

神经网络发展迅速,已广泛应用于计算机视觉[1]和自然语音处理[2]领域. 偏微分方程(partial differential equation,PDE)源于对物理现象的建模,对现代科学与工程技术至关重要. 传统的数值方法,如有限差分法[3]、有限元法[4]和有限体积法[5]依赖网络细化,计算成本高. 深度学习技术的解拟合能力优秀,被广泛用于解决PDEs中. Raissi等[6]提出物理信息神经网络(physics-informed neural networks, PINN)将数据条件(初始和边界条件)和PDE本身嵌入神经网络的损失函数中,通过训练优化网络参数. PINN是简化、灵活且高精度的PDE求解方法,具有良好的泛化能力.
PINN虽被广泛应用于由PDE控制的各种系统中,但难以解具有高梯度特征或不适定计算域的PDE[7]. 现有改进方法分为4类:1)神经网络结构的优化设计、2)区域分解、3)损失平衡、4)自适应采样. 关于类别1),Ramabathiran等[8]基于距离的编码层,提出稀疏的、基于物理的、部分可解释的神经网络SPINN,增强了神经网络求解偏微分方程的可解释性. 关于类别2),Jagtap等[9]提出XPINNs框架,通过在计算域内进行空间-时间域分解,使各区域由单独的神经网络拟合,提高并行化能力并降低训练成本. 针对高梯度和多尺度解问题,Dolean等[10]提出基于多级区域分解的物理信息神经网络框架结构,通过促进子域间的全局通信提高有限基物理神经网络的精度. 关于类别3),Liu等[11]为了解决数据稀疏问题,开发出双二聚体方法,采用最小-最大架构,调整梯度下降上升步骤,通过极端特征值和特征向量信息调整不同损失函数的权重,寻找高阶鞍点,提高神经网络的训练效率和性能. 关于类别4),Tang等[12]创建模型KRnet,将残差视为概率密度函数,最小化KL散度近似;使用训练好的KRnet生成集中在残差较大区域内的新样本点,以此提高解的准确性. Liu等[13]提出2种新的自适应采样算法(EI-RAR和EI-Grad). EI-RAR通过引入新的期望改进函数来替代传统的残差作为误差指示函数,不仅关注解域内部的样本点,还特别关注边界上的样本点;EI-Grad在EI-RAR基础上引入残差梯度信息作为样本点选择标准,能够针对性地处理具有尖锐解的PDEs.
Jacot等[14]提出神经正切核(neural tangent kernel, NTK)理论,证明以足够小的学习率训练无限宽的神经网络可以收敛到高斯过程,提供了深度学习训练动态的理论依据. PINNs一般采用多隐藏层全连接神经网络[15],Bai等[16]就处理非线性偏微分方程时可能会遇到的高梯度特征和不适定计算域问题,提出新的物理信息径向基网络(physics informed radial basis network, PIRBN);使用径向基函数(radial basis function, RBF)作为激活函数,采用单隐藏层结构代替传统多层前馈神经网络,令网络具有局部近似特性;通过NTK理论证明,在无限宽度和极小学习率下,PIRBN的训练可收敛到高斯过程,且NTK矩阵在训练中保持近似对角化. 然而PIRBN仅有一层隐藏层且隐藏层宽度大、迭代次数多、训练时间长. 本研究提出基于残差/梯度的高斯分布自适应采样方法(radial basis network based on residual/gradient Gaussian adaptive sampling, G-PIRBN),对PIRBN进行改进,有效求解高梯度特性PDE. 针对高梯度问题,结合梯度特征和残差信息定义采样标准;借鉴连续学习概念和自适应有限元方法,采用高斯混合分布进行区域细化,增加高质量采样点数量,减少模型迭代次数,提高网络训练效率. 相较于传统的自适应采样方法,G-PIRBN建立双准则驱动机制:从残差和梯度入手确定基础自适应采样点位置;令残差和梯度较大的点作为高斯均值并利用这些点的残差梯度分别构造协方差;计算各点高斯分布区域并获得混合高斯采样点;将附加点加入训练集中进行下一轮训练. 本研究将以PINNs与PIRBN为基准模型,在涵盖线性和非线性的3类典型微分方程(包括非线性弹簧方程、波动方程及扩散方程)上进行对比试验,验证G-PIRBN的稳定性、效率和精度.
1. 经典神经网络
1.1. 物理信息神经网络
物理信息神经网络使用诸如深度神经网络的结构对一般微分方程计算近似解
其中
通过定义残差,将式(1)涉及的微分方程的解简化为优化问题,其中初始和边界条件被视为约束. 训练
式中:
算法1 物理信息神经网络
1. 从
2. 设置模型框架(层数、神经元数、激活函数和输入输出维度). 指定优化器权重参数
3. 初始化模型参数
根据均匀分布从N个配置点中随机选择一部分点用作训练.
4. 采取下降步骤
5. 结束循环.
1.2. 物理信息径向基网络
径向基网络是Broomhead等[17]提出的单层神经网络. 在原始径向基网络中,RBF用作激活函数. RBF的取值仅由从给定中心
在径向基网络中常用的RBF是高斯函数:
其中
式中:
2. 基于残差/梯度高斯自适应采样的径向基网络
2.1. 重采样区间定位
PIRBN的RBF框架复杂,在拟合偏微分方程时相较于传统的PINN需要的迭代次数更多并且收敛缓慢. 本研究提出基于残差/梯度高斯分布的自适应采样方法,不仅能够加速模型的拟合速度,还在一定程度上提高了模型在高梯度区域的拟合精度. 现有神经网络的大部分自适应采样方法根据网络迭代过程中的残差进行样点筛选. 网络每个样点的损失函数为
式中:
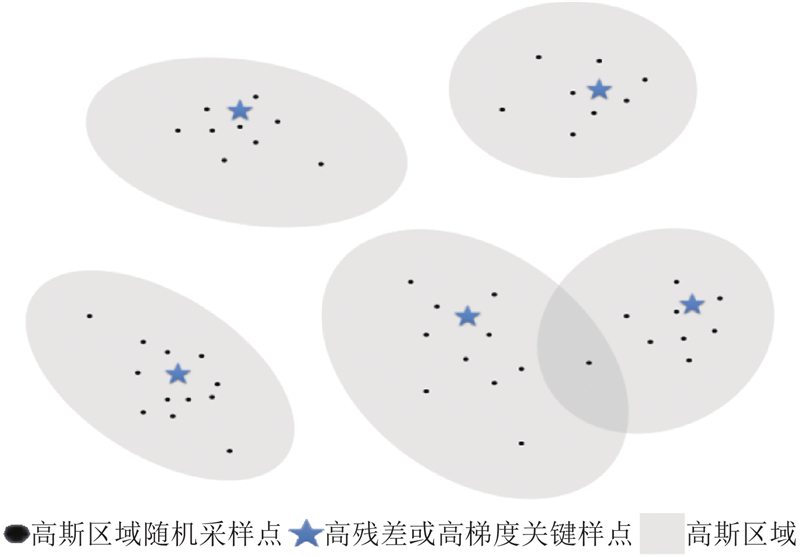
如图1所示,围绕每个关键样点会生成一个椭圆(即高斯区域),区域内的点是在该高斯区域内随机采样得到的补充点. 重采样的整体逻辑是围绕信息密度较高的关键样点,通过划定高斯区域来补充采样,以提升对应区域的采样覆盖度. 定义高梯度区域为函数变化速率显著高于平均水平的区间,由倒数绝对值(或梯度模量)的大小判定. 选取排在前20%的极大值作为阈值,所有超过该阈值的区域标记为高梯度区域,后续的样本点采取均在该区域内进行. 通过计算PIRBN中所有样点的残差和梯度的绝对值,分别选出2组中最高部分的点. 基于自适应有限元方法的核心思想,通过采样点的均值和协方差获得高斯分布并在分布区域内进行二次采样.
图 1
2.2. 高斯分布采样
静态预采样无法做到精确定位,为此提出采用一般背景分布
其中
为了更好地得到
将
其中
式(15)只有在
通过高残差和高梯度2个方向进行理论论证,证明背景密度函数存在合理性,以下为推导过程. 在由残差得到的高风险点、式(13)和
事实上,
以由梯度得到的高风险点、式(13)和
针对高风险区域,当样点处梯度越高,依据高斯分布获得的新采样点越紧凑、高风险点周围重采样点越密集. 在多峰和高维的情况下,通过对
式中:
其中
图 2
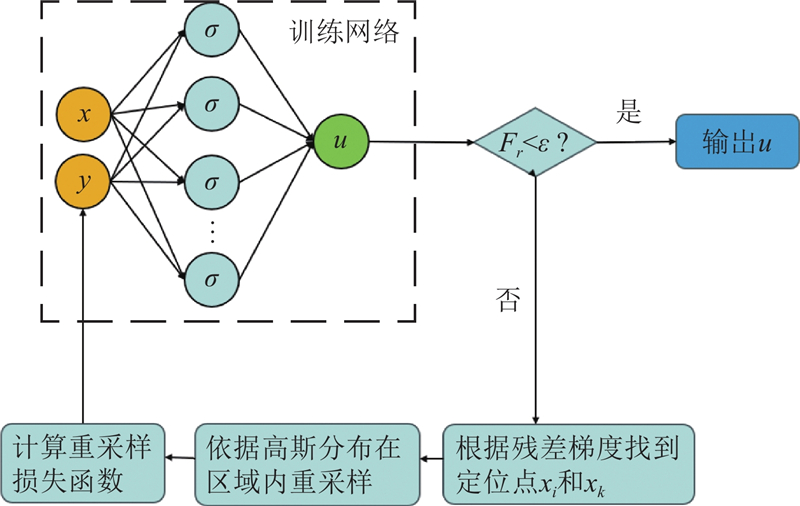
图 2 基于残差/梯度高斯自适应采样的径向基网络框架图
Fig.2 Framework diagram of radial basis network based on residual/gradient Gaussian adaptive sampling
算法2 基于残差/梯度高斯自适应采样的径向基网络
1. 确定网络结构,包括PIRBN的最大迭代次数
2. 对每个输入点进行RBF激活并加权得到函数的预测值,再通过自动微分
3. 当网络迭代次数为
4. 计算
5. 从每个高斯区域内随机获得
6. 通过设置超参数
7. 重复步骤2~6直到PIRBN迭代次数达到
3. 拟合性能验证实验
通过3个高梯度偏微分方程来展示G-PIRBN的模型拟合性能,设立其他网络作为对照组,比较不同网络的训练速度和精度. 实验在采用Intel(R) Core(TM) i7-9750H CPU @ 2.60GHz的Windows11系统上进行,神经网络基于TensorFlow库建立,选择Adam优化器作为训练算法.
3.1. 非线性弹簧方程
非线性弹簧方程的初始、边界条件式为
其中
由于非线性弹簧方程具有超长计算域、大预测值和高梯度的特征,PINN在拟合这类方程中面临严峻的数值稳定性和收敛性挑战. Bai等[16]将神经网络的神经元变更为RBF,应用具有1 021个神经元的PIRBN,来解决模型在拟合过程中可能会遇到的高梯度区域拟合精度较低的问题. RBF的复杂性和隐藏层单一导致PIRBN训练速度缓慢,采用残差/梯度高斯分布的自适应采样来解决这个问题,残差和梯度分别获得20个重采样区域,每个高斯区域随机获得25个新采样点.
如图3所示为PINN、PIRBN、EI-Grad和G-PIRBN在相同迭代次数条件下分别求解非线性弹簧方程的结果及逐点绝对误差
图 3
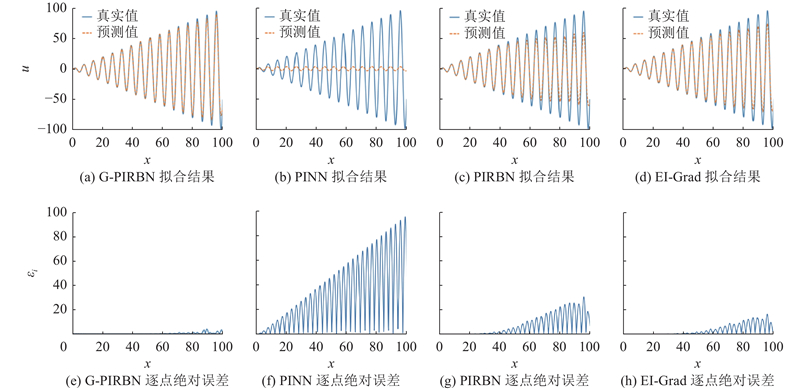
图 3 不同网络的非线性弹簧方程拟合结果和逐点绝对误差
Fig.3 Fitting results and point-wise absolute errors of different networks for nonlinear spring equation
表 1 不同网络的非线性弹簧方程重采样点数量和均方误差
Tab.1
| Np | MSE | ||
| PIRBN | EI-Grad | G-PIRBN | |
| 5×10 | 8.0×10−4 | 2.4×10−5 | 9.6×10−6 |
| 5×25 | 4.5×10−4 | 3.2×10−5 | 2.3×10−6 |
| 20×10 | 1.7×10−4 | 1.1×10−5 | 8.1×10−6 |
| 20×25 | 3.0×10−5 | 7.3×10−7 | 1.5×10−7 |
3.2. 波动方程
将G-PIRBN的应用扩展到二维问题上,考虑波动方程和相应的边界条件:
解析解为
利用具有61×61个的神经元的单层G-PIRBN来应对高梯度特征带来的挑战性. 神经元的中心均匀分布在计算域
图 4
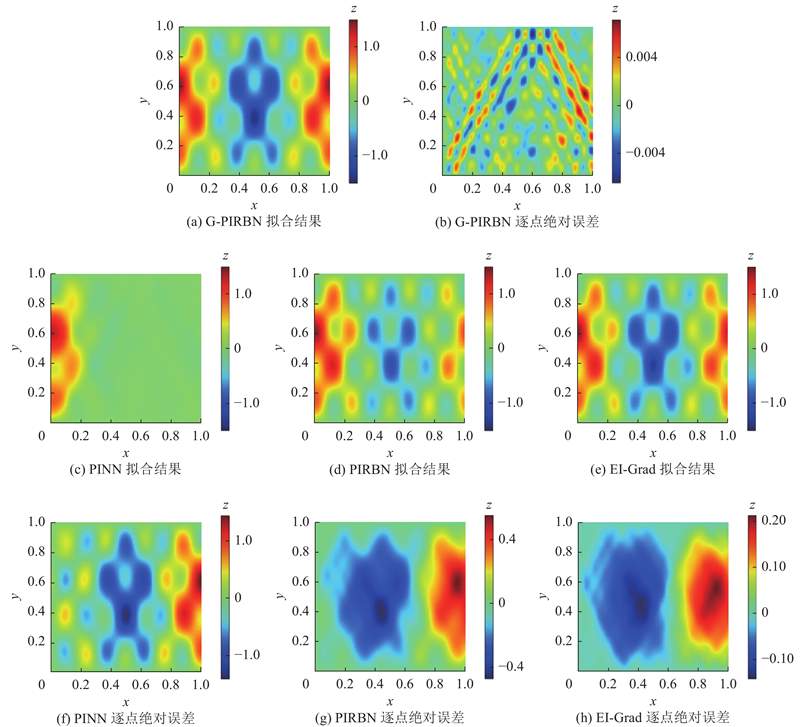
图 4 不同网络的波动方程拟合结果和逐点绝对误差
Fig.4 Fitting results and point-wise absolute errors of different networks for wave equation
表 2 不同网络的波动方程重采样点数量和均方误差
Tab.2
| Np | MSE | ||
| PIRBN | EI-Grad | G-PIRBN | |
| 5×10 | 1.8×10−4 | 1.9×10−5 | 2.9×10−6 |
| 5×25 | 8.8×10−5 | 5.2×10−6 | 8.2×10−7 |
| 20×10 | 9.8×10−6 | 9.8×10−7 | 4.4×10−7 |
| 20×25 | 7.5×10−6 | 2.7×10−7 | 1.1×10−8 |
3.3. 扩散方程
其中
利用61×61个RBF神经元的单层G-PIRBN来应对高梯度特征带来的挑战性. 中心的神经元均匀分布在域
图 5
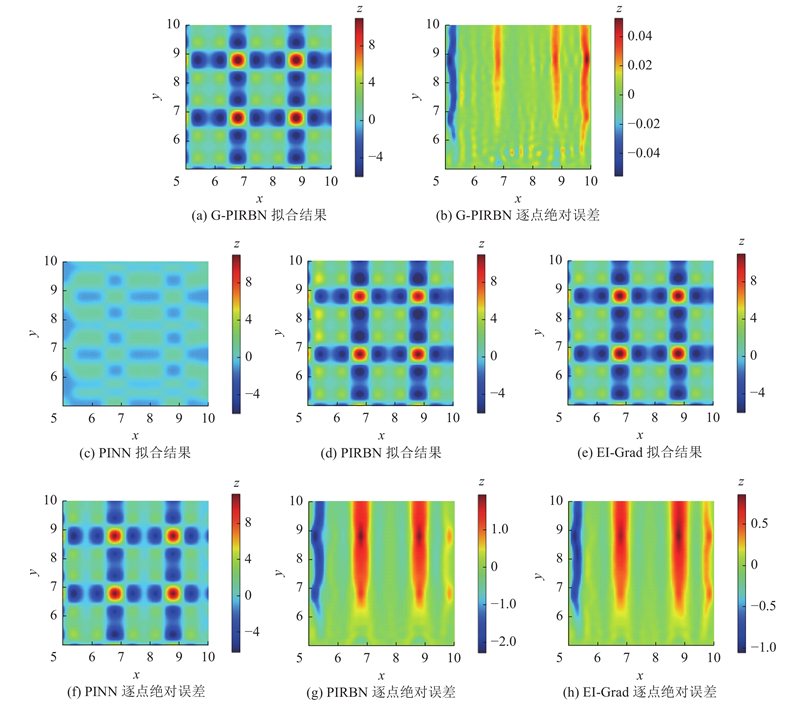
图 5 不同网络的扩散方程拟合结果和逐点绝对误差
Fig.5 Fitting results and point-wise absolute errors of different networks for diffusion equation
表 3 不同网络的扩散方程重采样点数量和均方误差
Tab.3
| Np | MSE | |||
| PIRBN | DAS-PIRBN | EI-Grad | G-PIRBN | |
| 5×10 | 5.7×10−4 | 5.3×10−5 | 1.8×10−5 | 2.3×10−6 |
| 5×25 | 4.3×10−5 | 2.4×10−5 | 4.8×10−6 | 6.2×10−7 |
| 20×10 | 3.2×10−5 | 7.2×10−6 | 1.2×10−6 | 4.2×10−7 |
| 20×25 | 6.6×10−6 | 8.6×10−7 | 7.5×10−8 | 9.3×10−9 |
表 4 不同物理信息径向基网络在不同径向基函数神经元数量下的方程拟合均方误差
Tab.4
| NRBF | MSE | ||
| PIRBN | DAS-PIRBN | G-PIRBN | |
| 25×30 | 8.3×10−2 | 8.2×10−3 | 1.6×10−3 |
| 25×55 | 6.3×10−4 | 2.4×10−4 | 3.8×10−5 |
| 50×30 | 9.2×10−5 | 4.6×10−6 | 8.8×10−7 |
| 50×55 | 6.6×10−6 | 8.6×10−7 | 9.3×10−9 |
表 5 固定迭代次数下不同网络的方程求解平均耗时
Tab.5
| 方程名称 | k | tt/s | |||
| PINN | PIRBN | EI-Grad | G-PIRBN | ||
| 非线性弹簧方程 | 357 | 514 | 602 | 323 | |
| 波动方程 | 435 | 680 | 703 | 422 | |
| 扩展方程 | 302 | 464 | 539 | 285 | |
4. 结 语
本研究提出基于残差/梯度高斯分布的自适应采样方法,并使用该方法改进物理信息径向基网络,得到可以有效地拟合具有高梯度特性偏微分方程的新型神经网络G-PIRBN. 通过计算样点的残差和梯度绝对值自主找出奇异区域,在区域内进行高斯分布式采样以加速神经网络的收敛速度并提高网络在高梯度区域的拟合精度. 与现有的自适应采样方法相比,所提方法能够根据不同的高残差或高梯度点的特性制定合适的采样密度,用更少的训练数据和计算成本获得更低的误差结果,提高网络拟合效率. 模型拟合实验结果表明,与PINN、PIRBN和EI-Grad相比,G-PIRBN在相同的迭代次数下能够在更少的时间内有效表现出方程的高梯度特征. G-PIRBN在泛化性、采样动态调节能力上还有提升空间,为了更快更好地建立模型,计划引入迁移学习,借助训练好的先验知识,进一步加快模型收敛速度,提升训练稳定性.
参考文献
Deep learning for computer vision: a brief review
[J].DOI:10.1016/bs.host.2023.01.003 [本文引用: 1]
Neural network-augmented differentiable finite element method for boundary value problems
[J].DOI:10.1016/j.ijmecsci.2024.109783 [本文引用: 1]
Numerical analyses of liquid slosh by finite volume and lattice Boltzmann methods
[J].DOI:10.1016/j.ast.2021.106681 [本文引用: 1]
Physics-informed neural networks: a deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations
[J].DOI:10.1016/j.jcp.2018.10.045 [本文引用: 1]
Physics-informed neural networks for high-frequency and multi-scale problems using transfer learning
[J].DOI:10.3390/app14083204 [本文引用: 1]
SPINN: sparse, physics-based, and partially interpretable neural networks for PDEs
[J].DOI:10.1016/j.jcp.2021.110600 [本文引用: 1]
Extended physics-informed neural networks (XPINNs): a generalized space-time domain decomposition based deep learning framework for nonlinear partial differential equations
[J].DOI:10.4208/cicp.oa-2020-0164 [本文引用: 1]
Multilevel domain decomposition-based architectures for physics-informed neural networks
[J].DOI:10.1016/j.cma.2024.117116 [本文引用: 1]
A Dual-Dimer method for training physics-constrained neural networks with minimax architecture
[J].DOI:10.1016/j.neunet.2020.12.028 [本文引用: 1]
Deep density estimation via invertible block-triangular mapping
[J].DOI:10.1016/j.taml.2020.01.023 [本文引用: 1]
An adaptive sampling method based on expected improvement function and residual gradient in PINNs
[J].DOI:10.1109/ACCESS.2024.3422224 [本文引用: 1]
Structure and performance of fully connected neural networks: emerging complex network properties
[J].DOI:10.1016/j.physa.2023.128585 [本文引用: 1]
Physics-informed radial basis network (PIRBN): a local approximating neural network for solving nonlinear partial differential equations
[J].DOI:10.1016/j.cma.2023.116290 [本文引用: 2]
Multivariable functional interpolation and adaptive networks
[J].
On the selection of a better radial basis function and its shape parameter in interpolation problems
[J].DOI:10.1016/j.amc.2022.127713 [本文引用: 1]
A multi-step probability density prediction model based on Gaussian approximation of quantiles for offshore wind power
[J].DOI:10.1016/j.renene.2022.11.111 [本文引用: 1]
Bayesian updating of model parameters using adaptive Gaussian process regression and particle filter
[J].DOI:10.1016/j.strusafe.2023.102328 [本文引用: 1]
SPHinXsys: an open-source multi-physics and multi-resolution library based on smoothed particle hydrodynamics
[J].DOI:10.1016/j.cpc.2021.108066 [本文引用: 1]
A physics-informed neural network-based surrogate framework to predict moisture concentration and shrinkage of a plant cell during drying
[J].DOI:10.1016/j.jfoodeng.2022.111137 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}