

语言是人类社会互动的核心功能之一,但诸如脑卒中、脑瘫、肌萎缩侧索硬化症(amyotrophic lateral sclerosis, ALS)和喉癌等疾病不仅限制了患者的语言表达能力,还增加了其社交与心理健康负担[1-2]. 脑机接口(brain-computer interface, BCI)技术为语言障碍患者提供了一种新的交流途径[3-4]. BCI通过解码与语言相关的脑信号,将患者的语言意图转化为外部语音表达. 这种基于脑电图(electroencephalography, EEG)或侵入式皮层脑电图(electrocorticography, ECoG)信号的技术,利用大脑中的神经活动进行语音解码,适用于失去语言能力或肌肉控制的患者[5]. 通过分析语音产生过程中的脑电信号,可以有效地恢复个体的发声内容[6]. 然而在实际情况中,许多情境下个体并不一定发声,或者其无法发声. 如何从无声语音和想象语音产生的脑电信号中提取有效信息,并进行精确解码,成为当前脑机接口研究的重要问题之一.
隐性语音解码面临的主要挑战在于其神经信号特征表现出强非线性、高度个体差异性、低信噪比等特点. 分类器承担着从这类复杂信号中提取有效特征并实现准确分类的关键任务. 传统脑电解码中广泛使用的有线性判别分析(linear discriminant analysis,LDA)、支持向量机(support vector machines,SVM)、高斯过程分类(Gaussian process classification,GPC)等经典分类器. LDA在信噪比较高、特征线性可分的显性语音场景中表现良好[7],但面对想象语音这种非线性强、噪声干扰显著的特征空间时判别能力骤降. 虽然SVM通过核技巧可捕获部分非线性特征,但噪声和残留伪影仍会导致其分类平面偏移进而降低准确率[8]. GPC受限于贝叶斯推断的高计算复杂度,难以适配大规模脑电数据集[9]. 朴素贝叶斯(naive Bayes classification,NBC)因强独立假设易受噪声与小样本扰动影响[10]. 可见传统方法在鲁棒性和泛化能力方面的局限.
深度学习通过神经网络的多层非线性映射机制,能够自适应地提取脑电信号中的高阶时空特征. 相较于传统浅层模型,深度学习在应对信号非线性及噪声鲁棒性方面展现出独特优势. Abdulg hani等[11]提出基于小波散射变换的想象语音分类方法,使用低成本8通道EEG设备实现对“上、下、左、右”4类指令的92.5%的分类准确率. Qi等[12]提出基于双神经网络的想象语音分类算法,利用短时傅里叶变换提取特征,通过双分支的卷积神经网络和k-NN分类器进行分类. Gasparini等[13]研究通过EEG信号进行想象语音识别,采用功率谱密度(power spectral density,PSD)方法来提取EEG信号的频率特征,并使用主成分分析(principal component analysis,PCA)进一步减少特征维度,之后采用BiLSTM架构来进行训练. Park等[14]提出结合噪声辅助多变量经验模态分解(NA-MEMD)和多接收场卷积神经网络(MRF-CNN)的方法,对包含5个元音和1个静息状态的想象语音EEG信号进行多分类. Vorontsova等[15]基于EEG的无声语音识别,并提出结合卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN)的混合模型,实现对9个单词的85%的分类准确率. Chen等[16]旨在通过ECoG解码人类的语音,其核心内容包括将大脑皮层的ECoG信号转化为可解释的语音参数,并通过差分语音合成器将这些语音参数转换为语音频谱图.
由上述文献可知,现有脑电语音解码方法多局限于同类型语音分类,尤其在隐性语音任务中,常受到样本数量有限以及信号表征不稳定等因素的限制,难以充分利用脑电信号中所包含的时序变化和语义相关信息. 已有研究表明显性语音和隐性语音在语义与时序模式上具有一定内在关联性[17-18],但这一特性在现有方法中尚未得到充分利用. 针对上述问题,本研究提出多尺度注意力时序编码网络(Multi-scale Attention Temporal Encoding Network,MATE-Net)来学习显性语音数据中的底层语义和动态信息,从而实现对隐性语音的有效解码. 该网络通过 Inception 多感受野结构提取不同时间尺度下的脑电特征,结合双向门控循环单元(gate recurrent unit, GRU)对长时序依赖进行建模,并利用残差连接机制提升深层网络训练的稳定性;同时,引入多头注意力机制以增强对关键时序特征的建模能力. 该方法可以缓解隐性语音数据稀缺的问题,也为脑电解码研究提供了新的思路.
1. 本研究方法
1.1. 流程概述
利用显性语音(overt speech)作为训练阶段的主要输入,原因在于显性语音产生时,大脑皮层会激活更丰富、更清晰的语言相关神经通路,从而在EEG信号中留下较为强烈的时频特征. 基于此,先从显性语音和其对应的脑电信号中提取特征,再将所学到的表征迁移到无声语音(whispered speech)和想象语音(imagined speech)上,可以在跨语音类型的解码任务中取得更好的表现. 如图1所示展示了本研究方法的整体流程,可以分为2个阶段:显性语音解码阶段和隐性语音解码阶段.
图 1
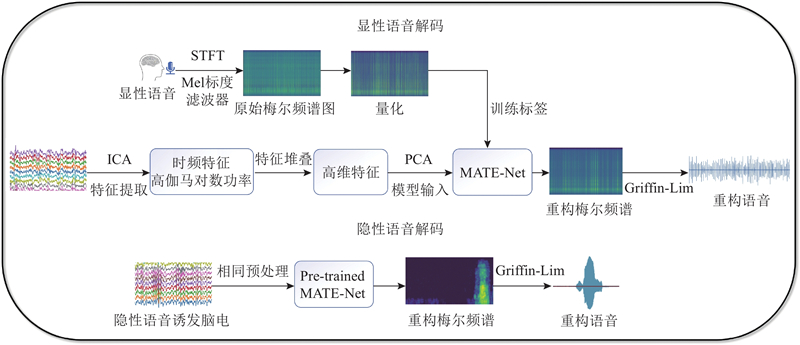
在显性语音解码阶段,首先通过短时傅里叶变换和梅尔标度滤波器生成显性语音的梅尔频谱图. 梅尔频谱图能够在时频域上贴近人耳听觉感知地刻画语音能量分布,从而更好地保留语言关键信息. 为了减少频谱值的噪声敏感性,采用Sigmoid量化算法将梅尔频谱图分为设定的能级(本研究中为9个能级),每个能级区间的初始代表值及边界表达式如下:
式中:
随后采用迭代算法对量化结果进行优化. 将归一化后的数据映射到上述区间内,然后通过如下公式不断更新每个区间的代表值
式中:
为了确保EEG数据的准确性,首先采用独立成分分析(independent component analysis, ICA)对与显性语音同步采集的EEG信号进行预处理,以剔除眼动和肌电伪影. 随后,从中提取时域与频域特征. 其中,时域特征(包括均值、标准差、峰值、最小值、峰峰值以及零交叉率)能够有效地反映信号的波动幅度、中心位置及变化速率,而频域特征(如主频率、频谱偏度和频谱峰度)则提供了关于信号频率分布的详细信息,主频率表征了信号中功率最大的频率成分,频谱偏度和峰度则进一步刻画了频谱的对称性和尖锐程度. 研究表明高伽马带(65~150 Hz)信号与认知功能及注意力调节密切相关[19],本研究采用带通滤波器提取该频段信号,并通过对数功率计算其能量分布. 对数功率被用来衡量该频段的能量分布,计算公式如下:
式中:
为了捕捉局部时间段内的细微变化,采用滑动窗口技术将EEG信号分割为若干小段,并对各段特征进行堆叠,从而在较高维度上综合反映多时刻信息. 最后对特征进行标准化后利用PCA[20]进行降维,保留了40个主要成分,显著减少了输入特征的维度,同时最大限度地保留了数据的主要信息. 被处理并降维后的EEG特征被输入到本研究所提的MATE-Net模型中,用以学习从EEG表征到梅尔频谱图的映射关系. 在训练完成后,网络输出重构的梅尔频谱图,再通过迭代 Griffin-Lim 算法将其转换为语音波形,实现从EEG到语音的闭环解码.
在隐性语音解码阶段,特征提取流程与显性语音的一致,同样先利用ICA进行伪影去除,然后提取高伽马频段特征并计算相应的时域和频域统计特征,之后利用PCA降维. 由于隐性语音缺乏对应的声学参考,解码时直接将降维后的特征输入至已经在显性语音任务上训练好的MATE-Net中,从而生成隐性语音的梅尔谱并最终得到重构语音输出.
1.2. MATE-Net模型设计
图 2
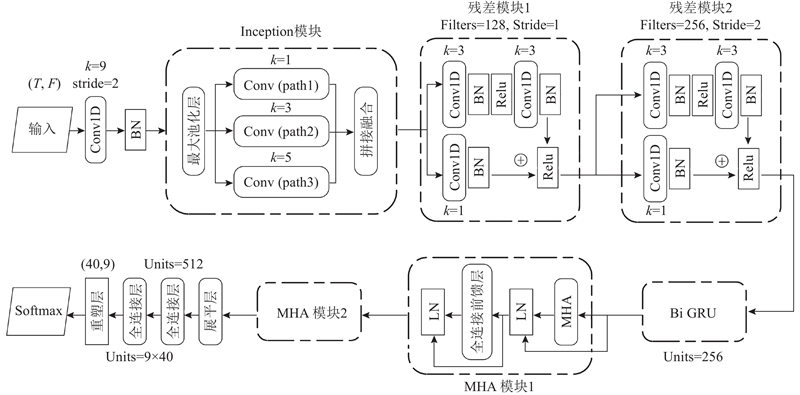
图 2 多尺度注意力时序编码网络(MATE-Net)的架构
Fig.2 Multi-scale Attention Temporal Encoding Network (MATE-Net) architecture
模型的输入数据以形状 (T,F) 表示时间步长和特征维度,经过一维卷积层(核大小为9,步幅为2)与批量归一化处理,有效地完成了初步的时序特征提取与数据标准化操作. 在这一基础上, Inception模块对数据进行多尺度特征捕捉,Inception模块设计了3条并行路径,分别采用卷积核大小为1、3和5的卷积操作. 这种结构通过多尺度感受野捕获不同层次的时空特征,并通过Concatenate将多路径卷积结果进行融合,保留各个尺度的信息冗余性,从而增强特征表示的丰富性和模型对局部细节的敏感性. 此后,特征经过最大池化层进一步降维,在减少冗余计算量的同时保留关键信息.
在深度特征提取阶段,引入残差块以提升模型的表达能力与训练稳定性. 第1个残差块使用128个卷积核,步幅为1,主要用于增强特征表达而不改变特征图尺寸;第2个残差块增加至256个卷积核,步幅为2,实现了特征通道的扩展与空间降采样. 残差连接有效缓解了梯度消失与爆炸问题,使信号能够直接从浅层传播到深层,同时保留了原始信息,这对于EEG数据中微弱但重要的特征保留尤为重要. 在残差块之后,特征进入时间卷积模块,通过连续的卷积操作与残差连接进一步建模时间序列中的局部依赖关系. 时间卷积模块和前面的残差块共同构成了网络的“主干”,为后续的时序建模和注意力机制提供了高质量的特征表示.
为了充分捕捉EEG的全局关联性,模型在特征提取后引入了双向GRU模块. 每个方向包含256个GRU单元,能够捕获丰富的时序动态特征. GRU相比传统LSTM更为轻量,具有更少的参数量,但仍保持了较强的长时依赖建模能力. 同时,通过空间Dropout操作[25],有效降低了过拟合风险,增强了模型的泛化能力. 其中 GRU 单元的更新机制表达式如下:
式中:
多头注意力机制的核心思想是允许模型在不同的表示子空间中并行地关注不同的信息模式. 在MATE-Net中,输入特征首先被投影到查询、键和值空间,然后通过缩放点积注意力计算权重并对值进行加权求和. 多头设计通过并行执行这一过程,引导每个头聚焦于特定的特征子空间,随后将各路输出拼接并经由线性层映射回原始维度. 之后这些输出经过前馈神经网络(feedforward neural network,FFN),通过2层线性变换和非线性激活,进一步增强了模型的特征转换能力.
通过Flatten操作将特征映射为一维向量,传入2个全连接层实现特征的高维表示与分类输出. 通过Reshape操作调整输出形状,确保其与任务需求相匹配,网络输出为概率张量
2. 实验设置与结果分析
2.1. 实验设置
本研究采用了一系列训练策略,解决训练中可能遇到的过拟合与训练不稳定问题. 优化器选择了AdamW,该优化器通过结合 Adam 的自适应学习率和 L2 权重衰减,有效控制了模型的复杂度和过拟合风险. 初始学习率设定为 1×10−4,并通过学习率调度器(learning rate scheduler)在训练过程中动态调整,以适应不同阶段的学习需求. 损失函数采用交叉熵损失和均方误差(MSE)的加权组合,旨在同时优化分类任务的精度和数值回归性能. 为了进一步提升模型的稳健性,在训练过程中引入多种正则化手段,包括 Dropout、空间丢弃和 Early Stopping 等策略. 监控验证集上的损失变化,当损失在若干轮次内未见显著改善时,训练过程将自动停止并恢复至最佳模型状态. 这种策略有效避免了过拟合,同时保证了训练的效率. 如表1所示为本次实验环境参数.
表 1 实验软硬件环境配置参数
Tab.1
| 环境名称 | 配置参数 |
| 系统 | Windows11 |
| CPU | Intel Core i9-14900KF |
| 主频 | 3.20 GHz |
| 内存 | 128 GB |
| GPU | NVIDIA RTX 4090D |
| 显存 | 24 GB |
| IDE环境 | Pycharm |
| 编译语言 | Python 3.10 |
2.2. 数据来源
脑电图数据来源于一名20岁女性癫痫患者,患者的母语为荷兰语,数据采集通过11个深度立体定向脑电图电极进行[26]. 实验任务分为3种语音表现方式:显性语音、无声语音和想象语音. 在显性语音阶段,患者会在显示器上看到一系列荷兰语单词,并根据屏幕指示大声朗读这些单词;而在无声语音阶段,患者则用无声语言进行表达(仅依靠口型动作);最后,在想象语音任务中,患者无需发出声音,通过脑部活动“想象”语音的发声. 每一组任务都由100个荷兰语单词组成,每个单词在屏幕上显示2 s,随后出现1 s的注视交叉符号.
2.3. 实验分析
为了保证模型的稳定性,使用五折交叉验证的方法进行训练,在有限的数据集下,将样本随机分为5个部分,选择其中4份作为训练集,剩下的1份作为测试集对模型进行测试,得到分类准确率. 最后,将得到的5个准确率取平均值作为模型的分类结果. 为了全面评估模型性能,选取了以下指标:训练集与测试集准确率(记为Acctrain和 Acctest)、均方误差(MSE)、余弦相似度(Scos)、Spearman 相关系数(ρ)以及 Pearson 相关系数(r).
首先用显性语音诱发的EEG信号进行训练. 设置训练批次为25次,每批次训练数据大小为64,进行五折交叉验证实验,实验结果如表2所示. 可以看出,模型在五折交叉验证中表现出良好的一致性和稳定性. 训练集准确率在76.31%~76.38%的窄范围内波动,测试集准确率在74.00%~74.60%范围内. 训练集与测试集准确率之间的差异平均为2.03个百分点,这个适中的泛化间隙表明模型既有足够的拟合能力,又避免了严重的过拟合现象. MSE平均值为0.325,且各折之间波动较小(0.314~0.344),表明模型在数值预测层面具有稳定的精度. 考虑到梅尔频谱图的值域通常为0~1.0,0.325的MSE意味着预测值与真实值的平均绝对偏差约为
表 2 五折交叉验证的实验结果
Tab.2
| 折叠编号 | Acctrain/% | Acctest/% | MSE | Scos | ρ | r |
| Fold1 | 76.38 | 74.33 | 0.319 | 0.975 | 0.890 | 0.945 |
| Fold2 | 76.32 | 74.00 | 0.344 | 0.975 | 0.880 | 0.937 |
| Fold3 | 76.31 | 74.14 | 0.334 | 0.975 | 0.885 | 0.941 |
| Fold4 | 76.35 | 74.43 | 0.314 | 0.975 | 0.884 | 0.943 |
| Fold5 | 76.31 | 74.60 | 0.314 | 0.975 | 0.882 | 0.943 |
| 平均值 | 76.33 | 74.30 | 0.325 | 0.975 | 0.884 | 0.942 |
为了探究各个主要模块对整体模型性能的影响,本研究设计了模块消融实验. 一共构造了4个不同的模型,所有模型均在相同的数据集和预处理条件下进行训练和评估. 同样采用五折交叉验证,实验结果如表3所示.可以看出,只保留 Inception的模型1的准确率和相关系数均处于最低水平. 进一步加入残差模块后,准确率提升了10.44个百分点,Pearson相关系数提升了0.161. 这种显著的性能提升验证了残差连接在深层网络训练中的重要作用,不仅有效缓解了深层网络中的梯度消失和爆炸问题,还增强了对复杂特征的学习能力. 引入双向GRU后(模型3),准确率进一步提升4.69个百分点,Pearson相关系数提升0.098. 虽然提升幅度略小,但考虑到语音信号的强时序特性,GRU对于捕获长时依赖关系的作用不可忽视. 多头注意力机制的引入有助于实现全局特征聚合和关键特征加权,使得MATE-Net在准确率和Pearson相关系数上均达到了最佳水平. 另外可以观察到各模块的性能贡献并非简单的线性叠加. 残差连接带来的提升最为显著,这表明在脑电语音解码这一复杂任务中,网络深度的增加和梯度流的稳定性是性能提升的关键因素. GRU和注意力机制的贡献相对较小但不可或缺,它们在残差连接建立的稳定训练基础上,进一步精细化了时序特征的建模和关键信息的提取.
表 3 MATE-Net 关键模块对模型性能影响的消融实验结果
Tab.3
| 模型结构 | Acctrain/% | ρ | r |
| 模型1(保留Inception) | 53.46 | 0.609 | 0.634 |
| 模型2(保留Inception+残差) | 63.90 | 0.743 | 0.795 |
| 模型3(保留Inception+残差+GRU) | 68.59 | 0.829 | 0.893 |
| 模型4(MATE-Net) | 74.30 | 0.884 | 0.942 |
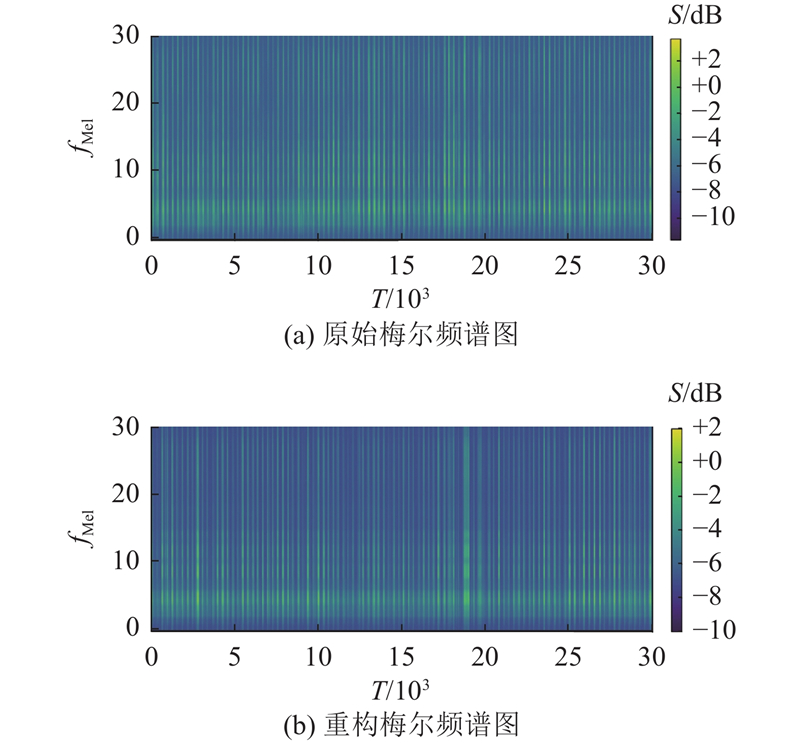
为了进一步验证MATE-Net模型的有效性,将本研究提出的模型与现有的多种模型进行对比实验,如表4所示. 实验结果表明,MATE-Net在评价指标上均表现出优势.通过可视化分析,对比模型生成的梅尔频谱图与原始频谱图,如图3所示. 其中,T表示时间帧索引, fMel表示梅尔频率通道索引,S表示梅尔频谱的对数功率分布. 可以看出,重构频谱在整体形态和主要特征上与原始频谱高度一致,特别是在低频段能量峰值的分布上,模型表现出较强的捕捉能力. 这表明模型能够从 EEG 数据中有效提取与语音频谱相关的关键信息. 但是细节特征的保留在高频区域略有不足,表现为预测频谱的平滑化和高频分辨率的下降,这可能是由于 EEG 信号中的高频信息较弱. 此外,预测频谱的动态范围相对较窄,能量对比度稍有减弱,反映了对细微能量变化的敏感性不足.
表 4 MATE-Net 与现有主流解码方法的性能对比
Tab.4
| 模型名称 | Acctrain/% | ρ | r |
| LDA | 56.61 | 0.645 | 0.661 |
| Logistic Regression | 55.39 | 0.640 | 0.658 |
| Decision Tree | 61.25 | 0.726 | 0.765 |
| Shallowconv[27] | 55.15 | 0.493 | 0.459 |
| deepconv[27] | 57.49 | 0.648 | 0.703 |
| EEGNet[27] | 58.31 | 0.541 | 0.570 |
| EEGItnet[28] | 54.66 | 0.532 | 0.542 |
| EEGTrans[29] | 59.46 | 0.683 | 0.713 |
| EEGTcNet[30] | 61.80 | 0.712 | 0.738 |
| EEGformer[31] | 64.39 | 0.813 | 0.872 |
| 平均值 | 74.30 | 0.884 | 0.942 |
图 3
为了进一步评估模型在词汇级别的重构能力,如图4所示,选取5个词语样本(“werd”,"mij”,“moment”,“mijn”,“maar”),对比分析其原始与重构频谱特征. 其中,f表示语音信号的物理频率. 这些片段的皮尔逊相关系数均超过0.71,最高达到 0.82,表明模型在从 EEG 数据中重建语音频谱方面表现较好. 整体来看,重构频谱与原始频谱在主要频段(0~4 kHz)的形态和时序上较为一致,显示出模型能够有效捕捉语音的核心特征. 但在高频段(4~8 kHz),重构频谱细节有所欠缺,表现为平滑化和细节丢失,同时伴有一定的噪声成分. 这可能是由于模型在高频细节和低能量特征捕捉上的能力不足.
图 4
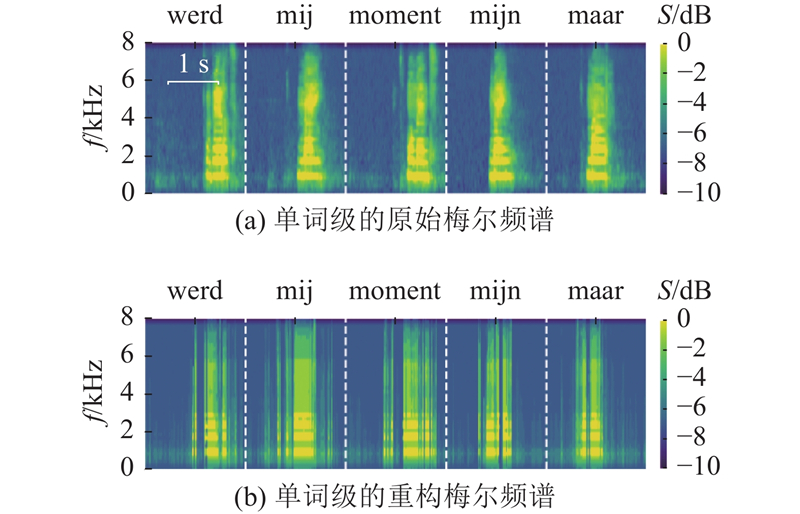
图 4 单词级的原始梅尔频谱图和重构梅尔频谱图对比
Fig.4 Comparison of original Mel spectrogram and reconstructed Mel spectrogram at word level
如图5所示展示了原始音频波形与模型重构的波形. 其中,T表示物理时间,A表示归一化振幅. 整体上,模型能够较好地捕捉到原始音频的主要振幅模式和周期性特征,特别是在 0~150 s内,两者的波形变化趋势相似,表明模型对时域信息的重建能力较强. 然而重构波形在振幅上略有偏差,表现为局部过度放大,尤其在高振幅区域. 细节上,重构波形较为平滑,高频细节的捕捉较弱,这可能与 EEG 数据在高频信息上的表达局限有关. 尽管如此,波形的主要峰谷位置大体保持一致,显示出良好的一致性.
图 5
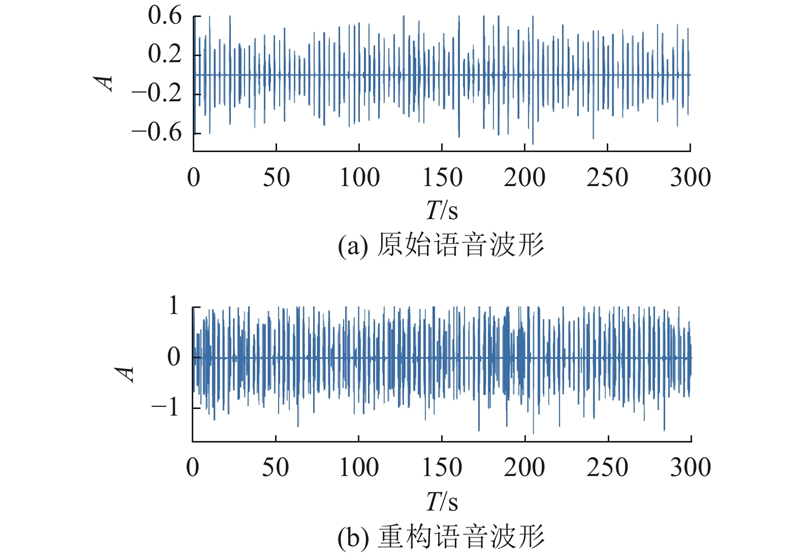
图 5 原始语音波形和重构语音波形对比
Fig.5 Comparison of original and reconstructed speech waveforms
为了进一步验证MATE-Net模型的泛化能力,使用了文献[32]中的数据集. 数据集包含3名受试者(P1,16岁男性;P2,20岁女性;P3,40岁男性). 在实验中,受试者在电脑屏幕上观看了来自Mozilla Common Voice荷兰语语料库的100个句子(句子长度为5~7个单词),并在每个句子后面有2 s的休息间隔. 神经数据以
表 5 跨数据集对比实验结果
Tab.5
| 模型名称 | Acctrain (P1/P2/P3)/% | ρ(P1/P2/P3) | r(P1/P2/P3) |
| LDA | 32.27 / 33.60 / 33.49 | 0.478 / 0.457 / 0.487 | 0.472 / 0.439 / 0.448 |
| Decision Tree | 45.55 / 46.92 / 45.01 | 0.581 / 0.593 / 0.571 | 0.582 / 0.602 / 0.570 |
| EEGformer | 54.34 / 53.50 / 54.79 | 0.781 / 0.783 / 0.766 | 0.782 / 0.789 / 0.770 |
| MATE-Net | 68.72 / 67.80 / 66.99 | 0.937 / 0.905 / 0.922 | 0.938 / 0.907 / 0.924 |
与解码显性语音不同,对于隐性语音,参与采集数据集的患者仅产生了几乎无法察觉的声音,这一声音低于麦克风的灵敏度. 因此,无法提供用于比较合成语音与实际语音的参考. 但是有73个单词同时存在于显性语音数据集和无声语音数据集,75个单词同时存在于显性语音数据集和想象语音数据集中. 尽管实验数据在时间上未严格对齐,但仍可对实际发音特征进行对比分析. 首先从音频信号中提取梅尔频谱图,接着转换为对数尺度(dB),以便更好地符合人类听觉系统的感知特性,而且对数变换有助于压缩信号的动态范围,并降低异常值的影响. 为了处理显性和隐性语音信号在时间轴上的不同步问题,本研究采用动态时间规整(DTW)算法. DTW算法能够计算2条时间序列之间的最小距离,并生成一个最佳匹配路径,使得2个序列在时间上对齐. DTW的计算过程表达式如下:
式中:
值得一提的是,在把梅尔能量谱转换到对数(dB)域时,会出现 NaN 和无穷值. 该转换通过如下公式进行:
式中:
当梅尔频谱中存在零值或接近零的功率分量时,对数函数
在对显性和隐性语音信号进行DTW对齐后,通过皮尔逊相关系数衡量两者之间的线性相关性. 依旧是选取表现较好的EEGFformer模型进行对比实验,结果如表6所示. 其中, Pearson 相关系数的平均值与中位数分别记为Mean r和Median r. 实验数据表明,MATE-Net 在无声与想象语音的解码上整体优于EEGformer,其Pearson相关系数在均值和中位数2个指标上均更高. 另外,观察到想象语音的平均相关系数略高于无声语音的,这一现象可能与想象语音时大脑的激活模式更接近于显性语音有关. 实验中发现有部分词汇表现良好,其Pearson相关系数大于0.8,但同时存在一些表现特别差的词汇样本,因此拉低了整体均值. 这种分布特征表明模型在某些特定词汇或音韵模式上可能存在迁移困难. 如图6所示展示了2个隐性语音重构的梅尔频谱图和语音波形,可以看到隐性语音的能量分布更弱且频带更窄,但波形与显性语音仍保持一定的相似性. 综合上述定量与定性分析可知,由显性语音训练的模型可以较为成功地对隐性语音的波形重构,说明该模型在隐性语音的解码上具有一定的有效性.
表 6 显性语音与隐性语音的相关性
Tab.6
| 模型名称 | Mean r(无声/想象) | Median r(无声/想象) |
| EEGformer | 0.313 / 0.366 | 0.352 / 0.391 |
| MATE-Net | 0.376 / 0.449 | 0.437 / 0.467 |
图 6
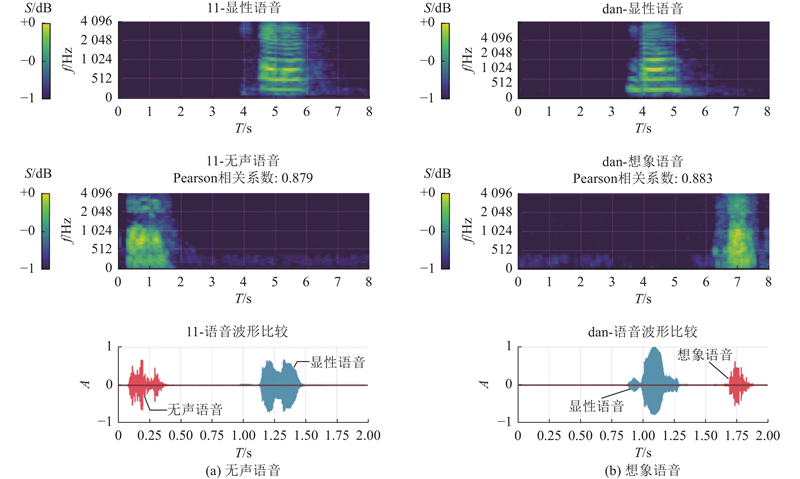
图 6 显性语音与隐性语音的频谱和波形对比
Fig.6 Spectral and waveform comparison between overt and covert speech
3. 结 语
隐性语音的脑电信号存在特征复杂、个体差异大、样本获取困难等特点,针对上述问题,提出多尺度注意力时序编码网络(MATE-Net). 利用显性语音的相对丰富的数据资源,采用迁移学习策略缓解隐性语音样本稀缺的问题,提升模型在隐性语音重构任务中的泛化能力与适应性. 为了增强模型的语义建模与时序特征提取能力,MATE-Net在结构上引入Inception多感受野模块以提取多尺度信息,采用双向GRU结构建模时序上下文依赖,引入多头注意力机制以增强模型对关键语义特征的关注,同时结合残差连接以保障深层网络训练稳定性. 实验结果表明,该模型在显性语音解码任务中的准确率达到74.30%,生成语音频谱与真实信号之间的余弦相似度高达0.975. 在隐性语音重构任务中,无声语音与想象语音的频谱相关系数分别为0.376和0.449,说明MATE-Net能够在一定程度上完成跨语音类型的语义迁移与频谱还原.
尽管本研究取得了较为理想的实验结果,但仍存在局限性. 本研究的数据来源于特定的临床环境,与健康人群或其他疾病患者的脑电特征可能存在差异. 在特征提取方面,虽然采用了多尺度特征融合策略,但对于高频段的细节重构能力仍显不足,表现为频谱平滑化和高频分辨率下降. 对于隐性语音任务,由于缺乏真实的声学参考,评估主要依赖于与显性语音的相关性分析,这种间接评估方式可能无法全面反映重构质量. 后续研究可对数据集进行扩展,建立多受试者的大规模脑电语音数据库. 另外,可在模型架构上进行优化,提升对高层语义的建模能力.
参考文献
What are the important factors in health-related quality of life for people with aphasia? a systematic review
[J].DOI:10.1016/j.apmr.2011.05.028 [本文引用: 1]
The spectrum of cognitive dysfunction in amyotrophic lateral sclerosis: an update
[J].DOI:10.3390/ijms241914647 [本文引用: 1]
基于卷积神经网络的多类运动想象脑电信号识别
[J].
Recognition of multi class motor imagery EEG signals based on convolutional neural network
[J].
Effect of brain-computer interface training on functional recovery after stroke
[J].DOI:10.54254/2753-8818/21/20230821 [本文引用: 1]
Stable decoding from a speech BCI enables control for an individual with ALS without recalibration for 3 months
[J].DOI:10.1002/advs.202304853 [本文引用: 1]
Speech synthesis from neural decoding of spoken sentences
[J].DOI:10.1038/s41586-019-1119-1 [本文引用: 1]
Application of continuous wavelet transform and support vector machine for autism spectrum disorder electroencephalography signal classification
[J].DOI:10.32620/reks.2023.3.07 [本文引用: 1]
Scalable Gaussian process classification with additive noise for non-Gaussian likelihoods
[J].DOI:10.1109/TCYB.2020.3043355 [本文引用: 1]
Complement-class harmonized Naïve Bayes classifier
[J].DOI:10.3390/app13084852 [本文引用: 1]
Imagined speech classification using EEG and deep learning
[J].DOI:10.3390/bioengineering10060649 [本文引用: 1]
Multiclass classification of imagined speech EEG using noise-assisted multivariate empirical mode decomposition and multireceptive field convolutional neural network
[J].DOI:10.3389/fnhum.2023.1186594 [本文引用: 1]
Silent EEG-speech recognition using convolutional and recurrent neural network with 85% accuracy of 9 words classification
[J].DOI:10.3390/s21206744 [本文引用: 1]
A neural speech decoding framework leveraging deep learning and speech synthesis
[J].DOI:10.1038/s42256-024-00824-8 [本文引用: 1]
Word pair classification during imagined speech using direct brain recordings
[J].DOI:10.1038/srep25803 [本文引用: 1]
Feasibility of decoding covert speech in ECoG with a Transformer trained on overt speech
[J].DOI:10.1038/s41598-024-62230-9 [本文引用: 1]
High gamma power is phase-locked to theta oscillations in human neocortex
[J].DOI:10.1126/science.1128115 [本文引用: 1]
Principal component analysis
[J].DOI:10.1002/wics.101 [本文引用: 1]
Dropout: a simple way to prevent neural networks from overfitting
[J].
Real-time synthesis of imagined speech processes from minimally invasive recordings of neural activity
[J].DOI:10.1038/s42003-021-02578-0 [本文引用: 1]
EEGNet: a compact convolutional neural network for EEG-based brain–computer interfaces
[J].DOI:10.1088/1741-2552/aace8c [本文引用: 3]
EEG-ITNet: an explainable inception temporal convolutional network for motor imagery classification
[J].DOI:10.1109/ACCESS.2022.3161489 [本文引用: 1]
EEGformer: a transformer-based brain activity classification method using EEG signal
[J].DOI:10.3389/fnins.2023.1148855 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}