[1]
CHEN J, LIU Y, WEI S, et al A survey on deep learning in medical image registration: new technologies, uncertainty, evaluation metrics, and beyond
[J]. Medical Image Analysis , 2025 , 100 : 103385
DOI:10.1016/j.media.2024.103385
[本文引用: 1]
[2]
沈瑜, 魏子易, 严源, 等 基于多尺度约束的大形变3D医学图像配准
[J]. 中国激光 , 2024 , 51 (21 ): 2107109
DOI:10.3788/CJL241180
[本文引用: 1]
SHEN Yu, WEI Ziyi, YAN Yuan, et al Large-deformation 3D medical image registration based on multi-scale constraints
[J]. Chinese Journal of Lasers , 2024 , 51 (21 ): 2107109
DOI:10.3788/CJL241180
[本文引用: 1]
[3]
AVANTS B B, TUSTISON N J, SONG G, et al A reproducible evaluation of ANTs similarity metric performance in brain image registration
[J]. NeuroImage , 2011 , 54 (3 ): 2033 - 2044
DOI:10.1016/j.neuroimage.2010.09.025
[本文引用: 2]
[4]
HERNANDEZ M, RAMON JULVEZ U Insights into traditional large deformation diffeomorphic metric mapping and unsupervised deep-learning for diffeomorphic registration and their evaluation
[J]. Computers in Biology and Medicine , 2024 , 178 : 108761
DOI:10.1016/j.compbiomed.2024.108761
[本文引用: 2]
[5]
李文举, 孔德卿, 曹国刚, 等 基于训练-推理解耦架构的2D-3D医学图像配准
[J]. 激光与光电子学进展 , 2022 , 59 (16 ): 1610015
DOI:10.3788/LOP202259.1610015
[本文引用: 1]
LI Wenju, KONG Deqing, CAO Guogang, et al 2D-3D medical image registration based on training-inference decoupling architecture
[J]. Laser and Optoelectronics Progress , 2022 , 59 (16 ): 1610015
DOI:10.3788/LOP202259.1610015
[本文引用: 1]
[6]
林立昊, 易见兵, 曹锋, 等 多尺度并行全卷积神经网络的肺计算机断层扫描图像非刚性配准算法
[J]. 激光与光电子学进展 , 2022 , 59 (16 ): 1617004
DOI:10.3788/LOP202259.1617004
[本文引用: 1]
LIN Lihao, YI Jianbing, CAO Feng, et al Non-rigid registration algorithm of lung computed tomography image based on multi-scale parallel fully convolutional neural network
[J]. Laser and Optoelectronics Progress , 2022 , 59 (16 ): 1617004
DOI:10.3788/LOP202259.1617004
[本文引用: 1]
[7]
BALAKRISHNAN G, ZHAO A, SABUNCU M R, et al VoxelMorph: a learning framework for deformable medical image registration
[J]. IEEE Transactions on Medical Imaging , 2019 , 38 (8 ): 1788 - 1800
DOI:10.1109/TMI.2019.2897538
[本文引用: 2]
[8]
尹艺晓, 马金刚, 张文凯, 等 从U-Net到Transformer: 混合模型在医学图像分割中的应用进展
[J]. 激光与光电子学进展 , 2025 , 62 (2 ): 1 - 23
DOI:10.3788/LOP240875
[本文引用: 1]
YIN Yixiao, MA Jingang, ZHANG Wenkai, et al From U-Net to transformer: progress in the application of hybrid models in medical image segmentation
[J]. Laser and Optoelectronics Progress , 2025 , 62 (2 ): 1 - 23
DOI:10.3788/LOP240875
[本文引用: 1]
[9]
JADERBERG M, SIMONYAN K, ZISSERMAN A. Spatial transformer networks [C]// Proceedings of the 29th International Conference on Neural Information Processing Systems . [S.l.]: MIT Press, 2015: 2017–2025.
[本文引用: 1]
[10]
JIA X, BARTLETT J, ZHANG T, et al. U-Net vs Transformer: is U-Net outdated inMedical image registration? [C]// Machine Learning in Medical Imaging . [S.l.]: Springer, 2022: 151–160.
[本文引用: 2]
[11]
VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems . [S.l.]: Curran Associates Inc. , 2017: 5998–6008.
[本文引用: 1]
[12]
石磊, 籍庆余, 陈清威, 等 视觉Transformer在医学图像分析中的应用研究综述
[J]. 计算机工程与应用 , 2023 , 59 (8 ): 41 - 55
DOI:10.3778/j.issn.1002-8331.2206-0022
[本文引用: 1]
SHI Lei, JI Qingyu, CHEN Qingwei, et al Review of research on application of vision transformer in medical image analysis
[J]. Computer Engineering and Applications , 2023 , 59 (8 ): 41 - 55
DOI:10.3778/j.issn.1002-8331.2206-0022
[本文引用: 1]
[13]
QIU W, XIONG L, LI N, et al UTR: a UNet-like transformer for efficient unsupervised medical image registration
[J]. Image and Vision Computing , 2024 , 150 : 105209
DOI:10.1016/j.imavis.2024.105209
[本文引用: 1]
[14]
MA T, DAI X, ZHANG S, et al. PIViT: large deformation image registration with Pyramid-iterative vision transformer [C]// Medical Image Computing and Computer Assisted Intervention – MICCAI 2023 . [S.l.]: Springer, 2023: 602–612.
[本文引用: 2]
[15]
LIU Z, LIN Y, CAO Y, et al. Swin Transformer: hierarchical vision transformer using shifted windows [C]// Proceedings of the IEEE/CVF International Conference on Computer Vision . Montreal: IEEE, 2022: 9992–10002.
[本文引用: 1]
[16]
WANG H, NI D, WANG Y Recursive deformable pyramid network for unsupervised medical image registration
[J]. IEEE Transactions on Medical Imaging , 2024 , 43 (6 ): 2229 - 2240
DOI:10.1109/TMI.2024.3362968
[本文引用: 2]
[17]
NAN J, FAN G, ZHANG K, et al. MsMorph: an unsupervised pyramid learning network for brain image registration [EB/OL]. (2024–10–23)[2025–05–29]. https://arxiv.org/abs/2410.18228.
[本文引用: 1]
[18]
刘卫朋, 李旭, 任子文, 等 多尺度残差可变形肺部CT图像配准算法
[J]. 华南理工大学学报: 自然科学版 , 2024 , 52 (10 ): 135 - 145
DOI:10.12141/j.issn.1000-565X.230726
[本文引用: 1]
LIU Weipeng, LI Xu, REN Ziwen, et al Algorithm for multiscale residual deformable lung CT image registration
[J]. Journal of South China University of Technology: Natural Science Edition , 2024 , 52 (10 ): 135 - 145
DOI:10.12141/j.issn.1000-565X.230726
[本文引用: 1]
[19]
YANG H, YUAN C, LI B, et al Asymmetric 3D convolutional neural networks for action recognition
[J]. Pattern Recognition , 2019 , 85 : 1 - 12
DOI:10.1109/icip.2019.8802910
[本文引用: 1]
[20]
MA Y, NIU D, ZHANG J, et al Unsupervised deformable image registration network for 3D medical images
[J]. Applied Intelligence , 2022 , 52 (1 ): 766 - 779
DOI:10.1007/s10489-021-02196-7
[本文引用: 1]
[21]
CHEN J, FREY E C, HE Y, et al TransMorph: transformer for unsupervised medical image registration
[J]. Medical Image Analysis , 2022 , 82 : 102615
DOI:10.1016/j.media.2022.102615
[本文引用: 2]
[23]
KIM B, KIM D H, PARK S H, et al CycleMorph: cycle consistent unsupervised deformable image registration
[J]. Medical Image Analysis , 2021 , 71 : 102036
DOI:10.1016/j.media.2021.102036
[本文引用: 1]
[24]
CHEN J, HE Y, FREY E C, et al. ViT-V-Net: vision transformer for unsupervised volumetric medical image registration [EB/OL]. (2021–04–13)[2025–05–29]. https://arxiv.org/abs/2104.06468.
[本文引用: 1]
[25]
CHEN Z, ZHENG Y, GEE J C TransMatch: a transformer-based multilevel dual-stream feature matching network for unsupervised deformable image registration
[J]. IEEE Transactions on Medical Imaging , 2024 , 43 (1 ): 15 - 27
DOI:10.1109/TMI.2023.3288136
[本文引用: 1]
[26]
KANG M, HU X, HUANG W, et al Dual-stream pyramid registration network
[J]. Medical Image Analysis , 2022 , 78 : 102379
DOI:10.1016/j.media.2022.102379
[本文引用: 1]
A survey on deep learning in medical image registration: new technologies, uncertainty, evaluation metrics, and beyond
1
2025
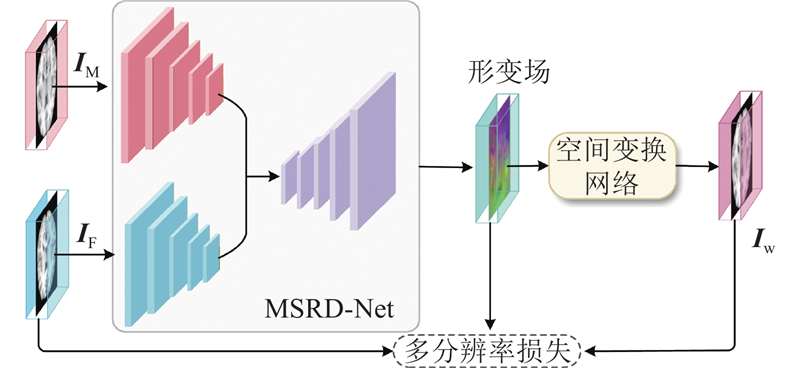
... 医学图像配准作为图像分析中的基本任务,用于评估移动图像和固定图像之间的非线性映射关系,使两幅图像上的像素点坐标达到空间上的一致,已广泛应用于病情诊断、术前计划和术中导航[1 -2 ] . 传统图像配准方法通过最小化目标函数实现两幅图像在空间上的配准,如SyN[3 ] 、LDDMM[4 ] . 上述方法须对每幅图像都进行迭代优化,存在耗时长、计算成本高和处理复杂形变能力不足的问题[5 -6 ] . ...
基于多尺度约束的大形变3D医学图像配准
1
2024
... 医学图像配准作为图像分析中的基本任务,用于评估移动图像和固定图像之间的非线性映射关系,使两幅图像上的像素点坐标达到空间上的一致,已广泛应用于病情诊断、术前计划和术中导航[1 -2 ] . 传统图像配准方法通过最小化目标函数实现两幅图像在空间上的配准,如SyN[3 ] 、LDDMM[4 ] . 上述方法须对每幅图像都进行迭代优化,存在耗时长、计算成本高和处理复杂形变能力不足的问题[5 -6 ] . ...
基于多尺度约束的大形变3D医学图像配准
1
2024
... 医学图像配准作为图像分析中的基本任务,用于评估移动图像和固定图像之间的非线性映射关系,使两幅图像上的像素点坐标达到空间上的一致,已广泛应用于病情诊断、术前计划和术中导航[1 -2 ] . 传统图像配准方法通过最小化目标函数实现两幅图像在空间上的配准,如SyN[3 ] 、LDDMM[4 ] . 上述方法须对每幅图像都进行迭代优化,存在耗时长、计算成本高和处理复杂形变能力不足的问题[5 -6 ] . ...
A reproducible evaluation of ANTs similarity metric performance in brain image registration
2
2011
... 医学图像配准作为图像分析中的基本任务,用于评估移动图像和固定图像之间的非线性映射关系,使两幅图像上的像素点坐标达到空间上的一致,已广泛应用于病情诊断、术前计划和术中导航[1 -2 ] . 传统图像配准方法通过最小化目标函数实现两幅图像在空间上的配准,如SyN[3 ] 、LDDMM[4 ] . 上述方法须对每幅图像都进行迭代优化,存在耗时长、计算成本高和处理复杂形变能力不足的问题[5 -6 ] . ...
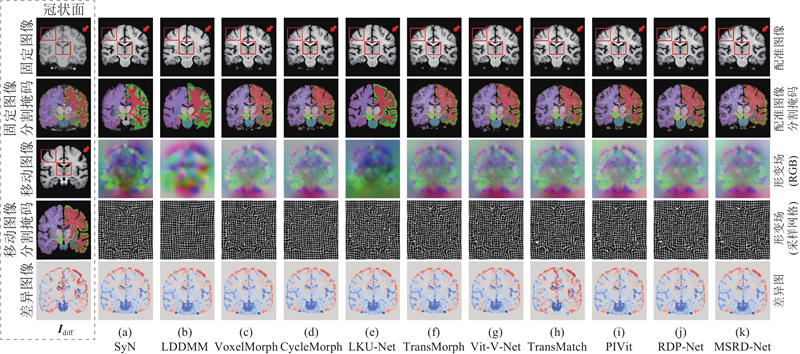
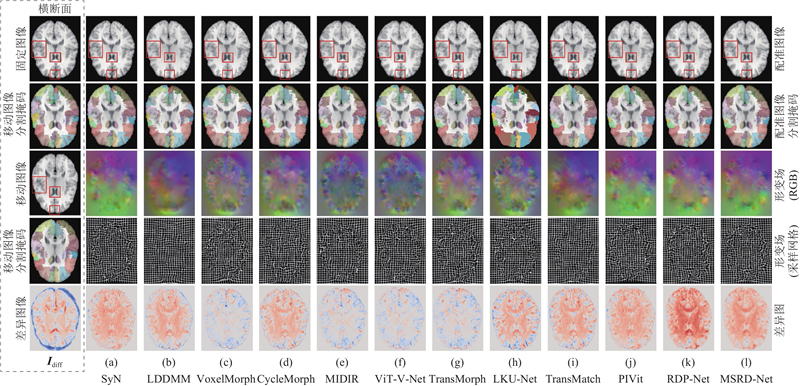
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
Insights into traditional large deformation diffeomorphic metric mapping and unsupervised deep-learning for diffeomorphic registration and their evaluation
2
2024
... 医学图像配准作为图像分析中的基本任务,用于评估移动图像和固定图像之间的非线性映射关系,使两幅图像上的像素点坐标达到空间上的一致,已广泛应用于病情诊断、术前计划和术中导航[1 -2 ] . 传统图像配准方法通过最小化目标函数实现两幅图像在空间上的配准,如SyN[3 ] 、LDDMM[4 ] . 上述方法须对每幅图像都进行迭代优化,存在耗时长、计算成本高和处理复杂形变能力不足的问题[5 -6 ] . ...
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
基于训练-推理解耦架构的2D-3D医学图像配准
1
2022
... 医学图像配准作为图像分析中的基本任务,用于评估移动图像和固定图像之间的非线性映射关系,使两幅图像上的像素点坐标达到空间上的一致,已广泛应用于病情诊断、术前计划和术中导航[1 -2 ] . 传统图像配准方法通过最小化目标函数实现两幅图像在空间上的配准,如SyN[3 ] 、LDDMM[4 ] . 上述方法须对每幅图像都进行迭代优化,存在耗时长、计算成本高和处理复杂形变能力不足的问题[5 -6 ] . ...
基于训练-推理解耦架构的2D-3D医学图像配准
1
2022
... 医学图像配准作为图像分析中的基本任务,用于评估移动图像和固定图像之间的非线性映射关系,使两幅图像上的像素点坐标达到空间上的一致,已广泛应用于病情诊断、术前计划和术中导航[1 -2 ] . 传统图像配准方法通过最小化目标函数实现两幅图像在空间上的配准,如SyN[3 ] 、LDDMM[4 ] . 上述方法须对每幅图像都进行迭代优化,存在耗时长、计算成本高和处理复杂形变能力不足的问题[5 -6 ] . ...
多尺度并行全卷积神经网络的肺计算机断层扫描图像非刚性配准算法
1
2022
... 医学图像配准作为图像分析中的基本任务,用于评估移动图像和固定图像之间的非线性映射关系,使两幅图像上的像素点坐标达到空间上的一致,已广泛应用于病情诊断、术前计划和术中导航[1 -2 ] . 传统图像配准方法通过最小化目标函数实现两幅图像在空间上的配准,如SyN[3 ] 、LDDMM[4 ] . 上述方法须对每幅图像都进行迭代优化,存在耗时长、计算成本高和处理复杂形变能力不足的问题[5 -6 ] . ...
多尺度并行全卷积神经网络的肺计算机断层扫描图像非刚性配准算法
1
2022
... 医学图像配准作为图像分析中的基本任务,用于评估移动图像和固定图像之间的非线性映射关系,使两幅图像上的像素点坐标达到空间上的一致,已广泛应用于病情诊断、术前计划和术中导航[1 -2 ] . 传统图像配准方法通过最小化目标函数实现两幅图像在空间上的配准,如SyN[3 ] 、LDDMM[4 ] . 上述方法须对每幅图像都进行迭代优化,存在耗时长、计算成本高和处理复杂形变能力不足的问题[5 -6 ] . ...
VoxelMorph: a learning framework for deformable medical image registration
2
2019
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
从U-Net到Transformer: 混合模型在医学图像分割中的应用进展
1
2025
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
从U-Net到Transformer: 混合模型在医学图像分割中的应用进展
1
2025
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
1
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
2
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
1
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
视觉Transformer在医学图像分析中的应用研究综述
1
2023
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
视觉Transformer在医学图像分析中的应用研究综述
1
2023
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
UTR: a UNet-like transformer for efficient unsupervised medical image registration
1
2024
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
2
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
1
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
Recursive deformable pyramid network for unsupervised medical image registration
2
2024
... 随着深度学习的快速发展,卷积神经网络(CNN)已广泛应用于医学图像分析领域,在医学图像配准任务中取得良好效果. Balakrishnan等[7 ] 提出的VoxelMorph模型,使用U-Net[8 ] 和分割掩码进行模型训练,预测出形变场,结合空间变换网络[9 ] (spatial transformation network,STN)对移动图像进行配准. VoxelMorph网络感受野大小有限,对复杂形变配准效果不佳. Jia等[10 ] 提出轻量化的LKU-Net模型,使用4层并行大内核卷积模块,在扩大感受野的同时提升了配准精度. 这些方法是以CNN为基础构建的网络,缺乏长距离依赖建模能力,对复杂形变信息捕获能力不足. Transformer[11 ] 在自然语言处理领域有出色表现,被广泛应用在医学图像处理领域,并取得显著成效[12 ] . Qiu等[13 ] 提出UTR模型,采用通道和滑动窗口注意力构建融合注意力模块(fusion attention block,FAB),结合CNN和Transformer的优势,充分捕获图像的全局上下文关系和局部细粒度信息,显著提升了模型的配准性能. 该模型参数量较大,在实时配准任务中的应用受到一定限制. Ma等[14 ] 提出PIViT模型,使用新的迭代金字塔配准网络和Swin Transformer[15 ] ,利用金字塔结构和低尺度迭代配准的方法,从粗到细逐步细化形变场. 该模型在金字塔编码端特征提取能力不足,无法有效捕获图像的细粒度信息. Wang等[16 ] 提出RDP-Net模型,将残差模块作为特征提取的骨干,使用递归策略和融合高级语义信息预测形变场,提高预测形变场的准确性. 该模型在面对不同数据集时泛化能力有限. ...
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
1
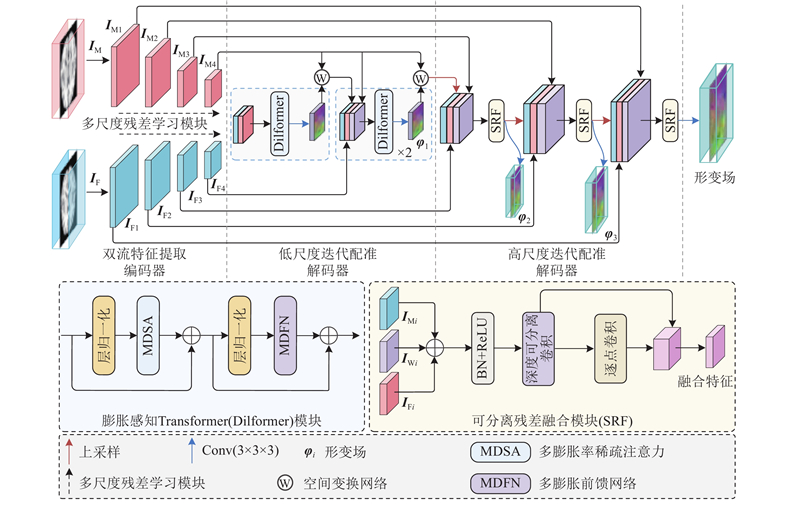
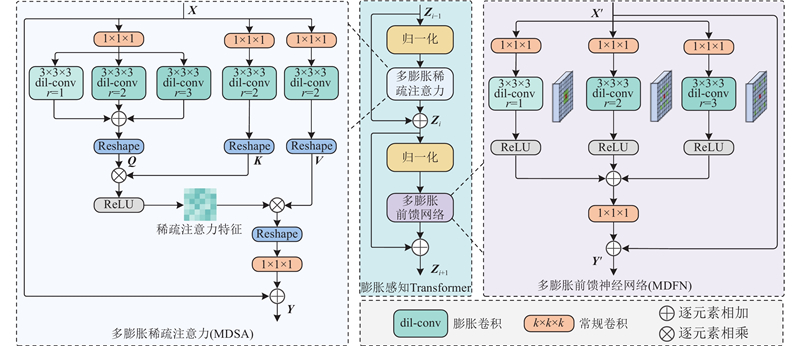
... 现有模型通常采用单编码-解码结构,将移动图像和固定图像同时输入网络,进行特征提取和形变场预测. 这种单流架构依赖CNN或Transformer对固定图像和移动图像的特征进行交互融合,难以对复杂形变信息进行准确建模,限制了配准精度[17 ] . 鉴于此,本研究提出的双流配准网络MSRD-Net由多尺度残差特征提取模块、Dilformer模块和可分离残差融合模块组成,实现从特征提取到形变建模,再到多尺度信息融合的高效流程,如图2 所示. 1)在双流金字塔特征提取阶段,将移动图像和固定图像分别作为输入,依次通过3个连续的多尺度残差特征学习模块和下采样操作,提取不同尺度下的特征信息,以增强模型对局部细节与全局结构的感知能力. 2)在低尺度迭代配准阶段,将连续下采样的低尺度特征拼接后输入Dilformer,以提取形变特征并预估形变场. 3)利用STN对低尺度移动特征图像进行变换,得到配准后特征图像. 4)将配准后的特征图像和低尺度固定特征图像进行拼接,输入Dilformer模块,经过2次迭代提取,生成最终的低尺度特征,使模型具备更强的全局语义表达能力. 5)对低尺度特征图像进行上采样,并与编码端相同尺度的特征图像分别输入可分离残差融合模块中,通过连续3层计算,以生成高精度的形变场. ...
多尺度残差可变形肺部CT图像配准算法
1
2024
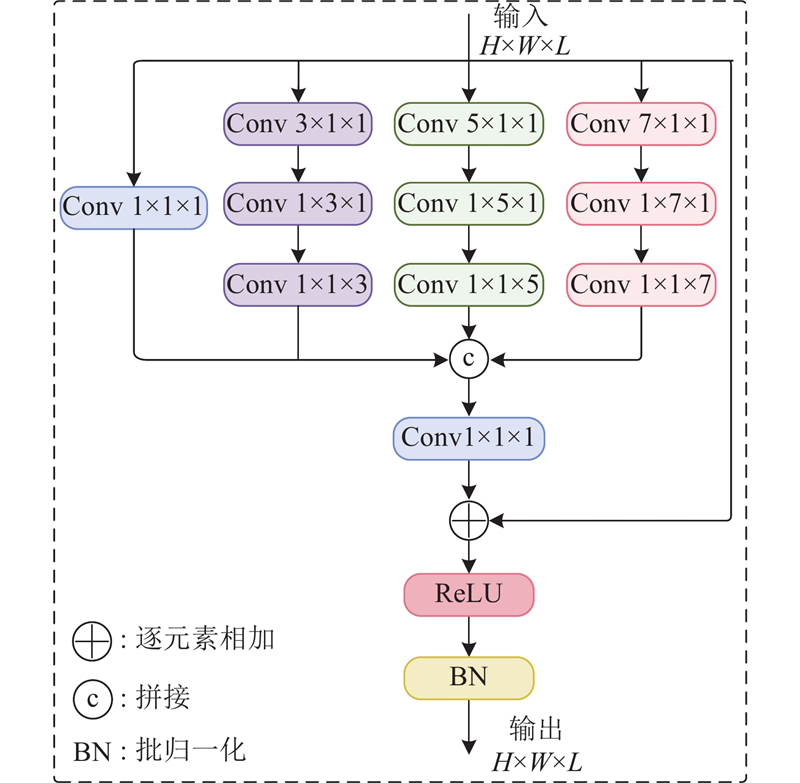
... 为了提升模型对图像中多尺度特征的表达能力,设计MSR,用于捕获局部细节和全局上下文信息[18 ] . 如图3 所示,MSR由4条并行路径构成,分别采用1×1×1、3×3×3、5×5×5、7×7×7的卷积核从不同感受野下提取丰富特征信息,有效增强纹理模糊或低对比度区域的上下文感知能力. 直接拼接多尺度特征容易引入低层分支中的高频噪声,干扰高层语义表达,造成特征表示不一致、语义冗余的问题. 借鉴InceptionNet和ResNet的设计思想,在多尺度特征融合前引入1×1×1卷积进行降维,用于整合不同尺度特征深层语义信息,并增强细粒度特征表达. 通过残差连接保留原始输入特征,并结合ReLU激活函数和批归一化操作,进一步提升模型的非线性建模能力与训练稳定性. 为了降低多内核带来的计算开销,MSR采用卷积分解策略[19 ] ,将k ×k ×k 的卷积分解为3步:k ×1×1、1×k ×1和1×1×k 的卷积操作,即保留了大感受野特性,又有效减少了参数量与计算复杂度. ...
多尺度残差可变形肺部CT图像配准算法
1
2024
... 为了提升模型对图像中多尺度特征的表达能力,设计MSR,用于捕获局部细节和全局上下文信息[18 ] . 如图3 所示,MSR由4条并行路径构成,分别采用1×1×1、3×3×3、5×5×5、7×7×7的卷积核从不同感受野下提取丰富特征信息,有效增强纹理模糊或低对比度区域的上下文感知能力. 直接拼接多尺度特征容易引入低层分支中的高频噪声,干扰高层语义表达,造成特征表示不一致、语义冗余的问题. 借鉴InceptionNet和ResNet的设计思想,在多尺度特征融合前引入1×1×1卷积进行降维,用于整合不同尺度特征深层语义信息,并增强细粒度特征表达. 通过残差连接保留原始输入特征,并结合ReLU激活函数和批归一化操作,进一步提升模型的非线性建模能力与训练稳定性. 为了降低多内核带来的计算开销,MSR采用卷积分解策略[19 ] ,将k ×k ×k 的卷积分解为3步:k ×1×1、1×k ×1和1×1×k 的卷积操作,即保留了大感受野特性,又有效减少了参数量与计算复杂度. ...
Asymmetric 3D convolutional neural networks for action recognition
1
2019
... 为了提升模型对图像中多尺度特征的表达能力,设计MSR,用于捕获局部细节和全局上下文信息[18 ] . 如图3 所示,MSR由4条并行路径构成,分别采用1×1×1、3×3×3、5×5×5、7×7×7的卷积核从不同感受野下提取丰富特征信息,有效增强纹理模糊或低对比度区域的上下文感知能力. 直接拼接多尺度特征容易引入低层分支中的高频噪声,干扰高层语义表达,造成特征表示不一致、语义冗余的问题. 借鉴InceptionNet和ResNet的设计思想,在多尺度特征融合前引入1×1×1卷积进行降维,用于整合不同尺度特征深层语义信息,并增强细粒度特征表达. 通过残差连接保留原始输入特征,并结合ReLU激活函数和批归一化操作,进一步提升模型的非线性建模能力与训练稳定性. 为了降低多内核带来的计算开销,MSR采用卷积分解策略[19 ] ,将k ×k ×k 的卷积分解为3步:k ×1×1、1×k ×1和1×1×k 的卷积操作,即保留了大感受野特性,又有效减少了参数量与计算复杂度. ...
Unsupervised deformable image registration network for 3D medical images
1
2022
... 无监督医学图像配准的实质是通过最小化损失函数以优化图像对之间的相似性,寻求最优的空间变换. 这种方式只对全分辨率下的形变场和配准图像进行损失计算,在涉及复杂形变时可能无法捕捉整体形变,优化过程易陷入局部最优,导致全局配准精度不佳. 引入多分辨率损失函数[20 ] ,在解码端网络逐步预测多分辨下的形变场,并对同分辨率下的移动图像进行变换. 多分辨率损失引导关注全局结构,稳定低对比区域的匹配. 该方法的相似性损失$ {L}^{K}_{{\mathrm{sim}}} $ ${L}^{K}_{\mathrm{smooth}}({\bf\textit{φ}} )$
TransMorph: transformer for unsupervised medical image registration
2
2022
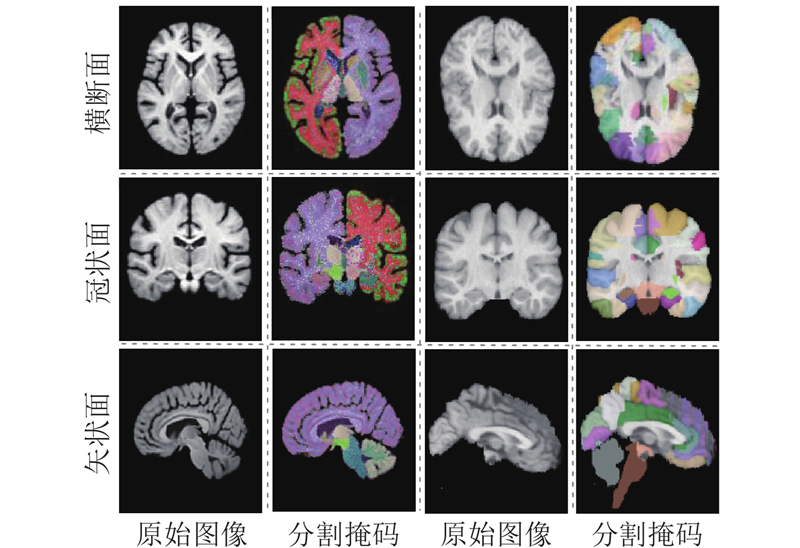
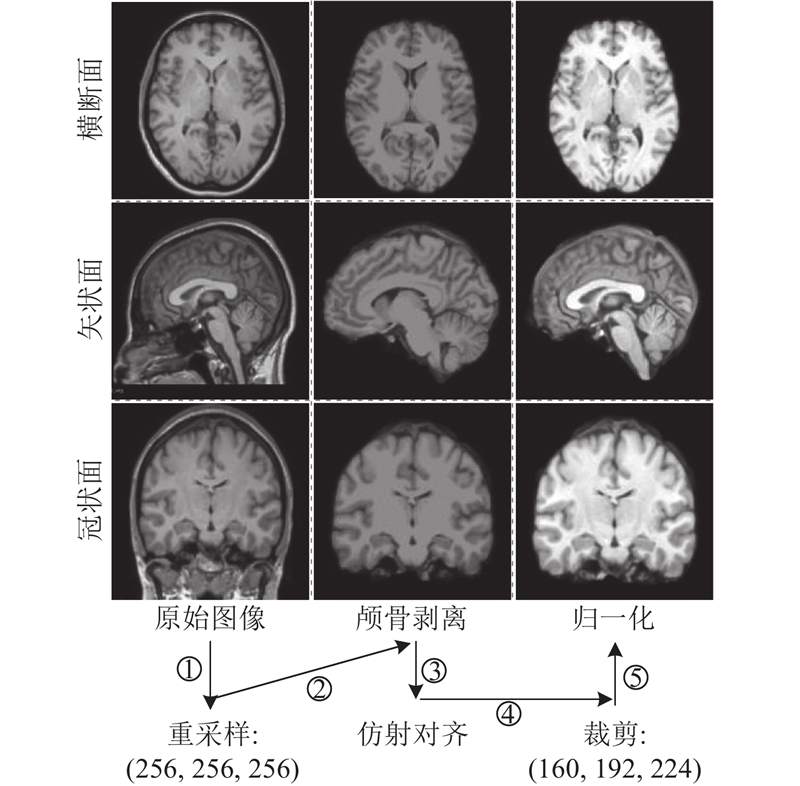
... 为了提升模型的学习效率,实验采用Chen等[21 ] 提出的预处理策略. 对于IXI数据集的每张图像重采样到256×256×256的规格,体素间距调整为1 mm×1 mm×1 mm;使用FreeSurfer[22 ] 对重采样后的图像进行颅骨剥离和仿射对齐,将图像裁剪为160×192×224对数据进行归一化. 如图6 所示为IXI数据集的预处理流程. ...
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
FreeSurfer
1
2012
... 为了提升模型的学习效率,实验采用Chen等[21 ] 提出的预处理策略. 对于IXI数据集的每张图像重采样到256×256×256的规格,体素间距调整为1 mm×1 mm×1 mm;使用FreeSurfer[22 ] 对重采样后的图像进行颅骨剥离和仿射对齐,将图像裁剪为160×192×224对数据进行归一化. 如图6 所示为IXI数据集的预处理流程. ...
CycleMorph: cycle consistent unsupervised deformable image registration
1
2021
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
1
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
TransMatch: a transformer-based multilevel dual-stream feature matching network for unsupervised deformable image registration
1
2024
... 为了验证所提方法的有效性,在IXI数据集上与10种主流的医学图像配准方法进行对比,涵盖传统方法SyN[3 ] 和LDDMM[4 ] ,以及基于深度学习的经典配准方法VoxelMorph[7 ] 、CycleMorph[23 ] 、ViT-V-Net[24 ] 、TransMorph[21 ] 、LKU-Net[10 ] 、TransMatch[25 ] 、PIVit[14 ] 和RDP-Net[16 ] . ...
Dual-stream pyramid registration network
1
2022
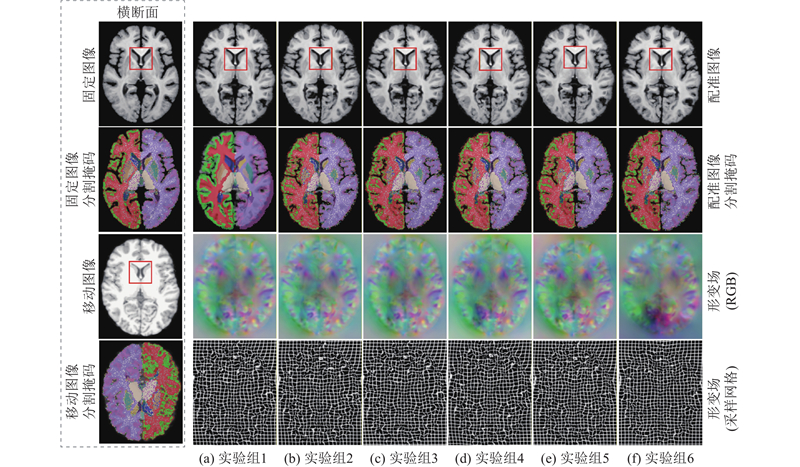
... 在IXI数据集上设计6组消融实验,验证所提模块的有效性. 第1组采用原始的Dual-PRNet++[26 ] 配准模型作为基准. 第2组在双流金字塔配准网络的基础上,加入MSR替换单一的卷积层,提取多尺度特征信息,增强模型对空间结构的感知能力. 第3组在低尺度配准阶段,使用Dilformer模块,提升模型在低尺度空间上的全局形变建模能力和模型对复杂形变的适应性. 第4组在解码端结合SRF,采用逐步配准的策略,实现从粗到细的配准. 第5组将MSR、Dilformer和SRF都保留在模型中. 第6组在第5组的基础上,加入多分辨率损失函数,验证损失对整体模型的优化情况. ...



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}