[1]
DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]//Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition . San Diego: IEEE, 2005: 886–893.
[本文引用: 1]
[2]
GIRSHICK R, DONAHUE J, DARRELL T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Columbus: IEEE, 2014: 580–587.
[本文引用: 1]
[3]
GIRSHICK R. Fast R-CNN [C]//Proceedings of the IEEE International Conference on Computer Vision . Santiago: IEEE, 2016: 1440–1448.
[本文引用: 1]
[4]
REN S, HE K, GIRSHICK R, et al Faster R-CNN: towards real-time object detection with region proposal networks
[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence , 2017 , 39 (6 ): 1137 - 1149
DOI:10.1109/TPAMI.2016.2577031
[本文引用: 1]
[5]
HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-CNN [C]//Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2980–2988.
[本文引用: 1]
[6]
赵志宏, 郝子晔 改进YOLOv8的航拍小目标检测方法: CRP-YOLO
[J]. 计算机工程与应用 , 2024 , 60 (13 ): 209 - 218
[本文引用: 1]
ZHAO Zhihong, HAO Ziye Improved YOLOv8 aerial small target detection method: CRP-YOLO
[J]. Computer Engineering and Applications , 2024 , 60 (13 ): 209 - 218
[本文引用: 1]
[7]
LIU W, ANGUELOV D, ERHAN D, et al. SSD: single shot MultiBox detector [C]// 14th European Conference on Computer Vision . Cham: Springer, 2016: 21–37.
[本文引用: 1]
[8]
REDMON J, DIVVALA S, GIRSHICK R, et al. You only look once: unified, real-time object detection [C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition . Las Vegas: IEEE, 2016: 779–788.
[本文引用: 1]
[9]
TANG S, ZHANG S, FANG Y. HIC-YOLOv5: improved YOLOv5 for small object detection [C]//Proceedings of the IEEE International Conference on Robotics and Automation . Yokohama: IEEE, 2024: 6614-6619.
[本文引用: 1]
[10]
YANG Y. Drone-view object detection based on the improved YOLOv5 [C]//Proceedings of the IEEE International Conference on Electrical Engineering, Big Data and Algorithms . Changchun: IEEE, 2022: 612–617.
[本文引用: 1]
[11]
韩俊, 袁小平, 王准, 等 基于YOLOv5s的无人机密集小目标检测算法
[J]. 浙江大学学报: 工学版 , 2023 , 57 (6 ): 1224 - 1233
[本文引用: 1]
HAN Jun, YUAN Xiaoping, WANG Zhun, et al UAV dense small target detection algorithm based on YOLOv5s
[J]. Journal of Zhejiang University: Engineering Science , 2023 , 57 (6 ): 1224 - 1233
[本文引用: 1]
[12]
张徐, 朱正为, 郭玉英, 等 基于cosSTR-YOLOv7的多尺度遥感小目标检测
[J]. 电光与控制 , 2024 , 31 (4 ): 28 - 34
[本文引用: 3]
ZHANG Xu, ZHU Zhengwei, GUO Yuying, et al Multi-scale remote sensing small target detection based on cosSTR-YOLOv7
[J]. Electronics Optics and Control , 2024 , 31 (4 ): 28 - 34
[本文引用: 3]
[13]
王燕妮, 张婧菲. 改进YOLOv8的无人机小目标检测算法 [J/OL]. 探测与控制学报, 2024, 46(6): 1–10. (2024-12-12). https://kns.cnki.net/KCMS/detail/detail.aspx?filename=XDYX20241211005&dbname=CJFD&dbcode=CJFQ.
[本文引用: 3]
WANG Yanni, ZHANG Jingfei. A modified YOLOv8 algorithm for UAV small object detection [J/OL]. Journal of Detection and Control , 2024, 46(6): 1–10. (2024-12-12). https://kns.cnki.net/KCMS/detail/detail.aspx?filename=XDYX20241211005&dbname=CJFD&dbcode=CJFQ.
[本文引用: 3]
[14]
WANG G, CHEN Y, AN P, et al UAV-YOLOv8: a small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios
[J]. Sensors , 2023 , 23 (16 ): 7190
DOI:10.3390/s23167190
[15]
李岩超, 史卫亚, 冯灿 面向无人机航拍小目标检测的轻量级YOLOv8检测算法
[J]. 计算机工程与应用 , 2024 , 60 (17 ): 167 - 178
LI Yanchao, SHI Weiya, FENG Can Lightweight YOLOv8 detection algorithm for small object detection in UAV aerial photography
[J]. Computer Engineering and Applications , 2024 , 60 (17 ): 167 - 178
[16]
龙伍丹, 彭博, 胡节, 等 基于加强特征提取的道路病害检测算法
[J]. 计算机应用 , 2024 , 44 (7 ): 2264 - 2270
[本文引用: 1]
LONG Wudan, PENG Bo, HU Jie, et al Road damage detection algorithm based on enhanced feature extraction
[J]. Journal of Computer Applications , 2024 , 44 (7 ): 2264 - 2270
[本文引用: 1]
[17]
JIAO J, TANG Y M, LIN K Y, et al DilateFormer: multi-scale dilated transformer for visual recognition
[J]. IEEE Transactions on Multimedia , 2023 , 25 : 8906 - 8919
DOI:10.1109/TMM.2023.3243616
[本文引用: 1]
[18]
徐佩, 陈亚江 融合Swin Transformer的YOLOv5口罩检测算法
[J]. 智能计算机与应用 , 2024 , 14 (5 ): 83 - 92
[本文引用: 1]
XU Pei, CHEN Yajiang Mask detection algorithm based on YOLOv5 integrating Swin Transformer
[J]. Intelligent Computer and Applications , 2024 , 14 (5 ): 83 - 92
[本文引用: 1]
[19]
李登峰, 高明, 叶文韬 结合轻量级特征提取网络的舰船目标检测算法
[J]. 计算机工程与应用 , 2023 , 59 (23 ): 211 - 218
[本文引用: 1]
LI Dengfeng, GAO Ming, YE Wentao Ship target detection algorithm combined with lightweight feature extraction network
[J]. Computer Engineering and Applications , 2023 , 59 (23 ): 211 - 218
[本文引用: 1]
[20]
YU H, WAN C, LIU M, et al. Real-time image segmentation via hybrid convolutional-transformer architecture search [EB/OL]. (2024-03-15). https://arxiv.org/abs/2403.10413.
[本文引用: 1]
[21]
徐光达, 毛国君 多层级特征融合的无人机航拍图像目标检测
[J]. 计算机科学与探索 , 2023 , 17 (3 ): 635 - 645
[本文引用: 1]
XU Guangda, MAO Guojun Aerial image object detection of UAV based on multi-level feature fusion
[J]. Journal of Frontiers of Computer Science and Technology , 2023 , 17 (3 ): 635 - 645
[本文引用: 1]
[22]
张洋, 夏英 多尺度特征融合的遥感图像目标检测方法
[J]. 计算机科学 , 2024 , 51 (3 ): 165 - 173
[本文引用: 1]
ZHANG Yang, XIA Ying Object detection method with multi-scale feature fusion for remote sensing images
[J]. Computer Science , 2024 , 51 (3 ): 165 - 173
[本文引用: 1]
[23]
曹利, 徐慧英, 谢刚, 等. ASOD-YOLO: 基于YOLOv8n改进的航空小目标检测算法 [J/OL]. 计算机工程与科学, 2024, 46(9): 1–13. (2024-09-27). https://kns.cnki.net/KCMS/detail/detail.aspx?filename=JSJK20240906002&dbname=CJFD&dbcode=CJFQ.
[本文引用: 1]
CAO Li, XU Huiying, XIE Gang, et al. ASOD-YOLO: improved aviation small objection detection algorithm based on YOLOv8n [J/OL]. Computer Engineering and Science , 2024, 46(9): 1–13. (2024-09-27). https://kns.cnki.net/KCMS/detail/detail.aspx?filename=JSJK20240906002&dbname=CJFD&dbcode=CJFQ.
[本文引用: 1]
[24]
LIN T Y, GOYAL P, GIRSHICK R, et al. Focal loss for dense object detection [C]//Proceedings of the IEEE International Conference on Computer Vision . Venice: IEEE, 2017: 2999–3007.
[本文引用: 1]
[25]
CAI Z, VASCONCELOS N. Cascade R-CNN: delving into high quality object detection [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . Salt Lake City: IEEE, 2018: 6154–6162.
[本文引用: 1]
[26]
LI C, LI L, JIANG H, et al. YOLOv6: a single-stage object detection framework for industrial applications [EB/OL]. (2022-09-07). https://arxiv.org/abs/2209.02976
[本文引用: 1]
[27]
PAN X, GE C, LU R, et al. On the integration of self-attention and convolution [C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition . New Orleans: IEEE, 2022: 805–815.
[本文引用: 1]
[28]
YANG L, ZHANG R Y, LI L, et al. SimAM: a simple, parameter-free attention module for convolutional neural networks [C]//Proceedings of the International Conference on Machine Learning . Graz: ACM, 2021: 11863-11874.
[本文引用: 1]
[29]
HE S, MING A, ZHENG S, et al. EAT: an enhancer for aesthetics-oriented transformers [C]//Proceedings of the 31st ACM International Conference on Multimedia . Ottawa: ACM, 2023: 1023–1032.
[本文引用: 1]
1
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
1
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
1
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
Faster R-CNN: towards real-time object detection with region proposal networks
1
2017
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
1
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
改进YOLOv8的航拍小目标检测方法: CRP-YOLO
1
2024
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
改进YOLOv8的航拍小目标检测方法: CRP-YOLO
1
2024
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
1
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
1
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
1
... 在无人机平台的目标检测领域,传统方法如DPM和Hog+Svm[1 ] 步骤繁复且效率低下,而深度学习方法虽然提高了检测精度,但在速度和实时性方面存在挑战. 特别是,双阶段方法(如R-CNN[2 ] 、Fast R-CNN[3 ] 、Faster R-CNN[4 ] 和Mask R-CNN[5 ] 等)尽管精度较高,但检测速度慢,这对于需要在飞行途中快速应对障碍物的航空飞行器来说是一个严重的限制因素[6 ] . 相比之下,单阶段检测方法如SSD[7 ] 和YOLO[8 ] 系列,虽然在一定程度上兼顾了精度和实时性,但在处理多尺度目标检测,尤其是小目标检测方面,存在特征丢失、模型复杂度高以及计算量大等问题[9 ] . ...
1
... 为了增强YOLO模型在航空目标检测领域的性能,多位研究者对模型进行了多种改进尝试. 在YOLOv5的结构中,Yang等[10 ] 引入上采样模块,提取小目标的特征图. 韩俊等[11 ] 改进YOLOv5s,提出LSA_YOLO算法,采用多尺度特征提取、混合域注意力与自适应特征融合. 此外,张徐等[12 ] 通过改进YOLOv7网络,引入余弦注意力机制与正则化策略. 虽然现有方法在复杂背景下的多尺度目标检测中有效,但应对高原地形时仍有不足. ...
基于YOLOv5s的无人机密集小目标检测算法
1
2023
... 为了增强YOLO模型在航空目标检测领域的性能,多位研究者对模型进行了多种改进尝试. 在YOLOv5的结构中,Yang等[10 ] 引入上采样模块,提取小目标的特征图. 韩俊等[11 ] 改进YOLOv5s,提出LSA_YOLO算法,采用多尺度特征提取、混合域注意力与自适应特征融合. 此外,张徐等[12 ] 通过改进YOLOv7网络,引入余弦注意力机制与正则化策略. 虽然现有方法在复杂背景下的多尺度目标检测中有效,但应对高原地形时仍有不足. ...
基于YOLOv5s的无人机密集小目标检测算法
1
2023
... 为了增强YOLO模型在航空目标检测领域的性能,多位研究者对模型进行了多种改进尝试. 在YOLOv5的结构中,Yang等[10 ] 引入上采样模块,提取小目标的特征图. 韩俊等[11 ] 改进YOLOv5s,提出LSA_YOLO算法,采用多尺度特征提取、混合域注意力与自适应特征融合. 此外,张徐等[12 ] 通过改进YOLOv7网络,引入余弦注意力机制与正则化策略. 虽然现有方法在复杂背景下的多尺度目标检测中有效,但应对高原地形时仍有不足. ...
基于cosSTR-YOLOv7的多尺度遥感小目标检测
3
2024
... 为了增强YOLO模型在航空目标检测领域的性能,多位研究者对模型进行了多种改进尝试. 在YOLOv5的结构中,Yang等[10 ] 引入上采样模块,提取小目标的特征图. 韩俊等[11 ] 改进YOLOv5s,提出LSA_YOLO算法,采用多尺度特征提取、混合域注意力与自适应特征融合. 此外,张徐等[12 ] 通过改进YOLOv7网络,引入余弦注意力机制与正则化策略. 虽然现有方法在复杂背景下的多尺度目标检测中有效,但应对高原地形时仍有不足. ...
... Model comparison experiment conducted on FOD dataset
Tab.2 模型 mAP@0.5/ mAP@0.5:0.95/ N p /6 FLOPs/9 Faster-RCNN 73.8 40.7 41.2 206.7 RetinaNet 70.7 38.1 19.8 93.7 Cascade-RCNN 71.4 39.2 — — YOLOv3-tiny 69.8 37.9 12.1 19.1 YOLOv5n 72.1 39.8 1.8 4.3 YOLOv5s 73.8 41.3 7.0 15.8 YOLOv6n 72.3 40.9 4.2 11.9 YOLOv8n 72.9 41.8 3.0 8.1 cosSTR-YOLOv7[12 ] 75.1 43.5 52.9 263.5 YOLOv8-NDTiny [13 ] 74.8 42.3 2.3 11.7 AO-YOLO 75.6 43.8 2.4 6.1
从表2 的对比实验数据可知,与其他主流的目标检测算法和改进算法相比,AO-YOLO算法在检测性能上更出色,计算量更少. ...
... Experimental result on VisDrone2019
Tab.4 模型 mAP@0.5/% FLOPs/109 Faster-RCNN 33.1 206.7 RetinaNet 26.5 93.7 YOLOv3-tiny 31.9 19.1 YOLOv5s 32.4 15.8 YOLOv6n 30.2 11.9 YOLOv8n 33.5 8.1 cosSTR-YOLOv7[12 ] 34.7 263.5 YOLOv8-NDTiny [13 ] 34.3 11.7 AO-YOLO 35.0 6.1
表 5 在NWPU VHR-10上的实验结果 ...
基于cosSTR-YOLOv7的多尺度遥感小目标检测
3
2024
... 为了增强YOLO模型在航空目标检测领域的性能,多位研究者对模型进行了多种改进尝试. 在YOLOv5的结构中,Yang等[10 ] 引入上采样模块,提取小目标的特征图. 韩俊等[11 ] 改进YOLOv5s,提出LSA_YOLO算法,采用多尺度特征提取、混合域注意力与自适应特征融合. 此外,张徐等[12 ] 通过改进YOLOv7网络,引入余弦注意力机制与正则化策略. 虽然现有方法在复杂背景下的多尺度目标检测中有效,但应对高原地形时仍有不足. ...
... Model comparison experiment conducted on FOD dataset
Tab.2 模型 mAP@0.5/ mAP@0.5:0.95/ N p /6 FLOPs/9 Faster-RCNN 73.8 40.7 41.2 206.7 RetinaNet 70.7 38.1 19.8 93.7 Cascade-RCNN 71.4 39.2 — — YOLOv3-tiny 69.8 37.9 12.1 19.1 YOLOv5n 72.1 39.8 1.8 4.3 YOLOv5s 73.8 41.3 7.0 15.8 YOLOv6n 72.3 40.9 4.2 11.9 YOLOv8n 72.9 41.8 3.0 8.1 cosSTR-YOLOv7[12 ] 75.1 43.5 52.9 263.5 YOLOv8-NDTiny [13 ] 74.8 42.3 2.3 11.7 AO-YOLO 75.6 43.8 2.4 6.1
从表2 的对比实验数据可知,与其他主流的目标检测算法和改进算法相比,AO-YOLO算法在检测性能上更出色,计算量更少. ...
... Experimental result on VisDrone2019
Tab.4 模型 mAP@0.5/% FLOPs/109 Faster-RCNN 33.1 206.7 RetinaNet 26.5 93.7 YOLOv3-tiny 31.9 19.1 YOLOv5s 32.4 15.8 YOLOv6n 30.2 11.9 YOLOv8n 33.5 8.1 cosSTR-YOLOv7[12 ] 34.7 263.5 YOLOv8-NDTiny [13 ] 34.3 11.7 AO-YOLO 35.0 6.1
表 5 在NWPU VHR-10上的实验结果 ...
3
... 当应对目标尺度多样性时,虽然已有研究采用特征融合策略,如王燕妮等[13 -16 ] 分别对YOLO系列模型进行改进,但这些方法可能导致小目标特征遗失或者模型复杂度增加的问题. ...
... Model comparison experiment conducted on FOD dataset
Tab.2 模型 mAP@0.5/ mAP@0.5:0.95/ N p /6 FLOPs/9 Faster-RCNN 73.8 40.7 41.2 206.7 RetinaNet 70.7 38.1 19.8 93.7 Cascade-RCNN 71.4 39.2 — — YOLOv3-tiny 69.8 37.9 12.1 19.1 YOLOv5n 72.1 39.8 1.8 4.3 YOLOv5s 73.8 41.3 7.0 15.8 YOLOv6n 72.3 40.9 4.2 11.9 YOLOv8n 72.9 41.8 3.0 8.1 cosSTR-YOLOv7[12 ] 75.1 43.5 52.9 263.5 YOLOv8-NDTiny [13 ] 74.8 42.3 2.3 11.7 AO-YOLO 75.6 43.8 2.4 6.1
从表2 的对比实验数据可知,与其他主流的目标检测算法和改进算法相比,AO-YOLO算法在检测性能上更出色,计算量更少. ...
... Experimental result on VisDrone2019
Tab.4 模型 mAP@0.5/% FLOPs/109 Faster-RCNN 33.1 206.7 RetinaNet 26.5 93.7 YOLOv3-tiny 31.9 19.1 YOLOv5s 32.4 15.8 YOLOv6n 30.2 11.9 YOLOv8n 33.5 8.1 cosSTR-YOLOv7[12 ] 34.7 263.5 YOLOv8-NDTiny [13 ] 34.3 11.7 AO-YOLO 35.0 6.1
表 5 在NWPU VHR-10上的实验结果 ...
3
... 当应对目标尺度多样性时,虽然已有研究采用特征融合策略,如王燕妮等[13 -16 ] 分别对YOLO系列模型进行改进,但这些方法可能导致小目标特征遗失或者模型复杂度增加的问题. ...
... Model comparison experiment conducted on FOD dataset
Tab.2 模型 mAP@0.5/ mAP@0.5:0.95/ N p /6 FLOPs/9 Faster-RCNN 73.8 40.7 41.2 206.7 RetinaNet 70.7 38.1 19.8 93.7 Cascade-RCNN 71.4 39.2 — — YOLOv3-tiny 69.8 37.9 12.1 19.1 YOLOv5n 72.1 39.8 1.8 4.3 YOLOv5s 73.8 41.3 7.0 15.8 YOLOv6n 72.3 40.9 4.2 11.9 YOLOv8n 72.9 41.8 3.0 8.1 cosSTR-YOLOv7[12 ] 75.1 43.5 52.9 263.5 YOLOv8-NDTiny [13 ] 74.8 42.3 2.3 11.7 AO-YOLO 75.6 43.8 2.4 6.1
从表2 的对比实验数据可知,与其他主流的目标检测算法和改进算法相比,AO-YOLO算法在检测性能上更出色,计算量更少. ...
... Experimental result on VisDrone2019
Tab.4 模型 mAP@0.5/% FLOPs/109 Faster-RCNN 33.1 206.7 RetinaNet 26.5 93.7 YOLOv3-tiny 31.9 19.1 YOLOv5s 32.4 15.8 YOLOv6n 30.2 11.9 YOLOv8n 33.5 8.1 cosSTR-YOLOv7[12 ] 34.7 263.5 YOLOv8-NDTiny [13 ] 34.3 11.7 AO-YOLO 35.0 6.1
表 5 在NWPU VHR-10上的实验结果 ...
UAV-YOLOv8: a small-object-detection model based on improved YOLOv8 for UAV aerial photography scenarios
0
2023
面向无人机航拍小目标检测的轻量级YOLOv8检测算法
0
2024
面向无人机航拍小目标检测的轻量级YOLOv8检测算法
0
2024
基于加强特征提取的道路病害检测算法
1
2024
... 当应对目标尺度多样性时,虽然已有研究采用特征融合策略,如王燕妮等[13 -16 ] 分别对YOLO系列模型进行改进,但这些方法可能导致小目标特征遗失或者模型复杂度增加的问题. ...
基于加强特征提取的道路病害检测算法
1
2024
... 当应对目标尺度多样性时,虽然已有研究采用特征融合策略,如王燕妮等[13 -16 ] 分别对YOLO系列模型进行改进,但这些方法可能导致小目标特征遗失或者模型复杂度增加的问题. ...
DilateFormer: multi-scale dilated transformer for visual recognition
1
2023
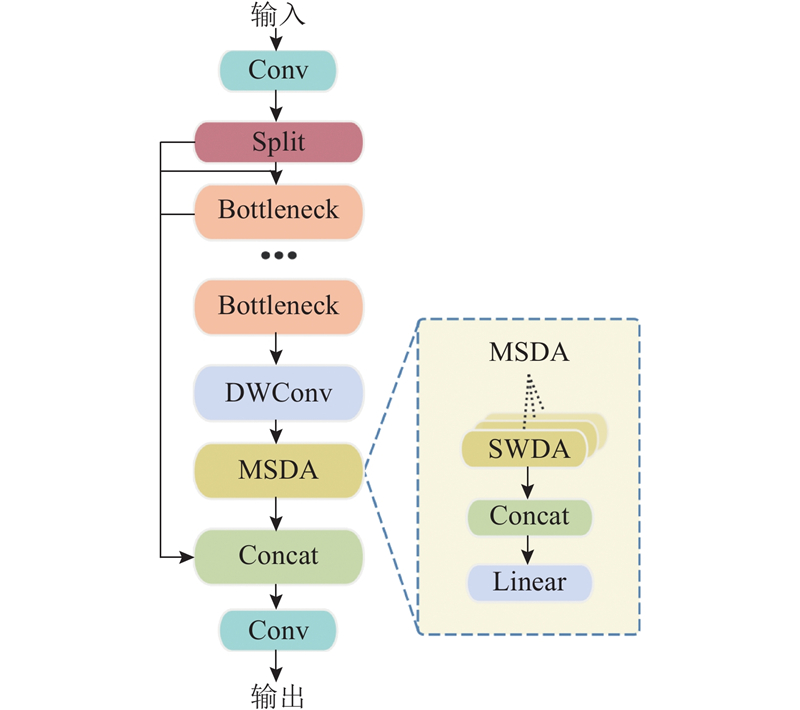
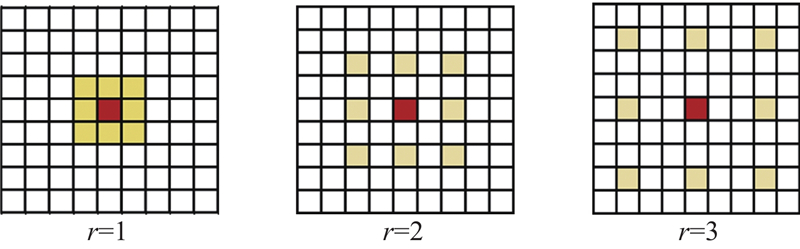
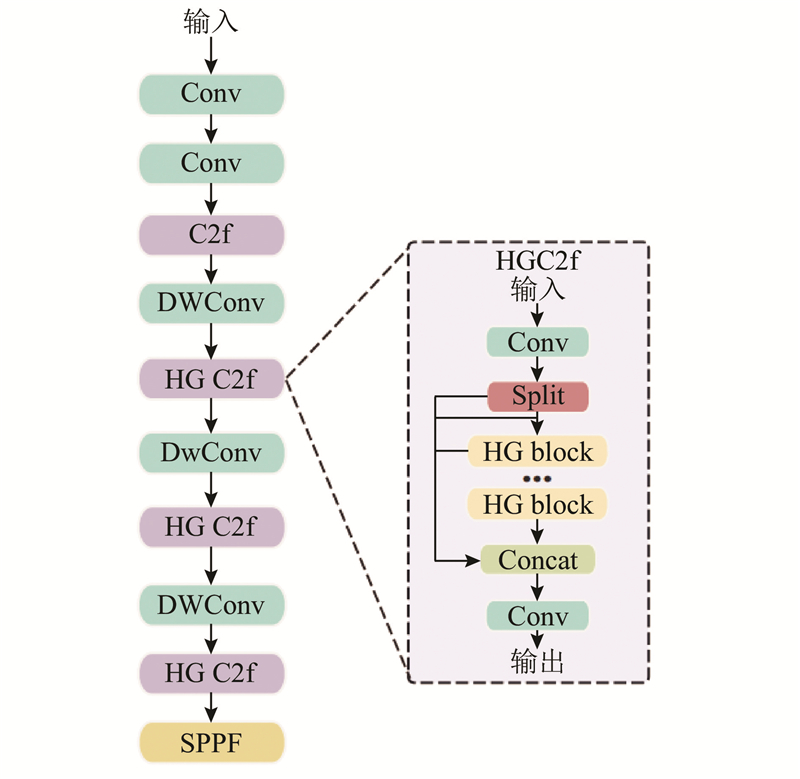
... YOLOv8的颈部网络(Neck)作为连接骨干网络与检测头的关键模块,利用特征金字塔架构(PAN-FPN)整合多尺度特征图,以提高目标检测的鲁棒性. 传统方法在上采样过程中容易引入特征模糊化的问题,并因局部区域信息稀疏而导致上下文语义关联不足,这在高原山区低对比度目标和多尺度障碍物堆叠场景中尤为明显. 为了应对这些问题,提出基于多尺度扩张注意力(MSDA)[17 ] 增强的颈部网络架构,通过构建C2f_MS模块实现精细化特征融合与跨尺度上下文建模,如图2 所示. ...
融合Swin Transformer的YOLOv5口罩检测算法
1
2024
... 为了进一步降低计算复杂度,C2f_MS模块引入深度可分离卷积(depthwise separable convolution, DWConv). 该方法将标准卷积操作分解为深度卷积和逐点卷积2个阶段,在深度卷积阶段,每个输入通道独立应用单通道卷积核[18 ] ,这种设计增强了模型对空间特征的敏感度,避免了额外计算开销. 随后的逐点卷积阶段采用1×1卷积核,对深度卷积的多通道输出进行融合,灵活调整输出通道的数量,促进跨通道信息的高效交互,从而在降低计算复杂度的同时保持了特征表达能力. ...
融合Swin Transformer的YOLOv5口罩检测算法
1
2024
... 为了进一步降低计算复杂度,C2f_MS模块引入深度可分离卷积(depthwise separable convolution, DWConv). 该方法将标准卷积操作分解为深度卷积和逐点卷积2个阶段,在深度卷积阶段,每个输入通道独立应用单通道卷积核[18 ] ,这种设计增强了模型对空间特征的敏感度,避免了额外计算开销. 随后的逐点卷积阶段采用1×1卷积核,对深度卷积的多通道输出进行融合,灵活调整输出通道的数量,促进跨通道信息的高效交互,从而在降低计算复杂度的同时保持了特征表达能力. ...
结合轻量级特征提取网络的舰船目标检测算法
1
2023
... 为了进一步提高模型效率,将主干网络中的部分标准卷积块(Conv)替换为深度可分离卷积(DWConv)[19 ] . DWConv通过分解卷积操作,在保持特征表达能力的同时,显著减少了计算量. ...
结合轻量级特征提取网络的舰船目标检测算法
1
2023
... 为了进一步提高模型效率,将主干网络中的部分标准卷积块(Conv)替换为深度可分离卷积(DWConv)[19 ] . DWConv通过分解卷积操作,在保持特征表达能力的同时,显著减少了计算量. ...
1
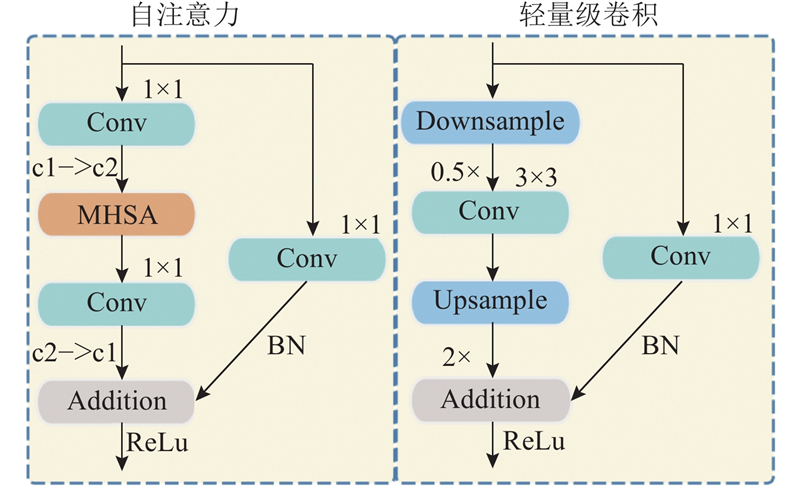
... YOLOv8模型检测头对捕捉图像中的长距离依赖关系能力有限,导致模型对山体、树木障碍物相对空间关系捕捉不足,影响检测精度. 为了提升模型对不同类型障碍物长距离依赖关系的特征提取能力,借鉴HyCTAS 框架[20 ] 的优势,结合内存高效的注意力模块和轻量级卷积模块,构建高效的自注意力模块,将其作为轻量级检测头SADetect来替换YOLOv8模型中原有的普通检测头. ...
多层级特征融合的无人机航拍图像目标检测
1
2023
... 实验分别利用公共遥感数据集VisDrone2019和NWPU VHR-10. VisDrone2019数据集[21 ] 包含8 629张由无人机摄像头捕获的图像,这些图像被划分为包含6 471张样本的训练集、含有548张样本的验证集以及含有1 610张样本的测试集. 数据集共分为行人、人、汽车、面包车、公共汽车、卡车、摩托、自行车、遮阳三轮车和三轮车10类. 该数据集包含复杂背景和多尺度目标,能够有效测试模型在高原环境下对类似挑战(如小目标检测和低对比度场景)的适应能力. NWPU VHR-10数据集[22 ] 是西北工业大学(NWPU)创建的高分辨率遥感图像,共800张,目标类别涵盖了飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁和汽车10个类别. 该数据集呈现多样化的物体类别和复杂背景,可以有效评估模型在不同场景下对障碍物的检测能力. 对初始图片采用马赛克数据增强方法,在不改变尺寸的前提下,将数据集扩展至6 400张,其中训练集、验证集、测试集分别为4 800张、400张和1 200张. ...
多层级特征融合的无人机航拍图像目标检测
1
2023
... 实验分别利用公共遥感数据集VisDrone2019和NWPU VHR-10. VisDrone2019数据集[21 ] 包含8 629张由无人机摄像头捕获的图像,这些图像被划分为包含6 471张样本的训练集、含有548张样本的验证集以及含有1 610张样本的测试集. 数据集共分为行人、人、汽车、面包车、公共汽车、卡车、摩托、自行车、遮阳三轮车和三轮车10类. 该数据集包含复杂背景和多尺度目标,能够有效测试模型在高原环境下对类似挑战(如小目标检测和低对比度场景)的适应能力. NWPU VHR-10数据集[22 ] 是西北工业大学(NWPU)创建的高分辨率遥感图像,共800张,目标类别涵盖了飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁和汽车10个类别. 该数据集呈现多样化的物体类别和复杂背景,可以有效评估模型在不同场景下对障碍物的检测能力. 对初始图片采用马赛克数据增强方法,在不改变尺寸的前提下,将数据集扩展至6 400张,其中训练集、验证集、测试集分别为4 800张、400张和1 200张. ...
多尺度特征融合的遥感图像目标检测方法
1
2024
... 实验分别利用公共遥感数据集VisDrone2019和NWPU VHR-10. VisDrone2019数据集[21 ] 包含8 629张由无人机摄像头捕获的图像,这些图像被划分为包含6 471张样本的训练集、含有548张样本的验证集以及含有1 610张样本的测试集. 数据集共分为行人、人、汽车、面包车、公共汽车、卡车、摩托、自行车、遮阳三轮车和三轮车10类. 该数据集包含复杂背景和多尺度目标,能够有效测试模型在高原环境下对类似挑战(如小目标检测和低对比度场景)的适应能力. NWPU VHR-10数据集[22 ] 是西北工业大学(NWPU)创建的高分辨率遥感图像,共800张,目标类别涵盖了飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁和汽车10个类别. 该数据集呈现多样化的物体类别和复杂背景,可以有效评估模型在不同场景下对障碍物的检测能力. 对初始图片采用马赛克数据增强方法,在不改变尺寸的前提下,将数据集扩展至6 400张,其中训练集、验证集、测试集分别为4 800张、400张和1 200张. ...
多尺度特征融合的遥感图像目标检测方法
1
2024
... 实验分别利用公共遥感数据集VisDrone2019和NWPU VHR-10. VisDrone2019数据集[21 ] 包含8 629张由无人机摄像头捕获的图像,这些图像被划分为包含6 471张样本的训练集、含有548张样本的验证集以及含有1 610张样本的测试集. 数据集共分为行人、人、汽车、面包车、公共汽车、卡车、摩托、自行车、遮阳三轮车和三轮车10类. 该数据集包含复杂背景和多尺度目标,能够有效测试模型在高原环境下对类似挑战(如小目标检测和低对比度场景)的适应能力. NWPU VHR-10数据集[22 ] 是西北工业大学(NWPU)创建的高分辨率遥感图像,共800张,目标类别涵盖了飞机、舰船、油罐、棒球场、网球场、篮球场、田径场、港口、桥梁和汽车10个类别. 该数据集呈现多样化的物体类别和复杂背景,可以有效评估模型在不同场景下对障碍物的检测能力. 对初始图片采用马赛克数据增强方法,在不改变尺寸的前提下,将数据集扩展至6 400张,其中训练集、验证集、测试集分别为4 800张、400张和1 200张. ...
1
... 式中:TP为模型正确识别的目标数量,FP为模型错误辨识的目标数量,FN为模型的误判和漏掉数量. 实验选用mAP@0.5和mAP@0.5:0.95作为性能参考,其中mAP@0.5为IoU阈值为0.5时的平均精度均值,mAP@0.5:0.95为IoU为50%~95%时的平均精度均值. 衡量模型轻量化与性能的关键在于参数量N p 和计算量FLOPs. 模型的总参数量涵盖了权重和偏置的所有参数. 计算量反映了模型在前向传播过程中所需执行的浮点运算次数,通常用每秒浮点运算次数作为衡量标准[23 ] . ...
1
... 式中:TP为模型正确识别的目标数量,FP为模型错误辨识的目标数量,FN为模型的误判和漏掉数量. 实验选用mAP@0.5和mAP@0.5:0.95作为性能参考,其中mAP@0.5为IoU阈值为0.5时的平均精度均值,mAP@0.5:0.95为IoU为50%~95%时的平均精度均值. 衡量模型轻量化与性能的关键在于参数量N p 和计算量FLOPs. 模型的总参数量涵盖了权重和偏置的所有参数. 计算量反映了模型在前向传播过程中所需执行的浮点运算次数,通常用每秒浮点运算次数作为衡量标准[23 ] . ...
1
... 为了证明AO-YOLO算法的卓越性能,挑选目前流行的目标检测算法Faster-RCNN、RetinaNet[24 ] 、Cascade-RCNN[25 ] 、YOLOv3-tiny、YOLOv5n、YOLOv5s、YOLOv6n[26 ] 、YOLOv8n及改进算法cosSTR-YOLOv7、YOLOv8-NDTiny,在FOD数据集上进行对比测试. 所有实验均在一致的实验环境下开展,结果在表2 中呈现. ...
1
... 为了证明AO-YOLO算法的卓越性能,挑选目前流行的目标检测算法Faster-RCNN、RetinaNet[24 ] 、Cascade-RCNN[25 ] 、YOLOv3-tiny、YOLOv5n、YOLOv5s、YOLOv6n[26 ] 、YOLOv8n及改进算法cosSTR-YOLOv7、YOLOv8-NDTiny,在FOD数据集上进行对比测试. 所有实验均在一致的实验环境下开展,结果在表2 中呈现. ...
1
... 为了证明AO-YOLO算法的卓越性能,挑选目前流行的目标检测算法Faster-RCNN、RetinaNet[24 ] 、Cascade-RCNN[25 ] 、YOLOv3-tiny、YOLOv5n、YOLOv5s、YOLOv6n[26 ] 、YOLOv8n及改进算法cosSTR-YOLOv7、YOLOv8-NDTiny,在FOD数据集上进行对比测试. 所有实验均在一致的实验环境下开展,结果在表2 中呈现. ...
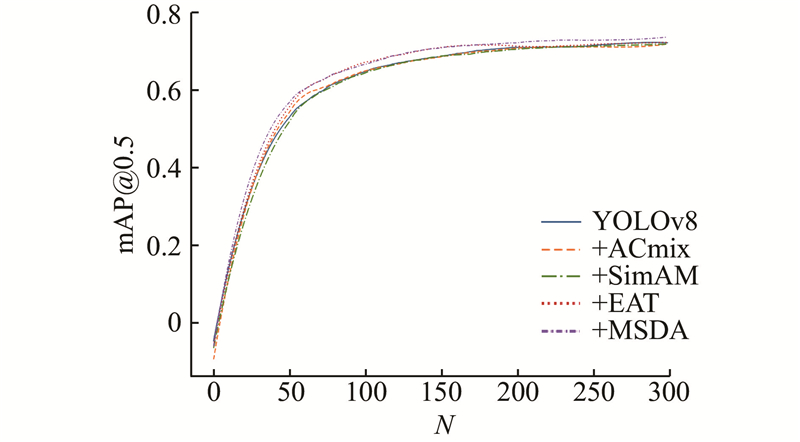
1
... 为了验证MSDA模块对检测精度的提升效果,将基线YOLOv8n模型与其他常见注意力模块进行整合,在相同的参数设置下进行对比实验. 在300轮的训练过程中,各模型的平均精度均值对比结果如图10 所示. 其中,N 为迭代次数. YOLOv8n模型在整合MSDA模块后,在整个训练周期内基本上维持了最高的检测精度. 从训练的第25个周期开始,该模块与ACmix[27 ] 、SimAM[28 ] 模块相比,已呈现出显著的性能差异. 尽管在前200个周期内与EAT模块[29 ] 的性能相当,但在最后100个周期的训练中,MSDA模块显著地展示了自身性能优势. ...
1
... 为了验证MSDA模块对检测精度的提升效果,将基线YOLOv8n模型与其他常见注意力模块进行整合,在相同的参数设置下进行对比实验. 在300轮的训练过程中,各模型的平均精度均值对比结果如图10 所示. 其中,N 为迭代次数. YOLOv8n模型在整合MSDA模块后,在整个训练周期内基本上维持了最高的检测精度. 从训练的第25个周期开始,该模块与ACmix[27 ] 、SimAM[28 ] 模块相比,已呈现出显著的性能差异. 尽管在前200个周期内与EAT模块[29 ] 的性能相当,但在最后100个周期的训练中,MSDA模块显著地展示了自身性能优势. ...
1
... 为了验证MSDA模块对检测精度的提升效果,将基线YOLOv8n模型与其他常见注意力模块进行整合,在相同的参数设置下进行对比实验. 在300轮的训练过程中,各模型的平均精度均值对比结果如图10 所示. 其中,N 为迭代次数. YOLOv8n模型在整合MSDA模块后,在整个训练周期内基本上维持了最高的检测精度. 从训练的第25个周期开始,该模块与ACmix[27 ] 、SimAM[28 ] 模块相比,已呈现出显著的性能差异. 尽管在前200个周期内与EAT模块[29 ] 的性能相当,但在最后100个周期的训练中,MSDA模块显著地展示了自身性能优势. ...





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}