

光学遥感图像小目标密集、背景复杂多变导致目标特征难以提取,因此采用YOLO模型检测易造成小目标在深层特征中消失. 近年来,针对以上问题,国内外研究学者给出了许多改进方法. Liu等[6]提出特征增强模块FEBlock (feature enhancement block),对每个最大池化层的结果进行特征增强,充分提取了小目标的特征. Qiu等[7]提出改进卷积核结构的新模型DKA-YOLO,利用广泛的感受野来增强特征提取. 许思源等[8]提出三极综合性融合模块,充分融合主干网络所提取的特征图,兼顾了浅层纹理信息和深层语义信息. 以上几种方法均通过增大感受野来捕捉到更为丰富的上下文信息,提高模型的检测性能,但并未考虑到背景和目标混淆的问题.
为了提高小目标检测精度、减少小目标误检漏检,本研究提出基于特征增强和融合注意力机制的光学遥感图像小目标检测算法FMCM-YOLO,主要贡献如下. 1)设计了四头检测模型,添加一层适合于小目标尺寸的小目标检测层以及对应尺寸的检测头,提高算法对小目标的检测能力. 2)提出特征增强模块MFFM,通过引入不同尺寸的空洞卷积,在有效限制网格效应的前提下增大感受野,增强对小目标特征的提取能力. 3)提出融合注意力机制模块CASA,将通道注意力机制和空间注意力机制融合后,添加残差结构,增强特征的传播,使算法更易区分出目标和背景,有效防止前背景混淆. 4)引入MPDIoU损失函数,以适应模型复杂度提高所带来的影响,加快模型收敛速度.
1. 网络设计
1.1. FMCM-YOLO网络结构
采用YOLOv5m作为基线网络,提出针对光学遥感图像小目标的改进检测算法FMCM-YOLO,该算法整体框架如图1所示. 首先,在原始颈部网络上增加一层小目标层并添加对应尺寸大小的检测头,将原始三头检测模型转变为四头检测模型. 其次,在通过主干网络对输入图像进行特征提取后,使用MFFM模块对不同尺寸特征图进行特征增强. 随后,所提取的特征通过融入注意力机制的颈部网络完成高低层信息的融合. 最后,在训练阶段引入MPDIoU损失函数,加快网络收敛速度,提高模型检测精度.
图 1
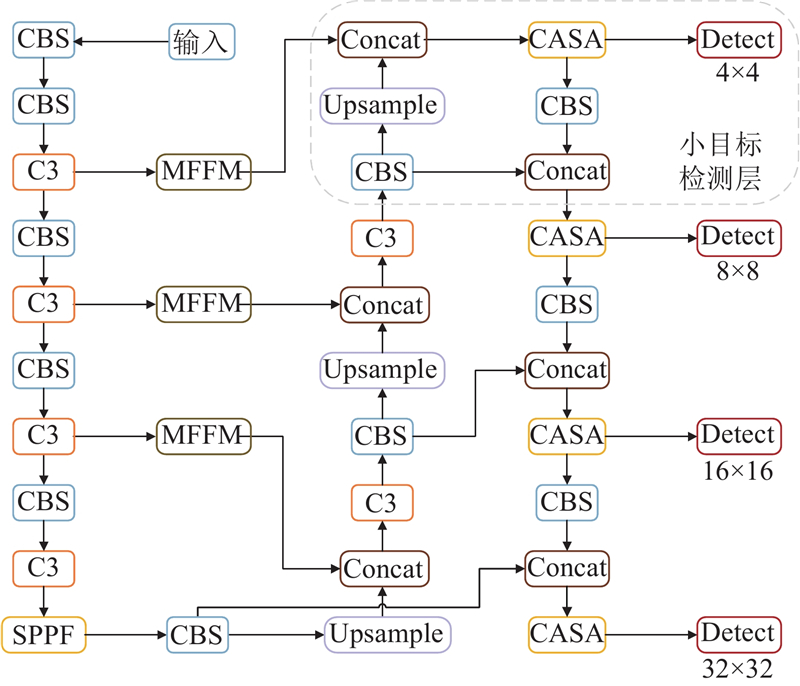
1.2. 小目标检测层
YOLOv5算法输入层统一将输入图像的尺寸大小转化640×640像素,随后在主干网络中采用多个CBS和C3模块对输入图像进行充分的特征提取. 为了保持统一性,本研究中除特殊说明外,特征图和物体尺寸的单位均为像素. 其中,每个CBS模块都会对输入图像进行2倍的下采样,C3模块则通过残差结构充分提取图像中的特征. 在主干网络多组CBS和C3模块的作用下,分别得到尺寸大小为80×80、40×40、20×20的特征图. 但网络深度的增加,会导致小目标的细粒度特征丢失,不能充分利用到小目标的浅层纹理信息. 此外,主干网络最小的采样倍数为8,这表明算法很难在图像中捕获到尺寸小于或等于8×8的物体,会导致严重的漏检问题.
本研究在YOLOv5颈部网络的基础上增加一层针对小目标的检测层,并添加对应尺寸特征图的检测头,如图1虚线框部分所示. 小目标检测层引入尺寸大小为160×160的特征图,该尺寸特征图为原始特征图经过4倍下采样所得到. 在该尺寸特征图中,每一个像素点都包含了原始特征图中4×4像素区域的信息. 并且,在头部网络中增加一个针对160×160大小特征图的检测头,以适应微小目标的检测,增强算法对小目标的检测能力.
1.3. 特征增强模块MFFM
MFFM模块通过不同膨胀率的空洞卷积增大感受野,充分提取低层级特征图中的信息. 采用多分支卷积结构,各分支之间并联组合,如图2所示. 各分支均先采用卷积核大小为1×1的标准二维卷积降低通道数;随后,前3个分支分别添加卷积核大小为3×3、不同膨胀率的空洞卷积,增大感受野;最后一个分支为残差结构,目的是保留小目标的浅层纹理信息.
图 2
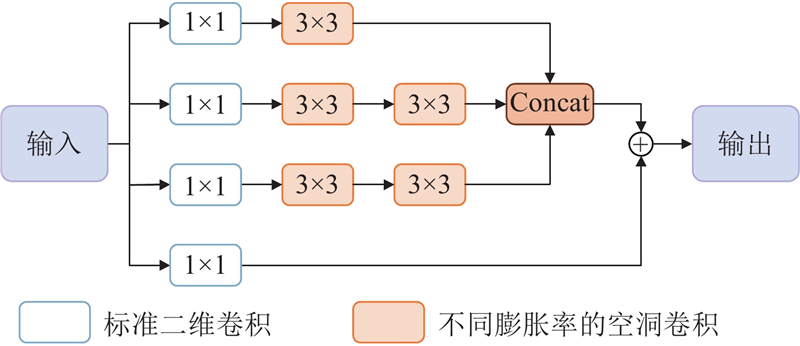
使用不同膨胀率的空洞卷积,可以有效限制网格效应,避免信息丢失. 输入特征图
式中:
1.4. 融合注意力机制模块CASA
图 3
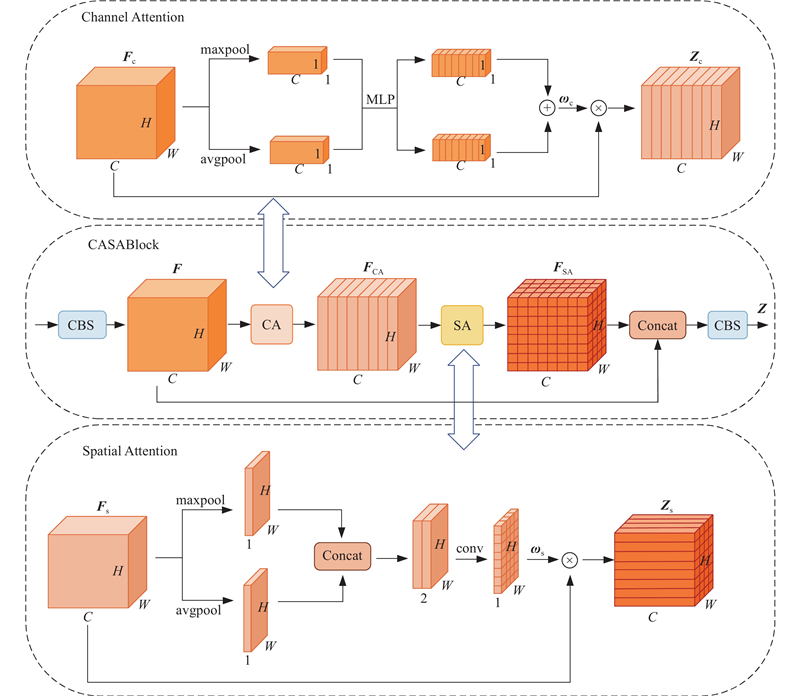
图 4
CA模块的上支路对输入特征图分别进行通道维度上的全局平均池化和最大池化操作,随后通过多层感知机(multilayer perceptron, MLP)学习2种不同的特征,并将其进行按位相加,经Relu函数激活后得到通道注意力机制权重. 最后,将权重与输入特征图相乘,再使用Sigmoid函数激活得到CA的输出特征图. 具体计算过程如下:
式中:
SA模块的上支路对输入特征图分别进行空间维度上的全局平均池化和最大池化操作,并拼接获得的特征图,使用7×7的卷积提取特征,然后使用Sigmoid函数激活得到空间注意力权重. 最后,将权重与输入特征图相乘后使用Sigmoid函数激活得到SA输出特征图. 具体计算过程如下:
式中:
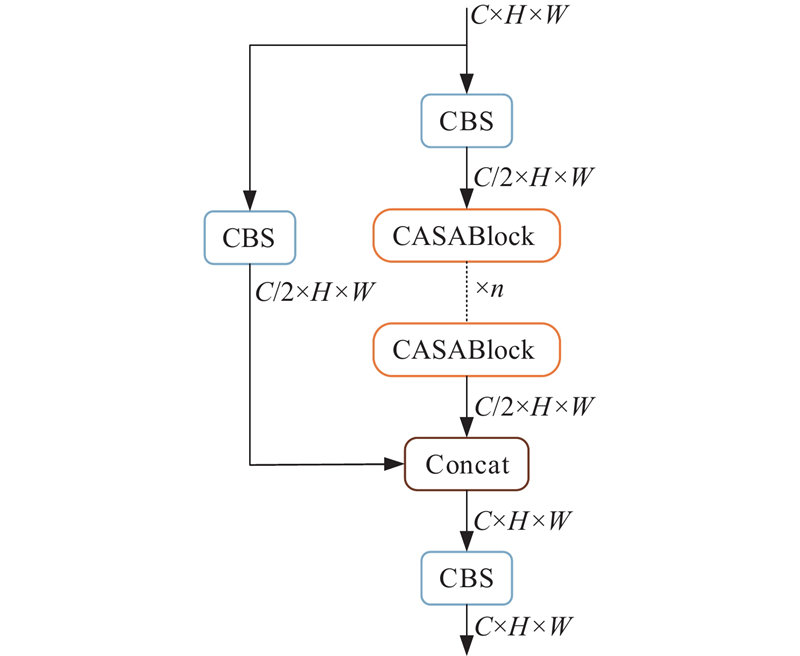
在CASABlock中,首先采用1×1的卷积降低通道数,随后分为2个分支:在上支路中,输入特征图
在下支路中,直接将特征图
式中:
用封装好的CASA模块,替换原始PAN结构中的C3模块,使颈部网络具有融合注意力机制,提高网络整体对于小目标的敏感程度.
1.5. MPDIoU损失函数
模块的添加使得网络整体复杂度提高,收敛速度变慢,而YOLOv5原始损失函数CIoU仅考虑预测框宽高比的相对值,当真实框和预测框具有相同的宽高比,但是宽和高的具体值不同时,损失函数CIoU将失去有效性,这将极大地限制模型的收敛速度和预测精度.
图 5
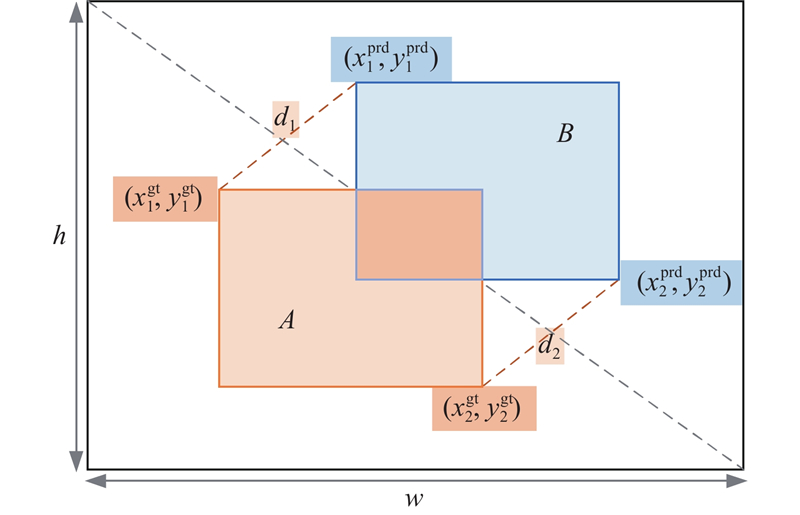
MPDIoU损失函数定义如下:
式中:
2. 实验结果与分析
2.1. 数据集
1) USOD数据集共包括
图 6
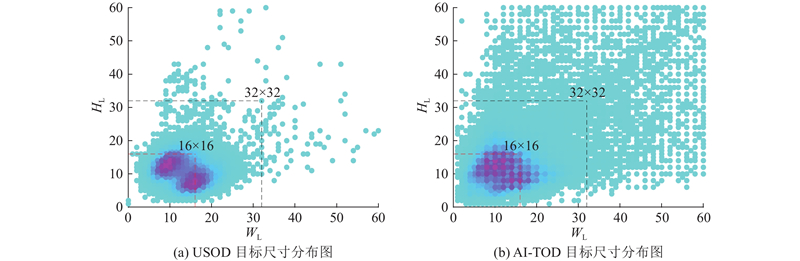
2) AI-TOD数据集包含
图6中不同深浅的颜色代表不同尺寸物体的数量分布,颜色越深表示该尺寸物体的数量越多;HL、WL分别表示数据集中物体标签框的高度和宽度. 由此可知,本研究所选取的2个数据集中的小目标居多,符合本研究的需求.
2.2. 实验环境及评估指标
使用Ubuntu22.04.4操作系统,GPU为一块24 G显存的NVDIARTX 4090D,所选深度学习计算框架为PyTorch,使用深度学习平台CUDA11.8对运行代码所需的工具库进行管理,使用PyCharm软件运行所述模型代码,训练采用SGD优化器,训练超参数设置参见表1.
表 1 模型训练超参数设置
Tab.1
| 参数 | 数值 | 参数 | 数值 | |
| 批次大小 | 16 | 权重衰减系数 | 0.005 | |
| 训练轮次 | 300 | 学习率动量 | 0.937 | |
| 初始学习率 | 0.01 | 图片尺寸 | 640×640 |
对于USOD数据集,选取精确率P、召回率R、平均均值精度mAP、参数量params以及每秒帧数FPS作为评估指标. 其中,精确率表示正确检出目标的概率;召回率表示目标被成功检测的概率;mAP50表示交并比阈值为0.5时,各类别平均精确度的均值;mAP50:95表示以0.05为步长,交并比阈值从0.50至0.95的10个不同阈值下各类别平均精确度的均值;Params是指模型需要训练的参数总数;FPS表示模型每秒能处理图像的数量.
对于AI-TOD数据集,除了选取mAP50和mAP50:95作为性能评估指标外,使用数据集官方提供的mAPvt、mAPt、mAPs作为额外的性能评估指标. mAPvt表示物体尺寸小于8×8时的平均均值精度,即非常微小目标的检测精度;mAPt表示物体尺寸在8×8和16×16之间的平均均值精度,即微小目标的检测精度;mAPs表示物体尺寸在16×16和32×32之间的平均均值精度,即小目标的检测精度.
2.3. 消融实验
为了验证本研究所增加的小目标检测层、MFFM、CASA和MPDIoU的有效性,基于USOD数据集设计10个消融实验,具体实验情况如表2所示,其中最佳指标通过加粗表示. 从实验B可以看出,在增加小目标检测层后,相较于基线算法,精确度、召回率、mAP50和mAP50:95分别提升1.2、0.5、0.8和0.8个百分点. 由此说明,小目标检测层和对应检测头的加入,使模型在小目标居多的场景拥有更好的表现. 实验C在基线算法的基础上增加MFFM,精确率、召回率和mAp50分别提高1.0、1.7和0.7个百分点,可见不同膨胀率的空洞卷积对特征进行增强使得检测性能得到进一步提升. 实验D在基线算法的基础上增加CASA,参数量仅增加0.07×106,而精确率、召回率、mAP50和mAP50:95分别提高2.9、0.9、1.5和1.4个百分点. 可知,引入融合注意力机制大大地提高了算法区分物体和背景的能力,有效地解决了前背景混淆的问题. 由实验E可知,将损失函数替换为MPDIoU后,模型损失值降低,模型误差变小,检测性能得到改善. 相较于其他实验结果,实验J在精确度、召回率、mAP50和mAP50:95上均有显著提升,但是增加了参数量(Params)和浮点运算次数(GFLOPs),存在较高的复杂度.
表 2 不同改进点组合的消融实验结果分析
Tab.2
| 序号 | 小目标层 | MFFM | CASA | MPDIoU | P/% | R/% | mAP50/% | mAP50:95/% | Params/106 | GFLOPs |
| A | — | — | — | — | 88.5 | 81.5 | 87.1 | 31.9 | 20.85 | 47.9 |
| B | √ | — | — | — | 89.7 | 82.0 | 87.9 | 32.7 | 21.29 | 56.3 |
| C | — | √ | — | — | 89.5 | 83.2 | 87.8 | 31.9 | 21.62 | 52.1 |
| D | — | — | √ | — | 91.4 | 82.4 | 88.6 | 33.3 | 20.92 | 48.3 |
| E | — | — | — | √ | 89.9 | 83.1 | 88.2 | 32.8 | 20.85 | 47.9 |
| F | √ | √ | √ | — | 91.7 | 84.0 | 89.1 | 33.0 | 22.13 | 62.3 |
| G | √ | √ | — | √ | 90.7 | 83.0 | 88.7 | 32.7 | 22.13 | 62.2 |
| H | √ | — | √ | √ | 91.3 | 83.3 | 89.0 | 32.9 | 21.33 | 56.4 |
| I | — | √ | √ | √ | 91.5 | 83.7 | 89.3 | 32.9 | 21.65 | 51.8 |
| J | √ | √ | √ | √ | 92.3 | 84.1 | 89.9 | 34.1 | 22.13 | 62.3 |
2.4. 对比实验
为了进一步探究本研究算法的性能表现,分别在USOD数据集和AI-TOD数据上设计了不同的对比实验.
2.4.1. 基于USOD数据集的对比实验
将FMCM-YOLO与YOLOv5基线算法、RefineDet[17]、YOLOv8[18]、TPH-YOLOv5[19]、MSFE-YOLO-m[20]、LS-YOLO[21]、L-FFCA-YOLO[15]等最新目标检测算法在精确度、召回率、平均均值精度和参数量上进行比较,结果如表3所示. FMCM-YOLO较基线算法在准确率、召回率、mAP50和mAP50:95分别提升3.8、2.6、2.8、2.2个百分点,并且较其他主流的检测算法也有不同程度的提升. FMCM-YOLO算法增加了单独的小目标检测层、CASA模块也更为复杂,对比基线算法,牺牲了一定的实时性,不过实时性仍优于大多数小目标检测算法.
表 3 不同算法在USOD上的性能比较结果
Tab.3
| 模型 | P/% | R/% | mAP50/% | mAP50:95/% | Params/106 | FPS |
| RefineDet | 88.1 | 82.4 | 85.1 | 31.4 | 35.68 | 32 |
| YOLOv5m | 88.5 | 81.5 | 87.1 | 31.9 | 20.85 | 258 |
| YOLOv8m | 90.5 | 82.2 | 87.6 | 32.4 | 29.74 | 155 |
| TPH-YOLOv5 | 91.0 | 83.7 | 89.5 | 32.1 | 45.36 | 134 |
| MSFE-YOLO-m | 91.6 | 83.5 | 89.6 | 33.1 | 59.5 | 137 |
| LS-YOLO | 90.8 | 83.6 | 89.3 | 33.9 | 22.6 | 153 |
| L-FFCA-YOLO | 91.3 | 82.8 | 89.3 | 33.2 | 5.10 | 165 |
| FMCM-YOLO(本研究算法) | 92.3 | 84.1 | 89.9 | 34.1 | 22.13 | 169 |
2.4.2. 基于AI-TOD数据集的对比实验
将FMCM-YOLO与YOLOv5基线算法、DedectoRS[22]、M-CenterNet[16]、HANet[23]、FFCA-YOLO[15]和L-FFCA-YOLO[15]等目标检测算法进行比较,选取5种不同的mAP作为评估指标,结果如表4所示. 可以看出,相较于基线算法,mAP50、mAP50:95、mAPvt和mAPt、mAPs分别提高5.9、5.0、2.1、6.5和5.1个百分点. DedectoRS算法的mAPvt为0,即该算法在面对目标较小的情况时,检测能力有限,无法检测出尺寸较小的目标. FMCM-YOLO算法的mAP50和mAP50:95较次于目前性能最优越的FFCA-YOLO算法,mAPvt与其持平,但是mAPt和mAPs分别提高3.7和0.3个百分点,说明FMCM-YOLO算法在整体性能上虽然不及FFCA-YOLO算法,但是在针对小目标和微小目标时,FMCM-YOLO算法具有更强的检测性能.
表 4 不同算法在AI-TOD上的性能比较结果
Tab.4
| 模型 | mAP50/% | mAP50:95/% | mAPvt/% | mAPt/% | mAPs/% | FPS |
| DedectoRS | 32.8 | 14.8 | 0 | 10.8 | 28.3 | 61 |
| M-CenterNet | 40.7 | 14.5 | 6.1 | 15.0 | 19.4 | 78 |
| YOLOv5m | 54.7 | 21.7 | 10.5 | 22.1 | 27.0 | 258 |
| HANet | 53.7 | 22.1 | 10.9 | 22.2 | 27.3 | 178 |
| FFCA-YOLO | 61.7 | 27.7 | 12.6 | 24.9 | 31.8 | 171 |
| L-FFCA-YOLO | 58.3 | 25.5 | 11.7 | 23.2 | 30.1 | 165 |
| FMCM-YOLO(本研究算法) | 60.6 | 26.7 | 12.6 | 28.6 | 32.1 | 169 |
另外,如表5所示,在算法改进前、后,针对不同类别目标的检测性能进行对比. 可以看出,所有类别的平均均值精度均有不同程度的提高. 由于FMCM-YOLO算法在2个数据集上均有不错的表现,说明所提算法具有较为出色的泛化性.
表 5 改进前、后AI-TOD数据集各类别目标的检测性能比较
Tab.5
| 类别 | mAP50/% | |
| FMCM-YOLO | YOLOv5m | |
| all | 60.6 | 54.7 |
| airplane | 66.9 | 64.3 |
| bridge | 50.4 | 44.9 |
| storage-tank | 88.9 | 77.9 |
| ship | 78.9 | 75.0 |
| swimming-pool | 51.7 | 51.2 |
| vehicle | 77.7 | 69.9 |
| person | 39.2 | 31.3 |
| wind-mill | 33.4 | 23.3 |
2.5. 可视化实验
2.5.1. 损失函数效果对比
图 7
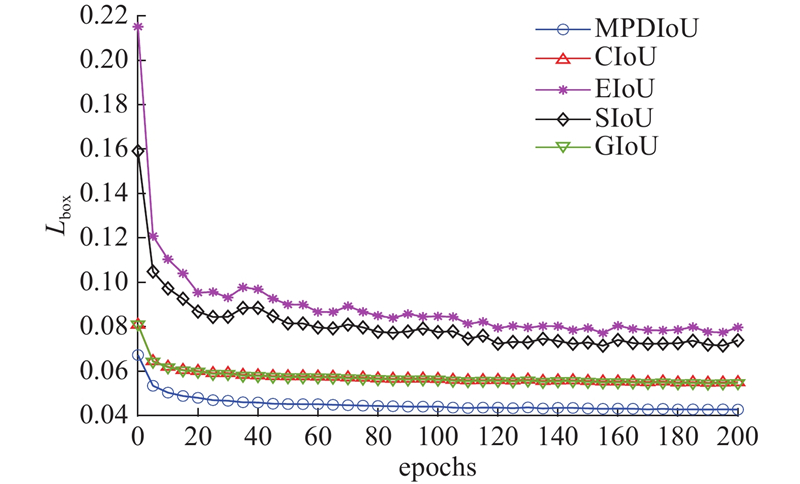
2.5.2. 可视化结果分析
为了验证本研究在实际场景中的使用效果,在AI-TOD的测试集中选取不同场景的图片进行测试,结果如图8所示,其中部分细节通过放大进行展示. 由于部分场景目标较为密集,为了更好地观察检测效果,在使用模型对图片进行检测时,将类别标签和置信度进行剔除仅保留检测框. 从图中可以看出,YOLOv5m算法在面对目标密集的场景时,漏检现象严重;而FMCM-YOLO算法能够轻松地检测出密集的小目标,将小目标区分开来. 特别,在夜间能见度较差的场景中,FMCM-YOLO的表现也较为出色.
图 8

图 8 模型改进前、后可视化检测效果对比
Fig.8 Comparison of visual detection effects before and after model improvement
3. 结 语
为了解决光学遥感图像中小目标特征提取受限、前背景混淆、漏检误检严重等问题,提出专门针对小目标的检测模型FMCM-YOLO. 首先,设计了一种四头检测模型,以更好地检测出光学遥感图像中繁多的小目标;其次,在主干网络中添加特征增强层MFFM,提高特征提取能力,增强算法检测性能;然后,在融合通道注意力机制和空间注意力机制后,引入残差结构,封装成CASA模块,替换掉Detect模块前的C3模块,使算法更易区分出目标和背景以防止前背景混淆;最后,引入MPDIoU损失函数,简化损失计算过程,加快模型收敛速度. 在USOD和AI-TOD这2个数据集上分别进行实验,实验结果表明所提算法在检测性能上较基准算法和其余主流检测算法均有不同程度的提升,表明所提算法在检测光学遥感图像中小目标时具有一定的优越性和鲁棒性.
虽然本研究所提算法在检测性能方面有所提升,但是须付出更多的计算代价,因此下一步研究将针对模型规模,在保证性能的同时,提出计算复杂度更低的模型,以适应计算资源有限的场景.
参考文献
基于遥感影像的军事阵地动态监测技术研究
[J].DOI:10.11873/j.issn.1004-0323.2014.3.0511 [本文引用: 1]
Dynamic monitoring of military position based on remote sensing image
[J].DOI:10.11873/j.issn.1004-0323.2014.3.0511 [本文引用: 1]
多分辨率特征融合的光学遥感图像目标检测
[J].
Optical remote sensing image object detection based on multi-resolution feature fusion
[J].
MAR20: 遥感图像军用飞机目标识别数据集
[J].DOI:10.11834/jrs.20222139 [本文引用: 1]
MAR20: a benchmark for military aircraft recognition in remote sensing images
[J].DOI:10.11834/jrs.20222139 [本文引用: 1]
An improved YOLOv5 method for small object detection in UAV capture scenes
[J].DOI:10.1109/ACCESS.2023.3241005 [本文引用: 1]
DKA-YOLO: enhanced small object detection via dilation kernel aggregation convolution modules
[J].DOI:10.1109/ACCESS.2024.3515201 [本文引用: 1]
多尺度特征融合的遥感图像目标检测算法研究
[J].
Research on object detection algorithm for remote sensing images based on multi-scale fea-ture fusion
[J].
注意力特征融合的快速遥感图像目标检测算法
[J].DOI:10.3778/j.issn.1002-8331.2303-0375 [本文引用: 1]
Fast remote sensing image object detection algorithm based on attention feature fusion
[J].DOI:10.3778/j.issn.1002-8331.2303-0375 [本文引用: 1]
基于特征注意力金字塔的遥感图像目标检测方法
[J].
Feature attention pyramid-based remote sensing image object detection method
[J].
FFCA-YOLO for small object detection in remote sensing images
[J].DOI:10.1109/tgrs.2024.3363057 [本文引用: 4]
MSFE-YOLO: an improved YOLOv8 network for object detection on drone view
[J].DOI:10.1109/lgrs.2024.3432536 [本文引用: 1]
LS-YOLO: a novel model for detecting multiscale landslides with remote sensing images
[J].DOI:10.1109/JSTARS.2024.3363160 [本文引用: 1]
Save the tiny, save the all: hierarchical activation network for tiny object detection
[J].DOI:10.1109/TCSVT.2023.3284161 [本文引用: 1]
Enhancing geometric factors in model learning and inference for object detection and instance segmentation
[J].DOI:10.1109/TCYB.2021.3095305 [本文引用: 1]
Focal and efficient IOU loss for accurate bounding box regression
[J].DOI:10.1016/j.neucom.2022.07.042 [本文引用: 1]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}