[1]
SUN L, SHANG Z, XIA Y, et al Review of bridge structural health monitoring aided by big data and artificial intelligence: from condition assessment to damage detection
[J]. Journal of Structural Engineering , 2020 , 146 (5 ): 04020073
DOI:10.1061/(ASCE)ST.1943-541X.0002535
[本文引用: 1]
[2]
DENG L, SUN T, YANG L, et al Binocular video-based 3D reconstruction and length quantification of cracks in concrete structures
[J]. Automation in Construction , 2023 , 148 : 104743
DOI:10.1016/j.autcon.2023.104743
[本文引用: 1]
[4]
吴杰, 黄楚越, 韩贝林, 等 基于深度学习和图像处理的螺栓损伤检测
[J]. 哈尔滨工程大学学报 , 2025 , 46 (9 ): 1754 - 1764
DOI:10.11990/jheu.202403035
[本文引用: 1]
WU Jie, HUANG Chuyue, HAN Beilin, et al Bolt damage detection based on deep learning and image processing
[J]. Journal of Harbin Engineering University , 2025 , 46 (9 ): 1754 - 1764
DOI:10.11990/jheu.202403035
[本文引用: 1]
[5]
MAEDA H, KASHIYAMA T, SEKIMOTO Y, et al Generative adversarial network for road damage detection
[J]. Computer-Aided Civil and Infrastructure Engineering , 2021 , 36 (1 ): 47 - 60
DOI:10.1111/mice.12561
[本文引用: 1]
[6]
DEEPA D, SIVASANGARI A ESSR-GAN: enhanced super and semi supervised remora resolution based generative adversarial learning framework model for smartphone based road damage detection
[J]. Multimedia Tools and Applications , 2024 , 83 (2 ): 5099 - 5129
DOI:10.1007/s11042-023-15850-8
[本文引用: 1]
[7]
XU B, LIU C Pavement crack detection algorithm based on generative adversarial network and convolutional neural network under small samples
[J]. Measurement , 2022 , 196 : 111219
DOI:10.1016/j.measurement.2022.111219
[本文引用: 1]
[9]
ZHONG J, JU H, ZHANG W, et al A deeper generative adversarial network for grooved cement concrete pavement crack detection
[J]. Engineering Applications of Artificial Intelligence , 2023 , 119 : 105808
DOI:10.1016/j.engappai.2022.105808
[本文引用: 1]
[10]
DONG J, WANG N, FANG H, et al Innovative method for pavement multiple damages segmentation and measurement by the Road-Seg-CapsNet of feature fusion
[J]. Construction and Building Materials , 2022 , 324 : 126719
DOI:10.1016/j.conbuildmat.2022.126719
[本文引用: 1]
[11]
DUNPHY K, FEKRI M N, GROLINGER K, et al Data augmentation for deep-learning-based multiclass structural damage detection using limited information
[J]. Sensors , 2022 , 22 (16 ): 6193
DOI:10.3390/s22166193
[本文引用: 1]
[12]
PEI L, SUN Z, XIAO L, et al Virtual generation of pavement crack images based on improved deep convolutional generative adversarial network
[J]. Engineering Applications of Artificial Intelligence , 2021 , 104 : 104376
DOI:10.1016/j.engappai.2021.104376
[本文引用: 1]
[13]
程风雯, 甘进, 李星, 等 基于DCGAN的水下结构物表面缺陷图像生成
[J]. 长江科学院院报 , 2023 , 40 (9 ): 155 - 161
DOI:10.11988/ckyyb.20220421
[本文引用: 1]
CHENG Fengwen, GAN Jin, LI Xing, et al Image generation for surface defects of underwater structures based on deep convolutional generative adversarial networks
[J]. Journal of Changjiang River Scientific Research Institute , 2023 , 40 (9 ): 155 - 161
DOI:10.11988/ckyyb.20220421
[本文引用: 1]
[17]
HU E J, SHEN Y, WALLIS P, et al. LoRA: low-rank adaptation of large language models [EB/OL]. (2021–10–16)[2025–07–12]. https://arxiv.org/pdf/2106.09685.
[本文引用: 1]
[18]
NICHOL A Q, DHARIWAL P. Improved denoising diffusion probabilistic models [C]// 38th International Conference on Machine Learning . [S.l.]: ML Research Press, 2021: 8162−8171.
[本文引用: 1]
[19]
ROMBACH R, BLATTMANN A, LORENZ D, et al. High-resolution image synthesis with latent diffusion models [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans. IEEE, 2022: 10674–10685.
[本文引用: 1]
[20]
罗义凯, 徐金华, 李昱燃, 等 基于时空关联和异构图卷积的车道级流量预测
[J]. 哈尔滨工业大学学报 , 2025 , 57 (11 ): 62 - 70
DOI:10.11918/202407040
[本文引用: 1]
LUO Yikai, XU Jinhua, LI Yuran, et al Lane-level traffic flow prediction based on spatiotemporal correlation and heterogeneous graph convolution
[J]. Journal of Harbin Institute of Technology , 2025 , 57 (11 ): 62 - 70
DOI:10.11918/202407040
[本文引用: 1]
[21]
RADFORD A, METZ L, CHINTALA S. Unsupervised representation learning with deep convolutional generative adversarial networks [EB/OL]. (2015−11−19) [2026−04−10]. https://arxiv.org/pdf/1511.06434.
[本文引用: 1]
[22]
GULRAJANI I, AHMED F, ARJOVSKY M, et al. Improved training of Wasserstein GANs [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . [S.l.]: Curran Associates Inc., 2017: 5769−5779.
[本文引用: 1]
[23]
KARRAS T, LAINE S, AILA T. A style-based generator architecture for generative adversarial networks [C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Long Beach: IEEE, 2019: 4401−4410
[本文引用: 1]
[24]
RONNEBERGER O, FISCHER P, BROX T. U-Net: convolutional networks for biomedical image segmentation [C]// Medical Image Computing and Computer-Assisted Intervention – MICCAI 2015 . [S.l.]: Springer, 2015: 234–241.
[本文引用: 1]
[25]
CHEN J, LU Y, YU Q, et al. TransUNet: transformers make strong encoders for medical image segmentation [EB/OL]. (2021–02–08)[2025–07–12]. https://arxiv.org/pdf/2102.04306.
[本文引用: 1]
[26]
MEHTA S, RASTEGARI M. MobileVIT: light-weight, general-purpose, and mobile-friendly vision transformer [EB/OL]. (2022–03–04)[2025–07–12]. https://arxiv.org/pdf/2110.02178.
[本文引用: 1]
[27]
LIU Y, YAO J, LU X, et al DeepCrack: a deep hierarchical feature learning architecture for crack segmentation
[J]. Neurocomputing , 2019 , 338 : 139 - 153
DOI:10.1016/j.neucom.2019.01.036
[本文引用: 1]
Review of bridge structural health monitoring aided by big data and artificial intelligence: from condition assessment to damage detection
1
2020
... 裂缝检测是结构健康监测中的关键任务,广泛应用于桥梁、隧道、道路等基础设施的安全评估[1 ] . 随着基础设施的老化和使用频率的增加,及时发现和修复裂缝对于确保结构安全至关重要[2 ] . 计算机视觉和深度学习技术在裂缝检测领域取得了显著进展,特别是在自动化检测、实时监测和大规模数据处理方面[3 -4 ] . 由于裂缝图像的采集成本较高、数据样本稀缺且裂缝形态复杂多变,现有的裂缝图像数据集面临类别不平衡和样本不足的问题[5 -6 ] . 这些问题导致传统的深度学习方法在裂缝检测任务中表现较差,模型容易出现过拟合现象,且泛化能力较弱[7 ] . 如何有效扩充裂缝图像数据集,提升深度学习模型在复杂场景下的检测性能,已成为重要课题. 传统的数据集扩充方法通过旋转、翻转、缩放、模糊处理和噪声添加等手段来增加样本数量. 尽管这些方法在一定程度上能够扩充数据量,但它们仅对原始裂缝图像进行简单的几何变换,生成的图像在裂缝形态和背景特征方面缺乏多样性. 裂缝的形状、宽度、长度和分布方式差异显著,传统方法难以涵盖这些多样化的裂缝特征. 此外,裂缝图像的背景涉及不同的材料纹理、光照条件、污渍、阴影等因素,这些背景特征对裂缝的可见性及模型的识别能力具有重要影响. 如何在数据集扩充过程中根本性地增加裂缝形态的多样性,已成为模型训练前数据集优化的关键挑战. ...
Binocular video-based 3D reconstruction and length quantification of cracks in concrete structures
1
2023
... 裂缝检测是结构健康监测中的关键任务,广泛应用于桥梁、隧道、道路等基础设施的安全评估[1 ] . 随着基础设施的老化和使用频率的增加,及时发现和修复裂缝对于确保结构安全至关重要[2 ] . 计算机视觉和深度学习技术在裂缝检测领域取得了显著进展,特别是在自动化检测、实时监测和大规模数据处理方面[3 -4 ] . 由于裂缝图像的采集成本较高、数据样本稀缺且裂缝形态复杂多变,现有的裂缝图像数据集面临类别不平衡和样本不足的问题[5 -6 ] . 这些问题导致传统的深度学习方法在裂缝检测任务中表现较差,模型容易出现过拟合现象,且泛化能力较弱[7 ] . 如何有效扩充裂缝图像数据集,提升深度学习模型在复杂场景下的检测性能,已成为重要课题. 传统的数据集扩充方法通过旋转、翻转、缩放、模糊处理和噪声添加等手段来增加样本数量. 尽管这些方法在一定程度上能够扩充数据量,但它们仅对原始裂缝图像进行简单的几何变换,生成的图像在裂缝形态和背景特征方面缺乏多样性. 裂缝的形状、宽度、长度和分布方式差异显著,传统方法难以涵盖这些多样化的裂缝特征. 此外,裂缝图像的背景涉及不同的材料纹理、光照条件、污渍、阴影等因素,这些背景特征对裂缝的可见性及模型的识别能力具有重要影响. 如何在数据集扩充过程中根本性地增加裂缝形态的多样性,已成为模型训练前数据集优化的关键挑战. ...
Deep learning-based structural health monitoring
1
2024
... 裂缝检测是结构健康监测中的关键任务,广泛应用于桥梁、隧道、道路等基础设施的安全评估[1 ] . 随着基础设施的老化和使用频率的增加,及时发现和修复裂缝对于确保结构安全至关重要[2 ] . 计算机视觉和深度学习技术在裂缝检测领域取得了显著进展,特别是在自动化检测、实时监测和大规模数据处理方面[3 -4 ] . 由于裂缝图像的采集成本较高、数据样本稀缺且裂缝形态复杂多变,现有的裂缝图像数据集面临类别不平衡和样本不足的问题[5 -6 ] . 这些问题导致传统的深度学习方法在裂缝检测任务中表现较差,模型容易出现过拟合现象,且泛化能力较弱[7 ] . 如何有效扩充裂缝图像数据集,提升深度学习模型在复杂场景下的检测性能,已成为重要课题. 传统的数据集扩充方法通过旋转、翻转、缩放、模糊处理和噪声添加等手段来增加样本数量. 尽管这些方法在一定程度上能够扩充数据量,但它们仅对原始裂缝图像进行简单的几何变换,生成的图像在裂缝形态和背景特征方面缺乏多样性. 裂缝的形状、宽度、长度和分布方式差异显著,传统方法难以涵盖这些多样化的裂缝特征. 此外,裂缝图像的背景涉及不同的材料纹理、光照条件、污渍、阴影等因素,这些背景特征对裂缝的可见性及模型的识别能力具有重要影响. 如何在数据集扩充过程中根本性地增加裂缝形态的多样性,已成为模型训练前数据集优化的关键挑战. ...
基于深度学习和图像处理的螺栓损伤检测
1
2025
... 裂缝检测是结构健康监测中的关键任务,广泛应用于桥梁、隧道、道路等基础设施的安全评估[1 ] . 随着基础设施的老化和使用频率的增加,及时发现和修复裂缝对于确保结构安全至关重要[2 ] . 计算机视觉和深度学习技术在裂缝检测领域取得了显著进展,特别是在自动化检测、实时监测和大规模数据处理方面[3 -4 ] . 由于裂缝图像的采集成本较高、数据样本稀缺且裂缝形态复杂多变,现有的裂缝图像数据集面临类别不平衡和样本不足的问题[5 -6 ] . 这些问题导致传统的深度学习方法在裂缝检测任务中表现较差,模型容易出现过拟合现象,且泛化能力较弱[7 ] . 如何有效扩充裂缝图像数据集,提升深度学习模型在复杂场景下的检测性能,已成为重要课题. 传统的数据集扩充方法通过旋转、翻转、缩放、模糊处理和噪声添加等手段来增加样本数量. 尽管这些方法在一定程度上能够扩充数据量,但它们仅对原始裂缝图像进行简单的几何变换,生成的图像在裂缝形态和背景特征方面缺乏多样性. 裂缝的形状、宽度、长度和分布方式差异显著,传统方法难以涵盖这些多样化的裂缝特征. 此外,裂缝图像的背景涉及不同的材料纹理、光照条件、污渍、阴影等因素,这些背景特征对裂缝的可见性及模型的识别能力具有重要影响. 如何在数据集扩充过程中根本性地增加裂缝形态的多样性,已成为模型训练前数据集优化的关键挑战. ...
基于深度学习和图像处理的螺栓损伤检测
1
2025
... 裂缝检测是结构健康监测中的关键任务,广泛应用于桥梁、隧道、道路等基础设施的安全评估[1 ] . 随着基础设施的老化和使用频率的增加,及时发现和修复裂缝对于确保结构安全至关重要[2 ] . 计算机视觉和深度学习技术在裂缝检测领域取得了显著进展,特别是在自动化检测、实时监测和大规模数据处理方面[3 -4 ] . 由于裂缝图像的采集成本较高、数据样本稀缺且裂缝形态复杂多变,现有的裂缝图像数据集面临类别不平衡和样本不足的问题[5 -6 ] . 这些问题导致传统的深度学习方法在裂缝检测任务中表现较差,模型容易出现过拟合现象,且泛化能力较弱[7 ] . 如何有效扩充裂缝图像数据集,提升深度学习模型在复杂场景下的检测性能,已成为重要课题. 传统的数据集扩充方法通过旋转、翻转、缩放、模糊处理和噪声添加等手段来增加样本数量. 尽管这些方法在一定程度上能够扩充数据量,但它们仅对原始裂缝图像进行简单的几何变换,生成的图像在裂缝形态和背景特征方面缺乏多样性. 裂缝的形状、宽度、长度和分布方式差异显著,传统方法难以涵盖这些多样化的裂缝特征. 此外,裂缝图像的背景涉及不同的材料纹理、光照条件、污渍、阴影等因素,这些背景特征对裂缝的可见性及模型的识别能力具有重要影响. 如何在数据集扩充过程中根本性地增加裂缝形态的多样性,已成为模型训练前数据集优化的关键挑战. ...
Generative adversarial network for road damage detection
1
2021
... 裂缝检测是结构健康监测中的关键任务,广泛应用于桥梁、隧道、道路等基础设施的安全评估[1 ] . 随着基础设施的老化和使用频率的增加,及时发现和修复裂缝对于确保结构安全至关重要[2 ] . 计算机视觉和深度学习技术在裂缝检测领域取得了显著进展,特别是在自动化检测、实时监测和大规模数据处理方面[3 -4 ] . 由于裂缝图像的采集成本较高、数据样本稀缺且裂缝形态复杂多变,现有的裂缝图像数据集面临类别不平衡和样本不足的问题[5 -6 ] . 这些问题导致传统的深度学习方法在裂缝检测任务中表现较差,模型容易出现过拟合现象,且泛化能力较弱[7 ] . 如何有效扩充裂缝图像数据集,提升深度学习模型在复杂场景下的检测性能,已成为重要课题. 传统的数据集扩充方法通过旋转、翻转、缩放、模糊处理和噪声添加等手段来增加样本数量. 尽管这些方法在一定程度上能够扩充数据量,但它们仅对原始裂缝图像进行简单的几何变换,生成的图像在裂缝形态和背景特征方面缺乏多样性. 裂缝的形状、宽度、长度和分布方式差异显著,传统方法难以涵盖这些多样化的裂缝特征. 此外,裂缝图像的背景涉及不同的材料纹理、光照条件、污渍、阴影等因素,这些背景特征对裂缝的可见性及模型的识别能力具有重要影响. 如何在数据集扩充过程中根本性地增加裂缝形态的多样性,已成为模型训练前数据集优化的关键挑战. ...
ESSR-GAN: enhanced super and semi supervised remora resolution based generative adversarial learning framework model for smartphone based road damage detection
1
2024
... 裂缝检测是结构健康监测中的关键任务,广泛应用于桥梁、隧道、道路等基础设施的安全评估[1 ] . 随着基础设施的老化和使用频率的增加,及时发现和修复裂缝对于确保结构安全至关重要[2 ] . 计算机视觉和深度学习技术在裂缝检测领域取得了显著进展,特别是在自动化检测、实时监测和大规模数据处理方面[3 -4 ] . 由于裂缝图像的采集成本较高、数据样本稀缺且裂缝形态复杂多变,现有的裂缝图像数据集面临类别不平衡和样本不足的问题[5 -6 ] . 这些问题导致传统的深度学习方法在裂缝检测任务中表现较差,模型容易出现过拟合现象,且泛化能力较弱[7 ] . 如何有效扩充裂缝图像数据集,提升深度学习模型在复杂场景下的检测性能,已成为重要课题. 传统的数据集扩充方法通过旋转、翻转、缩放、模糊处理和噪声添加等手段来增加样本数量. 尽管这些方法在一定程度上能够扩充数据量,但它们仅对原始裂缝图像进行简单的几何变换,生成的图像在裂缝形态和背景特征方面缺乏多样性. 裂缝的形状、宽度、长度和分布方式差异显著,传统方法难以涵盖这些多样化的裂缝特征. 此外,裂缝图像的背景涉及不同的材料纹理、光照条件、污渍、阴影等因素,这些背景特征对裂缝的可见性及模型的识别能力具有重要影响. 如何在数据集扩充过程中根本性地增加裂缝形态的多样性,已成为模型训练前数据集优化的关键挑战. ...
Pavement crack detection algorithm based on generative adversarial network and convolutional neural network under small samples
1
2022
... 裂缝检测是结构健康监测中的关键任务,广泛应用于桥梁、隧道、道路等基础设施的安全评估[1 ] . 随着基础设施的老化和使用频率的增加,及时发现和修复裂缝对于确保结构安全至关重要[2 ] . 计算机视觉和深度学习技术在裂缝检测领域取得了显著进展,特别是在自动化检测、实时监测和大规模数据处理方面[3 -4 ] . 由于裂缝图像的采集成本较高、数据样本稀缺且裂缝形态复杂多变,现有的裂缝图像数据集面临类别不平衡和样本不足的问题[5 -6 ] . 这些问题导致传统的深度学习方法在裂缝检测任务中表现较差,模型容易出现过拟合现象,且泛化能力较弱[7 ] . 如何有效扩充裂缝图像数据集,提升深度学习模型在复杂场景下的检测性能,已成为重要课题. 传统的数据集扩充方法通过旋转、翻转、缩放、模糊处理和噪声添加等手段来增加样本数量. 尽管这些方法在一定程度上能够扩充数据量,但它们仅对原始裂缝图像进行简单的几何变换,生成的图像在裂缝形态和背景特征方面缺乏多样性. 裂缝的形状、宽度、长度和分布方式差异显著,传统方法难以涵盖这些多样化的裂缝特征. 此外,裂缝图像的背景涉及不同的材料纹理、光照条件、污渍、阴影等因素,这些背景特征对裂缝的可见性及模型的识别能力具有重要影响. 如何在数据集扩充过程中根本性地增加裂缝形态的多样性,已成为模型训练前数据集优化的关键挑战. ...
Generative adversarial networks: an overview
1
2018
... 大量研究者使用生成对抗网络(generative adversarial network,GAN)[8 ] 生成裂缝图像,并对GAN的网络结构、损失函数及训练策略等方面进行改进以适用于裂缝生成. Zhong等[9 ] 提出改进的加深Wasserstein梯度惩罚生成对抗网络WGAN-GP,用于生成混凝土路面裂缝图像数据集,并在增强后的数据集上使用YOLOv3模型,平均精度达到81.98%. Dong等[10 ] 基于StyleGAN开发的数据增强算法通过扩充裂缝图像数据集来解决数据采集困难的问题. Dunphy等[11 ] 提出基于GAN的多类损伤图像生成方法,评估合成图像在混凝土表面多类损伤检测的有效性. Pei等[12 ] 将变分自编码器(variational autoencoder, VAE)得到的隐变量值作为深度卷积生成对抗网络(deep convolutional generative adversarial network, DCGAN)模型生成器的输入,生成路面裂缝图像,并将合成图像与实际训练图像一起用于训练更高效的Faster R-CNN模型. 程风雯等[13 ] 提出基于DCGAN的水下结构物表面缺陷图像生成方法,该方法为如大坝、引水隧洞的水工结构物的健康检测提供了技术支撑. 赵阳等[14 ] 引入梯度惩罚损失与相似性度量损失,提出改进的CycleGAN图像风格迁移网络,以此生成高质量混凝土坝水下裂缝图像,解决了数据样本不足的问题. ...
A deeper generative adversarial network for grooved cement concrete pavement crack detection
1
2023
... 大量研究者使用生成对抗网络(generative adversarial network,GAN)[8 ] 生成裂缝图像,并对GAN的网络结构、损失函数及训练策略等方面进行改进以适用于裂缝生成. Zhong等[9 ] 提出改进的加深Wasserstein梯度惩罚生成对抗网络WGAN-GP,用于生成混凝土路面裂缝图像数据集,并在增强后的数据集上使用YOLOv3模型,平均精度达到81.98%. Dong等[10 ] 基于StyleGAN开发的数据增强算法通过扩充裂缝图像数据集来解决数据采集困难的问题. Dunphy等[11 ] 提出基于GAN的多类损伤图像生成方法,评估合成图像在混凝土表面多类损伤检测的有效性. Pei等[12 ] 将变分自编码器(variational autoencoder, VAE)得到的隐变量值作为深度卷积生成对抗网络(deep convolutional generative adversarial network, DCGAN)模型生成器的输入,生成路面裂缝图像,并将合成图像与实际训练图像一起用于训练更高效的Faster R-CNN模型. 程风雯等[13 ] 提出基于DCGAN的水下结构物表面缺陷图像生成方法,该方法为如大坝、引水隧洞的水工结构物的健康检测提供了技术支撑. 赵阳等[14 ] 引入梯度惩罚损失与相似性度量损失,提出改进的CycleGAN图像风格迁移网络,以此生成高质量混凝土坝水下裂缝图像,解决了数据样本不足的问题. ...
Innovative method for pavement multiple damages segmentation and measurement by the Road-Seg-CapsNet of feature fusion
1
2022
... 大量研究者使用生成对抗网络(generative adversarial network,GAN)[8 ] 生成裂缝图像,并对GAN的网络结构、损失函数及训练策略等方面进行改进以适用于裂缝生成. Zhong等[9 ] 提出改进的加深Wasserstein梯度惩罚生成对抗网络WGAN-GP,用于生成混凝土路面裂缝图像数据集,并在增强后的数据集上使用YOLOv3模型,平均精度达到81.98%. Dong等[10 ] 基于StyleGAN开发的数据增强算法通过扩充裂缝图像数据集来解决数据采集困难的问题. Dunphy等[11 ] 提出基于GAN的多类损伤图像生成方法,评估合成图像在混凝土表面多类损伤检测的有效性. Pei等[12 ] 将变分自编码器(variational autoencoder, VAE)得到的隐变量值作为深度卷积生成对抗网络(deep convolutional generative adversarial network, DCGAN)模型生成器的输入,生成路面裂缝图像,并将合成图像与实际训练图像一起用于训练更高效的Faster R-CNN模型. 程风雯等[13 ] 提出基于DCGAN的水下结构物表面缺陷图像生成方法,该方法为如大坝、引水隧洞的水工结构物的健康检测提供了技术支撑. 赵阳等[14 ] 引入梯度惩罚损失与相似性度量损失,提出改进的CycleGAN图像风格迁移网络,以此生成高质量混凝土坝水下裂缝图像,解决了数据样本不足的问题. ...
Data augmentation for deep-learning-based multiclass structural damage detection using limited information
1
2022
... 大量研究者使用生成对抗网络(generative adversarial network,GAN)[8 ] 生成裂缝图像,并对GAN的网络结构、损失函数及训练策略等方面进行改进以适用于裂缝生成. Zhong等[9 ] 提出改进的加深Wasserstein梯度惩罚生成对抗网络WGAN-GP,用于生成混凝土路面裂缝图像数据集,并在增强后的数据集上使用YOLOv3模型,平均精度达到81.98%. Dong等[10 ] 基于StyleGAN开发的数据增强算法通过扩充裂缝图像数据集来解决数据采集困难的问题. Dunphy等[11 ] 提出基于GAN的多类损伤图像生成方法,评估合成图像在混凝土表面多类损伤检测的有效性. Pei等[12 ] 将变分自编码器(variational autoencoder, VAE)得到的隐变量值作为深度卷积生成对抗网络(deep convolutional generative adversarial network, DCGAN)模型生成器的输入,生成路面裂缝图像,并将合成图像与实际训练图像一起用于训练更高效的Faster R-CNN模型. 程风雯等[13 ] 提出基于DCGAN的水下结构物表面缺陷图像生成方法,该方法为如大坝、引水隧洞的水工结构物的健康检测提供了技术支撑. 赵阳等[14 ] 引入梯度惩罚损失与相似性度量损失,提出改进的CycleGAN图像风格迁移网络,以此生成高质量混凝土坝水下裂缝图像,解决了数据样本不足的问题. ...
Virtual generation of pavement crack images based on improved deep convolutional generative adversarial network
1
2021
... 大量研究者使用生成对抗网络(generative adversarial network,GAN)[8 ] 生成裂缝图像,并对GAN的网络结构、损失函数及训练策略等方面进行改进以适用于裂缝生成. Zhong等[9 ] 提出改进的加深Wasserstein梯度惩罚生成对抗网络WGAN-GP,用于生成混凝土路面裂缝图像数据集,并在增强后的数据集上使用YOLOv3模型,平均精度达到81.98%. Dong等[10 ] 基于StyleGAN开发的数据增强算法通过扩充裂缝图像数据集来解决数据采集困难的问题. Dunphy等[11 ] 提出基于GAN的多类损伤图像生成方法,评估合成图像在混凝土表面多类损伤检测的有效性. Pei等[12 ] 将变分自编码器(variational autoencoder, VAE)得到的隐变量值作为深度卷积生成对抗网络(deep convolutional generative adversarial network, DCGAN)模型生成器的输入,生成路面裂缝图像,并将合成图像与实际训练图像一起用于训练更高效的Faster R-CNN模型. 程风雯等[13 ] 提出基于DCGAN的水下结构物表面缺陷图像生成方法,该方法为如大坝、引水隧洞的水工结构物的健康检测提供了技术支撑. 赵阳等[14 ] 引入梯度惩罚损失与相似性度量损失,提出改进的CycleGAN图像风格迁移网络,以此生成高质量混凝土坝水下裂缝图像,解决了数据样本不足的问题. ...
基于DCGAN的水下结构物表面缺陷图像生成
1
2023
... 大量研究者使用生成对抗网络(generative adversarial network,GAN)[8 ] 生成裂缝图像,并对GAN的网络结构、损失函数及训练策略等方面进行改进以适用于裂缝生成. Zhong等[9 ] 提出改进的加深Wasserstein梯度惩罚生成对抗网络WGAN-GP,用于生成混凝土路面裂缝图像数据集,并在增强后的数据集上使用YOLOv3模型,平均精度达到81.98%. Dong等[10 ] 基于StyleGAN开发的数据增强算法通过扩充裂缝图像数据集来解决数据采集困难的问题. Dunphy等[11 ] 提出基于GAN的多类损伤图像生成方法,评估合成图像在混凝土表面多类损伤检测的有效性. Pei等[12 ] 将变分自编码器(variational autoencoder, VAE)得到的隐变量值作为深度卷积生成对抗网络(deep convolutional generative adversarial network, DCGAN)模型生成器的输入,生成路面裂缝图像,并将合成图像与实际训练图像一起用于训练更高效的Faster R-CNN模型. 程风雯等[13 ] 提出基于DCGAN的水下结构物表面缺陷图像生成方法,该方法为如大坝、引水隧洞的水工结构物的健康检测提供了技术支撑. 赵阳等[14 ] 引入梯度惩罚损失与相似性度量损失,提出改进的CycleGAN图像风格迁移网络,以此生成高质量混凝土坝水下裂缝图像,解决了数据样本不足的问题. ...
基于DCGAN的水下结构物表面缺陷图像生成
1
2023
... 大量研究者使用生成对抗网络(generative adversarial network,GAN)[8 ] 生成裂缝图像,并对GAN的网络结构、损失函数及训练策略等方面进行改进以适用于裂缝生成. Zhong等[9 ] 提出改进的加深Wasserstein梯度惩罚生成对抗网络WGAN-GP,用于生成混凝土路面裂缝图像数据集,并在增强后的数据集上使用YOLOv3模型,平均精度达到81.98%. Dong等[10 ] 基于StyleGAN开发的数据增强算法通过扩充裂缝图像数据集来解决数据采集困难的问题. Dunphy等[11 ] 提出基于GAN的多类损伤图像生成方法,评估合成图像在混凝土表面多类损伤检测的有效性. Pei等[12 ] 将变分自编码器(variational autoencoder, VAE)得到的隐变量值作为深度卷积生成对抗网络(deep convolutional generative adversarial network, DCGAN)模型生成器的输入,生成路面裂缝图像,并将合成图像与实际训练图像一起用于训练更高效的Faster R-CNN模型. 程风雯等[13 ] 提出基于DCGAN的水下结构物表面缺陷图像生成方法,该方法为如大坝、引水隧洞的水工结构物的健康检测提供了技术支撑. 赵阳等[14 ] 引入梯度惩罚损失与相似性度量损失,提出改进的CycleGAN图像风格迁移网络,以此生成高质量混凝土坝水下裂缝图像,解决了数据样本不足的问题. ...
基于改进CycleGAN与YOLOv8s的混凝土坝水下裂缝识别方法
1
2025
... 大量研究者使用生成对抗网络(generative adversarial network,GAN)[8 ] 生成裂缝图像,并对GAN的网络结构、损失函数及训练策略等方面进行改进以适用于裂缝生成. Zhong等[9 ] 提出改进的加深Wasserstein梯度惩罚生成对抗网络WGAN-GP,用于生成混凝土路面裂缝图像数据集,并在增强后的数据集上使用YOLOv3模型,平均精度达到81.98%. Dong等[10 ] 基于StyleGAN开发的数据增强算法通过扩充裂缝图像数据集来解决数据采集困难的问题. Dunphy等[11 ] 提出基于GAN的多类损伤图像生成方法,评估合成图像在混凝土表面多类损伤检测的有效性. Pei等[12 ] 将变分自编码器(variational autoencoder, VAE)得到的隐变量值作为深度卷积生成对抗网络(deep convolutional generative adversarial network, DCGAN)模型生成器的输入,生成路面裂缝图像,并将合成图像与实际训练图像一起用于训练更高效的Faster R-CNN模型. 程风雯等[13 ] 提出基于DCGAN的水下结构物表面缺陷图像生成方法,该方法为如大坝、引水隧洞的水工结构物的健康检测提供了技术支撑. 赵阳等[14 ] 引入梯度惩罚损失与相似性度量损失,提出改进的CycleGAN图像风格迁移网络,以此生成高质量混凝土坝水下裂缝图像,解决了数据样本不足的问题. ...
基于改进CycleGAN与YOLOv8s的混凝土坝水下裂缝识别方法
1
2025
... 大量研究者使用生成对抗网络(generative adversarial network,GAN)[8 ] 生成裂缝图像,并对GAN的网络结构、损失函数及训练策略等方面进行改进以适用于裂缝生成. Zhong等[9 ] 提出改进的加深Wasserstein梯度惩罚生成对抗网络WGAN-GP,用于生成混凝土路面裂缝图像数据集,并在增强后的数据集上使用YOLOv3模型,平均精度达到81.98%. Dong等[10 ] 基于StyleGAN开发的数据增强算法通过扩充裂缝图像数据集来解决数据采集困难的问题. Dunphy等[11 ] 提出基于GAN的多类损伤图像生成方法,评估合成图像在混凝土表面多类损伤检测的有效性. Pei等[12 ] 将变分自编码器(variational autoencoder, VAE)得到的隐变量值作为深度卷积生成对抗网络(deep convolutional generative adversarial network, DCGAN)模型生成器的输入,生成路面裂缝图像,并将合成图像与实际训练图像一起用于训练更高效的Faster R-CNN模型. 程风雯等[13 ] 提出基于DCGAN的水下结构物表面缺陷图像生成方法,该方法为如大坝、引水隧洞的水工结构物的健康检测提供了技术支撑. 赵阳等[14 ] 引入梯度惩罚损失与相似性度量损失,提出改进的CycleGAN图像风格迁移网络,以此生成高质量混凝土坝水下裂缝图像,解决了数据样本不足的问题. ...
基于AIGC技术的民族服饰设计研究: 以畲族为例
1
2025
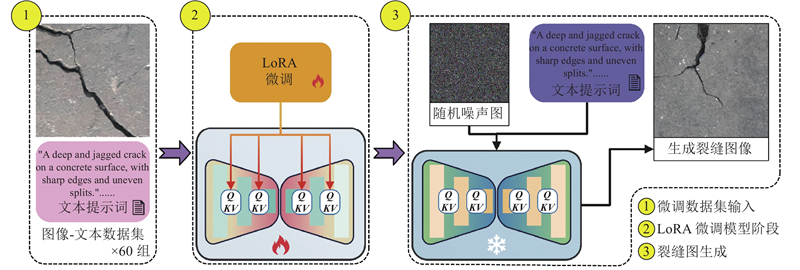
... 尽管GAN在裂缝图像生成方面取得了较好的成果,但训练过程中的不稳定性以及模式崩塌问题,使得生成的图像质量和多样性受到限制. GAN使用随机向量作为生成器的输入,导致生成的裂缝图像在轮廓和尺寸上不稳定,缺乏人为控制和编辑的能力,生成图像的风格变化随机,难以实现数据均衡的目标. 相比之下,扩散模型通过逐步降噪生成图像,拥有更强的稳定性和细节还原能力. 尤其是稳定扩散模型(stable diffusion,SD),通过在潜在空间(latent space)中进行扩散采样,采用文本提示词引导模型生成图像,能够显著提高生成图像的质量,在多个应用领域(如服装设计[15 ] 、动漫设计[16 ] )有优异表现. 在使用SD进行裂缝图像生成任务时,尽管使用了大量详细的提示词,生成的裂缝图像仍无法达到预期效果,存在裂缝像素不平衡、裂缝图像角度与实际工程检测结果严重不符等问题. 本研究提出基于低秩自适应[17 ] (low-rank adaptation,LoRA)微调稳定扩散模型的裂缝图像数据集扩充方法. 通过在跨模态交叉注意力层中引入低秩更新,对裂缝的形态、尺度与纹理特征进行建模与适配,从而实现面向裂缝图像生成任务的参数高效微调. ...
基于AIGC技术的民族服饰设计研究: 以畲族为例
1
2025
... 尽管GAN在裂缝图像生成方面取得了较好的成果,但训练过程中的不稳定性以及模式崩塌问题,使得生成的图像质量和多样性受到限制. GAN使用随机向量作为生成器的输入,导致生成的裂缝图像在轮廓和尺寸上不稳定,缺乏人为控制和编辑的能力,生成图像的风格变化随机,难以实现数据均衡的目标. 相比之下,扩散模型通过逐步降噪生成图像,拥有更强的稳定性和细节还原能力. 尤其是稳定扩散模型(stable diffusion,SD),通过在潜在空间(latent space)中进行扩散采样,采用文本提示词引导模型生成图像,能够显著提高生成图像的质量,在多个应用领域(如服装设计[15 ] 、动漫设计[16 ] )有优异表现. 在使用SD进行裂缝图像生成任务时,尽管使用了大量详细的提示词,生成的裂缝图像仍无法达到预期效果,存在裂缝像素不平衡、裂缝图像角度与实际工程检测结果严重不符等问题. 本研究提出基于低秩自适应[17 ] (low-rank adaptation,LoRA)微调稳定扩散模型的裂缝图像数据集扩充方法. 通过在跨模态交叉注意力层中引入低秩更新,对裂缝的形态、尺度与纹理特征进行建模与适配,从而实现面向裂缝图像生成任务的参数高效微调. ...
AIGC技术赋能江苏动画产业研究与应用
1
2024
... 尽管GAN在裂缝图像生成方面取得了较好的成果,但训练过程中的不稳定性以及模式崩塌问题,使得生成的图像质量和多样性受到限制. GAN使用随机向量作为生成器的输入,导致生成的裂缝图像在轮廓和尺寸上不稳定,缺乏人为控制和编辑的能力,生成图像的风格变化随机,难以实现数据均衡的目标. 相比之下,扩散模型通过逐步降噪生成图像,拥有更强的稳定性和细节还原能力. 尤其是稳定扩散模型(stable diffusion,SD),通过在潜在空间(latent space)中进行扩散采样,采用文本提示词引导模型生成图像,能够显著提高生成图像的质量,在多个应用领域(如服装设计[15 ] 、动漫设计[16 ] )有优异表现. 在使用SD进行裂缝图像生成任务时,尽管使用了大量详细的提示词,生成的裂缝图像仍无法达到预期效果,存在裂缝像素不平衡、裂缝图像角度与实际工程检测结果严重不符等问题. 本研究提出基于低秩自适应[17 ] (low-rank adaptation,LoRA)微调稳定扩散模型的裂缝图像数据集扩充方法. 通过在跨模态交叉注意力层中引入低秩更新,对裂缝的形态、尺度与纹理特征进行建模与适配,从而实现面向裂缝图像生成任务的参数高效微调. ...
AIGC技术赋能江苏动画产业研究与应用
1
2024
... 尽管GAN在裂缝图像生成方面取得了较好的成果,但训练过程中的不稳定性以及模式崩塌问题,使得生成的图像质量和多样性受到限制. GAN使用随机向量作为生成器的输入,导致生成的裂缝图像在轮廓和尺寸上不稳定,缺乏人为控制和编辑的能力,生成图像的风格变化随机,难以实现数据均衡的目标. 相比之下,扩散模型通过逐步降噪生成图像,拥有更强的稳定性和细节还原能力. 尤其是稳定扩散模型(stable diffusion,SD),通过在潜在空间(latent space)中进行扩散采样,采用文本提示词引导模型生成图像,能够显著提高生成图像的质量,在多个应用领域(如服装设计[15 ] 、动漫设计[16 ] )有优异表现. 在使用SD进行裂缝图像生成任务时,尽管使用了大量详细的提示词,生成的裂缝图像仍无法达到预期效果,存在裂缝像素不平衡、裂缝图像角度与实际工程检测结果严重不符等问题. 本研究提出基于低秩自适应[17 ] (low-rank adaptation,LoRA)微调稳定扩散模型的裂缝图像数据集扩充方法. 通过在跨模态交叉注意力层中引入低秩更新,对裂缝的形态、尺度与纹理特征进行建模与适配,从而实现面向裂缝图像生成任务的参数高效微调. ...
1
... 尽管GAN在裂缝图像生成方面取得了较好的成果,但训练过程中的不稳定性以及模式崩塌问题,使得生成的图像质量和多样性受到限制. GAN使用随机向量作为生成器的输入,导致生成的裂缝图像在轮廓和尺寸上不稳定,缺乏人为控制和编辑的能力,生成图像的风格变化随机,难以实现数据均衡的目标. 相比之下,扩散模型通过逐步降噪生成图像,拥有更强的稳定性和细节还原能力. 尤其是稳定扩散模型(stable diffusion,SD),通过在潜在空间(latent space)中进行扩散采样,采用文本提示词引导模型生成图像,能够显著提高生成图像的质量,在多个应用领域(如服装设计[15 ] 、动漫设计[16 ] )有优异表现. 在使用SD进行裂缝图像生成任务时,尽管使用了大量详细的提示词,生成的裂缝图像仍无法达到预期效果,存在裂缝像素不平衡、裂缝图像角度与实际工程检测结果严重不符等问题. 本研究提出基于低秩自适应[17 ] (low-rank adaptation,LoRA)微调稳定扩散模型的裂缝图像数据集扩充方法. 通过在跨模态交叉注意力层中引入低秩更新,对裂缝的形态、尺度与纹理特征进行建模与适配,从而实现面向裂缝图像生成任务的参数高效微调. ...
1
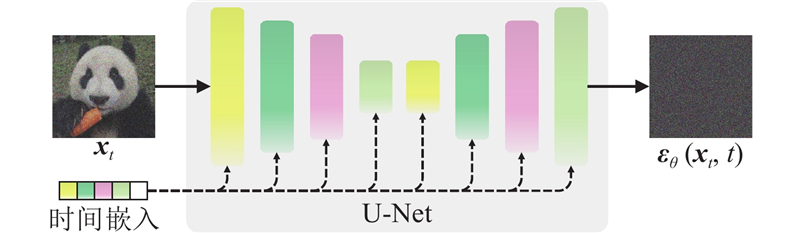
... 扩散模型是在图像生成任务中表现突出的生成模型,其代表性结构为去噪扩散概率模型[18 ] (denoising diffusion probabilistic models,DDPM). DDPM通过模拟马尔可夫过程,将复杂的图像生成任务转化为逐步加噪与去噪的过程,实现从纯高斯噪声中重构出高质量图像的目的. 与传统的GAN相比,DDPM在训练稳定性、生成样本的多样性以及保真度方面表现更优. 如图1 所示,DDPM主要包括2个阶段:正向扩散过程和反向扩散过程. 在正向过程中,模型从原始图像$ {\boldsymbol{x}}_{0} $ $ \boldsymbol{\varepsilon }\sim {N}(0,I) $ $ {\boldsymbol{x}}_{t} $ $ t $ $ {\boldsymbol{x}}_{0} $ $ {\boldsymbol{x}}_{t} $
1
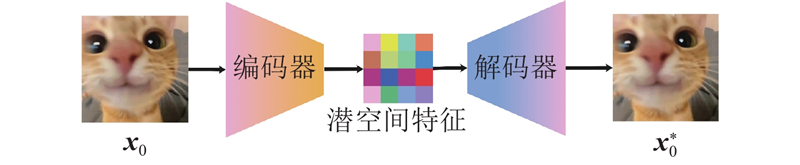
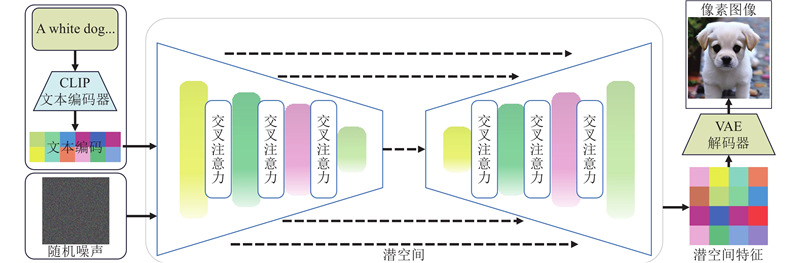
... DDPM直接在高维像素空间中进行扩散和去噪操作,导致计算成本高、采样速度慢,限制了其在实际应用中的推广. DDPM属于无条件生成模型,缺乏对外部信息(如文本、标签)的有效建模能力. SD通过引入潜在扩散模型[19 ] (latent diffusion model, LDM),使扩散过程在潜在空间中进行. LDM的核心思想是通过预训练的VAE将原始图像压缩至低维潜在表示(latent representation),并仅在该潜在空间中执行扩散与去噪过程,如图3 所示. 此外,稳定扩散模型结合对比语言-图像预训练模型(contrastive language–image pre-training,CLIP)获取文本嵌入向量,并将文本嵌入向量作为条件输入引入扩散过程中的U-Net模型,实现对图像生成过程的精细控制,如图4 所示. ...
基于时空关联和异构图卷积的车道级流量预测
1
2025
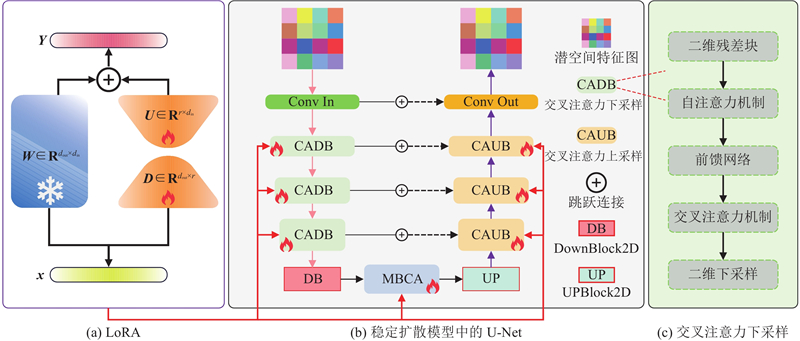
... LoRA是高效的大模型微调技术,能够在保持预训练模型主干结构和参数不变的前提下,通过引入少量可训练参数,实现对模型生成能力的定向优化. LoRA的核心思想是使用低秩矩阵分解对模型权重进行增量式调整. 如图6 所示,在微调过程中,原始权重矩阵$ \boldsymbol{W}\in {\mathbf{R}}^{{{d}_{\text{out}}}\times {{d}_{\text{in}}}} $ $ \boldsymbol{A}=\boldsymbol{U}\times \boldsymbol{D} $ $ {\boldsymbol{W}}^{*}=\boldsymbol{W}+\boldsymbol{U}\times \boldsymbol{D} $ $ \boldsymbol{Y}={\boldsymbol{W}}^{*}\times \boldsymbol{x} $ . $ \boldsymbol{U} $ $ \boldsymbol{D} $ [20 ] . LoRA通过对注意力模块中的关键映射矩阵$ {\boldsymbol{W}}_{\boldsymbol{Q}},{\boldsymbol{W}}_{\boldsymbol{K}},{\boldsymbol{W}}_{\boldsymbol{V}},{\boldsymbol{W}}_{\boldsymbol{O}} $
基于时空关联和异构图卷积的车道级流量预测
1
2025
... LoRA是高效的大模型微调技术,能够在保持预训练模型主干结构和参数不变的前提下,通过引入少量可训练参数,实现对模型生成能力的定向优化. LoRA的核心思想是使用低秩矩阵分解对模型权重进行增量式调整. 如图6 所示,在微调过程中,原始权重矩阵$ \boldsymbol{W}\in {\mathbf{R}}^{{{d}_{\text{out}}}\times {{d}_{\text{in}}}} $ $ \boldsymbol{A}=\boldsymbol{U}\times \boldsymbol{D} $ $ {\boldsymbol{W}}^{*}=\boldsymbol{W}+\boldsymbol{U}\times \boldsymbol{D} $ $ \boldsymbol{Y}={\boldsymbol{W}}^{*}\times \boldsymbol{x} $ . $ \boldsymbol{U} $ $ \boldsymbol{D} $ [20 ] . LoRA通过对注意力模块中的关键映射矩阵$ {\boldsymbol{W}}_{\boldsymbol{Q}},{\boldsymbol{W}}_{\boldsymbol{K}},{\boldsymbol{W}}_{\boldsymbol{V}},{\boldsymbol{W}}_{\boldsymbol{O}} $
1
... 为了全面评估不同生成模型在裂缝图像质量方面的表现,从主观视觉感知与客观定量指标2个层面对生成结果进行对比分析. 实验共选取5种裂缝图像生成方法进行比较:DCGAN[21 ] 、WGAN-GP[22 ] 、StyleGAN[23 ] 、微调前的SD以及本研究提出的基于LoRA微调的SD. 所有模型均采用与微调SD相同的裂缝数据集作为训练集,每种模型均生成500张512×512像素大小的裂缝图像用于后续分析. ...
1
... 为了全面评估不同生成模型在裂缝图像质量方面的表现,从主观视觉感知与客观定量指标2个层面对生成结果进行对比分析. 实验共选取5种裂缝图像生成方法进行比较:DCGAN[21 ] 、WGAN-GP[22 ] 、StyleGAN[23 ] 、微调前的SD以及本研究提出的基于LoRA微调的SD. 所有模型均采用与微调SD相同的裂缝数据集作为训练集,每种模型均生成500张512×512像素大小的裂缝图像用于后续分析. ...
1
... 为了全面评估不同生成模型在裂缝图像质量方面的表现,从主观视觉感知与客观定量指标2个层面对生成结果进行对比分析. 实验共选取5种裂缝图像生成方法进行比较:DCGAN[21 ] 、WGAN-GP[22 ] 、StyleGAN[23 ] 、微调前的SD以及本研究提出的基于LoRA微调的SD. 所有模型均采用与微调SD相同的裂缝数据集作为训练集,每种模型均生成500张512×512像素大小的裂缝图像用于后续分析. ...
1
... 为了评估LoRA微调后SD生成的裂缝图像对分割模型性能的影响,使用3种不同架构的分割模型进行测试:U-Net [24 ] (CNN架构)、TransUNet[25 ] (Transformer架构)和MobileVIT[26 ] (CNN-Transformer混合架构). ...
1
... 为了评估LoRA微调后SD生成的裂缝图像对分割模型性能的影响,使用3种不同架构的分割模型进行测试:U-Net [24 ] (CNN架构)、TransUNet[25 ] (Transformer架构)和MobileVIT[26 ] (CNN-Transformer混合架构). ...
1
... 为了评估LoRA微调后SD生成的裂缝图像对分割模型性能的影响,使用3种不同架构的分割模型进行测试:U-Net [24 ] (CNN架构)、TransUNet[25 ] (Transformer架构)和MobileVIT[26 ] (CNN-Transformer混合架构). ...
DeepCrack: a deep hierarchical feature learning architecture for crack segmentation
1
2019
... 数据集DeepCrack[27 ] 包含300张训练图像和237张测试图像,涵盖多尺度裂缝特征与复杂背景信息. 训练集占总数据量的约55%,样本规模有限. 考虑到裂缝分割任务对像素级标注的强依赖及其高昂的人工成本,本研究在原有300张训练样本的基础上,利用LoRA微调后的SD生成新的120张高质量的裂缝图像,使训练集规模提升约40%. 这些生成样本在裂缝形态、宽度及纹理分布方面与真实样本高度一致,有效提升了数据集的结构多样性与特征丰富度,为模型训练提供了更充分的结构信息. 为了进一步对比不同数据增强策略的效果,采用随机旋转、缩放、仿射变换等传统几何增强方式对DeepCrack数据集进行同等规模的扩充. 最终的数据集分布如表2 所示,其中N S 为样本数量,P T 为训练集样本占比,N ST 为训练集样本数量,DC表示原始DeepCrack数据集,ADU表示传统数据增强方法,AIGC表示基于LoRA微调SD生成的增强数据. ...








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}