计使用余弦相似度衡量方向一致性. 图1 给出MDML同时训练3个任务时的结构图. ...
... [20 ]彼此一致. 在MTL中,由于不同任务具有不同的输出形式,具体地,语义分割输出是分类分布,深度估计是回归输出,表面法线估计输出是归一化的方向向量. 这表示不是所有任务的输出都适合用KL散度对齐,一般情况下,语义分割使用对称KL散度对齐,深度估计使用均方误差(mean squared error, MSE)函数对齐2个多任务网络的深度输出,表面法线估计使用余弦相似度衡量方向一致性. 图1 给出MDML同时训练3个任务时的结构图. ...
1
... 在NYUv2[21 ] 和Cityscapes[22 ] 2个公共数据集上,对提出的方法进行评估. NYUv2数据集专注于室内场景理解,提供由语义分割、单目深度估计和表面法线估计组成的多任务场景. Cityscapes数据集是城市场景理解领域的标准数据集之一,具有高分辨率的图像和精细的语义标注,适合多种计算机视觉任务,该数据集用于评估语义分割(7个标签)和单目深度估计2个任务的性能. ...
1
... 在NYUv2[21 ] 和Cityscapes[22 ] 2个公共数据集上,对提出的方法进行评估. NYUv2数据集专注于室内场景理解,提供由语义分割、单目深度估计和表面法线估计组成的多任务场景. Cityscapes数据集是城市场景理解领域的标准数据集之一,具有高分辨率的图像和精细的语义标注,适合多种计算机视觉任务,该数据集用于评估语义分割(7个标签)和单目深度估计2个任务的性能. ...
DeepLab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs
2
2017
... 为了排除DNN类型对实验的干扰,使用DeepLab[23 -24 ] 作为任务特定网络. 所提MDML方法是由2个未经训练的学生网络开始训练,后续需要观察MDML在预训练网络上的效果. 对于多任务网络主干,采用从头开始训练的方式进行训练,使用在ImageNet[25 ] 数据集上预训练所得的残差网络ResNet-18和ResNet-34[26 ] 进行训练. ...
... DeepLabV3[24 ] 网络是对DeepLabV2[23 ] 网络的改进,核心思想是利用空洞卷积增强感受野,通过多尺度特征融合提升语义分割的效果. 为了便于描述,将DeepLabV3与残差网络ResNet-18和ResNet-34的结合分别用Net 1(DeeplabV3-18)和Net 2(DeeplabV3-34)表示. ...
2
... 为了排除DNN类型对实验的干扰,使用DeepLab[23 -24 ] 作为任务特定网络. 所提MDML方法是由2个未经训练的学生网络开始训练,后续需要观察MDML在预训练网络上的效果. 对于多任务网络主干,采用从头开始训练的方式进行训练,使用在ImageNet[25 ] 数据集上预训练所得的残差网络ResNet-18和ResNet-34[26 ] 进行训练. ...
... DeepLabV3[24 ] 网络是对DeepLabV2[23 ] 网络的改进,核心思想是利用空洞卷积增强感受野,通过多尺度特征融合提升语义分割的效果. 为了便于描述,将DeepLabV3与残差网络ResNet-18和ResNet-34的结合分别用Net 1(DeeplabV3-18)和Net 2(DeeplabV3-34)表示. ...
1
... 为了排除DNN类型对实验的干扰,使用DeepLab[23 -24 ] 作为任务特定网络. 所提MDML方法是由2个未经训练的学生网络开始训练,后续需要观察MDML在预训练网络上的效果. 对于多任务网络主干,采用从头开始训练的方式进行训练,使用在ImageNet[25 ] 数据集上预训练所得的残差网络ResNet-18和ResNet-34[26 ] 进行训练. ...
1
... 为了排除DNN类型对实验的干扰,使用DeepLab[23 -24 ] 作为任务特定网络. 所提MDML方法是由2个未经训练的学生网络开始训练,后续需要观察MDML在预训练网络上的效果. 对于多任务网络主干,采用从头开始训练的方式进行训练,使用在ImageNet[25 ] 数据集上预训练所得的残差网络ResNet-18和ResNet-34[26 ] 进行训练. ...
1
... 参照文献[12 ]的训练方法进行实验. 利用所提MDML方法,采用从头开始进行训练和使用ResNet-18和ResNet-34进行训练的方式,因此当MDML从头开始进行训练时,按照文献[27 ]进行网络随机初始化. MDML采用Adam算法[28 ] ,批大小为4. 为了保证网络收敛,当采用ResNet-18和ResNet-34进行训练时训练轮次设置为130,当采用从头开始训练的方式时训练轮次设置为200. 对传统监督学习损失和模仿损失进行分析,将分割、深度和法线的模仿损失权重分别设置为0.000 1、10和10. 全局学习率$ \eta $ 12 ,13 ,16 ]取为10−4 ,以保证模型训练的公平性. ...
1
... 参照文献[12 ]的训练方法进行实验. 利用所提MDML方法,采用从头开始进行训练和使用ResNet-18和ResNet-34进行训练的方式,因此当MDML从头开始进行训练时,按照文献[27 ]进行网络随机初始化. MDML采用Adam算法[28 ] ,批大小为4. 为了保证网络收敛,当采用ResNet-18和ResNet-34进行训练时训练轮次设置为130,当采用从头开始训练的方式时训练轮次设置为200. 对传统监督学习损失和模仿损失进行分析,将分割、深度和法线的模仿损失权重分别设置为0.000 1、10和10. 全局学习率$ \eta $ 12 ,13 ,16 ]取为10−4 ,以保证模型训练的公平性. ...
1
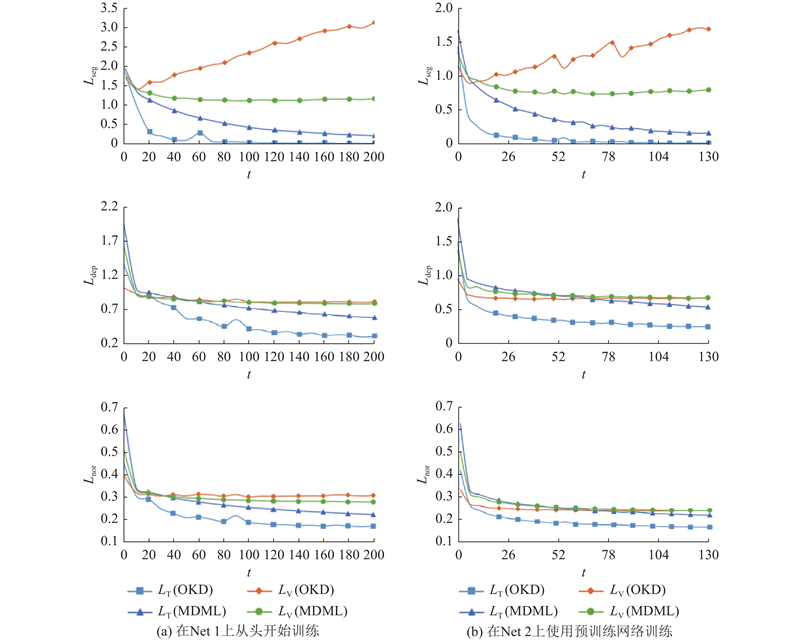
... 使用不同的DNN参数设置,可以得到较好的训练效果,但某些参数的设置可使参数值扰动不会急剧改变网络性能[29 ] . 在从头开始训练网络和预训练网络上,比较MDML算法(本节用加权方案MLW)和OKD算法在3个任务上的训练损失和测试损失的变化,实验结果如图2 所示. 其中,L T 和L V 为3个任务上的训练损失和测试损失,$L_{\mathrm{seg}} $ $ {L}_{\mathrm{dep}} $ $ {L}_{\mathrm{nor}} $



{kind=link}
{kind=link}
{kind=link}
{kind=link}