

可重构智能表面(reconfigurable intelligent surface, RIS)是一种可编程的人工表面,由大量低功耗、可调相的元件组成[3-5]. 目前已经有大量关于RIS在通感一体化系统中的应用研究. Nassar等[6]提出针对支持反向散射的混合RIS辅助非正交多址(non-orthogonal multiple access, NOMA)网络的稳健波束成形设计. Chen等[7]在通信服务质量(quality of service, QoS)的约束下,分别构建了不同的优化问题. Zhang等[8]设计联合波束成形方法,优化RIS反射和信号发射性能. Chen等[9]研究RIS辅助ISAC系统,并提出同时波束训练与目标感知方案.
上述研究都在探讨有源RIS对通感一体化系统性能的影响,但无论是混合RIS还是有源RIS,当基站传输功率过高时,在放大信号的同时,不仅会引起功耗提高,还会使系统能效降低. 不规则RIS在反射单元部署可行的情况下,给系统带来额外的空间自由度. Su等[15]提出的不规则RIS在反射面元件数量一定的情况下能够提高系统容量. El-Meadawy等[16]提出新的多层不规则RIS(multi-layer irregular reconfigurable intelligent surface, MLI-RIS)架构,并针对其设计优化框架. 此外,由于传统优化算法在高维空间中易于陷入局部最优,深度强化学习(deep reinforcement learning , DRL)能更好地探索和开发更优解. Liu等[17]采用DRL算法,研究在RIS辅助的ISAC系统中的物理层安全性的问题. Zhu等[18]提出应用2种DRL算法,解决复杂的非凸问题,最大化系统的长期效益.
本研究引入不规则智能反射面辅助通感一体化系统,以处理在感知波束图增益约束以及不规则RIS拓扑矩阵约束下的最小化多用户间干扰问题. 1)首先采用模拟退火算法计算不规则RIS拓扑矩阵部署问题,保证在一定RIS元件数量下的最优空间利用. 2)分别采用Adam优化器结合传统的梯度下降法与基于DRL的算法联合优化处理基站恒模波形与反射面离散相移设计问题. 3)从多用户干扰、加权和速率、感知波束强度等方面进行实验对比分析.
1. 系统模型
考虑不规则RIS辅助多用户的通感一体化通信系统模型如图1所示. 通过一个双功能基站,同时实现通信与感知功能. 该基站配备
图 1
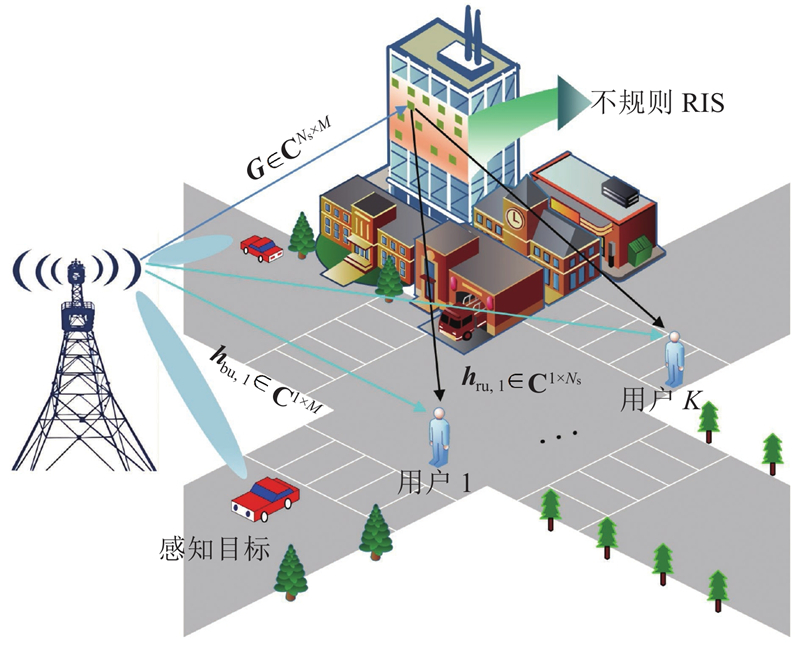
图 1 不规则RIS辅助通信感知一体化系统模型
Fig.1 Model of irregular RIS-assisted integrated sensing and communication system
1.1. 通信模型
下行通信链路用户收到的信号可以表示为
式中:
已知下行通信用户期望的星座符号矩阵为
通过引入期望信号将多用户干扰(multi-user interference, MUI)能量分离为可优化部分,则式 (2)第2项MUI总能量可以表示为
MUI能量直接影响用户的可达和速率,第
式中:
1.2. 感知模型
期望的雷达波束协方差矩阵表达式 [21] 如下:
式中:
式中:
感知波束图增益定义为[21]
式中:
2. 问题描述
本研究目标是联合优化通感一体化波形与RIS相移设计,在感知波束图增益约束以及不规则RIS的拓扑矩阵约束下最小化多用户间干扰,该问题可以描述为
式中:
3. 不规则RIS的稀疏部署与波束成形设计方案
关于问题
3.1. 基于模拟退火算法的不规则RIS拓扑结构优化
求解
定义拓扑矩阵状态:采用
初始化:初始温度
重复:计算邻域拓扑
根据Metropolis 准则决定是否接受邻域拓扑作为当前拓扑:
为了使算法不容易陷入局部最优解,生成一个随机数
3.2. 基于梯度下降算法的波形矩阵优化
对于给定的离散相移矩阵
计算其梯度:
初始化一阶矩估计
式中:
式中:
在每次更新
3.3. 基于梯度下降算法的离散相移矩阵优化
对于给定的信号矩阵
重新定义目标函数为
梯度为
同理,计算动量估计与梯度平方估计,然后进行偏差校正,最后更新
须注意的是,在每次更新完相移矩阵后,须将结果投影到离散相移集合上,即
依次采用Adam优化器来更新波形矩阵与相移矩阵,直到算法收敛.
4. 基于深度强化学习(DRL)联合波形与相移矩阵设计
为了更高效地处理本研究的优化问题,提出DRL算法解决
图 2
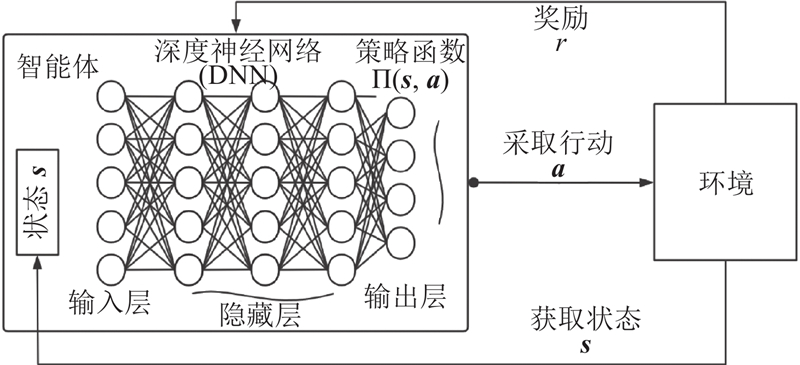
4.1. 基于DRL的联合优化算法
首先将状态空间定义为
在本研究DRL算法中,DQN用于优化不规则RIS的相移矩阵
式中:
PPO算法用于优化基站发射的信号矩阵,首先将
式中:
式中:
DQN网络与PPO网络的奖励函数分别为
式中:
在DQN中,策略是基于
式中:
DQN是一种基于值的算法,即通过
式中:
在PPO中,策略函数为
式中:
DQN中价值函数是通过最大化
在本研究中,DQN采用的神经网络模型是近似于
图 3
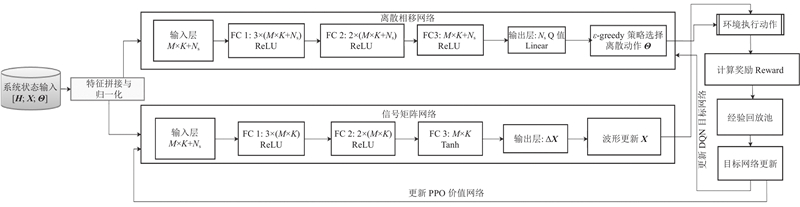
图 3 深度强化学习网络架构示意图
Fig.3 Schematic diagram of deep reinforcement learning network architecture
DQN算法流程如下.
1)初始化网络参数
2)输入当前信道状态信息与信号矩阵
3)根据
4)执行相应的动作,计算奖励
5)将状态转移
6)从经验回放池中随机抽取小批量数据,通过最小化
7)定期将目标网络参数
PPO算法流程如下.
1)初始化策略网络参数
2)将当前信道状态
3)策略网络输出一个连续的动作,即信号矩阵
4)通过以下目标函数优化策略网络:
5)通过最小化以下损失函数更新价值网络:
5. 实验仿真
为了验证所提算法及方案的有效性,对不同算法(Adam优化器结合梯度下降法(算法2)与基于DRL的算法(算法3))下的ISAC系统性能进行仿真. 通信用户随机分布在一个
表 1 不规则RIS辅助通感一体化系统仿真参数设置
Tab.1
| 仿真参数 | 取值 |
| 用户数量 | 3 |
| 感知目标数量Q | 2 |
| 基站天线数量 | 8 |
| 系统带宽 | 10 |
| 总发射功率 | 25 |
| 噪声功率 | −170 |
| 不规则RIS元件总数 | 128 |
| 最小波束图增益 | 10 |
| 误差范围 | 0.01 |
| 初始温度 | 100 |
| 温度衰减因子 | 0.9 |
| 一阶矩估计指数衰减 | 0.9 |
| 二阶矩估计指数衰减 | 0.999 |
| 迭代次数 | 400 |
| 数值稳定因子 | 0.00 000 001 |
| 学习率 | 0.001/0.001/ |
| 折扣因子 | 0.99 |
| 经验回放池容量 | 100 000 |
| 探索率 | 1.00~0.01 |
| 裁剪范围 | 0.2 |
| 训练回合数 | 100 |
| 每回合步骤数 | 8 000 |
为了得到不规则RIS的拓扑结构,设置固定的基站发射功率为20 dBm. 考虑一个小型通信系统,其中
图 4

图 4 不同RIS拓扑部署结构下对应的加权和速率图
Fig.4 Weighted sum rate under different RIS topology deployment structures
为了理解所提算法的可行性,在不同批量大小情况下进行仿真研究,结果如图5所示. 其中,E为训练回合数,
图 5
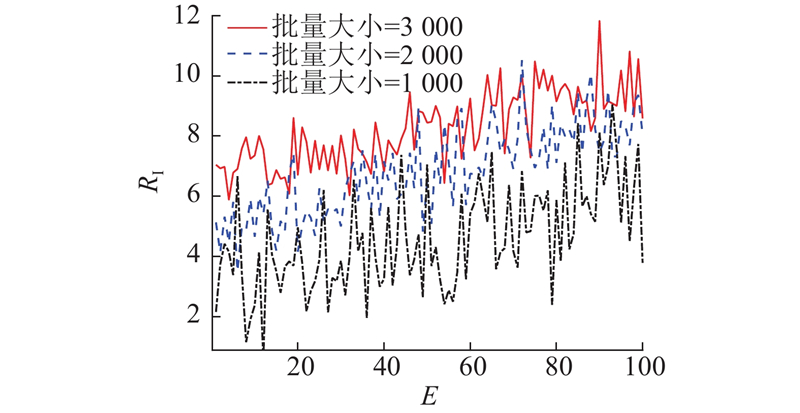
图 5 不同批量大小下的即时奖励曲线图
Fig.5 Instantaneous reward curves for different batch sizes
为了更好地理解算法3,研究不同发射功率(10、20、30 dBm)对即时奖励的影响,结果如图6、7所示,展示了不同功率条件下,即时奖励与平均奖励随步长的变化情况. 其中,S为每回合步骤数,
图 6
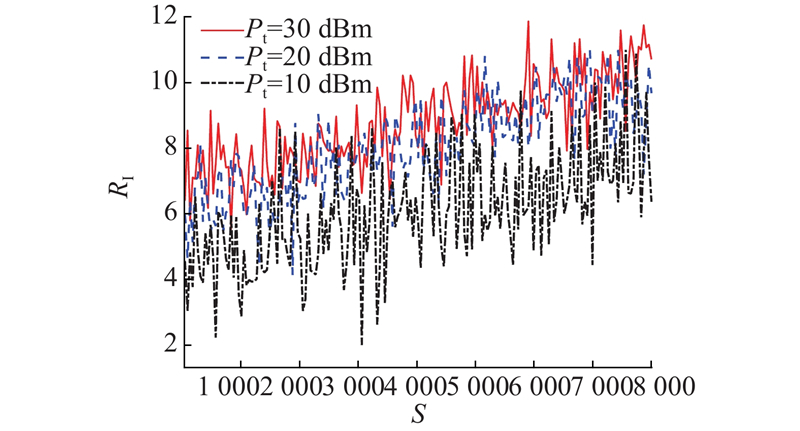
图 6 不同传输功率下的即时奖励曲线图
Fig.6 Instantaneous reward curves under different transmission powers
图 7
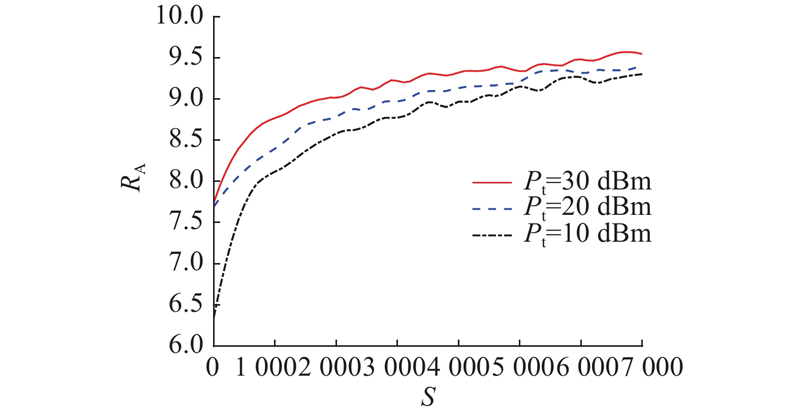
图 7 不同基站传输功率下的平均奖励曲线图
Fig.7 Average reward curves under different base station transmission powers
为了验证所提算法的可行性,假设CSI是完全已知的,如图8所示,展示算法2、3在不同量化级别数量情况下的收敛情况. 其中,M为目标函数值,I为迭代次数. 当b=1时,不规则RIS由于在更大的表面上选择了最佳的单元布局,可以更灵活地控制信道的空间自由度,这种布局的灵活性允许不规则RIS在用户之间形成更清晰的信号分离,从而有效降低MUI. 当b=4时,2种算法的MUI大幅降低,但不规则RIS与传统RIS之间的差异在进一步缩小,这是由于量化比特数的增加使得传统RIS的相移控制精度提升,使得它在MUI抑制方面也有所改善. 但由于规则RIS仍然受到单元布局的限制,相较不规则RIS,其MUI抑制效果会略差一些. 此外,不论何种量化比特数,算法2、3总能在迭代4至5次时达到收敛,且可以看出算法3在降低用户间干扰的效果上是略高于算法2的,这也说明了本研究所提算法的有效性.
图 8
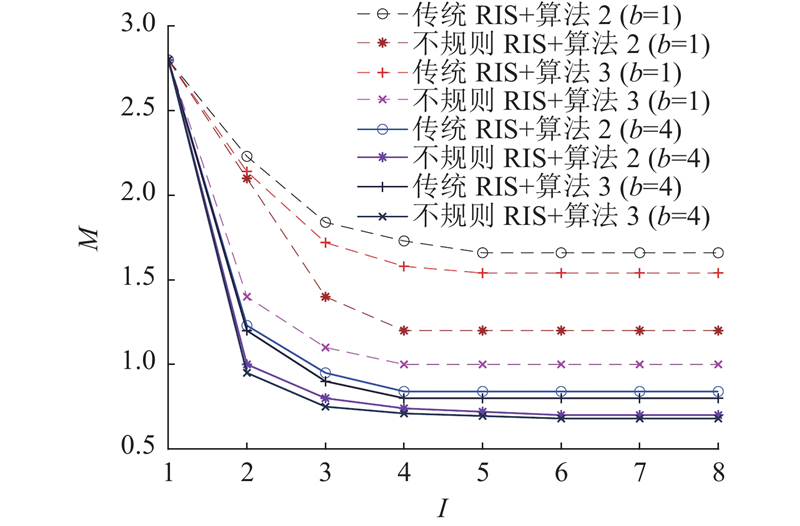
图 8 所提算法在不同量化级别下的多用户干扰变化情况图
Fig.8 Multi-user interference variation plot of proposed algorithm under different quantization levels
本研究的目标函数是最小化MUI,为了展示算法在ISAC通信模型中的优越性,将算法2和算法3与文献[9]中的半正定松弛(semidefinite relaxation, SDR)方案进行对比. 如图9所示,展示了所提算法在不同RIS辅助下系统加权和速率随基站功率的变化图. 其中,
图 9
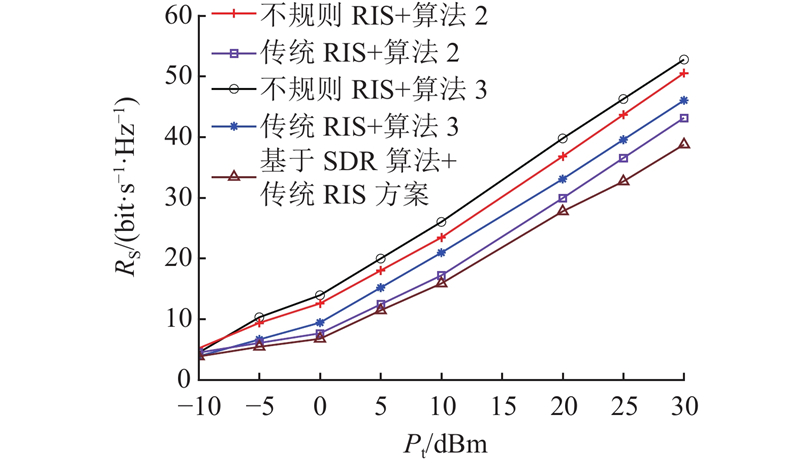
图 9
所提算法在不同RIS辅助下的系统加权和速率随基站功率
Fig.9
Graph of system weighted sum rate versus base station power
此外,还研究了当b=4时,不同RIS类型下的和速率随传输信噪比SNR的变化情况,如图10所示. 其中,
图 10
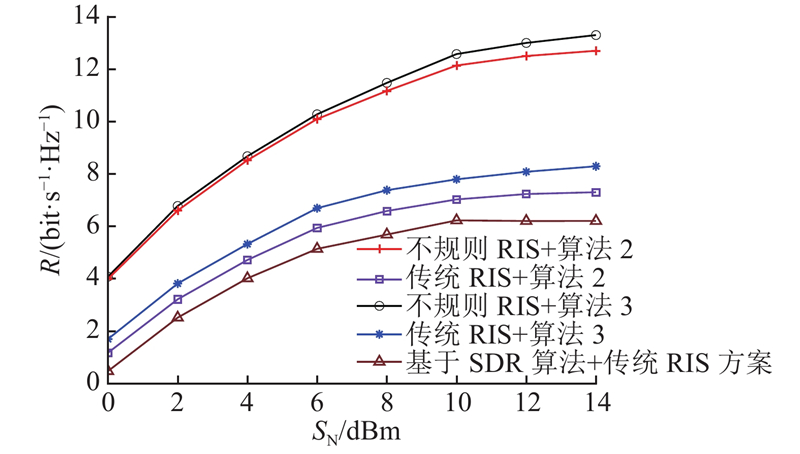
图 10 所提算法在不同RIS辅助下的系统和速率随基站信噪比变化图
Fig.10 Graph of system sum rate versus base station signal-to-noise ratio under different RIS-assisted scenarios using proposed algorithm
为了比较传统RIS与不规则RIS的性能差异,假设2种结构均部署在同一尺寸、网格划分相同(
图 11
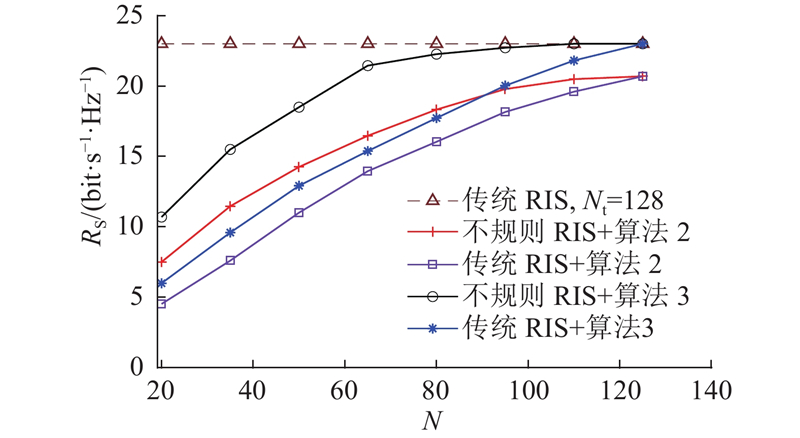
图 11 所提算法在不同RIS辅助下的系统加权和速率随RIS元件数量变化图
Fig.11 Graph of system weighted sum rate versus RIS element number under different RIS assistance using proposed algorithm
如图12所示,展示了在笛卡尔坐标系下,不同方案下的波束强度图. 其中,
图 12
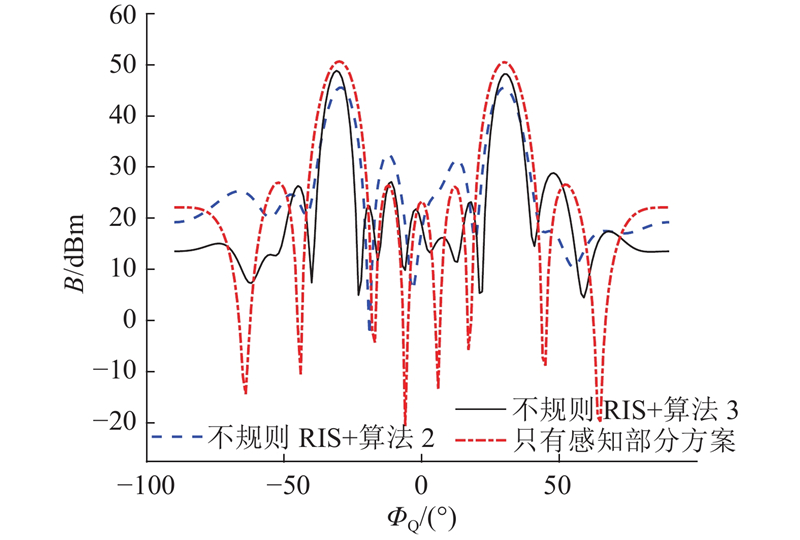
图 12 不同方案下的基站波束强度图
Fig.12 Base station beam intensity maps under different schemes
6. 结 语
引入不规则RIS来提高通感一体化系统的性能. 采用模拟退火算法解决拓扑矩阵的稀疏部署问题,然后分别使用Adam优化器结合梯度下降法以及DRL算法联合处理恒模波形及RIS相移设计,解决了在感知波束图增益约束以及不规则RIS拓扑矩阵约束下的最小化多用户间干扰问题. 仿真结果显示,相较于传统方案,所提方案有效提高了ISAC系统性能. 本研究考虑的通信用户是处于静止或缓慢移动状态的,并未考虑用户处于快速移动时的场景,因此,所提算法能否适用于用户移动场景,有待进一步研究.
参考文献
Multi-domain NOMA for ISAC: utilizing the DOF in the delay-Doppler domain
[J].DOI:10.1109/lcomm.2022.3228873 [本文引用: 1]
Beamforming optimization for wireless network aided by intelligent reflecting surface with discrete phase shifts
[J].DOI:10.1109/TCOMM.2019.2958916 [本文引用: 1]
面向6G移动通信的可重构智能反射表面技术研究综述
[J].DOI:10.16356/j.1005-2615.2023.05.001
Overview of reconfigurable intelligent surface for 6G mobile communication
[J].DOI:10.16356/j.1005-2615.2023.05.001
Hybrid beamforming for reconfigurable intelligent surface based multi-user communications: achievable rates with limited discrete phase shifts
[J].DOI:10.1109/JSAC.2020.3000813 [本文引用: 1]
Spectral and energy efficient waveform design for RIS-assisted ISAC
[J].DOI:10.1109/TCOMM.2024.3435030 [本文引用: 1]
Multipath exploitation for fluctuating target detection in RIS-assisted ISAC systems
[J].DOI:10.1109/LWC.2024.3416453 [本文引用: 1]
Simultaneous beam training and target sensing in ISAC systems with RIS
[J].DOI:10.1109/TWC.2023.3302319 [本文引用: 2]
Energy-efficient cell-free network assisted by hybrid RISs
[J].DOI:10.1109/LWC.2023.3241644 [本文引用: 1]
Cramér-Rao bound optimization for active RIS-empowered ISAC systems
[J].DOI:10.1109/TWC.2024.3384501 [本文引用: 1]
Joint transceiver beamforming and reflecting design for active RIS-aided ISAC systems
[J].DOI:10.1109/TVT.2023.3249752 [本文引用: 1]
Secure wireless communication in active RIS-assisted DFRC systems
[J].DOI:10.1109/TVT.2024.3438151 [本文引用: 1]
混合智能反射面辅助的通信感知一体化: 高能效波束成形设计
[J].DOI:10.11999/JEIT230699 [本文引用: 1]
Hybrid reconfigurable intelligent surface assisted integrated sensing and communication: energy efficient beamforming design
[J].DOI:10.11999/JEIT230699 [本文引用: 1]
Capacity enhancement for reconfigurable intelligent surface-aided wireless network: from regular array to irregular array
[J].DOI:10.1109/TVT.2023.3236179 [本文引用: 1]
Multilayer irregular RIS-assisted wireless communication system performance optimization
[J].
DRL-based secrecy rate optimization for RIS-assisted secure ISAC systems
[J].DOI:10.1109/TVT.2023.3297602 [本文引用: 1]
Per-antenna constant envelope precoding for large multi-user MIMO systems
[J].DOI:10.1109/TCOMM.2013.012913.110827 [本文引用: 2]
Toward dual-functional radar-communication systems: optimal waveform design
[J].DOI:10.1109/TSP.2018.2847648 [本文引用: 1]
On probing signal design for MIMO radar
[J].DOI:10.1109/TSP.2007.894398 [本文引用: 2]
Two-timescale channel estimation for reconfigurable intelligent surface aided wireless communications
[J].DOI:10.1109/TCOMM.2021.3072729 [本文引用: 1]
Optimization by simulated annealing
[J].DOI:10.1126/science.220.4598.671 [本文引用: 1]
Cooling schedules for optimal annealing
[J].DOI:10.1007/978-1-4612-4808-8_42 [本文引用: 1]
Communication-efficient edge AI: algorithms and systems
[J].DOI:10.1109/COMST.2020.3007787 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}