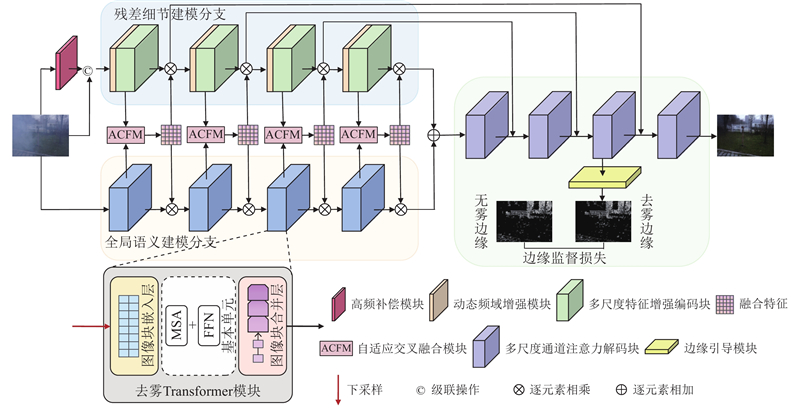
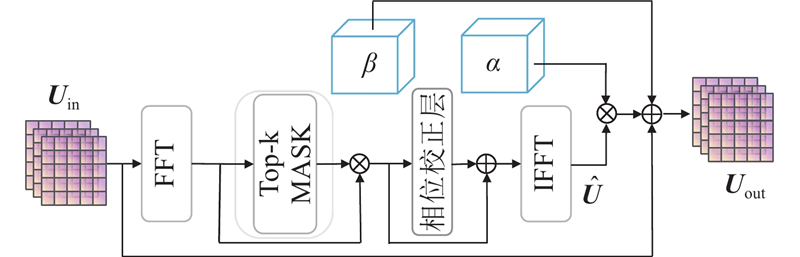
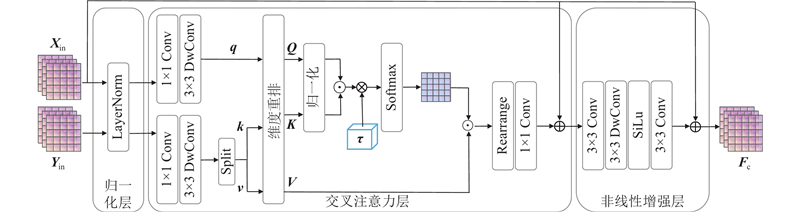
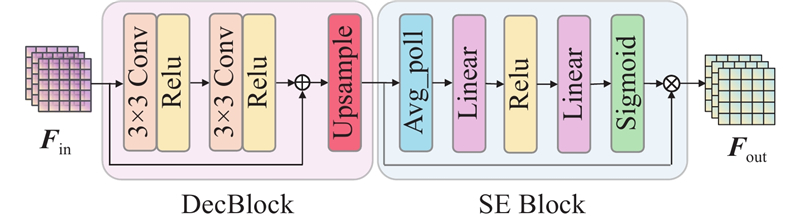
An interactive dual-branch image dehazing network based on dynamic frequency-domain modulation was proposed in order to address the limitation of existing image dehazing method in diverse and complex haze scene. A parallel encoder composed of a global semantic modeling branch and a residual detail modeling branch was constructed to capture global semantic information and local texture feature, respectively. An adaptive cross fusion module was introduced to enable dynamic interaction between cross-branch feature and enhance cross-feature collaboration capability. A dynamic frequency-domain enhancement module was designed to strengthen the response of the model to high-frequency detail and complex haze region. An edge-guided auxiliary supervision mechanism was introduced in the decoder, which formed complementary constraint with frequency-domain enhancement to guide the network to focus on the image contour. Then detail restoration and visual clarity were improved. The experimental results on the RESIDE, NH-HAZE, O-HAZE and I-HAZE datasets demonstrate that the proposed method achieves stronger structure restoration capability and better visual consistency. PSNR and SSIM reached 24.93 dB and 0.812 6 on the I-HAZE dataset, respectively, which were improved by 2.02 dB and 0.0496 compared with the second-best method.
YANG Yan, SONG Xinyu. Interactive image dehazing network based on dynamic frequency-domain modulation. Journal of Zhejiang University(Engineering Science)[J], 2026, 60(6): 1221-1230 doi:10.3785/j.issn.1008-973X.2026.06.009
为了验证本文方法各部分在去雾任务中的有效性,设计消融实验,从编码器结构、模块引入及监督机制进行逐步分析. 具体的实验设置如下. 1) Model A(基础模型):将编码器拆分为上、下两分支提取特征,未加入多尺度增强与交互融合机制,仅采用基础损失项训练. 2) Model B(主干融合结构):在编码器中每一级将上下分支特征相加,传递至下一层,建立基础信息融合路径. 3) Model C(主干+ACFM):在Model B的基础上引入ACFM模块,用于连接每一级上下分支特征. 4) Model D(主干+DFDEM):在Model B的残差细节建模分支中引入DFDEM模块. 5) Model E(主干+ACFM+DFDEM):在Model B中同时引入ACFM模块和DFDEM模块,完成编码器结构的整体构建. 6) Model F(本文方法):在Model E的基础上引入边缘引导模块,并在损失函数中引入边缘监督项,即本文的去雾方法.
THANGARASU G, KANNAN K N, RAMAMOORTHY M, et al. Artificial intelligence-driven image dehazing using deep convolutional neural networks for enhanced satellite imagery perception [C]//Proceedings of the IEEE 15th Symposium on Computer Applications and Industrial Electronics. Penang: IEEE, 2025: 1–6.
NANDINI B M, KAULGUD N. Wavelet-based method for enhancing the visibility of hazy images using color attenuation prior [C]//International Conference on Recent Trends in Electronics and Communication. Mysore: IEEE, 2023: 1–6.
REN W, LIU S, ZHANG H, et al. Single image dehazing via multi-scale convolutional neural networks [C]// European Conference on Computer Vision. Amsterdam: Springer, 2016: 154–169.
LI B, PENG X, WANG Z, et al. Aod-net: all-in-one dehazing network [C]// IEEE International Conference on Computer Vision. Venice: IEEE, 2017: 4770–4778.
LIU X, MA Y, SHI Z, et al. Griddehazenet: attention-based multi-scale network for image dehazing [C]// IEEE/CVF International Conference on Computer Vision. Seoul: IEEE, 2019: 7314–7323.
HU J, SHEN L, SUN G. Squeeze-and-excitation networks [C]// IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 7132–7141.
QIN X, WANG Z, BAI Y, et al. FFA-Net: feature fusion attention network for single image dehazing [C]// AAAI Conference on Artificial Intelligence. New York: AAAI Press, 2020: 11908–11915.
MOU C, WANG Q, ZHANG J. Deep generalized unfolding networks for image restoration [C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 17378–17389.
FU M, LIU H, YU Y, et al. Dw-gan: a discrete wavelet transform gan for nonhomogeneous dehazing [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. [S. l.]: IEEE, 2021: 203–212.
WANG Z, CUN X, BAO J, et al. Uformer: a general U-shaped transformer for image restoration [C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 17662–17672.
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]//IEEE/CVF International Conference on Computer Vision. Montreal: IEEE, 2021: 9992–10002.
ZAMIR S W, ARORA A, KHAN S, et al. Restormer: efficient transformer for high-resolution image restoration [C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022: 5728–5739.
LAI W S, HUANG J B, AHUJA N, et al. Deep Laplacian pyramid networks for fast and accurate super-resolution [C]//IEEE Conference on Computer Vision and Pattern Recognition. Honolulu: IEEE, 2017: 5835–5843.
PASZKE A, GROSS S, MASSA F, et al. Pytorch: an imperative style, high-performance deep learning library [C]// Advances in Neural Information Processing Systems. Vancouver: Curran Associates, 2019: 8024–8035.
ANCUTI C O, ANCUTI C, TIMOFTE R. NH-HAZE: an image dehazing benchmark with non-homogeneous hazy and haze-free images [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Seattle: IEEE, 2020: 444–445.
ANCUTI C O, ANCUTI C, TIMOFTE R, et al. O-haze: a dehazing benchmark with real hazy and haze-free outdoor images [C]// IEEE Conference on Computer Vision and Pattern Recognition Workshops. Salt Lake: IEEE, 2018: 754–762.
ANCUTI C, ANCUTI C O, TIMOFTE R, et al. I-HAZE: a dehazing benchmark with real hazy and haze-free indoor images [C]// International Conference on Advanced Concepts for Intelligent Vision Systems. Poitiers: Springer, 2018: 620–631.
CHEN D, HE M, FAN Q, et al. Gated context aggregation network for image dehazing and deraining [C]// IEEE Winter Conference on Applications of Computer Vision. Waikoloa: IEEE, 2019: 1375–1383.
ZHENG Y, ZHAN J, HE S, et al. Curricular contrastive regularization for physics-aware single image dehazing [C]// IEEE/CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023: 5785–5794.
CHEN J, YAN X, XU Q, et al. Tokenize image patches: global context fusion for effective haze removal in large images [C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2025: 2258–2268.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}