

城市环境复杂,建筑物在大小、形状和外观上存在很大差异,给建筑物提取带来了挑战. 基于卷积神经网络(CNN)的模型[5-6]能够从数据中直接学习高层次语义特征,适用于复杂的图像分析任务. 基于CNN的模型有很多,Ronneberger等[7]提出U-Net,采用编码器-解码器结构,有效地捕获了局部和全局特征. Li等[8]提出多注意力网络(multi-attention-network, MANet),通过引入双注意力机制加强了网络对关键特征的捕获能力,同时多尺度特征融合提升了语义分割的精度和鲁棒性. CNN模型存在全局信息捕捉不足和感受野有限的问题. Transformer模型[9]的出现推动了研究的进展. Transformer模型最初用于自然语言处理任务,因其捕捉长距离依赖关系的能力而被应用于计算机视觉领域. Dosovitskiy等[10]提出Vision Transformer, 将Transformer应用于图像任务. 该方法将图像划分为固定大小的图像块,对每个图像块进行编码和自注意力计算. Liu等[11]提出Swin Transformer,采用层次化设计和移动窗口机制,保留了局部特征提取的能力,在全局上下文建模上表现良好. Cao等[12]提出的Swin-Unet结合Swin Transformer和U-Net的架构,特别适用于高分辨率遥感图像的建筑物提取任务. 这些纯Transformer模型全局建模能力出色,却存在计算资源需求大、捕捉局部细节能力不足的问题. 为了弥补纯CNN和Transformer模型在建筑物提取任务中的不足,研究人员提出了多种结合CNN和Transformer的混合模型[13-21],以充分利用CNN的局部特征提取能力和Transformer的全局上下文建模能力. Wang等[22]提出的密集连接型Swin变换器(densely connected Swin transformer, DCSwin)采用动态跨尺度注意力机制,有效地在不同尺度之间建立关联,既能捕获局部细节信息,又能关注全局上下文关系. Wang等[23]提出的BuildFormer采用双路径结构,一条全局上下文路径利用窗口式线性多头自注意力机制高效捕捉全局语义信息,另一条空间细节路径通过堆叠卷积层保留高分辨率的空间细节,该模型的分割效果良好. 上述方法[8,12,22-23]侧重于全局语义信息或局部细节信息的提取,缺乏对两者的有效协调与融合,在建筑物提取任务中易导致漏检或误检问题.
本研究从充分学习全局上下文和局部细节特征出发,解决建筑物提取中存在的漏检、误检问题,基于BuildFormer模型[23],引入VGG13[24]作为局部特征分支骨干网络以提取丰富的局部特征信息,设计多尺度全局局部特征融合方法(multi-scale global-local feature fusion method, MGLFF),构建包含局部细节和全局上下文的多尺度特征表示. 受多分支特征聚合方法[25]启发,本研究设计双分支特征融合模块(dual-branch feature fusion module, DFM),实现双分支互相促进特征提取. 此外,本研究将通道优先卷积注意力机制(channel prior convolutional attention mechanism, CPCA)[26]引入DFM,使网络模型聚焦于感兴趣的区域,抑制无关和噪声信息的干扰.
1. 网络结构介绍
1.1. 双分支特征融合与相互增强网络
双分支特征融合与相互增强网络(dual-branch feature fusion and mutual enhancement network, DFFME-Net)采用基于编-解码器的BuildFormer作为网络架构的基础. 如图1所示,在编码器部分,设计2条并行的特征提取分支:一条专注于局部特征提取,另一条负责全局特征捕获. 局部特征提取分支采用对内部卷积层通道数微调后的VGG13骨干网络,全局特征提取分支沿用基准模型BuildFormer的设计. 为了促进特征分支间的信息交互,将2条分支对应阶段的特征图输入至相应的DFM. DFM将来自2条分支的特征图融合,并将融合后的特征图加到原始分支上,实现全局和局部分支之间的特征交互,彼此促进提取. DFM引入的CPCA令网络更加注意含有建筑物的区域. 在每个阶段的最后,全局和局部特征图通过相加的方式实现融合,并经过1×1卷积层进行通道维度统一,调整为384个通道. 这些特征图以跳跃连接的方式,作为解码器对应层级的输入. 在解码端,采用自底向上的方式,下层的特征图先经过上采样处理,随后与来自编码阶段上一层的特征图进行融合,生成新的特征图. 这一过程逐层向上进行,直至所有层级特征图均完成融合. 将这些特征图经过数量不同的卷积层和上采样操作,使它们尺寸相同,然后以相加的方式进行特征融合,再进行后续处理,以生成预测结果.
图 1
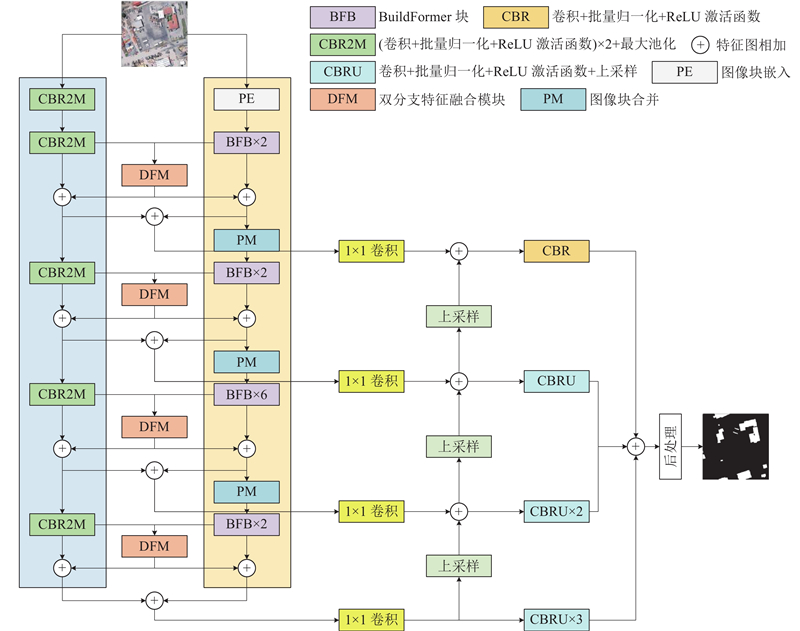
图 1 双分支特征融合与相互增强网络
Fig.1 Dual-branch feature fusion and mutual enhancement network
1.2. 多尺度全局局部特征融合方法
在建筑物提取任务中,局部细节和全局上下文信息对于准确识别建筑物至关重要. BuildFormer原本的局部特征提取分支受限于深度与表达能力,难以全面捕捉建筑物复杂的局部特征. 鉴于全局语义信息由另一条分支负责提取,本研究设计的局部分支聚焦局部特征的精细建模. 为此,在多种主流网络结构中进行对比选择,最终采用结构更深、卷积核更小的VGG骨干网络结构作为局部特征提取分支,其中小卷积核相比于大卷积核在空间感受野更小的同时,具备更强的局部信息建模能力,更适用于细节特征(如建筑物轮廓、边缘)的提取. 为了充分提取局部特征信息,在多种VGG网络结构中选择VGG13,微调卷积层的通道数,将微调后的网络作为DFFME-Net的局部特征提取分支,以增强模型对建筑物细节信息的感知能力. 分阶段将来自2条分支的特征图进行融合,得到多尺度的含有局部精细结构和全局语义信息的特征图. VGG13骨干网络分为5个阶段,每个阶段都是由2个3×3卷积层和1个下采样比例因子为2的最大池化层组成,依次产出5个不同分辨率大小的特征图:H/2×W/2、H/4×W/4、H/8×W/8、H/16×W/16和H/32×W/32,H、W分别为特征图的高和宽. VGG13原本每个模块内的卷积层通道数分别为64、128、256、512和512,为了与全局特征提取分支每个阶段得到的特征图通道数对应,将通道数分别调整为48、96、192、384和768. 全局特征提取分支分为4个阶段,第1个阶段由图像块嵌入和BuildFormer块组成,其他3个阶段由图像块合并和BuildFormer块组成,每个阶段的BuildFormer块个数分别为2、2、6和2个. 每个阶段产出的特征图的分辨率分别是H/4×W/4、H/8×W/8、H/16×W/16和H/32×W/32,产出的特征图的通道数分别为96、192、384和768. 与基准模型仅在最后阶段融合特征的方法不同,本研究将局部特征提取分支的后4个阶段和全局特征提取分支的4个阶段对应. 对应阶段产出的特征图的大小和通道数相同. 将对应阶段的特征图采用相加的方式进行融合. 这种融合方法有助于模型在处理复杂场景时,更好地平衡细节和全局结构,提高建筑物提取的准确性. 将融合后的特征图通过跳跃连接的方式分别传递至对应层次的解码端部分.
1.3. 双分支特征融合模块
在建筑物提取任务中,要求网络能够准确地区分建筑物与背景,同时捕捉建筑物的精细边界和形状. 为了实现这一目标,一些网络模型设计2条分支,分别用来提取局部细节和全局上下文信息. 这些网络的特征提取分支之间往往互相独立、互不干涉,这种设计难以平衡模型对局部与全局信息的捕捉,导致在复杂场景下建筑物提取的精度和鲁棒性受限. 设计DFM,实现将局部特征和全局特征充分的融合,再将融合后的特征图加回到2个分支,实现2条分支间的特征信息交互、相互促进,共同提升特征提取的效果.
DFM结构如图2所示. 将双分支对应的第
图 2
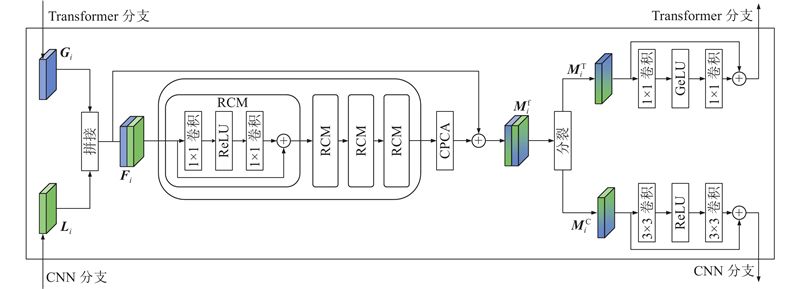
在拼接后,使用映射函数
RCM整体是残差连接的结构,主分支由1×1的卷积、ReLU激活函数和1×1的卷积串联组成:
式中:
为了改善梯度流,使网络更容易训练和优化,设计残差连接结构,与模块最开始拼接了双分支信息的特征
融合后的特征
这2个特征会被加回到相对应的分支上,以完成特征信息在双分支之间的交互:
DFM融合CNN分支提取的局部特征(如边缘和纹理)与Transformer分支提取的全局特征(如长距离依赖和上下文信息),实现特征的互补与双向增强. 这种融合不仅提升了特征的表达能力,还通过将融合后的特征反馈到各自分支,增强了分支的适应性和学习能力. DFM提升了模型对复杂建筑物轮廓的捕捉能力,也提升了模型在复杂场景下的鲁棒性和泛化能力.
为了增强网络对有用特征的聚焦能力,提高建筑物提取的效果,在DFM中引入CPCA. CPCA采用顺序结构,先执行通道注意力,再进行空间注意力. 这种设计使得注意力权重能够在通道和空间维度上动态调整. 如图3所示,CPCA对输入特征图
图 3
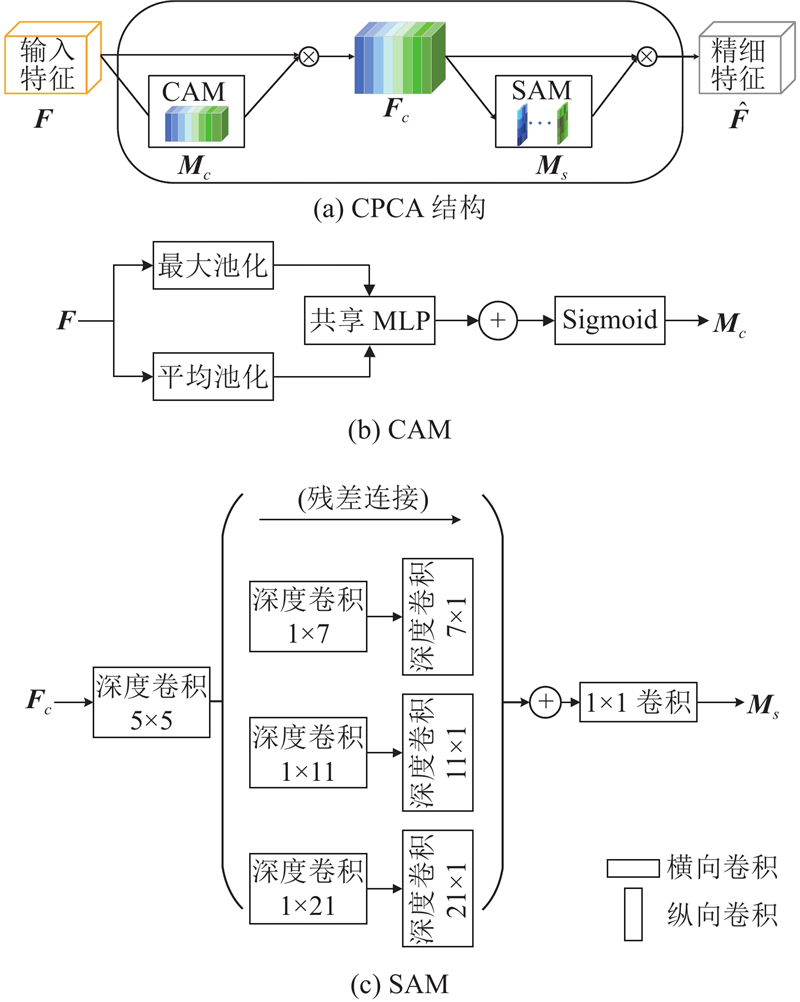
式中:
式中:
式中:
CPCA机制能够捕捉特征图之间的依赖关系,特别是跨通道或跨空间位置的依赖. 这种上下文感知能力有助于网络更好地理解建筑物的结构、纹理和与背景的差异. CPCA通过深度卷积构建空间注意力模块,采用多尺度卷积核分别对每个通道计算空间注意力,实现空间注意力在每个通道上的动态分布,能够更精确地贴合实际的特征分布. 遥感图像普遍具有多尺度特性,CPCA中的多尺度条形卷积能够照顾到这一特性,提升分割效果.
2. 数据集和实验设置
2.1. 数据集介绍
WHU建筑数据集包含卫星图像和航拍图像2种类型的图像. 本实验选用航拍图像, 该子集覆盖面积超过450 km2,共包含约22 000栋建筑物. 图像为RGB三通道,空间分辨率为0.3 m,图像大小为512×512像素. 该子集共计8 188张图像,其中4 736张用于训练,1 036张用于验证,2 416张用于测试. 实验采用官方提供的数据集划分方案.
Massachusetts建筑数据集包含来自波士顿地区的151张航拍图像,图像尺寸为1 500×1 500像素,地面采样距离为1 m. 此数据集覆盖城市与郊区场景,建筑物的大小、形状、纹理及颜色各异,具有较高的挑战性,适合作为模块有效性验证的基准数据集. 本实验依照官方提供的数据集划分方案. 由于硬件条件的限制,实验前先将图像与标签填充至1 536×1 536像素,再以九宫格样式切分成512×512像素的图像与标签,采用数据增强策略(如水平和垂直翻转)扩展训练集. 实验将该数据集中的3 699张图像用于训练,36张图像用于验证,90张图像用于测试. 评估时不计算填充区域的结果.
2.2. 评估指标
采用5种常见的评价指标对DFFME-Net在建筑物提取任务中的性能进行量化分析:交并比IoU、F1分数F1、精确率P、召回率R和总体精度OA. 这些指标从不同角度评估了模型在建筑物目标分割中的表现. 交并比是建筑物提取领域中常用的指标,用于衡量预测结果与真实建筑物区域的重叠程度,计算式为
F1分数是精确率与召回率的调和平均数,能够在权衡这2个指标的同时反映模型的综合性能,计算式为
精确率衡量模型预测的建筑物区域中有多少是真实的建筑物,计算式为
召回率反映真实建筑物区域中有多少被模型成功检测到,计算式为
总体精度衡量模型在所有分类中预测正确的像素占总像素的比例,是评价模型整体性能的重要指标,计算式为
式中:
2.3. 实验设置
所有实验均在配备24 GB显存的NVIDIA GeForce RTX 3090 GPU上执行,采用PyTorch 2.2.1(CUDA 12.1)作为深度学习框架. 实验过程中,选用AdamW优化器与余弦退火学习率策略. 在数据增强环节,随机水平翻转与垂直翻转被用于提升模型的泛化能力. 针对WHU数据集,为了确保实验公正性,所有模型均未采用预训练参数. 训练的迭代次数为140,初始学习率设定为
3. 实验结果及分析
3.1. 对比实验
3.1.1. WHU数据集对比实验
如表1所示为不同方法在WHU建筑数据集上的评价指标对比. 与其他的方法相比,DFFME-Net在交并比、F1分数、精确率和总体精度上达到了最优,在召回率上几乎和BuildFormer持平. 具体来说,DFFME-Net和BuildFormer相比,交并比提高了0.97个百分点,F1分数提高了0.53个百分点,精确率提高了1.07个百分点,总体精度提高了0.12个百分点,召回率只下降了0.01个百分点. 这些指标的显著优势反映了本研究所提方法的优越性.
表 1 在WHU建筑数据集上不同图像分割方法的定量比较
Tab.1
| 方法 | IoU | F1 | P | R | OA |
| Trans-UNet | 90.21 | 94.85 | 94.75 | 94.95 | 98.85 |
| Swin-Unet | 89.67 | 94.56 | 94.67 | 94.44 | 98.79 |
| DCSwin | 88.83 | 94.09 | 94.48 | 93.70 | 98.69 |
| MANet | 90.62 | 95.08 | 95.46 | 94.70 | 98.91 |
| BuildFormer | 90.84 | 95.20 | 94.86 | 95.54 | 98.93 |
| DFFME-Net | 91.81 | 95.73 | 95.93 | 95.53 | 99.05 |
如图4所示为不同方法在该数据集中的图像提取性能可视化对比. 可以看到,多数模型在识别建筑物时会出现漏检和误检现象,DFFME-Net提取效果是其中最好的. 对于复杂建筑物,DFFME-Net提取结果最为完整,建筑物边界提取的尤为精确、规整. 同时该模型是唯一准确识别出被树木遮挡的建筑物区域的模型. 在处理大型建筑物时,部分模型的提取出现空洞现象,而DFFME-Net准确完整地提取出了建筑物. 在区分建筑物相似地物这一环节上,DFFME-Net未对颜色和轮廓与建筑物相似的非建筑物区域做出误判,这是其他模型未能做到的.
图 4

图 4 在WHU建筑数据集上不同图像分割方法的定性比较
Fig.4 Qualitative comparison of different image segmentation methods on WHU building dataset
3.1.2. Massachusetts数据集对比实验
如表2所示为不同方法在Massachusetts建筑数据集上的各种评价指标对比. 与其他方法相比,DFFME-Net在所有指标上取得了最优. 具体来说,DFFME-Net和BuildFormer相比,交并比提高了1.29个百分点,F1分数提高了0.82个百分点,精确率提高了0.45个百分点,召回率提高了1.17个百分点,总体精度提高了0.27个百分点. 这些指标的显著优势反映了本研究所提方法的优越性.
表 2 在Massachusetts建筑数据集上不同图像分割方法的定量比较
Tab.2
| 方法 | IoU | F1 | P | R | OA |
| Trans-UNet | 75.26 | 85.88 | 87.61 | 84.22 | 95.09 |
| Swin-Unet | 74.45 | 85.36 | 86.75 | 84.01 | 94.89 |
| DCSwin | 72.77 | 84.24 | 86.53 | 82.06 | 94.55 |
| MANet | 74.97 | 85.69 | 88.06 | 83.45 | 95.06 |
| BuildFormer | 75.72 | 86.19 | 88.06 | 84.39 | 95.20 |
| DFFME-Net | 77.01 | 87.01 | 88.51 | 85.56 | 95.47 |
如图5所示为不同方法在该数据集中的图像提取性能可视化对比. 可以看到,多数模型在提取建筑物时出现了漏检和误检现象,DFFME-Net在这方面的表现是最好的. 针对规则建筑物的提取,部分模型出现提取不完整和不连续的现象,DFFME-Net不仅提取更为完整,而且在边缘细节的捕捉上表现出色. 对于复杂建筑物提取,DFFME-Net无论是从整体提取效果还是细节处理上均优于其他模型. 在处理小型建筑物时,其他模型出现漏检现象,只有DFFME-Net将其完整地提取出来. 在判别与建筑物相似地物方面,由于背景颜色和轮廓的相似性,许多模型将非建筑物误判为建筑物,DFFME-Net准确地将建筑物与非建筑物区分开来,展现了其在复杂场景下的稳定性和准确性.
图 5

图 5 在Massachusetts建筑数据集上不同图像分割方法的定性比较
Fig.5 Qualitative comparison of different image segmentation methods on Massachusetts building dataset
3.2. 消融实验
3.2.1. 多尺度全局局部特征融合方法与双分支特征融合模块的有效性
为了验证所提方法和模块的有效性,在WHU建筑数据集上进行消融实验. 如表3所示,相比于基准模型,添加MGLFF的模型在多个重要指标上得到提升,其中交并比上增加了0.43个百分点,F1分数上增加了0.24个百分点,总体精度上增加了0.06个百分点. MGLFF的应用导致召回率稍微下降,精确率则显著上升,究其原因是MGLFF通过多尺度全局局部特征图融合平衡了模型对局部信息和全局信息的提取能力. DFFME-Net是在基准模型的基础上添加了MGLFF和DFM的模型,相比于只添加MGLFF的模型,DFFME-Net在5个指标上都得到提升,其中交并比上增加了0.54个百分点,F1分数增加了0.29个百分点,总体精度上增加了0.06个百分点. 该结果验证了将2个特征提取分支相互关联、协同指导特征提取策略的有效性,也证实了DFM的有效性. F1分数是综合了精确率和召回率的指标,在消融实验中,F1分数、交并比和总体精度指标均随着模块的增加而提升.
表 3 在WHU建筑数据集上多尺度全局局部特征融合方法和双分支特征融合模块的消融实验结果
Tab.3
| 方法 | IoU | F1 | P | R | OA |
| 基准模型 | 90.84 | 95.20 | 94.86 | 95.54 | 98.93 |
| +MGLFF | 91.27 | 95.44 | 95.52 | 95.35 | 98.99 |
| +MGLFF+DFM | 91.81 | 95.73 | 95.93 | 95.53 | 99.05 |
3.2.2. 残差卷积模块的有效性
表 4 在WHU建筑数据集上残差卷积模块的消融实验结果
Tab.4
| 方法 | IoU | F1 | P | R | OA |
| 不含RCM | 91.05 | 95.32 | 95.21 | 95.42 | 98.96 |
| 含1个RCM | 91.75 | 95.70 | 95.92 | 95.48 | 99.04 |
| 含2个RCM | 91.78 | 95.72 | 95.94 | 95.49 | 99.04 |
| 含4个RCM | 91.81 | 95.73 | 95.93 | 95.53 | 99.05 |
3.2.3. 通道优先卷积注意力机制的有效性
对DFM内部的CPCA进行消融实验,结果如表5所示. CPCA能够动态地调整特征图的权重,强调对建筑物提取任务重要的特征,同时抑制不相关或噪声特征. 含有CPCA的网络在5个指标上都优于不含有CPCA机制的网络模型,其中交并比提升0.20个百分点,F1分数提升0.11个百分点.
表 5 在WHU建筑数据集上通道优先卷积注意力机制的消融实验结果
Tab.5
| 方法 | IoU | F1 | P | R | OA |
| 不含CPCA | 91.61 | 95.62 | 95.83 | 95.41 | 99.03 |
| 含有CPCA | 91.81 | 95.73 | 95.93 | 95.53 | 99.05 |
4. 结 语
本研究针对建筑物提取任务中存在的漏检和误检现象,提出基于BuildFormer的双分支特征融合与相互增强网络. 1)采用VGG13骨干网络并设计多尺度全局局部特征融合方法,提升模型对局部特征的提取能力和对不同尺度目标的处理能力. 2)双分支特征融合模块促进双分支间的协同作用,增强和平衡模型对全局上下文和局部细节信息的提取能力. 3)通道优先卷积注意力机制通过通道和空间协同优化提升模型对复杂背景区分能力. 4)在WHU建筑数据集和Massachusetts建筑数据集上的对比实验结果表明,DFFME-Net相较于对比模型提取精度更高. 未来将进一步优化网络结构,继续探索CNN和Transformer在遥感领域的潜力和应用.
参考文献
A review of building extraction from remote sensing imagery: geometrical structures and semantic attributes
[J].DOI:10.1109/tgrs.2024.3369723 [本文引用: 1]
Large-scale individual building extraction from open-source satellite imagery via super-resolution-based instance segmentation approach
[J].DOI:10.1016/j.isprsjprs.2022.11.006
Decoupling semantic and edge representations for building footprint extraction from remote sensing images
[J].DOI:10.1109/tgrs.2023.3287298 [本文引用: 1]
SAU-Net: a novel network for building extraction from high-resolution remote sensing images by reconstructing fine-grained semantic features
[J].DOI:10.1109/JSTARS.2024.3371427 [本文引用: 1]
Multi-scale feature fusion attention network for building extraction in remote sensing images
[J].DOI:10.3390/electronics13050923 [本文引用: 1]
Multiattention network for semantic segmentation of fine-resolution remote sensing images
[J].
Integrating spatial details with long-range contexts for semantic segmentation of very high-resolution remote-sensing images
[J].
Asymmetric network combining CNN and transformer for building extraction from remote sensing images
[J].
Building rooftop extraction from high resolution aerial images using multiscale global perceptron with spatial context refinement
[J].DOI:10.1038/s41598-025-91206-6
SDSC-UNet: dual skip connection ViT-based U-shaped model for building extraction
[J].
DSAT-net: dual spatial attention transformer for building extraction from aerial images
[J].
Complementarity-aware local–global feature fusion network for building extraction in remote sensing images
[J].
BCTNet: bi-branch cross-fusion transformer for building footprint extraction
[J].
HD-Net: high-resolution decoupled network for building footprint extraction via deeply supervised body and boundary decomposition
[J].DOI:10.1016/j.isprsjprs.2024.01.022 [本文引用: 1]
A novel transformer based semantic segmentation scheme for fine-resolution remote sensing images
[J].DOI:10.1109/lgrs.2022.3143368 [本文引用: 3]
Building extraction with vision transformer
[J].
Channel prior convolutional attention for medical image segmentation
[J].DOI:10.1016/j.compbiomed.2024.108784 [本文引用: 1]
Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set
[J].DOI:10.1109/TGRS.2018.2858817 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}