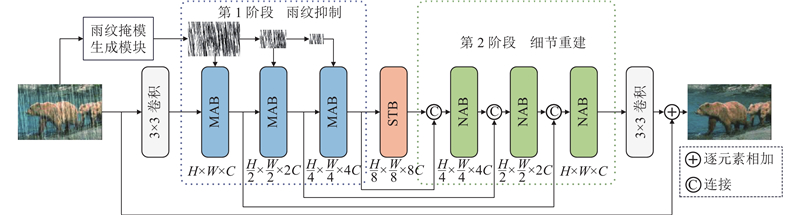
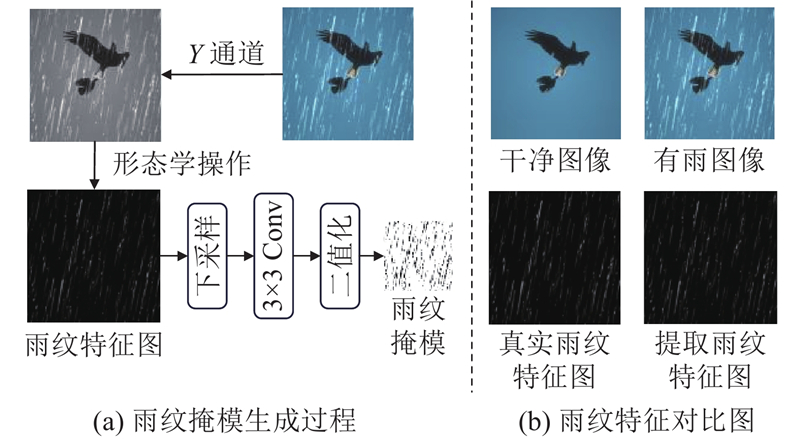
A dual-stage image deraining network based on rain streak mask suppression and non-local reconstruction collaboration was proposed to address severe rain streak noise interference and insufficient spatial global modeling capability of existing attention mechanisms in single-image deraining networks. In the first stage of the network, a rain streak mask attention mechanism was designed, in which rain streak masks were generated through morphological operations, to enhance the model’s ability to suppress rain streak interference by selectively masking rain-affected regions during feature extraction. In the second stage, a non-local attention mechanism was devised by employing a feature clustering-based non-local similarity measurement method to guide pixel rearrangement, which broke spatial constraints, thereby augmenting the long-range modeling capability of the sliding window attention mechanism and improving the deraining performance. Through progressive optimization based on the dual-stage “rain streak suppression-detail reconstruction” process, high-quality reconstruction of rain-free images was achieved. Experimental results on multiple public datasets demonstrate that the proposed network achieves significant improvements in both PSNR and SSIM metrics compared to other networks, effectively removing rain streaks while better preserving image details and producing high-quality restored results with natural-looking appearance and fine-grained texture representations.
HOU Yuzhen, SHEN Xiaohong, LI Li, YANG Mingyuan, ZHANG Caiming. Dual-stage deraining network based on mask and non-local attention. Journal of Zhejiang University(Engineering Science)[J], 2026, 60(4): 791-799 doi:10.3785/j.issn.1008-973X.2026.04.011
尽管以上工作取得了优异的成绩,但是当前基于注意力机制的去雨方法仍面临2个关键性局限:1) 由于雨纹污染区域特征失真,在计算注意力权重时会引入干扰信号,从而导致雨纹去除不彻底. Li等[7]选择将受雨影响和未受雨影响区域分别进行不同的处理,提出基于区域信息的Transformer模型(regional information Transformer,Regformer),但是该方法削弱了无雨区域对有雨区域恢复过程的贡献. 2) 现有注意力机制在建模远距离空间依赖关系上仍有局限性,窗口注意力虽通过滑动窗口扩大处理范围,但要求捕捉全局依赖的多个滑动窗口注意力(shifted windows Transformer,Swin Transformer)层组成的信息传输链是连续的,否则无法获取距离较远的相似特征之间的关系[8];而通道注意力因弱化空间位置关系,难以构建远距离像素关联,从而影响去雨图像的最终恢复效果.
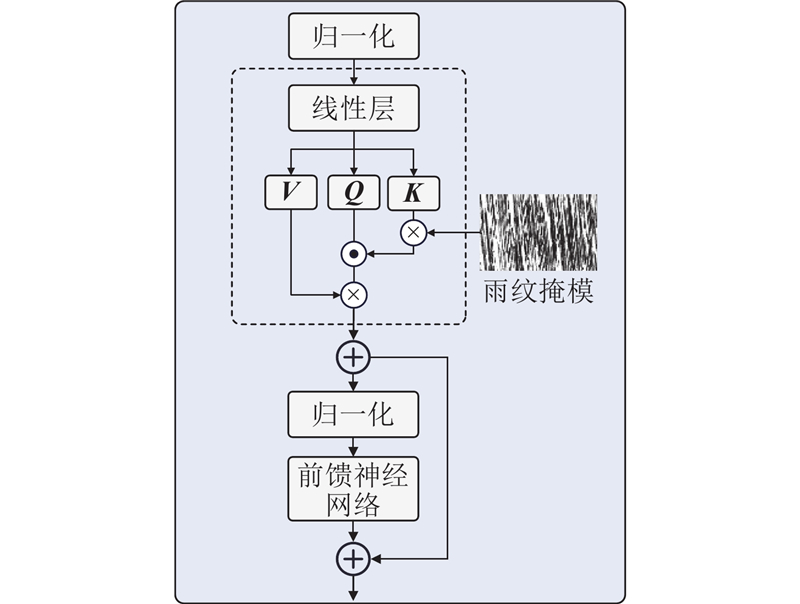
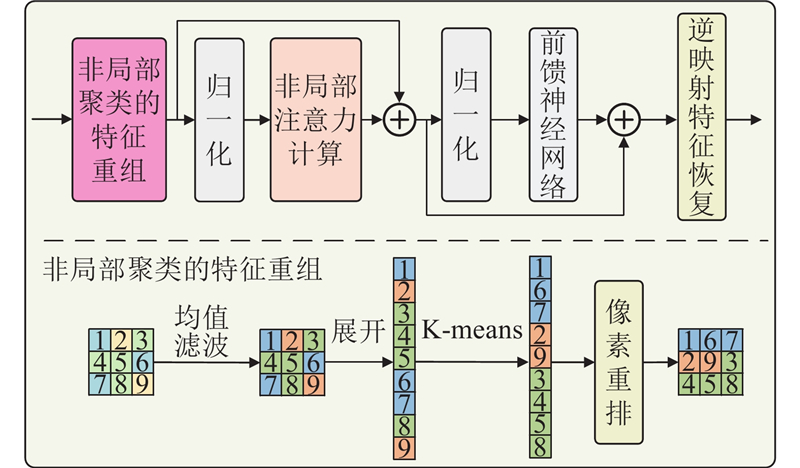
针对以上问题,本研究提出掩模抑制与非局部重建协同的窗口注意力方法(non-local and masked Swin Transformer,NMSFormer),该方法通过分阶段递进优化实现“雨纹抑制-细节重建”的针对性处理. 创新点如下:1) 在编码阶段提取特征时,设计雨纹掩模注意力机制,通过选择性遮蔽有雨区域,降低雨纹噪声干扰. 2) 在解码阶段,考虑到窗口注意力在建模全局依赖关系时的局限性,提出非局部注意力机制,通过像素重排使相似特征在空间上邻接,提高去雨网络的细节恢复能力.
数据集与评估指标:本实验在4个主流去雨基准数据集上进行验证,包括:Rain200L[17]、Rain200H[17]、DID-Data [29]、DDN-Data[15]. 具体而言,Rain200L和Rain200H各包含1800组训练图像对和200组测试图像对;DID-Data和DDN-Data分别包含12000组和12600组训练图像对,以及1200组和1400组测试图像对,上述数据集均是在干净图像上添加不同密度和强度的雨纹获得的合成数据集. 为了保持与现有研究的可比性[24],本实验将以在亮度通道计算的峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性指数(structure similarity index measure,SSIM)作为定量评估指标.
CARION N, MASSA F, SYNNAEVE G, et al. End-to-end object detection with transformers [C]// The 16th European Conference on Computer Vision. Cham: Springer, 2020: 213–229.
LI B, ZHANG Z, ZHENG H, et al. Diving deep into regions: exploiting regional information Transformer for single image deraining [EB/OL]. (2024-08-04) [2025 -07-01]. https://arxiv.org/abs/2402.16033.
ZHENG X, LIAO Y, GUO W, et al. Single-image-based rain and snow removal using multi-guided filter [C]// International Conference Neural Information Processing. Berlin, Heidelberg: Springer, 2013.
KIM J H, LEE C, SIM J Y, et al. Single-image deraining using an adaptive nonlocal means filter [C]// 2013 IEEE International Conference on Image Processing. Melbourne: IEEE, 2013: 914–917.
LUO Y, XU Y, JI H. Removing rain from a single image via discriminative sparse coding [C]// 2015 IEEE International Conference on Computer Vision (ICCV). Santiago: IEEE, 2015: 3397–3405.
LI Y, TAN R T, GUO X, et al. Rain streak removal using layer priors [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 2736–2744.
FU X, HUANG J, ZENG D, et al. Removing rain from single images via a deep detail network [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 1715–1723.
REN D, ZUO W, HU Q, et al. Progressive image deraining networks: a better and simpler baseline [C]// 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Long Beach: IEEE, 2019: 3932-3941.
YANG W, TAN R T, FENG J, et al. Deep joint rain detection and removal from a single image [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Honolulu: IEEE, 2017: 1685–1694.
WANG H, XIE Q, ZHAO Q, et al. A model-driven deep neural network for single image rain removal [C]// 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle: IEEE, 2020: 3100–3109.
FU X, QI Q, ZHA Z, et al. Rain streak removal via dual graph convolutional network [C]// Proceedings of the AAAI Conference on Artificial Intelligence. [S. l. ]: AAAI Press, 2021: 1352–1360.
YI Q, LI J, DAI Q, et al. Structure-preserving deraining with residue channel prior guidance [C]// 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal: IEEE, 2021: 4218–4227.
DOAOVUTSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale [EB/OL]. (2021-06-03) [2025-07-01]. https://arxiv.org/abs/2010.11929.
LIU Z, LIN Y, CAO Y, et al. Swin transformer: hierarchical vision transformer using shifted windows [C]// 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Montreal: IEEE, 2021: 9992–10002.
ZAMIR S W, ARORA A, KHAN S, et al. Restormer: efficient transformer for high-resolution image restoration [C]// 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). New Orleans: IEEE, 2022: 5718–5729.
CHEN X, LI H, LI M, et al. Learning a sparse transformer network for effective image deraining [C]// 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Vancouver: IEEE, 2023: 5896–5905.
HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 770–778.
SHI W, CABALLERO J, HUSZÁR F, et al. Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network [C]// 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Las Vegas: IEEE, 2016: 1874–1883.
ZHANG H, PATEL V M. Density-aware single image de-raining using a multi-stream dense network [C]// 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City: IEEE, 2018: 695–704.
... 数据集与评估指标:本实验在4个主流去雨基准数据集上进行验证,包括:Rain200L[17]、Rain200H[17]、DID-Data [29]、DDN-Data[15]. 具体而言,Rain200L和Rain200H各包含1800组训练图像对和200组测试图像对;DID-Data和DDN-Data分别包含12000组和12600组训练图像对,以及1200组和1400组测试图像对,上述数据集均是在干净图像上添加不同密度和强度的雨纹获得的合成数据集. 为了保持与现有研究的可比性[24],本实验将以在亮度通道计算的峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性指数(structure similarity index measure,SSIM)作为定量评估指标. ...
... 数据集与评估指标:本实验在4个主流去雨基准数据集上进行验证,包括:Rain200L[17]、Rain200H[17]、DID-Data [29]、DDN-Data[15]. 具体而言,Rain200L和Rain200H各包含1800组训练图像对和200组测试图像对;DID-Data和DDN-Data分别包含12000组和12600组训练图像对,以及1200组和1400组测试图像对,上述数据集均是在干净图像上添加不同密度和强度的雨纹获得的合成数据集. 为了保持与现有研究的可比性[24],本实验将以在亮度通道计算的峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性指数(structure similarity index measure,SSIM)作为定量评估指标. ...
... [17]、DID-Data [29]、DDN-Data[15]. 具体而言,Rain200L和Rain200H各包含1800组训练图像对和200组测试图像对;DID-Data和DDN-Data分别包含12000组和12600组训练图像对,以及1200组和1400组测试图像对,上述数据集均是在干净图像上添加不同密度和强度的雨纹获得的合成数据集. 为了保持与现有研究的可比性[24],本实验将以在亮度通道计算的峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性指数(structure similarity index measure,SSIM)作为定量评估指标. ...
... 数据集与评估指标:本实验在4个主流去雨基准数据集上进行验证,包括:Rain200L[17]、Rain200H[17]、DID-Data [29]、DDN-Data[15]. 具体而言,Rain200L和Rain200H各包含1800组训练图像对和200组测试图像对;DID-Data和DDN-Data分别包含12000组和12600组训练图像对,以及1200组和1400组测试图像对,上述数据集均是在干净图像上添加不同密度和强度的雨纹获得的合成数据集. 为了保持与现有研究的可比性[24],本实验将以在亮度通道计算的峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性指数(structure similarity index measure,SSIM)作为定量评估指标. ...
... 数据集与评估指标:本实验在4个主流去雨基准数据集上进行验证,包括:Rain200L[17]、Rain200H[17]、DID-Data [29]、DDN-Data[15]. 具体而言,Rain200L和Rain200H各包含1800组训练图像对和200组测试图像对;DID-Data和DDN-Data分别包含12000组和12600组训练图像对,以及1200组和1400组测试图像对,上述数据集均是在干净图像上添加不同密度和强度的雨纹获得的合成数据集. 为了保持与现有研究的可比性[24],本实验将以在亮度通道计算的峰值信噪比(peak signal to noise ratio,PSNR)和结构相似性指数(structure similarity index measure,SSIM)作为定量评估指标. ...






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}