[1]
HAN C, O’SULLIVAN J, LUO Y, et al Speaker-independent auditory attention decoding without access to clean speech sources
[J]. Science Advances , 2019 , 5 (5 ): eaav6134
DOI:10.1126/sciadv.aav6134
[本文引用: 1]
[2]
MONESI M J, ACCOU B, MONTOYA-MARTINEZ J, et al. An LSTM based architecture to relate speech stimulus to eeg [C]// ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing . Barcelona: IEEE, 2020: 941–945.
[3]
CAI S, SU E, XIE L, et al EEG-based auditory attention detection via frequency and channel neural attention
[J]. IEEE Transactions on Human-Machine Systems , 2021 , 52 (2 ): 256 - 266
[本文引用: 1]
[4]
HWANG H J, KIM S, CHOI S, et al EEG-based brain-computer interfaces: a thorough literature survey
[J]. International Journal of Human-Computer Interaction , 2013 , 29 (12 ): 814 - 826
DOI:10.1080/10447318.2013.780869
[本文引用: 1]
[5]
CEOLINI E, HJORTKJÆR J, WONG D D E, et al Brain-informed speech separation (BISS) for enhancement of target speaker in multitalker speech perception
[J]. NeuroImage , 2020 , 223 : 117282
DOI:10.1016/j.neuroimage.2020.117282
[本文引用: 1]
[6]
DE TAILLEZ T, KOLLMEIER B, MEYER B T Machine learning for decoding listeners’ attention from electroencephalography evoked by continuous speech
[J]. European Journal of Neuroscience , 2020 , 51 (5 ): 1234 - 1241
DOI:10.1111/ejn.13790
[本文引用: 1]
[7]
THORNTON M, MANDIC D, REICHENBACH T Robust decoding of the speech envelope from EEG recordings through deep neural networks
[J]. Journal of Neural Engineering , 2022 , 19 (4 ): 046007
DOI:10.1088/1741-2552/ac7976
[本文引用: 1]
[8]
SOMERS B, VERSCHUEREN E, FRANCART T Neural tracking of the speech envelope in cochlear implant users
[J]. Journal of Neural Engineering , 2019 , 16 (1 ): 016003
DOI:10.1088/1741-2552/aae6b9
[本文引用: 1]
[9]
WANG L, WU E X, CHEN F EEG-based auditory attention decoding using speech-level-based segmented computational models
[J]. Journal of Neural Engineering , 2021 , 18 (4 ): 046066
DOI:10.1088/1741-2552/abfeba
[本文引用: 1]
[10]
XU Z, BAI Y, ZHAO R, et al Auditory attention decoding from EEG-based Mandarin speech envelope reconstruction
[J]. Hearing Research , 2022 , 422 : 108552
DOI:10.1016/j.heares.2022.108552
[本文引用: 1]
[11]
ZHU H, CAI S, JIANG Y, et al. EEG-derived voice signature for attended speaker detection [EB/OL]. (2023−08−29) [2025−12−25]. https://doi.org/10.48550/arXiv.2308.14774.
[本文引用: 1]
[12]
王春丽, 李金絮, 高玉鑫, 等 一种基于时空频多维特征的短时窗口脑电听觉注意解码网络
[J]. 电子与信息学报 , 2025 , 47 (3 ): 814 - 824
DOI:10.11999/JEIT240867
[本文引用: 1]
WANG Chunli, LI Jinxu, GAO Yuxin, et al A short-time window ElectroEncephaloGram auditory attention decoding network based on multi-dimensional characteristics of temporal-spatial-frequency
[J]. Journal of Electronics and Information Technology , 2025 , 47 (3 ): 814 - 824
DOI:10.11999/JEIT240867
[本文引用: 1]
[13]
CAI S, SUN P, SCHULTZ T, et al. Low-latency auditory spatial attention detection based on spectro-spatial features from EEG [C]// 43rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society . Mexico: IEEE, 2021: 5812-5815.
[本文引用: 2]
[14]
XIE Z, WEI J, LU W, et al. EEG-based fast auditory attention detection in real-life scenarios using time-frequency attention mechanism [C]// 2024 IEEE International Conference on Acoustics, Speech and Signal Processing . Seoul: IEEE, 2024: 1741–1745.
[本文引用: 1]
[15]
JIANG Z, AN X, LIU S, et al Neural oscillations reflect the individual differences in the temporal perception of audiovisual speech
[J]. Cerebral Cortex , 2023 , 33 (20 ): 10575 - 10583
DOI:10.1093/cercor/bhad304
[本文引用: 1]
[16]
FRIESE U, DAUME J, GÖSCHL F, et al Oscillatory brain activity during multisensory attention reflects activation, disinhibition, and cognitive control
[J]. Scientific Reports , 2016 , 6 : 32775
DOI:10.1038/srep32775
[本文引用: 1]
[17]
POPOV T, KASTNER S, JENSEN O FEF-controlled alpha delay activity precedes stimulus-induced gamma-band activity in visual cortex
[J]. The Journal of Neuroscience , 2017 , 37 (15 ): 4117 - 4127
DOI:10.1523/JNEUROSCI.3015-16.2017
[本文引用: 1]
[18]
LIU Y J, YU M, ZHAO G, et al Real-time movie-induced discrete emotion recognition from EEG signals
[J]. IEEE Transactions on Affective Computing , 2018 , 9 (4 ): 550 - 562
DOI:10.1109/TAFFC.2017.2660485
[本文引用: 1]
[19]
KAUSAR T, LU Y, ASGHAR M A, et al Auditory-GAN: deep learning framework for improved auditory spatial attention detection
[J]. PeerJ Computer Science , 2024 , 10 : e2394
DOI:10.7717/peerj-cs.2394
[本文引用: 1]
[20]
DAS N, FRANCART T, BERTRAND A Auditory attention detection dataset KUL euven
[J]. Zenodo , 2020 , 25 (5 ): 402 - 412
[本文引用: 1]
[21]
GEIRNAERT S, FRANCART T, BERTRAND A Fast EEG-based decoding of the directional focus of auditory attention using common spatial patterns
[J]. IEEE Transactions on Bio-Medical Engineering , 2021 , 68 (5 ): 1557 - 1568
DOI:10.1109/TBME.2020.3033446
[本文引用: 1]
[23]
FUGLSANG S A, WONG D D E, HJORTKJAER J. EEG audio dataset for auditory attention decoding [EB/OL]. [2025−12−25]. https://doi.org/10.5281/zenodo. 1199011.
[本文引用: 1]
[24]
CICCARELLI G, NOLAN M, PERRICONE J, et al Comparison of two-talker attention decoding from EEG with nonlinear neural networks and linear methods
[J]. Scientific Reports , 2019 , 9 : 11538
DOI:10.1038/s41598-019-47795-0
[本文引用: 1]
[25]
ZHANG Z, ZHANG G, DANG J, et al. EEG-based short-time auditory attention detection using multi-task deep learning [C]// Interspeech 2020 . ISCA: 2020: 2517-2521.
[26]
VANDECAPPELLE S, DECKERS L, DAS N, et al EEG-based detection of the locus of auditory attention with convolutional neural networks
[J]. eLife , 2021 , 10 : e56481
DOI:10.7554/eLife.56481
[本文引用: 2]
[27]
FU Z, WANG B, WU X, et al. Auditory attention decoding from EEG using convolutional recurrent neural network [C]// 29th European Signal Processing Conference . Dublin: IEEE, 2021: 970–974.
[本文引用: 1]
[28]
ZION GOLUMBIC E M, DING N, BICKEL S, et al Mechanisms underlying selective neuronal tracking of attended speech at a “cocktail party”
[J]. Neuron , 2013 , 77 (5 ): 980 - 991
DOI:10.1016/j.neuron.2012.12.037
[本文引用: 1]
[29]
MIZOKUCHI K, TANAKA T, SATO T G, et al Alpha band modulation caused by selective attention to music enables EEG classification
[J]. Cognitive Neurodynamics , 2024 , 18 (3 ): 1005 - 1020
DOI:10.1007/s11571-023-09955-x
[本文引用: 1]
[30]
SU E, CAI S, LI P, et al. Auditory attention detection with EEG channel attention [C]// 43rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society . Mexico: IEEE, 2021: 5804−5807.
[本文引用: 1]
[31]
CAI S, LI P, SU E, et al A neural-inspired architecture for EEG-based auditory attention detection
[J]. IEEE Transactions on Human-Machine Systems , 2022 , 52 (4 ): 668 - 676
DOI:10.1109/THMS.2022.3176212
[本文引用: 1]
Speaker-independent auditory attention decoding without access to clean speech sources
1
2019
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
EEG-based auditory attention detection via frequency and channel neural attention
1
2021
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
EEG-based brain-computer interfaces: a thorough literature survey
1
2013
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
Brain-informed speech separation (BISS) for enhancement of target speaker in multitalker speech perception
1
2020
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
Machine learning for decoding listeners’ attention from electroencephalography evoked by continuous speech
1
2020
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
Robust decoding of the speech envelope from EEG recordings through deep neural networks
1
2022
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
Neural tracking of the speech envelope in cochlear implant users
1
2019
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
EEG-based auditory attention decoding using speech-level-based segmented computational models
1
2021
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
Auditory attention decoding from EEG-based Mandarin speech envelope reconstruction
1
2022
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
1
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
一种基于时空频多维特征的短时窗口脑电听觉注意解码网络
1
2025
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
一种基于时空频多维特征的短时窗口脑电听觉注意解码网络
1
2025
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
2
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
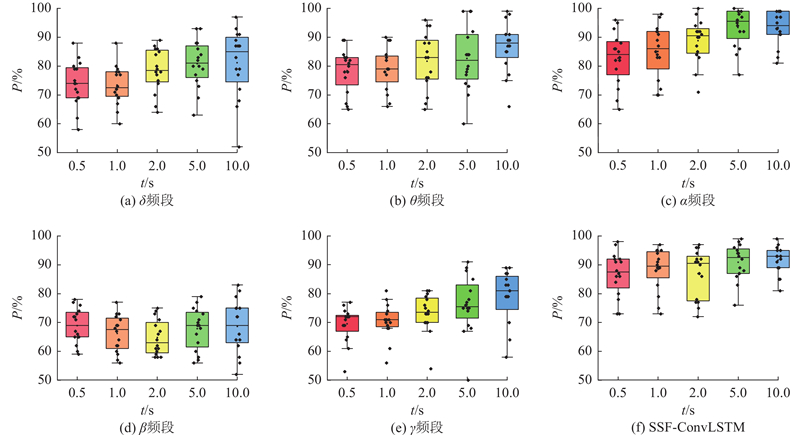
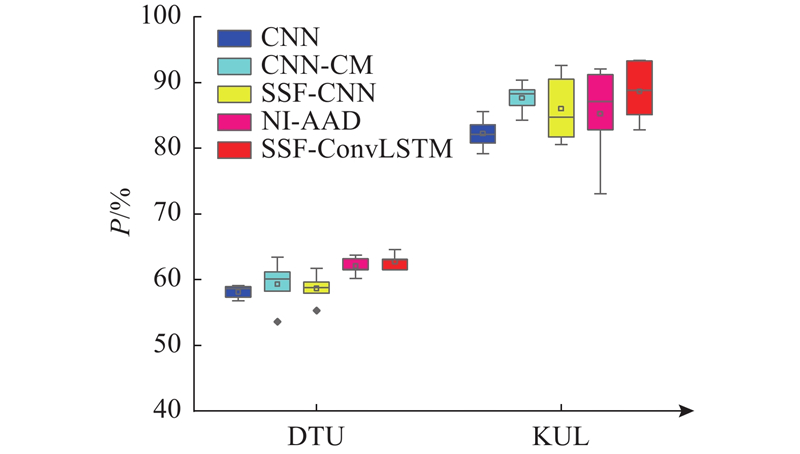
... 通过对比CNN[26 ] 、CNN-CM[30 ] 、SSF-CNN[13 ] 、NI-AAD[31 ] 、SSF-ConvLSTM这5种模型在2个数据集下$\alpha $ 图7 所示. 结果表明,KUL数据集上的解码精度相比于DTU整体较高. 在KUL数据集上,CNN模型平均解码精度为82.26%(SD:1.87%),在0.5 s下的解码精度达到最低仅为79.2%(SD:2.34%),在10.0 s下达到85.6%(SD:1.98%)的解码精度;SSF-CNN平均准确率为86.02%(SD:4.42%),NI-AAD模型平均准确率为85.26(SD:5.85%),本研究提出的SSF-ConvLSTM平均准确率为88.66%(SD:3.80%),在10.0 s的决策窗口下达到最高的解码精度92.1%(SD:5%),较CNN提高6.40个百分点,较SSF-CNN提高2.64个百分点;在DTU数据集上,SSF-CNN模型平均准确率为59.10%(SD:1.24%),NI-AAD平均准确率为62.04%(SD:1.13%),而SSF-ConvLSTM平均解码精度达到63.04%(SD:0.85%),在10.0 s决策窗口下达到64.6%(SD:3.32%),较CNN提升5.5个百分点. 综合2个数据集实验结果,$\alpha $ $\alpha $
1
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
Neural oscillations reflect the individual differences in the temporal perception of audiovisual speech
1
2023
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
Oscillatory brain activity during multisensory attention reflects activation, disinhibition, and cognitive control
1
2016
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
FEF-controlled alpha delay activity precedes stimulus-induced gamma-band activity in visual cortex
1
2017
... 在复杂声学场景中,人类大脑能够通过选择性听觉注意力从多声源混合信号中精准分离并跟踪目标语音,这种能力对日常交流至关重要[1 -3 ] . 解码听觉注意力的神经机制不仅是认知神经科学的核心问题,更为开发脑机接口(brain-computer interface,BCI)辅助设备(如智能助听器)提供了理论基础[4 -5 ] . 近年来,基于脑电图的听觉注意力检测技术通过分析语音包络追踪取得显著进展[6 -7 ] . Somers等[8 ] 提出一种周期性中断电刺激的创新方法,在刺激间隙采集无伪迹EEG信号并训练线性解码器,首次在持续电刺激条件下验证了语音包络的神经追踪信号. Wang等[9 ] 提出分段AAD方法解码来自不同均方根级别的语音片段的目标语音包络方法,与统一解码器相比,所提出分段解码方法有更高的信息传输速率和更短的切换时间. Xu等[10 ] 提出基于LSTM的AAD框架,通过优化EEG通道选择与频带增强来提升注意力识别的准确性,在17通道构建的LSTM模型通过语音包络重建实现了74.29%的注意力解码精度. Zhu等[11 ] 提出脑电驱动的参与说话者检测方法(E-ASD),通过对比脑电图的语音包络与音频包络的相关性从而确定目标话者,在0.5 s决策窗口,达到最优解码精度. 王春丽等[12 ] 提出时空频多维特征的短时窗口脑电听觉注意解码网络,在1.0 s决策窗口下解码精度效果达到最佳. Cai等[13 ] 提出SSF-CNN架构,在5.0 s的决策窗口,解码精度达到81.7%. Xie等[14 ] 提出时频注意机制,采集受试者在真实场景中的脑电信号,在0.1 s时解码精度达到最好91.8%. 然而,这些方法普遍依赖全频段EEG信号解码,忽视了不同频段对听觉注意表征的特异性贡献. 传统AAD研究多基于宽频信号(如1~50 Hz)构建解码模型,但神经科学证据表明,听觉注意力的动态调控与特定频段的神经振荡密切相关[15 ] . 例如,$\alpha $ [16 -17 ] ,而$\theta $ $\beta $
Real-time movie-induced discrete emotion recognition from EEG signals
1
2018
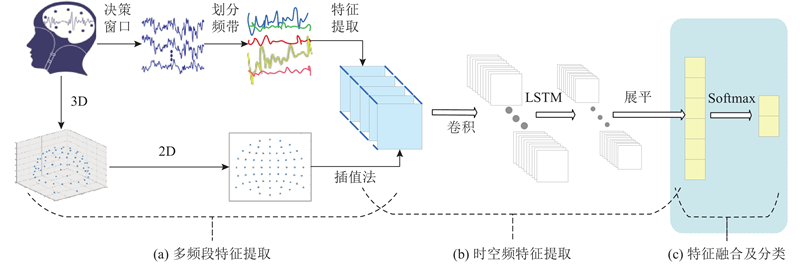
... 将原始EEG信号划分为多个决策窗口,通过带通滤波将决策窗口划分为5个不同的频带[18 ] . 在时间维度上,决策窗口采用 50% 重叠的滑动窗设计,以确保时间序列分析的连续性与数据完整性;频带维度则为固定频带划分,各频带间不存在重叠情况,以此实现频域特征的独立提取与分析. 对每个频带的时域信号进行快速傅里叶变换(fast Fourier transform,FFT),得到频域表示. 为了充分利用EEG信号的空间特性,将这些测量值映射到32×32的网格,堆叠5个频带的图形数据,从而形成时空频三维特征. 利用方位角投影技术将EEG电极从3D投影到2D来获取坐标的位置信息[19 ] ,为了确保所有点从中心精确散布,设置头顶中心为切点,保持中心点到所有投影的方位角与距离不变,以此来保留电极空间的相对位置;然后通过插值法将离散的功率谱测量值转换为连续信号平面;将平面划分为32×32的均匀网格,在每个网格点评估插值结果,形成二维图像. 由于获得的2D平面包含频谱和空间信息,称之为SSF图,这里总共生成5×32×32个SSF图. ...
Auditory-GAN: deep learning framework for improved auditory spatial attention detection
1
2024
... 将原始EEG信号划分为多个决策窗口,通过带通滤波将决策窗口划分为5个不同的频带[18 ] . 在时间维度上,决策窗口采用 50% 重叠的滑动窗设计,以确保时间序列分析的连续性与数据完整性;频带维度则为固定频带划分,各频带间不存在重叠情况,以此实现频域特征的独立提取与分析. 对每个频带的时域信号进行快速傅里叶变换(fast Fourier transform,FFT),得到频域表示. 为了充分利用EEG信号的空间特性,将这些测量值映射到32×32的网格,堆叠5个频带的图形数据,从而形成时空频三维特征. 利用方位角投影技术将EEG电极从3D投影到2D来获取坐标的位置信息[19 ] ,为了确保所有点从中心精确散布,设置头顶中心为切点,保持中心点到所有投影的方位角与距离不变,以此来保留电极空间的相对位置;然后通过插值法将离散的功率谱测量值转换为连续信号平面;将平面划分为32×32的均匀网格,在每个网格点评估插值结果,形成二维图像. 由于获得的2D平面包含频谱和空间信息,称之为SSF图,这里总共生成5×32×32个SSF图. ...
Auditory attention detection dataset KUL euven
1
2020
... 1) KUL数据集[20 -21 ] . 在此数据集中,采用BioSemi ActiveTwo系统收集16名听力正常的受试者(8名男性和8名女性)的64通道脑电信号,采样率为8192 Hz. 言语刺激由4个荷兰语故事构成,并由3名男性佛兰德语发音者叙述,所有刺激语音都被标准化为具有相同的均方根(root mean square,RMS)强度,被认为具有相同音效. 为了模拟真实场景中声音的方向性,采用2种方法来处理音频信号:一是通过头部相关传递函数(head related transfer functions,HRTF)进行滤波;二是采用二分法技术,即每只耳朵通过一个单独的扬声器播放,声源分别在受试者±90°方向. 实验中,每位受试者同时聆听2个不同说话者录制的语音,并被明确指示仅专注于其中一个说话者的语音,2个说话者的语音呈现顺序对于不同受试者是随机的. 每个受试者收听 8 次语音,每次试验的长度为 6 min,详细信息如表1 所示. 其中,N 为受试者的数量,t s 为每名受试者进行测试的时间,T 为16名受试者测试总时间. ...
Fast EEG-based decoding of the directional focus of auditory attention using common spatial patterns
1
2021
... 1) KUL数据集[20 -21 ] . 在此数据集中,采用BioSemi ActiveTwo系统收集16名听力正常的受试者(8名男性和8名女性)的64通道脑电信号,采样率为8192 Hz. 言语刺激由4个荷兰语故事构成,并由3名男性佛兰德语发音者叙述,所有刺激语音都被标准化为具有相同的均方根(root mean square,RMS)强度,被认为具有相同音效. 为了模拟真实场景中声音的方向性,采用2种方法来处理音频信号:一是通过头部相关传递函数(head related transfer functions,HRTF)进行滤波;二是采用二分法技术,即每只耳朵通过一个单独的扬声器播放,声源分别在受试者±90°方向. 实验中,每位受试者同时聆听2个不同说话者录制的语音,并被明确指示仅专注于其中一个说话者的语音,2个说话者的语音呈现顺序对于不同受试者是随机的. 每个受试者收听 8 次语音,每次试验的长度为 6 min,详细信息如表1 所示. 其中,N 为受试者的数量,t s 为每名受试者进行测试的时间,T 为16名受试者测试总时间. ...
Noise-robust cortical tracking of attended speech in real-world acoustic scenes
1
2017
... 2) DTU数据集[22 -23 ] . 采用Biosemi系统以512 Hz采样率收集18名受试者的64通道EEG数据,电极定位遵循10/20系统. 言语刺激由同时在无声或混响房间的3位男性和3位女性母语说话者语音组成,采用空间分离的双语音流刺激范式,2个独立音源分别呈现于受试者±60°水平方向,听觉刺激是通过ER-2耳机设置在60 db的,目标说话者的位置和性别在整个实验中都是随机分配的. 对每个受试者收集60次试验,每次50 s,详细信息见表1 . ...
1
... 2) DTU数据集[22 -23 ] . 采用Biosemi系统以512 Hz采样率收集18名受试者的64通道EEG数据,电极定位遵循10/20系统. 言语刺激由同时在无声或混响房间的3位男性和3位女性母语说话者语音组成,采用空间分离的双语音流刺激范式,2个独立音源分别呈现于受试者±60°水平方向,听觉刺激是通过ER-2耳机设置在60 db的,目标说话者的位置和性别在整个实验中都是随机分配的. 对每个受试者收集60次试验,每次50 s,详细信息见表1 . ...
Comparison of two-talker attention decoding from EEG with nonlinear neural networks and linear methods
1
2019
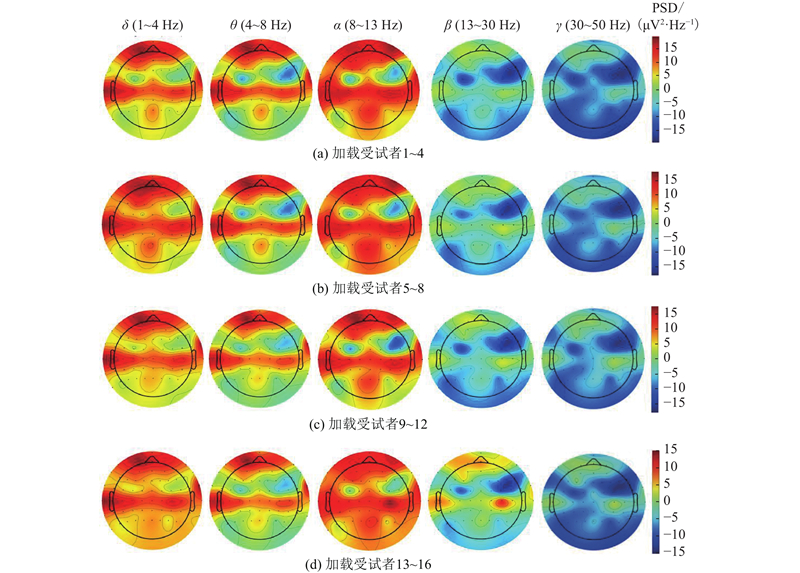
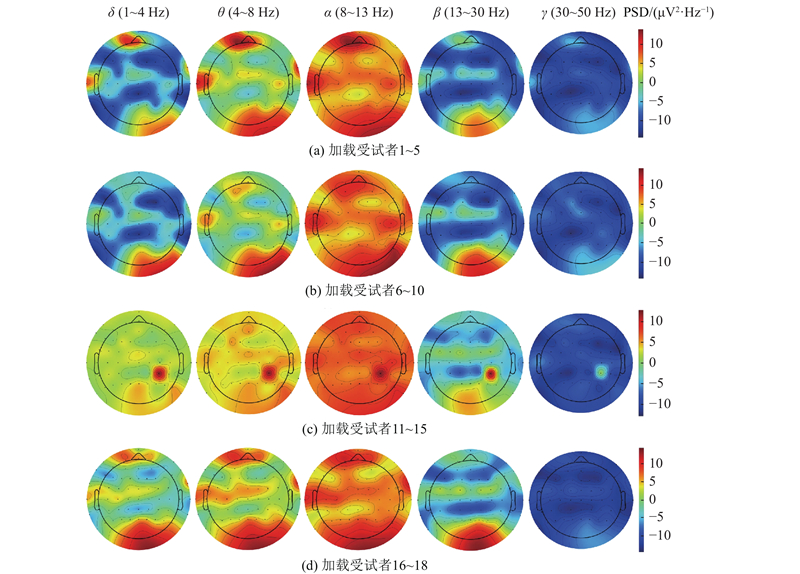
... 在脑地形图中,黑点代表电极的位置,用于采集大脑不同区域的电活动,脑电活动的强度可通过颜色来呈现,其中颜色的深浅与脑区活动强度成正比,即颜色越深,表明对应脑区的活动强度越大. 空间维度分析结果显示,低频段($\delta $ $\theta $ $\alpha $ ) 在前额叶和颞叶区域呈现显著激活,其中$\alpha $ $\beta $ $\gamma $ ) 则在前额叶和颞叶区域形成与听觉注意力解码密切相关的权重聚集区,该现象与听觉信息处理的层级加工理论相吻合. 从频率梯度演变来看,前额叶与颞叶权重随频率升高呈现非线性变换的趋势,其权重在$\alpha $ $\gamma $ $\alpha $ [24 -27 ] 也发现了这一区域的显著性. 也有一些研究发现了听觉注意过程中顶叶区域表现得较为活跃,这与本研究结果一致[26 ,28 ] . ...
EEG-based detection of the locus of auditory attention with convolutional neural networks
2
2021
... 在脑地形图中,黑点代表电极的位置,用于采集大脑不同区域的电活动,脑电活动的强度可通过颜色来呈现,其中颜色的深浅与脑区活动强度成正比,即颜色越深,表明对应脑区的活动强度越大. 空间维度分析结果显示,低频段($\delta $ $\theta $ $\alpha $ ) 在前额叶和颞叶区域呈现显著激活,其中$\alpha $ $\beta $ $\gamma $ ) 则在前额叶和颞叶区域形成与听觉注意力解码密切相关的权重聚集区,该现象与听觉信息处理的层级加工理论相吻合. 从频率梯度演变来看,前额叶与颞叶权重随频率升高呈现非线性变换的趋势,其权重在$\alpha $ $\gamma $ $\alpha $ [24 -27 ] 也发现了这一区域的显著性. 也有一些研究发现了听觉注意过程中顶叶区域表现得较为活跃,这与本研究结果一致[26 ,28 ] . ...
... 通过对比CNN[26 ] 、CNN-CM[30 ] 、SSF-CNN[13 ] 、NI-AAD[31 ] 、SSF-ConvLSTM这5种模型在2个数据集下$\alpha $ 图7 所示. 结果表明,KUL数据集上的解码精度相比于DTU整体较高. 在KUL数据集上,CNN模型平均解码精度为82.26%(SD:1.87%),在0.5 s下的解码精度达到最低仅为79.2%(SD:2.34%),在10.0 s下达到85.6%(SD:1.98%)的解码精度;SSF-CNN平均准确率为86.02%(SD:4.42%),NI-AAD模型平均准确率为85.26(SD:5.85%),本研究提出的SSF-ConvLSTM平均准确率为88.66%(SD:3.80%),在10.0 s的决策窗口下达到最高的解码精度92.1%(SD:5%),较CNN提高6.40个百分点,较SSF-CNN提高2.64个百分点;在DTU数据集上,SSF-CNN模型平均准确率为59.10%(SD:1.24%),NI-AAD平均准确率为62.04%(SD:1.13%),而SSF-ConvLSTM平均解码精度达到63.04%(SD:0.85%),在10.0 s决策窗口下达到64.6%(SD:3.32%),较CNN提升5.5个百分点. 综合2个数据集实验结果,$\alpha $ $\alpha $
1
... 在脑地形图中,黑点代表电极的位置,用于采集大脑不同区域的电活动,脑电活动的强度可通过颜色来呈现,其中颜色的深浅与脑区活动强度成正比,即颜色越深,表明对应脑区的活动强度越大. 空间维度分析结果显示,低频段($\delta $ $\theta $ $\alpha $ ) 在前额叶和颞叶区域呈现显著激活,其中$\alpha $ $\beta $ $\gamma $ ) 则在前额叶和颞叶区域形成与听觉注意力解码密切相关的权重聚集区,该现象与听觉信息处理的层级加工理论相吻合. 从频率梯度演变来看,前额叶与颞叶权重随频率升高呈现非线性变换的趋势,其权重在$\alpha $ $\gamma $ $\alpha $ [24 -27 ] 也发现了这一区域的显著性. 也有一些研究发现了听觉注意过程中顶叶区域表现得较为活跃,这与本研究结果一致[26 ,28 ] . ...
Mechanisms underlying selective neuronal tracking of attended speech at a “cocktail party”
1
2013
... 在脑地形图中,黑点代表电极的位置,用于采集大脑不同区域的电活动,脑电活动的强度可通过颜色来呈现,其中颜色的深浅与脑区活动强度成正比,即颜色越深,表明对应脑区的活动强度越大. 空间维度分析结果显示,低频段($\delta $ $\theta $ $\alpha $ ) 在前额叶和颞叶区域呈现显著激活,其中$\alpha $ $\beta $ $\gamma $ ) 则在前额叶和颞叶区域形成与听觉注意力解码密切相关的权重聚集区,该现象与听觉信息处理的层级加工理论相吻合. 从频率梯度演变来看,前额叶与颞叶权重随频率升高呈现非线性变换的趋势,其权重在$\alpha $ $\gamma $ $\alpha $ [24 -27 ] 也发现了这一区域的显著性. 也有一些研究发现了听觉注意过程中顶叶区域表现得较为活跃,这与本研究结果一致[26 ,28 ] . ...
Alpha band modulation caused by selective attention to music enables EEG classification
1
2024
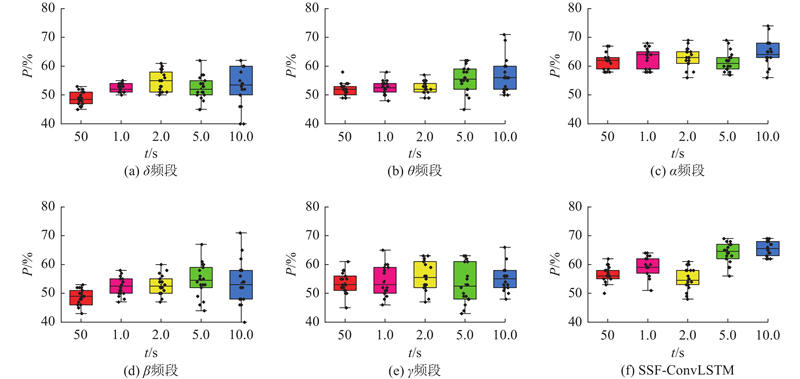
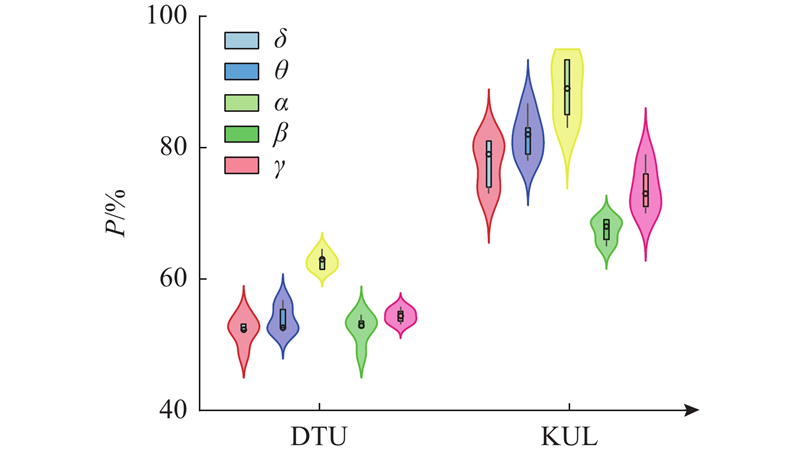
... 与此同时,构建五频带解码精度在KUL和DTU数据集上的演变趋势图,如图6 所示,揭示神经振荡频段与时间分辨间的动态耦合机制. 具体而言,$\alpha $ $\delta $ $\beta $ $\alpha $ [29 ] . 进一步研究发现,延长决策窗口长度可有效抑制$\alpha $
1
... 通过对比CNN[26 ] 、CNN-CM[30 ] 、SSF-CNN[13 ] 、NI-AAD[31 ] 、SSF-ConvLSTM这5种模型在2个数据集下$\alpha $ 图7 所示. 结果表明,KUL数据集上的解码精度相比于DTU整体较高. 在KUL数据集上,CNN模型平均解码精度为82.26%(SD:1.87%),在0.5 s下的解码精度达到最低仅为79.2%(SD:2.34%),在10.0 s下达到85.6%(SD:1.98%)的解码精度;SSF-CNN平均准确率为86.02%(SD:4.42%),NI-AAD模型平均准确率为85.26(SD:5.85%),本研究提出的SSF-ConvLSTM平均准确率为88.66%(SD:3.80%),在10.0 s的决策窗口下达到最高的解码精度92.1%(SD:5%),较CNN提高6.40个百分点,较SSF-CNN提高2.64个百分点;在DTU数据集上,SSF-CNN模型平均准确率为59.10%(SD:1.24%),NI-AAD平均准确率为62.04%(SD:1.13%),而SSF-ConvLSTM平均解码精度达到63.04%(SD:0.85%),在10.0 s决策窗口下达到64.6%(SD:3.32%),较CNN提升5.5个百分点. 综合2个数据集实验结果,$\alpha $ $\alpha $
A neural-inspired architecture for EEG-based auditory attention detection
1
2022
... 通过对比CNN[26 ] 、CNN-CM[30 ] 、SSF-CNN[13 ] 、NI-AAD[31 ] 、SSF-ConvLSTM这5种模型在2个数据集下$\alpha $ 图7 所示. 结果表明,KUL数据集上的解码精度相比于DTU整体较高. 在KUL数据集上,CNN模型平均解码精度为82.26%(SD:1.87%),在0.5 s下的解码精度达到最低仅为79.2%(SD:2.34%),在10.0 s下达到85.6%(SD:1.98%)的解码精度;SSF-CNN平均准确率为86.02%(SD:4.42%),NI-AAD模型平均准确率为85.26(SD:5.85%),本研究提出的SSF-ConvLSTM平均准确率为88.66%(SD:3.80%),在10.0 s的决策窗口下达到最高的解码精度92.1%(SD:5%),较CNN提高6.40个百分点,较SSF-CNN提高2.64个百分点;在DTU数据集上,SSF-CNN模型平均准确率为59.10%(SD:1.24%),NI-AAD平均准确率为62.04%(SD:1.13%),而SSF-ConvLSTM平均解码精度达到63.04%(SD:0.85%),在10.0 s决策窗口下达到64.6%(SD:3.32%),较CNN提升5.5个百分点. 综合2个数据集实验结果,$\alpha $ $\alpha $



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}