

近年来,深度学习在颌面结构分割中取得明显进展[6-7]. Cui等[8]提出的ToothNet利用两阶段深度网络提取边缘、相似性和空间关系实现牙齿实例分割,但缺乏缺牙推理机制,难以稳定完成牙位标定. Liu等[9]利用骨分割网络获取牙槽骨、牙齿和上颌窦的分割结果,进而将牙齿和下颌区域作为感兴趣区域实现牙齿和下牙槽神经管的分割,但未涵盖严重金属伪影,导致模型鲁棒性不足. Wu等[10]结合感兴趣区域提取和边界优化策略,实现下颌髁突皮质骨与骨髓的分割. Wei等[11]通过多平面重建和纹理增强提升IAC的对比度,采用二维线追踪实现精准分割. Morgan等[12]采用双阶段3D U-Net架构,通过粗-精分割生成上颌窦分割结果. Daza等[13]基于Transformer网络提取局部和全局特征,并融合语言信息指导实体分割. 薄士仕等[14]基于ResNet设计多网络体系,分别进行牙齿实例分割和牙位标定. 然而,现有研究多局限于有限的口腔解剖结构,缺乏全景分割能力,难以辅助医生全面掌握患者口腔状况;此外,卷积神经网络(CNN)难以对长距离依赖进行有效建模,导致内部结构语义信息提取不足、牙位标定精度较低,进而限制了定量分析效果.
针对现有分割方法在复杂颌面结构中的不足,本研究结合Kolmogorov-Arnold表示定理与U-Net架构,提出多尺度特征提取模型MC-UKAN,并基于该模型设计了三阶段分割框架. 第1阶段,在低分辨率图像上通过MC-UKAN完成粗分割,该网络基于编码器-解码器架构,在第1层编码器前嵌入3D位置编码模块,为初步提取的特征注入位置先验信息,从而强化网络对长距离位置依赖的建模能力与绝对位置感知能力;提出多尺度通道可分离KAN(multi-scale channel-separable KAN,MC-KAN)卷积替代传统卷积解码器,提升非线性建模能力并扩大感受野,提升模型特征提取能力. 第2阶段在原始分辨率图像上,基于粗分割结果定位目标结构,再通过颌面结构相似性与K-means聚类算法定量分析,将目标划分为前牙、磨牙、修复体、上颌窦和IAC共5个类别,根据粗分割标签确定所属类别并应用对应网络进行精细分割. 第3阶段采用轻量网络单独分割出上、下颌骨与咽喉结构. 最后融合粗分割标签与原始图像上的分割结果,实现完整精准的全景结构分割. 在公开数据集ToothFairy3上进行模型训练和测试,以验证方法的性能.
1. 研究方法
1.1. 三阶段颌面分割框架
当前颌面结构分割算法普遍存在2大局限,多数研究集中于对局部结构的分割,缺乏针对全景结构的整体结果,且难以输出符合FDI标准的精确牙位标定. 为此,本研究设计了三阶段颌面分割框架,3个阶段分别对应3个核心模块:粗分割模块、局部高分辨细分割模块和大尺度结构分割模块,具体架构见图1.
图 1
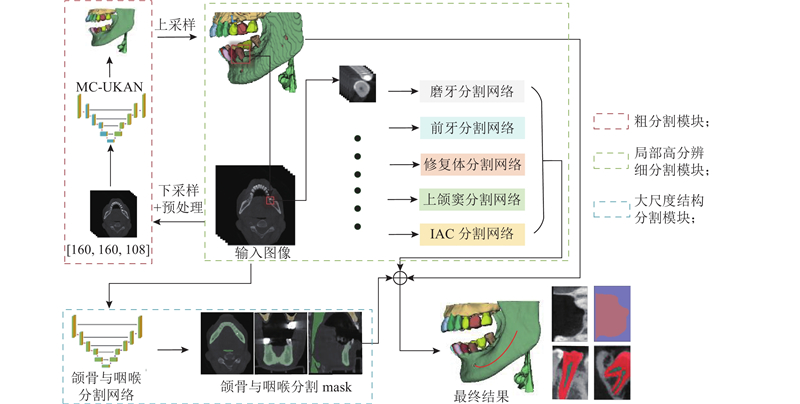
由于原始图像尺寸较大,为了适应网络输入,首先将图像统一降采样至160×160×108(ToothFairy3的Set B/C中样本的上颌结构缺失,因此先将尺寸缩至160×160×80再补充28层背景切片). 图像经预处理后输入粗分割模块,采用高效的MC-UKAN模型进行分割,获得42类粗分割结果(不包含牙髓),并为后续局部精细分割提供全局结构定位基础.
基于解剖学相似性,局部高分辨细分割模块将特征划分为5类:前牙(包括切牙和尖牙,位于牙弓前部,形态窄长)、磨牙(位于牙弓后部,牙合面宽大且常为多根)、修复体(如金属或陶瓷修复体)、上颌窦(位于磨牙区上方的含气空腔)以及IAC(下牙槽神经管,沿下颌骨内走行). 研究进一步提取了6项量化特征,包括CT值25%分位数、CT值中位数、CT值偏度、质心位置、边界框体积和表面积/体积比,并采用K-means聚类算法对5类结构进行聚类分析,并结合t-SNE可视化工具呈现特征分布. 结果如图2所示,除少数前牙与磨牙样本同修复体存在轻微重叠外,5类结构均呈现清晰的聚类中心与分布边界. 实验针对 5 类目标结构分别设定固定区块尺寸并从原始 CBCT 影像中截取对应区域进行分割:前牙与磨牙统一采用 48×48×72 尺寸(用于牙齿、牙髓及背景的分割),上颌窦为 64×96×48,下牙槽神经管为 120×200×200,修复体为 48×48×48. 对于实际尺寸超出设定区块的目标结构,采用智能滑块分块推理,再通过最大概率法完成区块拼接. 这种在固定区域内进行局部细分的方法,能够有效解决微小结构的分割难题. 例如,牙髓在原始影像中仅占十万分之一的体积,但通过准确定位至牙齿中心,只需局部区域的高分辨率图像,即可实现亚体素级别的分割精度. 大尺度结构分割模块则使用轻量网络专责分割上、下颌骨与咽喉. 最终通过概率图融合机制实现多模块信息互补,将精细分割结果与粗分类标签融合,输出精确的全景分割结果. 该方法融合了全局定位与局部细分的优势,优化了计算资源.
图 2
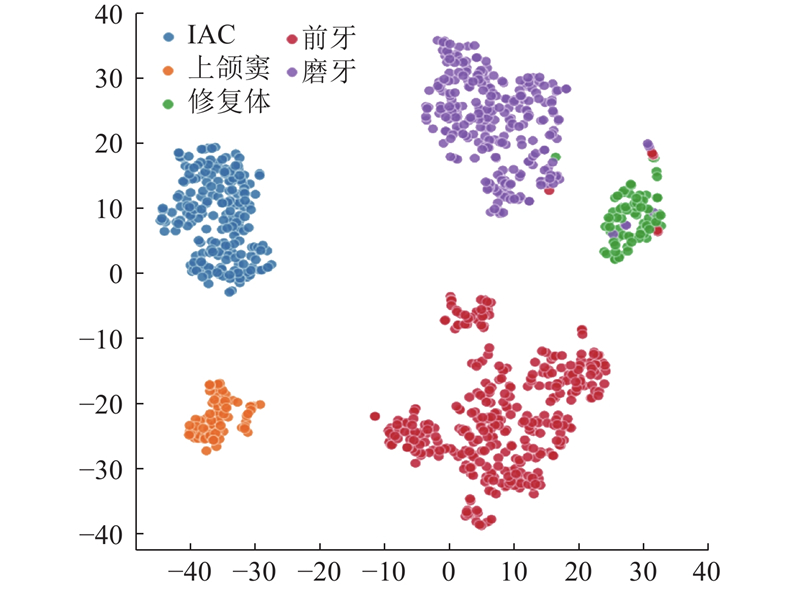
图 2 5类结构的 K-means 与 t-SNE 可视化结果图
Fig.2 Visualization results of K-means and t-SNE for five types of structures
1.2. MC-UKAN架构
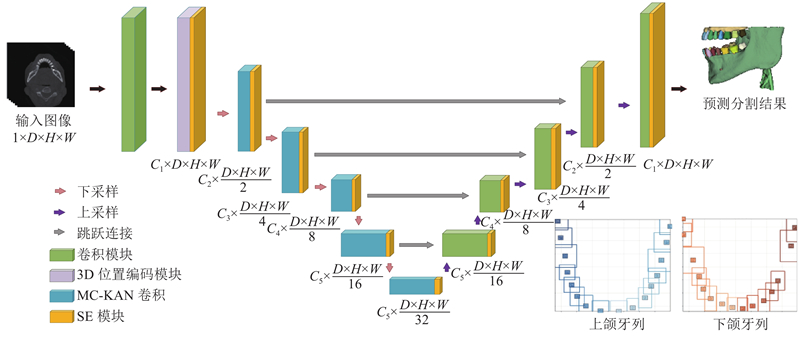
针对3D U-Net非线性建模能力不足和感受野受限问题,提出MC-UKAN架构,其结构如图3所示. 包括初始特征提取模块、3D位置编码模块、MC-KAN卷积层编码器与卷积解码器. 首先,输入图像通过卷积模块完成特征提取,输出64 个通道的特征图,再通过3D位置编码模块后显式注入位置先验信息,以增强模型长距离位置依赖建模和绝对位置感知能力. 随后,这些特征图被送入MC-KAN卷积层,采用多尺度KAN卷积核逐通道提取特征,结合残差连接构建层次化多尺度表征,以增强网络对复杂目标与形变结构的适应性. 在架构中,网络以MC-KAN卷积层替换传统3D U-Net中的编码器卷积层,通过使用可学习的非线性激活函数和多尺度卷积提高全局特征的提取能力. 每层编码器使用2×2×2的最大池化将特征分辨率减半,并在卷积块后添加SE模块[15],利用全局注意力机制强化特征表示. 因粗分割任务对低维纹理特征敏感度较低,取消了首层与解码器的跳跃连接. 最终,特征经上采样与跳跃连接传递至解码器,通过逐点卷积和Sigmoid激活生成42类结构的通道概率分布图,利用argmax函数提取最大概率标签,获得含牙位标定的粗分割结果.
图 3
1.3. 3D位置编码模块
口腔结构在空间上的排列具有一定的规律性,而传统3D U-Net存在长距离位置依赖建模与绝对位置感知能力不足的问题. 针对这个问题,本研究采用3D位置编码模块(positional encoding 3D, PE3D). 通过该模块,在第1层编码器之前显式注入空间位置先验信息,从而提升模型特征感知能力. 模块输入为初始特征提取后的特征图
式中:
1.4. MC-KAN卷积层
本研究提出多尺度通道可分离KAN卷积层(MC-KAN),通过融合KAN的非线性逼近能力与多尺度特征提取优势,增强模型表达能力与泛化性. 如图4(a)所示,输入特征
图 4
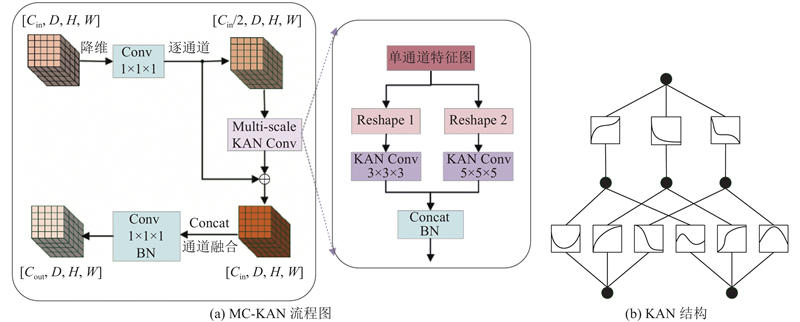
Liu等[16]从Kolmogorov-Arnold表示定理中汲取灵感,提出Kolmogorov-Arnold网络(KAN). K层的KAN网络可以表示为多个KAN层的嵌套:
式中:
式中:
式中:
特征经残差连接后,通过点卷积与批量归一化实现通道融合. 残差机制通过跨层直连加速梯度传播,缓解网络退化问题[17],同时,配合输入缩放与偏移操作稳定各层分布,能提升收敛效率与表达能力.
2. 数据准备与网络训练
2.1. 实验数据集
ToothFairy3数据集共涵盖77个标签类别,包括使用FDI牙位表示法的各恒牙、牙髓、种植体修复体(牙桥、牙冠、种植牙体)、上下颌骨、左右上颌窦、咽喉、左右下牙槽神经管(IAC)等(见图5(a)~(d)). 本研究暂不涉及舌侧管与切牙管分割.
图 5
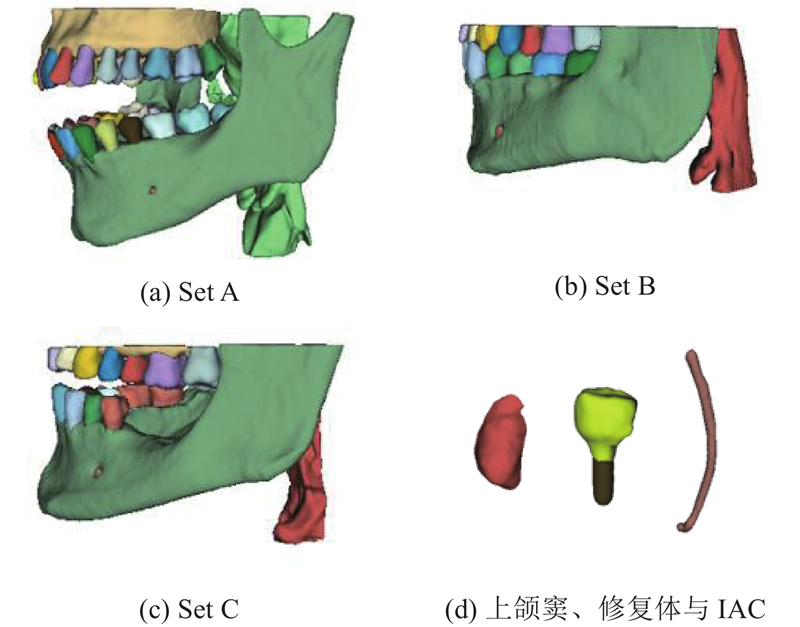
为了保证数据划分科学性,采用分层留出法,按6∶2∶2比例从3个子集中选取训练集(318例)、验证集(106例)和测试集(108例),确保各子集在训练、验证和测试阶段合理分布,提升模型评估可靠性.
2.2. 图像预处理
在预处理阶段,图像的CT值被截断至[−
为了缓解降采样导致的分辨率损失及精细结构辨识困难,对降采样图像进行特征增强处理,如图6(a)~(d)所示,使用三维Sobel算子计算梯度幅值平均值,生成边缘特征图;对CT值为800~1 600的骨组织区域应用自适应直方图均衡化,增强骨小梁、皮质骨、牙槽骨骨板等骨组织微结构对比度;利用如下公式将降采样图像及其边缘特征图、骨组织增强图进行融合,得到特征融合图像:
图 6
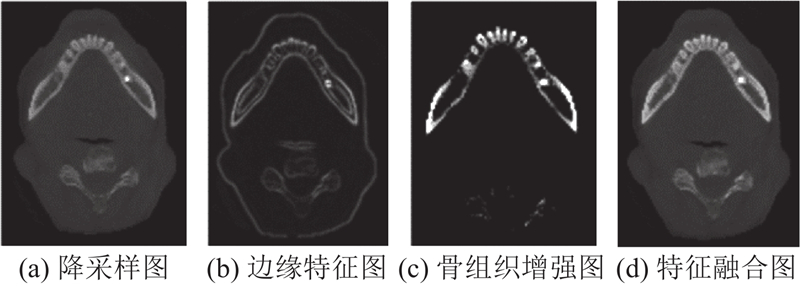
式中:
2.3. 运行环境
本研究模型训练采用GeForce RTX 4070Ti SUPER显卡平台与PyTorch-cuda=12.40框架. MC-UKAN模型配置具体参数如下:输入图像大小为160×160×108,批大小设为1,训练周期为100,优化器选择Adam,初始学习率为1×10−4,损失函数采用Dice Loss.
2.4. 评价指标
采用2项通用评估指标衡量分割性能:Dice系数与第95百分位豪斯多夫距离(95th percentile Hausdorff Distance,HD95). 表达式分别如下:
式中:
3. 实验结果与分析
3.1. 比较实验
为了验证方法的有效性,在ToothFairy3数据集上进行对比实验. 该数据集在ToothFairy2的基础上新增了另一设备制造商提供的52例CBCT图像,并统一添加牙髓标注,新数据集分类结构更多,同时能够更好地支持模型泛化能力评估. 实验结果将74类目标结构分7组计算平均值,包括:颌骨、IAC、上颌窦、咽喉、修复体、牙齿与牙髓(含牙位标定). 须说明的是,由于对比方法基于ToothFairy2训练集进行训练,为了最大限度保证比较的公平性,在计算总体均值时排除牙髓相关统计项,从而使评价维度保持一致. 此外,公开训练集Set B和Set C中上颌结构标注不全,因此上颌骨、上颌窦及上颌牙齿也未纳入均值计算.
Dice系数及HD95系数对比结果如表1、2所示. 可以看出,本研究提出的基于MC-UKAN的三阶段分割框架,在颌面全景分割任务中综合性能优于固定Patch Size的CNN、Transformer和Mamba类模型. 其分类平均Dice系数达到88.87%,较次优方法UMamba提升3.82个百分点;除了IAC与上颌窦分割外,在其余任务中均取得最优性能. HD95指标平均值为5.04 mm,仅次于Swin-UMamba的,且在颌骨、上颌窦、咽喉及牙齿的分割任务中均展现出最优性能. 分析原因,这种多阶段分割框架通过特征融合机制,有效建模了颌面结构间的语义关联,同时兼顾全局拓扑约束与局部边界细节,而对比方法中除Mamba使用二维切片外,其他方法均通过从原图裁取固定大小的三维Patch并拼接的方式进行处理,无论哪种方法,都缺乏全面捕捉和学习颌面区域三维空间结构的能力. 此外,在粗分割阶段应用不同模型的对比表明,MC-UKAN的Dice与HD95最优,进一步验证了其更优秀的非线性建模能力.
表 1 不同的方法Dice系数比较
Tab.1
| 网络 | Dice/% | ||||||||
| 均值(不计牙髓) | 颌骨 | IAC | 上颌窦 | 咽喉 | 牙齿 | 修复体 | 牙髓 | ||
| CNNs | nnU-Net[20] | 70.92 | 90.31 | 71.34 | 64.81 | 95.66 | 73.17 | 29.50 | — |
| nnU-Net ResEnc[20] | 74.16 | 91.77 | 73.01 | 65.71 | 95.26 | 76.48 | 37.10 | — | |
| Transf. | TransU-Net[20] | 70.32 | 90.33 | 81.96 | 59.69 | 87.89 | 72.46 | 27.68 | — |
| nnFormer[20] | 76.79 | 91.50 | 72.28 | 75.11 | 90.85 | 79.37 | 18.95 | — | |
| UNETR++[20] | 71.43 | 92.38 | 68.87 | 74.51 | 91.60 | 73.70 | 26.21 | — | |
| Mamba | UMamba[20] | 85.05 | 90.05 | 85.26 | 77.02 | 92.18 | 86.58 | 43.89 | — |
| VMamba[20] | 73.13 | 90.75 | 60.62 | 73.20 | 88.23 | 75.99 | 14.86 | — | |
| Swin-UMamba[20] | 79.64 | 94.29 | 72.64 | 87.75 | 93.05 | 80.71 | 25.30 | — | |
| 3-Stage | 3D UKAN_SE | 86.51 | 94.95 | 82.62 | 76.84 | 95.96 | 89.49 | 80.49 | 86.09 |
| PMFSNet3D | 87.96 | 95.94 | 84.99 | 73.80 | 95.96 | 88.82 | 80.27 | 85.10 | |
| 本研究模型 | 88.87 | 95.95 | 84.22 | 82.09 | 95.96 | 89.51 | 81.18 | 87.55 | |
表 2 不同的方法HD95系数比较
Tab.2
| 网络 | HD95/mm | ||||||||
| 均值(不计牙髓) | 颌骨 | IAC | 上颌窦 | 咽喉 | 牙齿 | 修复体 | 牙髓 | ||
| CNNs | nnU-Net[20] | 17.86 | 12.53 | 29.11 | 28.39 | 19.23 | 18.32 | 20.95 | — |
| nnU-Net ResEnc[20] | 14.48 | 12.53 | 27.81 | 29.99 | 17.75 | 14.26 | 16.32 | — | |
| Transf. | TransU-Net[20] | 20.17 | 49.02 | 11.99 | 59.76 | 42.87 | 15.04 | 22.65 | — |
| nnFormer[20] | 5.45 | 20.09 | 10.06 | 8.22 | 24.53 | 2.94 | 13.67 | — | |
| UNETR++[20] | 17.23 | 5.44 | 15.10 | 15.48 | 18.96 | 17.91 | 19.70 | — | |
| Mamba | UMamba[20] | 5.28 | 22.17 | 16.23 | 4.35 | 25.25 | 2.23 | 13.97 | — |
| VMamba[20] | 5.17 | 7.17 | 9.94 | 9.89 | 23.95 | 3.39 | 14.63 | — | |
| Swin-UMamba[20] | 2.94 | 4.25 | 2.02 | 2.38 | 2.79 | 2.59 | 14.93 | — | |
| 3-Stage | 3D UKAN_SE | 5.27 | 1.62 | 9.96 | 8.20 | 1.17 | 2.18 | 24.87 | 2.86 |
| PMFSNet3D | 5.48 | 1.63 | 11.38 | 5.25 | 1.17 | 2.37 | 29.03 | 2.80 | |
| 本研究模型 | 5.04 | 1.59 | 10.78 | 2.33 | 1.17 | 1.96 | 24.82 | 2.11 | |
如表3所示对比了本研究方法与其他改进模型在颌面结构分割任务中的分类平均Dice系数. 在更具挑战性的条件下(包含修复体和牙髓),基于MC-UKAN的口腔智能分割模型仍展现出最优异的性能. 实验数据表明,本方法的平均Dice系数达到88.3%,较次优的方法(排除了修复体干扰)提升了0.42个百分点. 这一结果表明,MC-UKAN模型在复杂口腔解剖结构的分割任务中具有优势,能够有效处理多类别分割带来的挑战,同时保持较高的分割精度.
表 3 带牙位标定的分类平均Dice系数比较
Tab.3
图 7
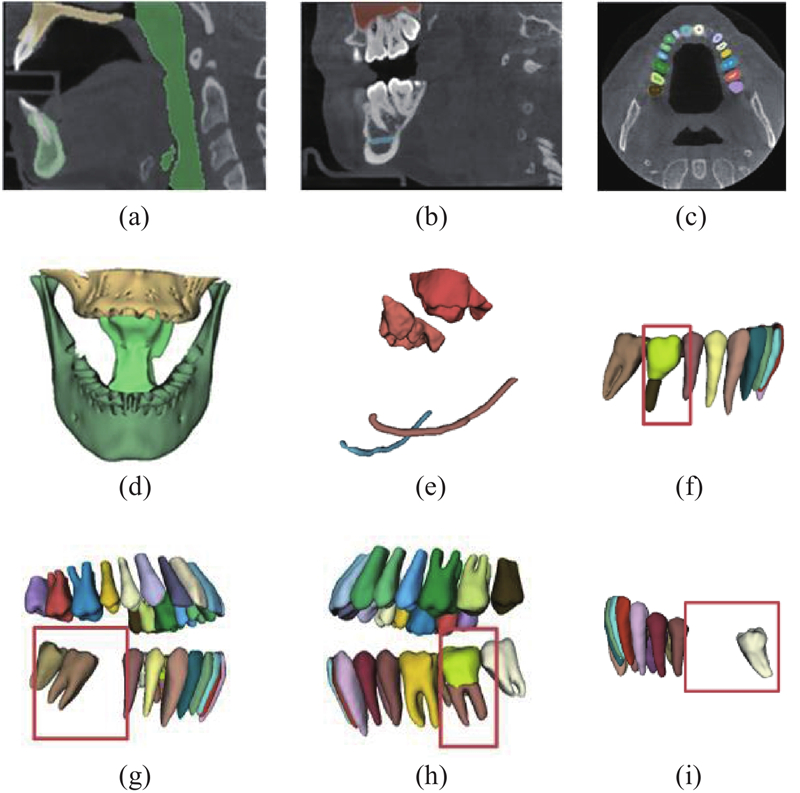
图 7 上/下颌骨、咽喉、上颌窦、IAC与牙齿及其牙髓的分割结果
Fig.7 Segmentation results of maxilla/mandible, pharynx, maxillary sinus, IAC, teeth and their dental pulps
3.2. 各个模块性能表现
3.2.1. 粗分割模块
如表4所示对比了粗分割模块中不同方法的性能表现,包括3D U-Net、3D Unet_SE、3D U-KAN[22]、3D UKAN_SE和PMFSNet3D[23]等基准方法. 实验数据表明,本研究提出的MC-UKAN模型以86.89%的分类平均Dice系数领先,较次优的3D UKAN_SE方法提升0.70个百分点. 尤其在牙齿和修复体分类任务中,MC-UKAN表现尤为突出,其Dice系数分别较3D UKAN_SE提高了1.72和2.48个百分点. 原因在于模型的多尺度结构设计有效扩展了感受野,从而增强了复杂解剖结构的语义分割能力. 然而,在固定位置结构的分类任务中,本方法性能略有下降,这可能是由于多尺度特征提取过程对局部空间信息产生了一定干扰. 此外,使用单一设备数据(Set A/B)训练得到的模型在另一设备数据Set C上推理时,Dice系数仅下降1.18个百分点,进一步证明了该方法具有良好的泛化能力.
表 4 粗分割模块不同网络的分类Dice系数比较
Tab.4
| 网络 | Dice/% | ||||||
| 均值 | 颌骨 | IAC | 上颌窦 | 咽喉 | 牙齿 | 修复体 | |
| 3D U-Net | 83.71 | 86.90 | 77.46 | 95.50 | 95.36 | 83.35 | 78.95 |
| 3D Unet_SE | 86.00 | 88.36 | 78.06 | 95.42 | 96.48 | 85.74 | 82.73 |
| 3D U-KAN | 85.84 | 88.71 | 79.30 | 97.77 | 95.63 | 85.62 | 80.50 |
| 3D UKAN_SE | 86.19 | 88.56 | 78.56 | 94.41 | 96.57 | 86.15 | 81.27 |
| PMFSNet3D | 84.80 | 87.82 | 79.16 | 88.63 | 96.50 | 84.79 | 80.21 |
| MC-UKAN(3×3×3) | 83.70 | 85.40 | 77.15 | 83.51 | 95.88 | 83.68 | 83.25 |
| MC-UKAN(5×5×5) | 84.13 | 86.50 | 76.21 | 81.49 | 95.93 | 83.96 | 83.58 |
| MC-UKAN(单一设备商) | 85.71 | 95.90(下颌) | 79.31 | — | 94.33 | 85.91 | 82.64 |
| MC-UKAN | 86.89 | 86.10 | 77.13 | 96.61 | 96.07 | 87.87 | 83.75 |
U-KAN较U-Net的改进在于,在瓶颈层通过CNN卷积的线性投影将特征映射到潜在嵌入空间,生成令牌序列后再利用KAN网络对高维特征进行非线性建模,并以隐式方式编码位置信息. 而MC-UKAN通过直接采用MC-KAN卷积替代编码器,实现了多方面的优势. 首先,MC-KAN卷积不仅有效扩大了模型的感受野,还通过PE3D模块显式注入空间位置信息,增强了模型对复杂颌面结构的特征提取能力. 图8(c)、(d)展示了第2层编码器中MC-KAN卷积层与传统CNN卷积层提取的特征图. 随着下采样和高维特征提取,MC-KAN能更准确地捕捉口腔内部的多结构特征,而传统CNN在下颌特征提取上出现明显失真. 这是因为KAN卷积的可学习非线性激活函数提升了特征提取能力(见图8 (a)、(b)). 另一方面,由表4可知,相较于采用单一 KAN 卷积核的 MC-UKAN(3×3×3)与 MC-UKAN(5×5×5)模型,融合双 KAN 卷积核的多尺度 MC-UKAN 模型有效扩大了感受野,兼顾局部细节与全局上下文信息,平均 Dice 系数较2种模型分别提升 3.19 和 2.26 个百分点. 实验结果表明,在本研究涉及的各类基础模型中,引入SE注意力模块后均观察到了性能的提升. 这归因于 SE 模块的全局通道注意力机制可对特征通道间的权重进行动态调整,增强关键特征的表示能力,并抑制无关噪声,从而优化分割效果.
图 8

图 8 不同卷积方式下第2层编码器后横截面切片
Fig.8 Cross-sectional slices after second layer encoder with different convolution methods
3.2.2. 局部高分辨细分割模块与大尺度结构分割模块
鉴于这2个模块的处理目标明确,本研究在保证分割精度的前提下,采用轻量化 3D Unet_SE 模型以提升计算效率. 如表5所示展示了局部高分辨细分割模块与大尺度结构分割模块的性能表现. 须说明的是,由于上颌骨仅在Set A中完整存在,表中上颌骨、上颌窦的分割性能是基于测试集中的14例样本计算所得的,其余结构则使用完整测试集数据测试. 实验结果表明,基于精确分割定位的局部高分辨细分割模块在各类解剖结构上均表现出色,特别是上颌窦的平均Dice系数与HD95距离分别达到98.26%和1.00 mm. 大尺度结构分割模块对对比度明显的解剖结构(上颌骨、下颌骨与咽喉)分割效果优异. 其中下颌骨与咽喉的平均Dice系数分别为96.45%、95.96%,对应的HD95 距离分别2.57、2.60 mm.
表 5 局部高分辨细分割模块与大尺度结构分割模块的实验结果
Tab.5
| 模块 | 结构 | Dice/% | HD95/mm |
| 局部高分辨细 分割模块 | IAC | 94.69 | 0.97 |
| 上颌窦 | 98.26 | 1.00 | |
| 前牙及牙髓 | 93.58 | 2.03 | |
| 磨牙及牙髓 | 90.69 | 3.30 | |
| 修复体 | 93.49 | 2.27 | |
| 大尺度结构 分割模块 | 上颌骨 | 85.72 | 11.10 |
| 下颌骨 | 96.45 | 2.57 | |
| 咽喉 | 95.96 | 2.60 |
3.2.3. 各模块推理时间
如表6所示,本研究三阶段分割方法,在 108 例测试样本上的单样本平均推理时间为 27.04 s. 表明在单块GPU硬件下本研究模型仍具有较高的推理效率. 在本模型中,在局部精细分割阶段须对5种结构进行独立推理,若采用多块GPU硬件,则可通过并行化实现这5类结构的并行推理,从而有望显著提高推理效率. 总体而言,尽管多阶段设计带来一定的开销,但在现有硬件条件下仍显示出较高的临床应用潜力,未来工作将聚焦模型优化以进一步提升效率.
表 6 三阶段模块推理时间
Tab.6
| 模块 | 耗时/s |
| 粗分割模块 | 3.86 |
| 大尺度结构分割模块 | 2.46 |
| 局部高分辨细分割模块 | 20.72 |
| 总计 | 27.04 |
3.3. 消融实验
为了验证MC-UKAN核心模块(PE3D模块与MC-KAN卷积层)的有效性,配置不同MC-KAN层数量,记为NMC-KAN. 其中取消的MC-KAN层均替换为包含3×3×3卷积层、批量归一化和ReLU激活的2组级联结构,数量记为
表 7 PE3D模块与MC-KAN卷积层的消融实验结果
Tab.7
| PE3D | NMC-KAN | Dice% | |
| √ | 0 | 5 | 86.00 |
| √ | 1 | 4 | 82.66 |
| √ | 2 | 3 | 85.79 |
| √ | 3 | 2 | 85.54 |
| √ | 4 | 1 | 85.95 |
| √ | 5 | 0 | 86.89 |
| × | 5 | 0 | 86.06 |
如表8所示为不同规模的MC-UKAN模型分割实验结果对比. 结果表明,网络的规模对性能有较大影响,最大规模的MC-UKAN网络比中等和小规模网络在Dice系数上分别提升了3.10、15.61个百分点. 这说明更大规模的网络结构能够更有效地建立结构间的语义联系,进一步改善分割效果.
表 8 不同规模MC-UKAN模型的分割实验结果对比
Tab.8
| Model Scale | (C1,C2, C3, C4, C5) | Dice/% |
| MC-UKAN_S | (16,32,64,128,256) | 71.28 |
| MC-UKAN_M | (32,64,128,256,512) | 83.79 |
| MC-UKAN | (32,64,256,512, | 86.89 |
3.4. 鲁棒性实验
表 9 ToothFairy3 测试集上添加不同噪声的分割实验结果对比
Tab.9
| 噪声类型 | Dice/% | |||
| 高斯噪声 | 0.02 | — | — | 86.50 |
| 泊松噪声 | — | 0.5 | — | 87.94 |
| 脉冲噪声 | — | — | 0.01 | 86.68 |
| 高斯+泊松 | 0.02 | 0.5 | — | 86.00 |
| 高斯+脉冲 | 0.02 | — | 0.01 | 84.42 |
| 泊松+脉冲 | — | 0.5 | 0.01 | 86.09 |
| 高斯+泊松+脉冲 | 0.02 | 0.5 | 0.01 | 83.98 |
| 无噪声 | — | — | — | 88.30 |
4. 结 语
针对口腔颌面结构全景分割中存在的多尺度结构难以精准分割、复杂拓扑关系建模困难以及全局与局部特征协同的挑战,融合Kolmogorov-Arnold 表示定理的非线性建模能力与U-Net的层级特征融合优势,提出MC-UKAN网络,并构建三阶段分割框架,实现了涵盖牙齿、牙髓、颌骨、下牙槽神经管、上颌窦、咽喉及修复体等74类结构的口腔颌面全景分割. 该方法通过PE3D模块注入位置先验,结合MC-KAN卷积层的非线性建模和多尺度特征聚合机制,有效建立了跨结构语义关联. 三阶段框架的设计兼顾了全局大尺度结构的完整性与局部细微结构的精确性. 在ToothFairy3上的实验表明,该方法有效实现了从宏观到微观的全景式分割覆盖. 作为口腔颌面全景分割方案,其能全面输出各类解剖结构的分割结果,为数字化口腔诊疗中的结构分析、牙位标定及缺牙评估等提供完整信息支撑,可辅助医务人员提升诊疗计划的制定效率与精准度,减轻人工分割的工作负担.
未来研究将聚焦优化模型,提升对极端金属伪影的鲁棒性,并降低计算复杂度,探索构建端到端的模型架构,以减少当前多阶段流程间的依赖,从而提升临床应用中的流程效率,进一步提升全景分割在临床实际场景中的适用性.
参考文献
Canalis sinuosus: an anatomic repair that may prevent success of dental implants in anterior maxilla
[J].DOI:10.1111/jopr.13256 [本文引用: 1]
Inferior alveolar nerve canal segmentation on CBCT using U-Net with frequency attentions
[J].DOI:10.4274/meandros.galenos.2021.14632 [本文引用: 1]
Alternate level set evolutions with controlled switch for tooth segmentation
[J].DOI:10.1109/ACCESS.2022.3192411 [本文引用: 1]
Is manual segmentation the real gold standard for tooth segmentation? a preliminary in vivo study using cone-beam computed tomography images
[J].DOI:10.4274/meandros.galenos.2021.14632
Automated tooth segmentation as an innovative tool to assess 3D-tooth movement and root resorption in rodents
[J].DOI:10.1186/s13005-020-00254-y [本文引用: 1]
Tooth automatic segmentation from CBCT images: a systematic review
[J].DOI:10.1007/s00784-023-05048-5 [本文引用: 1]
Performance of artificial intelligence using cone-beam computed tomography for segmentation of oral and maxillofacial structures: a systematic review and meta-analysis
[J].DOI:10.4317/jced.60287 [本文引用: 1]
Fully automatic AI segmentation of oral surgery-related tissues based on cone beam computed tomography images
[J].DOI:10.1038/s41368-024-00294-z [本文引用: 1]
Automatic segmentation and visualization of cortical and marrow bone in mandibular condyle on CBCT: a preliminary exploration of clinical application
[J].DOI:10.1007/s11282-024-00780-4 [本文引用: 1]
Inferior alveolar canal segmentation based on cone-beam computed tomography
[J].DOI:10.1002/mp.15274 [本文引用: 1]
Convolutional neural network for automatic maxillary sinus segmentation on cone-beam computed tomographic images
[J].DOI:10.1038/s41598-022-11483-3 [本文引用: 1]
基于卷积神经网络实现锥形束CT牙齿分割及牙位标定
[J].DOI:10.19723/j.issn.1671-167X.2024.04.030 [本文引用: 2]
Tooth segmentation and identification on cone-beam computed tomography with convolutional neural network based on spatial embedding information
[J].DOI:10.19723/j.issn.1671-167X.2024.04.030 [本文引用: 2]
ResMIBCU-Net: an encoder–decoder network with residual blocks, modified inverted residual block, and bi-directional ConvLSTM for impacted tooth segmentation in panoramic X-ray images
[J].DOI:10.1007/s11282-023-00677-8 [本文引用: 1]
Enhancing patch-based learning for the segmentation of the mandibular canal
[J].DOI:10.1109/ACCESS.2024.3408629 [本文引用: 1]
Segmenting the inferior alveolar canal in CBCTs volumes: the ToothFairy challenge
[J].
U-KAN makes strong backbone for medical image segmentation and generation
[J].DOI:10.1609/aaai.v39i5.32491 [本文引用: 1]
PMFSNet: polarized multi-scale feature self-attention network for lightweight medical image segmentation
[J].DOI:10.1016/j.cmpb.2025.108611 [本文引用: 1]
An improved nonlinear diffusion in Laplacian pyramid domain for cone beam CT denoising during image-guided vascular intervention
[J].DOI:10.1186/s12880-018-0269-1 [本文引用: 1]
Noise suppression in scatter correction for cone-beam CT
[J].DOI:10.1118/1.3063001 [本文引用: 1]
Anisotropic total variation denoising technique for low-dose cone-beam computed tomography imaging
[J].DOI:10.14316/pmp.2018.29.4.150 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}